
Прогнозирование SEO-трафика с помощью Prophet и Python
Опубликовано: 2021-03-16Постановка целей и оценка достижений с течением времени — очень интересное упражнение, позволяющее понять, чего мы можем достичь, и эффективна ли используемая нами стратегия. Однако обычно не так просто установить эти цели, потому что сначала нам нужно составить прогноз.
Создание прогноза — дело непростое, но благодаря некоторым доступным процедурам прогнозирования, нашему процессору и некоторым навыкам программирования мы можем значительно снизить его сложность. В этом посте я собираюсь показать вам, как мы можем делать точные прогнозы и как вы можете применить это к SEO, используя Python и библиотеку Prophet и не обладая сверхспособностями гадалки.
Если вы никогда не слышали о Пророке, вам может быть интересно, что это такое. Короче говоря, Prophet — это процедура прогнозирования, выпущенная командой Facebook Core Data Science, которая доступна на Python и R и которая очень хорошо справляется с выбросами и сезонными эффектами, чтобы
делать точные и быстрые прогнозы.
Когда мы говорим о прогнозировании, мы должны учитывать две вещи:
- Чем больше у нас исторических данных, тем точнее будет наша модель и, следовательно, наши прогнозы.
- Прогностическая модель будет действительна только в том случае, если внутренние факторы остаются прежними и на нее не влияют внешние факторы. Это означает, что если, например, мы публикуем один пост в неделю и начинаем публиковать два поста в неделю, эта модель может оказаться недействительной для предсказания того, каким будет результат от этого изменения стратегии. С другой стороны, если есть обновление алгоритма, модель также может быть недействительной. Имейте в виду, что модель построена на основе исторических данных.
Чтобы применить это к SEO, мы собираемся прогнозировать сеансы SEO на предстоящий месяц, выполнив следующие шаги:
- Получение данных из Google Analytics об органических сессиях за определенный период времени.
- Обучение нашей модели.
- Прогнозирование SEO-трафика на ближайший месяц.
- Оценка того, насколько хороша наша модель, по средней абсолютной ошибке.
Хотите узнать больше о том, как работает эта процедура прогнозирования? Тогда давайте начнем!
Получение данных из Google Analytics
Мы можем подойти к извлечению данных из Google Analytics двумя способами: экспортировать файл Excel из обычного интерфейса или использовать API для извлечения этих данных.
Импорт данных из файла Excel
Самый простой способ получить эти данные из Google Analytics — перейти в раздел «Каналы» на боковой панели, щелкнуть «Органический» и экспортировать данные с помощью кнопки, которая находится вверху страницы. Убедитесь, что вы выбрали в раскрывающемся меню в верхней части графика переменную, которую хотите проанализировать, в данном случае Sessions.
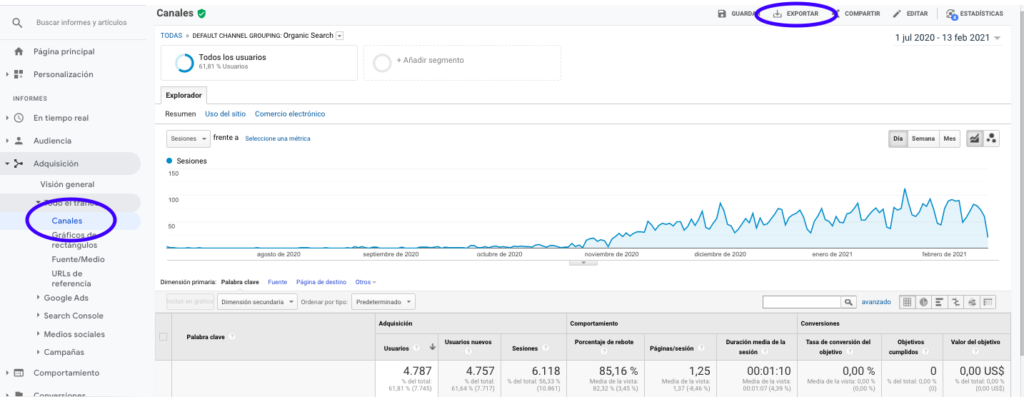
После экспорта данных в виде файла Excel мы можем импортировать их в нашу записную книжку с помощью Pandas. Обратите внимание, что файл Excel с такими данными будет содержать разные вкладки, поэтому вкладку с месячным трафиком необходимо указать в качестве аргумента в фрагменте кода, который находится ниже. Мы также удаляем последнюю строку, потому что она содержит общее количество сеансов, что исказило бы нашу модель.
импортировать панд как pd
df = pd.read_excel ('.xlsx', имя_листа = "")
df = df.drop (len (df) - 1)
Мы можем нарисовать с помощью Matplotlib, как выглядят данные:
из matplotlib импортировать pyplot
df["Сеансы"].plot(title = "Сессии")
pyplot.show () 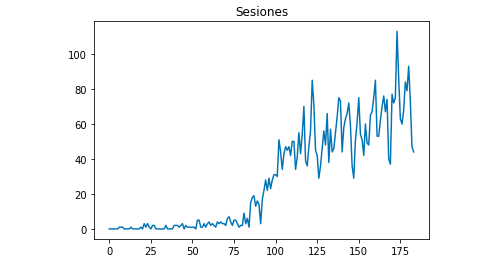
Использование API Google Аналитики
Прежде всего, чтобы использовать Google Analytics API, нам нужно создать проект в консоли разработчика Google, включить службу отчетов Google Analytics и получить учетные данные. Жан-Кристоф Шуинар очень хорошо объясняет в этой статье, как это настроить.
Как только учетные данные получены, нам нужно пройти аутентификацию, прежде чем делать запрос. Аутентификацию необходимо выполнить с помощью файла учетных данных, который был первоначально получен из консоли разработчика Google. Нам также нужно будет записать в наш код идентификатор просмотра GA из свойства, которое мы хотели бы использовать.
из сборки импорта apiclient.discovery
из oauth2client.service_account импортировать учетные данные ServiceAccountCredentials
ОБЛАСТИ = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
ПОСМОТРЕТЬ_
учетные данные = ServiceAccountCredentials.from_json_keyfile_name (KEY_FILE_LOCATION, SCOPES)
analytics = build('отчеты по аналитике', 'v4', учетные данные=учетные данные)После аутентификации нам просто нужно сделать запрос. Тот, который нам нужно использовать для получения данных об органических сеансах за каждый день:
ответ = аналитика.отчеты().batchGet(тело={
'запросы отчета': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
«метрики»: [
{"выражение": "ga:sessions"}
], "Габаритные размеры": [
{"имя": "га:дата"}
],
"filtersExpression":"ga:channelGrouping=~Органический",
"includeEmptyRows": "истина"
}]}).выполнять()Обратите внимание, что мы выбираем диапазон времени в dateRanges. В моем случае я собираюсь получить данные с 1 сентября по 31 января: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
После этого нам нужно только получить файл ответов, чтобы добавить в список дни с их органическими сеансами:
список_значений = [] для x в ответ["отчеты"][0]["данные"]["строки"]: list_values.append([x["параметры"][0],x["метрики"][0]["значения"][0]])
Как видите, использовать API Google Analytics довольно просто, и его можно использовать для многих целей. В этой статье я объяснил, как вы можете использовать API Google Analytics для создания предупреждений для обнаружения неэффективных страниц.

Адаптация списков к Dataframes
Чтобы использовать Prophet, нам нужно ввести Dataframe с двумя столбцами, которые должны быть названы: «ds» и «y». Если вы импортировали данные из файла Excel, они у нас уже есть как Dataframe, поэтому вам нужно будет только назвать столбцы «ds» и «y»:
df.columns = ['дс', 'у']
Если вы использовали API для извлечения данных, нам нужно преобразовать список в фрейм данных и назвать столбцы по мере необходимости:
из pandas импортировать DataFrame df_sessions = DataFrame (list_values, столбцы = ['ds', 'y'])
Обучение модели
Когда у нас есть Dataframe с требуемым форматом, мы можем очень легко определить и обучить нашу модель с помощью:
импортировать fbprophet из fbprophet импортировать пророка модель = Пророк() model.fit(df_sessions)
Делаем наши прогнозы
Наконец, после обучения нашей модели мы можем начать прогнозировать! Чтобы продолжить прогнозы, нам сначала нужно создать список с диапазоном времени, который мы хотели бы предсказать, и настроить формат даты и времени:
из pandas импортировать to_datetime прогноз_дней = [] для x в диапазоне (1, 28): дата = "2021-02-" + строка (х) прогноз_дней.добавление([дата]) прогноз_дней = кадр данных (прогноз_дней) прогноз_дней.columns = ['ds'] прогноз_дней['дс']= to_datetime(прогноз_дней['дс'])
В этом примере я использую цикл, который создаст фрейм данных, содержащий все дни февраля. И теперь это просто вопрос использования модели, которая была обучена ранее:
прогноз = model.predict (прогноз_дней)
Мы можем нарисовать график, выделяющий прогнозируемый период времени:
из matplotlib импортировать pyplot model.plot(прогноз) pyplot.show ()
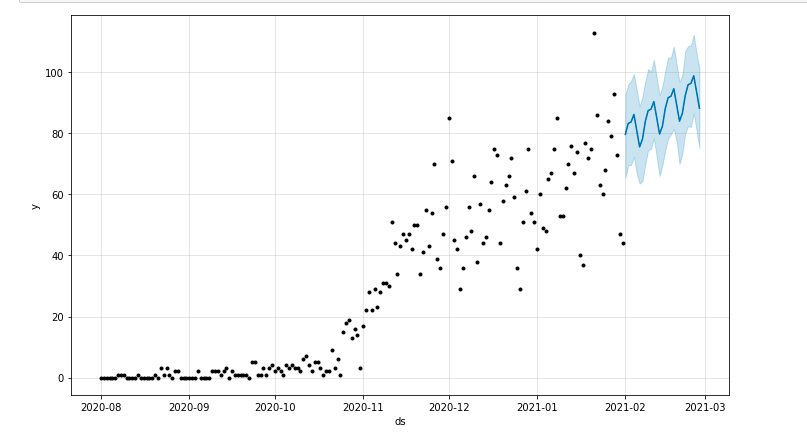
Оценка модели
Наконец, мы можем оценить, насколько точна наша модель, исключив несколько дней из данных, которые используются для обучения модели, прогнозируя сеансы для этих дней и вычисляя среднюю абсолютную ошибку.
В качестве примера я собираюсь удалить из исходного фрейма данных последние 12 дней января, прогнозируя сеансы на каждый день и сравнивая фактический трафик с прогнозируемым.
Сначала мы удаляем из исходного фрейма данных 12 последних дней с pop и создаем новый фрейм данных, который будет включать только те 12 дней, которые будут использоваться для прогноза:
поезд = df_sessions.drop(df_sessions.index[-12:]) будущее = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Теперь мы обучаем модель, делаем прогноз и вычисляем среднюю абсолютную ошибку. В конце концов, мы можем нарисовать график, который покажет разницу между фактическими прогнозируемыми значениями и реальными. Это то, что я узнал из этой статьи, написанной Джейсоном Браунли.
из sklearn.metrics импорта mean_absolute_error
импортировать numpy как np
из массива импорта numpy
#Обучаем модель
модель = Пророк()
model.fit(поезд)
# Адаптируйте фрейм данных, который используется для дней прогноза, к требуемому формату Prophet.
будущее = список (будущее)
будущее = DataFrame (будущее)
будущее = будущее. переименовать (столбцы = {0: 'ds'})
# Делаем прогноз
прогноз = модель.предсказать(будущее)
# Мы рассчитываем MAE между фактическими значениями и прогнозируемыми значениями
y_true = df_sessions['y'][-12:].values
y_pred = прогноз['yhat'].значения
mae = mean_absolute_error(y_true, y_pred)
# Мы рисуем окончательный вывод для визуального понимания
y_true = np.stack(y_true).astype(с плавающей запятой)
pyplot.plot (y_true, метка = 'Фактическое')
pyplot.plot (y_pred, метка = 'Предсказанный')
pyplot.легенда()
pyplot.show ()
печать (маэ) 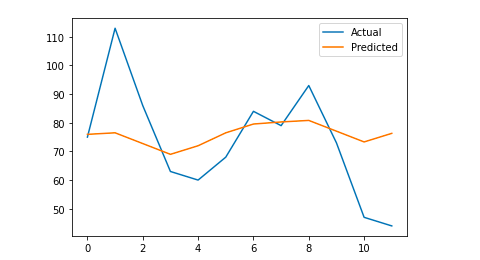
Моя средняя абсолютная ошибка равна 13, что означает, что моя прогнозируемая модель отводит каждому дню на 13 сессий больше, чем реальное, что кажется приемлемой ошибкой.
Это все люди! Я надеюсь, что вы нашли эту статью интересной, и вы можете начать делать свои SEO-прогнозы, чтобы установить цели.
Идем дальше: OnCrawl Labs
Если вам понравилось прогнозировать трафик с помощью этого метода, вас также заинтересует OnCrawl Labs, лаборатория OnCrawl по обработке данных и машинному обучению, которая предлагает предварительно закодированные проекты для ваших рабочих процессов SEO.
В SEO-прогнозировании OnCrawl Labs поможет вам уточнить ваши SEO-прогнозы:
- Получите лучшее представление о теориях и процессах, лежащих в основе алгоритма Facebook Prophet.
- Проанализируйте сегмент трафика, например, трафик только по ключевым словам с длинным хвостом или только по брендированным ключевым словам…
- Следуйте пошаговому процессу, чтобы настроить исторические события, регулируя их влияние и вероятность их повторения.