
Введение в поисковый робот
Опубликовано: 2016-03-08Когда я говорю с людьми о том, чем я занимаюсь и что такое SEO, они обычно довольно быстро все понимают или действуют так, как делают. Хорошая структура сайта, хороший контент, хорошие обратные ссылки. Но иногда это становится немного более техническим, и я заканчиваю тем, что говорю о поисковых системах, сканирующих ваш сайт, и я обычно их теряю…
Зачем сканировать веб-сайт?
Веб-сканирование началось с картирования Интернета и того, как каждый веб-сайт был связан друг с другом. Он также использовался поисковыми системами для обнаружения и индексации новых онлайн-страниц. Веб-сканеры также использовались для проверки уязвимости веб-сайта путем тестирования веб-сайта и анализа того, была ли обнаружена какая-либо проблема.
Теперь вы можете найти инструменты, которые сканируют ваш сайт, чтобы предоставить вам информацию. Например, OnCrawl предоставляет данные о вашем контенте и поисковой оптимизации на месте, а Majestic — о всех ссылках, указывающих на страницу.
Сканеры используются для сбора информации, которая затем может использоваться и обрабатываться для классификации документов и предоставления информации о собранных данных.
Создание краулера доступно любому, кто хоть немного разбирается в коде. Однако создать эффективный сканер сложнее и требует времени.
Как это работает ?
Чтобы сканировать веб-сайт или сеть, вам сначала нужна точка входа. Роботы должны знать, что ваш веб-сайт существует, чтобы они могли прийти и посмотреть на него. В те дни вы бы отправили свой сайт в поисковые системы, чтобы сообщить им, что ваш сайт находится в сети. Теперь вы можете легко создать несколько ссылок на свой веб-сайт, и вуаля, вы в курсе!
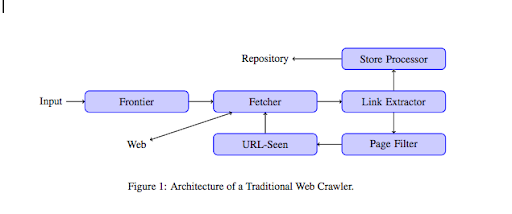
Как только сканер попадает на ваш веб-сайт, он анализирует весь ваш контент построчно и переходит по каждой из ваших ссылок, независимо от того, являются ли они внутренними или внешними. И так до тех пор, пока он не попадет на страницу, на которой больше нет ссылок, или не обнаружит ошибки, такие как 404, 403, 500, 503.
С более технической точки зрения сканер работает с начальным числом (или списком) URL-адресов. Это передается сборщику, который извлекает содержимое страницы. Затем этот контент перемещается в средство извлечения ссылок, которое анализирует HTML и извлекает все ссылки. Эти ссылки отправляются в процессор Store, который, как следует из названия, будет их хранить. Эти URL-адреса также будут проходить через фильтр страниц, который будет отправлять все интересные ссылки в модуль просмотра URL-адресов. Этот модуль определяет, был ли уже просмотрен URL-адрес или нет. Если нет, он отправляется сборщику, который извлекает содержимое страницы и так далее.
Имейте в виду, что некоторые виды содержимого, такие как Flash, не могут быть просканированы пауками. Теперь GoogleBot правильно сканирует Javascript, но время от времени не сканирует его. Изображения не являются контентом, который Google технически может сканировать, но он стал достаточно умным, чтобы начать их понимать!
Если роботам не сказать обратное, они все проползут. Именно здесь файл robots.txt становится очень полезным. Он сообщает сканерам (может быть специфичным для каждого поискового робота, например GoogleBot или MSN Bot — узнайте больше о ботах здесь), какие страницы они не могут сканировать. Предположим, например, что у вас есть навигация с использованием фасетов, вы можете не захотеть, чтобы роботы сканировали их все, так как они имеют небольшую добавленную стоимость и будут использовать краулинговый бюджет. Использование этой простой линии поможет вам предотвратить ее сканирование любым роботом.
Пользовательский агент: *
Запретить: /папка-a/
Это говорит всем роботам не сканировать папку A.
Агент пользователя: GoogleBot
Запретить: /repertoire-b/
Это, с другой стороны, указывает, что только Google Bot не может сканировать папку B.
Вы также можете использовать указание в HTML, которое говорит роботам не переходить по определенной ссылке, используя тег rel=”nofollow”. Некоторые тесты показали, что даже использование тега rel="nofollow" в ссылке не блокирует переход по ней робота Googlebot. Это противоречит его назначению, но будет полезно в других случаях.
[Пример успеха] Повысьте видимость, улучшив возможности сканирования веб-сайта для робота Googlebot
 Читать тематическое исследование
Читать тематическое исследование
Вы упомянули краулинговый бюджет, но что это такое?
Допустим, у вас есть веб-сайт, который был обнаружен поисковыми системами. Они регулярно приходят посмотреть, внесли ли вы какие-либо обновления на свой сайт и создали ли новые страницы.
Каждый веб-сайт имеет свой собственный краулинговый бюджет, зависящий от нескольких факторов, таких как количество страниц на вашем веб-сайте и его работоспособность (например, если на нем много ошибок). Вы можете легко получить представление о своем краулинговом бюджете, войдя в консоль поиска.
Ваш краулинговый бюджет будет фиксировать количество страниц, которые робот просматривает на вашем веб-сайте каждый раз, когда он посещает его. Он пропорционально связан с количеством страниц на вашем веб-сайте и уже просканирован. Некоторые страницы сканируются чаще, чем другие, особенно если они регулярно обновляются или на них есть ссылки с важных страниц.
Например, ваш дом является вашей основной точкой входа, которая будет очень часто сканироваться. Если у вас есть блог или страница категории, они будут часто сканироваться, если они связаны с основной навигацией. Блог также будет часто сканироваться, поскольку он регулярно обновляется. Сообщение в блоге может часто сканироваться при первой публикации, но через несколько месяцев оно, вероятно, не будет обновляться.
Чем чаще страница сканируется, тем важнее робот считает ее важной по сравнению с другими. Именно тогда вам нужно начать работать над оптимизацией краулингового бюджета.
Оптимизация краулингового бюджета
Чтобы оптимизировать свой бюджет и убедиться, что ваши самые важные страницы получают то внимание, которого они заслуживают, вы можете проанализировать журналы своего сервера и посмотреть, как сканируется ваш сайт:
- Как часто сканируются ваши главные страницы
- Видите ли вы, что менее важные страницы сканируются чаще, чем более важные?
- Часто ли роботы получают ошибку 4xx или 5xx при сканировании вашего сайта?
- Встречаются ли роботы с ловушками для пауков? (Мэттью Генри написал о них замечательную статью)
Проанализировав свои журналы, вы увидите, какие страницы, которые вы считаете менее важными, сканируются чаще. Затем вам нужно углубиться в вашу внутреннюю ссылочную структуру. Если он сканируется, он должен иметь много ссылок, указывающих на него.
Вы также можете работать над исправлением всех этих ошибок (4xx и 5xx) с помощью OnCrawl. Это улучшит возможности сканирования, а также удобство для пользователей, это беспроигрышный случай.
Сканирование VS Скрапинг?
Сканирование и парсинг — это две разные вещи, которые используются для разных целей. Сканирование веб-сайта — это переход на страницу и переход по ссылкам, которые вы найдете при сканировании контента. Затем сканер перейдет на другую страницу и так далее.
Скрапинг, с другой стороны, сканирует страницу и собирает определенные данные со страницы: тег заголовка, метаописание, тег h1 или определенную область вашего сайта, например список цен. Парсеры обычно действуют как «люди», они будут игнорировать любые правила из файла robots.txt, файла в формах и использовать пользовательский агент браузера, чтобы не быть обнаруженными.
Сканеры поисковых систем обычно действуют как скребки, поскольку им необходимо собирать данные, чтобы обрабатывать их для своего алгоритма ранжирования. Они не ищут конкретные данные по сравнению с парсером, они просто используют все доступные данные на странице и даже больше (время загрузки — это то, что вы не можете получить со страницы). Сканеры поисковых систем всегда идентифицируют себя как сканеры, поэтому владелец веб-сайта может знать, когда он в последний раз посещал свой веб-сайт. Это может быть очень полезно, когда вы отслеживаете реальную активность пользователей.
Итак, теперь вы знаете немного больше о сканировании, о том, как оно работает и почему это важно, следующим шагом будет анализ журналов сервера. Это даст вам глубокое представление о том, как роботы взаимодействуют с вашим веб-сайтом, какие страницы они часто посещают и сколько ошибок они обнаруживают при посещении вашего веб-сайта.
Для получения дополнительной технической и исторической информации о поисковых роботах вы можете прочитать «Краткая история поисковых роботов».