
Извлечение данных из Google Search Console API для анализа данных в Python
Опубликовано: 2022-03-01Консоль поиска Google (GSC), безусловно, является одним из самых полезных инструментов для SEO-специалистов, поскольку позволяет получить информацию о покрытии индекса и особенно о запросах, по которым вы в настоящее время ранжируетесь. Зная это, многие люди анализируют данные GSC с помощью электронных таблиц, и это нормально, если вы понимаете, что есть гораздо больше возможностей для улучшения с помощью таких инструментов, как языки программирования.
К сожалению, интерфейс GSC довольно ограничен как с точки зрения отображаемых строк (всего 5000), так и доступного периода времени, всего 16 месяцев. Понятно, что это может серьезно ограничить вашу способность получать информацию, и это не подходит для больших веб-сайтов.
Python позволяет легко получать данные GSC и автоматизировать более сложные вычисления, которые потребовали бы гораздо больше усилий в традиционном программном обеспечении для работы с электронными таблицами.
Это решение одной из самых больших проблем в Excel, а именно ограничение количества строк и скорость. В настоящее время у вас есть гораздо больше возможностей для анализа данных, чем раньше, и именно здесь в игру вступает Python.
Вам не нужны какие-либо продвинутые знания в области кодирования, чтобы следовать этому руководству, достаточно понимания некоторых основных концепций и некоторой практики работы с Google Colab.
Начало работы с API Google Search Console
Прежде чем мы начнем, важно настроить API Google Search Console. Процесс довольно прост, все, что вам нужно, это учетная запись Google. Шаги следующие:
- Создайте новый проект на Google Cloud Platform. У вас должна быть учетная запись Google, и я уверен, что она у вас есть. Перейдите в консоль, а затем вы должны найти вверху опцию для создания нового проекта.
- Нажмите на меню слева и выберите «API и сервисы», вы попадете на другой экран.
- В строке поиска вверху найдите «API Google Search Console» и включите его.
- Затем перейдите на вкладку «Учетные данные», вам нужно какое-то разрешение на использование API.
- Настройте экран «согласие», так как это обязательно. Для использования, которое мы собираемся сделать, не имеет значения, будет ли оно публичным или нет.
- Вы можете выбрать «Настольное приложение» в качестве типа приложения.
- Мы будем использовать OAuth 2.0 для этого руководства, вы должны загрузить файл json, и все готово.
На самом деле это самая сложная часть для большинства людей, особенно для тех, кто не привык к API Google. Не волнуйтесь, следующие шаги будут намного проще и менее проблематичными.
Получение данных из Google Search Console API с помощью Python
Я рекомендую вам использовать блокнот, такой как Jupyter Notebook или Google Colab. Последнее лучше, так как вам не нужно беспокоиться о требованиях. Поэтому то, что я собираюсь объяснить, основано на Google Colab.
Прежде чем мы начнем, обновите файл json до Google Colab, указав следующий код:
из файлов импорта google.colab файлы.загрузить()
Затем давайте установим все библиотеки, которые нам понадобятся для нашего анализа, и давайте улучшим визуализацию таблицы с помощью этого фрагмента кода:
%%захватывать #загрузить то, что нужно !pip установить git+https://github.com/joshcarty/google-searchconsole импортировать панд как pd импортировать numpy как np импортировать matplotlib.pyplot как plt из google.colab импортировать data_table !git клон https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip установить umap-learn data_table.enable_dataframe_formatter() # для лучшей визуализации таблицы
Наконец, вы можете загрузить библиотеку searchconsole, которая предлагает самый простой способ сделать это, не полагаясь на длинные функции. Запустите следующий код с аргументами, которые я использую, и убедитесь, что client_config имеет то же имя, что и загруженный файл json.
импортировать поисковую консоль account = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', поток='console')
Вы будете перенаправлены на страницу Google для авторизации приложения, выберите свою учетную запись Google, а затем скопируйте и вставьте полученный код в панель Google Colab.
Мы еще не закончили, вам нужно выбрать свойство, для которого вам понадобятся данные. Вы можете легко проверить свои свойства через account.webproperties, чтобы увидеть, что вам следует выбрать.
property_name = input('Вставьте название вашего веб-сайта, указанное в GSC: ')
webproperty=account[str(property_name)]
Когда вы закончите, вы собираетесь запустить пользовательскую функцию для создания объекта, содержащего наши данные.
def extract_gsc_data (веб-свойство, запуск, остановка, *аргументы):
если веб-свойство не None:
print(f'Извлечение данных для {webproperty}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
вернуть gsc_data
еще:
print('Веб-ресурс не найден, выберите правильный')
возврат Нет
Идея функции состоит в том, чтобы взять свойство, которое вы определили ранее, и временные рамки в виде дат начала и окончания, а также измерения.
Возможность выбора параметров имеет решающее значение для SEO-специалистов, поскольку позволяет вам понять, нужен ли вам определенный уровень детализации. Например, в некоторых случаях вас может не заинтересовать получение измерения даты.
Я предлагаю всегда выбирать запрос и страницу, так как интерфейс Google Search Console может экспортировать их по отдельности, а объединять их каждый раз очень неудобно. Это еще одно преимущество API Search Console.
В нашем случае мы также можем напрямую получить измерение даты, чтобы показать некоторые интересные сценарии, в которых необходимо учитывать время.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'запрос', 'страница', 'дата')
Выберите правильный период времени, учитывая, что для более крупных объектов вам придется ждать много времени. Для этого примера я просто рассматриваю временной интервал в 3 месяца, которого в среднем достаточно, чтобы получить ценную информацию из большинства наборов данных.
Вы можете выбрать даже одну неделю, если вы имеете дело с огромным количеством данных, нам важен процесс.
То, что я покажу вам здесь, основано либо на синтетических данных, либо на модифицированных реальных данных, чтобы их можно было использовать в качестве примеров. Как следствие, то, что вы видите здесь, абсолютно реалистично и может отражать сценарии реального мира.
Очистка данных
Для тех, кто не знает, мы не можем использовать наши данные как есть, есть несколько дополнительных шагов, чтобы убедиться, что мы работаем правильно. Прежде всего, мы должны преобразовать наш объект в фрейм данных Pandas, структуру данных, с которой вы должны быть знакомы, поскольку она является основой анализа данных в Python.
df = pd.DataFrame (данные = ex) дф.голова()
Метод head может показать первые 5 строк вашего набора данных, это очень удобно, чтобы увидеть, как выглядят ваши данные. Мы можем подсчитать, сколько страниц у нас есть, используя простую функцию.
Хороший способ удалить дубликаты — преобразовать объект в набор, поскольку наборы не могут содержать повторяющиеся элементы.
Некоторые фрагменты кода были вдохновлены записной книжкой Гамлета Батисты, а еще один — Масаки Оказавой.
Удаление фирменных терминов
Самое первое, что нужно сделать, это удалить брендированные ключевые слова, мы ищем те запросы, которые не содержат наши брендированные термины. Это довольно просто сделать с пользовательской функцией, и у вас обычно будет набор фирменных терминов.
В демонстрационных целях вам не нужно отфильтровывать их все, но, пожалуйста, сделайте это для реального анализа. Это один из самых важных шагов по очистке данных в SEO, иначе вы рискуете представить вводящие в заблуждение результаты.
domain_name = str(input('Вставьте названия брендов через запятую: ')).replace(',', '|')
импортировать повторно
имя_домена = re.sub(r"\s+", "", имя_домена)
print('Удалите все пробелы, используя RegEx:\n')
df['Фирменный/Небрендовый'] = np.where(
df['query'].str.contains(domain_name), 'Бренд', 'Небрендированный'
)
Мы собираемся добавить новый столбец в наш набор данных, чтобы распознать разницу между двумя классами. Мы можем визуализировать с помощью таблиц или гистограмм, насколько они составляют общее количество запросов.
Я не буду показывать вам гистограмму, так как она очень проста, и я думаю, что таблица лучше подходит для этого случая.
brand_count_df = df['Брендовые/Небрендовые'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Процент'] = brand_count_df['количество']/сумма(brand_count_df['количество'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Вы можете быстро увидеть, каково соотношение между брендовыми и небрендовыми ключевыми словами, чтобы понять, сколько вы собираетесь удалить из своего набора данных. Здесь нет идеального соотношения, хотя вы определенно хотите иметь более высокий процент небрендированных ключевых слов.
Затем мы можем просто удалить все строки, помеченные как фирменные, и перейти к другим шагам.
#выбирать только небрендированные ключевые слова df = df.loc[df['Фирменный/Нефирменный'] == 'Нефирменный']
Заполнение пропущенных значений и другие шаги
Если в вашем наборе данных есть пропущенные значения (или NA на жаргоне), у вас есть несколько вариантов. Наиболее распространенными являются либо удаление их всех, либо заполнение их значением-заполнителем, например 0, или средним значением этого столбца.
Правильного ответа нет, и оба подхода имеют свои плюсы и минусы, а также риски. Для данных Google Search Console мой лучший совет — поставить значение-заполнитель, например 0, чтобы недооценить влияние некоторых показателей.
df.fillna (0, на месте = Истина)
Прежде чем мы перейдем к фактическому анализу данных, нам нужно настроить наши функции, а именно столбцы нашего набора данных. Эта позиция особенно интересна, так как мы хотим использовать ее для некоторых крутых сводных таблиц.
Мы можем округлить позицию до целого числа, что служит нашей цели.
df['position'] = df['position'].round(0).astype('int64')
Вы должны выполнить все остальные шаги очистки, описанные выше, а затем настроить столбец даты.
Мы извлекаем месяцы и годы с помощью панд. Вам не нужно быть таким конкретным, если вы работаете с более короткими временными рамками, это пример, который учитывает полгода.
#преобразовать дату в правильный формат df['дата'] = pd.to_datetime(df['дата']) #извлечь месяцы df['месяц'] = df['дата'].dt.month #извлечь годы df['год'] = df['дата'].dt.year
[Электронная книга] Data SEO: следующее большое приключение
 Читать электронную книгу
Читать электронную книгуИсследовательский анализ данных
Основное преимущество Python заключается в том, что вы можете делать то же самое, что и в Excel, но с гораздо большим количеством опций и проще. Начнем с того, что хорошо известно каждому аналитику: сводные таблицы.
Анализ среднего CTR по группе позиций
Анализ среднего CTR по группе позиций — одно из самых полезных действий, поскольку оно позволяет вам понять общую ситуацию на веб-сайте. Примените пивот, а затем давайте построим его.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table (index = ['position'], values = ['ctr'], aggfunc = ['mean'])
query_analysis.sort_values(by=['position'], по возрастанию=True).head(10)
топор = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Средняя позиция')
ax.set_ylabel('CTR')
ax.set_title('CTR по средней позиции')
ax.grid('включено')
ax.get_legend().удалить()
plt.xticks (вращение = 0)
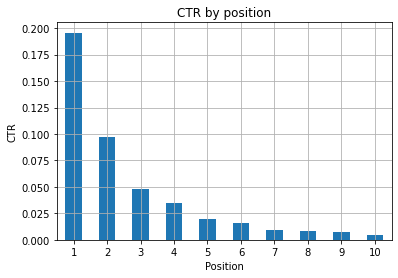
Рисунок 1: Представление CTR по положению для выявления аномалий.
Идеальным сценарием здесь является лучший CTR в левой части графика, так как обычно результаты на позиции 1 должны иметь гораздо более высокий CTR. Однако будьте осторожны, вы можете столкнуться с некоторыми случаями, когда первые 3 позиции имеют более низкий CTR, чем ожидалось, и вам необходимо провести расследование.
Пожалуйста, учитывайте крайние случаи, например те, где позиция 11 лучше, чем быть первой. Как поясняется в документации Google для Search Console, эта метрика не соответствует порядку, который может показаться на первый взгляд.
Более того, добавляется, что эта метрика является средней, так как позиция ссылки каждый раз меняется и добиться 100% точности невозможно.
Иногда ваши страницы имеют высокий рейтинг, но недостаточно убедительны, поэтому вы можете попробовать исправить заголовок. Поскольку это обзор высокого уровня, вы не увидите детальных различий, поэтому ожидайте быстрых действий, если эта проблема имеет большой масштаб.
Также обратите внимание, когда группа страниц с более низкими позициями имеет более высокий средний CTR, чем страницы с более высокими позициями.
По этой причине вы можете расширить свой анализ до позиции 15 или более, чтобы обнаружить странные закономерности.
Количество запросов на позицию и измерение усилий SEO
Увеличение количества запросов, по которым вы ранжируетесь, всегда является хорошим сигналом, но это не обязательно означает более высокий рейтинг в будущем. Подсчет запросов — это процесс подсчета количества запросов, по которым вы ранжируетесь, и это одна из самых важных задач, которые вы можете выполнять с данными GSC.
Сводные таблицы снова очень помогают, и мы можем отображать результаты.
rating_queries = df.pivot_table (index = ['position'], values = ['query'], aggfunc = ['count']) rating_queries.sort_values(by=['position']).head(10)
То, что вы хотите как специалист по SEO, — это иметь большее количество запросов в самой левой части, на верхних позициях. Причина вполне естественна: высокие позиции в среднем повышают CTR, что может привести к тому, что больше людей будут нажимать на вашу страницу.
топор = rating_queries.head(10).plot(kind='bar')
ax.set_ylabel('Количество запросов')
ax.set_xlabel('Позиция')
ax.set_title('Рейтинговое распределение')
ax.grid('включено')
ax.get_legend().удалить()
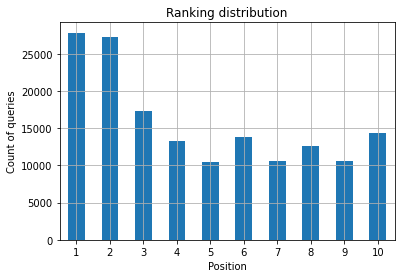
Рисунок 2. Сколько у меня запросов по позициям?
Что вас волнует, так это увеличение количества запросов на верхних позициях с течением времени.
Игра с параметром даты
Посмотрим, как меняются клики на рассматриваемом интервале времени, сначала получим сумму кликов:
clicks_sum = df.groupby('дата')['клики'].sum()
Мы группируем данные по измерению даты и получаем сумму кликов по каждому из них, это своего рода обобщение.
Теперь мы готовы отобразить то, что у нас получилось, код будет довольно длинным, просто чтобы улучшить визуализацию, не пугайтесь этого.

# Сумма кликов за период
%config InlineBackend.figure_format = 'сетчатка'
из рисунка импорта matplotlib.pyplot
рисунок (figsize = (8, 6), dpi = 80)
топор = clicks_sum.plot (цвет = 'красный')
ax.grid('включено')
ax.set_ylabel('Сумма кликов')
ax.set_xlabel('Месяц')
ax.set_title('Как изменялось количество кликов в месяц')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('курсив')
xlab.set_size(10)
ylab.set_style('курсив')
ylab.set_size(10)
ттл = акс.название
ttl.set_weight('жирный')
ax.spines['право'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
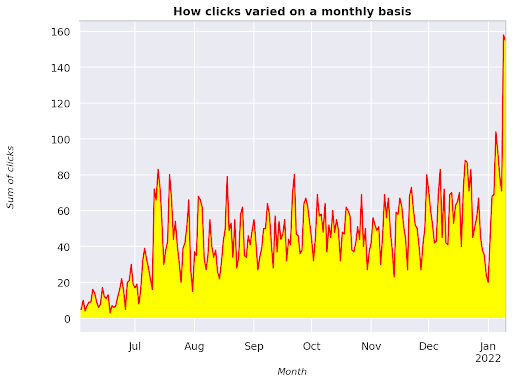
Рисунок 3. График суммы кликов по отношению к переменной месяца
Это пример, начиная с июня 2021 года и заканчивая половиной января 2022 года. Все линии, которые вы видите выше, играют роль в том, чтобы сделать эту визуализацию более красивой, вы можете попробовать поиграть с ней, чтобы увидеть, что произойдет.
Количество запросов на позицию, месячный снимок
Еще одна интересная визуализация, которую мы можем построить в Python, — это тепловая карта, которая даже более наглядна, чем простая гистограмма. Я собираюсь показать вам, как отображать количество запросов с течением времени и в соответствии с их положением.
импортировать Seaborn как sns sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # Загрузить пример набора данных о рейсах и преобразовать его в полную форму df_heat = df_new.pivot_table (индекс = «позиция», столбцы = «месяц», значения = «запрос», aggfunc = 'количество') # Нарисуйте тепловую карту с числовыми значениями в каждой ячейке f, топор = plt.subplots (figsize = (20, 12)) x_axis_labels = ["Сентябрь", "Октябрь", "Ноябрь", "Декабрь"] sns.heatmap(df_heat, annot=True, linewidths=0,5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Месяц', ylabel = 'Позиция', title = 'Как количество запросов на позицию меняется со временем') #rotate Расположите метки, чтобы сделать их более читабельными plt.yticks (вращение = 0)
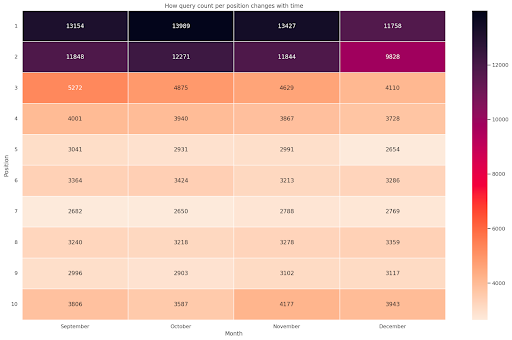
Рис. 4. Тепловая карта, показывающая ход подсчета запросов в зависимости от позиции и месяца.
Это один из моих любимых вариантов, тепловые карты могут быть весьма эффективными для отображения сводных таблиц, как в этом примере. Период охватывает более 4 месяцев, и если вы прочитаете его по горизонтали, вы увидите, как количество запросов меняется с течением времени. Для позиции 10 у вас есть небольшой рост с сентября по декабрь, но для позиции 2 у вас есть резкое снижение, как показано фиолетовым цветом.
В следующем сценарии у вас есть большинство запросов на верхних позициях, что может быть поразительно необычным. Если это произойдет, вы можете вернуться и проанализировать фрейм данных в поисках возможных фирменных терминов, если таковые имеются.
Как видно из кода, создавать сложные графики не так уж сложно, если вы понимаете логику.
Количество запросов должно увеличиваться со временем, если вы делаете «правильные» вещи, и мы можем построить график разницы для двух разных периодов времени. В приведенном мной примере это явно не так, особенно для верхних позиций, где у вас должен быть более высокий CTR.
Знакомство с некоторыми основными концепциями НЛП
Обработка естественного языка (NLP) — это находка для SEO, и вам не нужно быть экспертом, чтобы применять основные алгоритмы. N-граммы — одна из самых мощных, но простых идей, которые могут дать вам представление о данных GSC.
N-граммы — это непрерывные последовательности букв, слогов или слов. Для нашего анализа единицей измерения будут слова. N-грамма называется биграммой, если смежных элементов два (пара), и триграммой, если их три, и так далее. Я предлагаю вам протестировать различные комбинации и максимально увеличить дозу до 5 граммов.
Таким образом, вы сможете определить наиболее распространенные предложения на страницах ваших конкурентов или оценить свои собственные. Поскольку Google может полагаться на индексирование на основе фраз, лучше оптимизировать предложения, а не отдельные ключевые слова, как показано в патентах Google, касающихся этой темы.
Как заявил на странице выше сам Билл Славски, понимание связанных терминов имеет большое значение для оптимизации и для ваших пользователей.
Библиотека nltk очень известна приложениями НЛП и дает нам возможность удалять стоп-слова на заданном языке, например английском. Думайте о них как о шуме, который вы хотите удалить, на самом деле артикли и очень часто встречающиеся слова не добавляют никакой ценности для понимания текста.
импортировать нлтк
nltk.download('стоп-слова')
из nltk.corpus импортировать стоп-слова
стоп-лист = стоп-слова.слова('английский')
из sklearn.feature_extraction.text импортировать CountVectorizer
c_vec = CountVectorizer (stop_words = стоп-лист, ngram_range = (2,3))
# матрица энграмм
ngrams = c_vec.fit_transform (df ['запрос'])
# считать частоту нграмм
count_values = ngrams.toarray().sum(ось=0)
# список нграмм
словарный запас = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) для k,i в vocab.items()], reverse=True)
).rename(columns={0: 'частота', 1: 'биграмма/триграмма'})
df_ngram.head(20).style.background_gradient()
Мы берем столбец запроса и подсчитываем частоту биграмм, чтобы создать фрейм данных, в котором хранятся биграммы и их количество вхождений.
Этот шаг на самом деле очень важен для анализа сайтов конкурентов. Вы можете просто очистить их текст и проверить, какие n-граммы являются наиболее распространенными, настраивая n каждый раз, чтобы увидеть, замечаете ли вы разные шаблоны на страницах с высоким рейтингом.
Если вы задумаетесь об этом на секунду, это обретет гораздо больше смысла, поскольку отдельное ключевое слово ничего не говорит вам о контексте.
Низко висящие плоды
Одна из самых приятных вещей — проверять низко висящие плоды, те страницы, которые вы можете легко улучшить, чтобы увидеть хорошие результаты как можно раньше. Это крайне важно на первых этапах каждого SEO-проекта, чтобы убедить заинтересованных лиц. Поэтому, если есть возможность использовать такие страницы, просто сделайте это!
Нашими критериями для рассмотрения страницы как таковой являются квантили показов и CTR. Другими словами, мы фильтруем строки, которые находятся в верхних 80 % показов, но входят в 20 %, которые получают самый низкий CTR. Эти строки будут иметь худший CTR, чем 80% остальных.
top_impressions = df[df['впечатления'] >= df['впечатления'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('показы', по возрастанию = False))
Теперь у вас есть список со всеми возможностями, отсортированными по показам в порядке убывания.
Вы можете придумать другие критерии, чтобы определить, что является низко висящим плодом, в соответствии с потребностями вашего сайта и его размером.
Для небольших веб-сайтов вы можете подумать о поиске более высоких процентов, тогда как на крупных веб-сайтах вы уже должны получить много информации с критериями, которые я использую.
[Электронная книга] Техническое SEO для нетехнических мыслителей
 Читать электронную книгу
Читать электронную книгуЗнакомство с querycat: классификация и ассоциации
Querycat — это простая, но мощная библиотека, которая включает анализ правил ассоциации для кластеризации ключевых слов и многое другое. Я покажу вам только ассоциации, так как они более ценны в этом типе анализа.
Вы можете узнать больше об этой замечательной библиотеке, заглянув в репозиторий querycat на GitHub.
Краткое введение об изучении ассоциативных правил
Изучение правил ассоциации — это метод поиска правил, определяющих ассоциации и совпадения между наборами элементов. Это немного отличается от другого метода машинного обучения без учителя, так называемой кластеризации.
Конечная цель одна и та же: получить кластеры ключевых слов, чтобы понять, как работает наш веб-сайт по некоторым темам.
Querycat дает вам возможность выбирать между двумя алгоритмами: Apriori и FP-Growth. Мы собираемся выбрать последнее для лучшей производительности, поэтому вы можете игнорировать первое.
FP-Growth — это улучшенная версия Apriori для поиска частых закономерностей в наборах данных. Изучение правил ассоциации также очень полезно для транзакций электронной коммерции, например, вам может быть интересно понять, что люди покупают вместе.
В данном случае все внимание сосредоточено на запросах, но другое приложение, о котором я упоминал, может быть еще одной полезной идеей для данных Google Analytics.
Объяснение этих алгоритмов с точки зрения структуры данных довольно сложно и, на мой взгляд, не обязательно для ваших SEO-задач. Я просто объясню некоторые основные понятия, чтобы понять, что означают параметры.
3 основных элемента 2 алгоритмов:
- Поддержка — выражает популярность предмета или набора предметов. Говоря техническими словами, это количество транзакций, в которых запрос X и запрос Y появляются вместе, деленное на общее количество транзакций.
Кроме того, его можно использовать в качестве порога для удаления редко встречающихся элементов. Очень полезно для повышения статистической значимости и производительности. Установка хорошей минимальной поддержки — это очень хорошо. - Уверенность — вы можете думать об этом как о вероятности совпадения терминов.
- Подъем — соотношение между поддержкой (термин 1 и термин 2) и поддержкой термина 1. Мы можем посмотреть на его значение, чтобы получить представление о взаимосвязи между терминами. Если больше 1, условия коррелированы; если меньше 1, маловероятно, что члены будут иметь связь: если подъем ровно 1 (или близок), значимой связи нет.
Более подробная информация представлена в этой статье о querycat, написанной автором библиотеки.
Теперь мы готовы перейти к практической части.
импортировать запрос
query_cat = querycat.Categorize (df, 'запрос', min_support = 10, alg = 'fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', по возрастанию = False)
#создать группу для фильтрации категорий с менее чем 15 кликами (произвольное число)
группа фильтров = dfgrouped[dfgrouped['sumclicks'] > 15]
группа фильтров
#применить фильтр
df = df.merge(filtergroup, on=['category','category'], как='inner')
В процессе мы отфильтровали менее частые категории, в моем случае я выбрал 15 в качестве эталона. Это просто произвольное число, за ним нет никакого критерия.
Давайте проверим наши категории с помощью следующего фрагмента:
df['категория'].value_counts()
А как насчет 10 самых популярных категорий? Давайте проверим, сколько запросов у нас есть для каждого из них.
df.groupby('категория').sum()['клики'].sort_values(возрастание=ложь).head(10)
Число для выбора является произвольным, обязательно выберите тот, который отфильтровывает хороший процент групп. Одна из возможных идей — получить медиану показов и отбросить самые низкие 50%, при условии, что вы хотите исключить небольшие группы.
Получение кластеров и что делать с выводом
Я рекомендую экспортировать новый фрейм данных, чтобы избежать повторного запуска FP-Growth. Сделайте это, чтобы сэкономить полезное время.
Как только у вас есть кластеры, вы хотите знать клики и показы для каждого из них, чтобы оценить, какие области нуждаются в наибольшем улучшении.
grouped_df = df.groupby('категория')[['клики', 'показы']].agg('сумма')
С помощью некоторых манипуляций с данными мы можем улучшить наши результаты ассоциации и получить клики и показы для каждого кластера.
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#удалить повторяющиеся запросы, а затем отсортировать их по алфавиту
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['категория', 'категория'], как='внутренний')
df_final.head()
Теперь у вас есть файл CSV со всеми кластерами ключевых слов, а также кликами и показами.
#сохраните CSV-файл и загрузите его на локальный компьютер. Если вы используете Safari, рассмотрите возможность перехода на Chrome для загрузки этих файлов, поскольку он может не работать.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
На самом деле, есть лучшие методы для кластеризации, это всего лишь пример того, как вы можете использовать querycat для выполнения нескольких задач для немедленного использования. Основная цель здесь — получить как можно больше информации, особенно для новых веб-сайтов, о которых у вас не так много знаний.
В настоящее время лучшие подходы включают семантику, поэтому, если вы хотите сосредоточиться на кластеризации, я предлагаю вам рассмотреть возможность изучения графов или вложений.
Тем не менее, это дополнительные темы, если вы новичок, и вы можете просто попробовать некоторые готовые приложения Streamlit, доступные в Интернете.
Данные при сканировании³
 Учить больше
Учить большеЗаключение и что дальше
Python может оказать большую помощь в анализе вашего веб-сайта и может помочь вам объединить очистку данных, визуализацию и анализ в одном месте. Извлечение данных из GSC API определенно необходимо для более сложных задач и является «мягким» введением в автоматизацию данных.
Хотя с помощью Python можно выполнять множество более сложных расчетов, я рекомендую проверить, что имеет смысл с точки зрения ценности SEO.
Например, количество запросов в целом гораздо важнее в долгосрочной перспективе, поскольку вы хотите, чтобы ваш веб-сайт рассматривался для большего количества запросов.
Использование блокнотов очень помогает для упаковки кода комментариями, и это основная причина, по которой я предлагаю вам привыкнуть к Google Colab.
Это только начало того, что может предложить вам анализ данных, поскольку лучшие идеи возникают при объединении разных наборов данных.
Консоль поиска Google сама по себе является мощным инструментом, и она абсолютно бесплатна, количество практической информации, которую вы можете получить из нее, практически неограничено в хороших руках.