
Как определить краулинговый бюджет?
Опубликовано: 2016-09-14Мы все говорим об этом как SEO-специалисты, но как на самом деле работает краулинговый бюджет? Мы знаем, что количество страниц, которые поисковые системы сканируют и индексируют при посещении веб-сайтов наших клиентов, коррелирует с их успехом в обычном поиске, но всегда ли лучше иметь больший краулинговый бюджет?
Как и все в Google, я не думаю, что взаимосвязь между краулинговым бюджетом вашего сайта и ранжированием/производительностью в поисковой выдаче на 100 % прямолинейна, она зависит от ряда факторов.
Почему краулинговый бюджет важен? Из-за обновления Caffeine 2010 года. С этим обновлением Google перестроил способ индексации контента с помощью добавочной индексации. Внедрив систему «перколятора», они устранили «узкое место» индексации страниц.
Как Google определяет краулинговый бюджет?
Все дело в вашем PageRank, потоке цитирования и потоке доверия.
Почему я не упомянул об авторитете домена? Честно говоря, на мой взгляд, это одна из самых неправильно используемых и неправильно понятых метрик, доступных SEO-специалистам и контент-маркетологам, которая имеет свое место, но слишком много агентств и SEO-специалистов придают ей слишком большое значение, особенно при построении ссылок.
PageRank сейчас, конечно, устарел, особенно после того, как они убрали панель инструментов, так что все дело в коэффициенте доверия сайта (коэффициент доверия = поток доверия / поток цитирования). По сути, более мощные домены имеют больший бюджет сканирования, так как же определить активность ботов Google на вашем веб-сайте и, что важно, определить любые проблемы со сканированием ботов? Файлы журнала сервера.
Теперь мы все знаем, что для того, чтобы указать роботу Google страницы, которые мы проиндексировали (и ранжировали), мы используем внутреннюю структуру ссылок и держим их близко к корневому домену, а не к 5 подпапкам вдоль URL-адреса. Но как насчет более технических вопросов? Например, растрата краулингового бюджета, ловушки для ботов или попытка Google заполнить формы на сайте (такое случается).
Идентификация активности поискового робота
Для этого вам нужно заполучить некоторые файлы журналов сервера. Вам может потребоваться запросить их у вашего клиента, или вы можете скачать их непосредственно у хостинговой компании.
Идея заключается в том, что вы хотите попытаться найти запись о том, как бот Google попал на ваш сайт, но, поскольку это не запланированное событие, вам может потребоваться получить данные за несколько дней. Существуют различные программы для анализа этих файлов.
Ниже приведен пример обращения к серверу Apache:
50.56.92.47 – – [31/May/2012:12:21:17 +0100] «GET» – «/wp-content/themes/wp-theme/help.php» – «404» «-» «Mozilla/ 5.0 (совместимо; Googlebot/2.1; +http://www.google.com/bot.html)» – www.hit-example.com
Отсюда вы можете использовать инструменты (такие как OnCrawl) для анализа файлов журналов и выявления таких проблем, как Google, сканирующий PPC-страницы или бесконечные запросы GET к сценариям JSON — оба из них могут быть исправлены в файле Robots.txt.
Когда краулинговый бюджет является проблемой?
Бюджет сканирования не всегда является проблемой, если на вашем сайте много URL-адресов и пропорционально распределено «сканирование», все в порядке. Но что, если на вашем веб-сайте 200 000 URL-адресов, а Google ежедневно сканирует только 2000 страниц вашего сайта? Google может занять до 100 дней, чтобы заметить новые или обновленные URL-адреса — теперь это проблема.
Один быстрый тест, чтобы увидеть, является ли ваш краулинговый бюджет проблемой, — это использовать Google Search Console и количество URL-адресов на вашем сайте для расчета вашего «сканирующего числа».
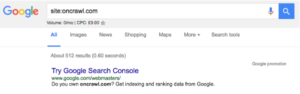
- Сначала вам нужно определить, сколько страниц на вашем сайте, вы можете сделать это, выполнив поиск site:, например, oncrawl.com имеет примерно 512 страниц в индексе:
- Во-вторых, вам нужно зайти в свою учетную запись Google Search Console и перейти в Crawl, а затем в Crawl Stats. Если ваша учетная запись GSC не настроена должным образом, у вас может не быть этих данных.
- Третий шаг — взять среднее число «Просканированных страниц в день» (среднее) и общее количество URL-адресов на вашем сайте и разделить их:
Всего страниц на сайте / Среднее количество просканированных страниц в день = X

Если X больше 10, вам нужно подумать об оптимизации краулингового бюджета. Если меньше 5, браво. Вам не нужно читать дальше.
Оптимизация возможностей вашего «краулингового бюджета»
У вас может быть самый большой краулинговый бюджет в Интернете, но если вы не знаете, как его использовать, он бесполезен.
Да, это клише, но это правда. Если Google просканирует все страницы вашего сайта и обнаружит, что подавляющее большинство из них дублируются, пусты или загружаются так медленно, что вызывают ошибки тайм-аута, ваш бюджет может оказаться нулевым.
Чтобы максимально эффективно использовать краулинговый бюджет (даже без доступа к файлам журнала сервера), вам необходимо убедиться, что вы делаете следующее:
Удалить дубликаты страниц
Часто на сайтах электронной коммерции такие инструменты, как OpenCart, могут создавать несколько URL-адресов для одного и того же продукта. Я видел экземпляры одного и того же продукта на 4 URL-адресах с разными подпапками между местом назначения и корнем.
Вы не хотите, чтобы Google индексировал более одной версии каждой страницы, поэтому убедитесь, что у вас есть канонические теги, указывающие Google на правильную версию.
Устранение неработающих ссылок
Используйте консоль поиска Google или программное обеспечение для сканирования, найдите все неработающие внутренние и внешние ссылки на своем сайте и исправьте их. Использование 301 — это здорово, но если это навигационные ссылки или ссылки в нижнем колонтитуле, которые не работают, просто измените URL-адрес, на который они указывают, не полагаясь на 301.
Не пишите тонкие страницы
Избегайте большого количества страниц на вашем сайте, которые практически не представляют никакой ценности для пользователей или поисковых систем. Без контекста Google с трудом классифицирует страницы, а это означает, что они не вносят никакого вклада в общую релевантность сайта и являются просто пассажирами, расходующими краулинговый бюджет.
Удалить цепочки переадресации 301
Цепные перенаправления не нужны, беспорядочны и неправильно поняты. Цепочки переадресации могут нанести ущерб вашему краулинговому бюджету несколькими способами. Когда Google достигает URL-адреса и видит ошибку 301, он не всегда сразу следует за ним, вместо этого он добавляет новый URL-адрес в список, а затем следует за ним.
Вам также необходимо убедиться, что ваша карта сайта в формате XML (и карта сайта в формате HTML) является точной, а если ваш веб-сайт многоязычный, убедитесь, что у вас есть карты сайта для каждого языка веб-сайта. Вам также необходимо внедрить интеллектуальную архитектуру сайта, архитектуру URL-адресов и ускорить работу ваших страниц. Размещение вашего сайта за CDN, например CloudFlare, также было бы полезно.
TL;DR:
Бюджет сканирования, как и любой другой бюджет, — это возможность. Теоретически вы используете свой бюджет, чтобы купить время, которое роботы Googlebot, Bingbot и Slurp проводят на вашем сайте. Важно максимально использовать это время.
Оптимизировать краулинговый бюджет непросто, и уж точно это не «быстрая победа». Если у вас есть небольшой сайт или сайт среднего размера, который хорошо поддерживается, у вас, вероятно, все в порядке. Если у вас есть гигантский сайт с десятками тысяч URL-адресов, а файлы журналов сервера выходят за рамки вашей головы — возможно, пришло время обратиться к экспертам.