
Анализ файла журнала: умная альтернатива Google Analytics
Опубликовано: 2022-03-08Знаете ли вы, что происходит на вашем сайте каждый день? Первое, что приходит на ум при ответе на этот вопрос, скорее всего, это использование инструментов отслеживания аудитории и поведения. На рынке доступно множество таких инструментов, включая Google Analytics, At Internet, Matomo, Fathom Analytics и Simple Analytics, и это лишь некоторые из них. Хотя эти инструменты позволяют нам иметь довольно хорошее представление о том, что происходит в любой момент времени на наших веб-сайтах, этические нормы, применяемые этими инструментами, в частности Google Analytics, снова ставятся под сомнение.
Это говорит о том, что существуют другие источники данных, которые в настоящее время недостаточно используются всеми владельцами веб-сайтов: журналы.
Инструменты анализа и GDPR (с акцентом на Google Analytics)
Личные данные стали чувствительным предметом во Франции после введения в действие Общего регламента по защите данных (GDPR) и создания Национальной комиссии по информатике и свободе (CNIL). Защита данных стала приоритетом.
Итак, ваш веб-сайт по-прежнему соответствует требованиям GDPR?
Если мы посмотрим на все веб-сайты, мы обнаружим, что многие нашли способ обойти правила, используя свои файлы cookie (баннеры для сбора данных) для сбора необходимой им информации, в то время как другие по-прежнему строго придерживаются официальных правил.
Собирая эту информацию, инструменты анализа данных позволяют нам анализировать, откуда приходит аудитория и поведение посетителей. Этот вид анализа требует безупречного плана тегирования для сбора максимально надежных и точных данных, и, в конечном счете, собранные данные являются результатом каждого действия и события на сайте.
После ряда жалоб CNIL решил обратить внимание на Google Analytics, объявив его на время незаконным во Франции. Эта санкция исходит из очевидного отсутствия надзора за передачей личных данных разведывательным службам в Соединенных Штатах, хотя информация о посетителях ранее собиралась с их согласия. Следует внимательно следить за развитием событий.
В этом текущем контексте с ограниченным доступом к Google Analytics или без него было бы интересно рассмотреть другие варианты сбора данных. Компиляция исторических событий сайта и относительно простые для восстановления файлы журналов являются отличным источником информации.
Несмотря на то, что файлы журналов обеспечивают доступ к интересному архиву информации для анализа, они не позволяют нам отображать бизнес-ценности или реальное поведение посетителя сайта, например навигацию по сайту с самого начала до того момента, когда он или она проверяет корзину покупок или покидает страницу. сайт. Однако поведенческий аспект остается специфичным для инструментов, упомянутых выше; анализ журнала может помочь нам продвинуться довольно далеко.
Понимание файлов журнала
Что такое лог-файлы? Журналы — это тип файла, основной задачей которого является хранение истории событий.
О каких событиях идет речь? По сути, «события» — это посетители и роботы, которые заходят на ваш сайт каждый день.
Консоль поиска Google также может собирать эту информацию, но по ряду причин, в частности из соображений конфиденциальности, она применяет очень специфический фильтр.
(Источник: https://support.google.com/webmasters/answer/7576553. «Различия между Search Console и другими инструментами».)
Следовательно, у вас будет только образец того, что может предоставить анализ журнала. Благодаря лог-файлам у вас есть доступ ко 100% данных!
Анализ строк файлов журнала может помочь вам расставить приоритеты для ваших будущих действий.
Вот несколько примеров прошлых посещений сайта Oncrawl разными роботами:
ФЕЙСБУК:
66.220.149.10 www.oncrawl.com - [07/Feb/2022:00:18:35 +0000] "GET /feed/ HTTP/1.0" 200 298008 "-" "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)"
СЕМРУШ:
185.191.171.20 fr.oncrawl.com - [13/Feb/2022:00:18:27 +0000] "GET /infographie/mises-jour-2017-algorithme-google/ HTTP/1.0" 200 50441 "-" "Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)"
БИНГ:
207.46.13.188 www.oncrawl.com - [22/Jan/2022:00:18:40 +0000] "GET /wp-content/uploads/2018/04/url-detail-word-count.png HTTP/1.0" 200 156829 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
ГУГЛ БОТ:
66.249.64.6 www.oncrawl.com - [21/Jan/2022:00:19:12 +0000] "GET /product-updates/introducing-search-console-integration-skyrocket-organic-search/ HTTP/1.0" 200 73497 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
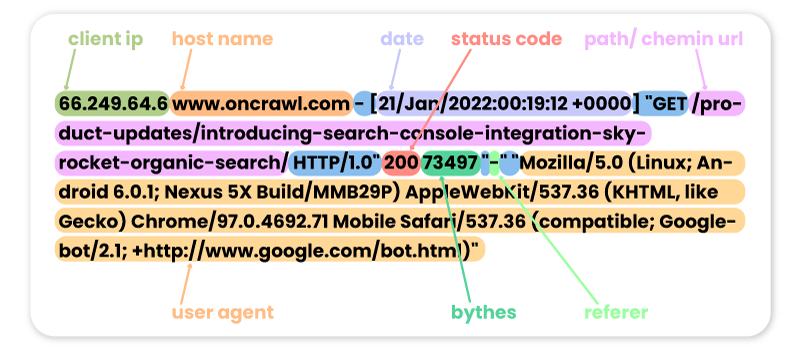
Обратите внимание, что некоторые визиты ботов могут быть поддельными. Важно не забыть проверить IP-адреса, чтобы узнать, являются ли они реальными посещениями от Googlebot, Bingbot и т. д. За этими поддельными пользовательскими агентами могут стоять профессионалы, которые иногда запускают роботов для доступа к вашему сайту и проверки ваших цен, вашего контента или других данных. информацию, которую они считают полезной. Чтобы их распознать, поможет только IP!
Вот несколько примеров посещений сайта Oncrawl пользователями Интернета:
С Google.com:
41.73.11x.xxx fr.oncrawl.com - [13/Feb/2022:00:25:29 +0000] "GET /seo-technique/predire-trafic-seo-prophet-python/ HTTP/1.0" 200 57768 "https://www.google.com/" "Mozilla/5.0 (Linux; Android 10; Orange Sanza touch) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.98 Mobile Safari/537.36"
Из UTM Google Рекламы:
199.223.xxx.x www.oncrawl.com - [11/Feb/2022:15:18:30 +0000] "GET /?utm_source=sea&utm_medium=google-ads&utm_campaign=brand&gclid=EAIaIQobChMIhJ3Aofn39QIVgoyGCh332QYYEAAYASAAEgLrCvD_BwE HTTP/1.0" 200 50423 "https://www.google.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
От LinkedIn благодаря рефереру:
181.23.1xx.xxx www.oncrawl.com - [14/Feb/2022:03:54:14 +0000] "GET /wp-content/uploads/2021/07/The-SUPER-SEO-Game-Building-an-NLP-pipeline-with-BigQuery-and-Data-Studio.pdf HTTP/1.0" 200 3319668 "https://www.linkedin.com/"
[Электронная книга] Четыре варианта использования SEO-анализа журнала
 Скачать бесплатно
Скачать бесплатноЗачем анализировать содержимое журнала?
Теперь, когда мы знаем, что на самом деле содержат журналы, что мы можем с этим сделать? Ответ: анализируйте их, как и любой другой инструмент аналитики.

Боты или роботы
Здесь мы можем задать себе следующий вопрос:
Какие роботы проводят больше всего времени на моем сайте?
Если ориентироваться на поисковые системы, с детальным просмотром каждого бота, вот что мы можем увидеть:
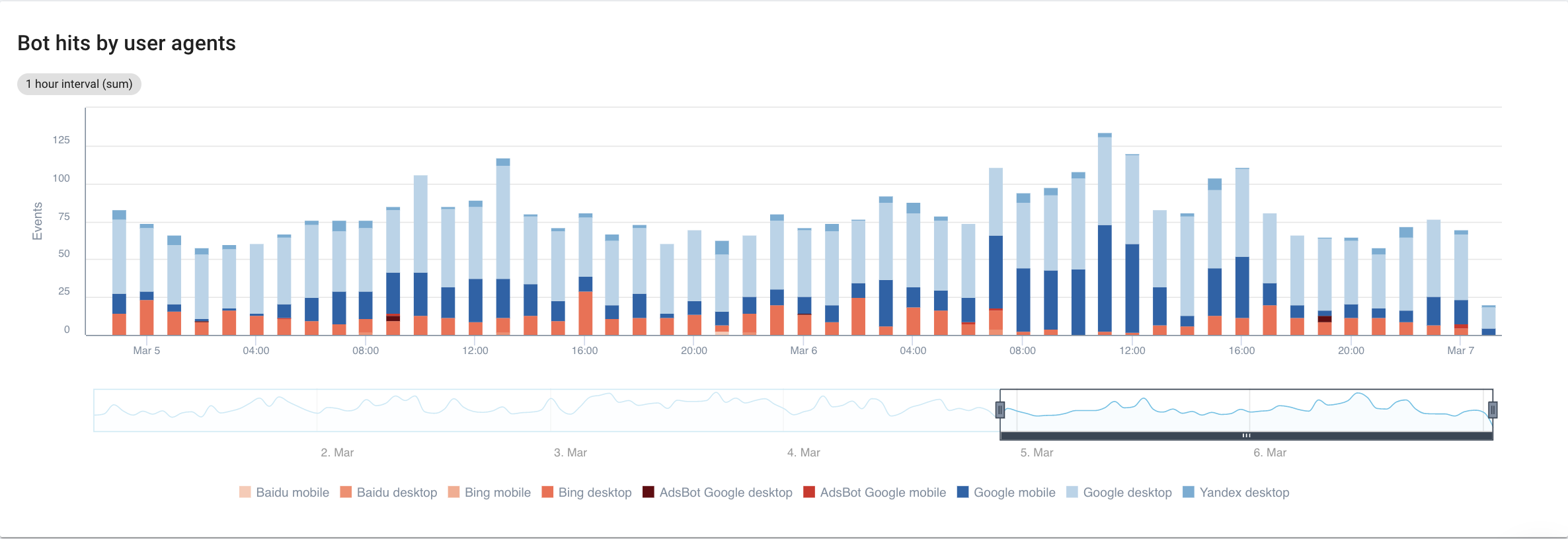
Источник: приложение Oncrawl.
Очевидно, что Google Mobile и Desktop тратят на сканирование гораздо больше времени, чем боты Bing или Yandex. Доля Googlebot на мировом рынке составляет более 90%.
Если Google сканирует мои страницы, индексируются ли они автоматически? Нет, не обязательно.
Если мы вернемся на несколько лет назад, Google использовал автоматический рефлекс для индексации страниц сразу после их посещения. Сегодня это уже не так, учитывая объем страниц, которые он должен обрабатывать. В результате начинается SEO-битва за краулинговый бюджет.
При всем этом вы можете спросить: какой смысл знать, какой бот проводит на моем сайте больше времени, чем другой?
Ответ на этот вопрос зависит от каждого из алгоритмов ботов. Каждый из них немного отличается и не обязательно возвращается по одним и тем же причинам.
У каждой поисковой системы есть свой краулинговый бюджет, который она распределяет между этими ботами . Другими словами, это означает, что Google делит свой краулинговый бюджет между всеми этими ботами. Поэтому становится довольно интересно посмотреть поближе на то, что делает GooglebotAds, особенно если у нас завалялись ошибки 404. Их очистка — это способ оптимизировать краулинговый бюджет и, в конечном счете, SEO.
Анализатор журнала сканирования
 Учить больше
Учить большеСопоставление данных Googlebot с данными Oncrawl Crawler
Чтобы глубже проанализировать поведение робота Googlebot, Oncrawl сопоставляет данные журнала с данными сканирования, чтобы получить наиболее подробную и точную информацию.
Цель также состоит в том, чтобы подтвердить или опровергнуть гипотезы, связанные с несколькими ключевыми показателями эффективности, такими как глубина, содержание, производительность и т. д.
Соответственно, вы должны задать себе правильные вопросы:
- Сканирует ли робот Googlebot все страницы вашего сайта? Интересуйтесь коэффициентом сканирования, который четко предоставляет эту информацию, которую вы также можете отфильтровать с помощью сегментации своих страниц.
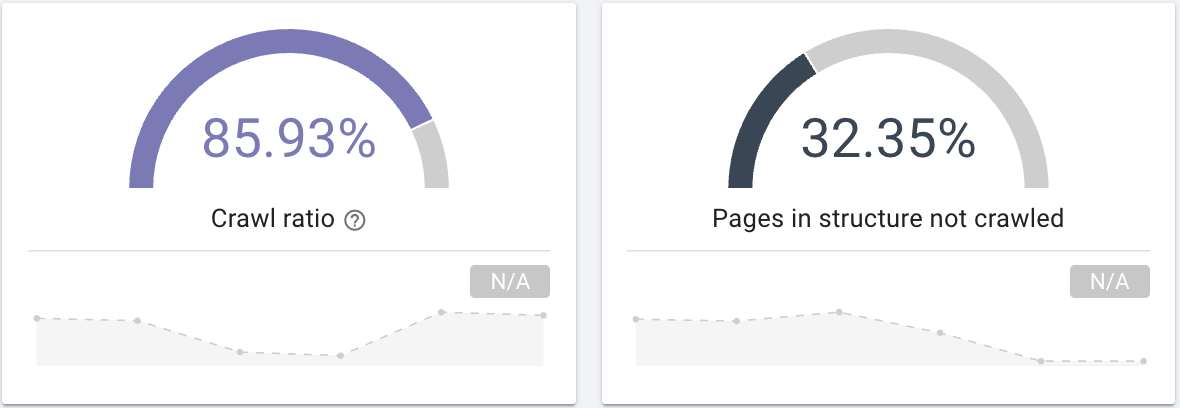
Источник: приложение Oncrawl.
- На какую категорию тратит свое время робот Googlebot? Является ли это оптимальным использованием краулингового бюджета? На этом графике в отчете Oncrawl о воздействии на SEO данные перекрестно ссылаются, и вы получаете эту информацию.
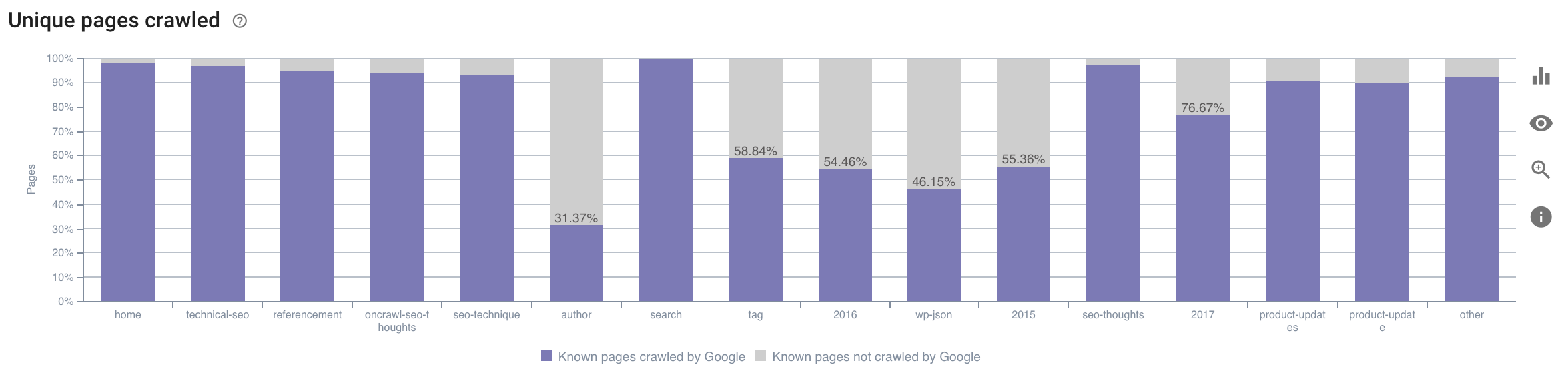 Источник: приложение Oncrawl.
Источник: приложение Oncrawl.
- У нас также могут возникнуть вопросы, выходящие за рамки того, что по умолчанию предлагает отчет о сканировании Oncrawl. Например, влияет ли длина описания на поведение робота Googlebot? У нас есть данные об этом благодаря сканированию, поэтому мы можем использовать их для создания сегментации, как показано ниже:
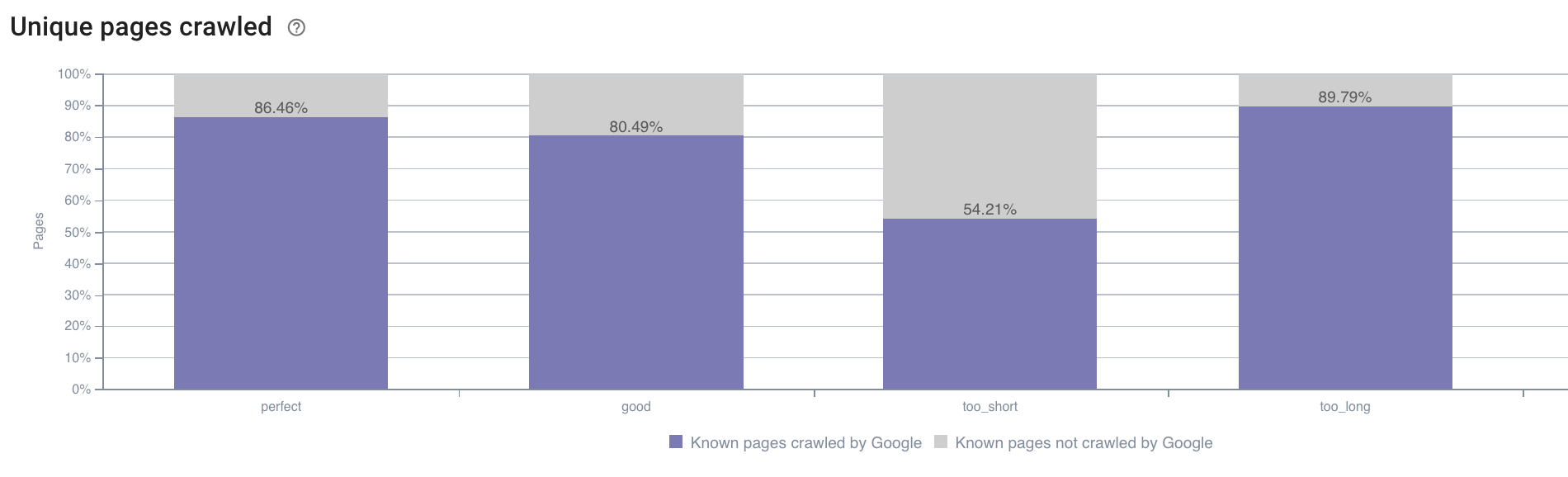
Источник: приложение Oncrawl.
Слишком короткие описания сканируются гораздо реже, чем те, которые имеют идеальный размер, определяемый приложением Oncrawl как «идеальный» или «хороший» (от 110 до 169 символов).
Если описание соответствует критериям релевантности и размера, робот Googlebot с радостью увеличит свой краулинговый бюджет на релевантных страницах.
Примечание. Google иногда переписывает страницы, которые считаются слишком длинными.
Анализ посещаемости сайта с помощью журналов
Далее, если мы посмотрим на пример SEO, поскольку это то, что мы пытаемся проанализировать с помощью Oncrawl, я предлагаю вам задать себе еще один вопрос:
- Какова корреляция между поведением робота Googlebot и посещениями SEO?
Oncrawl имеет те же графики для перекрестных ссылок между данными сканирования и посещениями SEO, полученными в журналах.
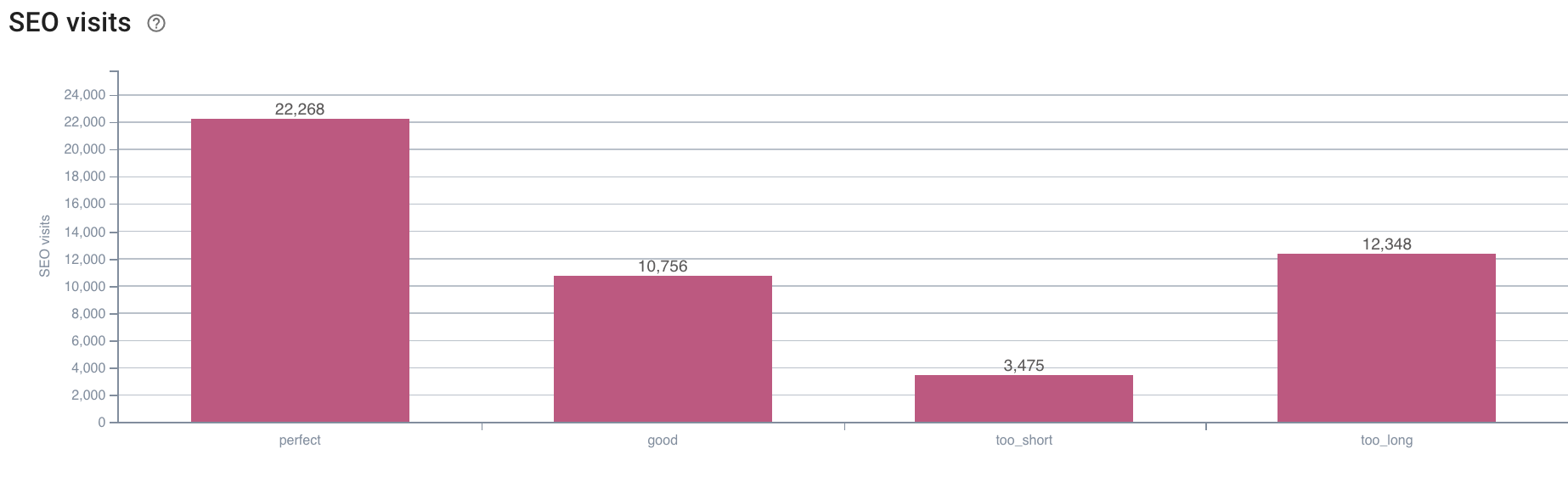 Источник: приложение Oncrawl.
Источник: приложение Oncrawl.
Ответ очень ясен: страницы с «идеальной» длиной описания — это те, которые, по-видимому, генерируют больше всего SEO-посещений. Поэтому мы должны сосредоточить наши усилия на этом направлении. Помимо «кормления» робота Google, пользователи, похоже, ценят релевантность описания.
Приложение Oncrawl предоставляет аналогичные данные для многих других KPI. Не стесняйтесь проверять свои гипотезы!
В заключение
Теперь, когда вы знаете и понимаете возможность изучения того, что происходит на вашем сайте каждый день благодаря журналам, я рекомендую вам проанализировать пользователей Интернета и посещения роботов, чтобы найти различные способы оптимизации вашего сайта. Ответы могут быть техническими или связанными с контентом, но помните, что хорошая сегментация — ключ к хорошему анализу.
Однако такой анализ невозможен с помощью инструментов Google Analytics; их данные иногда можно спутать с данными нашего поискового робота. Иметь в своем распоряжении как можно больше данных также является хорошим решением.
Чтобы получить еще больше от ваших данных журналов и анализа сканирования, не стесняйтесь взглянуть на исследование, проведенное командой Oncrawl, в котором собраны 5 ключевых показателей эффективности SEO, связанных с журналами на сайтах электронной коммерции.