
Как прогнозировать доход от небрендированного органического трафика на основе позиции URL с помощью Python
Опубликовано: 2022-05-24Что такое SEO-прогнозирование?
SEO-прогнозирование или оценка органического трафика — это процесс использования данных вашего собственного сайта или сторонних данных для оценки будущего органического трафика вашего сайта, доходов от SEO и рентабельности инвестиций в SEO. Эта оценка может быть рассчитана с использованием многих различных методов на основе наших данных.
В этом руководстве мы хотим предсказать наш небрендированный органический доход и небрендированный органический трафик на основе позиций наших URL-адресов и их текущего дохода. Это может помочь нам как SEO-специалистам получить больше поддержки от других заинтересованных сторон: от увеличения ежемесячного, квартального или годового бюджета до увеличения количества человеко-часов от команды продукта и разработчиков.
Имейте в виду, что это руководство применимо не только к небрендированному органическому трафику; сделав несколько изменений и зная Python, вы можете использовать его для оценки трафика целевых страниц.
В результате мы можем создать Google Sheet, как на изображении ниже.
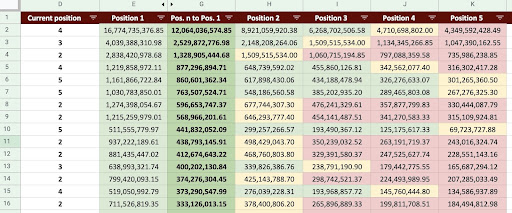
Изображение Google Таблиц
Прогнозирование небрендового SEO-трафика
Первый вопрос, который вы можете задать после прочтения введения: «Зачем рассчитывать небрендированный органический трафик?».
Давайте рассмотрим такую компанию, как Amazon. Когда вы хотите купить книгу или маску, вы просто ищете «купить маску на Amazon».
Бренды часто занимают первое место, и когда вы хотите что-то купить, вы предпочитаете покупать то, что вам нужно, у этих компаний. В каждой отрасли есть известные компании, которые влияют на поведение пользователей при поиске в Google.
Если бы мы проверили данные Google Search Console (GSC) Amazon, мы, вероятно, обнаружили бы, что она получает много трафика от брендовых запросов, и в большинстве случаев первым результатом брендовых запросов является сайт этого бренда.
Как SEO-специалист, как и я, вы, вероятно, много раз слышали: «Только наш бренд помогает нашему SEO!» Как мы можем сказать «Нет, это не так» и показать трафик и доход от небрендовых запросов?
Доказать это еще сложнее, потому что мы знаем, что алгоритмы Google настолько сложны, что трудно четко отделить брендовые поиски от небрендовых. Но это то, что делает то, что мы делаем как SEO, еще более важным.
В этом уроке я покажу вам, как отличить их от брендовых и небрендовых, и покажу вам, насколько мощным может быть SEO.
Даже если ваша компания не брендовая, вы все равно можете многое почерпнуть из этой статьи: вы узнаете, как оценить органические данные вашего сайта.
SEO ROI на основе оценки трафика
Независимо от того, где вы находитесь и чем занимаетесь, ресурсы ограничены; будь то бюджет или просто количество часов в рабочем дне. Знание того, как лучше распределить свои ресурсы, играет важную роль в общей рентабельности инвестиций в SEO (ROI).
Директор по маркетингу, вице-президент по маркетингу или специалист по маркетингу имеют разные ключевые показатели эффективности и требуют разных ресурсов для достижения своих целей. Лучший способ убедиться, что вы получите то, что вам нужно, — это доказать его необходимость, продемонстрировав прибыль, которую это принесет компании. SEO ROI ничем не отличается. Когда подходит время распределения бюджета и ваша команда хочет запросить больший бюджет, оценка рентабельности инвестиций в SEO может дать вам преимущество в переговорах. После того, как вы подсчитали оценку небрендированного трафика, вы можете лучше оценить необходимый бюджет для достижения желаемых результатов.
Влияние SEO-прогнозирования на SEO-стратегию
Как мы знаем, каждые 3 или 6 месяцев мы пересматриваем нашу стратегию SEO и корректируем ее, чтобы получить наилучшие результаты. Но что происходит, когда вы не знаете, где ваша компания получает наибольшую прибыль? Вы можете принимать решения, но они не будут столь же эффективными, как решения, принимаемые, когда у вас есть более полное представление о трафике сайта.
Оценка доходов от небрендированного органического трафика может быть объединена с сегментацией ваших целевых страниц и запросов, чтобы получить общую картину, которая поможет вам разработать лучшие стратегии в качестве SEO-менеджера или SEO-стратега.
Различные способы прогнозирования органического трафика
В SEO-сообществе существует множество различных методов и общедоступных скриптов для прогнозирования будущего органического трафика.
Некоторые из этих методов включают в себя:
- Прогнозирование органического трафика на весь сайт
- Прогнозирование органического трафика на определенных страницах (блог, товары, категории и т. д.) или на отдельной странице
- Прогнозирование органического трафика по конкретным запросам (запросы содержат «купить», «как сделать» и т. д.) или запросу
- Прогнозирование органического трафика на определенные периоды (особенно для сезонных событий)
Мой метод предназначен для конкретных страниц, а временные рамки - один месяц.
[Пример успеха] Стимулирование роста на новых рынках с помощью SEO на странице
 Читать тематическое исследование
Читать тематическое исследованиеКак рассчитать доход от органического трафика
Точный способ основан на ваших данных Google Analytics (GA). Если ваш сайт новый, вам придется использовать сторонние инструменты. Я предпочитаю избегать использования таких инструментов, когда у вас есть собственные данные.
Помните, что вам нужно будет протестировать сторонние данные, которые вы используете, в сравнении с вашими реальными данными страницы, чтобы найти возможные ошибки в их данных.
Как рассчитать доход от небрендированного SEO-трафика с помощью Python
До сих пор мы рассмотрели множество теоретических концепций, с которыми нам следует ознакомиться, чтобы лучше понять различные аспекты прогнозирования органического трафика и доходов. Теперь перейдем к практической части этой статьи.
Во-первых, мы начнем с расчета нашей кривой CTR. В моей статье о кривых CTR на Oncrawl я объясняю два разных метода, а также другие методы, которые вы можете использовать, внеся несколько изменений в мой код. Я рекомендую вам сначала прочитать статью о кривой кликов; это дает вам представление об этой статье.
В этой статье я изменяю некоторые части своего кода, чтобы получить конкретные результаты, которые нам нужны при оценке трафика. Затем мы получим данные из GA и воспользуемся измерением дохода GA для оценки нашего дохода.
Прогнозирование дохода от небрендового органического трафика с помощью Python: начало работы
Вы можете запустить этот код самостоятельно, даже не зная Python. Однако я предпочитаю, чтобы вы немного знали синтаксис Python и базовые знания о библиотеках Python, которые я буду использовать в этом коде прогнозирования. Это поможет вам лучше понять мой код и настроить его под себя.
Для запуска этого кода я буду использовать Visual Studio Code с расширением Python от Microsoft, которое включает в себя расширение «Jupyter». Но вы можете использовать сам блокнот Jupyter.
Для всего процесса нам нужно использовать эти библиотеки Python:
- Нампи
- Панды
- сюжетно
Также мы импортируем некоторые стандартные библиотеки Python:
- JSON
- ппринт
# Импорт необходимых для нашего процесса библиотек импортировать json из pprint импортировать pprint импортировать numpy как np импортировать панд как pd импортировать plotly.express как px
Шаг 1. Расчет относительной кривой CTR (кривая относительного клика)
На первом этапе мы хотим рассчитать относительную кривую CTR. Но какова относительная кривая CTR?
Что такое относительная кривая CTR?
Начнем с «абсолютной кривой CTR». Когда мы рассчитываем абсолютную кривую CTR, мы говорим, что медианный CTR (или средний CTR) первой позиции составляет 36%, второй позиции — 20% и так далее.
На кривой относительного CTR в процентах мы делим медиану каждой позиции на CTR первой позиции. Например, относительная кривая CTR для первой позиции будет 0,36/0,36 = 1, для второй – 0,20/0,36 = 0,55 и так далее.
Может быть, вам интересно, почему это полезно вычислить? Подумайте о странице, занимающей первую позицию, с CTR 44%. Если эта страница переместится на вторую позицию, кривая CTR не снизится до 20%, скорее всего, CTR снизится до 44% * 0,55 = 24,2%.
1. Получение данных о брендированном и небрендированном органическом трафике от GSC.
Для нашего процесса расчета нам нужно получить данные от GSC. В первый раз все данные будут основаны на брендовых запросах, а в следующий раз все данные будут основаны на небрендовых запросах.
Чтобы получить эти данные, вы можете использовать разные методы: из скриптов Python или из надстройки Google Sheets «Поисковая аналитика для таблиц». Я буду использовать GSC API Explorer.
Результатом этих данных являются два файла JSON, которые показывают производительность каждой страницы. Один файл JSON показывает эффективность целевых страниц на основе брендовых запросов, а другой показывает производительность целевых страниц на основе нефирменных запросов.
Чтобы получить данные из GSC API Explorer, выполните следующие действия:
- Перейдите на страницу https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Разверните обозреватель API, который находится в правом верхнем углу страницы.
- В поле «
siteUrl» введите ваше доменное имя. Например, «https://www.example.com» или «http://your-domain.com». - В теле запроса сначала нам нужно определить параметры «
startDate» и «endDate». Я предпочитаю последние 30 дней. - Затем мы добавляем «
dimensions» и выбираем «page» для этого списка. - Теперь мы добавляем «
dimensionFilterGroups» для фильтрации наших запросов. Один раз для брендированных и второй для небрендовых запросов. - В конце мы устанавливаем для нашего «
rowLimit» значение 25 000. Если страницы вашего сайта, которые ежемесячно получают органический трафик, превышают 25 тыс., вы должны изменить тело запроса. - После каждого запроса сохраняйте ответ в формате JSON. Для фирменной производительности сохраните файл JSON как «
branded_data.json», а для производительности без торговой марки сохраните файл JSON как «non_branded_data.json».
После того, как мы поймем параметры в нашем теле запроса, единственное, что вам нужно сделать, это скопировать и вставить ниже тела запроса. Рассмотрите возможность замены названий ваших торговых марок на « brand variation names ».
Вы должны разделять названия брендов конвейером или символом « | ». Например, « amazon|amazon.com|amazn ».
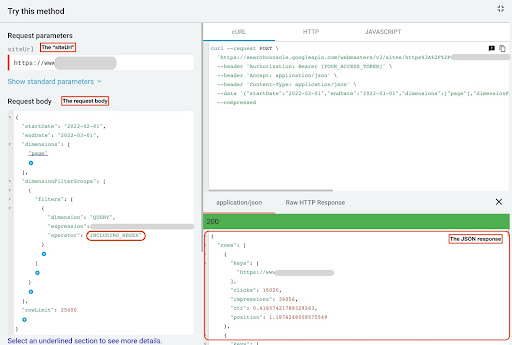
Обозреватель API GSC
Фирменное тело запроса:
{
"дата начала": "01.02.2022",
"endDate": "2022-03-01",
"Габаритные размеры": [
"страница"
],
"группы фильтров измерений": [
{
"фильтры": [
{
"размер": "ЗАПРОС",
"expression": "названия вариаций бренда",
"оператор": "INCLUDING_REGEX"
}
]
}
],
"лимит строк": 25000
}
Тело запроса без бренда:
{
"дата начала": "01.02.2022",
"endDate": "2022-03-01",
"Габаритные размеры": [
"страница"
],
"группы фильтров измерений": [
{
"фильтры": [
{
"размер": "ЗАПРОС",
"expression": "названия вариаций бренда",
"оператор": "EXCLUDING_REGEX"
}
]
}
],
"лимит строк": 25000
}
2. Импорт данных в нашу записную книжку Jupyter и извлечение каталогов сайтов.
Теперь нам нужно загрузить наши данные в нашу записную книжку Jupyter, чтобы иметь возможность изменять их и извлекать из них то, что мы хотим. Давайте продолжим с того места, на котором остановились выше.
Чтобы загрузить фирменные данные, вам нужно выполнить этот блок кода:
# Создание DataFrame для производительности URL-адресов веб-сайта по бренду и брендовых запросов
с open("./branded_data.json") как json_file:
branded_data = json.loads(json_file.read())["строки"]
branded_df = pd.DataFrame(branded_data)
# Переименование столбца «ключи» в столбец «целевая страница» и преобразование списка «целевая страница» в URL
branded_df.rename(columns={"keys": "целевая страница"}, inplace=True)
branded_df["целевая страница"] = branded_df["целевая страница"].apply(лямбда x: x[0])
Для производительности целевых страниц без бренда вам необходимо выполнить этот блок кода:
# Создание DataFrame для производительности URL-адресов веб-сайта по небрендовым запросам
с open("./non_branded_data.json") как json_file:
non_branded_data = json.loads(json_file.read())["строки"]
non_branded_df = pd.DataFrame(non_branded_data)
# Переименование столбца «ключи» в столбец «целевая страница» и преобразование списка «целевая страница» в URL
non_branded_df.rename(columns={"keys": "целевая страница"}, inplace=True)
non_branded_df["целевая страница"] = non_branded_df["целевая страница"].apply(лямбда x: x[0])
Мы загружаем наши данные, затем нам нужно определить имя нашего сайта, чтобы извлечь его каталоги.
# Определение имени вашего сайта в кавычках. Например, «https://www.example.com/» или «http://mydomain.com/». SITE_NAME = "https://www.your_domain.com/"
Нам нужно только извлечь каталоги из нефирменного исполнения.
# Получение каталога каждой целевой страницы (URL)
non_branded_df["каталог"] = non_branded_df["целевая страница"].str.extract(
pat=f"((?<={ИМЯ_САЙТА})[^/]+)"
)
Затем мы распечатываем каталоги, чтобы выбрать, какие из них важны для этого процесса. Вы можете выбрать все каталоги, чтобы лучше понять свой сайт.

# Чтобы получить все каталоги на выходе, нам нужно манипулировать параметрами Pandas
pd.set_option("display.max_rows", нет)
# Каталоги веб-сайтов
non_branded_df["каталог"].value_counts()
Здесь вы можете вставить любые каталоги, которые важны для вас.
""" Выберите, какие каталоги важны для получения кривой CTR.
Вставьте каталоги в переменную «important_directories».
Например, «продукт,тег,категория продукта,маг». Разделяйте значения каталога запятой.
"""
IMPORTANT_DIRECTORIES = "ваши_важные_каталоги"
ВАЖНЫЕ_КАТАЛОГИ = ВАЖНЫЕ_КАТАЛОГИ.split(",")
3. Маркировка страниц на основе их позиции и расчет относительной кривой CTR.
Теперь нам нужно пометить наши целевые страницы в зависимости от их положения. Мы делаем это, потому что нам нужно рассчитать относительную кривую CTR для каждого каталога на основе позиции его целевой страницы.
# Маркировка небрендированных позиций
для я в диапазоне (1, 11):
non_branded_df.loc[
(non_branded_df["position"] >= i) & (non_branded_df["position"] < i + 1),
"метка положения",
] = я
Затем мы группируем целевые страницы на основе их каталога.
# Группировка целевых страниц на основе их значения «каталога» non_brand_grouped_df = non_branded_df.groupby(["каталог"])
Определим функцию для расчета относительной кривой CTR.
def each_dir_relative_ctr_curve (dir_df, ключ):
"""Эта функция вычисляет относительную кривую CTR каждой IMPORTANT_DIRECTORIES.
"""
# Группировка «non_brand_grouped_df» на основе их значения «метки позиции»
dir_grouped_df = dir_df.groupby(["метка позиции"])
# Список для сохранения медианы CTR каждой позиции
median_ctr_list = []
# Сохраняем каждый каталог как ключ, а его "median_ctr_list" как значение
directorys_median_ctr = {}
# Перебираем каждую группу "dir_grouped_df"
для я в диапазоне (1, 11):
# Попытка за исключением случаев, когда в каталоге, например, нет данных для позиции 4
пытаться:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
кроме:
median_ctr_list.append(0)
# Расчет относительной кривой CTR
directorys_median_ctr [ключ] = np.array (median_ctr_list) / np.array (
[медианный_ctr_list[0]] * 10
)
вернуть directorys_median_ctr
После определения функции мы запускаем ее.
# Перебираем каталоги и выполняем функцию 'each_dir_relative_ctr_curve'
directorys_median_ctr_dict = dict()
для ключа, элемент в non_brand_grouped_df:
если ключ в IMPORTANT_DIRECTORIES:
directorys_median_ctr_dict.update (each_dir_relative_ctr_curve (элемент, ключ))
pprint (directories_median_ctr_dict)
Теперь мы загрузим наши целевые страницы, брендированные и небрендированные, производительность и рассчитаем относительную кривую CTR для наших небрендовых данных. Почему мы делаем это только для данных, не относящихся к бренду? Потому что мы хотим предсказать небрендовый органический трафик и доход.
Шаг 2. Прогнозирование дохода от небрендированного органического трафика
На этом втором шаге мы узнаем, как получить данные о доходах и спрогнозировать их.
1. Объединение брендированных и небрендированных органических данных
Теперь мы объединим наши фирменные и нефирменные данные. Это поможет нам рассчитать процент небрендированного органического трафика на каждой целевой странице по сравнению со всем трафиком.
# «main_df» представляет собой комбинацию «данных всего сайта» и «данных, не связанных с брендом» DataFrames.
# Используя этот DataFrame, вы можете узнать, где больше всего кликов и показов
# исходят из запросов, которые не брендированы.
main_df = non_branded_df.merge(
branded_df, on="целевая страница", suffixes=("_non_brand", "_branded")
)
Затем мы модифицируем столбцы, чтобы удалить бесполезные.
# Изменение столбцов 'main_df' на нужные нам
main_df = main_df[
[
"целевая страница",
"клики_не_бренд",
"ctr_non_brand",
"каталог",
"метка положения",
"клики_брендированные",
]
]
Теперь давайте посчитаем процент небрендовых кликов от общего числа кликов целевой страницы.
# Расчет процента кликов по небрендированным запросам на основе целевых страниц по отношению ко всем кликам целевой страницы
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
лямбда x: x["клики_не_бренд"] / (x["клики_не_бренд"] + x["клики_бренд"]),
ось=1,
)
[Электронная книга] Автоматизация SEO с помощью Oncrawl
 Читать электронную книгу
Читать электронную книгу2. Загрузка доходов от органического трафика
Как и при получении данных GSC, у нас есть несколько способов получить данные GA: мы можем использовать «надстройку Google Analytics Sheets» или API GA. В этом руководстве я предпочитаю использовать Google Data Studio (GDS) из-за его простоты.
Чтобы получить данные GA из GDS, выполните следующие действия:
- В GDS создайте новый отчет или обозреватель и таблицу.
- Для измерения добавьте «целевую страницу», а для метрики мы должны добавить «Доход».
- Затем вам нужно будет создать собственный сегмент в GA на основе источника и канала. Отфильтруйте «гугл/органический» трафик. После создания сегмента добавьте его в раздел сегментов в GDS.
- На последнем шаге экспортируйте таблицу и сохраните ее как «
landing_pages_revenue.csv».
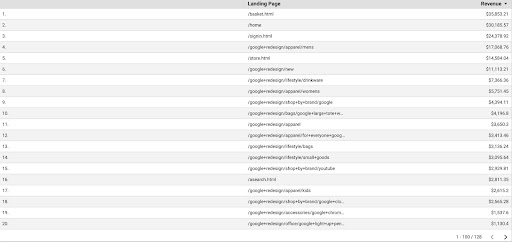
Экспорт доходов от целевых страниц в csv
Давайте загрузим наши данные.
Organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Теперь нам нужно добавить название нашего сайта к URL-адресам целевых страниц GA.
Когда мы экспортируем наши данные из GA, целевые страницы имеют относительную форму, но наши данные GSC имеют абсолютную форму.
Не забудьте проверить данные целевых страниц GA. В наборах данных, с которыми я работал, я обнаружил, что данные GA каждый раз нуждаются в небольшой очистке.
# Объединение URL-адресов целевых страниц GA с SITE_NAME.
# Кроме того, переименование столбцов
Organic_revenue_df.loc[:, "Целевая страница"] = (
SITE_NAME[:-1] + Organic_revenue_df[organic_revenue_df.columns[0]]
)
Organic_revenue_df.rename(columns={"Целевая страница": "Целевая страница", "Доход": "Доход"}, inplace=True)
Теперь давайте объединим наши данные GSC с данными GA.
# На этом шаге я объединяю «main_df» с «dk_organic_revenue_df» DataFrame, который содержит процент данных запросов, не относящихся к бренду. main_df = main_df.merge(organic_revenue_df, on="целевая страница", как="слева")
В конце этого раздела мы немного очистим наши столбцы DataFrame.
# Небольшая очистка DataFrame main_df
main_df = main_df[
[
"целевая страница",
"клики_не_бренд",
"ctr_non_brand",
"каталог",
"метка положения",
"clicks_non_brand_percentage",
"доход",
]
]
3. Расчет небрендового дохода
В этом разделе мы обработаем данные для извлечения нужной информации.
Но прежде всего давайте отфильтруем наши целевые страницы по « IMPORTANT_DIRECTORIES »:
# Удаление целевых страниц других каталогов, не включенных в "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["каталог"].isin(ВАЖНЫЕ_КАТАЛОГИ)]
.dropna(подмножество=["доход"])
.reset_index(drop=Истина)
)
Теперь давайте посчитаем небрендовый органический доходный трафик.
Я определил метрику, которую мы не можем легко рассчитать, и это больше интуиция, чем что-либо еще, заставляет нас присвоить ей число.
Метрика « brand_influence » показывает силу вашего бренда. Если вы считаете, что поисковые запросы, не относящиеся к бренду, приводят к снижению продаж вашего бизнеса, уменьшите это число; что-то вроде 0,8 например.
# Если ваш бренд настолько силен, что запросы без вашего бренда могут продавать столько же, сколько запросы с вашим брендом, то 1 подходит для вас.
# Подумайте о поиске книги без торговой марки, включенной в ваш запрос. Когда вы видите Amazon, вы покупаете на других торговых площадках или в других магазинах?
бренд_влияние = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
лямбда х: х["доход"] * х["клики_не_бренд_процент"] * бренд_влияние, ось = 1
)
Давайте построим круговую диаграмму, чтобы получить представление о небрендовом доходе на основе важных каталогов.
# В этой ячейке я хочу получить весь доход от небрендовых целевых страниц на основе их каталога.
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
индекс = "каталог",
значения = ["не_бренд_доход"],
aggfunc={"non_brand_revenue": "сумма"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
значения = "не_бренд_доход",
имена = non_branded_directory_dist_revenue_df.index,
title="Небрендовый доход на основе каталогов веб-сайтов",
)
pie_fig.update_traces(textposition="внутри", textinfo="процент+метка")
pie_fig.show()
На этом графике показано распределение небрендированных запросов в IMPORTANT_DIRECTORIES .
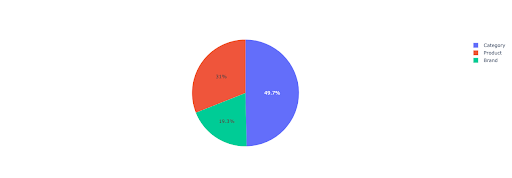
Распределение небрендовых запросов
Основываясь на данных моей кривой CTR, я вижу, что не могу полагаться на CTR для позиций выше 5. Из-за этого я фильтрую свои данные на основе позиции.
Вы можете изменить приведенный ниже блок кода на основе ваших данных.
# Из-за точности CTR в нашей кривой CTR я думаю, что мы можем пропустить лендинги с позицией больше 5. Из-за этого я отфильтровал другие лендинги main_df = main_df[main_df["метка положения"] < 6].reset_index(drop=True)
4. Расчет «Дохода за клик» (RPC)
Здесь я создал пользовательскую метрику и назвал ее «Доход за клик» или RPC. Это показывает нам доход от каждого небрендированного клика.
Вы можете использовать эту метрику по-разному. Я нашел страницу с высоким RPC, но низким количеством кликов. Когда я проверил страницу, я обнаружил, что она была проиндексирована менее недели назад, и мы можем использовать различные методы для оптимизации страницы.
# Расчет дохода от каждого клика (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
лямбда x: x["не_бренд_доход"] / x["клики_не_бренд"], ось=1
)
5. Прогнозирование доходов!
Мы подходим к концу, мы ждали до сих пор, чтобы спрогнозировать наш небрендовый органический доход.
Давайте запустим последние блоки кода.
# Основная функция для расчета дохода на основе разных позиций
для индекса row_values в main_df.iterrows():
# Переключение между каталогами CTR list
ctr_curve = directorys_median_ctr_dict[row_values["каталог"]]
# Перебрать позиции с 1 по 5 и рассчитать доход на основе увеличения или уменьшения CTR.
для i в диапазоне (1, 6):
если я == row_values["метка позиции"]:
main_df.loc[index, i] = row_values["не_бренд_доход"]
еще:
# main_df.loc[индекс, i + 1] ==
main_df.loc[индекс, я] = (
row_values["не_бренд_доход"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["метка позиции"] - 1)]
)
# Вычисление метрики "N к 1". Это показывает увеличение дохода, когда ваш рейтинг повышается с «N» до «1».
main_df.loc[индекс, "от N до 1"] = main_df.loc[индекс, 1] - main_df.loc[индекс, row_values["метка положения"]]
Глядя на окончательный результат, у нас есть новые столбцы. Имена этих столбцов «1», «2», «3», «4», «5».
Что означают эти имена? Например, у нас есть страница на позиции 3, и мы хотим предсказать ее доход, если она улучшит свою позицию, или мы хотим знать, сколько мы потеряем, если упадем в рейтинге.
Столбцы «1» и «2» показывают доход страницы, когда средняя позиция этой страницы улучшается, а столбцы «4» и «5» показывают доход этой страницы, когда мы падаем в рейтинге.
Столбец «3» в этом примере показывает текущий доход страницы.
Кроме того, я создал метрику под названием «N к 1». Это показывает, изменится ли средняя позиция этой страницы с «3» (или N) на «1», и насколько это изменение может повлиять на доход.
Подведение итогов
Я многое рассказал в этой статье, и теперь ваша очередь запачкать руки и спрогнозировать свой доход от небрендового органического трафика.
Это самый простой способ, которым мы можем использовать это предсказание. Мы могли бы усложнить этот алгоритм и совместить его с некоторыми моделями машинного обучения, но это усложнило бы статью.
Я предпочитаю сохранять эти данные в формате CSV и загружать их в таблицу Google. Или, если я планирую поделиться им с другими членами моей команды или организации, я открою его в Excel и отформатирую столбцы, используя цвета, чтобы их было легче читать.
На основе этих данных вы можете спрогнозировать рентабельность инвестиций в небрендированный органический трафик и использовать ее в процессе переговоров.