
Глубокое обучение против машинного обучения — как отличить?
Опубликовано: 2020-03-10В последние годы машинное обучение, глубокое обучение и искусственный интеллект стали модными словами. В результате вы можете найти их повсюду в маркетинговых материалах и рекламных объявлениях все большего количества компаний.
Но что такое машинное обучение и глубокое обучение? Кроме того, каковы различия между ними? В этой статье я постараюсь ответить на эти вопросы и покажу вам несколько случаев применения глубокого и машинного обучения.
Что такое машинное обучение?
Машинное обучение — это часть компьютерных наук, которая занимается представлением реальных событий или объектов с помощью математических моделей на основе данных. Эти модели строятся с помощью специальных алгоритмов, которые адаптируют общую структуру модели так, чтобы она соответствовала обучающим данным. В зависимости от типа решаемой задачи мы определяем контролируемые и неконтролируемые алгоритмы машинного обучения и машинного обучения.
Контролируемое и неконтролируемое машинное обучение
Контролируемое машинное обучение фокусируется на создании моделей, которые могли бы переносить знания, которые у нас уже есть о данных, в новые данные. Новые данные невидимы для алгоритма построения (обучения) модели на этапе обучения. Мы предоставляем алгоритму данные признаков вместе с соответствующими значениями, которые алгоритм должен научиться извлекать из них (так называемая целевая переменная).
В неконтролируемом машинном обучении мы предоставляем алгоритму только функции. Это позволяет ему самостоятельно определять их структуру и/или зависимости. Не указана четкая целевая переменная. Поначалу может быть трудно понять понятие обучения без учителя, но, взглянув на примеры, представленные на четырех диаграммах ниже, вы должны прояснить эту идею.
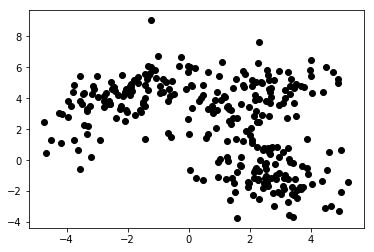
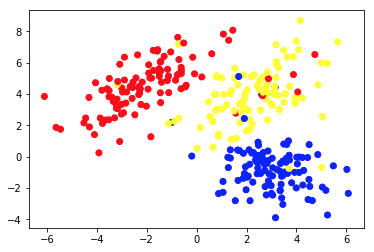

На диаграмме 1а представлены некоторые данные, описанные двумя функциями по осям x и y . Один, отмеченный как 1b, показывает те же данные, окрашенные. Мы использовали алгоритм кластеризации K- средних, чтобы сгруппировать эти точки в 3 кластера и соответствующим образом их раскрасить. Это пример неконтролируемого алгоритма машинного обучения. Алгоритму были даны только признаки, и нужно было вычислить метки (номера кластеров).
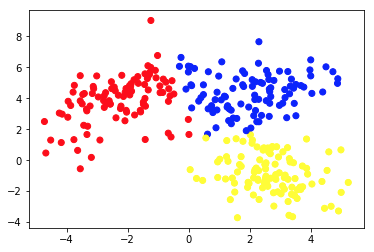
На втором рисунке показана диаграмма 2а, на которой представлен другой набор помеченных (и окрашенных соответственно) данных. Мы знаем, к каким группам принадлежит каждая из точек данных априори . Мы используем алгоритм SVM , чтобы найти 2 прямые линии, которые покажут нам, как разделить точки данных, чтобы лучше всего соответствовать этим группам. Этот раскол не идеален, но это лучшее, что можно сделать с прямыми линиями. Если мы хотим назначить группу новой, немаркированной точке данных, нам просто нужно проверить, где она находится на плоскости. Это пример контролируемого приложения машинного обучения.
Приложения моделей машинного обучения
Стандартные алгоритмы машинного обучения созданы для обработки данных в табличной форме. Это означает, что для их использования нам нужна какая-то таблица. В таких таблицах строки можно рассматривать как экземпляры моделируемого объекта (например, ссуды). При этом столбцы следует рассматривать как признаки (характеристики) данного конкретного экземпляра (например, ежемесячный платеж по кредиту, ежемесячный доход заемщика).

Интересуетесь развитием машинного обучения?
Учить большеТаблица 1 представляет собой очень короткий пример таких данных. Конечно, это не означает, что сами чистые данные должны быть табличными и структурированными. Но если мы хотим применить стандартный алгоритм машинного обучения к какому-то набору данных, нам обычно приходится очищать, смешивать и преобразовывать его в таблицу. В обучении с учителем также есть один специальный столбец, который содержит целевое значение (например, информацию о невозврате кредита).
Алгоритм обучения пытается подогнать под эти данные общую структуру модели. Указанный алгоритм делает это путем настройки параметров модели. В результате получается модель, максимально точно описывающая взаимосвязь между заданными данными и целевой переменной.
Важно, чтобы модель не только хорошо соответствовала заданным обучающим данным, но и была способна обобщать. Обобщение означает, что мы можем использовать модель для определения цели для экземпляров, не используемых во время обучения. Это также важная особенность полезной модели. Построение хорошо обобщающей модели — непростая задача. Это часто требует сложных методов проверки и тщательного тестирования модели.
| идентификатор_кредита | заемщик_возраст | доход_ежемесячно | сумма кредита | ежемесячно оплата | дефолт |
| 1 | 34 | 10 000 | 100 000 | 1200 | 0 |
| 2 | 43 | 5700 | 25000 | 800 | 0 |
| 3 | 25 | 2500 | 24000 | 400 | 0 |
| 4 | 67 | 4600 | 40 000 | 2000 | 1 |
| 5 | 38 | 35000 | 2 500 000 | 10 000 | 0 |
Таблица 1. Данные по кредиту в табличной форме
Люди используют алгоритмы машинного обучения в различных приложениях. В таблице 2 представлены некоторые варианты использования в бизнесе, позволяющие применять алгоритмы и модели неглубокого машинного обучения. Имеются также краткие описания потенциальных данных, целевых переменных и выбранных применимых алгоритмов.
| Вариант использования | Примеры данных | Целевое (моделированное) значение | Используемый алгоритм/модель |
| Рекомендации статей на сайте блога | ID статей, прочитанных пользователями, время, потраченное на каждую из них | Предпочтения пользователей к статьям | Совместная фильтрация с чередованием метода наименьших квадратов |
| Кредитный скоринг ипотеки | Транзакционная и кредитная история, данные о доходах потенциального заемщика | Двоичное значение, показывающее, будет ли кредит погашен полностью или по умолчанию. | СветGBM |
| Прогнозирование оттока премиум-пользователей мобильной игры | Время ежедневной игры, время с первого запуска, прогресс в игре | Двоичное значение, показывающее, собирается ли пользователь отменить подписку в следующем месяце. | XGBoost |
| Обнаружение мошенничества с кредитными картами | Исторические данные о транзакциях по кредитным картам — сумма, место, дата и время | Двоичное значение, показывающее, является ли транзакция по кредитной карте мошеннической. | Случайный лес |
| Сегментация клиентов интернет-магазина | История покупок участников программы лояльности | Номер сегмента, присвоенный каждому клиенту | К-означает |
| Профилактическое обслуживание машинного парка | Данные от датчиков производительности, температуры, влажности и т. д. | Один из следующих классов – «отлично», «для наблюдения», «требует обслуживания». | Древо решений |
Таблица 2. Примеры использования машинного обучения
Глубокое обучение и глубокие нейронные сети
Глубокое обучение является частью машинного обучения, в котором мы используем модели определенного типа, называемые глубокими искусственными нейронными сетями (ИНС). С момента своего появления искусственные нейронные сети прошли обширный процесс эволюции. Это привело к ряду подтипов, некоторые из которых очень сложны. Но чтобы представить их, лучше всего объяснить одну из их основных форм — многослойный персептрон (MPL).
Многослойный персептрон
Проще говоря, MLP имеет форму графа (сети) вершин (также называемых нейронами) и ребер (представленных числами, называемыми весами). Нейроны расположены слоями, а нейроны в последовательных слоях связаны друг с другом. Данные проходят через сеть от входа к выходному слою. Затем данные преобразуются в нейронах и на границах между ними. Как только точка данных проходит через всю сеть, выходной слой содержит предсказанные значения в своих нейронах.
Каждый раз, когда часть обучающих данных проходит через сеть, мы сравниваем прогнозы с соответствующими истинными значениями. Это позволяет нам адаптировать параметры (веса) модели, чтобы делать прогнозы лучше. Мы можем сделать это с помощью алгоритма, называемого обратным распространением. После некоторого количества итераций, если структура модели хорошо разработана специально для решения проблемы машинного обучения.
Получение высокоточной модели
Как только достаточное количество данных пройдет через сеть несколько раз, мы получим высокоточную модель. На практике существует множество преобразований, которые можно применить к нейронам. Это делает ИНС очень гибкими и мощными. Однако сила ИНС имеет свою цену. Обычно чем сложнее структура модели, тем больше данных и времени требуется для ее обучения с высокой точностью.
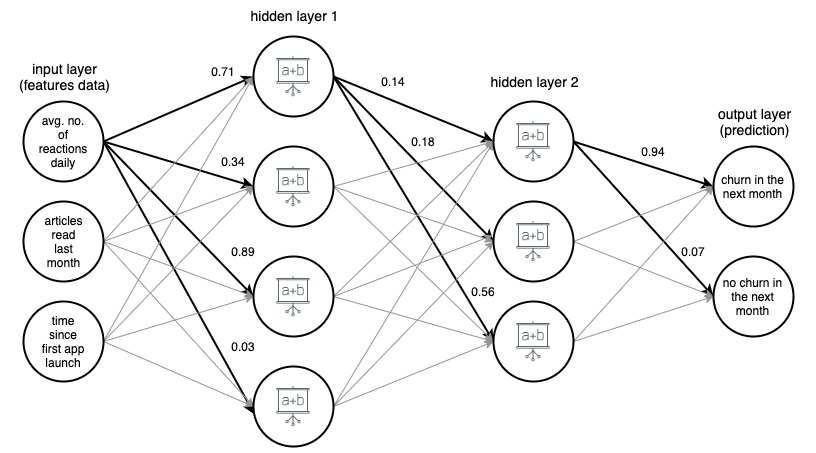
Изображение 1. (draw.io) Структура 4-слойной искусственной нейронной сети, предсказывающей, уйдет ли пользователь новостного приложения в следующем месяце, на основе трех простых функций.
Для ясности веса отмечены только для выбранных (выделенных жирным шрифтом) ребер, но каждое ребро имеет свой собственный вес. Данные передаются от входного слоя к выходному слою, проходя через 2 скрытых слоя посередине. На каждом ребре входное значение умножается на вес ребра, и полученное произведение идет к узлу, на котором заканчивается ребро. Затем в каждом из узлов скрытых слоев поступающие сигналы от ребер суммируются, а затем преобразуются некоторой функцией. Результат этих преобразований затем обрабатывается как вход для следующего уровня.
В выходном слое входящие данные снова суммируются и преобразуются, в результате чего получается два числа — вероятность того, что пользователь уйдет из приложения в следующем месяце, и вероятность того, что этого не произойдет.
Расширенные типы нейронных сетей
В нейронных сетях более продвинутых типов слои имеют гораздо более сложную структуру. Они состоят не только из простых плотных слоев с однооперативными нейронами, известных из MLP, но и из гораздо более сложных многооперационных слоев, таких как сверточные и рекуррентные слои.
Сверточные и рекуррентные слои
Сверточные слои в основном используются в приложениях компьютерного зрения . Они состоят из небольших массивов чисел, которые скользят по пиксельному представлению изображения. Значения пикселей умножаются на эти числа, а затем агрегируются, что дает новое, сжатое представление изображения.
Рекуррентные слои используются для моделирования упорядоченных последовательных данных, таких как временные ряды или текст . Они применяют к входным данным очень сложные многоаргументные преобразования, пытаясь выяснить зависимости между элементами последовательности. Тем не менее, независимо от типа и структуры сети, всегда есть несколько (один или несколько) входных и выходных слоев, а также строго определенные пути и направления, по которым данные проходят через сеть.
В общем, глубокие нейронные сети представляют собой ИНС с несколькими уровнями. На изображениях 1, 2 и 3 ниже показаны архитектуры выбранных глубоких искусственных нейронных сетей. Все они были разработаны и обучены в Google и доступны для общественности. Они дают представление о том, насколько сложны высокоточные глубинные искусственные сети, используемые сегодня.
Эти сети имеют огромные размеры. Например, частично показанный на Рисунке 3 InceptionResNetV2 имеет 572 слоя и в общей сложности более 55 миллионов параметров! Все они были разработаны как модели классификации изображений (они присваивают заданному изображению метку, например, «автомобиль»), и были обучены на изображениях из набора ImageNet, состоящего из более чем 14 миллионов помеченных изображений.
Изображение 2. Структура NASNetMobile (пакет keras)


Изображение 3. Структура XCeption (пакет keras)

Изображение 4. Структура части (около 25%) InceptionResNetV2 (пакет keras)
В последние годы мы наблюдаем большое развитие глубокого обучения и его приложений. Многие «умные» функции наших смартфонов и приложений являются плодом этого прогресса. Хотя идея ИНС не нова, этот недавний бум является результатом выполнения нескольких условий. Прежде всего, мы открыли потенциал вычислений на GPU. Архитектура графических процессоров отлично подходит для параллельных вычислений, что очень полезно для эффективного глубокого обучения.
Более того, развитие облачных вычислений сделало доступ к высокоэффективному оборудованию намного проще, дешевле и стало возможным в гораздо большем масштабе. Наконец, вычислительная мощность новейших мобильных устройств достаточно велика для применения моделей глубокого обучения, что создает огромный рынок потенциальных пользователей функций, управляемых DNN.
Приложения моделей глубокого обучения
Модели глубокого обучения обычно применяются к задачам, которые имеют дело с данными, которые не имеют простой структуры строк и столбцов, таких как классификация изображений или языковой перевод, поскольку они отлично подходят для работы с неструктурированными данными и данными сложной структуры, с которыми справляются эти задачи — изображения, текст. и звук. Существуют проблемы с обработкой данных этих типов и размеров с помощью классических алгоритмов машинного обучения, а создание и применение некоторых глубоких нейронных сетей для решения этих проблем вызвало огромный прогресс в области распознавания изображений, распознавания речи, классификации текста и языкового перевода в мире. Последние несколько лет.
Применение глубокого обучения к этим задачам стало возможным благодаря тому, что DNN принимают многомерные таблицы чисел, называемые тензорами, как на вход, так и на выход, и могут отслеживать пространственные и временные отношения между их элементами. Например, мы можем представить изображение в виде трехмерного тензора, где измерения один и два представляют собой разрешение цифрового изображения (то есть размеры ширины и высоты изображения соответственно), а третье измерение представляет цвет RGB. кодирование каждого из пикселей (поэтому третье измерение имеет размер 3).
Это позволяет нам не только представлять всю информацию об изображении в виде тензора, но и сохранять пространственные отношения между пикселями, что оказывается решающим при применении так называемых сверточных слоев, необходимых для успешной классификации изображений и сетей распознавания.
Гибкость нейронной сети в структурах ввода и вывода помогает и в других задачах, таких как языковой перевод . При работе с текстовыми данными мы передаем в глубокие нейронные сети числовые представления слов, упорядоченные в соответствии с их появлением в тексте. Каждое слово представлено вектором из ста или нескольких сотен чисел, вычисленных (обычно с использованием другой нейронной сети) таким образом, чтобы отношения между векторами, соответствующими разным словам, имитировали отношения самих слов. Эти представления векторного языка, называемые встраиваниями, после обучения могут быть повторно использованы во многих архитектурах и являются центральным строительным блоком языковых моделей нейронных сетей.
Примеры использования моделей глубокого обучения
Таблица 3. содержит примеры применения моделей глубокого обучения к реальным задачам. Как видите, проблемы, решаемые и решаемые с помощью алгоритмов глубокого обучения, намного сложнее, чем задачи, решаемые стандартными методами машинного обучения, подобными представленным в таблице 1.
Тем не менее важно помнить, что многие варианты использования машинного обучения, которые сегодня могут помочь в бизнесе, не требуют таких сложных методов и могут быть решены более эффективно (и с большей точностью) с помощью стандартных моделей. Таблица 3 также дает представление о том, сколько существует различных типов слоев искусственных нейронных сетей и сколько различных полезных архитектур можно построить с их помощью.
| Вариант использования | Данные | Цель/результат модели | Используемый алгоритм/модель |
| Классификация изображений | Картинки | Метка, присвоенная изображению | Сверточная нейронная сеть (CNN) |
| Обнаружение изображений беспилотными автомобилями | Картинки | Метки и ограничивающие рамки вокруг объектов, обозначенных на изображениях | Быстрый R-CNN |
| настроение анализ комментарии в интернет-магазине | Текст онлайн-комментариев | Метка тональности (например, положительная, нейтральная, отрицательная), присвоенная каждому комментарию. | Сеть двунаправленной долговременной памяти (LSTM) |
| Гармонизация мелодии | MIDI-файл с мелодией | MIDI-файл с этой гармонизированной мелодией | Генеративно-состязательная сеть |
| Предсказание следующего слова в онлайн Эл. адрес редактор | Очень большой кусок текста (например, дамп всех статей Википедии на английском языке) | Слово, которое подходит как следующее к тексту, написанному до сих пор | Рекуррентная нейронная сеть (RNN) со слоем внедрения |
| Перевод текста на другой язык | Текст на польском языке | Тот же текст переведен на английский | Кодер - Сеть декодера, построенная на слоях рекуррентной нейронной сети (RNN). |
| Перенос стиля Моне на любой образ | Набор изображений картин Моне и набор других изображений | Изображения изменены, чтобы они выглядели как нарисованные Моне. | Генеративно-состязательная сеть |
Таблица 3. Примеры использования глубокого обучения
Преимущества моделей глубокого обучения
Генеративно-состязательные сети
Одним из самых впечатляющих применений глубоких нейронных сетей стало появление генеративно-состязательных сетей (GAN). Они были представлены в 2014 году Яном Гудфеллоу, и с тех пор его идея была включена во многие инструменты, некоторые из которых дали поразительные результаты.
GAN ответственны за существование приложений, которые заставляют нас выглядеть старше на фотографиях, преобразовывают изображения так, как будто они были нарисованы Ван Гогом, или даже гармонизируют мелодии для нескольких групп инструментов. Во время обучения GAN конкурируют две нейронные сети. Сеть генератора генерирует выходные данные из случайного ввода, в то время как дискриминатор пытается отличить сгенерированные экземпляры от реальных. Во время обучения генератор учится, как успешно «обмануть» дискриминатор, и в конечном итоге может создавать выходные данные, которые выглядят так, как если бы они были реальными.
Мощные глубокие нейронные сети в мобильных приложениях
Важно отметить, что несмотря на то, что обучение глубокой нейронной сети является очень ресурсоемкой вычислительной задачей и может занять много времени, применение обученной сети для выполнения конкретной задачи необязательно, особенно если она применяется к одной или нескольким задачам. несколько случаев сразу. На самом деле, сегодня мы можем запускать мощные глубокие нейронные сети в мобильных приложениях на наших смартфонах.
Существуют даже некоторые сетевые архитектуры, специально разработанные для эффективной работы с мобильными устройствами (например, NASNetMobile, представленная на рисунке 1). Несмотря на то, что они намного меньше по размеру по сравнению с современными сетями, они все же могут обеспечить высокую точность прогнозирования.
Трансферное обучение
Еще одна очень мощная функция искусственных нейронных сетей, позволяющая широко использовать модели глубокого обучения, — это трансферное обучение . Когда у нас есть модель, обученная на некоторых данных (либо созданных нами, либо загруженных из общедоступного репозитория), мы можем использовать их все или часть, чтобы получить модель, которая решает наш конкретный вариант использования. Например, мы могли бы использовать предварительно обученную модель NASNetLarge, обученную на огромном наборе данных ImageNet, которая присваивает метку изображению, вносит небольшие изменения в верхнюю часть его структуры, обучает ее дальше с новым набором помеченных изображений и используйте его, чтобы обозначить некоторые объекты определенного типа (например, вид дерева на основе изображения его листа).
Преимущества трансферного обучения
Трансферное обучение очень полезно, так как обычно обучение глубокой нейронной сети, которая будет выполнять некоторые практические, полезные задачи, требует огромных объемов данных и огромной вычислительной мощности. Часто это может означать миллионы размеченных экземпляров данных и сотни графических процессоров (GPU), работающих в течение нескольких недель.
Не каждый может позволить себе или имеет доступ к таким ресурсам, что может сильно затруднить создание с нуля высокоточного пользовательского решения, скажем, для классификации изображений. К счастью, некоторые предварительно обученные модели (особенно сети для классификации изображений и предварительно обученные матрицы встраивания для языковых моделей) имеют открытый исходный код и доступны бесплатно в легко применимой форме (например, в виде экземпляра модели в Keras, нейронной сети). сетевых API).
Как выбрать и построить правильную модель машинного обучения для вашего приложения
Если вы хотите применить машинное обучение для решения бизнес-задачи, вам, вероятно, не нужно сразу выбирать тип модели. Обычно есть несколько подходов, которые можно протестировать. Часто возникает соблазн начать сначала с самых сложных моделей, но стоит начинать с простых и постепенно увеличивать сложность применяемых моделей. Более простые модели обычно дешевле с точки зрения настройки, времени вычислений и ресурсов. Более того, их результаты являются отличным ориентиром для оценки более продвинутых подходов.
Наличие таких тестов может помочь специалистам по данным оценить, является ли направление, в котором они развивают свои модели, правильным. Еще одним преимуществом является возможность повторного использования некоторых ранее построенных моделей и их слияния с более новыми, создавая так называемую ансамблевую модель. Смешивание моделей разных типов часто дает более высокие показатели производительности, чем каждая из объединенных моделей по отдельности. Кроме того, проверьте, есть ли какие-либо предварительно обученные модели, которые можно использовать и адаптировать к вашему бизнес-кейсу с помощью трансферного обучения.
Больше практических советов
Прежде всего, какую бы модель вы ни использовали, убедитесь, что данные обрабатываются правильно. Не забывайте о правиле «мусор на входе – мусор на выходе». Если обучающие данные, предоставленные модели, имеют низкое качество или не были должным образом помечены и очищены, весьма вероятно, что результирующая модель также будет работать плохо. Также убедитесь, что модель — независимо от ее сложности — была тщательно проверена на этапе моделирования и в конце проверена, хорошо ли она обобщает невидимые данные.
С практической точки зрения убедитесь, что созданное решение может быть реализовано в рабочей среде на доступной инфраструктуре. И если ваш бизнес может собрать больше данных, которые можно использовать для улучшения вашей модели в будущем, следует подготовить конвейер переобучения, чтобы обеспечить ее легкое обновление. Такой конвейер можно даже настроить для автоматического переобучения модели с заданной периодичностью.
Последние мысли
Не забывайте отслеживать производительность и удобство использования модели после ее развертывания в рабочей среде, поскольку бизнес-среда очень динамична. Некоторые отношения в ваших данных могут меняться со временем, и могут возникать новые явления. Следовательно, они могут изменить эффективность вашей модели, и с ними следует обращаться должным образом. Кроме того, могут быть изобретены новые мощные типы моделей. С одной стороны, они могут сделать ваше решение относительно слабым, а с другой — дать вам возможность еще больше улучшить свой бизнес и воспользоваться преимуществами новейших технологий.
Более того, модели машинного обучения и глубокого обучения могут помочь вам создать мощные инструменты для вашего бизнеса и приложений и предоставить вашим клиентам исключительный опыт . Хотя создание этих «умных» функций требует значительных усилий, потенциальные выгоды того стоят. Просто убедитесь, что вы и ваша команда по науке о данных пробуете подходящие модели и следуете передовым методам, и вы будете на правильном пути, чтобы расширить возможности своего бизнеса и приложений с помощью передовых решений машинного обучения.
Источники:
- https://en.wikipedia.org/wiki/Неконтролируемое_обучение
- https://keras.io/
- https://developer.nvidia.com/глубокое обучение
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf