
Управление сканированием и индексированием: SEO-руководство по robots.txt и тегам
Опубликовано: 2019-02-19Оптимизация краулингового бюджета и блокирование индексации страниц ботами — это концепции, знакомые многим SEO-специалистам. Но дьявол кроется в деталях. Тем более, что лучшие практики значительно изменились за последние годы.
Одно небольшое изменение в файле robots.txt или тегах robots может оказать существенное влияние на ваш сайт. Чтобы убедиться, что влияние на ваш сайт всегда положительное, сегодня мы собираемся углубиться в:
Оптимизация краулингового бюджета
Что такое файл robots.txt
Что такое теги Meta Robots
Что такое X-Robots-Tags
Директивы по роботам и SEO
Контрольный список лучших практик роботов
Оптимизация краулингового бюджета
У паука поисковой системы есть «допуск» на то, сколько страниц он может и хочет просканировать на вашем сайте. Это известно как «краулинговый бюджет».
Найдите краулинговый бюджет вашего сайта в отчете Google Search Console (GSC) «Статистика сканирования». Обратите внимание, что GSC представляет собой совокупность 12 ботов, не все из которых предназначены для SEO. Он также собирает ботов AdWords или AdSense, которые являются ботами SEA. Таким образом, этот инструмент дает вам представление о вашем глобальном краулинговом бюджете, но не о его точном перераспределении.
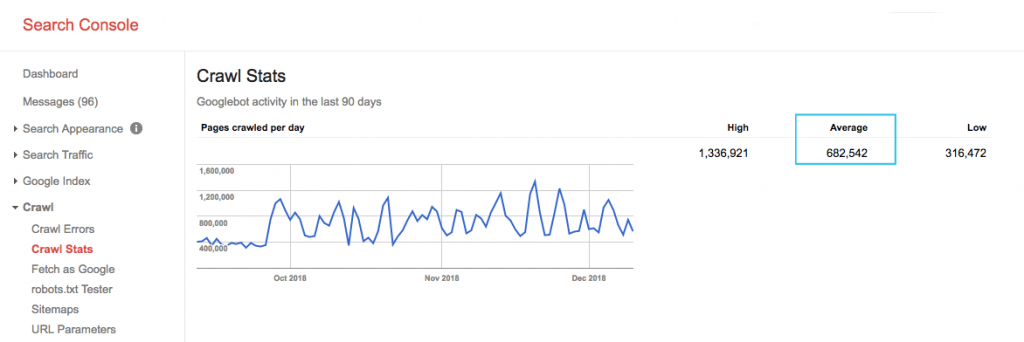
Чтобы число было более действенным, разделите среднее число страниц, просматриваемых за день, на общее количество просматриваемых страниц на вашем сайте. Вы можете запросить это число у своего разработчика или запустить неограниченное количество поисковых роботов. Это даст вам ожидаемый коэффициент сканирования, по которому вы сможете начать оптимизацию.
Хотите пойти глубже? Получите более подробную информацию об активности робота Googlebot, например о посещенных страницах, а также статистику других поисковых роботов, проанализировав файлы журналов сервера вашего сайта.
Существует много способов оптимизировать краулинговый бюджет, но проще всего начать с проверки отчета GSC «Покрытие», чтобы понять текущее поведение Google при сканировании и индексировании.
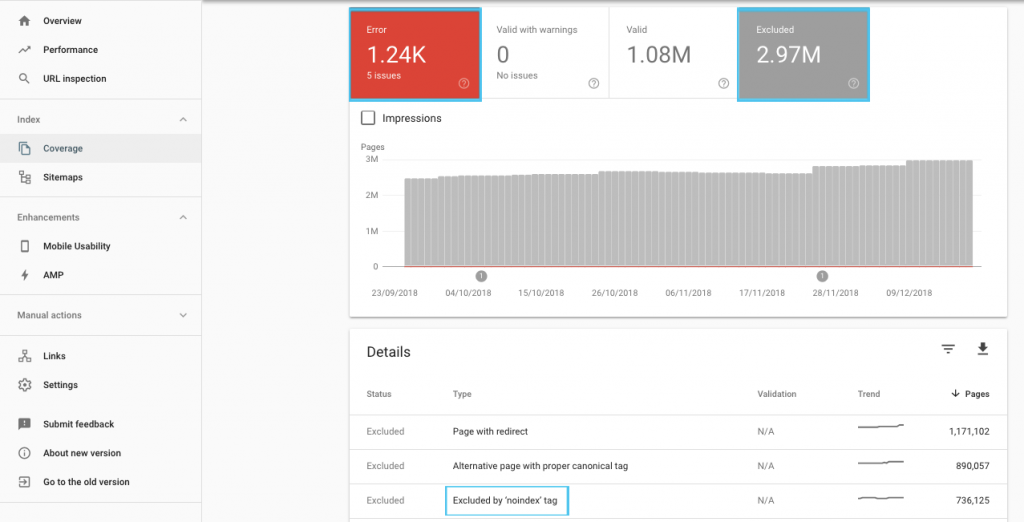
Если вы видите такие ошибки, как «Отправленный URL-адрес с пометкой «noindex»» или «Отправленный URL-адрес заблокирован файлом robots.txt», обратитесь к своему разработчику, чтобы исправить их. Для любых исключений роботов изучите их, чтобы понять, являются ли они стратегическими с точки зрения SEO.
В целом SEO-специалисты должны стремиться минимизировать ограничения сканирования для роботов. Улучшение архитектуры вашего веб-сайта, чтобы сделать URL-адреса полезными и доступными для поисковых систем, — лучшая стратегия.
Сами Google отмечают, что «надежная информационная архитектура, вероятно, будет гораздо более продуктивным использованием ресурсов, чем сосредоточение внимания на приоритизации сканирования».
При этом полезно понимать, что можно сделать с файлами robots.txt и тегами robots, чтобы управлять сканированием, индексированием и передачей ссылочного капитала. И, что более важно, когда и как лучше всего использовать это для современного SEO.
[Пример успеха] Управление сканированием ботов Google
 Читать тематическое исследование
Читать тематическое исследованиеЧто такое файл robots.txt
Прежде чем поисковая система просканирует любую страницу, она проверит файл robots.txt. Этот файл сообщает ботам, какие пути URL-адресов им разрешено посещать. Но эти записи являются только директивами, а не мандатами.
Robots.txt не может надежно предотвратить сканирование , как брандмауэр или защита паролем. Это цифровой эквивалент знака «пожалуйста, не входите» на незапертой двери.
Вежливые сканеры, такие как основные поисковые системы, обычно подчиняются инструкциям. Враждебные поисковые роботы, такие как скребки электронной почты, спам-боты, вредоносные программы и поисковые роботы, которые сканируют сайты на наличие уязвимостей, часто не обращают на это внимания.
Более того, это общедоступный файл . Любой может видеть ваши директивы.
Не используйте файл robots.txt для:
- Чтобы скрыть конфиденциальную информацию. Используйте защиту паролем.
- Чтобы заблокировать доступ к вашему промежуточному сайту и/или сайту разработки. Используйте аутентификацию на стороне сервера.
- Явно блокировать враждебные поисковые роботы. Используйте блокировку по IP-адресу или блокировку агента пользователя (также запрещайте доступ к определенному сканеру с помощью правила в вашем файле .htaccess или такого инструмента, как CloudFlare).
На каждом веб-сайте должен быть действительный файл robots.txt с хотя бы одной группой директив. Без него всем ботам по умолчанию предоставляется полный доступ, поэтому каждая страница считается доступной для сканирования. Даже если это то, что вы намереваетесь сделать, лучше сделать это понятным для всех заинтересованных сторон с помощью файла robots.txt. Кроме того, без него журналы вашего сервера будут переполнены неудачными запросами robots.txt.
Структура файла robots.txt
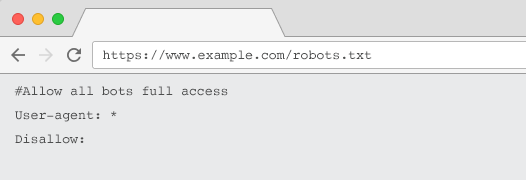
Чтобы поисковые роботы распознали ваш файл robots.txt, он должен:
- Текстовый файл с именем «robots.txt». Имя файла чувствительно к регистру. «Robots.TXT» или другие варианты не будут работать.
- Находиться в каталоге верхнего уровня вашего канонического домена и, при необходимости, поддоменов. Например, чтобы контролировать сканирование всех URL-адресов ниже https://www.example.com, файл robots.txt должен находиться по адресу https://www.example.com/robots.txt, а для subdomain.example.com — по адресу https://www.example.com/robots.txt. субдомен.example.com/robots.txt.
- Вернуть статус HTTP 200 OK.
- Используйте допустимый синтаксис robots.txt. Проверьте с помощью инструмента тестирования robots.txt в Google Search Console.
Файл robots.txt состоит из групп директив. Записи в основном состоят из:
- 1. User-agent: обращается к различным поисковым роботам. Вы можете создать одну группу для всех роботов или использовать группы для присвоения имен конкретным поисковым системам.
- 2. Запретить: указывает файлы или каталоги, которые должны быть исключены из сканирования указанным выше пользовательским агентом. Вы можете иметь одну или несколько таких строк в блоке.
Полный список имен пользовательских агентов и другие примеры директив можно найти в руководстве robots.txt на Yoast.
Помимо директив «User-agent» и «Disallow», есть несколько нестандартных директив:
- Разрешить: укажите исключения из директивы запрета для родительского каталога.
- Crawl-delay (Задержка сканирования): сдерживайте тяжелые поисковые роботы, сообщая ботам, сколько секунд ждать перед посещением страницы. Если у вас мало обычных сеансов, задержка сканирования может сэкономить пропускную способность сервера. Но я бы приложил усилия только в том случае, если сканеры активно вызывают проблемы с нагрузкой на сервер. Google не подтверждает эту команду, предлагает возможность ограничить скорость сканирования в Google Search Console.
- Clean-param: избегайте повторного сканирования дублированного контента, созданного динамическими параметрами.
- Без индексации: предназначен для управления индексацией без использования краулингового бюджета. Он больше официально не поддерживается Google. Хотя есть свидетельства того, что он все еще может оказывать влияние, он ненадежен и не рекомендуется такими экспертами, как Джон Мюллер.
@maxxeight @google @DeepCrawl Я бы не стал использовать там noindex.
— ???? Джон ???? (@JohnMu) 1 сентября 2015 г.
- Карта сайта . Оптимальный способ отправки вашей XML-карты сайта — через Google Search Console и инструменты для веб-мастеров других поисковых систем. Однако добавление директивы карты сайта в файл robots.txt поможет другим поисковым роботам, которые могут не предлагать вариант отправки.
Ограничения robots.txt для SEO
Мы уже знаем, что файл robots.txt не может предотвратить сканирование для всех ботов. Точно так же запрет поисковых роботов на странице не препятствует ее включению в страницы результатов поисковой системы (SERP).
Если у заблокированной страницы есть другие сильные сигналы ранжирования, Google может счесть ее релевантной для отображения в результатах поиска. Несмотря на то, что страница не просканирована.
Поскольку содержание этого URL-адреса неизвестно Google, результат поиска выглядит следующим образом:

Чтобы окончательно заблокировать отображение страницы в поисковой выдаче, вам нужно использовать метатег robots «noindex» или HTTP-заголовок X-Robots-Tag.
В этом случае не запрещайте страницу в robots.txt , потому что страница должна быть просканирована, чтобы тег «noindex» был виден и соблюдался. Если URL-адрес заблокирован, все теги robots недействительны.
Более того, если на странице накопилось много внешних ссылок, но Google не может сканировать эти страницы с помощью файла robots.txt, а ссылки известны Google, ссылочный вес теряется.
Что такое теги Meta Robots
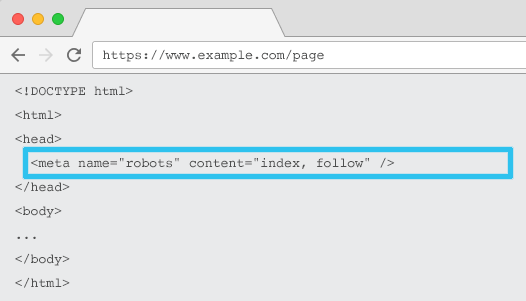
Мета name="robots", размещенная в HTML-коде каждого URL-адреса, сообщает поисковым роботам, следует ли и как "индексировать" контент и следует ли "следить" (то есть сканировать) все ссылки на странице, передавая ссылочный вес.
Используя общее метаимя = «роботы», директива применяется ко всем поисковым роботам. Вы также можете указать конкретный пользовательский агент. Например, метаимя="googlebot". Но редко требуется использовать несколько метатегов robots для установки инструкций для конкретных пауков.
При использовании метатегов robots необходимо учитывать два важных момента:
- Подобно robots.txt, метатеги являются директивами, а не мандатами, поэтому некоторые боты могут их игнорировать.
- Директива nofollow для роботов применяется только к ссылкам на этой странице. Возможно, сканер может перейти по ссылке с другой страницы или веб-сайта без указания nofollow. Таким образом, бот все равно может зайти на нежелательную страницу и проиндексировать ее.
Вот список всех директив мета-тегов robots:
- index: указывает поисковым системам показывать эту страницу в результатах поиска. Это состояние по умолчанию, если директива не указана.
- noindex: указывает поисковым системам не показывать эту страницу в результатах поиска.
- Follow: Сообщает поисковым системам переходить по всем ссылкам на этой странице, даже если страница не проиндексирована. Это состояние по умолчанию, если директива не указана.
- nofollow: указывает поисковым системам не переходить ни по одной ссылке на этой странице или передавать права собственности.
- all: Эквивалентно «index, follow».
- none: эквивалентно «noindex, nofollow».
- noimageindex: указывает поисковым системам не индексировать изображения на этой странице.
- noarchive: указывает поисковым системам не показывать кешированную ссылку на эту страницу в результатах поиска.
- nocache: То же, что и noarchive, но используется только Internet Explorer и Firefox.
- nosnippet: указывает поисковым системам не показывать метаописание или предварительный просмотр видео для этой страницы в результатах поиска.
- notranslate: указывает поисковой системе не предлагать перевод этой страницы в результатах поиска.
- unavailable_after: запретить поисковым системам индексировать эту страницу после указанной даты.
- noodp: в настоящее время устарел, когда-то не позволял поисковым системам использовать описание страницы из DMOZ в результатах поиска.
- noydir : теперь устарел, когда-то он не позволял Yahoo использовать описание страницы из каталога Yahoo в результатах поиска.
- noyaca: запрещает Яндексу использовать описание страницы из каталога Яндекса в результатах поиска.
Как задокументировано Yoast, не все поисковые системы поддерживают все метатеги роботов или даже четко понимают, что они поддерживают, а что нет.
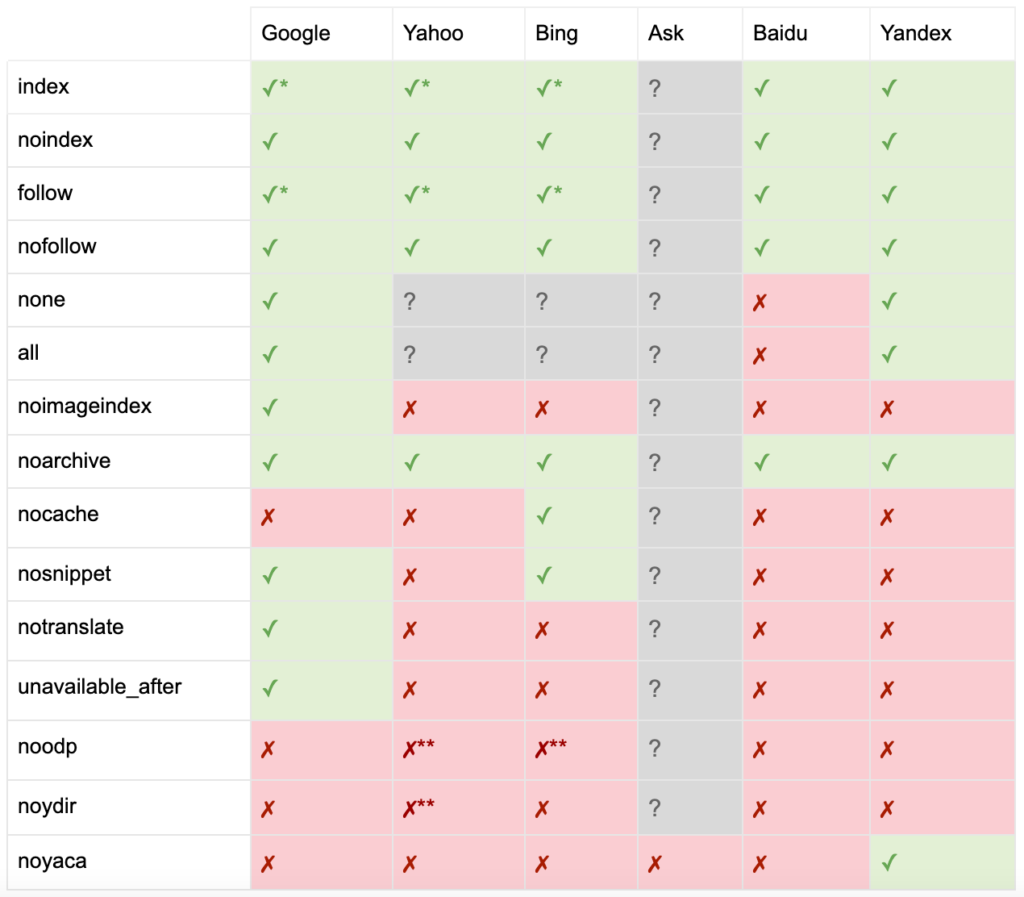
* У большинства поисковых систем нет специальной документации для этого, но предполагается, что поддержка исключающих параметров (например, nofollow) подразумевает поддержку положительного эквивалента (например, follow).
** Хотя атрибуты noodp и noydir все еще могут быть «поддерживаемыми», каталоги больше не существуют, и вполне вероятно, что эти значения ничего не делают.

Обычно для тегов robots устанавливается значение «индексировать, следить». Некоторые оптимизаторы считают добавление этого тега в HTML излишним, так как он используется по умолчанию. Контраргумент состоит в том, что четкая спецификация директив может помочь избежать любой человеческой путаницы.
Обратите внимание: URL-адреса с тегом «noindex» будут сканироваться реже и, если он присутствует в течение длительного времени, в конечном итоге приведет к тому, что Google будет использовать nofollow для ссылок на странице.
Редко можно найти вариант использования «nofollow» для всех ссылок на странице с метатегом robots. Чаще можно увидеть, что «nofollow» добавляется к отдельным ссылкам с использованием атрибута ссылки rel=»nofollow». Например, вы можете захотеть добавить атрибут rel=”nofollow” к пользовательским комментариям или платным ссылкам.
Еще реже встречаются варианты использования SEO для директив тегов роботов, которые не касаются базовой индексации и следят за поведением, таким как кэширование, индексация изображений, обработка фрагментов и т. д.
Проблема с метатегами robots заключается в том, что их нельзя использовать для файлов, отличных от HTML, таких как изображения, видео или документы PDF. Здесь вы можете обратиться к X-Robots-Tags.
Что такое X-Robots-Tags
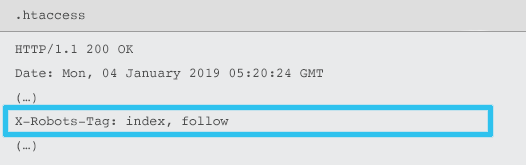
X-Robots-Tag отправляется сервером как элемент заголовка HTTP-ответа для заданного URL-адреса с использованием файлов .htaccess и httpd.conf.
Любая директива метатега robots также может быть указана как X-Robots-Tag. Тем не менее, X-Robots-Tag предлагает дополнительную гибкость и функциональность.
Вы можете использовать X-Robots-Tag вместо метатегов robots, если хотите:
- Контролируйте поведение роботов для файлов, отличных от HTML, а не только для файлов HTML.
- Управлять индексацией определенного элемента страницы, а не страницы в целом.
- Добавьте правила, определяющие, следует ли индексировать страницу. Например, если у автора более 5 опубликованных статей, проиндексируйте страницу его профиля.
- Применяйте директивы index & follow на уровне всего сайта, а не на уровне отдельных страниц.
- Используйте регулярные выражения.
Избегайте использования мета-роботов и тега x-robots на одной странице — это было бы излишним.
Чтобы просмотреть теги X-Robots, вы можете использовать функцию «Выбрать как Google» в Google Search Console.
Директивы по роботам и SEO
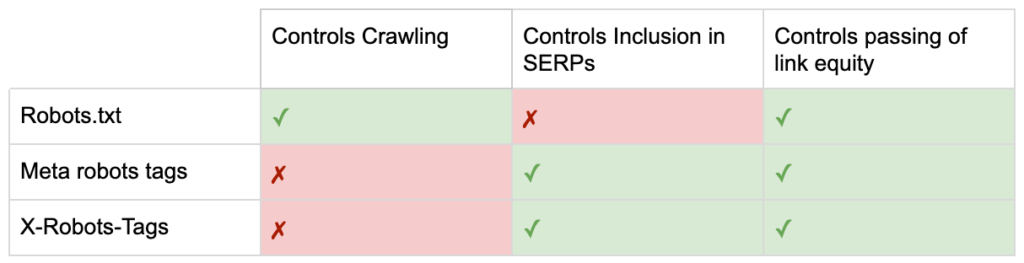
Итак, теперь вы знаете разницу между тремя директивами robots.
robots.txt ориентирован на экономию краулингового бюджета, но не препятствует показу страницы в результатах поиска. Он действует как первый привратник вашего веб-сайта, запрещая ботам доступ до тех пор, пока страница не будет запрошена.
Оба типа тегов robots сосредоточены на контроле индексации и передаче ссылочного веса. Метатеги robots вступают в силу только после загрузки страницы . В то время как заголовки X-Robots-Tag обеспечивают более детальный контроль и вступают в силу после того, как сервер ответит на запрос страницы.
Понимая это, SEO-специалисты могут изменить способ использования директив роботов для решения задач сканирования и индексации.
Блокировка ботов для экономии пропускной способности сервера
Проблема: анализируя файлы журналов, вы увидите, что многие пользовательские агенты используют пропускную способность, но мало что отдают.
- SEO-сканеры, такие как MJ12bot (от Majestic) или Ahrefsbot (от Ahrefs).
- Инструменты, которые сохраняют цифровой контент в автономном режиме, такие как Webcopier или Teleport.
- Поисковые системы, не соответствующие вашему рынку, такие как Baiduspider или Яндекс.
Неоптимальное решение: блокировка этих пауков с помощью robots.txt, так как это не гарантирует соблюдения и является довольно публичным заявлением, которое может дать заинтересованным сторонам конкурентную информацию.
Подход наилучшей практики: более тонкая директива блокировки пользовательского агента. Это можно сделать разными способами, но обычно это делается путем редактирования файла .htaccess, чтобы перенаправить любые нежелательные поисковые запросы на страницу 403 — Forbidden.
Страницы внутреннего поиска по сайту с использованием краулингового бюджета
Проблема. На многих веб-сайтах страницы результатов внутреннего поиска по сайту динамически генерируются на статических URL-адресах, которые затем расходуют краулинговый бюджет и могут вызвать проблемы с недостаточным содержанием или дублированием содержимого при индексировании.
Неоптимальное решение: запретить каталог с robots.txt. Хотя это может предотвратить ловушки поисковых роботов, это ограничивает вашу способность ранжироваться по ключевым запросам клиентов и таким страницам передавать ссылочный вес.
Передовой подход: сопоставьте релевантные запросы большого объема с существующими URL-адресами, удобными для поисковых систем. Например, если я ищу «телефон samsung», а не создаю новую страницу для /search/samsung-phone, перенаправляю на страницу /phones/samsung.
Если это невозможно, создайте URL-адрес на основе параметров. Затем вы можете легко указать, хотите ли вы, чтобы этот параметр сканировался или нет, в Google Search Console.
Если вы разрешаете сканирование, проанализируйте, достаточно ли высокого качества такие страницы для ранжирования. Если нет, добавьте директиву «noindex, follow» в качестве краткосрочного решения, пока вы разрабатываете стратегию улучшения качества результатов, чтобы помочь как SEO, так и пользовательскому опыту.
Блокировка параметров с помощью роботов
Проблема. Параметры строки запроса, такие как те, которые генерируются фасетной навигацией или отслеживанием, печально известны тем, что расходуют бюджет сканирования, создают дублирующиеся URL-адреса контента и разделяют сигналы ранжирования.
Неоптимальное решение: запретить сканирование параметров с помощью robots.txt или с помощью метатега robots «noindex», так как оба варианта (первое сразу, второе в течение более длительного периода) предотвратят поток ссылочного капитала.
Передовой подход: убедитесь, что у каждого параметра есть четкая причина существования, и внедрите правила упорядочения, которые используют ключи только один раз и предотвращают пустые значения. Добавьте атрибут ссылки rel=canonical к подходящим страницам параметров, чтобы объединить возможности ранжирования. Затем настройте все параметры в Google Search Console, где есть более детальная возможность сообщить о предпочтениях сканирования. Дополнительные сведения см. в руководстве по обработке параметров Search Engine Journal.
Блокировка областей администратора или учетной записи
Проблема: запретить поисковым системам сканировать и индексировать любой частный контент.
Неоптимальное решение: использование robots.txt для блокировки каталога, так как это не гарантирует, что частные страницы не попадут в поисковую выдачу.
Передовой подход: используйте защиту паролем, чтобы предотвратить доступ сканеров к страницам, и отмените директиву «noindex» в заголовке HTTP.
Блокировка маркетинговых целевых страниц и страниц благодарности
Проблема: часто вам нужно исключить URL-адреса, не предназначенные для обычного поиска, такие как выделенная электронная почта или целевые страницы кампании с ценой за клик. Точно так же вы не хотите, чтобы люди, которые не конвертировались, посещали ваши страницы благодарности через поисковую выдачу.
Неоптимальное решение: запретить файлы с robots.txt, так как это не помешает включению ссылки в результаты поиска.
Лучший подход: используйте метатег noindex.
Управление дублирующимся контентом на сайте
Проблема: Некоторым веб-сайтам требуется копия определенного контента для удобства пользователей, например версия страницы для печати, но они хотят, чтобы каноническая страница, а не дубликат, распознавалась поисковыми системами. На других веб-сайтах дублированный контент возникает из-за плохих методов разработки, таких как отображение одного и того же товара для продажи по нескольким URL-адресам категорий.
Неоптимальное решение: запрет URL-адресов с помощью robots.txt предотвратит передачу дубликатом страницы каких-либо сигналов ранжирования. Отсутствие индексации для роботов в конечном итоге приведет к тому, что Google будет рассматривать ссылки как «nofollow», что предотвратит передачу дубликатов страниц по любой ссылочной массе.
Передовой подход: если нет причин для существования дублирующегося контента, удалите источник и перенаправьте 301 на удобный для поисковой системы URL-адрес. Если есть причина для существования, добавьте атрибут ссылки rel=canonical, чтобы консолидировать сигналы ранжирования.
Недостаточное содержание страниц, связанных с доступной учетной записью
Проблема: страницы, связанные с учетной записью, такие как вход в систему, регистрация, корзина покупок, оформление заказа или контактные формы, часто малосодержательны и не представляют большой ценности для поисковых систем, но необходимы для пользователей.
Неоптимальное решение: запретить файлы с robots.txt, так как это не помешает включению ссылки в результаты поиска.
Оптимальный подход: на большинстве веб-сайтов таких страниц должно быть очень мало, и вы можете не увидеть влияния реализации обработки роботов на KPI. Если есть необходимость, то лучше использовать директиву noindex, если нет поисковых запросов по таким страницам.
Отметьте страницы с помощью краулингового бюджета
Проблема: неконтролируемое добавление тегов расходует краулинговый бюджет и часто приводит к проблемам с недостаточным содержанием.
Неоптимальные решения: запрет с помощью robots.txt или добавление тега «noindex», поскольку и то и другое будет препятствовать ранжированию релевантных для SEO тегов и (сразу или в конечном итоге) предотвратит передачу ссылочного капитала.
Лучший практический подход: оцените ценность каждого из ваших текущих тегов. Если данные показывают, что страница мало полезна для поисковых систем или пользователей, 301 перенаправляет их. Для страниц, переживших отбраковку, работайте над улучшением элементов на странице, чтобы они стали ценными как для пользователей, так и для ботов.
Сканирование JavaScript и CSS
Проблема: раньше боты не могли сканировать JavaScript и другой мультимедийный контент. Это изменилось, и теперь настоятельно рекомендуется разрешить поисковым системам доступ к файлам JS и CSS для дополнительного отображения страниц.
Неоптимальное решение: запрет файлов JavaScript и CSS с помощью robots.txt для экономии краулингового бюджета может привести к плохому индексированию и отрицательно сказаться на ранжировании. Например, блокирование доступа поисковой системы к JavaScript, который обслуживает межстраничное объявление или перенаправляет пользователей, может рассматриваться как маскировка.
Передовой подход: проверьте наличие проблем с рендерингом с помощью инструмента «Просмотреть как Google» или получите краткий обзор того, какие ресурсы заблокированы с помощью отчета «Заблокированные ресурсы», оба доступны в Google Search Console. Если заблокированы какие-либо ресурсы, которые могут помешать поисковым системам правильно отображать страницу, удалите запрет в robots.txt.
SEO-краулер OnCrawl
 Учить больше
Учить большеКонтрольный список лучших практик роботов
Пугающе распространено, что веб-сайт был случайно удален из Google из-за ошибки управления роботами.
Тем не менее, работа с роботами может стать мощным дополнением к вашему SEO-арсеналу, если вы знаете, как ее использовать. Только не забудьте действовать мудро и с осторожностью.
Чтобы помочь, вот краткий контрольный список:
- Защитите личную информацию с помощью защиты паролем
- Блокировка доступа к сайтам разработки с помощью проверки подлинности на стороне сервера
- Ограничьте поисковые роботы, которые потребляют пропускную способность, но предлагают небольшую отдачу с блокировкой пользовательского агента.
- Убедитесь, что основной домен и любые поддомены имеют текстовый файл с именем «robots.txt» в каталоге верхнего уровня, который возвращает код 200.
- Убедитесь, что в файле robots.txt есть хотя бы один блок со строкой пользовательского агента и строкой запрета.
- Убедитесь, что в файле robots.txt есть хотя бы одна строка карты сайта, введенная последней строкой.
- Проверьте файл robots.txt в тестере GSC robots.txt.
- Убедитесь, что на каждой индексируемой странице указаны директивы тега robots.
- Убедитесь, что между файлом robots.txt, метатегами robots, тегами X-Robots-Tags, файлом .htaccess и обработкой параметров GSC нет противоречивых или избыточных директив.
- Исправьте все ошибки «Отправленный URL-адрес с пометкой «noindex»» или «Отправленный URL-адрес, заблокированный robots.txt» в отчете о покрытии GSC.
- Понять причину каких-либо исключений, связанных с роботами, в отчете о покрытии GSC.
- Убедитесь, что в отчете GSC «Заблокированные ресурсы» отображаются только релевантные страницы.
Проверьте работу ваших роботов и убедитесь, что вы все делаете правильно.