
Обновления Google Core: эффекты, проблемы и решения для сайтов YMYL
Опубликовано: 2019-12-04В этом тематическом исследовании я рассмотрю Hangikredi.com, который является одним из крупнейших финансовых и цифровых активов Турции. Мы увидим технические подзаголовки SEO и немного графики.
Это тематическое исследование представлено в двух статьях. В этой статье рассказывается об обновлении Google Core от 12 марта, которое оказало сильное негативное влияние на веб-сайт, и о том, что мы предприняли, чтобы противодействовать этому. Мы рассмотрим 13 технических проблем и решений, а также целостные вопросы.
Прочтите вторую часть, чтобы узнать, как я применил знания из этого обновления, чтобы стать победителем в каждом обновлении Google Core.
Проблемы и решения: исправление последствий обновления Google Core от 12 марта
Согласно данным аналитики, до обновления основного алгоритма от 12 марта для веб-сайта все было гладко. За один день, после выхода новости об обновлении основного алгоритма, в офисе произошло огромное падение рейтинга и большое разочарование. Я лично не видел этого дня, потому что я прибыл только тогда, когда они наняли меня, чтобы начать новый SEO-проект и процесс через 14 дней.
[Пример успеха] Улучшение рейтинга, органических посещений и продаж с помощью анализа лог-файлов
 Читать тематическое исследование
Читать тематическое исследованиеОтчет об ущербе для веб-сайта фирмы после обновления основного алгоритма от 12 марта приведен ниже:
- 36 % органических потерь сеансов
- 65 % – клики – сброс
- 30% потеря CTR
- 33% органической потери пользователей
- 100 000 потерянных показов в день.
- 9,72% потери впечатлений
- 8 000 ключевых слов потеряны

Теперь, как мы заявили в начале статьи о конкретном примере, мы должны задать один вопрос. Мы не могли спросить: «Когда произойдет следующее обновление основного алгоритма?» потому что это уже произошло. Остался только один вопрос.
«Какие разные критерии учитывал Google между мной и моим конкурентом?»
Как видно из диаграммы выше и из отчета о повреждениях, мы потеряли наш основной трафик и ключевые слова.
1. Проблема: внутренние ссылки
Я заметил, что когда я впервые проверил количество внутренних ссылок, анкорный текст и поток ссылок, мой конкурент меня опередил.
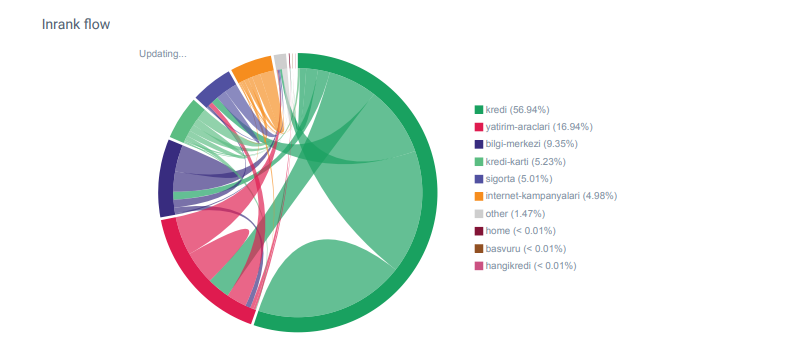
Отчет о потоке ссылок для категорий Hangikredi.com из OnCrawl
У моего основного конкурента более 340 000 внутренних ссылок с тысячами анкорных текстов. В наши дни на нашем веб-сайте было всего 70 000 внутренних ссылок без ценных анкорных текстов. Кроме того, отсутствие внутренних ссылок повлияло на бюджет сканирования и производительность веб-сайта. Несмотря на то, что 80% нашего трафика было собрано только на 20 страницах продуктов, 90% нашего сайта состояло из страниц руководств с полезной информацией для пользователей. И большинство наших ключевых слов и показателей релевантности для финансовых запросов взяты с этих страниц. Кроме того, было слишком много потерянных страниц.
Из-за отсутствия внутренней структуры ссылок, когда я проводил анализ журнала с помощью Kibana, я заметил, что страницы, которые чаще всего просматриваются, получают наименьший трафик. Кроме того, когда я соединил это с сетью внутренних ссылок, я обнаружил, что корпоративные страницы с самым низким трафиком (Конфиденциальность, Cookies, Безопасность, О нас) имеют максимальное количество внутренних ссылок.
Как я расскажу в следующем разделе, это заставило робота Googlebot удалить фактор внутренних ссылок из PageRank при сканировании сайта, понимая, что внутренние ссылки не были построены должным образом.
2. Проблема: архитектура сайта, внутренний рейтинг страницы, трафик и эффективность сканирования.
Согласно заявлению Google, внутренние ссылки и якорные тексты помогают Googlebot понять важность и контекст веб-страницы. Внутренний PageRank или Inrank рассчитывается на основе более чем одного фактора. По словам Билла Славски, внутренние и внешние ссылки не всегда равны. Значение ссылки для потока PageRank меняется в зависимости от ее положения, вида, стиля и веса шрифта.

Если робот Googlebot понимает, какие страницы важны для вашего сайта, он будет сканировать их чаще и быстрее индексировать. Важными факторами для этого являются внутренние ссылки и правильный дизайн Site-Tree. Другие эксперты также прокомментировали эту корреляцию на протяжении многих лет:
«Большинство ссылок предоставляют дополнительный контекст через анкорный текст. По крайней мере, они должны, верно?
– Джон Мюллер, Google, 2017 г.«Если у вас есть страницы, которые вы считаете важными на своем сайте , не прячьте их на 15 ссылок глубоко внутри вашего сайта, и я не говорю о длине каталога, я говорю о том, что вам нужно щелкнуть по 15 ссылкам, чтобы найти эту страницу. если есть страница, которая важна или имеет большую прибыль или действительно конвертирует — ну — эскалируйте, поместите ссылку на эту страницу с вашей корневой страницы , это то, что может иметь большой смысл ».
– Мэтт Каттс, Google, 2011 г.«Если одна страница ссылается на другую со словом «контакт» или словом «о нас», а страница, на которую делается ссылка, включает адрес, то местоположение этого адреса может считаться релевантным для страницы, делающей эту ссылку».
12 методов анализа ссылок Google, которые могли измениться — Билл Славски
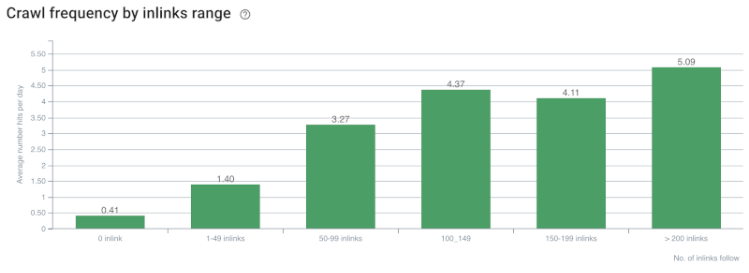
Корреляция скорости сканирования/спроса и количества внутренних ссылок. Источник: OnCrawl.
Пока мы можем сделать следующие выводы:
- Google заботится о глубине кликов. Если веб-страница ближе к домашней странице, она должна быть более важной. Это также было подтверждено Джоном Мюллером 1 июля 2018 года на английском языке Google Webmaster Hangout.
- Если на веб-странице много внутренних ссылок, указывающих на нее, это должно быть важно.
- Якорные тексты могут придать контекстуальную силу веб-странице.
- Внутренняя ссылка может передавать различные значения PageRank в зависимости от ее положения, типа, веса шрифта или стиля.
- Дружественное к UX дерево сайта, которое дает четкие сообщения о внутреннем авторитете страницы для сканеров поисковых систем, является лучшим выбором для распределения Inrank и эффективности сканирования.
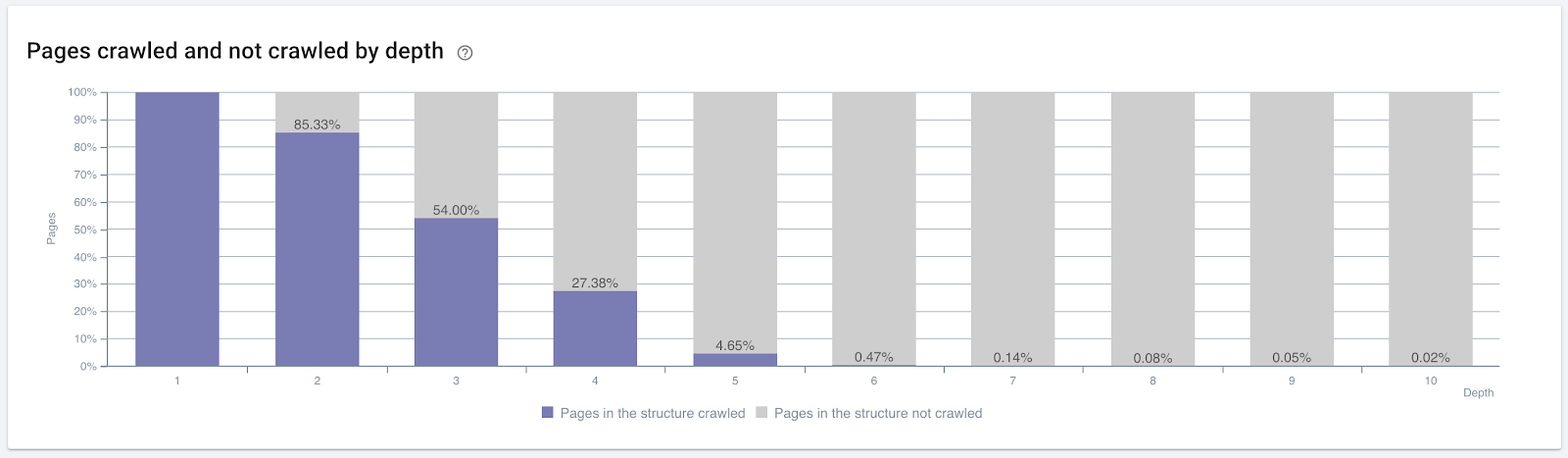
Процент страниц, просканированных по глубине кликов. Источник: OnCrawl.
Но этого недостаточно, чтобы понять природу внутренних ссылок и их влияние на эффективность сканирования.
SEO-краулер OnCrawl
 Учить больше
Учить большеЕсли ваши страницы с наибольшим количеством внутренних ссылок не создают трафика или не получают кликов, это дает сигналы, указывающие на то, что ваше дерево сайта и внутренняя структура ссылок не построены в соответствии с намерениями пользователя. И Google всегда пытается найти ваши наиболее релевантные страницы с пользовательскими намерениями или объектами поиска. У нас есть еще одна цитата Билла Славски, которая проясняет эту тему:
«Если на ресурс ссылается количество ресурсов, непропорциональное по отношению к трафику, полученному с использованием этих ссылок, этот ресурс может быть понижен в рейтинге в процессе ранжирования».
В Google только что произошло обновление сурка? — Билл Славски«Показатель качества выбора может быть выше для выбора, который приводит к длительному времени ожидания (например, больше порогового периода времени), чем показатель качества выбора для выбора, который приводит к короткому времени ожидания».
В Google только что произошло обновление сурка? — Билл Славски
Итак, у нас есть еще два фактора:
- Время пребывания на связанной странице.
- Пользовательский трафик, произведенный по ссылке.
Количество внутренних ссылок и стиль/позиция — не единственные факторы. Также важно количество пользователей, перешедших по этим ссылкам, и показатели их поведения. Кроме того, мы знаем, что ссылки и страницы, которые были нажаты/посещены, сканируются Google гораздо чаще, чем ссылки и страницы, на которые не нажимали или не посещали.
«Мы все больше и больше продвигаемся к пониманию разделов сайта, чтобы понять качество этих разделов».
Джон Мюллер, 2 мая 2017 г., Google Webmasters Hangout на английском языке.
В свете всех этих факторов я поделюсь двумя разными результатами PageRank Simulator:
Эти расчеты рейтинга страницы сделаны с предположением, что все страницы одинаковы, включая домашнюю страницу. Реальная разница определяется иерархией ссылок.
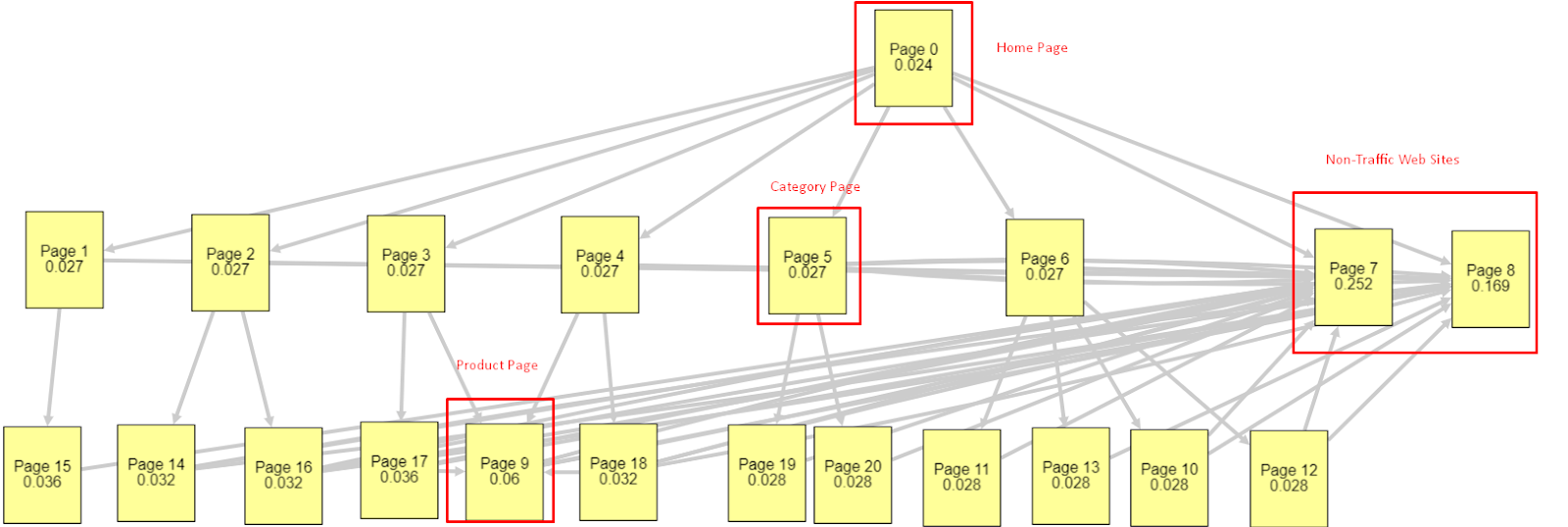
Показанный здесь пример ближе к структуре внутренних ссылок до 12 марта. PR домашней страницы: 0,024, PR страницы категории: 0,027, PR страницы продукта: 0,06, PR веб-страниц без трафика: 0,252.
Как вы могли заметить, Googlebot не может доверять этой внутренней структуре ссылок для расчета внутреннего рейтинга и важности внутренних страниц. Страницы без трафика и товаров имеют в 12 раз больше авторитета, чем домашняя страница. Он имеет больше, чем страницы продукта.

Этот пример ближе к нашей ситуации до обновления основного алгоритма от 5 июня. PR домашней страницы: 0,033, страница категории: 0,037, страница продукта: 0,148 и PR страниц без трафика: 0,037.
Как вы можете заметить, внутренняя структура ссылок по-прежнему неправильная, но, по крайней мере, страницы, не связанные с трафиком, не имеют больше PR, чем страницы категорий и страницы продуктов.
Что является еще одним доказательством того, что Google вывел внутренние ссылки и структуру сайта из области PageRank в соответствии с потоком пользователей, запросами и намерениями? Конечно, поведение робота Googlebot, а также внутренние корреляции PageRank и рейтинга:
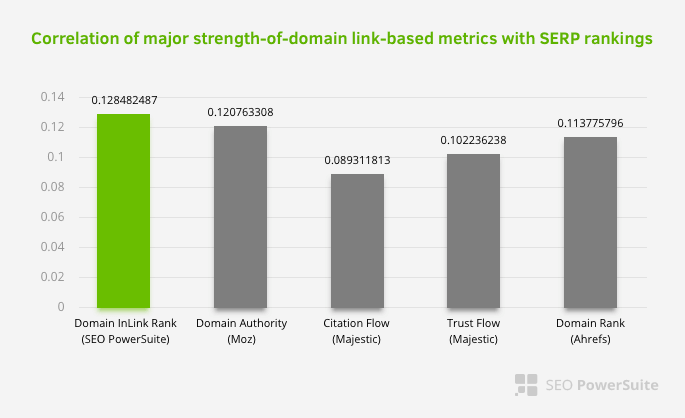
Это не означает, что внутренняя ссылочная сеть особенно важнее других факторов. Перспектива SEO, которая фокусируется на одной точке, никогда не может быть успешной. При сравнении сторонних инструментов видно, что внутреннее значение PageRank прогрессирует по отношению к другим критериям.
Согласно исследованию Inlink Rank и ранговой корреляции Олега Борисевича, страницы с наибольшим количеством внутренних ссылок имеют более высокий рейтинг, чем другие страницы сайта. Согласно опросу, проведенному 4-6 марта 2019 года, было проанализировано 1 000 000 страниц по внутренней метрике PageRank по 33 500 ключевым словам. Результаты этого исследования, проведенного SEO PowerSuite, были сопоставлены с различными показателями Moz, Majestic и Ahrefs и дали более точные результаты.
Вот некоторые номера внутренних ссылок с нашего сайта до обновления основного алгоритма от 12 марта:
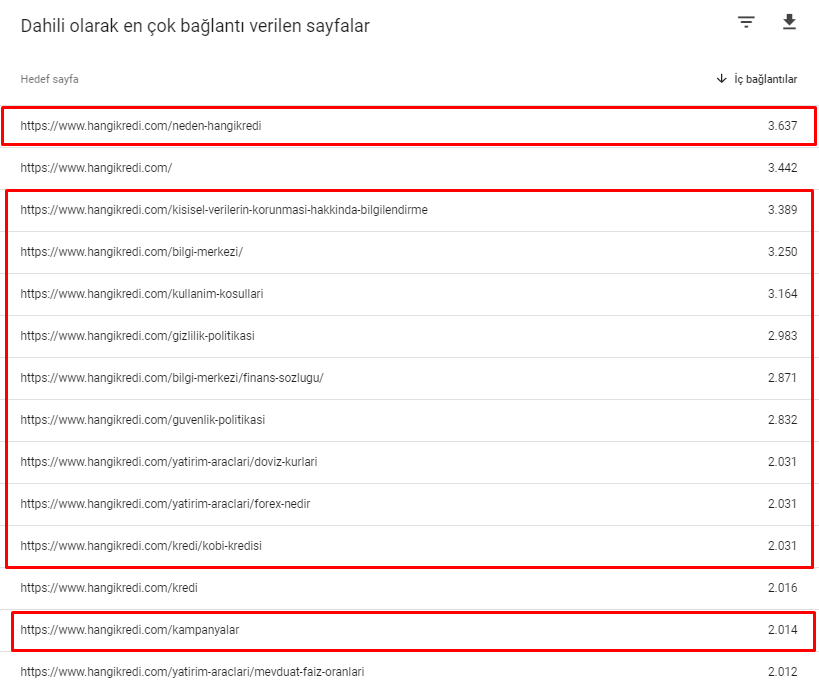
Как видите, наша внутренняя схема подключения не отражала намерения и поток пользователей. Страницы, которые получают наименьший трафик (страницы второстепенных продуктов) или которые никогда не получают трафика (выделены красным), были непосредственно в 1st Click Depth и получали PR от главной страницы. А у некоторых было даже больше внутренних ссылок, чем на главной странице.
В свете всего этого есть только два последних момента, которые мы можем показать по этому вопросу.
- Скорость сканирования / спрос на страницы с наибольшим количеством внутренних ссылок
- Скульптура ссылок и PageRank
В период с 1 февраля по 31 марта вот страницы, которые Googlebot сканировал чаще всего:
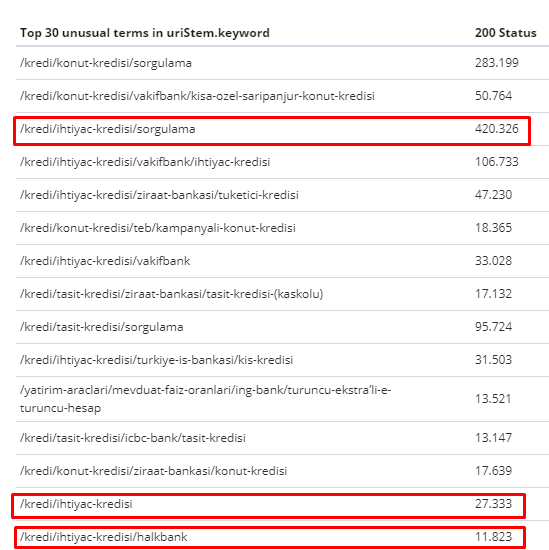
Как вы могли заметить, просканированные страницы и страницы с наибольшим количеством внутренних ссылок полностью отличаются друг от друга. Страницы с наибольшим количеством внутренних ссылок были неудобны для пользователей; у них нет органических ключевых слов или какой-либо прямой ценности SEO. (
URL-адреса в красных полях — это наши наиболее посещаемые и важные категории страниц продуктов. Другие страницы в этом списке являются вторыми или третьими по посещаемости и важными категориями.)
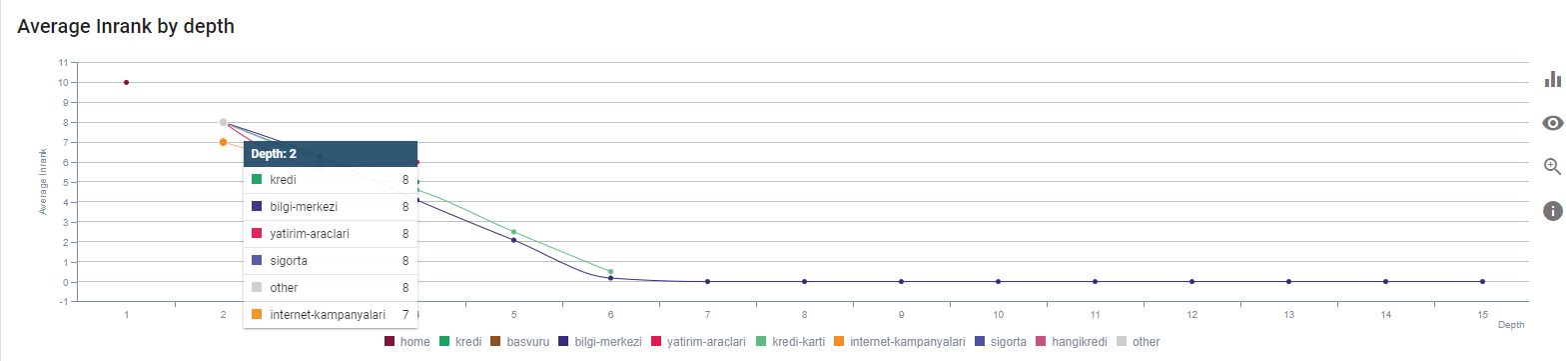
Наш текущий Inrank по глубине страницы. Источник: Онкраул.
Что такое скульптинг ссылок и что делать с внутренними ссылками Nofollow?
Вопреки мнению большинства SEO-специалистов, ссылки, помеченные тегом «nofollow», по-прежнему проходят внутреннее значение PageRank. Для меня, после всех этих лет, никто не рассказал об этом элементе SEO лучше, чем Мэтт Каттс в своей статье о моделировании рейтинга страниц от 15 июня 2009 года.
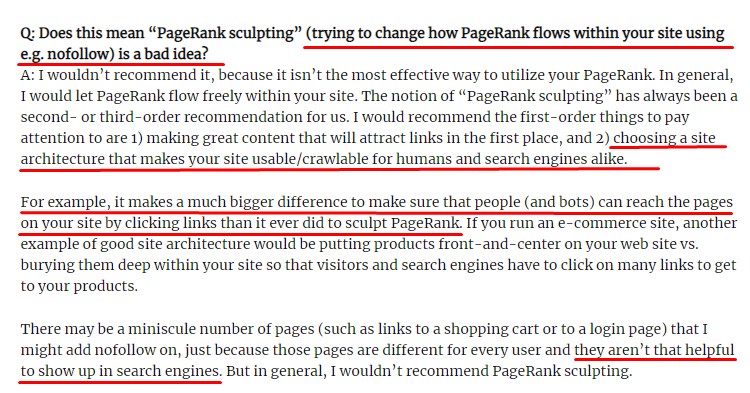
Полезная часть для Link Sculpting, которая показывает реальную цель PageRank Sculpting.
«Я бы не рекомендовал использовать nofollow для моделирования PageRank на веб-сайте, потому что он, вероятно, не делает того, что вы думаете».
– Джон Мюллер, Google, 2017 г.
Если у вас есть бесполезные веб-страницы с точки зрения Google и пользователей, вы не должны помечать их тегом «nofollow». Это не остановит поток PageRank. Вы должны запретить их из файла robots.txt. Таким образом, робот Googlebot не будет их сканировать, но и не передаст им внутренний рейтинг страницы. Но вы должны использовать это только для действительно бесполезных страниц, как десять лет назад сказал Мэтт Каттс. Страницы, которые делают автоматические перенаправления для аффилированного маркетинга, или страницы практически без контента — вот несколько удобных примеров.
Решение: лучшая и более естественная внутренняя структура ссылок
У нашего конкурента был недостаток. На их веб-сайте было больше анкорного текста, больше внутренних ссылок, но их структура не была естественной и полезной. Один и тот же якорный текст использовался с одним и тем же предложением на каждой странице их сайта. Начальный абзац для каждой страницы был покрыт этим повторяющимся содержанием. Каждый пользователь и поисковая система могут легко понять, что это не естественная структура, учитывающая выгоду пользователя.
Поэтому я решил сделать три вещи, чтобы исправить внутреннюю структуру ссылок:
- Информационная архитектура сайта или дерево сайта должны следовать по пути, отличному от ссылок, размещенных в контенте. Он должен более внимательно следить за разумом пользователя и нейронной сетью с ключевыми словами.
- В каждом фрагменте контента побочные ключевые слова должны использоваться вместе с основными ключевыми словами целевой страницы.
- Якорные тексты должны быть естественными, адаптированными к содержанию и должны использоваться в разных местах на каждой странице с учетом восприятия пользователем.
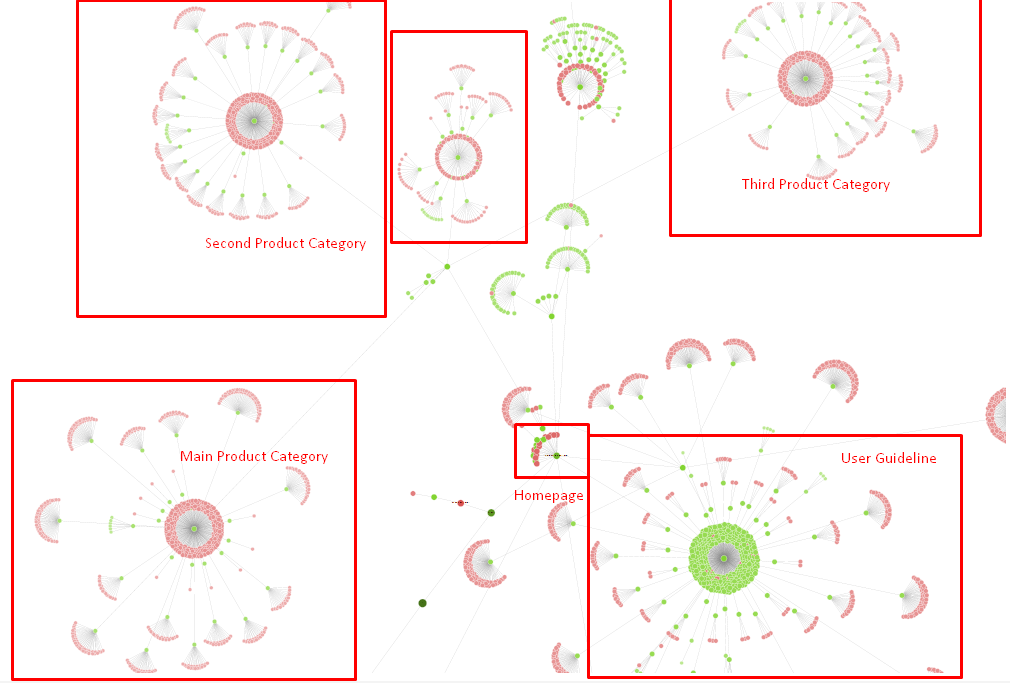
Наше дерево сайта и часть внутренней структуры на данный момент.
На приведенной выше диаграмме вы можете увидеть нашу текущую внутреннюю ссылку и дерево сайта.
Некоторые из вещей, которые мы сделали для решения этой проблемы, приведены ниже:
- Мы создали еще 30 000 внутренних ссылок с полезными анкорами.
- Мы использовали естественные места и ключевые слова для пользователя.
- Мы не использовали повторяющиеся предложения и шаблоны для внутренних ссылок.
- Мы дали правильные сигналы роботу Googlebot о ранжировании веб-страницы.
- Мы изучили влияние правильной структуры внутренних ссылок на эффективность сканирования с помощью анализа журналов и увидели, что наши основные страницы продуктов сканировались чаще, чем в предыдущей статистике.
- Создано более 50 000 внутренних ссылок для осиротевших страниц.
- Использовал внутренние ссылки главной страницы для питания подстраниц и создал больше внутренних источников ссылок на главной странице.
- Для защиты PageRank Power мы также использовали тег nofollow для некоторых ненужных внешних ссылок. (Речь не шла о внутренних ссылках, но она служит той же цели.)
3. Проблема: структура контента
Google говорит, что для веб-сайтов YMYL надежность и авторитетность намного важнее, чем для других типов сайтов.

В старые времена ключевые слова были просто ключевыми словами. Но теперь они также являются объектами , которые четко определены, единичны, значимы и различимы. В нашем контенте было четыре основные проблемы:
- Наш контент был коротким. (Обычно длина контента не важна. Но в этом случае они не содержали достаточно информации по темам.)
- Имена наших писателей не были единичными, значимыми или различимыми как единое целое.
- Наш контент не был приятным для глаз. Другими словами, это не был контент «фаст-фуд». Это было содержание без подзаголовков.
- Мы использовали маркетинговый язык. На пространстве одного абзаца мы могли определить название бренда и его рекламу для пользователя.
- Было много кнопок, которые направляли пользователей на страницы продуктов с информационных страниц.
- В содержании наших страниц продуктов не было достаточно информации или подробных рекомендаций.
- Дизайн не был удобным для пользователя. Мы использовали в основном один и тот же цвет для шрифта и фона. (В основном это все еще имеет место из-за проблем с инфраструктурой.)
- Изображения и видео не рассматривались как часть контента.
- Намерение пользователя и намерение поиска по конкретному ключевому слову раньше не считались такими важными.
- Было много дублированного, ненужного и повторяющегося контента по одной и той же теме.
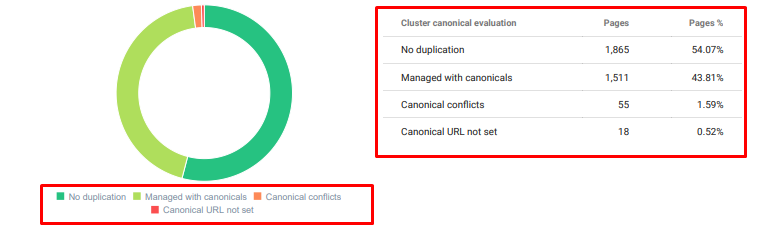
OnCrawl Duplicated Content Audit с сегодняшнего дня.
Решение: лучшая структура контента для доверия пользователей
При проверке проблемы в масштабе всего сайта использование программы аудита для всего сайта в качестве помощника — лучший способ организовать время, затрачиваемое на SEO-проекты. Как и в разделе внутренних ссылок, я использовал Oncrawl Site Audit вместе с другими инструментами и проверками Xpath.
Во-первых, исправление каждой проблемы в разделе контента заняло бы слишком много времени. В те разваливающиеся кризисные дни время было роскошью. Поэтому я решил исправить такие быстро выигрывающие проблемы, как:
- Удаление повторяющегося, ненужного и повторяющегося контента
- Объединение короткого и тонкого контента без исчерпывающей информации
- Повторная публикация контента без подзаголовков и структуры, отслеживаемой глазами.
- Исправление интенсивного маркетингового тона в контенте
- Удаление множества кнопок призыва к действию из контента
- Лучшая визуальная коммуникация с изображениями и видео
- Обеспечение совместимости контента и целевых ключевых слов с намерением пользователя и поиска
- Использование и отображение финансовых и образовательных организаций в контенте для доверия
- Использование социального сообщества для создания социального доказательства одобрения
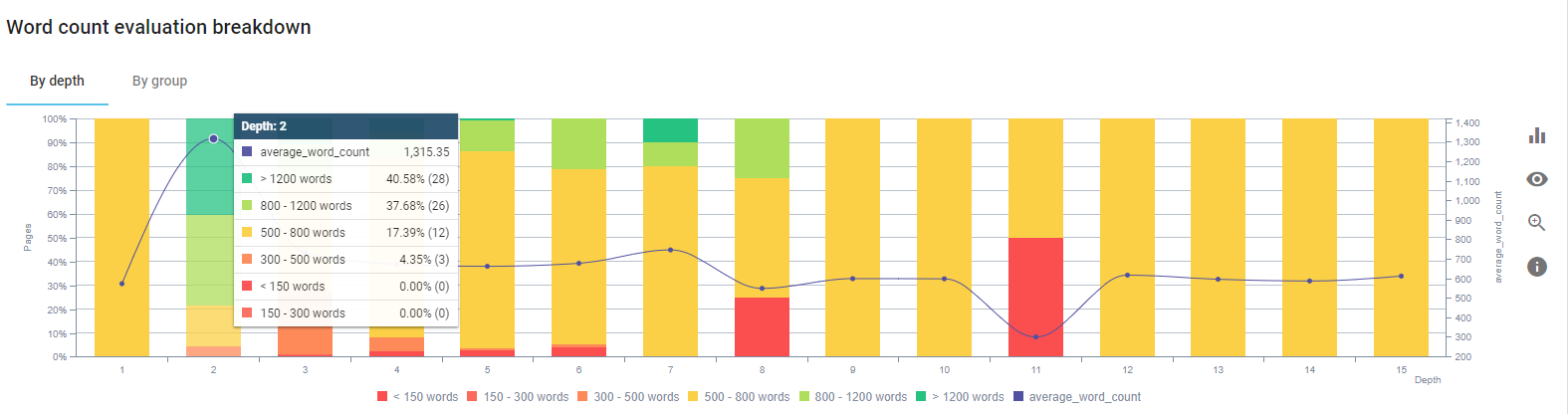

Мы сосредоточились на исправлении содержимого страниц продуктов и ближайших к ним справочных страниц.
В начале этого процесса большая часть наших целевых страниц продуктов и транзакций содержала менее 500 слов без исчерпывающей информации.
За 25 дней мы выполнили следующие действия:
- Удалено 228 страниц с дублирующимся, ненужным и повторяющимся контентом. (Профили обратных ссылок Ccontent были проверены перед процессом удаления. И мы использовали коды состояния 301 или 410 для лучшей связи с Googlebot.)
- В совокупности более 123 страниц не хватает исчерпывающей информации.
- Используемые подзаголовки в соответствии с их важностью и потребностью пользователей в содержании.
- Удалено название бренда и кнопки CTA с маркетинговым языком.
- Включите текст в изображения, чтобы усилить основную тему.
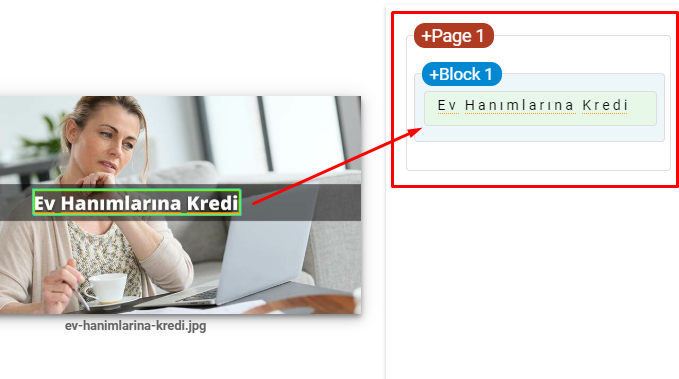
Это скриншот из Google Vision AI. Google может читать текст на изображениях и определять чувства и идентичность внутри сущностей.
- Активировали нашу социальную сеть, чтобы привлечь больше пользователей.
- Изучил разрыв в контенте между конкурентами и нами и создал более 80 новых единиц контента.
- Использовали Google Analytics, Search Console и Google Data Studio для определения неэффективных страниц с высоким показателем отказов и низким трафиком.
- Провел исследование для Featured Snippets, их ключевых слов и структуры контента. Мы добавили те же заголовки и структуру контента в наш связанный контент. Это увеличило наши избранные фрагменты.
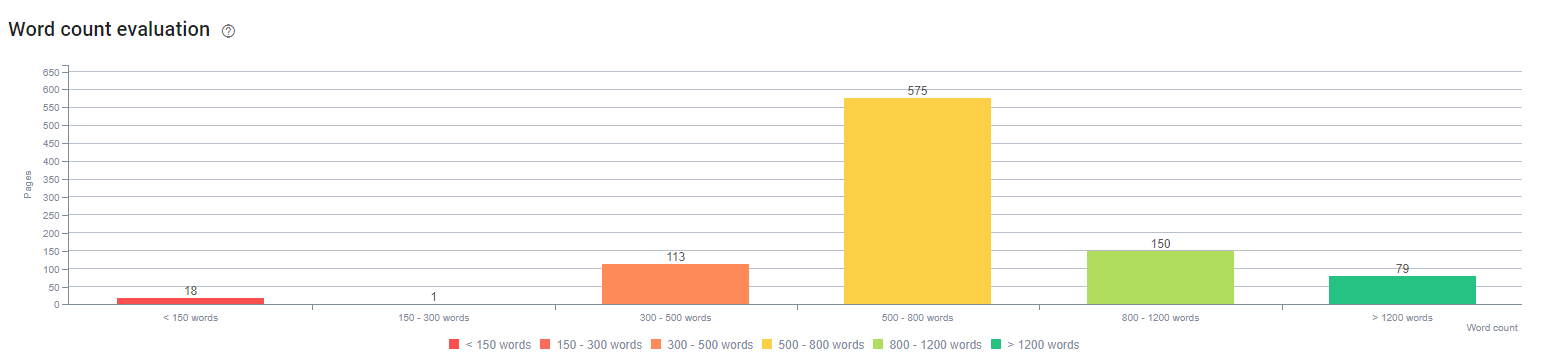
В начале этого процесса наш контент состоял в основном из 150–300 слов. Наша средняя длина контента увеличилась на 350 слов для всего сайта.
4. Проблема: загрязнение индекса, раздувание и канонические теги
Google никогда не делал заявлений о загрязнении индекса, и на самом деле я не уверен, использовал ли кто-то его как термин SEO раньше или нет. Все страницы, которые не имеют смысла для Google для более эффективного индексирования, должны быть удалены из индексных страниц Google. Страницы, вызывающие загрязнение индекса, — это страницы, которые не приносят трафика в течение нескольких месяцев. У них нулевой CTR и ноль органических ключевых слов. В тех случаях, когда у них есть несколько органических ключевых слов, они должны стать конкурентами других страниц вашего сайта по тем же ключевым словам.
Кроме того, мы провели исследование на предмет раздувания индекса и обнаружили еще больше ненужных проиндексированных страниц. Эти страницы существовали из-за неправильной информационной структуры сайта или из-за неправильной структуры URL.
Еще одной причиной этой проблемы было неправильное использование канонических тегов. Более двух лет канонические теги рассматривались как подсказки для робота Googlebot. Если они используются неправильно, Googlebot не будет их вычислять или обращать на них внимание при оценке сайта. Кроме того, для этого расчета вы, вероятно, будете расходовать краулинговый бюджет неэффективно. Из-за неправильного использования канонического тега у нас было проиндексировано более 300 страниц комментариев с дублирующимся контентом.
Моя теория направлена на то, чтобы показать Google только качественные и нужные страницы, которые потенциально могут приносить клики и создавать ценность для пользователей.
Решение: исправление загрязнения и раздувания индекса
Сначала я воспользовался советом Джона Мюллера из Google. Я спросил его, если я использую тег noindex для этих страниц, но все же позволю роботу Googlebot следовать за ними, «потеряю ли я ссылочный вес и эффективность сканирования?»
Как вы можете догадаться, он сначала сказал «да», но затем предположил, что использование внутренних ссылок может преодолеть это препятствие.
Я также обнаружил, что использование тегов noindex одновременно с dofollow снижает скорость сканирования этих страниц роботом Googlebot. Эти стратегии позволили мне заставить робота Googlebot чаще сканировать мой продукт и важные страницы рекомендаций. Я также изменил свою внутреннюю структуру ссылок, как посоветовал Джон Мюллер.
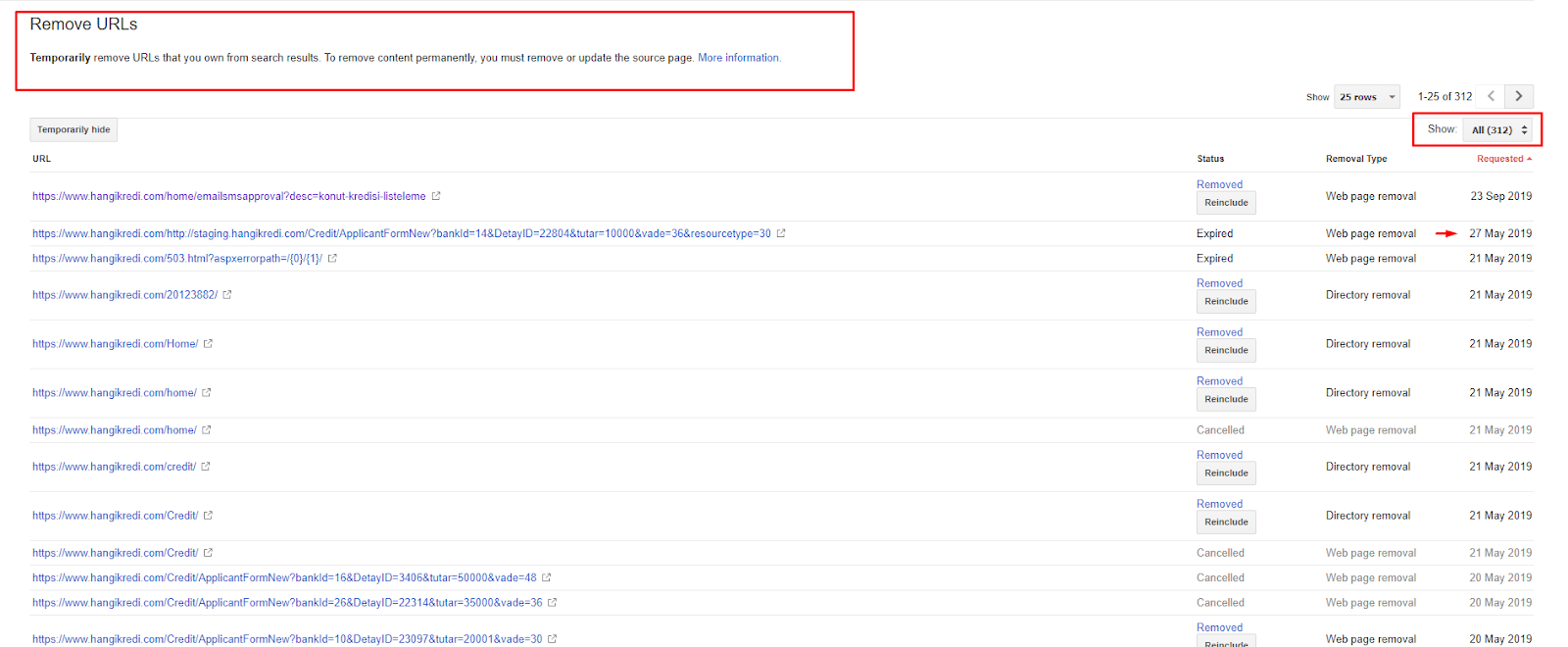
В течение короткого времени:
- Обнаружены ненужные проиндексированные страницы.
- Из индекса было удалено более 300 страниц.
- Был реализован тег noindex.
- Внутренняя ссылочная структура изменена для страниц, получивших ссылки со страниц, удаленных из индекса.
- Эффективность и качество сканирования проверялись с течением времени.
5. Проблема: неверные коды состояния
Вначале я заметил, что робот Googlebot посещает много удаленного контента из прошлого. Даже страницы восьмилетней давности все еще сканировались. Это произошло из-за использования неправильных кодов состояния, особенно для удаленного контента.
Существует огромная разница между функциями 404 и 410. Один из них предназначен для страницы с ошибкой, на которой не существует контента, а другой — для удаленного контента. Кроме того, действительные страницы также ссылались на множество удаленных URL-адресов источников и контента. Некоторые удаленные изображения и ресурсы CSS или JS также использовались на действительных опубликованных страницах в качестве ресурсов. Наконец, было много мягких страниц 404, множественных цепочек перенаправлений и временных перенаправлений 302-307 для страниц с постоянным перенаправлением.
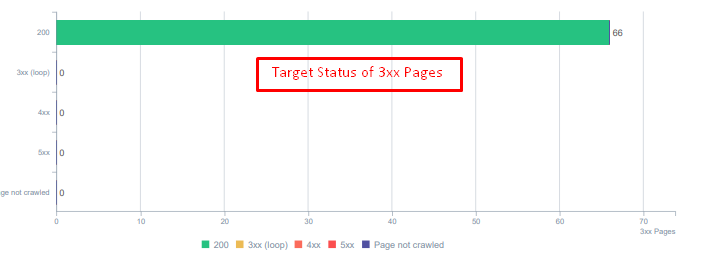
Коды состояния для перенаправленных активов сегодня.
Решение: исправление неправильных кодов состояния
- Каждый код состояния 404 был преобразован в код состояния 410. (более 30000)
- Каждый ресурс с кодом состояния 404 был заменен новым действительным ресурсом. (более 500)
- Каждое перенаправление 302-307 было преобразовано в постоянное перенаправление 301. (более 1500)
- Цепочки перенаправления были удалены из используемых активов.
- Каждый месяц мы получали более 25 000 посещений страниц и ресурсов с кодом состояния 404 в нашем анализе журналов. Теперь это меньше 50 для 404 кодов состояния в месяц и ноль обращений для 410 кодов состояния…
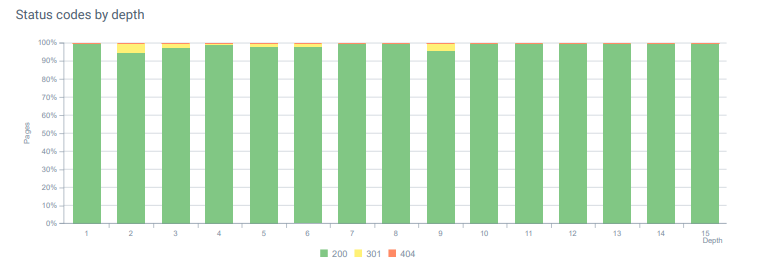
Коды состояния на всей глубине страницы сегодня.
6. Проблема: семантический HTML
Семантика относится к тому, что что-то означает. Семантический HTML включает теги, которые придают значение компоненту страницы в иерархии. С помощью этой иерархической структуры кода вы можете сообщить Google, какова цель части контента. Кроме того, в случае, если робот Googlebot не может просканировать все ресурсы, необходимые для полного отображения вашей страницы, вы можете, по крайней мере, указать макет своей веб-страницы и функции частей контента для робота Googlebot.
На Hangikredi.com, после обновления основного алгоритма Google от 12 марта, я понял, что краулингового бюджета недостаточно из-за неоптимизированной структуры веб-сайта. Итак, чтобы роботу Googlebot было легче понять цель, функцию, содержание и полезность веб-страницы, я решил использовать семантический HTML.
Решение: семантическое использование HTML
Согласно Руководству Google по оценке качества, у каждого пользователя, ищущего, есть намерение, и каждая веб-страница имеет функцию, соответствующую этому намерению. Чтобы продемонстрировать эти функции роботу Googlebot, мы внесли некоторые улучшения в нашу HTML-структуру для некоторых страниц, которые реже сканируются роботом Googlebot.
- Используется тег <main> для отображения основного содержимого и функций страницы.
- Используется <nav> для навигационной части.
- Используется <footer> для нижнего колонтитула сайта.
- Используется <article> для статьи.
- Используемые теги <section> для каждого тега заголовка.
- Использованы теги <picture>, <table>, <citation> для изображений, таблиц и цитат в содержании.
- Используется тег <aside> для дополнительного контента.
- Исправлены проблемы с иерархией H1-H6 (несмотря на последнее заявление Google «использование двух H1 не является проблемой», использование правильной структуры помогает роботу Googlebot).
- Как и в разделе «Структура контента», мы также использовали семантический HTML для избранных фрагментов, мы использовали таблицы и списки для большего количества результатов избранных фрагментов.

Для нас это не было реально реализуемой разработкой для всего сайта. Тем не менее, с каждым обновлением дизайна мы продолжаем внедрять семантические теги HTML для дополнительных веб-страниц.
7. Проблема: использование структурированных данных
Как и использование семантического HTML, структурированные данные могут использоваться для демонстрации функций и определений частей веб-страницы роботу Googlebot. Кроме того, структурированные данные являются обязательными для расширенных результатов. На нашем сайте структурированные данные не использовались или, что чаще всего, использовались некорректно до конца марта. Чтобы улучшить отношения с объектами на нашем веб-сайте и в наших внестраничных учетных записях, мы начали внедрять структурированные данные.
Решение: правильное и проверенное использование структурированных данных
Для финансовых учреждений и веб-сайтов YMYL структурированные данные могут решить множество проблем. Например, они могут отображать идентичность бренда, тип контента и улучшать представление фрагментов. Мы использовали следующие структурированные типы данных для всего сайта и отдельных страниц:
- Часто задаваемые вопросы Структурированные данные для основных страниц продуктов
- Структурированные данные веб-страницы
- Структурированные данные организации
- Хлебные крошки структурированные данные
8. Оптимизация карты сайта и robots.txt
На Hangikredi.com нет динамической карты сайта. Существующая карта сайта в то время не включала все необходимые страницы, а также включала удаленный контент. Кроме того, в файле Robots.txt не были запрещены некоторые партнерские реферальные страницы с тысячами внешних ссылок. Это также включало некоторые сторонние JS-файлы, не связанные с контентом, и другие дополнительные ресурсы, которые не нужны роботу Googlebot.
Были применены следующие шаги:
- Создан файл sitemap_index.xml для нескольких карт сайта, которые создаются в соответствии с категориями сайтов для улучшения сигналов сканирования и лучшего изучения охвата.
- Некоторые сторонние файлы JS и некоторые ненужные файлы JS были запрещены в файле robots.txt.
- Партнерские страницы с внешними ссылками и без ценности целевой страницы были запрещены, как мы упоминали в разделе PageRank или скульптура внутренних ссылок.
- Исправлено более 500 проблем с покрытием. (Большинство из них были страницами, которые были проиндексированы, несмотря на то, что они были запрещены Robots.txt.)
Вы можете увидеть нашу скорость сканирования, увеличение нагрузки и спроса на диаграмме ниже:
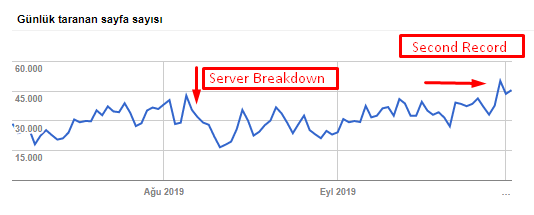
Количество просканированных страниц в день роботом Googlebot. До 1 августа наблюдался устойчивый рост количества просканированных страниц в день. После атаки, вызвавшей сбой сервера в начале августа, он восстановил свою стабильность чуть более чем через месяц.

Ежедневная нагрузка робота Googlebot сканируется параллельно с количеством сканируемых страниц в день.
9. Устранение проблем с AMP
На веб-сайте фирмы каждая страница блога имеет версию AMP. Из-за неправильной реализации кода и отсутствия канонических символов AMP все AMP-страницы неоднократно удалялись из индекса. Это создало нестабильную оценку индекса и отсутствие доверия к веб-сайту. Кроме того, на AMP-страницах по умолчанию использовались английские термины и слова в турецком контенте.
- Канонические теги были исправлены для более чем 400 страниц AMP.
- Были найдены и исправлены некорректные реализации кода. (В основном это было связано с некорректной реализацией тегов AMP-Analytics и AMP-Canonical.)
- Английские термины по умолчанию были переведены на турецкий язык.
- Индекс и стабильность рейтинга были созданы для блоговой части веб-сайта фирмы.
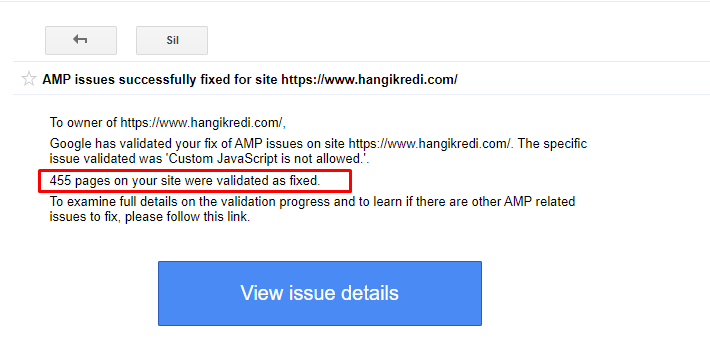
Пример сообщения в GSC об улучшениях AMP
10. Проблемы с метатегами и решения
Из-за проблем с краулинговым бюджетом, иногда в критических поисковых запросах для важных основных страниц продукта, Google не индексировал и не отображал контент в метатегах. Вместо мета-заголовка в поисковой выдаче отображалось только название фирмы, состоящее из двух слов. Описание фрагмента не было показано. Это снижало наш CTR и наносило ущерб нашей торговой марке. Мы исправили эту проблему, переместив метатеги в начало нашего исходного кода, как показано ниже.
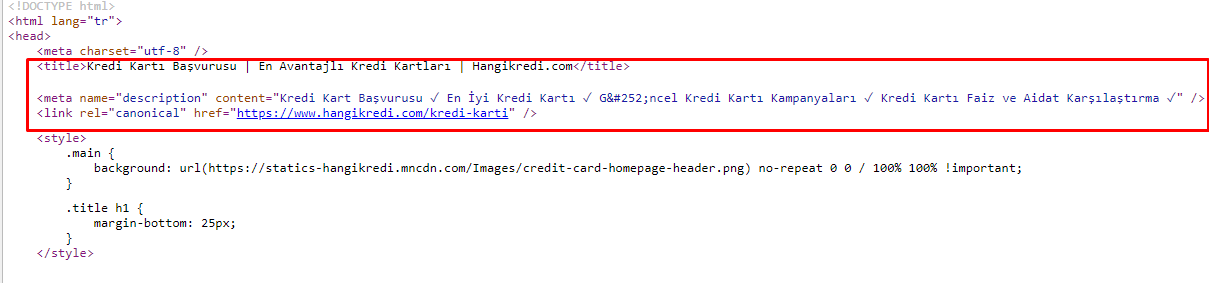
Помимо краулингового бюджета, мы также оптимизировали более 600 метатегов для транзакционных и информационных страниц:
- Оптимизирована длина символов для мобильных устройств.
- Используется больше ключевых слов в заголовках
- Использовали разные стили метатегов и изучили CTR, разрыв ключевых слов и изменения рейтинга.
- Благодаря этим процессам оптимизации создано больше страниц с правильной структурой дерева сайтов для лучшего таргетинга на второстепенные ключевые слова.
- На нашем сайте у нас все еще есть разные мета-заголовки, описания и заголовки для тестирования алгоритма Google и CTR поискового пользователя.
11. Проблемы с производительностью изображения и решения
Проблемы с изображением можно разделить на два типа. Для удобства содержания и для скорости страницы. Для обоих веб-сайт фирмы еще многое предстоит сделать.
В марте и апреле после отрицательного обновления основного алгоритма от 12 марта:
- У изображений не было alt-тегов или у них были неправильные alt-теги.
- У них не было титулов.
- У них неправильная структура URL.
- У них не было расширений следующего поколения.
- Они не сжимались.
- У них не было правильного разрешения для каждого размера экрана устройства.
- У них не было надписей.
Чтобы подготовиться к следующему обновлению основного алгоритма Google:
- Изображения были сжаты.
- Их расширения были частично изменены.
- Для большинства из них были написаны теги Alt.
- Заголовки и подписи были фиксированы для пользователя.
- Структуры URL были частично исправлены для пользователя.
- Мы нашли несколько неиспользуемых изображений, которые все еще загружаются браузером, и удалили их из системы.
Из-за инфраструктуры сайта мы частично внедрили SEO-корректировку изображений.
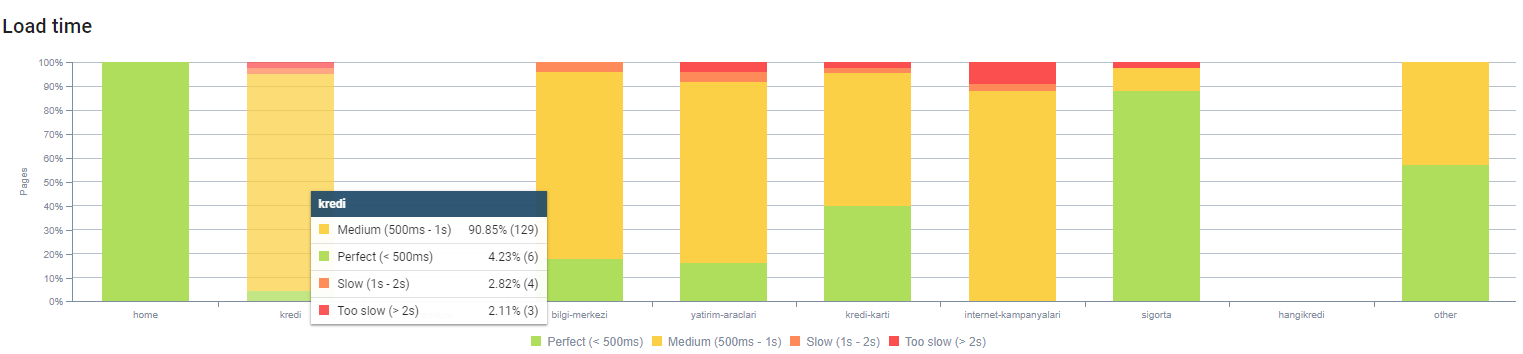
Вы можете наблюдать время загрузки нашей страницы по глубине страницы выше. Как видите, большинство страниц товаров по-прежнему тяжелые.
12. Проблемы с кэшем, предварительной выборкой и предварительной загрузкой и их решения
Перед обновлением основного алгоритма от 12 марта на веб-сайте фирмы существовала незащищенная система кэширования. Некоторые части контента были в кеше, а некоторые нет. Это было особенно проблемой для страниц продуктов, потому что они были медленнее, чем страницы продуктов нашего конкурента, в 2 раза. Большинство компонентов наших веб-страниц на самом деле являются статическими источниками, но у них все еще нет Etags для указания диапазона кеша.
Чтобы подготовиться к следующему обновлению основного алгоритма Google:
- Мы кэшировали некоторые компоненты для каждой веб-страницы и сделали их статическими.
- Эти страницы были важными страницами продукта.
- Мы по-прежнему не используем электронные теги из-за инфраструктуры сайта.
- В частности, изображения, статические ресурсы и некоторые важные части контента теперь полностью кэшируются по всему сайту.
- Мы начали использовать код dns-prefetch для некоторых забытых внешних ресурсов.
- Мы по-прежнему не используем код предварительной загрузки, но работаем над пользовательским путешествием по сайту, чтобы реализовать его в будущем.
13. Оптимизация и минимизация HTML, CSS и JS
Из-за проблем с инфраструктурой сайта было не так много вещей, которые нужно было сделать для скорости сайта. Я пытался восполнить пробел всеми возможными способами, включая удаление некоторых компонентов страницы. Для важных страниц товаров мы очистили структуру HTML-кода, минифицировали и сжали ее.
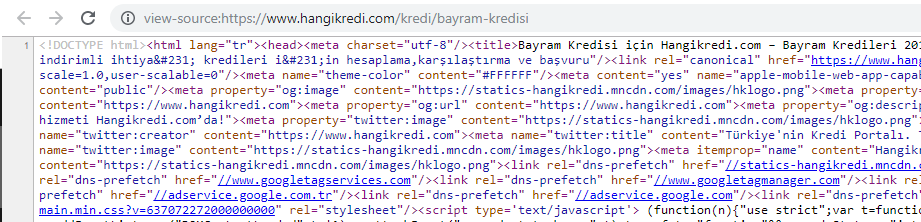
Скриншот исходного кода одной из наших сезонных, но важных страниц продукта. Использование структурированных данных часто задаваемых вопросов, минимизации HTML, оптимизации изображений, обновления контента и внутренних ссылок дало нам первое место в нужное время. (Ключевое слово «Bayram Kredisi» на турецком языке, что означает «Праздничный кредит»)
Мы также реализовали факторинг CSS, рефакторинг и сжатие JS частично небольшими шагами. Когда рейтинг упал, мы изучили разрыв в скорости сайта между страницами нашего конкурента и нашей. Мы выбрали несколько срочных страниц, которые можно было бы ускорить. Мы также частично очистили и сжали важные CSS-файлы на этих страницах. Мы инициировали процесс удаления некоторых сторонних JS-файлов, используемых разными отделами фирмы, но они еще не удалены. Для некоторых страниц товаров мы также смогли изменить порядок загрузки ресурсов.
Изучение конкурентов
В дополнение к каждому техническому улучшению SEO, изучение конкурентов было моим лучшим руководством для понимания природы и целей обновления основного алгоритма. Я использовал несколько полезных и полезных программ, чтобы следить за изменениями в дизайне, содержании, рейтинге и технологиях моего конкурента.
- Для изменения рейтинга ключевых слов я использовал Wincher, Semrush и Ahrefs.
- Для упоминаний брендов я использовал Google Alerts, BuzzSumo, Talkwalker.
- Для отчетов о новых ссылках и новых ключевых словах я использовал Ahrefs Alert.
- Для изменения контента и дизайна я использовал Visualping.
- Для технологических изменений я использовал SimilarTech.
- Для Google Update News and Inspection я в основном использовал Semrush Sensor, Algoroo и CognitiveSEO Signals.
- Для проверки истории URL-адресов конкурентов я использовал Wayback Machine.
- Для скорости сервера конкурентов я использовал Chrome DevTools и ByteCheck.
- Для стоимости сканирования и рендеринга я использовал «Сколько стоит мой сайт». (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
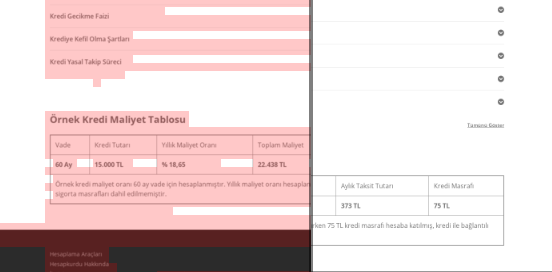
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.