
Сканирование, индексирование и Python: все, что вам нужно знать
Опубликовано: 2021-05-31Я хотел бы начать эту статью с очень простого уравнения: если ваши страницы не сканируются, они никогда не будут проиндексированы, и, следовательно, ваша эффективность SEO всегда будет страдать (и вонять).
Как следствие этого, SEO-специалисты должны попытаться найти лучший способ сделать свои веб-сайты доступными для сканирования и предоставить Google свои наиболее важные страницы, чтобы проиндексировать их и начать получать через них трафик.
К счастью, у нас есть много ресурсов, которые могут помочь нам улучшить сканирование нашего веб-сайта, таких как Screaming Frog, Oncrawl или Python. Я покажу вам, как Python может помочь вам проанализировать и улучшить показатели удобства сканирования и индексации. В большинстве случаев такого рода улучшения также приводят к лучшему рейтингу, большей видимости в поисковой выдаче и, в конечном итоге, к большему количеству пользователей, посещающих ваш сайт.
1. Запрос индексации с помощью Python
1.1. Для Google
Запросить индексацию для Google можно несколькими способами, хотя, к сожалению, ни один из них меня не убеждает. Я расскажу вам о трех разных вариантах с их плюсами и минусами:
- Selenium и Google Search Console: с моей точки зрения и после тестирования его и остальных вариантов, это самое эффективное решение. Однако после нескольких попыток возможно всплывающее окно с капчей, которое его сломает.
- Пинг карты сайта: это определенно помогает сделать так, чтобы карты сайта сканировались по запросу, но не по конкретным URL-адресам, например, в случае, если на веб-сайт были добавлены новые страницы.
- Google Indexing API: он не очень надежен, за исключением вещательных компаний и сайтов с вакансиями. Это помогает увеличить скорость сканирования, но не индексировать определенные URL-адреса.
После этого краткого обзора каждого метода давайте рассмотрим их один за другим.
1.1.1. Selenium и Google Search Console
По сути, в этом первом решении мы будем получать доступ к консоли поиска Google из браузера с помощью Selenium и повторять тот же процесс, который мы будем выполнять вручную, чтобы отправить множество URL-адресов для индексации с помощью консоли поиска Google, но автоматически.
Примечание. Не злоупотребляйте этим методом и отправляйте страницу на индексацию только в том случае, если ее содержимое было обновлено или страница совершенно новая.
Хитрость, позволяющая войти в консоль поиска Google с помощью Selenium, заключается в том, чтобы сначала получить доступ к игровой площадке OUATH, как я объяснил в этой статье о том, как автоматизировать загрузку отчета статистики сканирования GSC.
#Импортируем эти модули
время импорта
из веб-драйвера импорта селена
из webdriver_manager.chrome импортировать ChromeDriverManager
из selenium.webdriver.common.keys импортировать ключи
#Устанавливаем наш Selenium Driver
драйвер = webdriver.Chrome(ChromeDriverManager().install())
# Мы получаем доступ к учетной записи игровой площадки OUATH для входа в службы Google.
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
# Мы немного подождем, чтобы убедиться, что рендеринг завершен, прежде чем выбирать элементы с помощью Xpath и вводить наш адрес электронной почты.
время сна(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<ваш адрес электронной почты>")
form1.send_keys(Ключи.ENTER)
#То же самое здесь, мы немного ждем, а затем вводим наш пароль.
время сна(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<ваш пароль>")
form2.send_keys(Ключи.ENTER)
После этого мы можем получить доступ к URL-адресу нашей консоли поиска Google:
driver.get('https://search.google.com/search-console?resource_id=ваш_домен"')
время сна(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /дел[1]/ввод[2]')
box.send_keys("ваш_URL")
box.send_keys(Ключи.ENTER)
время сна(5)
indexation = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
время сна(120)
К сожалению, как объяснялось во введении, кажется, что после ряда запросов для продолжения запроса на индексацию начинает требоваться капча-головоломка. Поскольку автоматический метод не может решить капчу, это мешает этому решению.
1.1.2. Проверка карты сайта
URL-адреса карты сайта можно отправить в Google с помощью метода ping. По сути, вам нужно будет только сделать запрос к следующей конечной точке, указав URL-адрес вашей карты сайта в качестве параметра:
http://www.google.com/ping?sitemap=URL/of/file
Это можно очень легко автоматизировать с помощью Python и запросов, как я объяснил в этой статье.
импортировать urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" ответ = urllib.request.urlopen(url)
1.1.3. API индексирования Google
Google Indexing API может быть хорошим решением для повышения скорости сканирования, но обычно это не очень эффективный метод индексации вашего контента, поскольку его предполагается использовать только в том случае, если на вашем веб-сайте есть JobPosting или BroadcastEvent, встроенный в VideoObject. Однако, если вы хотите попробовать и проверить это самостоятельно, вы можете выполнить следующие шаги.
Прежде всего, чтобы начать работу с этим API, вам нужно перейти в Google Cloud Console, создать проект и учетные данные служебной учетной записи. После этого вам нужно будет включить Indexing API из библиотеки и добавить учетную запись электронной почты, указанную с учетными данными учетной записи службы, в качестве владельца свойства в Google Search Console. Возможно, вам придется использовать старую версию Google Search Console, чтобы иметь возможность добавить этот адрес электронной почты в качестве владельца собственности.
Выполнив предыдущие шаги, вы сможете начать запрашивать индексацию и деиндексацию с помощью этого API, используя следующий фрагмент кода:
из oauth2client.service_account импортировать учетные данные ServiceAccountCredentials
импортировать httplib2
ОБЛАСТИ = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:опубликовать"
client_secrets = "path_to_your_credentials.json"
учетные данные = ServiceAccountCredentials.from_json_keyfile_name (client_secrets, scopes = SCOPES)
если учетные данные отсутствуют или учетные данные. недействительны:
учетные данные = tools.run_flow (поток, хранилище)
http = учетные данные.авторизовать(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
для итерации в диапазоне (len(list_urls)):
содержание = '''{
'url': "'''+str(list_urls[итерация])+'''",
'тип': "URL_UPDATED"
}'''
ответ, содержимое = http.request(ENDPOINT, method="POST", body=content)
распечатать (ответ)
распечатать (содержание)Если вы хотите запросить деиндексацию, вам нужно будет изменить тип запроса с «URL_UPDATED» на «URL_DELETED». Предыдущий фрагмент кода будет печатать ответы от API со временем уведомления и их статусами. Если статус равен 200, то запрос будет выполнен успешно.
1.2. Для Бинга
Очень часто, когда мы говорим о поисковой оптимизации, мы думаем только о Google, но мы не можем забывать, что на некоторых рынках есть другие доминирующие поисковые системы и/или другие поисковые системы, которые занимают солидную долю рынка, например Bing.
С самого начала важно отметить, что Bing уже имеет очень удобную функцию в Bing Webmaster Tools, которая позволяет в большинстве случаев запрашивать отправку до 10 000 URL-адресов в день. Иногда ваша дневная квота может быть ниже 10 000 URL-адресов, но у вас есть возможность запросить увеличение квоты, если вы считаете, что вам потребуется большая квота для удовлетворения ваших потребностей. Подробнее об этом вы можете прочитать на этой странице.
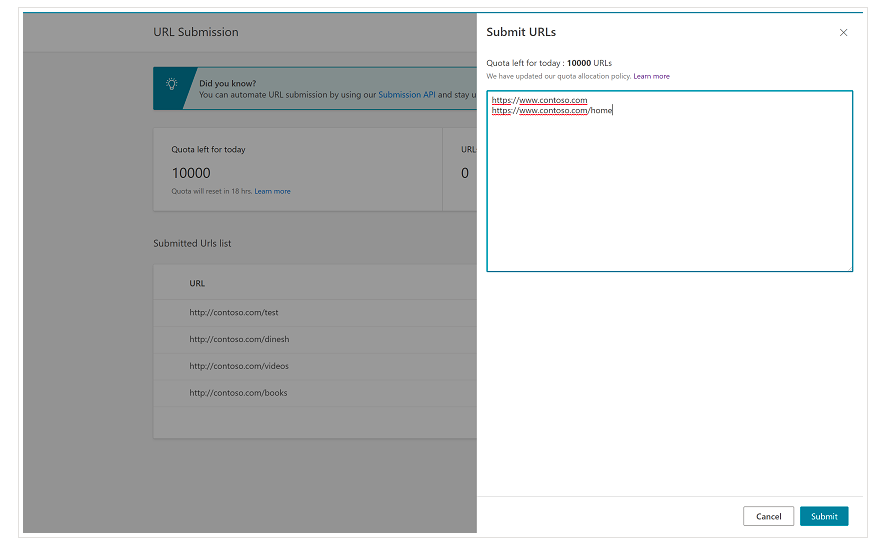
Эта функция действительно очень удобна для массовой отправки URL-адресов, поскольку вам нужно будет только ввести свои URL-адреса в разные строки в инструменте отправки URL-адресов из обычного интерфейса инструментов Bing для веб-мастеров.
1.2.1. API индексации Bing
Bing Indexing API можно использовать с ключом API, который необходимо указать в качестве параметра. Этот ключ API можно получить в Инструментах для веб-мастеров Bing, перейдя в раздел доступа к API и после этого сгенерировав ключ API.
После того, как ключ API получен, мы можем поиграть с API с помощью следующего фрагмента кода (вам нужно будет только добавить ключ API и URL-адрес вашего сайта):
запросы на импорт
list_urls = ["https://www.example.com", "https://www.example/test2/"]
для y в list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
заголовки = {'Content-type': 'application/json; кодировка=utf-8'}
x = request.post (url, данные = myobj, заголовки = заголовки)
печать (стр (у) + ": " + ул (х))Это будет печатать URL-адрес и его код ответа на каждой итерации. В отличие от Google Indexing API, этот API можно использовать для любого веб-сайта.
[Пример успеха] Повысьте видимость, улучшив возможности сканирования веб-сайта для робота Googlebot
 Читать тематическое исследование
Читать тематическое исследование2. Анализ, создание и загрузка файлов Sitemap
Как мы все знаем, карты сайта являются очень полезными элементами для предоставления ботам поисковых систем URL-адресов, которые мы хотели бы, чтобы они сканировали. Чтобы роботы поисковых систем знали, где находятся наши карты сайта, их нужно загрузить в Google Search Console и Bing Webmaster Tools и включить в файл robots.txt для остальных ботов.
С помощью Python мы можем работать в основном над тремя различными аспектами, связанными с картами сайта: их анализом, созданием, загрузкой и удалением из Google Search Console.
2.1. Импорт и анализ карты сайта с помощью Python
Advertools — отличная библиотека, созданная Элиасом Даббасом, которую можно использовать для импорта карты сайта, а также для многих других задач SEO. Вы сможете импортировать карты сайта в Dataframes, просто используя:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Эта библиотека поддерживает обычные XML-карты сайта, карты сайта для новостей и карты сайта для видео.
С другой стороны, если вас интересует только импорт URL-адресов из карты сайта, вы также можете использовать запросы библиотеки и BeautifulSoup.
запросы на импорт
из bs4 импортировать BeautifulSoup
r = request.get("https://www.example.com/your_sitemap.xml")
xml = р.текст
суп = BeautifulSoup(xml)
URL-адреса = суп.найти_все("loc")
urls = [[x.text] для x в URL]
После того, как карта сайта будет импортирована, вы можете поэкспериментировать с извлеченными URL-адресами и выполнить анализ контента, как описано Кораем Тугберком в этой статье.
2.2. Создание карты сайта с помощью Python
Вы также можете использовать Python для создания sitemaps.xml из списка URL-адресов, как объяснил JC Chouinard в этой статье. Это может быть особенно полезно для очень динамичных веб-сайтов, чьи URL-адреса быстро меняются, и вместе с методом ping, который был описан выше, это может быть отличным решением для предоставления Google новых URL-адресов и их быстрого сканирования и индексации.
Недавно Грег Бернхардт также создал приложение с Streamlit и Python для создания карт сайта.
2.3. Загрузка и удаление карт сайта из Google Search Console
Google Search Console имеет API, который можно использовать в основном двумя способами: для извлечения данных о веб-производительности и обработки карт сайта. В этом посте мы сосредоточимся на возможности загрузки и удаления карт сайта.
Во-первых, важно создать или использовать существующий проект из Google Cloud Console, чтобы получить учетные данные OUATH и включить службу Google Search Console. JC Chouinard очень хорошо объясняет шаги, которые необходимо выполнить, чтобы получить доступ к Google Search Console API с помощью Python, и как сделать свой первый запрос в этой статье. По сути, мы можем полностью использовать его код, но только внеся изменение, в области видимости мы добавим «https://www.googleapis.com/auth/webmasters» вместо «https://www.googleapis.com». /auth/webmasters.readonly», так как мы будем использовать API не только для чтения, но и для загрузки и удаления карт сайта.

Как только мы подключимся к API, мы можем начать играть с ним и перечислить все карты сайта из наших свойств Google Search Console с помощью следующего фрагмента кода:
для site_url в Verified_sites_urls:
распечатать (адрес_сайта)
# Получить список отправленных карт сайта
карты сайта = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
если «карта сайта» в картах сайта:
sitemap_urls = [s['path'] для s в картах сайта['sitemap']]
печать (" " + "\n ".join(sitemap_urls))
Когда дело доходит до конкретных карт сайта, мы можем выполнить три задачи, которые мы подробно рассмотрим в следующих разделах: загрузка, удаление и запрос информации.
2.3.1. Загрузка карты сайта
Чтобы загрузить карту сайта с помощью Python, нам нужно только указать URL-адрес сайта и путь к карте сайта и запустить этот фрагмент кода:
ВЕБ-САЙТ = 'ваша GSCproperty' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. Удаление карты сайта
Другая сторона медали — это когда мы хотим удалить карту сайта. Мы также можем удалить карты сайта из Google Search Console с помощью Python, используя метод «удалить» вместо «отправить».
ВЕБ-САЙТ = 'ваша GSCproperty' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Запрос информации из карты сайта
Наконец, мы также можем запросить информацию из карты сайта с помощью метода «получить».
ВЕБ-САЙТ = 'ваша GSCproperty' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
Это вернет ответ в формате JSON, например: 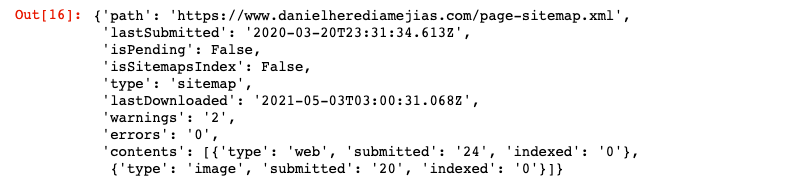
3. Анализ внутренних ссылок и возможности
Наличие надлежащей внутренней структуры ссылок очень полезно для облегчения ботов поисковых систем при сканировании вашего сайта. Вот некоторые из основных проблем, с которыми я столкнулся при аудите ряда веб-сайтов с очень сложными техническими настройками:
- Ссылки, представленные с событиями по клику: короче говоря, робот Googlebot не нажимает на кнопки, поэтому, если ваши ссылки вставлены с событием по клику, робот Googlebot не сможет перейти по ним.
- Ссылки, отображаемые на стороне клиента: несмотря на то, что робот Googlebot и другие поисковые системы все лучше справляются с выполнением JavaScript, для них это все еще довольно сложно, поэтому гораздо лучше отображать эти ссылки на стороне сервера и отображать их в необработанном HTML для ботов поисковых систем, чем ожидать от них выполнения скриптов JavaScript.
- Всплывающие окна входа и/или возрастных ограничений: всплывающие окна входа и возрастные ограничения могут помешать ботам поисковых систем сканировать контент, который стоит за этими «препятствиями».
- Чрезмерное использование атрибута nofollow: использование многих атрибутов nofollow, указывающих на ценные внутренние страницы, предотвратит их сканирование ботами поисковых систем.
- Noindex и follow: технически комбинация директив noindex и follow должна позволять ботам поисковых систем сканировать ссылки на этой странице. Однако, похоже, через некоторое время робот Googlebot перестает сканировать эти страницы с директивами noindex.
С помощью Python мы можем анализировать нашу внутреннюю структуру ссылок и находить новые возможности внутренних ссылок в массовом режиме.
3.1. Анализ внутренних ссылок с помощью Python
Несколько месяцев назад я написал статью о том, как использовать Python и библиотеку Networkx для создания графиков для наглядного отображения внутренней структуры ссылок:
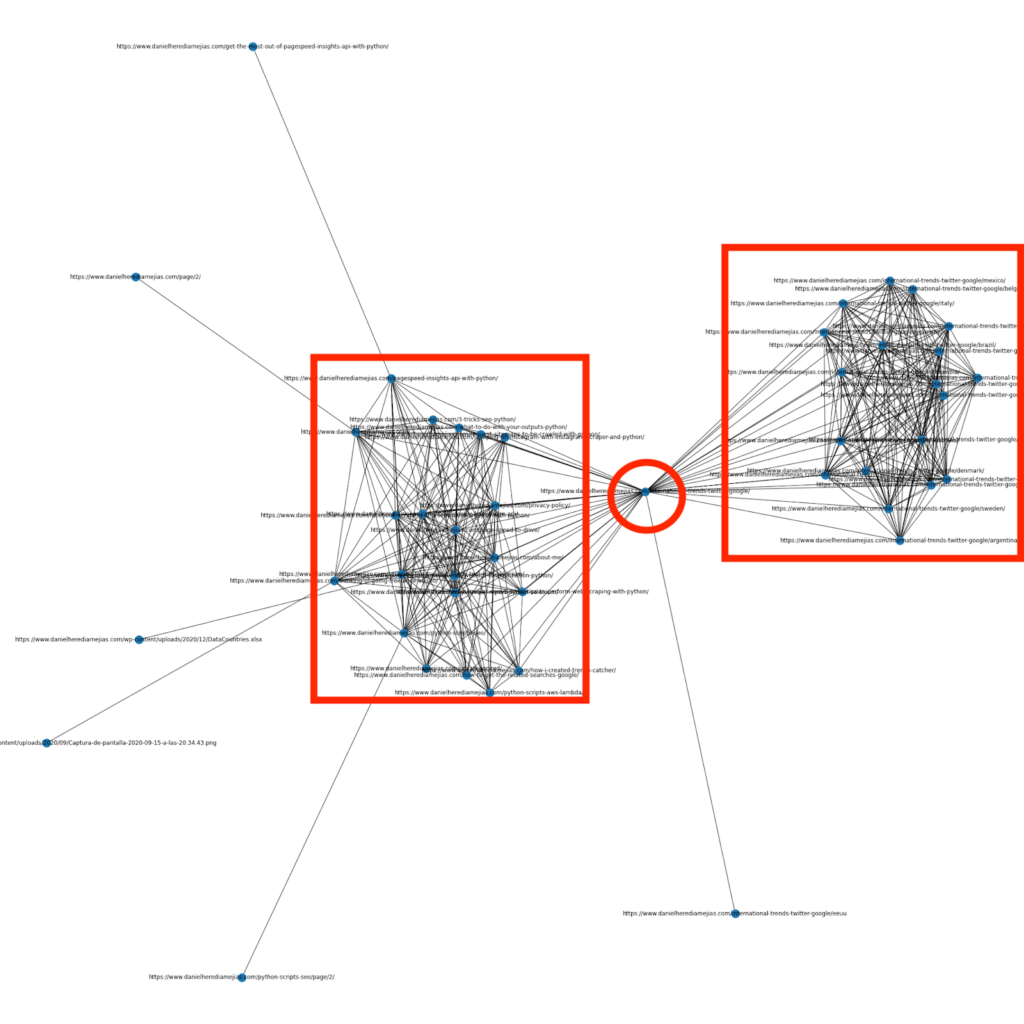
Это очень похоже на то, что вы можете получить от Screaming Frog, но преимущество использования Python для такого рода анализа заключается в том, что в основном вы можете выбирать данные, которые хотите включить в эти графики, и управлять большинством элементов графика, таких как как цвета, размеры узлов или даже страницы, которые вы хотели бы добавить.
3.2. Поиск новых возможностей внутренних ссылок с помощью Python
Помимо анализа структуры сайта, вы также можете использовать Python для поиска новых возможностей внутренних ссылок, указав ряд ключевых слов и URL-адресов и перебирая эти URL-адреса в поисках предоставленных терминов в их частях контента.
Это то, что может очень хорошо работать с экспортом Semrush или Ahrefs, чтобы найти мощные контекстные внутренние ссылки с некоторых страниц, которые уже ранжируются по ключевым словам и, следовательно, уже имеют определенный авторитет.
Подробнее об этом методе можно прочитать здесь.
4. Скорость сайта, 5xx и программные страницы ошибок
Как заявил Google на этой странице о том, что означает краулинговый бюджет для Google, ускорение вашего сайта улучшает взаимодействие с пользователем и увеличивает скорость сканирования. С другой стороны, есть и другие факторы, которые могут повлиять на краулинговый бюджет, такие как программные страницы с ошибками, низкокачественный контент и дублированный контент на сайте.
4.1. Скорость страницы и Python
4.2.1 Анализ скорости вашего сайта с помощью Python
Page Speed Insights API очень полезен для анализа производительности вашего веб-сайта с точки зрения скорости страницы и для получения большого количества данных о многих различных показателях скорости страницы (почти 50), а также Core Web Vitals.
Работать с Page Speed Insights с Python очень просто, для его использования необходимы только ключ API и запросы. Например:
импортировать urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Обратите внимание, что вы можете вставить свой URL-адрес с URL-адресом параметра, а также изменить параметр устройства, если хотите получить данные для рабочего стола. ответ = urllib.request.urlopen(url) данные = json.loads(response.read())
Кроме того, вы также можете прогнозировать с помощью калькулятора Python и Lighthouse Scoring, насколько улучшится ваша общая оценка производительности в случае внесения запрошенных изменений для повышения скорости вашей страницы, как описано в этой статье.
4.2.2 Оптимизация изображения и изменение размера с помощью Python
Что касается скорости веб-сайта, Python также можно использовать для оптимизации, сжатия и изменения размера изображений, как описано в этих статьях, написанных Кораем Тугберком и Грегом Бернхардтом:
- Автоматизируйте сжатие изображений с помощью Python через FTP.
- Массовое изменение размера изображений с помощью Python.
- Оптимизируйте изображения с помощью Python для SEO и UX.
4.2. Извлечение 5xx и других ошибок кода ответа с помощью Python
Ошибки кода ответа 5xx могут свидетельствовать о том, что ваш сервер недостаточно быстр, чтобы справиться со всеми запросами, которые он получает. Это может оказать очень негативное влияние на скорость сканирования, а также может повредить пользовательскому опыту.
Чтобы убедиться, что ваш веб-сайт работает должным образом, вы можете автоматизировать загрузку отчетов о статистике сканирования с помощью Python и Selenium и внимательно следить за своими файлами журналов.
4.3. Извлечение страниц программных ошибок с помощью Python
Недавно Хосе Луис Эрнандо опубликовал статью в честь Гамлета Батисты о том, как можно автоматизировать извлечение отчета о покрытии с помощью Node.js. Это может быть отличным решением для извлечения страниц программных ошибок и даже ошибок ответа 5xx, которые могут негативно повлиять на скорость сканирования.
Мы также можем воспроизвести этот же процесс с Python, чтобы скомпилировать только на одной вкладке Excel все URL-адреса, предоставленные Google Search Console, как ошибочные, действительные с предупреждениями, действительные и исключенные.
Во-первых, нам нужно войти в консоль поиска Google, как описано ранее в этой статье с Python с Selenium. После этого мы выберем все поля состояния URL-адресов, добавим до 100 строк на страницу и начнем перебирать все типы URL-адресов, о которых сообщает GSC, и загружать каждый файл Excel.
время импорта
из веб-драйвера импорта селена
из webdriver_manager.chrome импортировать ChromeDriverManager
из selenium.webdriver.common.keys импортировать ключи
драйвер = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
время сна(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<ваш адрес электронной почты>")
searchBox.send_keys(Keys.ENTER)
время сна(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<вашпароль>")
searchBox.send_keys(Keys.ENTER)
время сна(5)
yourdomain = str(input("Вставьте здесь свой http-ресурс или домен. Если это домен, включите: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] для i в диапазоне (len(df1["URL"]))]
df1['Тип'] = значения списка
list_results = df1.values.tolist()
еще:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + сегодня + "(" + str(x) + ").xlsx", 'Таблa')
listvalues = [list_problems[x] для i в диапазоне (len(df2["URL"]))]
df2['Тип'] = значения списка
list_results = list_results + df2.values.tolist()
df = pd.DataFrame (list_results, columns = ["URL", "TimeStamp", "Type"])
df.to_csv('<имя файла>.csv', заголовок = Истина, индекс = Ложь, кодировка = "utf-8")
Окончательный вывод выглядит так: 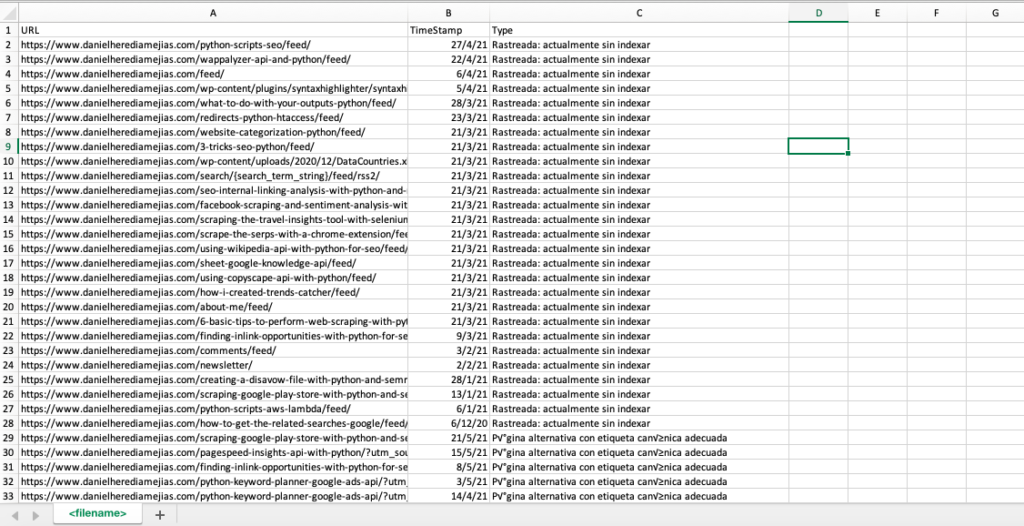
4.4. Анализ файла журнала с помощью Python
Помимо данных, доступных в отчете о статистике сканирования из Google Search Console, вы также можете анализировать свои собственные файлы с помощью Python, чтобы получить гораздо больше информации о том, как боты поисковых систем сканируют ваш сайт. Если вы еще не используете анализатор журналов для SEO, вы можете прочитать эту статью из SEO Garden, где объясняется анализ журналов с помощью Python.
[Электронная книга] Четыре варианта использования SEO-анализа журнала
Скачать бесплатно5. Заключительные выводы
Мы увидели, что Python может быть отличным инструментом для анализа и улучшения сканирования и индексации наших веб-сайтов различными способами. Мы также увидели, как можно значительно облегчить жизнь, автоматизировав большинство утомительных и ручных задач, которые потребуют от вас тысячи часов вашего времени.
Я должен сказать, что, к сожалению, я не полностью убежден решениями, которые предлагает Google на данный момент для запроса индексации большого количества URL-адресов, хотя я могу в некоторой степени понять его опасения предложить лучшее решение: многие SEO-специалисты могут склоняться злоупотреблять им.
В отличие от этого, есть Bing, который предлагает исключительные и удобные решения для запроса индексации URL-адресов через API и даже через обычный интерфейс инструментов Bing для веб-мастеров.
В связи с тем, что API индексирования Google можно улучшить, другие элементы, такие как доступная и обновленная карта сайта, ваши внутренние ссылки, скорость вашей страницы, ваши страницы с программными ошибками, а также ваш дублированный и низкокачественный контент, становятся еще более важными для обеспечения что ваш веб-сайт правильно просканирован и ваши самые важные страницы проиндексированы.