
Статистическая значимость A/B-тестирования: как и когда завершать тестирование
Опубликовано: 2020-05-22
В нашем недавнем анализе 28 304 экспериментов, проведенных клиентами Convert, мы обнаружили, что только 20% экспериментов достигают уровня статистической значимости 95%. Econsultancy обнаружила аналогичную тенденцию в своем отчете об оптимизации за 2018 год. Две трети респондентов видят «явного и статистически значимого победителя» только в 30% или менее своих экспериментов.
Таким образом, большинство экспериментов (70-80%) либо безрезультатны, либо прекращены досрочно.
Из них те, которые были остановлены раньше, представляют собой любопытный случай, поскольку оптимизаторы откликаются на призыв прекратить эксперименты, когда они сочтут это целесообразным. Они делают это, когда могут «увидеть» явного победителя (или проигравшего) или явно незначительное испытание. Обычно у них также есть некоторые данные, подтверждающие это.
Это может показаться не таким уж удивительным, учитывая, что 50% оптимизаторов не имеют стандартной «точки остановки» для своих экспериментов. Для большинства это необходимо из-за необходимости поддерживать определенную скорость тестирования (XXX тестов в месяц) и гонки за доминирование в конкурентной борьбе.
Кроме того, существует вероятность того, что негативный эксперимент повредит доходам. Наше собственное исследование показало, что неудачные эксперименты в среднем могут привести к снижению коэффициента конверсии на 26% !
В общем, преждевременное прекращение экспериментов по-прежнему рискованно…
…потому что остается вероятность того, что если бы эксперимент продлился так, как предполагалось, при правильном размере выборки, его результат мог бы быть другим.
Так как же команды, которые рано заканчивают эксперименты, узнают, когда их пора заканчивать? Для большинства ответ заключается в разработке правил остановки, которые ускоряют принятие решений без ущерба для его качества.
Отказ от традиционных правил остановки
Для веб-экспериментов стандартным является значение p, равное 0,05. Эта 5-процентная устойчивость к ошибкам или 95-процентный уровень статистической значимости помогает оптимизаторам поддерживать целостность своих тестов. Они могут гарантировать, что результаты являются реальными результатами, а не случайностями.
В традиционных статистических моделях для тестирования с фиксированным горизонтом — когда тестовые данные оцениваются только один раз в фиксированное время или при определенном количестве вовлеченных пользователей — вы примете результат как значимый, если у вас есть p-значение ниже 0,05. На этом этапе вы можете отвергнуть нулевую гипотезу о том, что ваш контроль и лечение одинаковы и что наблюдаемые результаты не случайны.
В отличие от статистических моделей, которые дают вам возможность оценивать данные по мере их сбора, такие модели тестирования запрещают вам просматривать данные вашего эксперимента во время его выполнения. Эта практика, также известная как просмотр, не рекомендуется в таких моделях, потому что значение p колеблется почти ежедневно. Вы увидите, что эксперимент будет значимым в один день, а на следующий день его p-значение поднимется до уровня, когда он уже не будет значимым.
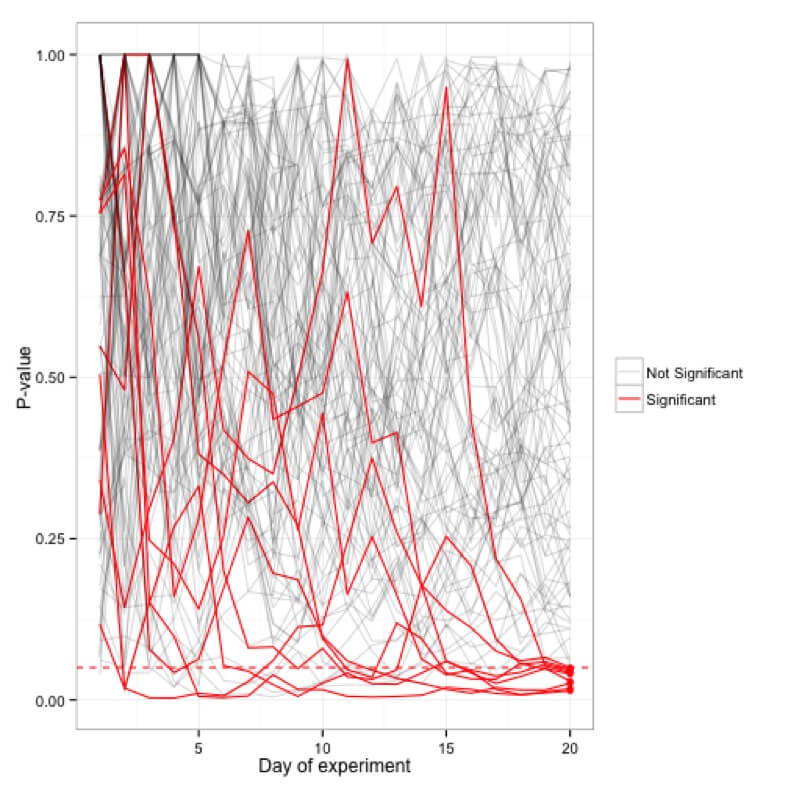
Моделирование p-значений, построенных для ста (20-дневных) экспериментов; только 5 экспериментов фактически оказываются значимыми на 20-дневной отметке, в то время как многие иногда достигают порога <0,05 в промежуточный период.
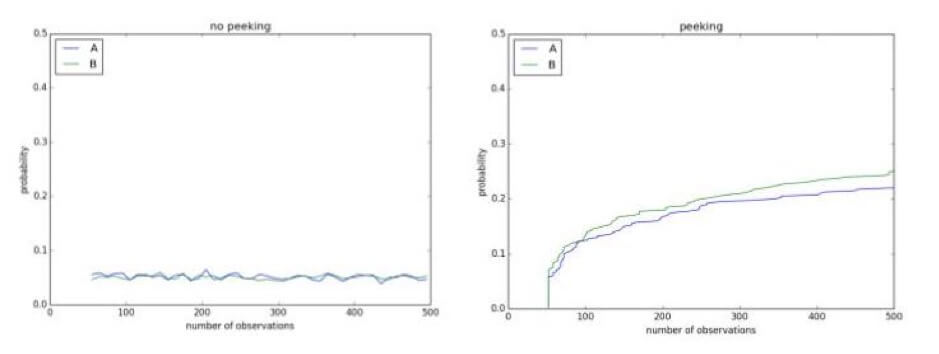
Просмотр ваших экспериментов в промежутке может показать результаты, которых не существует. Например, ниже у вас есть тест A/A с уровнем значимости 0,1. Поскольку это тест А/А, нет никакой разницы между контролем и лечением. Однако после 500 наблюдений в ходе продолжающегося эксперимента существует более 50% вероятности сделать вывод, что они разные и что нулевая гипотеза может быть отвергнута:
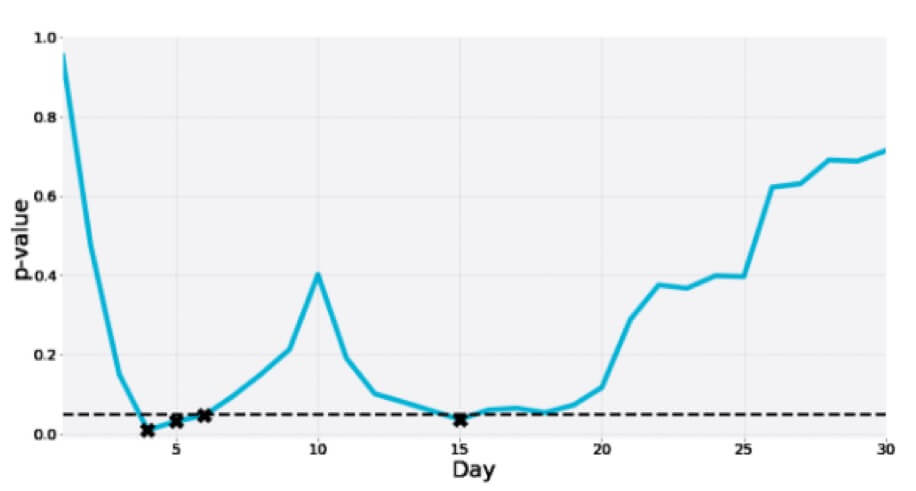
Вот еще один 30-дневный A/A-тест, в котором p-значение несколько раз падает в зону значимости только для того, чтобы, наконец, стать намного больше, чем отсечение:
Правильное сообщение p-значения из эксперимента с фиксированным горизонтом означает, что вам необходимо предварительно зафиксировать фиксированный размер выборки или продолжительность теста. Некоторые команды также добавляют определенное количество конверсий к критериям остановки этого эксперимента и предполагаемой продолжительности.
Однако проблема здесь в том, что для большинства веб-сайтов сложно получить достаточно тестового трафика для каждого эксперимента, чтобы оптимально прекратить использование этой стандартной практики.
Вот где помогает использование методов последовательного тестирования, которые поддерживают необязательные правила остановки.
Переход к гибким правилам остановки, которые позволяют быстрее принимать решения
Методы последовательного тестирования позволяют использовать данные ваших экспериментов по мере их появления и использовать собственные модели статистической значимости для более раннего выявления победителей с гибкими правилами остановки.
Команды оптимизации на самом высоком уровне зрелости CRO часто разрабатывают свои собственные статистические методологии для поддержки такого тестирования. Некоторые инструменты A/B-тестирования также запрограммированы на это и могут подсказать, кажется ли версия выигрышной. А некоторые дают вам полный контроль над тем, как вы хотите рассчитать статистическую значимость, с вашими пользовательскими значениями и многим другим. Таким образом, вы можете подсмотреть и определить победителя даже в продолжающемся эксперименте.

Георгий Георгиев, статистик, автор и инструктор популярного курса CXL по статистике A/B-тестирования, выступает за такие последовательные методы тестирования, которые обеспечивают гибкость в количестве и времени промежуточных анализов:
« Последовательное тестирование позволяет максимизировать прибыль за счет раннего развертывания выигрышного варианта, а также как можно раньше прекращать тесты, вероятность получения которых невелика. Последнее минимизирует потери из-за худших вариантов и ускоряет тестирование, когда варианты просто вряд ли превзойдут контроль. Во всех случаях сохраняется статистическая строгость. ”
Георгиев даже работал над калькулятором, который помогает командам отказаться от моделей тестирования с фиксированной выборкой в пользу модели, которая может определить победителя, пока эксперимент еще продолжается. Его модель учитывает множество статистических данных и помогает вам вызывать тесты примерно на 20-80% быстрее, чем стандартные расчеты статистической значимости, без ущерба для качества.
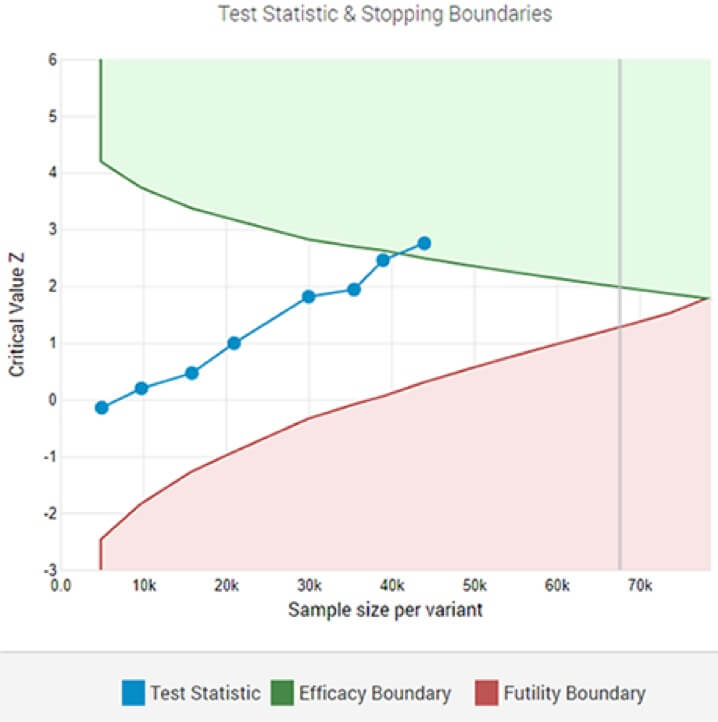
Адаптивный A/B-тест, показывающий статистически значимого победителя при обозначенном пороге значимости после 8-го промежуточного анализа.
Хотя такое тестирование может ускорить процесс принятия решений, необходимо обратить внимание на один важный аспект: фактическое воздействие эксперимента . Прекращение эксперимента в промежуточный период может привести к его переоценке.
Глядя на нескорректированные оценки размера эффекта может быть опасно, предупреждает Георгиев. Чтобы избежать этого, в его модели используются методы корректировки, учитывающие систематическую ошибку, возникшую в результате промежуточного мониторинга. Он объясняет, как их гибкий анализ корректирует оценки «в зависимости от стадии остановки и наблюдаемого значения статистики (перерегулирование, если таковое имеется)». Ниже вы можете увидеть анализ вышеуказанного теста: (Обратите внимание, что предполагаемый рост ниже наблюдаемого, и интервал не сосредоточен вокруг него.)
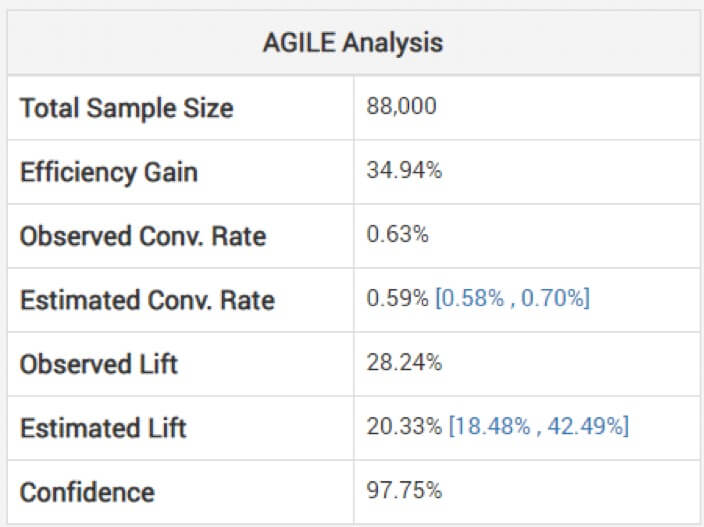
Таким образом, выигрыш может быть не таким большим, как кажется, исходя из вашего более короткого, чем предполагалось, эксперимента.
Проигрыш также необходимо учитывать, потому что вы, возможно, слишком рано ошибочно назвали победителя. Но этот риск существует даже при тестировании с фиксированным горизонтом. Однако внешняя валидность может быть более серьезной проблемой при раннем вызове экспериментов по сравнению с более длительным тестом с фиксированным горизонтом. Но это, как объясняет Георгиев, « простое следствие меньшего размера выборки и, следовательно, продолжительности теста. “
В конце концов… Дело не в победителях или проигравших…
… а о лучших бизнес-решениях, как говорит Крис Стуккио.
Или, как утверждает Том Редман (автор книги «Управление данными: прибыль от вашего самого важного бизнес-актива»), в бизнесе: « Часто есть более важные критерии, чем статистическая значимость. Важный вопрос: « Сохранится ли результат на рынке хотя бы на короткий период времени? ”'
И, скорее всего, так и будет, и не только в течение короткого периода времени, отмечает Георгиев, « если это будет статистически значимо и соображения внешней валидности будут удовлетворительным образом учтены на этапе проектирования».
Вся суть экспериментирования заключается в том, чтобы дать командам возможность принимать более обоснованные решения. Итак, если вы можете передать результаты — на которые указывают данные ваших экспериментов — раньше, то почему бы и нет?
Это может быть небольшой эксперимент с пользовательским интерфейсом, для которого практически невозможно получить «достаточный» размер выборки. Это также может быть эксперимент, в котором ваш соперник сокрушает оригинал, и вы можете просто принять эту ставку!
Как пишет Джефф Безос в своем письме акционерам Amazon, большие эксперименты приносят большие плоды:
« Учитывая 10-процентный шанс на 100-кратный выигрыш, вы должны принимать эту ставку каждый раз. Но вы все равно будете ошибаться девять раз из десяти. Мы все знаем, что если вы будете прыгать через заборы, вы будете много наносить ударов, но вы также будете делать несколько хоум-ранов. Однако разница между бейсболом и бизнесом заключается в том, что бейсбол имеет усеченное распределение результатов. Когда вы замахиваетесь, независимо от того, насколько хорошо вы контактируете с мячом, максимальное количество ударов, которое вы можете сделать, равно четырем. В бизнесе время от времени, когда вы подходите к тарелке, вы можете набрать 1000 пробежек. Это длиннохвостое распределение доходов — вот почему важно быть смелым. Крупные победители платят за столько экспериментов. “
Вызывать эксперименты рано, в значительной степени, все равно, что каждый день подглядывать за результатами и останавливаться в точке, которая гарантирует хорошую ставку.

