
Важность семантической сети для SEO: создание семантических сетей контента с помощью шаблонов запросов и документов — тематическое исследование
Опубликовано: 2022-01-11Семантическая сеть связана с концепцией базы знаний, которая может представлять реальную информацию о вещах, имеющих реляционные связи. База знаний может иметь тысячи типов отношений с миллиардами сущностей и триллионами фактов. Семантическая сеть может быть создана из любого реального существования с общими характеристиками, такими как вес, размер, тип, запах или цвет. Отношения между семантическими сетями и семантическим вебом создаются семантическими поисковыми системами и оптимизацией.
Семантические сети используются в семантическом анализе, устранении неоднозначности слов, создании WordNet, теории графов, обработке естественного языка, понимании и генерации. Перспектива семантической сети может быть использована в рамках семантической поисковой оптимизации путем предоставления сети семантического контента.
В этом тематическом исследовании SEO два разных веб-сайта с двумя разными методами с одинаковой точки зрения будут объяснены на основе шаблонов Query, Document, Intent и стоящих за ними пар сущность-атрибут.
Используя понимание того, как поисковые системы представляют знания и как они расширяют свое представление знаний, я могу использовать это для получения невероятных результатов ранжирования. Как только вы поймете основные концепции, я объясню, как я применил их к двум разным веб-сайтам, а затем подробно опишу методы, которые использовал.
Как семантические сети могут помочь рейтингу вашего сайта?
Ниже вы найдете общие необработанные результаты для проекта I.
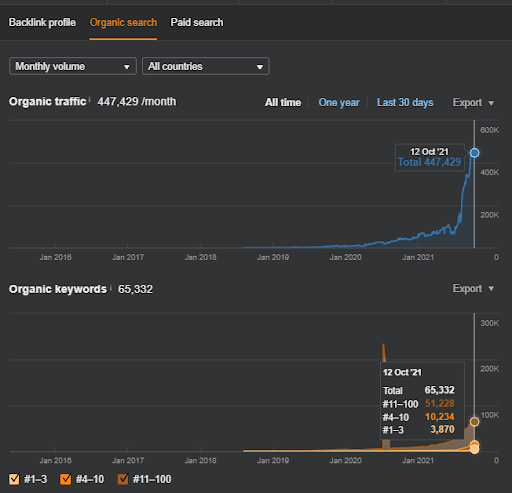
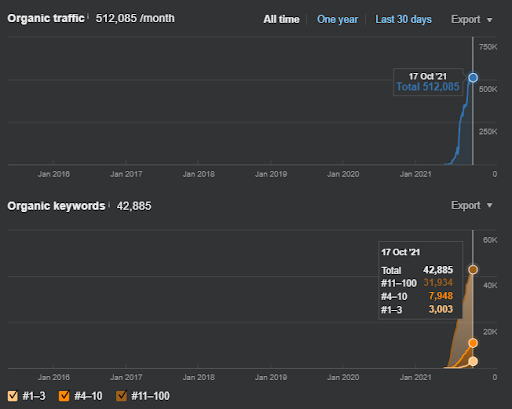
Результаты первого проекта IstanbulBogaziciEnstitu.com. Чтобы доказать, что «семантические сети» можно использовать для SEO с помощью шаблонов запросов и документов, я продемонстрирую две разные контентные сети из первого проекта. В ближайшем будущем Project One будет иметь гораздо лучшие результаты благодаря Semantic Content Network Two. Клиент будет отвечать за развертывание этой второй сети, но я также объясню ее логику.
17 дней спустя, вот прогресс, достигнутый в Проекте I: 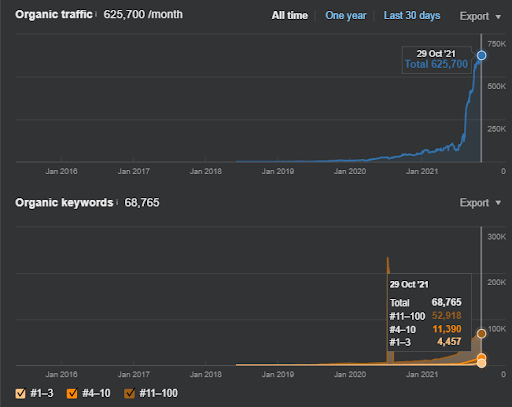
17 дней спустя процесс повторного ранжирования Semantic Content Network стал более четким.
Концепции семантической контентной сети помогают нам понять значение запроса, цели поиска, поведения и шаблонов документов для сущностей одного и того же типа. В этом тематическом исследовании SEO, ориентированном на семантическую сеть, предыдущее тематическое исследование тематического авторитета и семантического SEO будет углублено с помощью двух новых веб-сайтов, которые используют семантически созданные контентные сети вокруг тех же типов объектов.
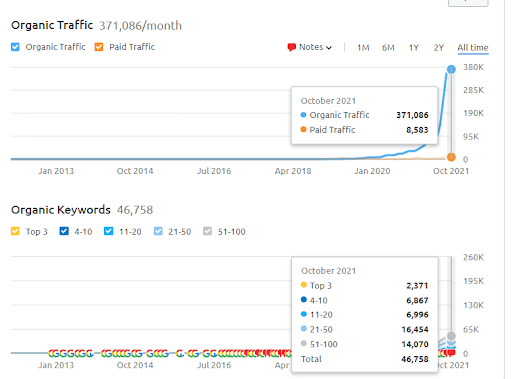
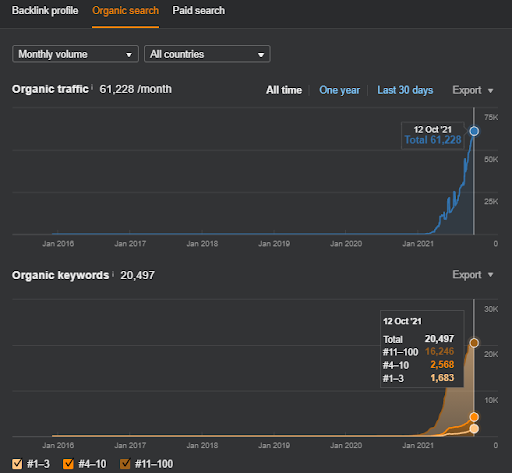
Это изображение SEMRush первого проекта. Я также должен упомянуть, что этот веб-сайт потерял июньское обновление алгоритма Broad Core, если бы он не потерял свою «ранжируемость», результаты были бы лучше. Для следующего обновления алгоритма Broad Core, с лучшим тематическим авторитетом, охватом и историческими данными, он может легко восстановить «ранжируемость».
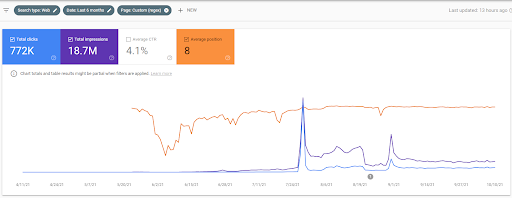
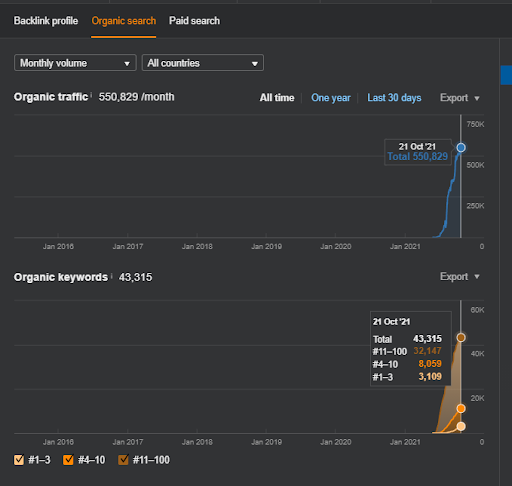
Название Второго Проекта - Vizem.net. В отличие от Project One, вы можете видеть, что Vizem.net имеет более медленный, но устойчивый рост. Это потому, что они используют сети семантического контента с несколько иной точки зрения. Ниже вы можете увидеть результаты второго проекта Ahrefs.
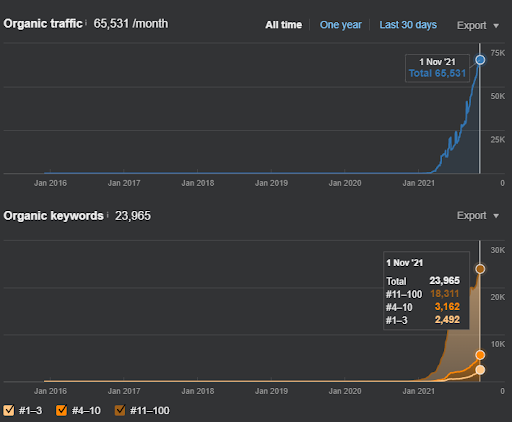
Результаты Второго проекта представляют собой «медленный процесс переоценки» за счет постепенного улучшения тематического охвата и авторитетности. Термины «Повторное ранжирование» и «Первоначальное ранжирование» будут объяснены после понятий, связанных с сетями семантического контента. Если вы понимаете «стабильность» в графике, это потому, что я перестал публиковать новый контент в исходниках. И это влияет на процесс повторного ранжирования, как вы понимаете из подсчета трех самых популярных запросов. Соотношения «Импульс» и «Переранжирование» можно найти после объяснения основных понятий.
Ниже вы можете найти результаты SEMRush от Vizem.net.
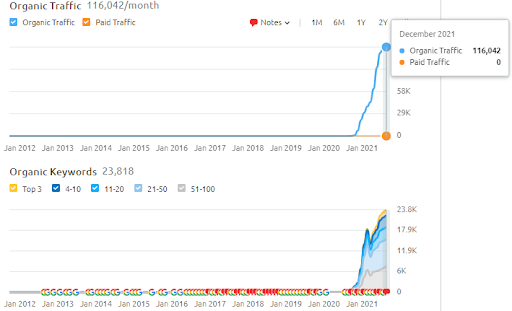
Фактический трафик этого сайта в 3 раза больше, чем указано в SEMRush. Вы можете реализовать ту же концепцию «стабильности» и «импульса» на этих графиках.
Во время написания Тематического тематического авторитетного SEO-кейса я поблагодарил Билла Славски за то, что он разъяснил мою точку зрения. Я повторяю это и для тематического исследования Semantic Content Network SEO. Чтобы понять концепции «Повторного ранжирования» и «Первоначального ранжирования», следует прочитать статью «Как поисковые системы могут переранжировать результаты поиска».
18 марта 2021 года Oncrawl, RankSense и Holistic SEO & Digital опубликовали вебинар по SEO и науке о данных на Python. На вебинаре была записана поисковая выдача для анимации различий в результатах. Видно, что поисковая система меняет позиции одних источников на другие с аналогичной периодичностью.
Прежде чем продолжить, я знаю, что это длинная статья. Но на самом деле это краткое объяснение очень сложной методологии SEO. Семантические контентные сети требуют слишком много размышлений при их разработке и месяцев обучения клиентов, авторов, а также адаптации. Таким образом, в этой статье я хочу сосредоточиться на определениях концепций с наилучшими исполнимыми краткими предложениями и важными патентами Google и других поисковых систем, исследовательскими работами, а также их собственными концепциями. В длинной версии (по сути, это книга) я сосредоточился на «начальном ранжировании» и «повторном ранжировании» сетей семантического контента.
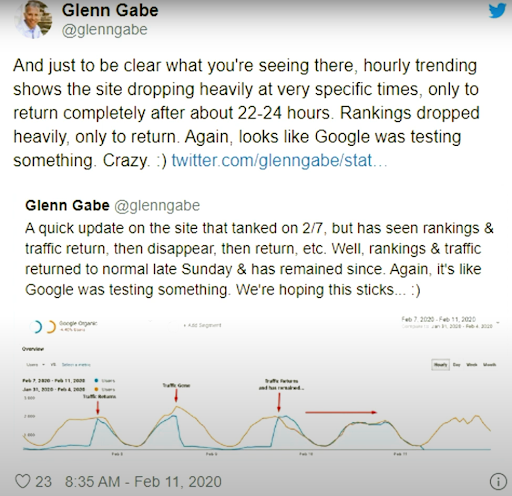
С 11 февраля 2020 года у Гленна Гейба есть хороший пример визуальной методологии повторного ранжирования и тестирования поисковых систем.
Если вы хотите узнать больше, прочитайте «Важность начального ранжирования и повторного ранжирования для SEO».
Чтобы глубже погрузиться в реальные данные для тематического исследования SEO, концепции для понимания сети семантического контента должны быть обработаны с точки зрения понимания и коммуникации поисковой системы.
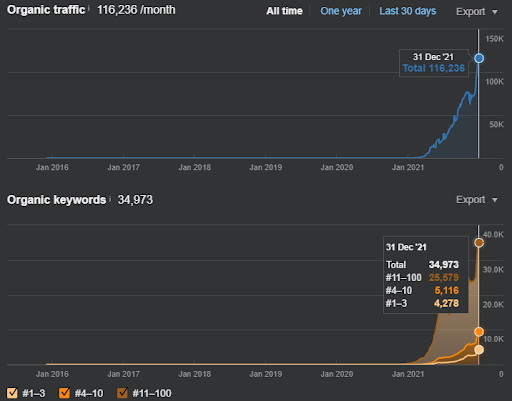
В качестве примера повторного ранжирования Vizem.net обновленную ситуацию можно увидеть выше. В следующих разделах тематического исследования SEO будет больше объяснений алгоритмов повторного ранжирования Google для SEO.
Что такое семантическая сеть?
Семантическая сеть может использоваться для подключения и анализа Интернета вещей. Это может быть полезно для распознавания потенциальных покупателей на рынке технологий или просто для совместного анализа слов для создания сети ключевых слов и кластеризации. Семантическая сеть может использоваться для поддержки навигации и выявления структуры отношений или относительной важности одной вещи по отношению к другой. Семантическая сеть имеет следующие компоненты:
- Лексическая семантика: понимание того, какое слово и понятие связаны с какими другими, с какими различиями.
- Структурный компонент: понимание того, какой узел соединен с каким краем и с какой информацией.
- Семантическая составляющая: Определение фактов.
- Процедурная часть: помогает создавать дополнительные связи между компонентами.
Поскольку семантические сети многоцелевые, алгоритмы НЛП также можно использовать для самых разных целей, например, для выявления сложных проблем со здоровьем. Одна и та же структура семантической сети может быть реализована во многих других областях, если эти другие области имеют семантическую связь друг с другом.
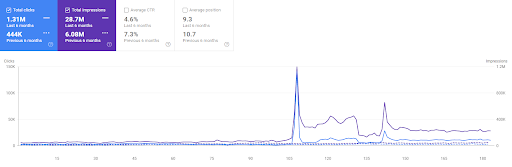
Сравнение первого проекта за последние 6 месяцев.
Что такое база знаний?
База знаний — это информационная библиотека с классификацией в машиночитаемом виде. Базу знаний можно использовать как энциклопедию, которую можно сужать и углублять на основе запроса. База знаний может быть сформирована на основе предложений, извлечения фактов и извлечения информации. Связь между семантической сетью и базой знаний заключается в том, что все, что находится в семантической сети, будет помещено в базу знаний при извлечении фактов.
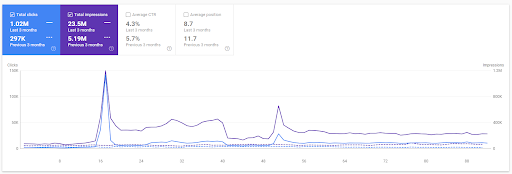
Сравнение первого проекта за последние 3 месяца
Что такое семантическая контентная сеть?
Семантическая контентная сеть представляет собой контентную сеть, подготовленную на основе компонентов семантической сети и понимания. Семантическая контентная сеть может включать в себя несколько атрибутов объекта или объектов из одной и той же группы, чтобы обеспечить базу знаний более подробной информацией.
В сети семантического контента термины предметной области и триплеты могут использоваться для обозначения основной цели документа и возможных соседствующих частей контента.
Поисковая система может сравнивать свою собственную базу знаний с базой знаний, которая может быть создана из содержимого веб-сайта. Если веб-сайт имеет высокий уровень точности и полноты для различных контекстных слоев, поисковая система может улучшить свою собственную базу знаний на основе содержимого веб-сайта. Если поисковая система улучшает и расширяет свою собственную базу знаний из другого источника в открытой сети, это сигнал высокого уровня доверия, основанного на знаниях.
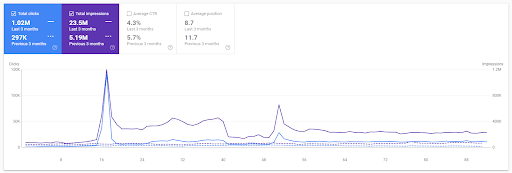
Годовое сравнение за последние 3 месяца на основе первого проекта.
Что такое доверие, основанное на знаниях?
Доверие, основанное на знаниях, ориентировано на открытую сеть на основе «точности информации», а не «PageRank». Это алгоритм, аналогичный RankMerge. Доверие, основанное на знаниях, включает триплеты, извлечение фактов, проверку точности и понимание текста путем устранения двусмысленности текста. Доверие, основанное на знаниях, может быть получено путем предоставления сетей семантического контента, которые имеют тесно связанные компоненты внутри статьи, основанные на разных, но релевантных контекстных слоях.
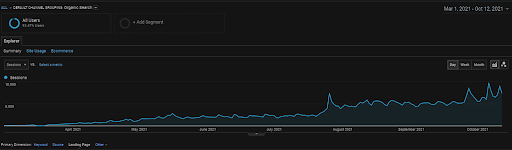
Органическая сессия Vizem.net от GA за последние 6 месяцев.
Ниже вы увидите пример презентации «Доверие, основанное на знаниях» от Луны Донг. Он показывает, как поисковая система может сосредоточиться на «внутренних факторах ранжирования», а не на экзогенных факторах ранжирования. Это объясняет, что высокий PageRank сам по себе не может отражать высокое качество и точность контента. Таким образом, важно иметь KBT (доверие, основанное на знаниях).
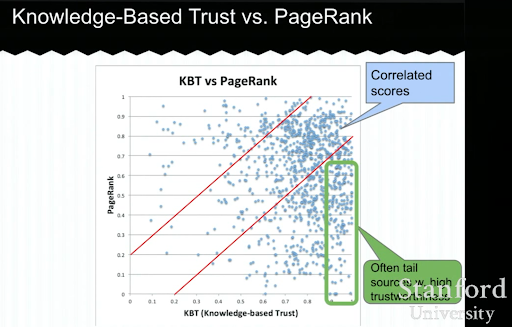
Большое спасибо Арноуту Хеллемансу, который поделился со мной этой обучающей лекцией во время приватного SEO-чата. Если вы хотите узнать больше о доверии, основанном на знаниях: Стэнфордский семинар – Хранилище знаний и доверие, основанное на знаниях
Что такое контекстное покрытие?
Контекстное освещение и тематическое освещение — это не одно и то же, поскольку домен знаний и контекстуальный домен — это не одно и то же. Контекстное покрытие представляет собой аспекты обработки концепции. Концепт может быть обработан на основе его общих точек с другими вещами. Например, если объектом является страна, можно обработать ее позицию в отношении экологического кризиса. Если другие страны обрабатываются с той же точки зрения, это означает, что мы охватываем контекстную область.

Поисковая система Google со временем пополняет свои исследовательские работы и патенты. Правая цитата из приведенного выше раздела является атрибутом «контекстных векторов», а левая часть — атрибутом «фразовой таксономии». Интересно то, что даже пример тот же, что и «цифровая камера».
Углубленные детали и части этих комбинаций представляют контекстуальные уровни внутри контекстуальной области. Каждая сущность, независимо от того, носит она имя или нет, имеет множество контекстуальных доменов. Таким образом, Google извлекает больше контекстных доменов, и пользователи с каждым годом выполняют поиск по более длинным запросам. Когда обработка естественного языка и понимание естественного языка разработаны, запросы и документы расширяются вместе с точки зрения деталей и контекста.
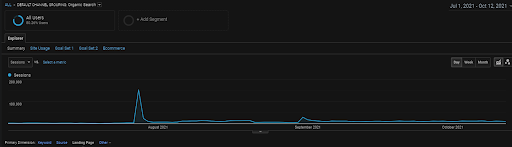
Графика GA Organic Sessions за последние 4 месяца проекта BogaziciEnstitu. Из-за «этапа сбора исторических данных» проекта увеличение количества деталей не ясно, чтобы их можно было рассматривать как линейные.
Контекстное покрытие можно понять с помощью «контекстных квалификаторов». Квалификатором контекста может быть прилагательное, наречие или любой другой предлог, например, фразы, начинающиеся со слов «для, в, в, во время, в то время как». Приведенные ниже вопросы, связанные с сущностями, не совпадают с точки зрения контекстной области:
- Какие фрукты самые полезные для детей при бессоннице?
- Какие фрукты самые полезные для детей с тревожностью?
Приведенные ниже вопросы, связанные с сущностями, не совпадают с точки зрения контекстуального слоя:
- Какие фрукты самые полезные для детей с сильной бессонницей старше 6 лет?
- Какие фрукты самые полезные для детей с низким уровнем тревожности до 6 лет?
Приведенные ниже вопросы, связанные с сущностями, не совпадают с точки зрения предметных областей:
- Какие книги самые полезные для детей с сильной бессонницей старше 6 лет?
- Какие самые полезные игры для детей с низким уровнем тревожности до 6 лет?
Но все эти вопросы могут быть в одной и той же сети семантического контента, потому что все они касаются одной и той же «концепции» и «области интересов» с аналогичной поисковой активностью и связанной с поиском реальной активностью.
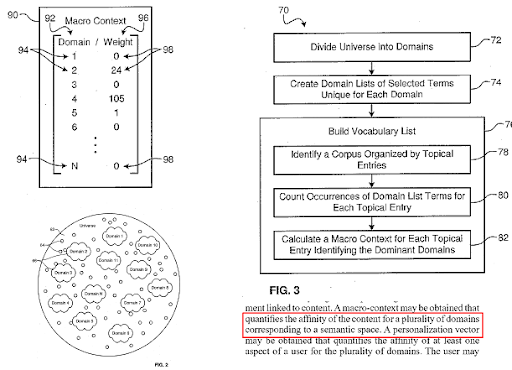
Поисковая система делит Интернет на разные области знаний и одновременно вычисляет оценки макро- и микроконтекста для источника, веб-страницы и раздела веб-страницы.
Я знаю, что у меня есть много новых концепций для вас, и, поскольку это краткая версия этой статьи, я не смогу здесь рассказать обо всем, но в будущем курсе Semantic SEO я обработаю такие вещи, как разница между «поисковой активностью» и «поисковой активностью в реальном мире».
Продолжим немного к более конкретным вещам.
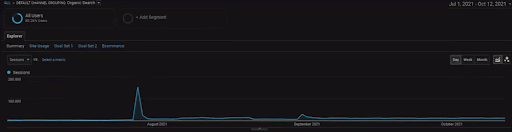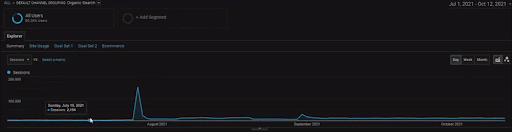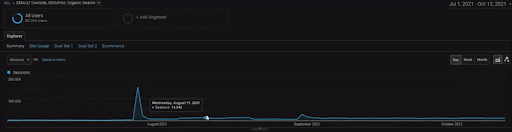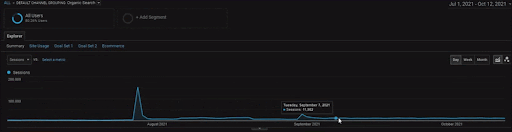
Чтобы показать детали проекта BogaziciEnstitu, вы можете проверить интерактивную версию изображения. Процесс тестирования и повторного ранжирования поисковых систем стал более понятным в этом проекте после события с историческим источником данных.
Как MuM связан с сетями семантического контента?
Многозадачное обучение с унифицированным преобразователем или многозадачной унифицированной моделью обучает языковые модели оценке визуальных входных данных, а также текста. Он способен генерировать текст вместе с пониманием. Кроме того, MuM не зависит от языка, другими словами, семантическая поисковая оптимизация зависит от языковых навыков, но не ограничивается языком. Поскольку у сущностей нет языка, а значение универсально, MuM использует информацию из нескольких языков и разных контекстов в единую базу знаний.
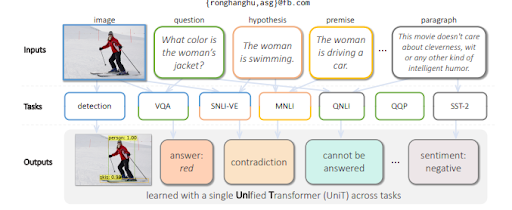
Чтобы ответить на вопросы визуального изображения, MuM генерирует вопросы на основе обнаруженных объектов на изображении. В ближайшем будущем также можно будет генерировать вопросы, связанные с аудио и видео.
MuM использует разные домены для обнаружения объектов и понимания естественного языка со структурой трансформера кодер-декодер. Каждый ввод поступает из разных областей открытой сети, в то время как все они оцениваются с помощью одного общего декодера. Ниже вы сможете увидеть еще один пример из исследовательской работы.
Следует отметить, что MuM может быть в 1000 раз сильнее, чем BERT, но BERT по-прежнему используется в текстовом кодировщике MuM. Основным преимуществом MuM является то, что его можно использовать для визуальных эффектов и непосредственно для аудио, поэтому его можно назвать «многозадачной» моделью. Второе преимущество заключается в том, что он напрямую устраняет все языковые барьеры. Третье преимущество заключается в том, что он может подключить все к другому без необходимости дополнительных посредников. Четвертое преимущество заключается в том, что MuM также может генерировать текст, в отличие от BERT.
Связь между MuM, базой знаний, семантическими сетями и контекстным охватом заключается в том, что поисковая система способна находить гораздо более контекстную область с помощью квалификаторов контекста и их комбинаций с возможными областями знаний. Таким образом, хорошо структурированная сеть семантического контента, сформированная с использованием надлежащей тематической карты и исходного контекста, может улучшить доверие к базе знаний, а также тематический авторитет.
Каков контекст источника?
Контекст источника представляет две вещи. Централизованный поиск в Интернете источника и центральная поисковая активность, которую можно выполнить с помощью связанной поисковой активности. Для веб-сайта электронной коммерции исходным контекстом является покупка определенного продукта или определенного типа продукта. Если это веб-сайт о путешествиях, контекст источника идет куда-то из другого места для разных видов еды, пейзажей или просто бизнеса. В зависимости от исходного контекста потребуется дальнейшая настройка сети семантического контента и тематической карты. Для этого необходимо выбрать центральные разделы на тематической карте и дополнительные разделы на тематической карте.
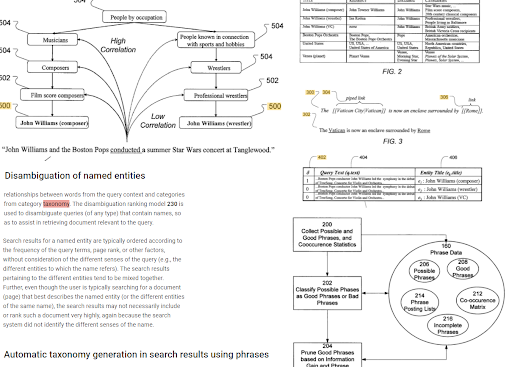
Индексирование на основе фраз и понимание поиска, ориентированного на объекты, связаны друг с другом на основе семантики. Выше «Устранение неоднозначности именованных объектов» и «Автоматическая генерация таксономии в результатах поиска с использованием фраз» можно увидеть вместе для определения «контекста». Хорошие фразы и уникальная, но коррелирующая информация по теме помогут лучшему начальному и повторному ранжированию.
Опять же, некоторые из этих понятий, «конфигурация тематической карты», «дизайн сети семантического контента», еще не определены, и здесь не место для этого. Но связанная с этим поисковая активность была объяснена вместе с каноническим поисковым намерением и репрезентативными фразами для этих канонических поисковых намерений.
Предыстория тематического исследования SEO, ориентированного на семантическую сеть
Основываясь на приведенных выше концепциях, я использовал семантические сети для создания тематического исследования SEO. Мы рассмотрим два проекта веб-сайтов, которые я упомянул в начале этой статьи, и изучим результаты, а также то, как я реализовал семантические сети для их получения.
Чтобы дать вам представление о том, насколько мощными могут быть эти сети, результаты, связанные с SEO, для тематического исследования SEO, ориентированного на семантическую сеть, перечислены ниже.
- Понимание семантической сети необходимо для создания правильной тематической карты.
- В обоих проектах техническое SEO не используется, чтобы изолировать эффекты семантического SEO.
- Оптимизация скорости страницы не используется по той же причине.
- Дизайн и оптимизация WUX (веб-сайт для пользователей) не используются.
- Обратные ссылки (внешние ссылки и поток PageRank) не используются.
- Оба бренда не имеют исторических данных. Vizem.net совершенно новый, BogaziciEnstitusu имеет более старую историю, но она была ниже, чем реальная компания.
- OnPage SEO или другие вертикали SEO не используются.
- У обоих брендов сервер лучше, чем в предыдущем примере тематического авторитетного примера.
Это тематическое исследование SEO, ориентированное на семантическую сеть, поможет людям, которые хотят улучшить свою перспективу семантического SEO с помощью двух разных методологий и концепций, ориентированных на два разных веб-сайта.
Второй проект: Vizem.net фокусируется на процессе подачи заявления на получение визы. Прежде чем писать, публиковать или даже запускать эти проекты, я много раз показывал оба этих сайта своим другим клиентам или партнерам. И недавно Vizem.net начал свой путь «Тематического авторитета».
SEO на основе тематического исследования семантических сетей было написано в двух разных версиях. Если вы хотите прочитать все соответствующие патенты, исследовательские работы и подробные исследования, интерпретации с точки зрения поисковых систем, а также глубже понять деревья решений поисковых систем, вы можете прочитать Важность начального ранжирования и повторного ранжирования SEO. Статья из тематического исследования объемом более 30 000 слов. Если вам не хватает теоретических знаний по SEO и исторической предыстории, вы можете продолжить чтение резюме.
Ниже вы можете увидеть график второго проекта (Vizem.net) от SEMRush.
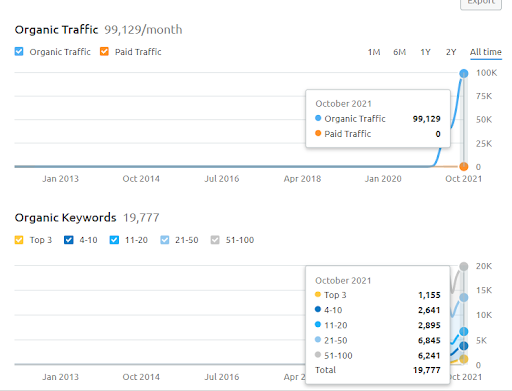
Графика SEMRush Второго веб-сайта. Vizem.net — это совершенно новый источник, предназначенный для отраслей с высоким уровнем укоренившихся конкурентов, таких как Visa Application. В частности, в связи с последними событиями в Турции уровень конкуренции в отрасли повышается. Таким образом, использование перспективы семантической сети для создания контентной сети полезно.
Первый проект: Istanbul Bogazici Enstitusu: увеличение органического клика на 600 % за 3 месяца — использование исторических данных и начального рейтинга
IstanbulBogazici Enstitusu — одно из самых сложных тематических исследований SEO, которые я проводил, не из-за поисковых систем, а из-за людей и моих проблем со здоровьем. Таким образом, я вышел из проекта и не стал публиковать третью сеть семантического контента, которая предназначена для завершения семантических отношений на основе исходного контекста. Даже если в нем нет терминов предметной области и правильно реализованных контекстных фраз, он настроен с достаточным уровнем семантических связей и точности, чтобы обеспечить общую производительность органического поиска более трех миллионов сеансов в месяц, если третья сеть контекстной рекламы публиковаться в будущем с учетом возрастающего эффекта второй сети семантического контента.
Ниже вы увидите изменяющуюся графику IstanbulBogazici Enstitusu на GSC за последние 12 месяцев. Проект был запущен в мае 2021 года надлежащим образом и завершился в сентябре 2021 года публикацией двух сетей семантического контента.
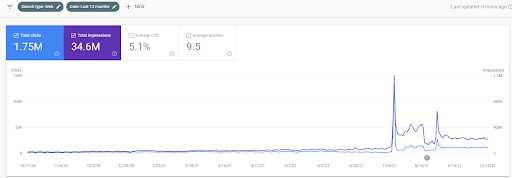
Ниже вы можете увидеть более подробную версию. От 1400 кликов в день до 140000 кликов, а затем можно увидеть обычные 10 000+ кликов в день в органическом поиске.
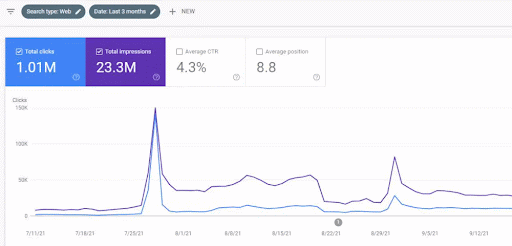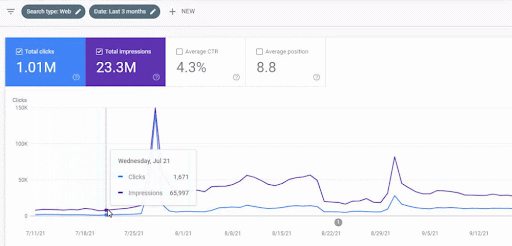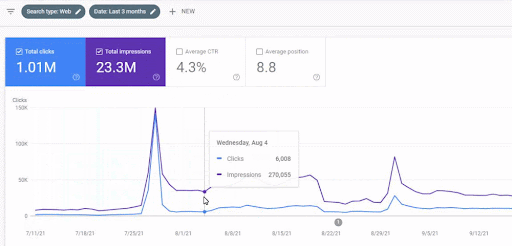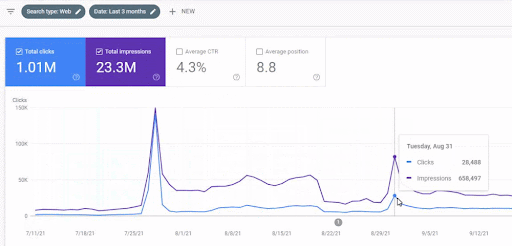
Рост трафика первой контентной сети после запуска можно увидеть ниже.
На этом снимке экрана показан четвертый месяц работы сети First Semantic Content Network.
Как вы можете видеть на графике, в общем трафике всего веб-сайта доминирует и зависит от сети First Semantic Content Network, которая фокусируется на «образовательных ответвлениях». Вторую сеть контекстной рекламы, которую я запустил с помощью этого веб-сайта, можно увидеть ниже в консоли поиска Google. На приведенном ниже снимке экрана показан 16-й день второй сети семантического контента.
Первоначальное ранжирование и повторное ранжирование использовались в статье, потому что они определяют этапы алгоритмов ранжирования вместе с их типами и целями перед тестированием источника и веб-страницы из источника в поисковой выдаче для более важных запросов, которые имеют популярность. .
На что ориентирована Первая Семантическая Контентная Сеть Первого Проекта?
«Семантическая информационная сеть» использует семантическую сеть из базы знаний для объяснения основных, вторичных и третичных отношений между вещами в базе знаний. Таким образом, создание сети семантического контента требует проектирования следующей сети семантического контента на основе исходного контекста, который является основной функцией веб-сайта. В этом контексте первая сеть семантического контента была сосредоточена на «университетских факультетах, образовательных филиалах и потребностях для университетского образования в конкретной организации и отрасли».
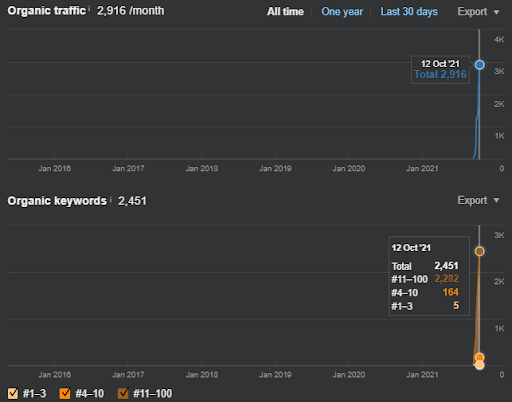
Ниже вы найдете графику Ahrefs от First Semantic Content Network.
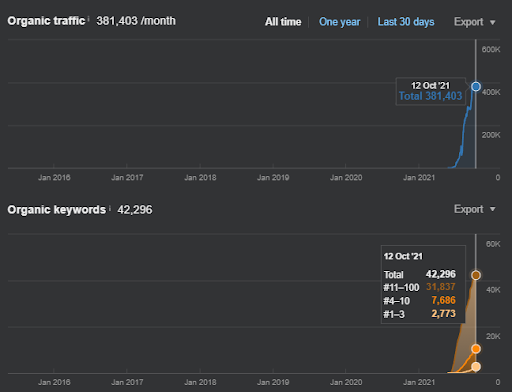
Это на пять дней позже предыдущего снимка экрана.
«Корень: istanbulbogazicienstitu.com/bolum», после первого этапа начального ранжирования процесс повторного ранжирования становится более эффективным и продуктивным.
Вы можете увидеть версию спустя четыре дня, как показано ниже, для подтверждения характера «переоценки».
На что ориентирована вторая семантическая контентная сеть первого проекта?
Вторая сеть семантического содержания сосредоточилась на профессиях, рабочих местах, навыках и необходимом образовании для этих навыков или рутине. На основе первой сети семантического контента поддерживается вторая сеть семантического контента. И по «шаблонам запросов-шаблонов намерений» создаются и размещаются с «реляционными связями» еще две разные семантические подсодержательные сети, при этом связанные с вышестоящими подобными иерархическими уровнями.
Я знаю, что эти разделы сложны для вас, потому что вы еще не видели определения того, что ниже.
- Семантическая контентная сеть
- Исходный контекст
- Семантическая подконтентная сеть
- База знаний
- Реляционные соединения
- Начальный рейтинг
- Переоценка
- Контекстное покрытие
- Сравнительный рейтинг
- Извлечение фактов
После объяснения второго веб-сайта будет легче понять эти понятия и предложения.
Vizem.net: от 0 до 9 000+ ежедневных кликов в день за 6 месяцев — сравнительный рейтинг с использованием контекста
Вы можете увидеть график Vizem.net за последние 12 месяцев. Для этого проекта из-за Covid-19 мы столкнулись с множеством экономических проблем, поскольку инвестор принадлежит индустрии спортзалов. Таким образом, я могу сказать, что экономические проблемы замедлили проект, и это вызвало некоторую задержку для «процессов переранжирования».
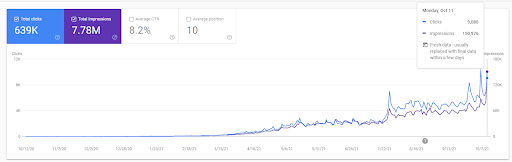
Чтобы понять первоначальный рейтинг и немного более высокий рейтинг, вы можете использовать график ниже.
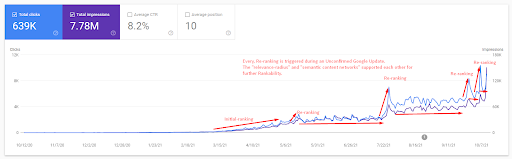
Некоторые определения, связанные с начальным ранжированием и повторным ранжированием на графике выше, можно найти ниже.
- Большие скачки рейтинга произошли во время неподтвержденных обновлений Google. Некоторые тесты давали избранные фрагменты, а люди также задавали вопросы.
- Некоторые тесты Google удалили заработок FS и PAA.
- Каждый раз временная шкала между двумя процессами переоценки сокращалась.
- Процессы повторного ранжирования каждый раз улучшали ранжируемость источника.
- Источник всегда улучшал свой радиус релевантности при расширении кластеров запросов.
В качестве примечания я могу оставить предложение ниже.
Если поисковая система индексирует вашу веб-страницу, это не означает, что поисковая система поняла веб-страницу. Индексация происходит быстрее, чем понимание, и в большинстве случаев поисковая система ранжирует веб-страницу с прогнозами «изначально». После понимания происходит «переранжирование». 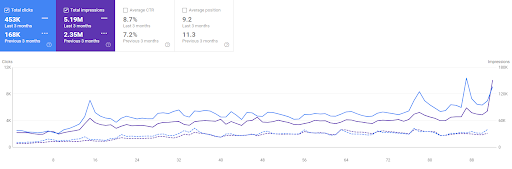
Сравнение Vizem.net за последние 3 месяца
Как устроена сеть семантического контента Vizem.net?
Я помню, что для многих моих клиентов, друзей или секретных SEO-групп во время встреч я демонстрировал оба этих веб-сайта, говоря: «Они взорвутся». И, пока я пишу эту статью, я говорю вам следующее:
Следите за сетью семантического контента «istanbulbogazicienstitu.com/meslek», потому что она взорвется. И вы можете найти видео, которое я опубликовал перед написанием этой статьи, демонстрирующее «исторические данные» сезонного события и их влияние на процессы начального и повторного ранжирования. Вы можете увидеть это ниже.
Исходя из этого, сеть семантического контента Vizem.net не похожа на IstanbulBogazici Enstitusu, поэтому я не использовал «интенсивный уровень увеличения тематического охвата и исторических данных», мне нужно было создать авторитет, связанный с определенным типы сущностей, их атрибуты и возможные действия, лежащие в основе запросов для этих пар сущность-атрибут. В Vizem.net нет только «филиалов образовательных университетов» или «профессий и онлайн-курсов». В нем есть «страны для получения визы». Таким образом, создание достаточного уровня тематического авторитета требует согласованности во времени как минимум с 190 различными сетями семантического контента.
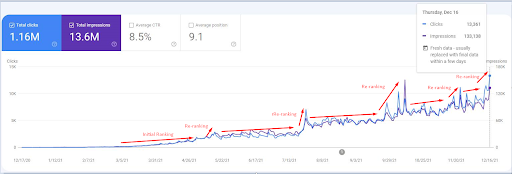
Скриншот от 18 декабря 2021 года. Вы можете видеть непрерывный ререйтинг и увеличение показов и кликов. Это на 4 недели позже, чем на предыдущем скриншоте.
Чтобы увидеть события повторного ранжирования, вы можете сравнить голую версию графика производительности органического поиска, который демонстрирует эффект семантического SEO. 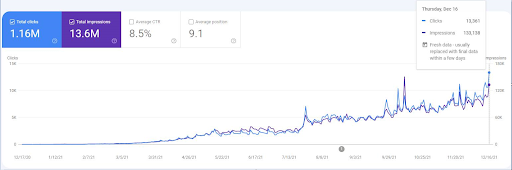
Эти 190 различных сетей семантического контента формируются на основе самой «страны», и страны помещаются в центр тематической карты со всеми возможными контекстными слоями для улучшения охвата поисковой активности.
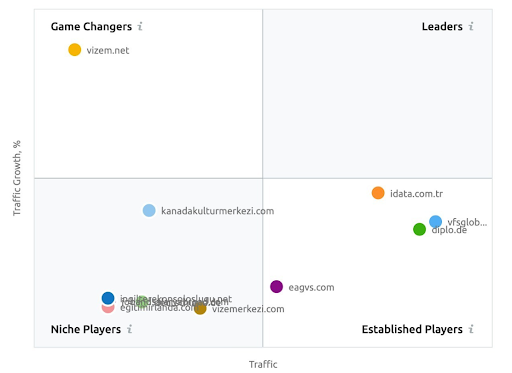
Скриншот из SEMRush, показывающий их восприятие Vizem.net в отличие от других игроков отрасли.
Я также опубликовал еще одно видео, только для Vizem.net. В этом видео последняя ситуация на веб-сайте не существует, поэтому, я считаю, оно также дает хорошее сравнение между сегодняшним и тем днем.
Наконец, публикация нерелевантных вещей в нерелевантной статье, сегменте веб-сайта или источнике может снизить общую релевантность веб-объекта для конкретной области знаний. Vizem.net покажет свою реальную ценность, и Rankability в будущем будет намного лучше.
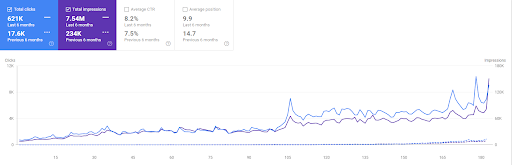
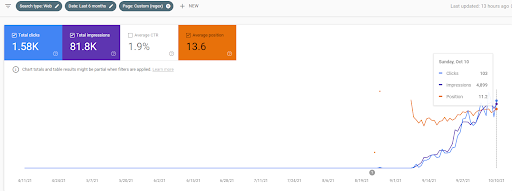
Сравнение Vizem.net за последние 6 месяцев.
Прежде чем продолжить, я знаю, что это длинная статья. Но на самом деле это краткое объяснение очень сложной методологии SEO. Семантические контентные сети требуют слишком много размышлений при их разработке и месяцев обучения клиентов, авторов, а также адаптации. Таким образом, в этой статье я хочу сосредоточиться на определениях концепций с наилучшими исполнимыми краткими предложениями и важными патентами Google и других поисковых систем, исследовательскими работами, а также их собственными концепциями. В длинной версии (по сути, это книга) я сосредоточился на «начальном ранжировании» и «повторном ранжировании» сетей семантического контента.
Если вы хотите узнать больше, прочитайте «Важность начального ранжирования и повторного ранжирования для SEO».
До сих пор мы обрабатывали вещи ниже.
- Семантическая сеть
- База знаний
- Семантическая контентная сеть
- Доверие, основанное на знаниях
- Контекстное покрытие
- Контекстный домен и слои
- Актуальность MuM для сетей семантического контента
- Контекст источника
Эти концепции предназначены для понимания того, как функционируют сети семантического контента и как их можно использовать с тематической картой. Следующие разделы будут посвящены тому, как поисковая система ранжирует сети семантического контента изначально, а затем модифицирует. В этом контексте будут обработаны вещи ниже.
- Начальный рейтинг
- Переоценка
- Шаблон запроса
- Шаблон документа
- Шаблон намерения поиска
- Что вы должны сделать, чтобы использовать сети семантического контента
Что такое начальное ранжирование для SEO?
Это новый термин и концепция для SEO, но старый для поисковых систем. Длинная версия «Семантическая сеть, ориентированная на SEO-кейс» фокусируется на алгоритмах ранжирования, основанных на алгоритмах, зависящих от запросов, документов, источников и нескольких патентах. Прогнозирующий поиск информации или алгоритмы прогнозирующего ранжирования пытаются снизить стоимость вычислений. И, даже если индексация происходит за один день, на понимание документа могут уйти месяцы или даже годы. Таким образом, вычисление начального рейтинга — это способ улучшить качество поисковой выдачи при одновременном снижении затрат. Некоторые задачи, связанные с поисковой системой, имеют более высокий приоритет, чем другие, для поддержания актуальности индекса и достаточно высокого качества.

Термин начальное ранжирование встречается в десятках тысяч различных патентов Google и исследовательских работ, потому что это классическая точка зрения среди создателей поисковых систем. Таким образом, выше вы можете увидеть разные патентные документы с продолжением одних и тех же пунктов и терминов с небольшими изменениями вокруг термина начальное ранжирование.
Начальный рейтинг представляет собой рейтинг документа в поисковой выдаче сразу после индексации. Начальный рейтинг документа представляет собой общий авторитет и релевантность источника для конкретной темы, шаблона запроса и цели поиска. Один и тот же контент может ранжироваться по-разному с точки зрения начального ранжирования между разными источниками. Начальное ранжирование важно при использовании сетей семантического контента, чтобы увидеть общее повышение качества и авторитетности источника. Каждый новый документ повышает свой первоначальный рейтинг, уменьшая при этом задержку индексации, если схема сети семантического контента правильно структурирована.
Начальное ранжирование поддерживает процесс повторного ранжирования и его эффективность для источника. И «ранжируемость источника» следует обрабатывать с помощью этих двух терминов, начального и повторного ранжирования.
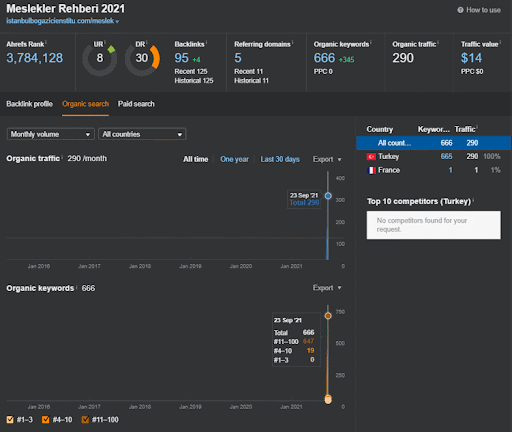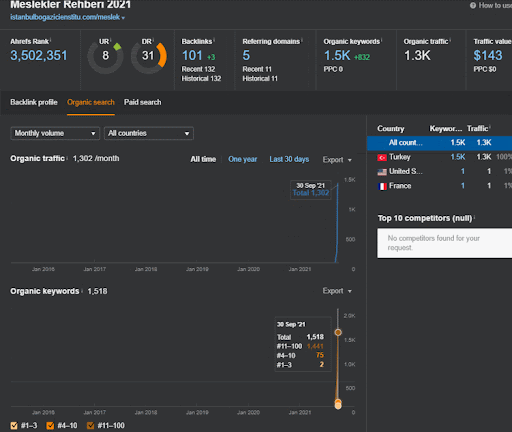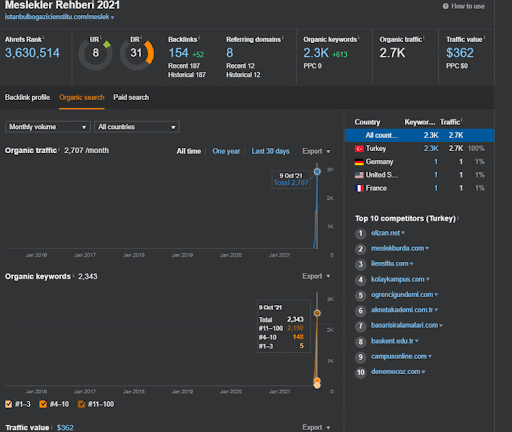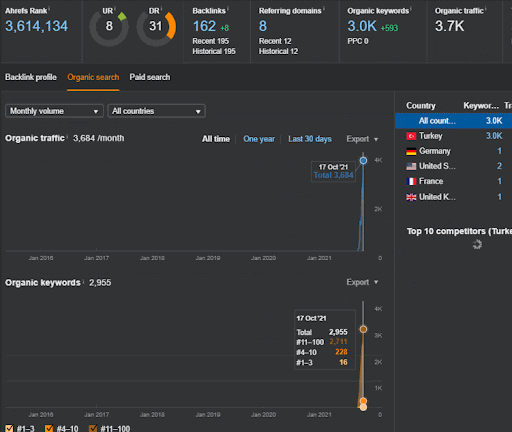
Вы можете наблюдать за первыми 20 днями органического изменения эффективности Второй контентной сети по сравнению с Проектом 1.
В этом контексте, всякий раз, когда Vizem.net публикует новый документ или всякий раз, когда IstanbulBogazici Enstitu публикует новую сеть семантического контента, первоначальный рейтинг становится лучше, чем раньше, а контент индексируется быстрее.
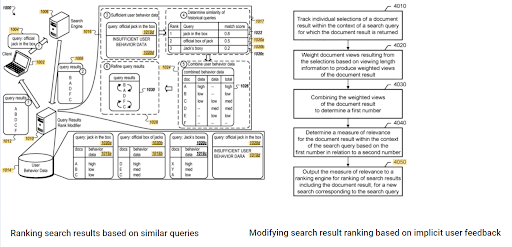
Выдающееся положение начального рейтинга и исторических данных можно увидеть между этими двумя взаимодополняющими патентами Google. Один предназначен для первоначальных и переоцененных документов на основе неявной обратной связи с пользователем. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 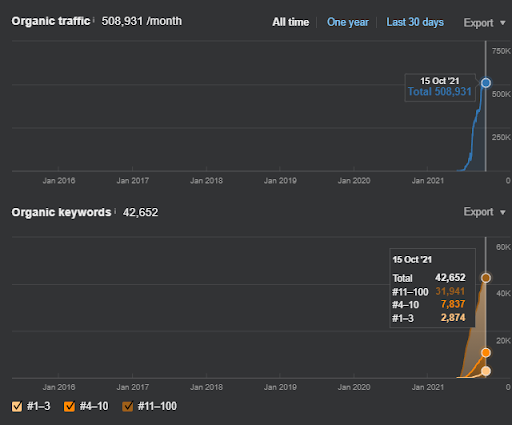
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 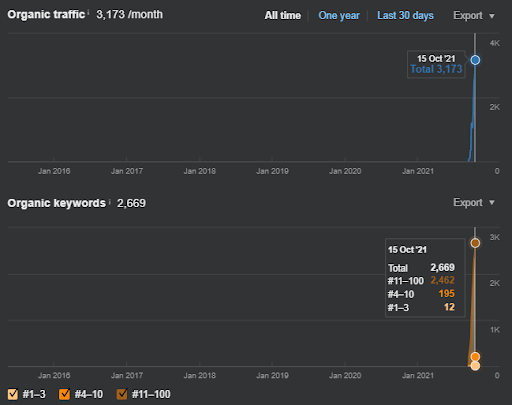
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 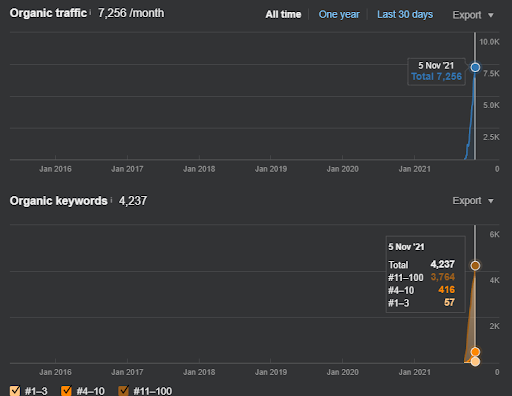
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 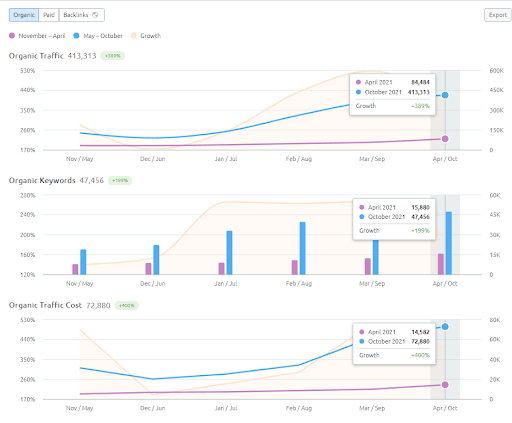
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Данные при сканировании³
 Учить больше
Учить большеWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 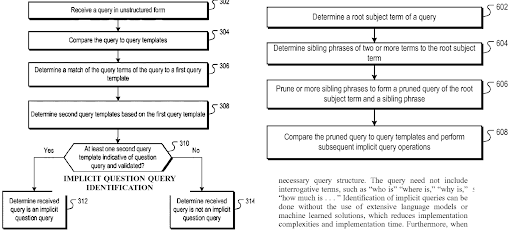
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Да. Вероятностное ранжирование и ранжирование ухудшенной релевантности являются основными столбцами семантической поисковой системы для понимания пользователей и создания наилучшей поисковой выдачи высочайшего качества, подготовленной для состояния возможностей. 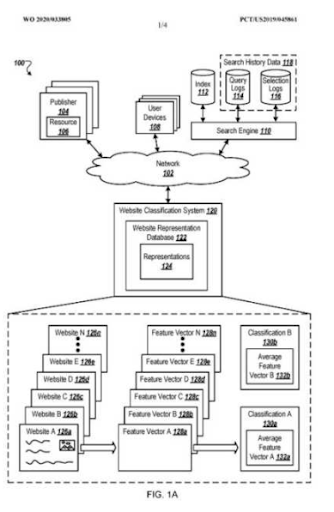
Ранее, чтобы сделать «дизайн веб-сайта, внешний вид или тональность» аргументом в пользу изучения репрезентации веб-сайтов, Билл Славски написал «Векторы репрезентации веб-сайтов».
Что такое шаблон намерения поиска?
Шаблон намерения поиска может быть представлен необходимостью, стоящей за шаблоном запроса. Шаблон запроса-документа может быть объединен на основе шаблона намерения. Наличие шаблона поискового намерения с возможным пониманием «Ухудшенного ранжирования релевантности» и «Вероятностного ранжирования» поможет создать наилучшую возможную поисковую активность и охват поискового намерения с правильным порядком. При создании сети семантического контента наиболее важным является корректировка шаблона документа-запроса-намерения на основе контекста источника для завершения семантической сети на основе предметной области за счет улучшения контекстного охвата для повышения доверия на основе знаний и тематического авторитета. . 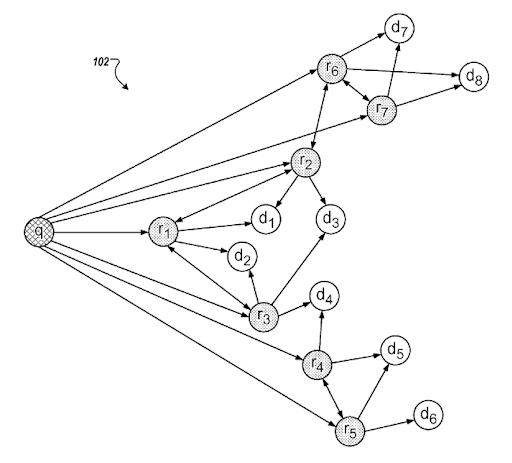
Раздел из Google «Уточнения запросов на основе предполагаемого намерения». Он работает через кластеры запросов и шаблоны намерений с семантическими связями. Вы можете испытать это на разных уровнях таксономии фраз.
Прежде чем перейти к некоторым конкретным примерам и предложениям, которые помогут вам создать лучшую сеть семантического контента, я должен сказать вам, что даже простая версия этого тематического исследования SEO требует высокого уровня понимания поисковых систем и навыков общения. Таким образом, хотя я чувствую, что даю информацию высокого уровня, я знаю, что курс семантического SEO, который я создам, покажет вам больше и лучше конкретных примеров. 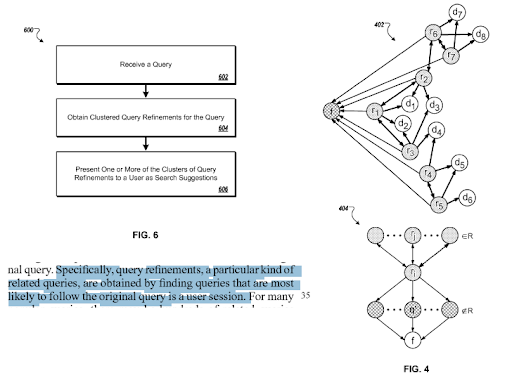
В том же патенте объясняются правильные связи между различными «путями запросов» и «изменениями контекста».
Что вы должны знать об использовании сетей семантического контента?
Чтобы создать сеть семантического контента, иногда даже простое краткое описание семантического содержания и дизайн могут занять один час, если вы поместите все соответствующие детали на основе лексической семантики или типов отношений между сущностями и фразами. Используя одновременно несколько точек зрения, таких как индексирование на основе фраз и векторы слов или векторы контекста для расчета контекстуальной релевантности контента в целом для контекстуальной области или его релевантности на основе отдельных типов подконтента, он требует высокого уровня семантического понимания поисковой системы.
Таким образом, использование генеративной методологии облегчит работу с концепциями, которые я объяснил вам выше, потому что даже если вы идеально подготовите каждую часть сети семантического контента, авторы и писатели не смогут ее написать, или контент-менеджеры не сможет следовать вашему видению. Таким образом, это может утомить вас напрасно и заставить вас покинуть проект, как это сделал я для некоторых из этих тематических исследований SEO, после того, как я докажу концепцию достаточно живым и проверяемым способом.
Предложения ниже будут только для простых исполняемых и кратких шагов, которые помогут вам.
1. Не используйте фиксированные ссылки на боковую панель из каждой сети семантического контента.
Каждая ссылка должна иметь описание связи между двумя гипертекстовыми документами, как и каждое слово на веб-странице. Использование семантического HTML может помочь указать положение и функцию документа на веб-странице, помогая поисковым системам по-разному взвешивать разделы с точки зрения контекста.
В примере с Vizem.net я не использовал такой же дизайн боковой панели. Боковая панель не показывала ни последние посты, ни самые критические. Боковые панели показывают только атрибуты центральных сущностей, и они не являются фиксированными, они являются динамическими. Другими словами, на основе иерархии в тематической карте сети семантической контентной сети изменяются, даже если они находятся на боковой панели. 
Размышление о моделях «Разумный серфер» и «Осторожный серфер» может помочь SEO-специалисту создать лучшую релевантность между различными гипертекстовыми документами.
Кроме того, ссылка течет с точки зрения известности, а популярность должна соответствовать контексту источника из наилучших возможных связей. Ниже вы можете увидеть разделы боковой панели с скорректированными семантическими HTML-кодами. 
В соответствии с иерархией статьи, которая активна в сеансе пользователя, вкладки, порядок вкладок, ссылки внутри вкладок будут меняться. Приведенный выше пример взят из приведенной ниже иерархии хлебных крошек. ![]()
2. Поддержите сети семантического контента с помощью PageRank
Даже если внешний PageRank не является обязательным из внешних источников, если вы сможете его использовать, вы поймете, что первоначальный рейтинг и повторный рейтинг будут лучше. В обоих этих проектах я их не использовал, но на этот раз это не было целью. У Vizem.net были проблемы с экономикой, и я не хотел тратить бюджет на цифровой PR и аутрич. Для Istanbul BogaziciEnstitusu я организовал пару «локально взаимосвязанных источников», чтобы подтвердить подлинность источника по конкретной теме, но опять же, компания не смогла реализовать это из-за проблем с бюджетом и организационной дисциплиной. 
Обнаружение дубликатов документов, специфичных для запроса, является важным аспектом поисковых систем, поскольку PageRank может помочь отфильтровать документ как ценный, даже если он дублируется. Поскольку высокоорганизованные сети семантического контента могут быть похожи друг на друга, поток PageRank и исторические данные полезны.
Когда дело доходит до выбора внешней точки потока PageRank для этих типов сетей семантического контента, используйте источники с историческими данными. В моем случае я установил эти конечные точки PageRank раньше, до того, как запустил и опубликовал первую сеть семантического контента. Таким образом, я смог получить внешние ссылки от прямых конкурентов, но когда я опубликовал сеть семантического контента, конкуренты отказались от ссылки на источник, потому что увидели массовое увеличение источника как конкурента.
Эта ситуация подводит нас к третьему предложению. Если бы мы могли использовать поток PageRank из внешних ссылок, процесс повторного ранжирования был бы быстрее, а первоначальный рейтинг был бы выше.
3. Используйте разные анкорные тексты из нижнего колонтитула, заголовка и основного контента для важных частей сети семантического контента.
Якорные тексты или «текст ссылки» с точки зрения поисковой системы сигнализируют о релевантности гипертекстового документа другому. Согласно исходному документу PageRank, количество ссылок пропорционально потоку PageRank. Но позже Google изменил это, чтобы предотвратить «наполнение ссылками» и ограничил ссылки, которые действительно могут пройти PageRank. На основе этого разрабатываются модели TrustRank, Cautious Surfer, Hilltop Algorithm или Reasonable Surfer. 
Это две ссылки на две разные сети семантического контента для BogaziciEnstitusu, но, поскольку я не реализовал техническое SEO или улучшения UX, вы можете осознать «дешевизну» дизайна кнопок.
Согласно Google, одна и та же ссылка не может передать PageRank второй раз на другую веб-страницу, в то время как PageRank будет передан только по первой ссылке. И в исходной форме алгоритма PageRank гипертекстовый документ может ссылаться на себя, чтобы улучшить свой PageRank, или можно использовать переадресацию 301 для получения PageRank целевого документа ссылки. Обе эти ситуации создали старые методы Black Hat, такие как временное перенаправление веб-страницы на другую только для того, чтобы получить ее PageRank. Это было в те дни, когда SEO-специалисты могли видеть PageRank веб-страницы из Google Search Console или SERP. Позже Google начал ослаблять PageRank с каждым перенаправлением, а Дэнни Салливан объяснил, что 301 перенаправление полностью пройдет PageRank. Помимо всех этих изменений, здесь важно то, что даже если вторая ссылка не проходит PageRank, она все же передает релевантность текста ссылки. 
Важные разделы сети семантического контента были связаны с домашней страницей на основе «промежуточных уточнений запроса», которые включают «глаголы, предикаты» или «действия искателя».
Таким образом, основные разделы сети семантического контента должны быть связаны из меню верхнего и нижнего колонтитула с разделами более высокой таксономии, а тексты ссылок должны отличаться друг от друга. В этих примерах я использовал ссылки в заголовке с заметными, но короткими текстами ссылок, в то время как примеры в нижнем колонтитуле были длиннее. 
Раздел «Индексирование тега привязки в системе поискового робота» обобщает важность текста привязки и текста аннотации для позиционирования веб-страницы в кластерах запросов и кластерах веб-страниц.
Если раздел Semantic Content Network слишком заметен, чтобы правильно передать PageRank и приоритет сканирования, я связал наиболее важные разделы с правильными текстами ссылок и пояснительными абзацами, которые включают заметные атрибуты с различными вариантами соответствующих N-грамм. 
Это вторая связанная область с главной страницы Vizem.net, она находится за аккордеоном, фокусируется на странах в запросах и связывает среднюю часть сети семантического контента.
Примечание. Вокруг якорных текстов всегда использовался запланированный «аннотационный текст», чтобы повысить точность цели ссылки.
4. Ограничьте количество ссылок и сопоставьте настольные и мобильные ссылки и основной контент.
В обоих проектах разрешено иметь менее 150 внутренних ссылок на веб-страницу. С помощью семантического HTML места ссылок и функции ссылок становятся понятными для поисковых роботов. У IstanbulBogazici Enstitusu было более 450 ссылок на веб-страницу, и некоторые из них были самостоятельными ссылками (ссылка с той же страницы на ту же страницу). Хуже всего то, что половины этих ссылок не было в мобильной версии контента. 
Оценка удержания URL, оценка сканирования и другие типы оценок могут использоваться для определения заметности ссылки во внутренней карте URL-адресов, а теги идентификации документов на разных уровнях могут использоваться для сортировки индекса на основе независимых от запроса оценок релевантности.
Поскольку Google использует индексирование только для мобильных устройств, если контент не существует в мобильной версии, он будет проигнорирован и не будет использоваться для оценки релевантности и ранжирования. Таким образом, контент для мобильных устройств и настольных компьютеров был настроен так, чтобы соответствовать друг другу. Даже если Google допускает несоответствие контента между настольной и мобильной версиями, это все равно затрудняет понимание и ранжирование веб-страницы для поисковых систем. 
Поисковая система может создать карту сайта для веб-сайта, и эта карта сайта может быть повторно сгенерирована в цикле, если ссылки и метаданные URL-адреса не совпадают между пользовательскими агентами или временными шкалами. Таким образом, важно, чтобы путь сканирования был коротким, очередь сканирования — короткой, а внутренние ссылки — непротиворечивыми.
Наряду со ссылками между различными веб-страницами также используются ссылки на подразделы веб-страниц с «таблицей содержания» и «Фрагментами URL». Эти фрагменты URL-адреса нацелены на определенный подраздел веб-страницы с правильным названием, и конкретный раздел был помещен в тег раздела с h2. С помощью фрагментов URL-адресов со «внутристраничными навигационными ссылками» направить пользователя из поисковой выдачи в определенный раздел веб-страницы стало проще, а нижние разделы контента стали более заметными для удовлетворения потребности, стоящей за запрос.
5. Дисциплина военного уровня для ваших SEO-проектов
Это совершенно другая тема, и можно написать еще одну статью, чтобы определить, что означает военная дисциплина или почему она полезна для SEO-проекта. Но я должен сказать вам, что за последние 2 месяца я обучил множество генеральных директоров и оптимизаторов из других агентств вместе с их командами, чтобы увидеть, будет ли мой дизайн курса работать хорошо или нет.
Всякий раз, когда я вижу успех и высокий уровень понимания учебных занятий, которые я провожу, я проявляю сильную волю и настойчивость. Основная проблема заключается в том, что семантическое SEO намного сложнее, чем другие SEO-вертикали. Техническое SEO универсально, и для каждого шага есть даже письменные руководства. OnPage SEO или WUX и дизайн макета можно отслеживать с помощью числовых измерений. Когда дело доходит до семантики, это практика объединения точки зрения машины, работающей на основе сложной адаптивной системы, с хомо-сапиенсами, которые не понимают, как работает машина.
Это различие требует бетонного основания, которое должно быть заложено с первого дня проекта. В большинстве случаев я использую приведенные ниже правила.
- Дизайн контента и сеть семантического контента не обязательно должны быть логичными для автора или писателя.
- Задача контент-менеджера — проверить совместимость контента с дизайном контента.
- Задачей автора является написание контента с соответствующей информацией, которая включает в себя высокий уровень точности и детализации.
- Ссылки, определения, доказательства, сравнения, предложения, ссылки должны быть сделаны с конкретными примерами, а не с пухом.
- Каждое лишнее слово — это разбавление контекста и концепции.
Когда вы читаете, это может показаться простым в реализации, но это не так просто. Таким образом, я могу сказать, что я даже собирался уволить некоторых из своих сотрудников. Я рад, что я этого не сделал, по крайней мере, сейчас. В нормальных условиях будет много вопросов, которые вам будут задавать, если владелец вопроса не SEO или владелец компании, не отвечайте. Сохраните свою энергию в хранилище данных поисковой системы, где будут храниться ваши положительные отзывы, а не избыточные и нерелевантные отзывы для ранжирования.
6. Расширьте источник с учетом контекста
Этот раздел полностью посвящен пониманию потребности Google в создании MuM. При разработке тематической карты она будет включать в себя множество сетей семантического контента, которые обеспечат лучшую базу знаний на уровне сайта. Таким образом, при публикации этих подразделов они должны иметь возможность подключаться к контексту источника, иначе он может изменить то, как поисковая система видит источник, и тема веб-сайта может переключиться на другую предметную область. Например, соединение вещей вокруг понятий и областей интересов с возможными действиями требует понимания сложных связей значений друг с другом. Сделать эти связи понятными пользователю, писателю и машине одновременно — процесс создания сети семантического контента. 
Для этого каждый новый раздел веб-сайта должен быть связан с центральным разделом тематической карты. Эти контекстуальные мосты можно увидеть из собственного дизайна и объяснения Google LaMDA.
Я сталкиваюсь с множеством вопросов типа «стоит ли писать на другую тему», «если у меня две разные ниши, не повредит ли это?». Если вы соедините все эти подразделы, сегменты веб-сайта как сильно связанные компоненты, эти сети семантического контента будут поддерживать друг друга для лучшего ранжирования, а не разделять идентичность бренда и актуальный авторитет на две разные и нерелевантные темы.
7. Создайте реальный трафик и проведите аудит с помощью пользовательской сегментации Google Analytics.
Фактический трафик связан с RankMerge так же, как доверие, основанное на знаниях, связано с PageRank. Вскоре я думаю написать еще одну статью под названием «Когда PageRank лжет…», чтобы объяснить, почему поисковая система пытается повлиять на PageRank с помощью побочных сигналов. На самом деле PageRank не является окончательным сигналом, показывающим авторитет, опыт и надежность источника. Это может быть сигналом для ранжирования и фактором, но одному ему нельзя доверять. RankMerge — это процесс объединения трафика веб-сайта и PageRank таким образом, чтобы веб-сайт мог быть понятен поисковой системе. Высокий PageRank и низкий трафик могут сигнализировать о «непопулярном трафике» или «манипулировании PageRank».
Таким образом, чтобы улучшить исторические данные источника, я использовал сезонные SEO-события и увеличил запросы «бренд + общий термин». Прямой трафик и веб-страницы с закладками увеличиваются за счет фактического и подлинного трафика.
Эти типы данных помогают поисковой системе доверять им, чтобы ранжировать их все выше и выше в поисковой выдаче.
Чтобы иметь возможность проверять этот фактический трафик, поступающий из сети семантического контента, SEO-специалист может создать пользовательский сегмент из Google Analytics, чтобы увидеть, как они поступают в виде прямого трафика. Кроме того, можно создавать настраиваемые цели, например создание возможного пути поиска из первой сети семантического контента во вторую сеть контента. Это доказательство того, что семантическая сеть построена вокруг интересов, концепций и возможных действий, связанных с поиском.
Ниже вы найдете только один пример для одной из веб-страниц, размещенных в первой сети семантического контента, для демонстрации полученного прямого трафика через органический трафик. 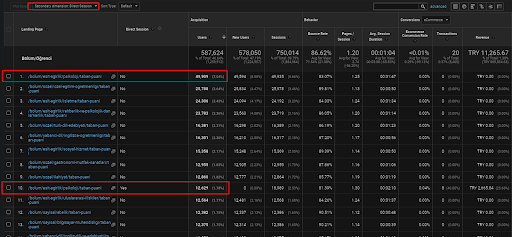
За последние 3 месяца только одна веб-страница из первой сети семантического контента использовалась 49 000 органических пользователей. И 12 900 дополнительных пользователей пришли в виде прямого трафика, который впервые был получен за счет органического поиска. И показатели сеанса/страницы и средняя продолжительность сеанса выше для этих сегментов пользователей.
Как было сказано ранее, поисковая система может группировать запросы, документы, намерения, концепции, интересы, действия, но она также может группировать пользователей. Если группа пользователей оставляет положительные отзывы при создании ценности бренда, добавляя эти веб-страницы в закладки, вводя текст напрямую в адресную строку и выполняя поиск по общим терминам вместе с названием бренда, это показывает, что источник повышает свой авторитет, а поисковая система способен распознавать все из поисковой выдачи, Chrome и собственных DNS-адресов. 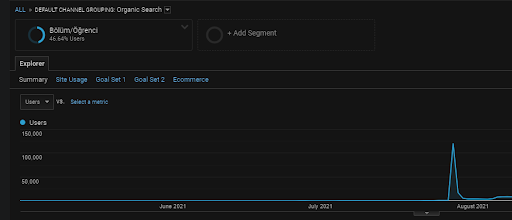
Выше вы можете увидеть пользовательский сегмент First Content Network. Вы можете создать пользовательский сегмент для каждой сети семантического контента с настраиваемыми целями, а также добавить сегменты субпользователей для сетей семантического субконтента.
8. Поддержка сетей семантического контента с подразделами, основанными на действиях поиска.
Этот раздел также посвящен разрешению атрибутов объекта и анализу, который является другой темой. Но, проще говоря, некоторые атрибуты этих сущностей, основанные на контекстных доменах, должны быть помещены в более низкую иерархию, а не в верхнюю иерархию. В этом случае «Vizem.net» может дать лучший пример, в то время как для Bogazici Enstitusu это можно продемонстрировать с помощью «Зарплат по профессиям» и «Экзаменационных баллов университетов». Эти два важных атрибута были размещены на основе шаблонов запросов и документов в семантических сетях субконтента. 
Идентификация семантических единиц внутри поискового запроса — это еще один патент Google, который делит фразы на разные семантические категории и объединяет релевантность документа на основе его близости ко всем вариантам запроса.
В предыдущем примере SEO я не следовал этому типу структуры, я создал путь сканирования на основе «хронологии» и строго ограниченных внутренних ссылок. В этих статьях количество размещенных внутренних ссылок основного контента выше, чем в предыдущем.
9. Используйте тематические слова в URL-адресах
Если Google обнаруживает два разных URL-адреса с одинаковым содержанием без какого-либо сигнала канонизации, он выбирает короткий из них в качестве канонического. Потому что короткие URL-адреса легче анализировать, разрешать и запрашивать. Когда у вас есть триллионы веб-страниц, которые вы обновляете миллиарды раз каждый день, даже буквы в URL-адресах могут показать «баланс стоимости и качества» веб-сайта. Как я уже говорил, «стоимость извлечения» должна быть ниже, чем «стоимость отсутствия извлечения». Если вы хотите, чтобы поисковая система вас понимала, вы должны поместить «упорядоченные и дополнительные контекстные сигналы» на каждый уровень, включая URL-адреса. 
Раздел из рейтинга, основанного на доказательствах, путем агрегирования доказательств. Это объясняет, как ответ может быть сопоставлен с вопросом.
В этом контексте большую часть времени я использую одно слово в URL-адресе. Они могут отражать иерархию и структуру сети семантического контента. Некоторые до сих пор думают, что «количество слоев» в URL-адресе влияет на частоту сканирования, до 2019 года это было правдой. Но пока контент имеет смысл и удовлетворяет пользователей популярной или известной темы, такая ситуация не повлияет на него.
Чтобы продемонстрировать это, вы можете следовать примеру ниже.
- Корневой домен/семантическая-контент-сеть-1/тип-1/суб-контент-сеть-часть-для-типа-1
- Корневой домен/семантическая-контент-сеть-2/тип-2/суб-контент-сеть-часть-для-типа-2
Эти две сети семантического контента могут связываться друг с другом из одной и той же иерархии, а также могут связываться друг с другом на основе релевантности. Здесь есть еще кое-что, о чем мы можем поговорить, например, «Содержимое группировщика сущностей — Содержимое типа концентратора», но это тема другого дня.
Примечание. Планируемая третья семантическая информационная сеть может также обрабатываться как «Концептуальная информационная сеть группировщика». И, если он будет опубликован, с эффектом Второй сети семантического контента общий органический трафик может составить более 3 миллионов сеансов в месяц.
10. Поймите разницу между вложением и соединением
Как практическое методологическое различие, соединение - это соединение похожих вещей друг с другом на основе контекстуальной области, в то время как вложение - это группировка аналогичного контента с одной и той же целью вместе. Эта кластеризация поможет поисковой системе быстрее находить контент, похожий друг на друга, и будет проще создавать оценку качества источника для этих групп или этого вложенного контента на основе семантической сети. 
Представьте, что есть два разных пути сканирования, как показано ниже.
- Путь сканирования 1: URL-адреса обнаруживаются случайным образом, без шаблона, сходства и контекстуальной релевантности.
- Путь сканирования 2: находит URL-адреса, которые имеют смысл даже из самого URL-адреса, с шаблоном, высоким уровнем сходства и релевантности в зависимости от контекста.
Если даже из пути сканирования контент имеет смысл, «начальное ранжирование» и «повторное ранжирование» будут лучше благодаря «запуску повторного ранжирования на основе понимания покрытия поисковой системой».
Примечание. Правильное использование внутренних ссылок с фразовой таксономией важно для вложения и соединения.
Это подводит нас к краткому обмену двумя последними практическими методологиями. И этот раздел опять же связан с высоким уровнем дисциплины и организованности. 
Патент Тристана Апстилла и Стивена Д. Бейкера на распознавание одновременно встречающихся терминов в списках HTML. Важность этого патента заключается в том, что он показывает ценность одного HTML-списка для определения совпадающих списков терминов для темы или части таксономии фраз.
11. Поймите, когда публиковать сеть семантического контента с отрегулированной периодичностью
Это было объяснено ранее, но в одном из этих тематических исследований SEO я опубликовал около 400 единиц контента за один день. Что касается другого, то я внезапно начал публиковать только 10-15 контента, затем со временем я стабильно увеличивал скорость, пока не начались экономические проблемы, связанные с Covid.
Если новый источник создает новую сеть семантического контента, опубликовать ее в первый день может быть немного сложнее, чем вы думаете, проверить все внутренние ссылки, грамматику и информацию на веб-странице не так просто. Но если весь контент относится только к одной теме и шаблону запроса, а источник не имеет истории по этой теме, публикация большей части сети семантического контента имеет такие преимущества, как более быстрое индексирование, понимание и переоценка.
В моей ситуации также имело место историческое событие с сезонностью. Итак, моя цель состояла в том, чтобы иметь достаточный уровень средней позиции, пока я не смогу пройти проверку поисковой системой на предмет конкретных объектов и поисковых действий по старым источникам. Таким образом, я опубликовал первую сеть семантического контента с высоким уровнем подготовки за 45 дней до сезонного события.
Затем вы можете увидеть, как поисковая система неоднократно проверяла источник, как показано ниже. 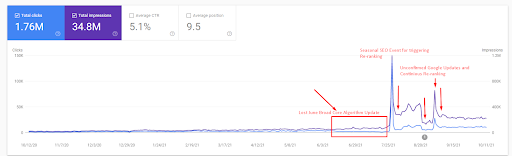
Более подробное объяснение можно найти ниже. 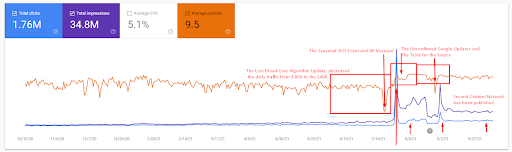
Быструю проверку фактов можно найти ниже для объяснения скриншота выше.
- Обновление алгоритма Broad Core уменьшило трафик сайта более чем на 200%.
- Сайт также потерял более 15 000 запросов.
- Это повлияло на общую индексацию источника для новой сети семантического контента, поскольку в подробной статье SEO Case Study было объяснено лучше.
- Благодаря Сезонному SEO-событию переранжирование произошло раньше, а после Сезонного SEO-события поисковая система нормализовала ранжирование источника на основе фактического трафика во время неподтвержденных обновлений.
- Запросы и рейтинги, полученные благодаря сети First Semantic Content Network и Seasonal Event, были защищены и улучшены.
- Первая сеть семантического контента также поддерживала новую и вторую сеть семантического контента.
Потеря запросов и средняя потеря ранжирования также могут быть видны из Ahrefs, как показано ниже. Вы можете проверить эффект обновления Google Broad Core Algorithm (GBCAU) за июнь 2021 года вместе с эффектом неподтвержденного обновления. 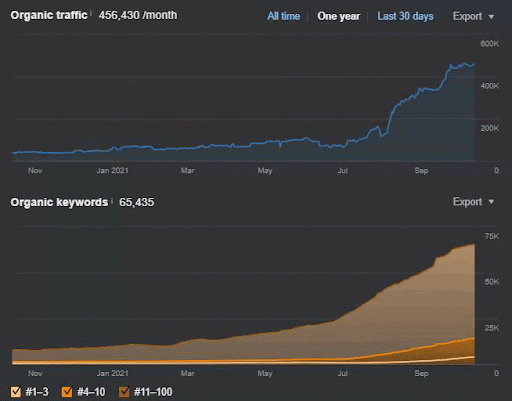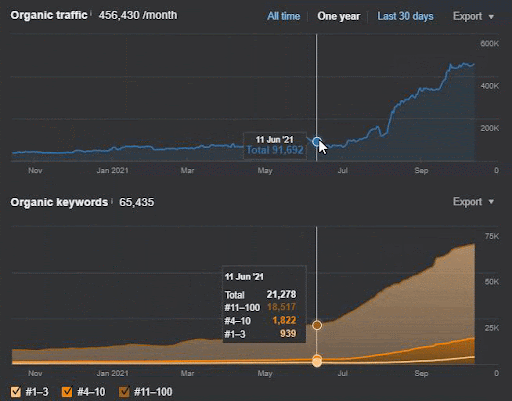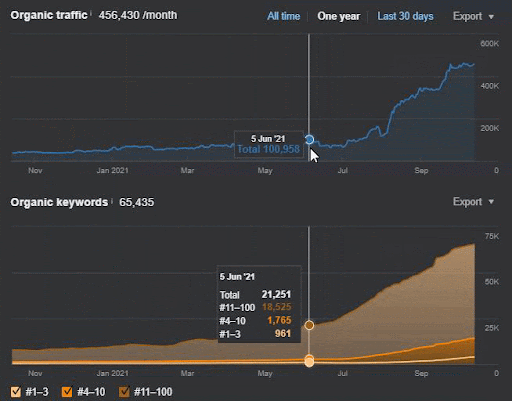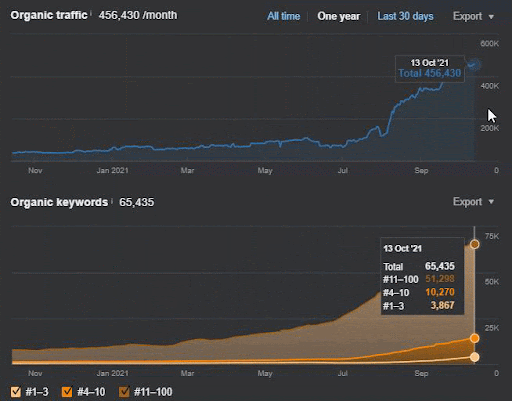
Таким образом, использование сети семантического контента с несколькими возможными стратегиями является необходимостью. Даже если GCBAU потерян, благодаря другим факторам, связанным с поисковой системой, природа может помочь SEO. Таким образом, вы можете себе представить, почему объяснить эти вещи автору или клиенту сложнее, чем техническое SEO. Семантическая поисковая оптимизация не использует числовые значения, она использует теоретические знания, которые исходят от понимания поисковых систем через патенты, исследовательские работы, опыт и исторические объявления.
12. Используйте оптимизацию предложений на странице для лучшей фактической структуры
Честно говоря, даже 10-й листинг — это совершенно новая тема, и здесь может потребоваться написать даже 20 000 слов. Но начну с простого примера.
- Х есть Y.
- Y есть Х.
Для примеров предложений выше вы можете понять вещи ниже.
- Приведенные выше предложения не являются дублирующим содержанием.
- Предложения выше дублируются.
- Реляционные объяснения между двумя предложениями одинаковы.
- Метки семантических ролей отличаются на 100%.
- Результат распознавания именованных объектов на 100 % такой же.
Оптимизация предложений на странице связана с алгоритмами генерации вопросов и технологиями сопряжения вопросов и ответов. Формат вопроса требует определенного типа предложения. И на определенные типы вопросов следует отвечать определенными типами предложений. Оптимизация структуры предложения повлияет на формат контента, NER и извлечение фактов. 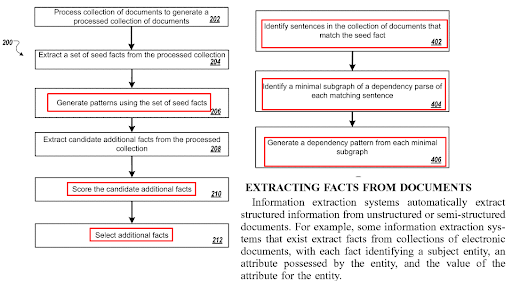
Триплеты (один объект, два субъекта) могут быть извлечены и проверены на точность быстрее. Два похожих предложения не означают, что они повторяются, это означает, что они близки друг другу по структуре предложения. Пока предложение отличается, использование похожих предложений в похожих шаблонах документов для разных пар запрос-намерение является необходимостью для создания сети семантического контента. 
Четкие структуры предложений с правильным шаблоном полезны для того, чтобы части текста были более релевантными друг другу, помогая поисковой системе распознавать именованные сущности, субъекты, атрибуты, а также их значения друг для друга.
Это также поможет увидеть, какой раздел статьи можно сделать лучше, и в тематических сетях, где ваш контент лучше ранжируется по тем или иным типам пар слов, векторам слов и намерениям. Потому что, если определенные типы структур предложений для определенных типов вопросов можно наблюдать на нескольких веб-страницах, это поможет для расширенных SEO-тестов A / B с бесконечным количеством образцов данных и тестовых образцов. Вы можете создать несколько дизайнов предложений на странице, чтобы проверить, как поисковая система извлекает факты для сравнения. 
Когда дело доходит до предоставления фактов, следует помнить о «Хранилище знаний» и Луна Донг.
13. Предоставляйте информацию из реального мира с точностью и последовательностью, а не с пустыми мнениями.
Точность здесь означает возможность сравнения с числовыми значениями или концептуальными конкретными отношениями. Последовательность означает, что вы защищаете свою позицию для конкретного предложения. Например, не говорите, что «Продукт X лучше всего подходит для Y» для каждого обзора продукта, связанного с Y. Не давайте противоречивых предложений по всему сайту. И, если продукт лучший, каковы доказательства этого? Материал, размер или цвет и запах? Путаница в тексте означает, что вы используете ненужные словесные переходы, либо не рассказываете вещи, которые невозможно доказать, либо противоречащие истине.
В контексте этих неопределенных инструкций, которые поддерживаются некоторыми примерами, вы можете проверить одну из языковых моделей Google, которая называется KeALM.
Он предназначен для генерации текста из базы данных с помощью моделей преобразования данных в текст и для проверки точности содержимого. 
KELM является примером аудита точности для предложений с методами преобразования текста в данные.
Это также немного об определении «Триплет» и «Открытое извлечение информации для неизвестных сущностей», но, как вы понимаете, это краткая версия, и, думаю, я рассказал достаточно. По сути, когда вы предоставляете неверную информацию на своем веб-сайте, убедитесь, что Google может ее понять, чтобы снизить доверие к источнику, основанное на знаниях. Здесь вам также может понадобиться знать, что, поскольку вы можете расширить базу знаний, поисковая система может изменить свою собственную базу знаний на основе вашей информации, если у вас есть коррелированный источник с PageRank и доверие к базе знаний. с высокой точностью и уникальными триплетами.
14. Понимание дерева семантической зависимости для сущностей
Семантическое дерево зависимостей означает, что атрибуты, сигнализирующие об отношениях с другими сущностями, имеют между собой иерархическую зависимость. Семантическое дерево зависимостей можно наблюдать, проверяя несколько профилей и точек зрения сущностей, например, страна может быть членом организации, и как другая сущность эта организация может иметь некоторые другие атрибуты, которые можно отнести к связанным странам с предполагаемыми отношениями.
Ниже вы сможете увидеть простой пример непосредственно из поисковой системы. 
REALM — это метод, использующий семантические деревья зависимостей для извлечения информации из неоднозначного текста.
В открытой сети извлечение открытой информации может распознавать новые именованные сущности и извлекать те же самые сущности как сосуществующие с другими сущностями. Эти совпадения и взаимные атрибуты в статье могут назначать контекст и потенциальный тип отношения между сущностями. На основе соединений и типа объекта может быть создано семантическое дерево зависимостей. Та же логика применима и к лексической семантике. Слово «мальчик» имеет несколько возможных значений и некоторые другие значения. Например, мальчик — это мужчина и, возможно, подросток, не состоящий в браке. Его можно использовать и рядом с учеником. С другой стороны, слово «королева» включает в себя другие побочные и точные значения, такие как «женщина» и «быть губернатором». Таким образом, иметь что-то для управления — это естественная иерархия дерева семантических зависимостей, которая может сигнализировать о некоторых определенных типах шаблонов запросов, таких как «Королева…» или «Для Квен». These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 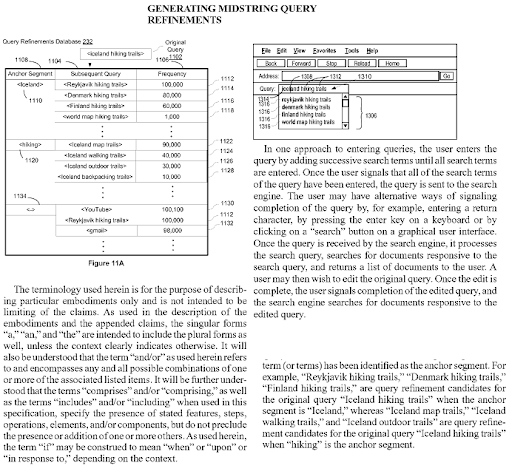
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.