
Что такое кривая CTR и как ее рассчитать с помощью Python?
Опубликовано: 2022-03-22Кривая CTR, или, другими словами, органический рейтинг кликов на основе позиции, представляет собой данные, которые показывают вам, сколько синих ссылок на странице результатов поисковой системы (SERP) получают CTR в зависимости от их позиции. Например, чаще всего первая синяя ссылка в поисковой выдаче получает наибольший CTR.
В конце этого руководства вы сможете рассчитать кривую CTR вашего сайта на основе его каталогов или рассчитать органический CTR на основе запросов CTR. Результатом моего кода Python является информативная диаграмма с прямоугольниками и гистограммами, описывающая кривую CTR сайта.
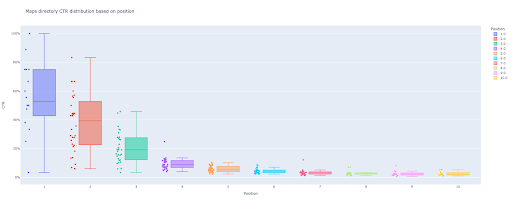
Если вы новичок и не знаете определение CTR, я объясню его подробнее в следующем разделе.
Что такое органический CTR или органический рейтинг кликов?
CTR получается из разделения органических кликов на показы. Например, если 100 человек ищут «яблоко» и 30 человек нажимают на первый результат, CTR первого результата составляет 30/100 * 100 = 30%.
Это означает, что из каждых 100 поисковых запросов вы получаете 30% из них. Важно помнить, что показы в Google Search Console (GSC) не основаны на появлении ссылки на ваш сайт в окне просмотра поисковика. Если результат появляется в поисковой выдаче, вы получаете один показ для каждого из поисков.
Для чего используется кривая CTR?
Одной из важных тем в SEO является прогнозирование органического трафика. Чтобы улучшить рейтинг по некоторому набору ключевых слов, нам нужно выделить тысячи и тысячи долларов, чтобы получить больше акций. Но вопрос на маркетинговом уровне компании часто звучит так: «Выгодно ли нам выделять этот бюджет?».
Кроме того, помимо темы выделения бюджета на SEO-проекты, нам необходимо получить оценку увеличения или уменьшения нашего органического трафика в будущем. Например, если мы видим, что один из наших конкурентов изо всех сил пытается заменить нас на нашей позиции в поисковой выдаче, сколько нам это будет стоить?
В этой ситуации или во многих других сценариях нам нужна кривая CTR нашего сайта.
Почему бы нам не использовать исследования кривых CTR и не использовать наши данные?
Проще говоря, нет другого веб-сайта, который имеет характеристики вашего сайта в поисковой выдаче.
Существует много исследований кривых CTR в разных отраслях и различных функциях SERP, но когда у вас есть данные, почему бы вашим сайтам не рассчитывать CTR вместо того, чтобы полагаться на сторонние источники?
Давайте начнем делать это.
Расчет кривой CTR с помощью Python: начало работы
Прежде чем мы углубимся в процесс расчета рейтинга кликов Google на основе позиции, вам необходимо знать базовый синтаксис Python и иметь общее представление о распространенных библиотеках Python, таких как Pandas. Это поможет вам лучше понять код и настроить его по-своему.
Кроме того, для этого процесса я предпочитаю использовать блокнот Jupyter.
Для расчета органического CTR на основе позиции нам нужно использовать эти библиотеки Python:
- Панды
- сюжетно
- Калейдо
Кроме того, мы будем использовать следующие стандартные библиотеки Python:
- Операционные системы
- json
Как я уже сказал, мы рассмотрим два разных способа расчета кривой CTR. Некоторые шаги одинаковы в обоих методах: импорт пакетов Python, создание папки для выходных изображений графиков и установка размеров выходных графиков.
# Импорт необходимых библиотек для нашего процесса импорт ОС импортировать json импортировать панд как pd импортировать plotly.express как px импортировать plotly.io как pio импорт калейдо
Здесь мы создаем выходную папку для сохранения наших сюжетных изображений.
# Создание папки вывода изображений сюжета
если не os.path.exists('./output plot images'):
os.mkdir('./выходные изображения графика')
Вы можете изменить высоту и ширину выходных изображений графика ниже.
# Установка ширины и высоты выходных изображений графика pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Начнем с первого метода, основанного на CTR запросов.
Первый метод: рассчитать кривую CTR для всего веб-сайта или определенного свойства URL на основе CTR запросов.
Прежде всего, нам нужно получить все наши запросы с их CTR, средней позицией и показом. Я предпочитаю использовать данные за один полный месяц за последний месяц.
Для этого я получаю данные запросов из источника данных о показах сайта GSC в Google Data Studio. Кроме того, вы можете получить эти данные любым удобным для вас способом, например, с помощью GSC API или надстройки Google Sheets «Search Analytics for Sheets». Таким образом, если ваш блог или страницы продуктов имеют выделенный URL-адрес, вы можете использовать их в качестве источника данных в GDS.
1. Получение данных запросов из Google Data Studio (GDS)
Сделать это:
- Создайте отчет и добавьте к нему табличную диаграмму
- Добавьте в отчет источник данных «Впечатления на сайте» вашего сайта.
- Выберите «запрос» для измерения, а также «ctr», «среднее положение» и «впечатление» для метрики.
- Отфильтруйте запросы, содержащие название бренда, создав фильтр (запросы, содержащие бренды, будут иметь более высокий рейтинг кликов, что снизит точность наших данных)
- Щелкните правой кнопкой мыши по таблице и выберите Экспорт.
- Сохраните вывод как CSV
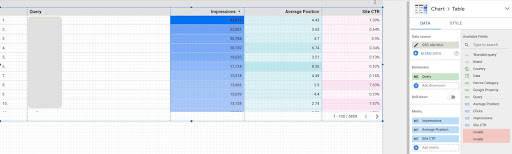
2. Загрузка наших данных и маркировка запросов в зависимости от их положения
Для управления загруженным CSV мы будем использовать Pandas.
Лучшей практикой для структуры папок нашего проекта является наличие папки «данные», в которой мы сохраняем все наши данные.
Здесь, ради плавности в туториале, я этого не делал.
query_df = pd.read_csv('./downloaded_data.csv')
Затем мы помечаем наши запросы в зависимости от их позиции. Я создал цикл for для маркировки позиций с 1 по 10.
Например, если средняя позиция запроса составляет 2,2 или 2,9, он будет помечен как «2». Управляя диапазоном среднего положения, вы можете добиться желаемой точности.
для я в диапазоне (1, 11):
query_df.loc[(query_df['Средняя позиция'] >= i) & (
query_df['Средняя позиция'] < i + 1), 'метка позиции'] = i
Теперь мы сгруппируем запросы в зависимости от их позиции. Это помогает нам лучше манипулировать данными запросов каждой позиции на следующих шагах.
query_grouped_df = query_df.groupby(['метка позиции'])
3. Фильтрация запросов по их данным для расчета кривой CTR
Самый простой способ рассчитать кривую CTR — использовать все данные запросов и произвести расчет. Однако; не забудьте подумать о запросах с одним показом на второй позиции в ваших данных.
Эти запросы, исходя из моего опыта, сильно влияют на конечный результат. Но лучший способ — попробовать самому. В зависимости от набора данных это может измениться.
Прежде чем мы начнем этот шаг, нам нужно создать список для вывода нашей гистограммы и DataFrame для хранения наших управляемых запросов.
# Создание DataFrame для хранения управляемых данных 'query_df' модифицированный_df = pd.DataFrame() # Список для сохранения каждой средней позиции для нашей гистограммы средний_ctr_list = []
Затем мы перебираем группы query_grouped_df и добавляем 20 % самых популярных запросов на основе показов в объект Modified_df modified_df .
Если расчет CTR только на основе первых 20% запросов с наибольшим количеством показов вам не подходит, вы можете изменить его.
Для этого вы можете увеличить или уменьшить его, манипулируя .quantile(q=your_optimal_number, interpolation='lower')] и your_optimal_number должен быть в диапазоне от 0 до 1.
Например, если вы хотите получить первые 30% ваших запросов, your_optimal_num — это разница между 1 и 0,3 (0,7).
для я в диапазоне (1, 11):
# Попытка за исключением случаев, когда в каталоге нет данных для некоторых позиций
пытаться:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['впечатления'] >= query_grouped_df.get_group(i)['впечатления']
.quantile(q=0,8, интерполяция='ниже')]
mean_ctr_list.append(tmp_df['ctr'].mean())
модифицированный_df = модифицированный_df.append (tmp_df, ignore_index = True)
кроме KeyError:
средний_ctr_list.append (0)
# Удаление DataFrame 'tmp_df' для уменьшения использования памяти
удалить [tmp_df]
4. Рисование коробчатой диаграммы
Этого шага мы и ждали. Чтобы рисовать графики, мы можем использовать Matplotlib, seaborn в качестве оболочки для Matplotlib или Plotly.
Лично я считаю, что использование Plotly лучше всего подходит для маркетологов, которые любят исследовать данные.
По сравнению с Mathplotlib, Plotly настолько прост в использовании, что с помощью всего нескольких строк кода вы можете нарисовать красивый сюжет.
№ 1. Коробчатый сюжет
box_fig = px.box(modified_df, x='метка позиции', y='CTR сайта', title='Распределение CTR запросов в зависимости от позиции',
points='all', color='метка позиции', labels={'метка позиции': 'Позиция', 'CTR сайта': 'CTR'})
# Отображение всех десяти тиков оси X
box_fig.update_xaxes(tickvals=[i для i в диапазоне (1, 11)])
# Изменяем формат делений по оси Y на проценты
box_fig.update_yaxes(tickformat=".0%")
# Сохранение графика в директорию 'output plot images'
box_fig.write_image('./выходные графические изображения/Кривая CTR блочной диаграммы запросов.png')
Всего лишь с этими четырьмя строками вы можете получить красивую коробчатую диаграмму и приступить к изучению своих данных.
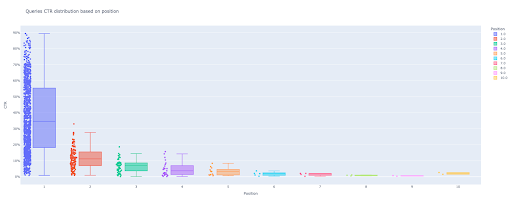
Если вы хотите взаимодействовать с этим столбцом, в новой ячейке запустите:
box_fig.show()
Теперь у вас есть привлекательная интерактивная диаграмма на выходе.
Когда вы наводите курсор на интерактивный график в выходной ячейке, важным числом, которое вас интересует, является «мужчина» каждой позиции.
Это показывает средний CTR для каждой позиции. Из-за средней важности, как вы помните, мы создаем список, содержащий среднее значение каждой позиции. Затем мы перейдем к следующему шагу, чтобы нарисовать гистограмму на основе среднего значения каждой позиции.
5. Рисование гистограммы
Как и блочная диаграмма, рисовать столбчатую диаграмму очень просто. Вы можете изменить title диаграмм, изменив аргумент title функции px.bar() .
№ 2. Барный сюжет
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='Запросы означают распределение CTR на основе позиции',
labels={'x': 'Позиция', 'y': 'CTR'}, text_auto=True)
# Отображение всех десяти тиков оси x
bar_fig.update_xaxes(tickvals=[i для i в диапазоне (1, 11)])
# Изменяем формат делений по оси Y на проценты
bar_fig.update_yaxes(tickformat='.0%')
# Сохранение графика в директорию 'output plot images'
bar_fig.write_image('./выходные графические изображения/Кривая CTR гистограммы запросов.png')
На выходе получаем такой график:
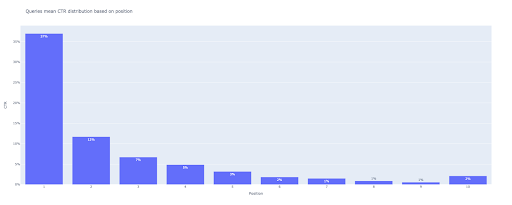
Как и в случае с блочной диаграммой, вы можете взаимодействовать с этим графиком, запустив bar_fig.show() .
Вот и все! С помощью нескольких строк кода мы получаем органический рейтинг кликов в зависимости от позиции с данными наших запросов.
Если у вас есть свойство URL для каждого из ваших поддоменов или каталогов, вы можете получить эти запросы свойств URL и рассчитать кривую CTR для них.
[Пример успеха] Улучшение рейтинга, органических посещений и продаж с помощью анализа лог-файлов
 Читать тематическое исследование
Читать тематическое исследованиеВторой метод: расчет кривой CTR на основе URL-адресов целевых страниц для каждого каталога.
В первом методе мы рассчитывали наш органический CTR на основе CTR запросов, но при этом подходе мы получаем все данные наших целевых страниц, а затем рассчитываем кривую CTR для выбранных нами каталогов.

Я люблю этот путь. Как вы знаете, CTR для наших страниц продуктов сильно отличается от CTR для наших сообщений в блоге или других страниц. Каждый каталог имеет свой CTR в зависимости от позиции.
Более продвинутым способом вы можете классифицировать каждую страницу каталога и получить органический рейтинг кликов Google на основе позиции для набора страниц.
1. Получение данных о целевых страницах
Как и в первом методе, есть несколько способов получить данные Google Search Console (GSC). В этом методе я предпочитаю получать данные целевых страниц из GSC API Explorer по адресу: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Для того, что необходимо в этом подходе, GDS не предоставляет надежных данных о целевых страницах. Кроме того, вы можете использовать надстройку Google Sheets «Search Analytics for Sheets».
Обратите внимание, что Google API Explorer хорошо подходит для сайтов, содержащих менее 25 тыс. страниц данных. Для больших сайтов вы можете получить данные целевых страниц частично и соединить их вместе, написать скрипт Python с циклом for, чтобы получить все ваши данные из GSC, или использовать сторонние инструменты.
Чтобы получить данные из Google API Explorer:
- Перейдите на страницу документации GSC API «Search Analytics: query»: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Используйте обозреватель API, который находится в правой части страницы.
- В поле «siteUrl» вставьте свой URL-адрес свойства, например
https://www.example.com. Кроме того, вы можете вставить свой домен следующим образомsc-domain:example.com - В поле «тело запроса» добавьте
startDateиendDate. Я предпочитаю получать данные за последний месяц. Формат этих значенийYYYY-MM-DD. - Добавьте
dimensionи установите его значения наpage - Создайте «dimensionFilterGroups» и отфильтруйте запросы с названиями вариантов брендов (заменив
brand_variation_namesна ваши названия брендов RegExp) - Добавьте
rawLimitи установите его на 25000 - В конце нажмите кнопку «ВЫПОЛНИТЬ»
Вы также можете скопировать и вставить тело запроса ниже:
{
"дата начала": "01.01.2022",
"endDate": "2022-02-01",
"Габаритные размеры": [
"страница"
],
"группы фильтров измерений": [
{
"фильтры": [
{
"размер": "ЗАПРОС",
"выражение": "brand_variation_names",
"оператор": "EXCLUDING_REGEX"
}
]
}
],
"лимит строк": 25000
}
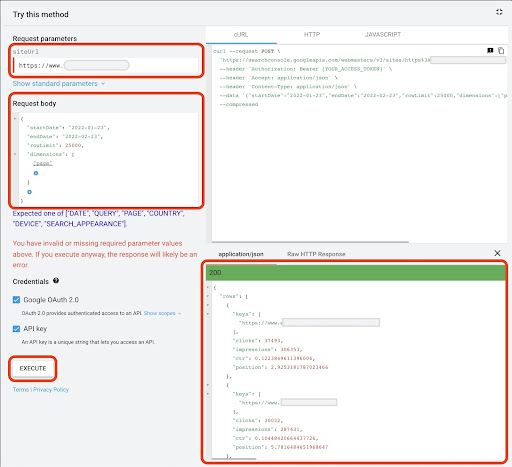
После выполнения запроса нам нужно его сохранить. Из-за формата ответа нам нужно создать файл JSON, скопировать все ответы JSON и сохранить его с именем файла downloaded_data.json .
Если ваш сайт небольшой, как сайт компании SASS, и данные вашей целевой страницы составляют менее 1000 страниц, вы можете легко установить дату в GSC и экспортировать данные целевых страниц для вкладки «СТРАНИЦЫ» в виде файла CSV.
2. Загрузка данных целевых страниц
Для этого руководства я предполагаю, что вы получаете данные из Google API Explorer и сохраняете их в файле JSON. Для загрузки этих данных мы должны запустить код ниже:
# Создание DataFrame для загруженных данных
с open('./downloaded_data.json') как json_file:
Lands_data = json.loads(json_file.read())['строки']
Landings_df = pd.DataFrame(landings_data)
Кроме того, нам нужно изменить имя столбца, чтобы придать ему больше смысла, и применить функцию для получения URL-адресов целевых страниц непосредственно в столбце «целевая страница».
# Переименование столбца «ключи» в столбец «целевая страница» и преобразование списка «целевая страница» в URL
lands_df.rename(columns={'keys': 'целевая страница'}, inplace=True)
lands_df['целевая страница'] = lands_df['целевая страница'].apply(лямбда x: x[0])
3. Получение всех корневых каталогов целевых страниц
Прежде всего, нам нужно определить имя нашего сайта.
# Определение имени вашего сайта в кавычках. Например, «https://www.example.com/» или «http://mydomain.com/». имя_сайта = ''
Затем мы запускаем функцию для URL-адресов целевых страниц, чтобы получить их корневые каталоги и увидеть их в выводе, чтобы выбрать их.
# Получение каталога каждой целевой страницы (URL)
lands_df['каталог'] = lands_df['целевая страница'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Чтобы получить все каталоги на выходе, нам нужно манипулировать параметрами Pandas
pd.set_option("display.max_rows", нет)
# Каталоги веб-сайтов
lands_df['каталог'].value_counts()
Затем мы выбираем, для каких каталогов нам нужно получить их кривую CTR.
Вставьте каталоги в переменную important_directories .
Например, product,tag,product-category,mag . Разделяйте значения каталога запятой.
важные_каталоги = ''
важные_каталоги = важные_каталоги.split(',')
4. Маркировка и группировка целевых страниц
Как и запросы, мы также помечаем целевые страницы на основе их средней позиции.
# Маркировка позиций целевых страниц
для я в диапазоне (1, 11):
landings_df.loc[(landings_df['position'] >= i) & (
lands_df['position'] < i + 1), 'метка позиции'] = i
Затем мы группируем целевые страницы на основе их «каталога».
# Группировка целевых страниц на основе их значения «каталога» lands_grouped_df = lands_df.groupby(['каталог'])
5. Создание прямоугольных и столбчатых диаграмм для наших каталогов.
В предыдущем методе мы не использовали функцию для создания графиков. Однако; для автоматического расчета кривой CTR для разных целевых страниц нам нужно определить функцию.
# Функция для создания и сохранения каждой диаграммы каталога
def each_dir_plot (dir_df, ключ):
# Группировка целевых страниц каталога на основе их значения «метки позиции»
dir_grouped_df = dir_df.groupby(['метка позиции'])
# Создание DataFrame для хранения управляемых данных 'dir_grouped_df'
модифицированный_df = pd.DataFrame()
# Список для сохранения каждой средней позиции для нашей гистограммы
средний_ctr_list = []
'''
Перебор групп «query_grouped_df» и добавление 20 % самых популярных запросов на основе показов в DataFrame «modified_df».
Если расчет CTR только на основе первых 20% запросов с наибольшим количеством показов вам не подходит, вы можете изменить его.
Для его изменения вы можете увеличить или уменьшить его, манипулируя '.quantile(q=your_optimal_number, interpolation='lower')]'.
'you_optimal_number' должен быть от 0 до 1.
Например, если вы хотите получить первые 30 % ваших запросов, «your_optimal_num» — это разница между 1 и 0,3 (0,7).
'''
для я в диапазоне (1, 11):
# Попытка за исключением случаев, когда в каталоге нет данных для некоторых позиций
пытаться:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['впечатления'] >= dir_grouped_df.get_group(i)['впечатления']
.quantile(q=0,8, интерполяция='ниже')]
mean_ctr_list.append(tmp_df['ctr'].mean())
модифицированный_df = модифицированный_df.append (tmp_df, ignore_index = True)
кроме KeyError:
средний_ctr_list.append (0)
№ 1. Коробчатый сюжет
box_fig = px.box(modified_df, x='метка позиции', y='ctr', title=f'{ключ} распределение CTR каталога на основе позиции',
points='all', color='метка позиции', labels={'метка позиции': 'Позиция', 'ctr': 'CTR'})
# Отображение всех десяти тиков оси X
box_fig.update_xaxes(tickvals=[i для i в диапазоне (1, 11)])
# Изменяем формат делений по оси Y на проценты
box_fig.update_yaxes(tickformat=".0%")
# Сохранение графика в директорию 'output plot images'
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
№ 2. Барный сюжет
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} каталог означает распределение CTR на основе позиции',
labels={'x': 'Позиция', 'y': 'CTR'}, text_auto=True)
# Отображение всех десяти тиков оси X
bar_fig.update_xaxes(tickvals=[i для i в диапазоне (1, 11)])
# Изменяем формат делений по оси Y на проценты
bar_fig.update_yaxes(tickformat='.0%')
# Сохранение графика в директорию 'output plot images'
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
После определения вышеуказанной функции нам нужен цикл for, чтобы перебирать данные каталогов, для которых мы хотим получить их кривую CTR.
# Цикл по каталогам и выполнение функции 'each_dir_plot'
для ключа, элемент в lands_grouped_df:
если ключ в важных_каталогах:
each_dir_plot (элемент, ключ)
На выходе мы получаем наши графики в папке output plot images графиков.
Продвинутый совет!
Вы также можете рассчитать кривые CTR для разных каталогов, используя целевую страницу запросов. С некоторыми изменениями в функциях вы можете группировать запросы на основе каталогов их целевых страниц.
Вы можете использовать тело запроса ниже, чтобы сделать запрос API в API Explorer (не забывайте об ограничении в 25000 строк):
{
"дата начала": "01.01.2022",
"endDate": "2022-02-01",
"Габаритные размеры": [
"запрос",
"страница"
],
"группы фильтров измерений": [
{
"фильтры": [
{
"размер": "ЗАПРОС",
"выражение": "brand_variation_names",
"оператор": "EXCLUDING_REGEX"
}
]
}
],
"лимит строк": 25000
}
Советы по настройке расчета кривой CTR с помощью Python
Для получения более точных данных для расчета кривой CTR нам необходимо использовать сторонние инструменты.
Например, помимо знания того, какие запросы имеют избранный фрагмент, вы можете изучить дополнительные функции SERP. Кроме того, если вы используете сторонние инструменты, вы можете получить пару запросов с рейтингом целевой страницы для этого запроса на основе функций SERP.
Затем маркировка целевых страниц их корневым (родительским) каталогом, группировка запросов на основе значений каталога, учет функций SERP и, наконец, группировка запросов на основе позиции. Для данных CTR вы можете объединить значения CTR из GSC с их одноранговыми запросами.