
Усиление банковской безопасности: машинное обучение для обнаружения мошенничества
Опубликовано: 2023-11-14С каждой возможностью приходит угроза. Переход к цифровизации в банковской сфере улучшил качество обслуживания клиентов и расширил клиентскую базу за счет групп населения, ранее не охваченных банковскими услугами. Обратной стороной было то, что онлайн-транзакции и цифровые платежные решения открыли новые возможности для использования мошенниками.
Результаты исследования мошенничества, проведенного KMPG, показывают, что кибератаки становятся все более частыми и серьезными, что приводит к потерям в миллиарды долларов.
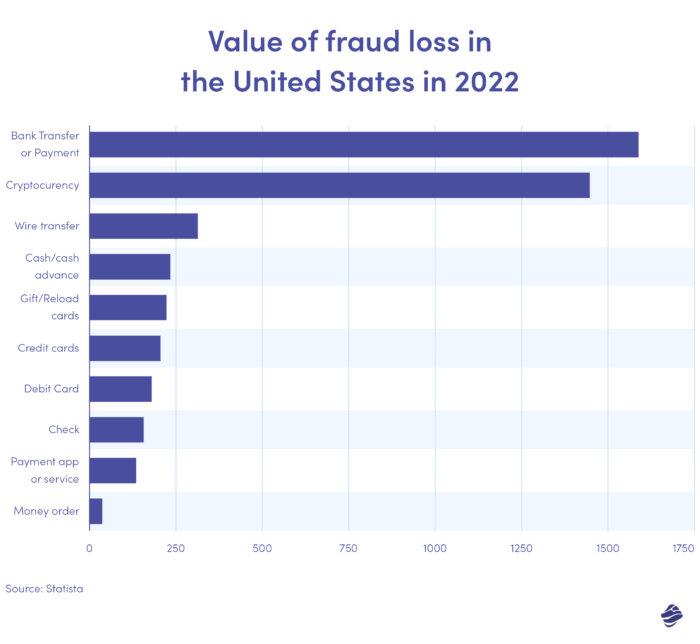
На приведенном выше графике показан размер потерь от мошенничества в зависимости от способа оплаты в США в 2022 году. Банковские переводы и платежи были самыми высокими: убытки составили 1,59 миллиарда долларов.
Эти потери вынудили банковские учреждения принять новые решения для обнаружения, смягчения и предотвращения финансового мошенничества. Одним из таких методов является искусственный интеллект (ИИ), в частности машинное обучение.
В этой статье мы обсудим все, что вам нужно знать о машинном обучении для обнаружения мошенничества , включая преимущества и реальные применения.
Эволюция обнаружения мошенничества
Традиционное обнаружение мошенничества основано на подходе, основанном на правилах. Как следует из названия, он действует в соответствии с набором правил или условий, которые определяют, является ли транзакция подлинной или мошеннической. К общим условиям относятся местоположение (находится ли покупка за пределами обычного региона пользователя?) и частота (обычно ли для пользователя количество и тип покупки?).
Транзакция состоится только тогда, когда она соответствует условиям. Например, у клиента из Огайо внезапно возникла оплата в POS-терминале в Новой Зеландии. Местоположение находится за пределами кода города пользователя, поэтому система помечает транзакции как мошеннические.
У этого типа системы обнаружения мошенничества есть несколько недостатков.
- Это дает большое количество ложных срабатываний. Здесь вы блокируете платежи от реальных клиентов.
- Это негибко. Подход, основанный на правилах, использует фиксированные результаты, что затрудняет адаптацию к тенденциям в цифровом банкинге. Вы должны изменить правила, чтобы выявить новые формы мошенничества.
- Это не масштабируется. Когда объем данных увеличивается, растут и усилия, необходимые для предотвращения этого. Любые изменения в системе вносятся вручную, что делает это дорогостоящим и трудоемким.
Обнаружение мошенничества на основе правил работает. Однако его недостатки делают его непригодным для современной цифровой среды. Он не может распознавать закономерности и полагается на вмешательство человека.
Кроме того, хакеры не придерживаются графика с 9 до 5 и могут использовать сложные методы, такие как подмена местоположения и имитация поведения клиента, чтобы обмануть системы обнаружения мошенничества. Поэтому вам нужна столь же высокоразвитая система, работающая 24/7.
Введите машинное обучение.
Машинное обучение — это искусственный интеллект (ИИ) , который использует данные для обучения алгоритмов обнаружения мошенничества, чтобы выявлять закономерности и взаимосвязи данных, получать ценную информацию и делать прогнозы.
Вы уже знакомы с машинным обучением, даже если не знаете его. Например, всякий раз, когда вы взаимодействуете с публикацией в Instagram, вы передаете алгоритму информацию о типе контента, который вам нравится. Затем он просматривает приложение в поисках аналогичного контента, который можно добавить в ленту.
Как машинное обучение изменит обнаружение мошенничества
Обнаружение мошенничества в банковской сфере с помощью машинного обучения уже меняет отрасль, обеспечивая более быстрое, гибкое и точное выявление мошенничества и реагирование на него.
Система искусственного интеллекта анализирует закономерности в данных о клиентах и автоматически меняет правила на основе исторических и новых угроз.
Помните комиссию в POS-терминалах Новой Зеландии, о которой мы упоминали ранее? При обнаружении мошенничества с использованием машинного обучения будет учитываться, что на той же банковской карте есть покупка на рейс в это место. Поэтому новый дебет, скорее всего, законен.
Для обучения алгоритмов обнаружению мошенничества используются две модели: контролируемое машинное обучение и неконтролируемое машинное обучение.
Контролируемое машинное обучение
Модель контролируемого обучения передает алгоритмам большие объемы данных, помеченных как мошенничество или не мошенничество. Алгоритм изучает эти примеры и узнает, какие закономерности и отношения отличают законные транзакции от мошеннических.
Эта модель обучения требует много времени, поскольку требует ручной разметки данных. Более того, ваши наборы данных должны быть правильно маркированы и хорошо организованы. Неправильно помеченная транзакция повлияет на точность алгоритма.
Кроме того, он обучается только на основе входных данных, включенных в обучающий набор. Таким образом, транзакции с использованием функций вашего недавно запущенного мобильного банковского приложения, которые не были частью исторических данных, не будут помечены. Теперь появилась лазейка, которой могут воспользоваться мошенники.
Машинное обучение без учителя
Модель обучения без присмотра требует минимального участия человека. Алгоритм изучает закономерности и взаимосвязи на больших объемах немаркированных данных, группируя наборы данных на основе сходств и различий.
Цель состоит в том, чтобы обнаружить необычную активность, не включенную в набор обучающих данных. Таким образом, неконтролируемое обучение начинается там, где контролируемое обучение прекращается, и обнаруживает новые случаи мошенничества.
Помните, что вам не нужно выбирать между контролируемой и неконтролируемой моделью машинного обучения. Вы можете использовать их вместе (модель обучения с полуконтролем) или независимо.
Преимущества использования ML для обнаружения мошенничества
Мы намекнули на преимущества обнаружения мошенничества с использованием машинного обучения в банковской сфере, но давайте обсудим их дальше.
- Скорость
Вычисления машинного обучения происходят быстро и принимают решения о мошенничестве в режиме реального времени. Хотя алгоритмы, основанные на правилах, также принимают решения в режиме реального времени, они полагаются на письменные правила для выявления мошенничества.
Что происходит в новых сценариях без заранее определенных правил? Это приводит к ложноположительным или ложноотрицательным результатам.
Машинное обучение автоматически обнаруживает новые закономерности, анализируя регулярную активность клиентов и рассчитывая соответствующие результаты в течение миллисекунд.
- Точность
Системы обнаружения на основе правил блокируют подлинные транзакции или допускают мошеннические, поскольку они не обнаруживают нюансов в поведении клиентов.
Системы машинного обучения учитывают переменные, выходящие за рамки прописанных правил, например, известное мошенническое поведение. Эти переменные помогают контекстуализировать транзакцию, снижая уровень ложных срабатываний.
- Гибкость
Машинное обучение является гибким и реактивным. Способность самообучения позволяет этой системе адаптироваться к новым сценариям и обнаруживать новые угрозы. Системы, основанные на правилах, являются жесткими и не обладают возможностями обучения. Поэтому он может реагировать на мошенническую деятельность только в соответствии с заранее определенными правилами.
- Эффективность
Алгоритмы машинного обучения могут анализировать тысячи данных транзакций в секунду. Вместо того, чтобы тратить рабочую силу и накладные расходы на расследование случаев мошенничества низкой и средней степени тяжести, машинное обучение может обрабатывать повторяющиеся или явные случаи мошенничества. Это позволяет специалистам по мошенничеству сосредоточиться на сложных закономерностях, требующих человеческого понимания.
- Масштабируемость
Увеличение объема данных оказывает давление на системы, основанные на правилах. Новые правила усложняют систему, затрудняя ее обслуживание. Любая ошибка или противоречие может сделать всю модель неэффективной.
Системы машинного обучения — полная противоположность. Они не только усваивают большие объемы новых данных, но и совершенствуются.
Методы машинного обучения, используемые для обнаружения мошенничества
Прежде чем мы рассмотрим различные алгоритмы, используемые при обнаружении мошенничества с помощью ИИ, давайте рассмотрим, как работает система.
Первый шаг — ввод данных. Точность модели зависит от объема и качества данных. Чем больше высококачественных данных вы добавите, тем точнее станет модель.
Затем модель анализирует данные и извлекает ключевые характеристики , которые описывают нормальное поведение в сравнении с мошенническим. Эти функции включают в себя идентификацию клиента (адрес электронной почты или номер телефона), местоположение (IP-адрес или адрес доставки), способы оплаты (имя владельца карты и страну происхождения) и многое другое.
Третий шаг — обучение алгоритма (с большим количеством данных) различению подлинных и мошеннических транзакций. Модель получает обучающий набор данных и прогнозирует вероятность мошенничества в различных случаях. Как только алгоритм будет достаточно обучен, вы готовы его запустить.
Теперь давайте посмотрим на различные алгоритмы, которые вы можете использовать.
1. Логистическая регрессия
Логистическая регрессия — это контролируемый алгоритм обучения. Он рассчитывает вероятность мошенничества в двоичной шкале – мошенничество или отсутствие мошенничества – на основе параметров модели.
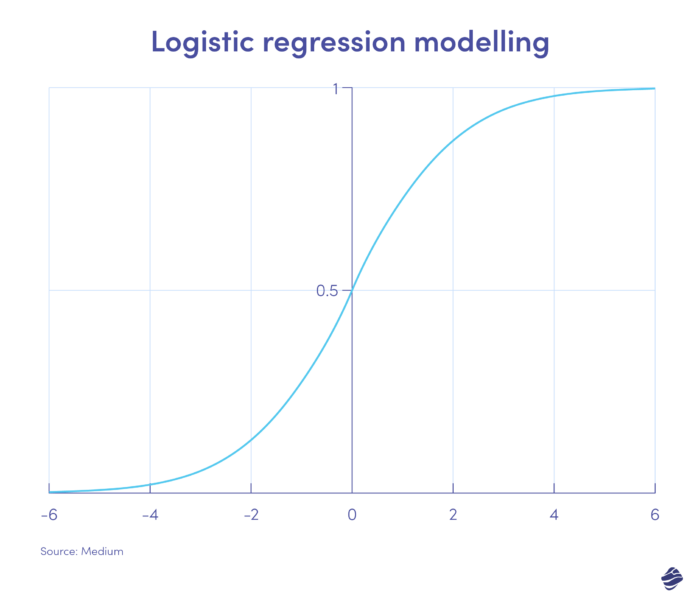
Транзакции, попадающие в положительную сторону графика, скорее всего, являются мошенническими, а те, что находятся в отрицательной части графика, скорее всего, являются законными.
2. Дерево решений
Дерево решений — это контролируемый алгоритм обучения, но он выходит за рамки алгоритмов логистической регрессии. Это иерархическая структура принятия решений, которая анализирует данные по уровням, чтобы определить, является ли транзакция подлинной или мошеннической.
Ниже показано дерево решений для обнаружения мошенничества с кредитными картами.
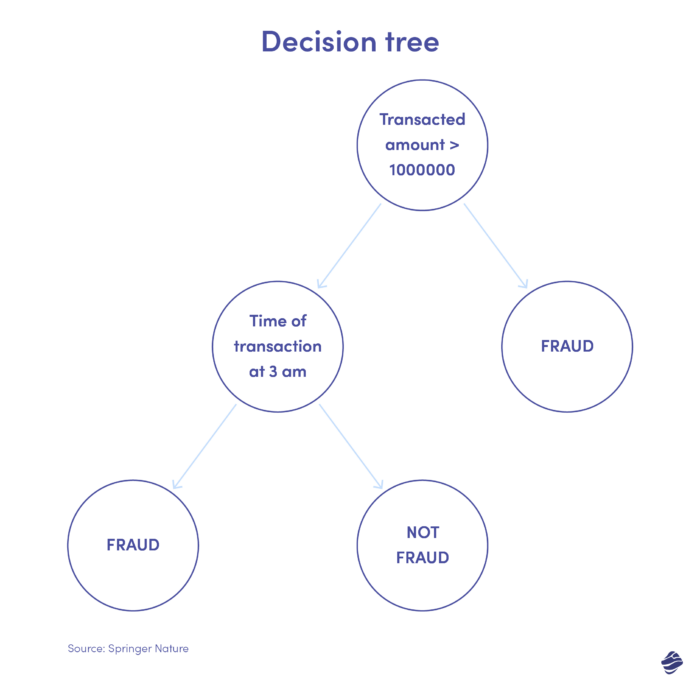
Условием определения того, является ли транзакция мошеннической, является сумма транзакции. Если стоимость транзакции превышает установленный порог, алгоритм считает ее мошеннической. Если нет, дерево проверяет другое условие — время транзакции. Если время необычное (здесь, 3 часа ночи), скорее всего, это мошенничество. Если нет, проверяется другое условие. Это продолжается.
3. Случайный лес
Случайный лес — это комбинация множества деревьев решений, где каждое дерево решений проверяет различные условия — идентичность, местоположение и т. д.
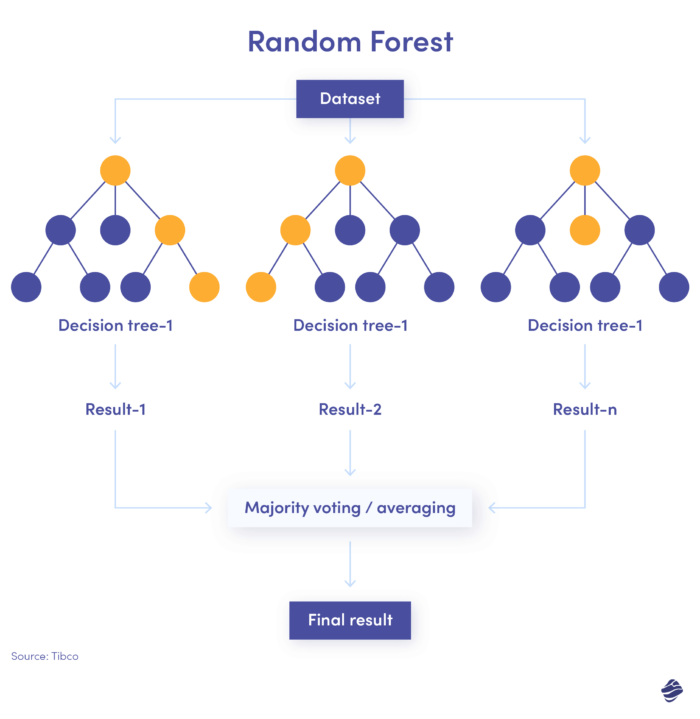
После проверки всех параметров каждое поддерево предлагает решение. Общая сумма определяет, является ли транзакция подлинной или мошеннической.

4. Нейронные сети
Нейронные сети — это сложные неконтролируемые алгоритмы. Вдохновленные человеческим мозгом, нейронные сети обрабатывают данные на нескольких уровнях для извлечения функций высокого уровня. Этот алгоритм идет рука об руку с глубоким обучением, которое позволяет распознавать закономерности в изображениях, тексте, аудио и других данных.
Вот упрощенная версия нейронной сети.
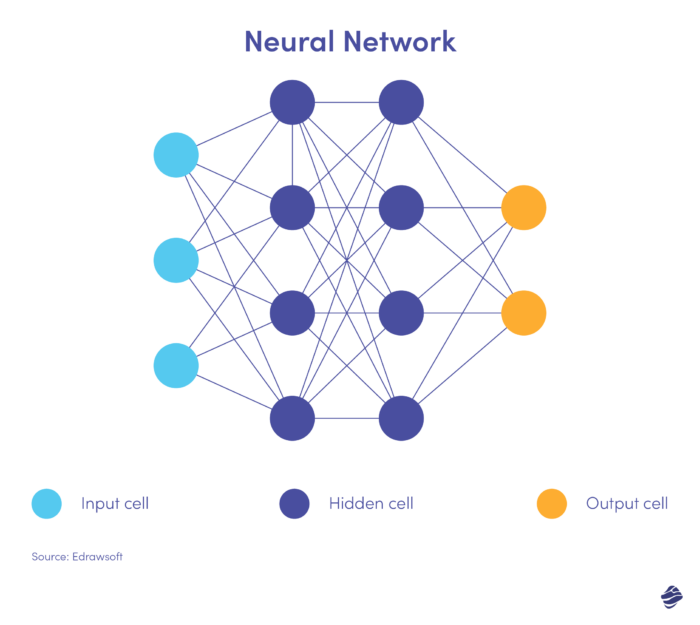
Нейронная сеть имеет три слоя: входной, скрытый и выходной. Входной уровень обрабатывает данные, скрытый уровень анализирует данные входного слоя для выявления скрытых закономерностей, а выходной уровень классифицирует данные.
Глубокие нейронные сети имеют несколько скрытых слоев. Они отлично подходят для выявления нелинейных связей и выявления беспрецедентных сценариев мошенничества.
5. Машина опорных векторов
Машины опорных векторов (SVM) — это контролируемые алгоритмы обучения, которые прогнозируют, классифицируют и обнаруживают выбросы.
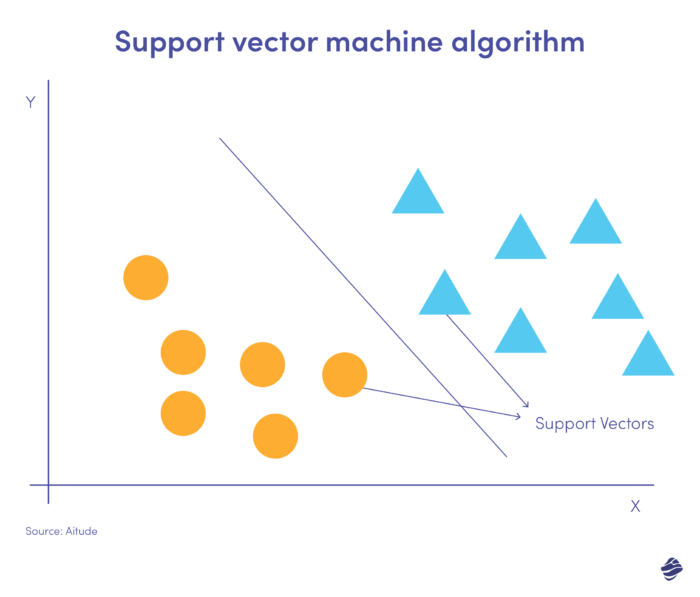
На этой линейной иллюстрации SVM показаны два набора данных, разделенные прямой линией, называемой гиперплоскостью. Это граница принятия решения, которая классифицирует данные как мошенничество и не мошенничество.
Точки данных, находящиеся дальше от гиперплоскости, легко классифицируются. Опорные векторы (ближайшие к гиперплоскости) сложно классифицировать. Эти выбросы могут повлиять на положение гиперплоскости, если их удалить.
6. K-ближайший сосед
K-ближайший сосед (KNN) — это контролируемый алгоритм обучения. Он действует исходя из предположения, что похожие предметы существуют рядом друг с другом.
Ниже приведена простая иллюстрация.
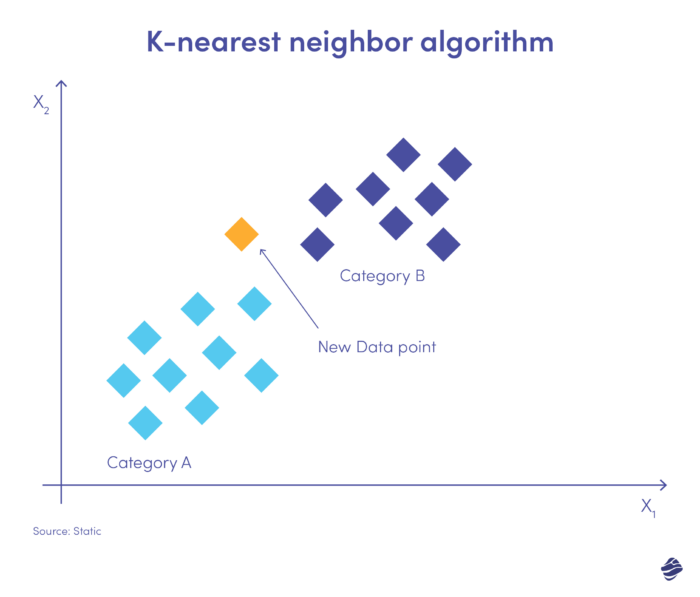
Новые данные необходимо поместить либо в категорию A, либо в категорию B. Алгоритм рассчитывает расстояние между точками данных, используя математическое уравнение, называемое евклидовым расстоянием. Новая точка данных попадает в группу с наибольшим количеством соседей. Если ближайший набор данных помечен как «мошенничество», эта транзакция классифицируется как мошенническая.
Решение проблем и стратегические соображения
Как и со всеми технологиями, с интеграцией машинного обучения для обнаружения мошенничества возникают проблемы роста. Вот некоторые распространенные проблемы, с которыми вы можете столкнуться.
Неадекватная инфраструктура
Многие банковские системы не могут анализировать большие объемы сложных данных. Более того, большая часть данных разрознена и размещена в отдельных хранилищах.
К сожалению, быстрого решения этой проблемы не существует. Вам придется инвестировать в соответствующее оборудование и программное обеспечение.
Вам нужно будет сотрудничать с опытным агентством по разработке приложений Fintech и настроить инфраструктуру для автоматического выбора подходящих алгоритмов для конкретных наборов данных, импорта необработанных данных и подготовки их к машинному обучению, визуализации данных, тестирования алгоритма и многого другого.
Качество и безопасность данных
Качество данных является серьезной проблемой для финансовых учреждений, стремящихся внедрить машинное обучение для обнаружения мошенничества. Модели машинного обучения не различают хорошие и плохие данные. Итак, если алгоритм испорчен нерелевантными или неполными данными, точность вашей модели будет неверной.
Решения для приема данных, такие как Amazon Kinesis, собирают, очищают и преобразовывают необработанные данные, что делает их пригодными для моделей машинного обучения. После того как данные очищены и систематизированы, вы должны разделить конфиденциальные и неконфиденциальные данные. Зашифруйте конфиденциальную информацию и храните ее в защищенных местах. Вам также следует ограничить доступ к этим данным.
Отсутствие таланта
Несмотря на то, чего люди боятся, машинное обучение не крадет рабочие места. Все совсем наоборот. Нам по-прежнему нужны аналитики по мошенничеству для управления сложными делами, требующими человеческого понимания и опыта. Кроме того, машинное обучение — это новая технология, и в этой области недостаточно специалистов.
Это хорошая новость для соискателей работы, но не для учреждений, которые не могут извлечь выгоду из всего потенциала машинного обучения. Вы можете преодолеть этот барьер, сотрудничая с компаниями, обладающими навыками внедрения машинного обучения.
Тематические исследования по выявлению мошенничества в банковской сфере с помощью машинного обучения
Теперь давайте посмотрим на реальные примеры обнаружения мошенничества в банковской сфере с помощью машинного обучения.
Обнаружение мошенничества
Danske Bank — датская транснациональная финансовая корпорация. Это крупнейший банк Дании и ведущий розничный банк в Северной Европе. В рамках системы обнаружения, основанной на правилах, банк изо всех сил пытался снизить риск мошенничества. Уровень обнаружения мошенничества составил 40%, а уровень ложных срабатываний — 99,5%.
Сотрудничая с Teradata, компанией-разработчиком программного обеспечения для обработки данных, Danske интегрировала программное обеспечение глубокого обучения, которое поможет выявить потенциальную мошенническую деятельность. Результатом стало снижение количества ложных срабатываний на 60% и увеличение количества истинных срабатываний на 50%.
Борьба с обмыванием денег
OakNorth — коммерческий кредитный банк в Великобритании, предоставляющий деловые и личные финансовые услуги масштабирующимся компаниям. В банке был разрозненный процесс проверки: один провайдер проводил проверки на предмет борьбы с отмыванием денег, а другой — клиентов. Более того, проверки политически значимых лиц (PEP) дали множество ложных срабатываний.
Сотрудничая с ComplyAdvantage, компанией по обнаружению случаев мошенничества и ПОД, банк интегрировал решение для проверки и постоянного мониторинга для оптимизации соблюдения требований и консолидации данных. Это способствовало быстрой передаче данных между кредитными и сберегательными операциями банка.
Кредитное андеррайтинг
Кредитный союз Гавайев США — крупнейший кредитный союз на Гавайях и один из лучших кредитных союзов по версии журнала Forbes. Компания хотела быть конкурентоспособной по отношению к финтех-компаниям и увеличивать свой портфель личных кредитов без увеличения риска.
Работая с Zest AI, кредитный союз автоматизировал процессы принятия решений, используя модель потребительского кредитования на основе искусственного интеллекта. В модели использовалось 278 переменных, чтобы обеспечить более глубокое понимание, чем в системе кредитного скоринга VantageScore. Результатом стало увеличение количества одобренных заявок на 21% и 0% случаев мошенничества с заявками на кредит или дефолт.
Ключевые соображения при использовании машинного обучения для обнаружения мошенничества
Хотя обнаружение мошенничества в банковской сфере с использованием машинного обучения является эффективным, оно также является сложной задачей. Эти системы требуют большого количества точных данных, иначе модели работают не так хорошо, как должны.
Итак, вот несколько советов по оптимизации процесса машинного обучения.
1. Ограничьте количество входных переменных
В этой статье мы говорили: «Чем больше, тем лучше». Это остается верным и в отношении объема данных. Однако чем меньше, тем лучше, учитывая количество переменных для обнаружения мошенничества.
Типичные особенности, которые следует учитывать при расследовании мошенничества, включают:
- айпи адрес
- Адрес электронной почты
- Адрес доставки
- Средняя стоимость заказа/транзакции
Преимущество меньшего количества функций заключается в сокращении времени обучения алгоритма. Вы также избегаете проблем перекрытия или нерелевантных наборов данных.
2. Обеспечить соблюдение нормативных требований
Предотвращение мошенничества является частью безопасности данных. Второе — конфиденциальность данных. Во многих странах действуют законы о том, как учреждения могут собирать, использовать и хранить данные клиентов. Есть Закон Китая о защите личной информации (PIPL), Калифорнийский закон о конфиденциальности потребителей (CCPA) и Общий регламент по защите данных Европейского Союза (GDPR), и это лишь некоторые из них.
Эти законы имеют значение для данных, используемых в машинном обучении. Основным принципом большинства правил соблюдения конфиденциальности данных является уведомление/согласие. Вы должны уведомить и получить разрешение на использование данных клиентов для целей, отличных от запросов пользователей, включая данные для обучения алгоритмов машинного обучения.
Самый простой способ обеспечить соблюдение стандартов конфиденциальности — использовать технических партнеров с функциями, соответствующими нормативным требованиям. Например, вам следует сотрудничать с компанией по разработке банковских приложений, которая понимает, как обеспечить конфиденциальность и безопасность данных.
3. Установите разумный порог
Правила стоимости транзакции имеют минимальные требования для запуска ответа о принятии или отклонении. Вам нужен порог, который сочетает в себе безопасность и удобство использования. Если порог слишком строгий, вы рискуете заблокировать законные транзакции. Если порог будет слишком мягким, вы увеличите количество успешных случаев мошенничества.
Рассчитайте свою склонность к риску, чтобы найти правильный баланс. Уровни риска различаются для каждого финансового учреждения или продукта. Например, предложение микрокредитного банка может установить высокий порог для кредитов на небольшую сумму. Коммерческий банк не может быть столь щедрым на ипотечные кредиты.
Предвидя будущее
Будущее уже наступило, однако только 17% организаций используют машинное обучение в программах по борьбе с мошенничеством. Не оставайтесь позади.
Вот некоторые прорывы, которых можно ожидать в обеспечении безопасности вашего банка с помощью машинного обучения.
- Профилирование устройств : идентифицируйте различные устройства, подключающиеся к вашей банковской сети, анализируя функции и поведение каждого конкретного устройства.
- Автоматическое обнаружение аномалий и реагирование : выявляйте мошенническое поведение известных устройств и изолируйте затронутые системы.
- Обнаружение нулевого дня : выявляйте ранее неизвестные уязвимости и вредоносное ПО для защиты организаций от кибератак.
- Маскирование данных : автоматически обнаруживает и анонимизирует конфиденциальные данные.
- Масштабируемая аналитика : выявляйте тенденции мошенничества на различных устройствах и в разных местах.
- Инновационная политика : используйте данные машинного обучения для разработки соответствующих политик безопасности.
Независимо от того, являетесь ли вы учреждением по управлению активами или кредитным союзом, искусственный интеллект и машинное обучение открывают огромные возможности для обнаружения мошенничества.
Однако важно помнить, что хакеры также используют эти технологии для обхода защитных мер. Обновите свои модели машинного обучения, чтобы опережать эти атаки. Вы также можете усилить свою безопасность на основе искусственного интеллекта с помощью старого доброго человеческого интеллекта.