
Как извлечь соответствующий текстовый контент из HTML-страницы?
Опубликовано: 2021-10-13Контекст
В отделе исследований и разработок Oncrawl мы все чаще стремимся повысить ценность семантического содержания ваших веб-страниц. Используя модели машинного обучения для обработки естественного языка (NLP), можно выполнять задачи с реальной добавленной стоимостью для SEO.
К этим задачам относятся такие действия, как:
- Тонкая настройка содержания ваших страниц
- Создание автоматических сводок
- Добавление новых тегов к вашим статьям или исправление существующих
- Оптимизация контента в соответствии с вашими данными Google Search Console
- и т.п.
Первым шагом в этом приключении является извлечение текстового содержимого веб-страниц, которое будут использовать эти модели машинного обучения. Когда мы говорим о веб-страницах, это включает в себя HTML, JavaScript, меню, мультимедиа, верхний и нижний колонтитулы… Автоматическое и правильное извлечение содержимого — непростая задача. В этой статье я предлагаю изучить проблему и обсудить некоторые инструменты и рекомендации для решения этой задачи.
Проблема
Извлечение текстового содержимого с веб-страницы может показаться простым. Например, несколько строк Python, пара регулярных выражений (regexp), библиотека синтаксического анализа, такая как BeautifulSoup4, и все готово.
Если вы на несколько минут проигнорируете тот факт, что все больше и больше сайтов используют механизмы рендеринга JavaScript, такие как Vue.js или React, синтаксический анализ HTML не очень сложен. Если вы хотите обозначить эту проблему, используя преимущества нашего сканера JS при сканировании, я предлагаю вам прочитать «Как сканировать сайт с помощью JavaScript?».
Однако мы хотим извлечь текст, который имеет смысл и является максимально информативным. Например, когда вы читаете статью о последнем посмертном альбоме Джона Колтрейна, вы игнорируете меню, нижний колонтитул… и, очевидно, не просматриваете весь HTML-контент. Эти HTML-элементы, которые появляются почти на всех ваших страницах, называются шаблонными. Мы хотим избавиться от него и оставить только часть: текст, несущий релевантную информацию.
Поэтому только этот текст мы хотим передать моделям машинного обучения для обработки. Поэтому важно, чтобы экстракция была максимально качественной.
Решения
В целом хотелось бы избавиться от всего, что «висит» вокруг основного текста: меню и прочих сайдбаров, элементов контактов, ссылок в футере и т. д. Для этого есть несколько способов. В основном нас интересуют проекты с открытым исходным кодом на Python или JavaScript.
простотекст
jusText — это предложенная реализация на Python из докторской диссертации: «Удаление шаблонов и дублированного контента из веб-корпораций». Метод позволяет классифицировать текстовые блоки из HTML как «хорошие», «плохие», «слишком короткие» в соответствии с различными эвристиками. Эти эвристики в основном основаны на количестве слов, соотношении текста и кода, наличии или отсутствии ссылок и т. д. Подробнее об алгоритме можно прочитать в документации.
трафилатура
trafilatura, также созданная на Python, предлагает эвристику как для типа элемента HTML, так и для его содержимого, например, длины текста, положения/глубины элемента в HTML или количества слов. trafilatura также использует jusText для выполнения некоторой обработки.
удобочитаемость
Вы когда-нибудь замечали кнопку в адресной строке Firefox? Это режим чтения: он позволяет удалить шаблоны со страниц HTML, чтобы сохранить только основное текстовое содержимое. Довольно практично использовать для новостных сайтов. Код, стоящий за этой функцией, написан на JavaScript и Mozilla называет его удобочитаемостью. Он основан на работе, инициированной лабораторией Arc90.
Вот пример того, как отобразить эту функцию для статьи с веб-сайта France Musique. 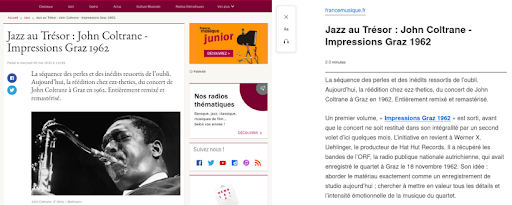
Слева — выдержка из оригинальной статьи. Справа это рендеринг функции Reader View в Firefox.
Другие
Наши исследования инструментов извлечения содержимого HTML также привели нас к рассмотрению других инструментов:
- газета: библиотека извлечения контента, предназначенная скорее для новостных сайтов (Python). Эта библиотека использовалась для извлечения контента из корпуса OpenWebText2.
- бойлерпи3 — это порт библиотеки бойлерпайп на Python.
- Библиотека Python dragnet, также вдохновленная котельной трубой.
Данные при сканировании³
 Учить больше
Учить большеОценка и рекомендации
Прежде чем оценивать и сравнивать различные инструменты, мы хотели узнать, использует ли сообщество НЛП некоторые из этих инструментов для подготовки своего корпуса (большого набора документов). Например, набор данных под названием The Pile, используемый для обучения GPT-Neo, содержит более 800 ГБ текстов на английском языке из Википедии, Openwebtext2, Github, CommonCrawl и т. д. Как и BERT, GPT-Neo — это языковая модель, в которой используются преобразователи типов. Он предлагает реализацию с открытым исходным кодом, аналогичную архитектуре GPT-3.

В статье «The Pile: 800GB Dataset of Diverse Text for Language Modeling» упоминается использование jusText для большей части их корпуса из CommonCrawl. Эта группа исследователей также планировала провести тест различных инструментов извлечения. К сожалению, они не смогли выполнить запланированную работу из-за нехватки ресурсов. В своих выводах следует отметить, что:
- jusText иногда удалял слишком много контента, но все равно обеспечивал хорошее качество. Учитывая количество данных, которые у них были, это не было для них проблемой.
- trafilatura лучше сохраняла структуру HTML-страницы, но содержала слишком много шаблонного кода.
Для нашего метода оценки мы взяли около тридцати веб-страниц. Мы извлекли основной контент «вручную». Затем мы сравнили извлечение текста различными инструментами с этим так называемым «эталонным» контентом. В качестве метрики мы использовали показатель ROUGE, который в основном используется для оценки автоматических текстовых резюме.
Мы также сравнили эти инструменты с «домашним» инструментом, основанным на правилах парсинга HTML. Оказывается, trafilatura, jusText и наш самодельный инструмент работают лучше, чем большинство других инструментов для этого показателя.
Вот таблица средних значений и стандартных отклонений оценки ROUGE:
| Инструменты | Иметь в виду | стандарт |
|---|---|---|
| трафилатура | 0,783 | 0,28 |
| при сканировании | 0,779 | 0,28 |
| простотекст | 0,735 | 0,33 |
| котёл3 | 0,698 | 0,36 |
| удобочитаемость | 0,681 | 0,34 |
| невод | 0,672 | 0,37 |
Принимая во внимание значения стандартных отклонений, обратите внимание, что качество экстракции может сильно различаться. Способ реализации HTML, согласованность тегов и правильное использование языка могут привести к большим различиям в результатах извлечения.
Три инструмента, которые работают лучше всего, — это trafilatura, наш внутренний инструмент, названный по случаю «oncrawl», и jusText. Поскольку jusText используется trafilatura в качестве запасного варианта, мы решили использовать trafilatura в качестве первого выбора. Однако, когда последний терпит неудачу и извлекает ноль слов, мы используем свои собственные правила.
Обратите внимание, что код trafilatura также предлагает бенчмарк на нескольких сотнях страниц. Он вычисляет показатели точности, показатель f1 и точность на основе наличия или отсутствия определенных элементов в извлеченном содержимом. Выделяются два средства: трафилатура и гусь3. Вы также можете прочитать:
- Выбор правильного инструмента для извлечения контента из Интернета (2020 г.)
- репозиторий Github: тест извлечения статей: библиотеки с открытым исходным кодом и коммерческие сервисы
Выводы
Качество HTML-кода и неоднородность типа страницы затрудняют извлечение качественного контента. Как выяснили исследователи EleutherAI, стоявшие за Pile и GPT-Neo, идеальных инструментов не существует. Существует компромисс между иногда усеченным содержанием и остаточным шумом в тексте, когда не весь шаблон был удален.
Преимущество этих инструментов в том, что они не зависят от контекста. Это означает, что им не нужны никакие данные, кроме HTML-кода страницы, для извлечения содержимого. Используя результаты Oncrawl, мы могли представить гибридный метод, использующий частоту появления определенных блоков HTML на всех страницах сайта, чтобы классифицировать их как шаблонные.
Что касается наборов данных, используемых в тестах, с которыми мы сталкивались в Интернете, они часто представляют собой страницы одного и того же типа: новостные статьи или сообщения в блогах. Они не обязательно включают в себя страховые, туристические агентства, сайты электронной коммерции и т. д., текстовое содержание которых иногда сложнее извлечь.
Что касается нашего эталона и из-за нехватки ресурсов, мы понимаем, что тридцати или около того страниц недостаточно для получения более подробного представления о результатах. В идеале мы хотели бы иметь большее количество различных веб-страниц, чтобы уточнить наши контрольные значения. И мы также хотели бы включить другие инструменты, такие как goose3, html_text или inscriptis.