
10 распространенных технических проблем SEO — и как их обнаружить
Опубликовано: 2019-06-04Выполняя SEO-услуги в различных отраслях, иногда вы можете решать общие проблемы, особенно при работе с распространенными CMS, такими как WordPress, Shopify или SquareSpace.
Здесь я описал 10 довольно распространенных технических проблем SEO, с которыми вы можете столкнуться при оптимизации веб-сайта.
Я не говорю, что эти вопросы обязательно будут проблематичными для вас или вашего клиента — очень часто контекст по-прежнему очень важен. Не всегда существует универсальное решение, но, вероятно, все же полезно опасаться описанных ниже сценариев.
1 – Файл robots.txt блокирует доступ к Googlebot.
В этом нет ничего нового для большинства технических SEO-специалистов, но по-прежнему очень легко пренебречь проверкой файла robots — и не только в момент проведения технического аудита, но и в качестве периодической проверки.
Вы можете использовать такой инструмент, как Search Console (старая версия), чтобы проверить, есть ли у Google проблемы с доступом, или вы можете просто попробовать просканировать свой сайт как Googlebot с помощью такого инструмента, как OnCrawl (просто выберите их пользовательский агент). OnCrawl будет подчиняться файлу robots.txt, если вы не укажете иное.
Экспортируйте результаты сканирования и сравните их с известным списком страниц на вашем сайте и проверьте, нет ли слепых зон для сканера.
Чтобы показать, что это все еще происходит довольно часто и с некоторыми довольно крупными сайтами, несколько недель назад я заметил, что инструмент тестирования скорости Pingdom был заблокирован в Google.
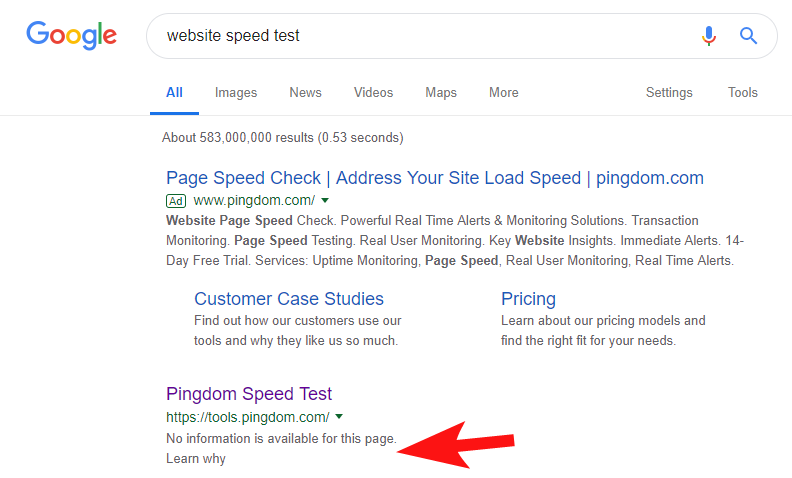
Глядя на их файл robots (и впоследствии пытаясь просканировать их страницу из OnCrawl как Googlebot), я подтвердил свои подозрения, что они блокируют доступ к своему сайту.
Провинившийся файл robots.txt показан ниже:

Я обратился к ним с «FYI», но не получил ответа, но через несколько дней увидел, что все вернулось в норму. Фух – я снова мог спать спокойно!
В их случае казалось, что всякий раз, когда вы сканируете свой сайт в рамках их аудита скорости, он создает URL-адрес, включающий хэш-символ, выделенный в файле robots выше.
Возможно, они каким-то образом сканировались и даже индексировались, и они хотели это контролировать (что было бы очень понятно). В этом случае они, вероятно, не полностью проверили потенциальное воздействие, которое, вероятно, было минимальным в конце.
Вот их текущие роботы для всех, кто заинтересован.

Стоит отметить, что в некоторых случаях вы можете получить доступ к историческим изменениям файла robots.txt с помощью Internet Wayback Machine. По моему опыту, это лучше всего работает на больших сайтах, как вы можете себе представить — они гораздо чаще сканируются архиватором Wayback Machine.
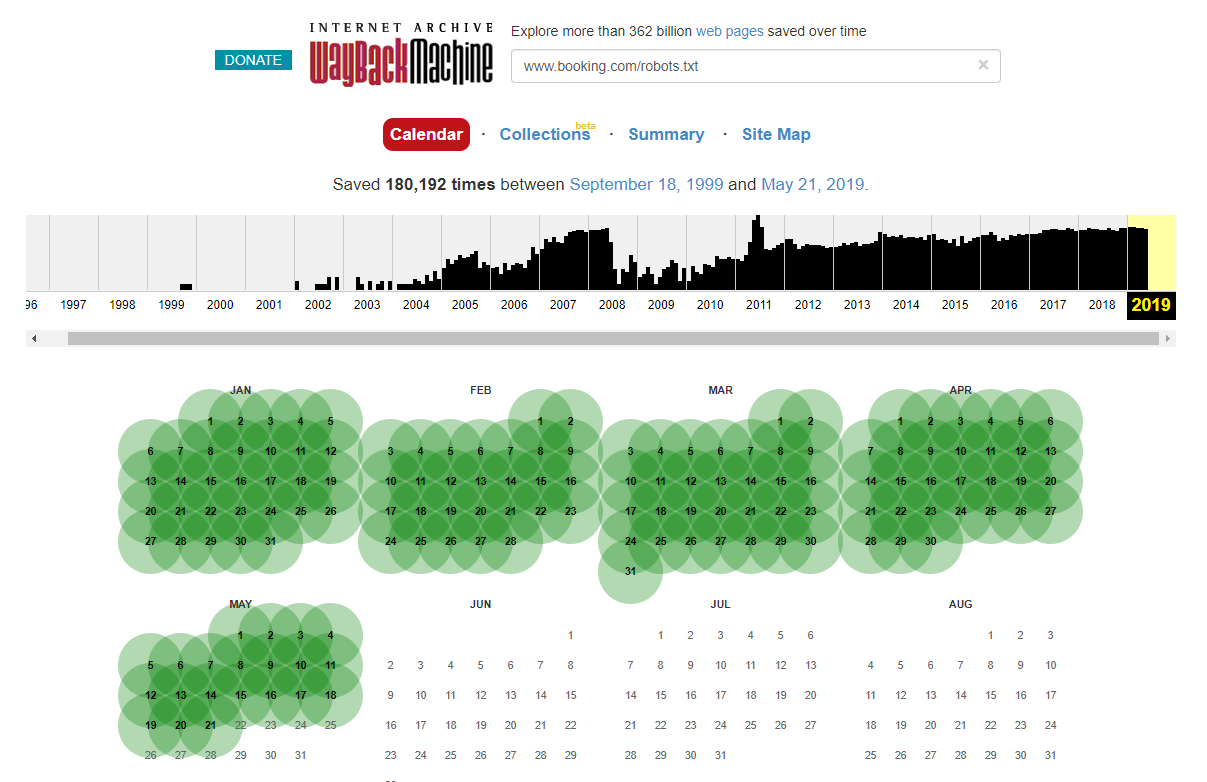
Это не первый раз, когда я вижу живой robots.txt в дикой природе, вызывающий небольшой хаос в поисковой выдаче. И это определенно не будет последним — это такая простая вещь, которой можно пренебречь (в конце концов, это буквально один файл), но проверка этого должна быть частью текущего рабочего графика каждого оптимизатора.
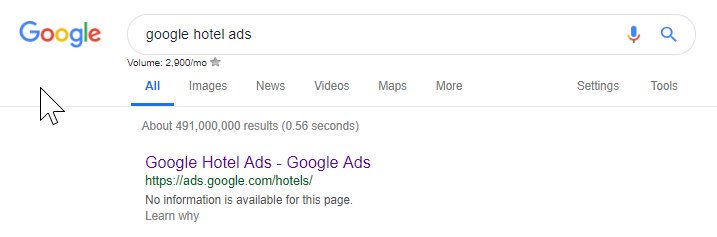
Из приведенного выше видно, что даже Google иногда портит файл robots, блокируя себе доступ к своему контенту. Это могло быть сделано намеренно, но, глядя на язык их файла robots ниже, я как-то сомневаюсь в этом.
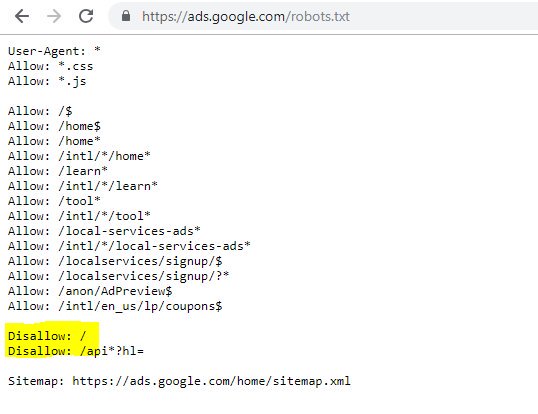
Выделенный Disallow: / в этом случае предотвратил доступ к любым URL-путям; вместо этого было бы безопаснее перечислить определенные разделы сайта, которые не следует сканировать.
2 – Проблемы с конфигурацией домена на уровне DNS
Это удивительно распространенная проблема, но обычно это быстро решается. Это одно из тех недорогих, *потенциально* эффективных SEO-изменений, которые любят специалисты по технической оптимизации.
Часто с реализациями SSL я не вижу правильно настроенной версии домена, отличной от WWW, например, 302 перенаправление на следующий URL-адрес и формирование цепочки, или в худшем случае вообще не загружается.
Хорошим примером здесь является веб-сайт Hotel Football.
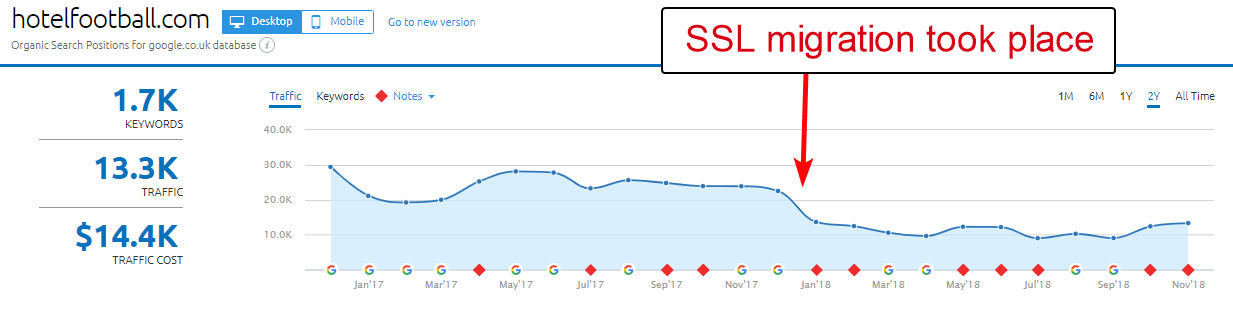
В начале прошлого года они перенесли SSL-миграцию, которая, судя по отчету об обзоре домена SEMRush выше, оказалась для них не очень хорошей.
Я заметил это некоторое время назад, так как много работал в индустрии путешествий и гостеприимства, и с большой любовью к футболу мне было интересно посмотреть, на что похож их веб-сайт (плюс, конечно, как он работает органично! ).
На самом деле это было очень легко диагностировать — на сайте было множество очень хороших обратных ссылок, и все они указывали на не-SSL, WWW-домен по адресу http://www.hotelfootball.com/.
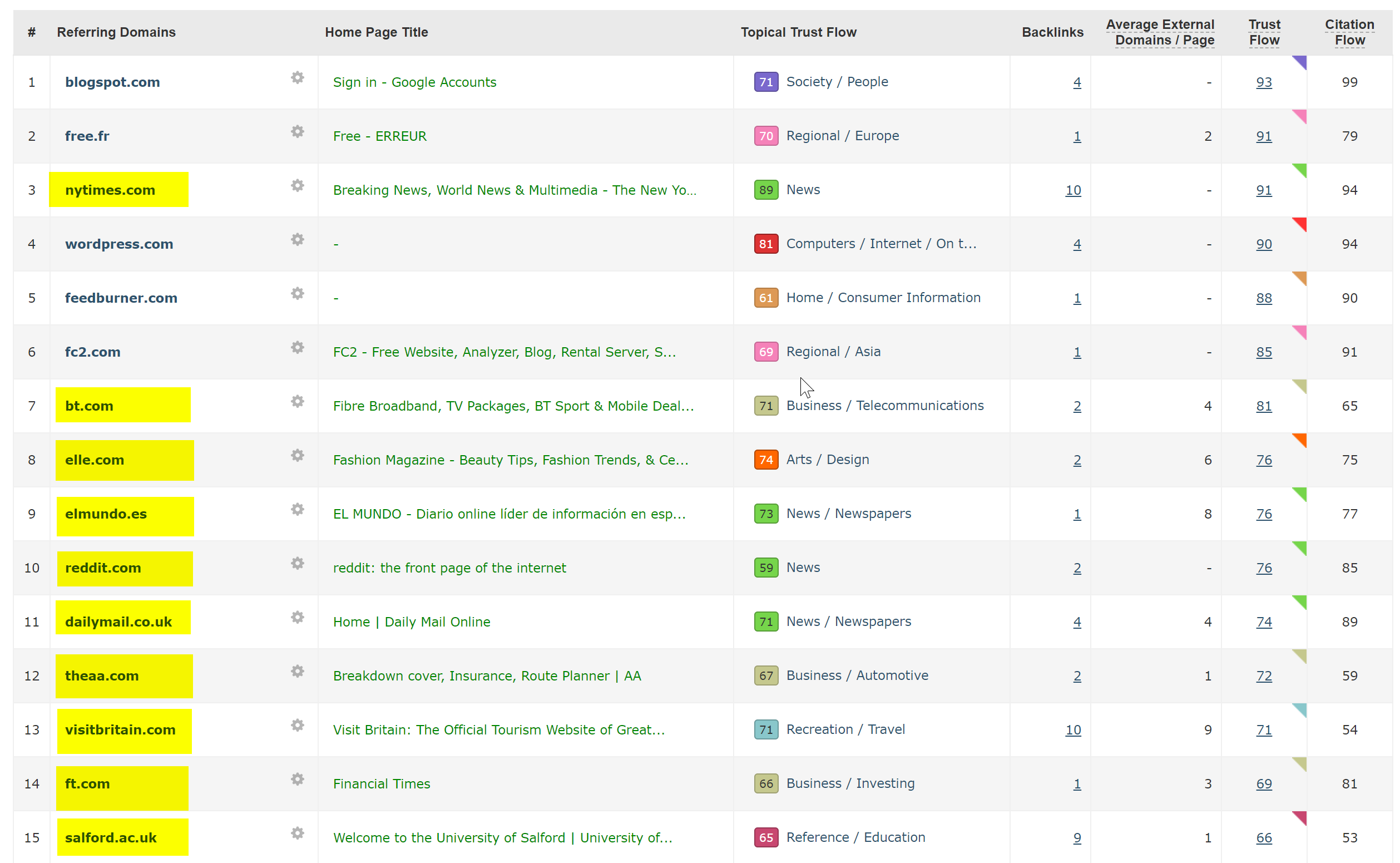
Если вы попытаетесь получить доступ к этому URL-адресу выше, он не загрузится. Упс. И так уже около 18 месяцев, по крайней мере. Я связался с агентством, которое управляет сайтом, через Twitter, чтобы сообщить им об этом, но не получил ответа.
В этом случае все, что им нужно сделать, это убедиться, что настройки зоны DNS верны, с записью «A» для «WWW» версии домена, которая указывает на правильный IP-адрес (CNAME также будет работать). Это предотвратит неразрешение домена.
Единственным недостатком или причиной, по которой эта проблема занимает так много времени, является то, что может быть сложно получить доступ к панели управления доменом сайта, или даже то, что пароли были потеряны, или это не считается высокоприоритетным.
Отправка инструкций по исправлению неспециалисту, у которого есть ключи от доменного имени, также не всегда является хорошей идеей.
Я был бы очень заинтересован в том, чтобы увидеть органическое влияние, если/когда они смогут внести вышеуказанные корректировки, особенно учитывая все обратные ссылки, которые не WWW-домен создал с тех пор, как отель был открыт бывшими футболистами «Манчестер Юнайтед» Гэри Невиллом и Райаном Гиггзом. и компания.
Несмотря на то, что они занимают первое место в Google по названию своего отеля (как вы можете себе представить), у них совсем нет сильных позиций ни по одному из наиболее конкурентных небрендовых поисковых запросов (в настоящее время они находятся на 10-й позиции). в Google для «отель рядом с Олд Траффорд»).
Они забили что-то вроде автогола с помощью вышеперечисленного, но исправление этой проблемы может хоть как-то решить эту проблему.
SEO-краулер OnCrawl
 Учить больше
Учить больше3 – Мошеннические страницы в XML-карте сайта
Опять же, это довольно простой, но странно распространенный вариант — при просмотре XML-карты сайта сайта (которая почти всегда находится либо по адресу domain.com/sitemap.xml, либо по адресу domain.com/sitemap_index.xml), здесь могут быть страницы, которые действительно не не нужно индексировать.
Типичные виновники включают скрытые страницы благодарности (спасибо за отправку контактной формы), целевые страницы PPC, которые могут вызывать проблемы с дублированием контента, или другие формы страниц/сообщений/таксономий, которые вы уже не проиндексировали в другом месте.
Включение их снова в XML-карту сайта может послать противоречивые сигналы поисковым системам — вам действительно следует перечислять только те страницы, которые вы хотите, чтобы они находили и индексировали, что в основном является целью карты сайта.
Теперь вы можете использовать удобный отчет в Search Console, чтобы узнать, были ли страницы включены в XML-карту сайта сайта или нет, с помощью параметра «Проверить URL».
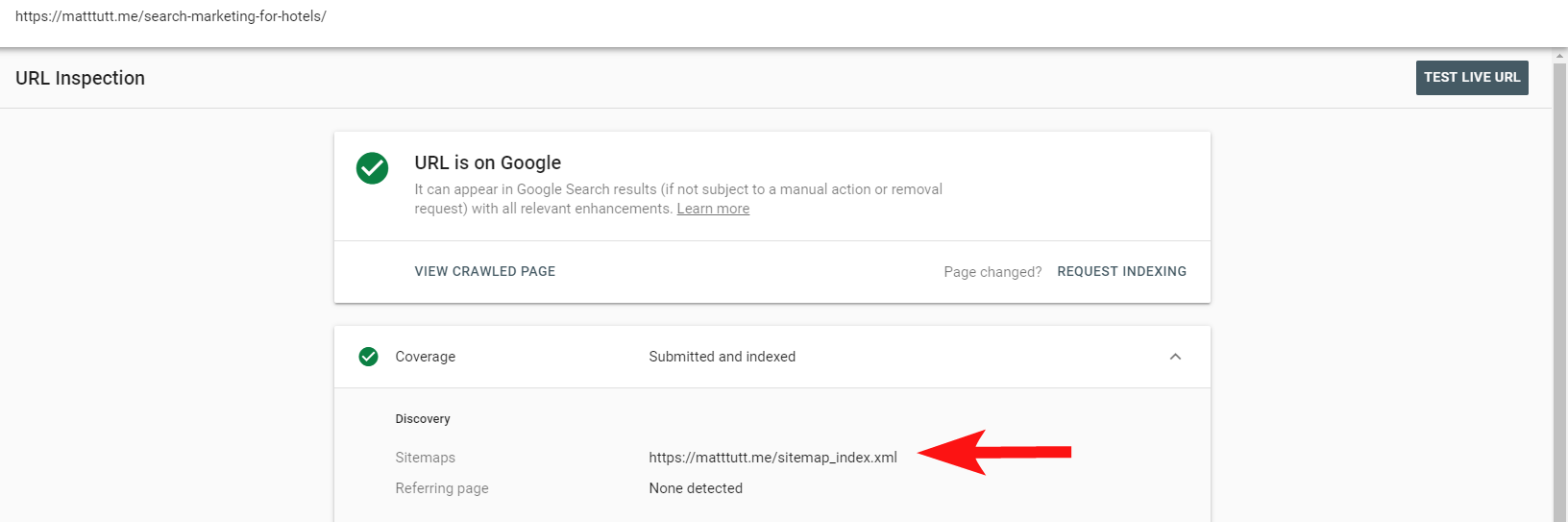
Если у вас довольно маленький сайт, вы, вероятно, можете просто вручную просмотреть свою XML-карту сайта в своем браузере — в противном случае загрузите ее и сравните с полным сканированием ваших индексируемых URL-адресов.
Часто такой некачественный бесценный контент можно обнаружить, выполнив поиск site:domain.com в Google, чтобы получить все, что было проиндексировано.
Здесь стоит отметить, что это может содержать старый контент и не следует полагаться на его 100% актуальность, но это легко проверить, чтобы убедиться, что нет большого количества контента, раздувающего ваши усилия по SEO и поглощающего краулинговые бюджеты.
4. Проблемы с рендерингом вашего контента роботом Googlebot.
Это достойно отдельной статьи, посвященной ему, и я лично чувствую, что провел всю жизнь, играя с инструментом выборки и рендеринга Google.
Многое было сказано об этом (и о JavaScript) некоторыми очень способными SEO-специалистами, поэтому я не буду углубляться в это слишком глубоко, но проверка того, как Googlebot отображает ваш сайт, всегда будет стоить вашего времени.
Выполнение нескольких проверок с помощью онлайн-инструментов может помочь обнаружить слепые зоны Googlebot (области на сайте, к которым они не могут получить доступ), проблемы с вашей средой хостинга, проблемный JavaScript, потребляющий ресурсы, и даже проблемы с масштабированием экрана.
Обычно эти сторонние инструменты весьма полезны при диагностике проблемы (например, Google даже сообщает вам, когда ресурс заблокирован из-за вашего файла robots), но иногда вы можете обнаружить, что ходите по кругу.
Чтобы показать живой пример проблемного сайта, я собираюсь выстрелить себе в ногу и сослаться на свой личный веб-сайт — и особенно разочаровывающую тему WordPress, которую я использую.
Иногда при запуске проверки URL-адресов из Search Console я получаю предупреждение «Страница не оптимизирована для мобильных устройств» (см. ниже).
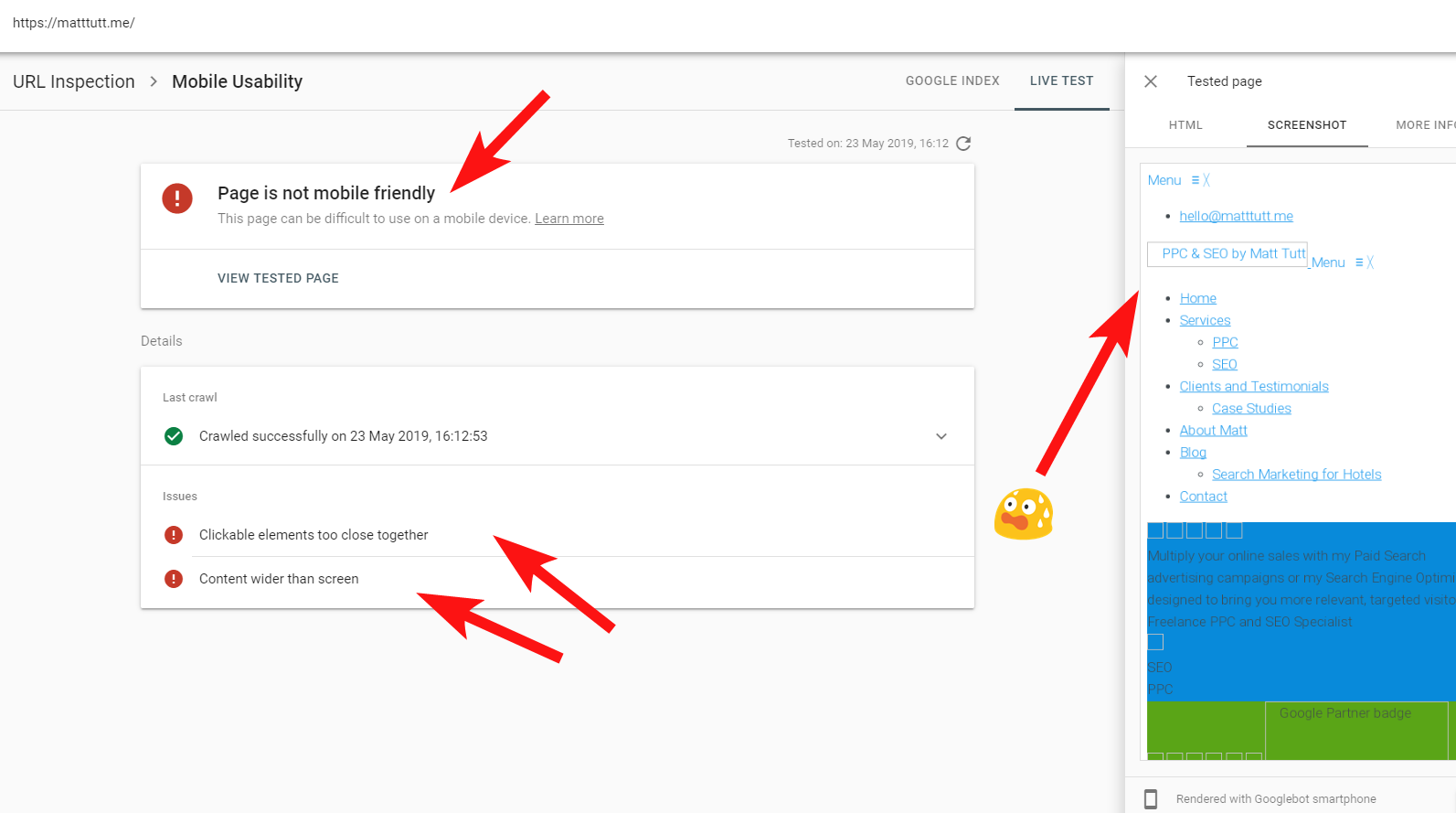
Нажав на вкладку «Дополнительная информация» (вверху справа), вы получите список ресурсов, к которым не может получить доступ робот Googlebot, в основном это файлы CSS и изображений.
Вероятно, это связано с тем, что робот Googlebot не всегда может отдать всю свою «энергию» рендерингу страницы — иногда это происходит потому, что Google опасается краха моего сайта (что очень мило с их стороны), а в других случаях я могу быть ограничен, поскольку они использовали уже много ресурсов для получения и отображения моего сайта.
Иногда из-за вышеперечисленного стоит запустить эти тесты несколько раз с разбросанными интервалами, чтобы получить более правдивую информацию. Я также рекомендую проверить журналы сервера, если вы можете проверить, как робот Googlebot получил доступ (или не получил доступ) к содержимому вашего сайта.
404 или другие плохие статусы для этих ресурсов явно были бы плохим признаком, особенно если они постоянны.
В моем случае Google ругает сайт за то, что он не оптимизирован для мобильных устройств, что в основном является результатом сбоя определенных файлов стилей CSS во время рендеринга, что может справедливо бить тревогу.
Чтобы еще больше запутать ситуацию, при запуске Mobile Friendly Test от Google или при использовании любого другого стороннего инструмента проблем не обнаружено: сайт оптимизирован для мобильных устройств.
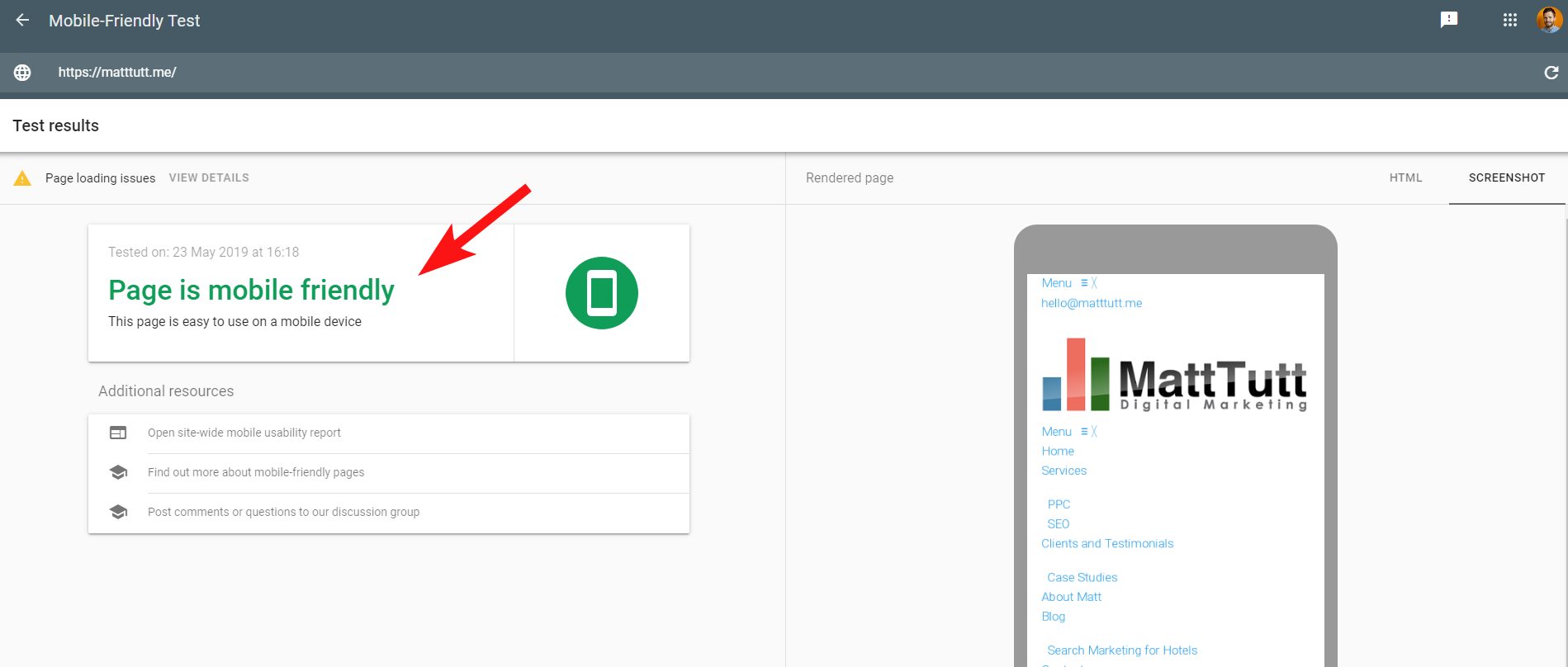
Эти противоречивые сообщения от Google могут быть сложными для расшифровки SEO-специалистами и веб-разработчиками. Чтобы лучше понять, я обратился к Джону Мюллеру, который предложил мне проверить мой веб-хостинг (без проблем) и убедиться, что файл CSS действительно может кэшироваться Google.
Search Console использует более старую службу веб-рендеринга (WRS) по сравнению с Mobile-Friendly Tool, поэтому в настоящее время я склонен придавать большее значение последнему.
Поскольку Google анонсирует новый робот Googlebot с новейшими возможностями рендеринга, все это может измениться, поэтому стоит быть в курсе того, какие инструменты лучше всего использовать для проверки рендеринга.
Еще один совет: если вы хотите увидеть полную прокручиваемую визуализацию страницы, вы можете переключиться на вкладку HTML в инструменте тестирования Google для мобильных устройств, нажать CTRL+A, чтобы выделить весь отображаемый HTML-код, затем скопировать и вставить в текстовый редактор и сохранить как файл HTML.
Открыв его в браузере (скрестим пальцы, иногда это зависит от используемой CMS!), вы получите прокручиваемый рендеринг. Преимущество этого в том, что вы можете проверить, как отображается любой сайт — вам не нужен доступ к Search Console.
5. Взломанные сайты и обратные спам-ссылки
Это довольно забавно, и часто можно подкрасться к сайтам, работающим на старых версиях WordPress или других платформах CMS, которые требуют регулярных обновлений безопасности.
В этом клиенте (салоне красоты) я заметил странные поисковые запросы, появляющиеся в Search Console.
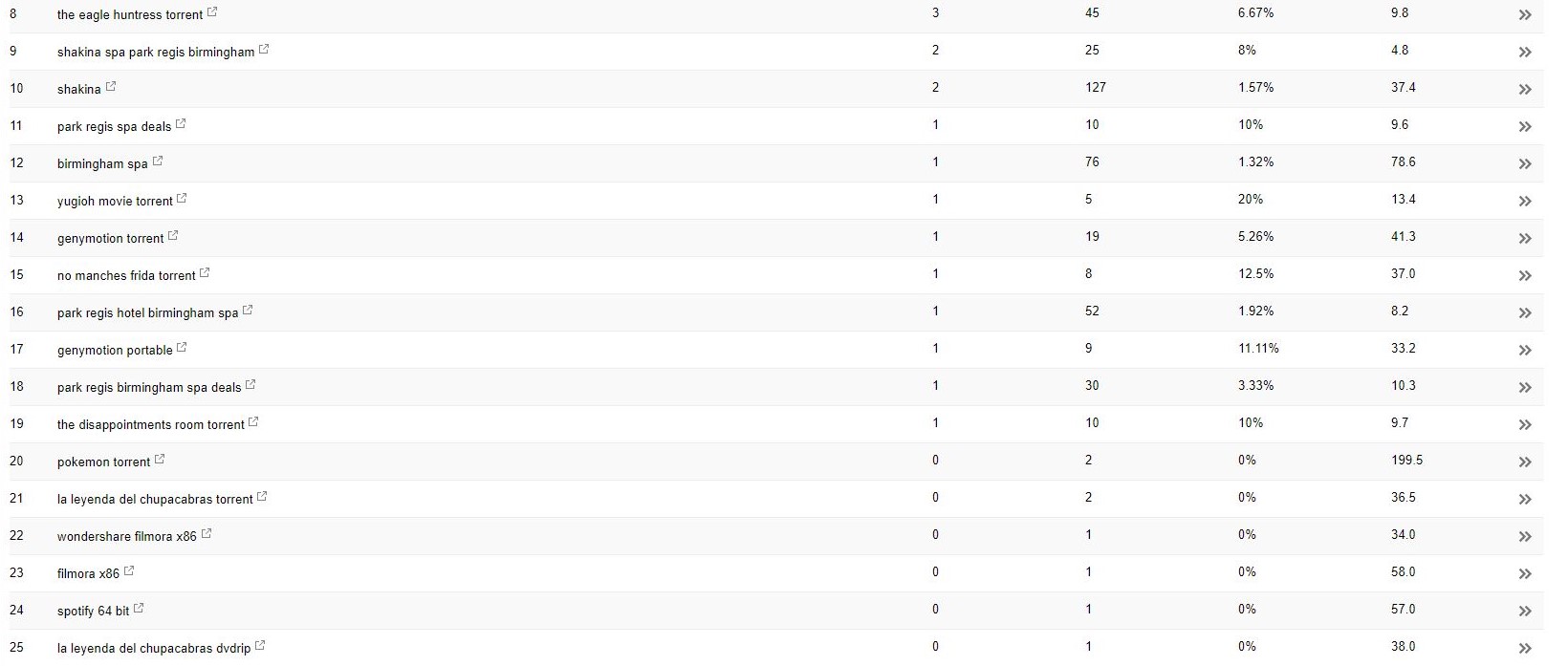
Удивительно, но у них были не только показы в Search Console, но и клики, то есть что-то должно было быть проиндексировано в домене.
Судя по запросам, это был явно спам, а не то, с чем клиент хотел бы ассоциировать свой бизнес.
Выполнив простой поиск «site:domain.com» в Google, мы обнаружили сотни страниц предполагаемых торрентов, которые клиент предположительно размещал на своем сайте.
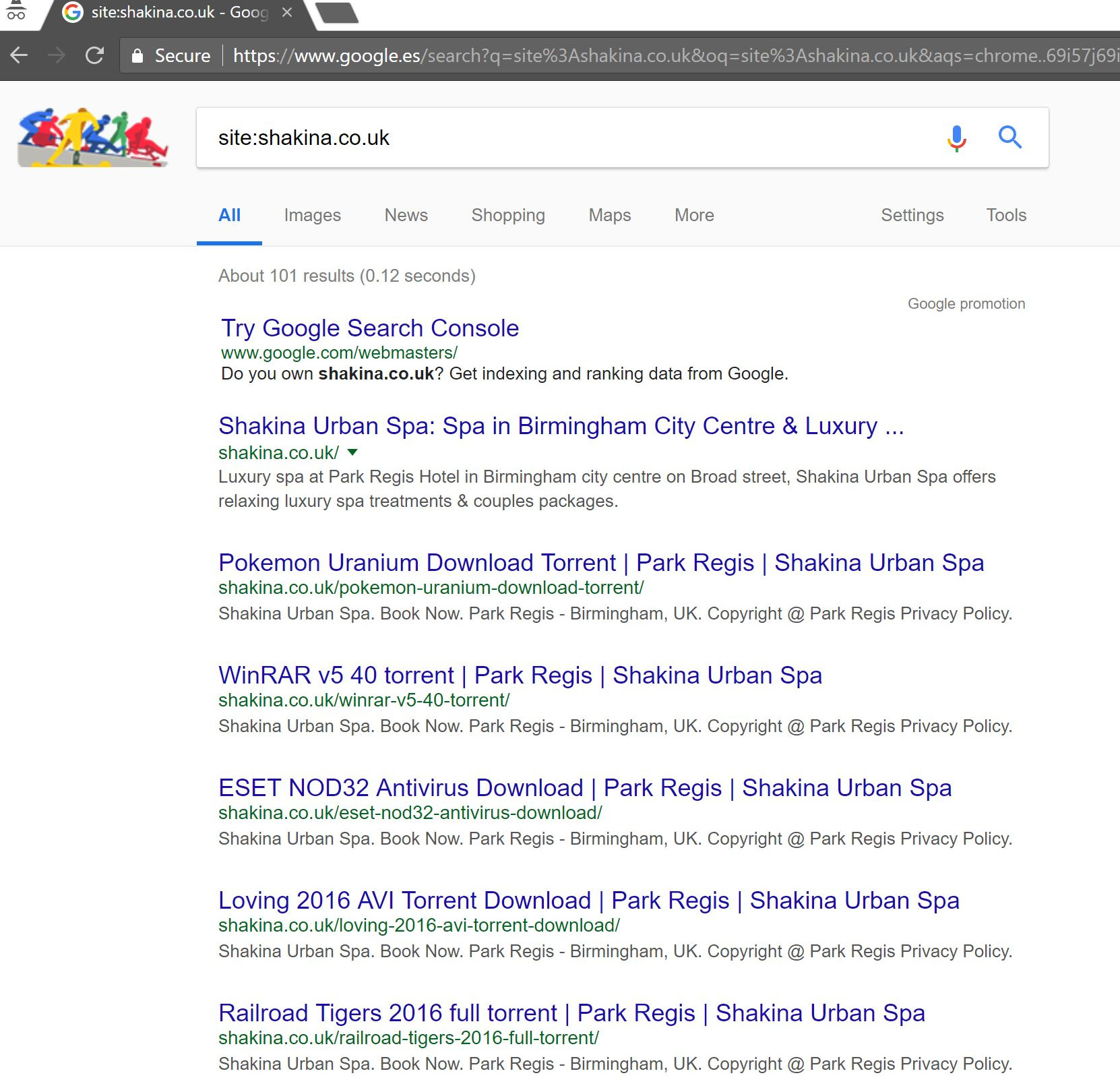
Посещение любого из этих URL-адресов фактически приводило к ошибке 404, но они все еще были проиндексированы (я также проверил различные пользовательские агенты, и все они получили одну и ту же ошибку 404).
Затем я прогнал домен через средство проверки обратных ссылок Majestic, и он выдал длинный список обратных ссылок очень низкого качества, указывающих на эти страницы на клиентских сайтах, что, вероятно, помогло их проиндексировать.
Глядя на Majestic Anchor Cloud обратных ссылок, действительно видно масштабы проблемы.


Единственное исправление здесь состояло в том, чтобы отклонить все эти обратные ссылки по доменам, а затем выполнить чистую проверку установки WordPress в надежде очистить любые инъекции кода или установить новую копию WordPress.
Если вас действительно беспокоит проиндексированный контент в случаях, подобных приведенному выше, вы также можете использовать код состояния 410, чтобы действительно прояснить ситуацию с помощью поисковых роботов.
Вышеупомянутое подходит для тех сайтов, которые получили юридические предупреждения из-за претензий об авторских правах со стороны кинопродюсеров, что иногда может произойти в подобных ситуациях, если проблема не будет решена быстро.
6 – Плохая международная SEO-настройка
Находясь в Испании, но просматривая Интернет на своем родном английском языке, я часто автоматически перенаправляюсь на испанскую версию веб-сайта.
Хотя я понимаю логику (я живу в Испании, поэтому хочу просматривать сайт на испанском языке), это довольно раздражает с точки зрения взаимодействия с пользователем, и, если все сделано неправильно, это также может вызвать небольшой хаос в вашем международном SEO.
Такие сайты, как Google Ads, выводят это на новый уровень — используют Angular JavaScript для динамического создания контента на основе моего местоположения, даже не пропуская перенаправления страниц любого рода и загружая контент прямо в DOM.
Мой предпочтительный метод выбора, когда доступно несколько языков, — это 302 перенаправление пользователя на язык в зависимости от настроек его интернет-браузера.
Поэтому, если кто-то использует немецкий язык в качестве языка по умолчанию в Google Chrome, ему, вероятно, будет удобно читать сайт на немецком языке независимо от их физического местоположения.
Это также помогает справляться с трудностями, когда кто-то находится в регионе, где говорят на разных языках, например, в Швейцарии, где используются французский, итальянский, немецкий и ретороманский.
Кроме того, для удобства использования важно обеспечить возможность переключения языков в зависимости от ваших предпочтений — на случай, если они захотят переключиться.
В одном случае я работал с отелем в Барселоне, где скрипт перенаправления языка JavaScript был добавлен на сайт без учета влияния SEO.
Этот сценарий перенаправлял пользователей в зависимости от языковых настроек их браузера (что само по себе не так уж плохо) с помощью перенаправления JavaScript на стороне клиента.
К сожалению, в этом случае скрипт был настроен неправильно из-за странной конфигурации постоянных ссылок сайтов, а в сочетании с тем фактом, что тег HTML lang отсутствовал на всех страницах сайта, Googlebot немного сошел с ума…
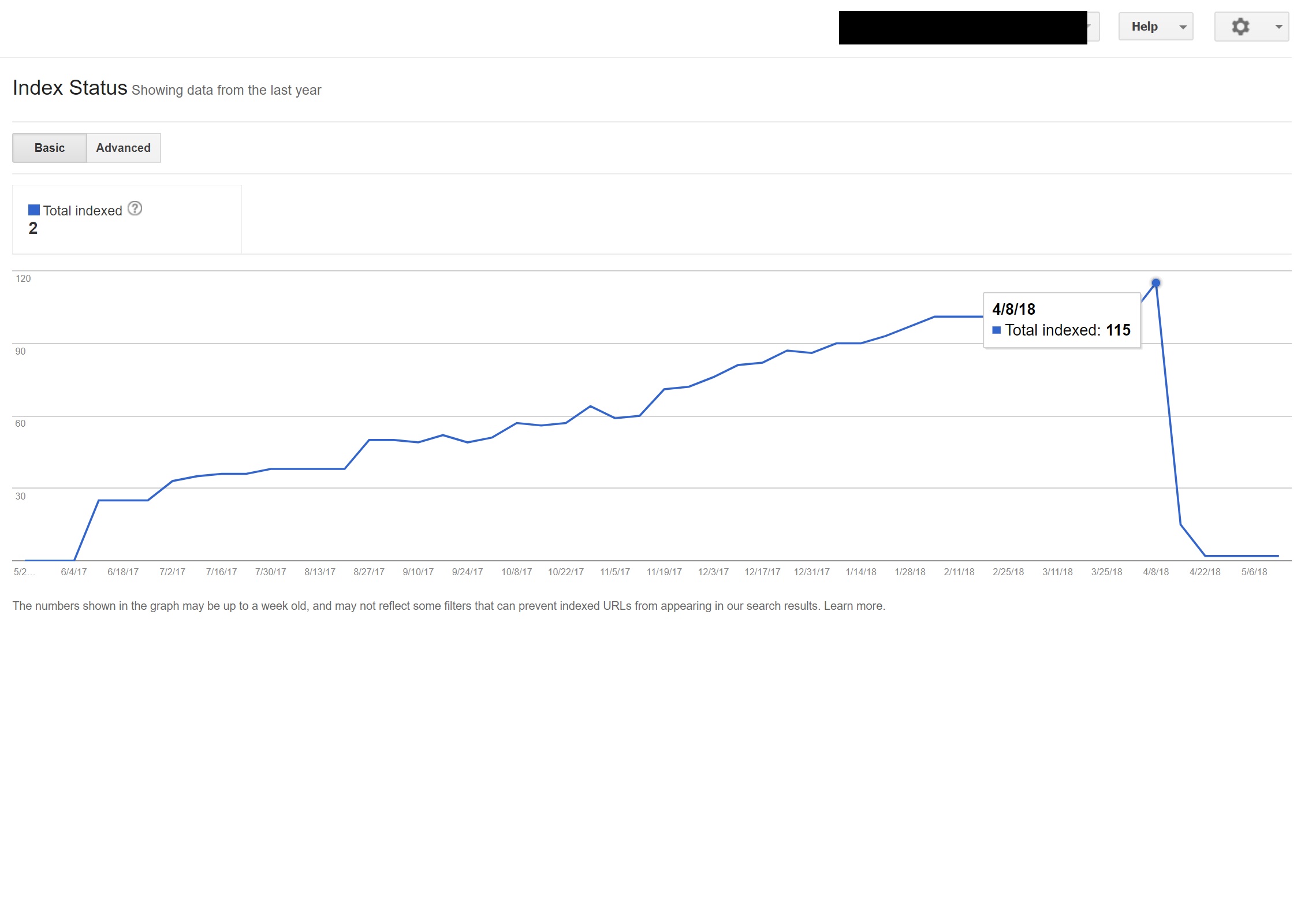
В этом примере почти весь неанглоязычный контент на сайте был деиндексирован Google, потому что он перенаправлялся на несуществующие страницы, что приводило к многочисленным ошибкам 404.
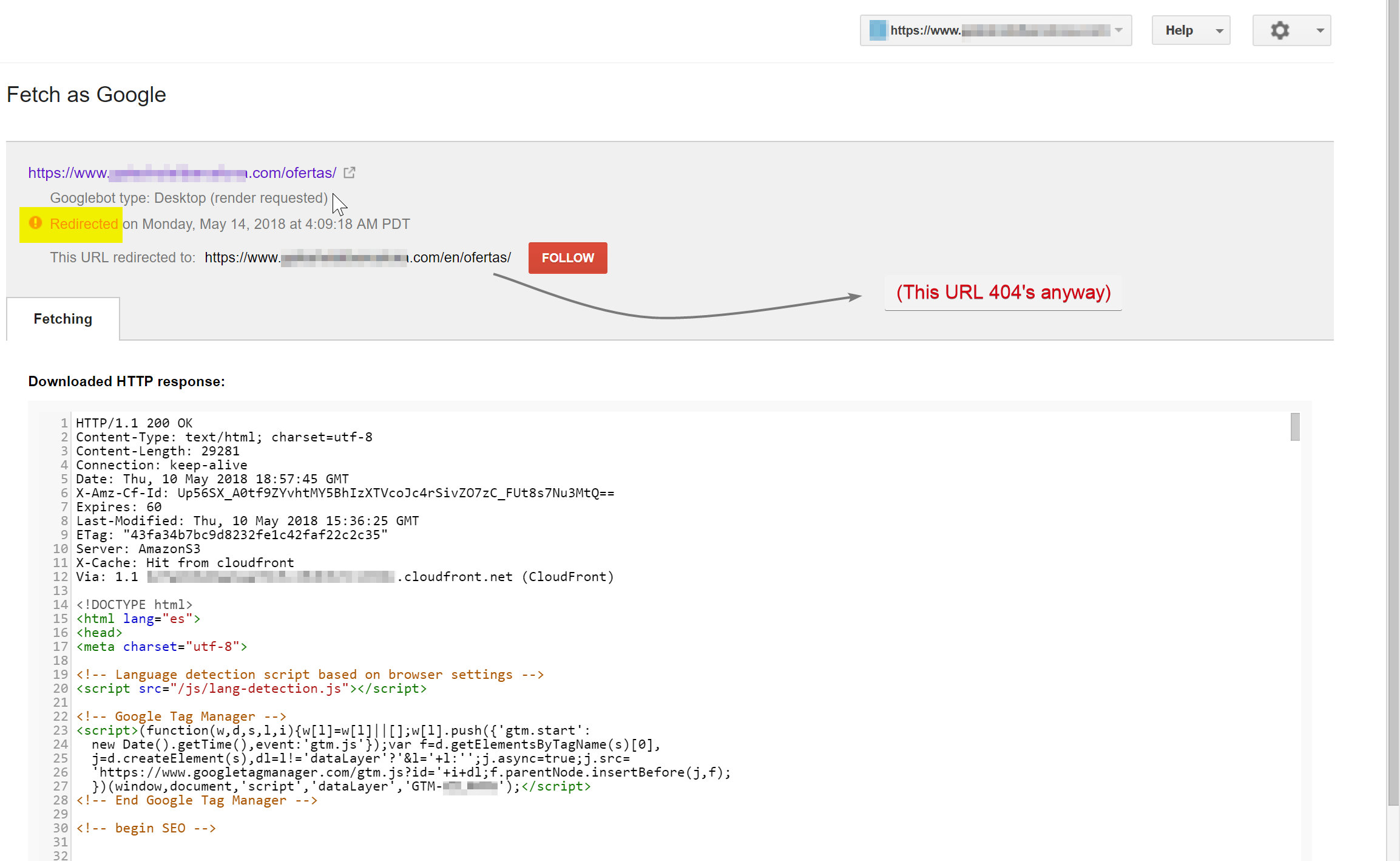
Робот Googlebot пытался просканировать контент на испанском языке (который существовал по адресу hotelname.com/ofertas) и был перенаправлен на hotelname.com/en/ofertas — несуществующий URL.
Удивительно, но в этом случае робот Googlebot отслеживал все эти перенаправления JavaScript, и поскольку он не мог найти эти URL-адреса, он был вынужден удалить их из своего индекса.
В приведенном выше случае я смог подтвердить это, получив доступ к журналам сервера сайта, отфильтровав робота Googlebot и проверив, где он получает 404-е.
Удаление неисправного скрипта перенаправления JavaScript решило проблему, и, к счастью, переведенные страницы не были деиндексированы надолго.
Всегда полезно полностью протестировать ситуацию — инвестиции в VPN могут помочь диагностировать такие типы сценариев или даже изменить ваше местоположение и/или язык в браузере Chrome.
[Пример успеха] Проведение аудитов нескольких сайтов
 Читать тематическое исследование
Читать тематическое исследование7 – Дублированный контент
Дублированный контент — довольно распространенная и хорошо обсуждаемая проблема, и есть много способов проверить дублированный контент на вашем сайте — недавно Ричард Бакстер написал отличную статью на эту тему.
В моем случае проблема, вероятно, немного проще. Я регулярно видел сайты, публикующие отличный контент, часто в виде сообщений в блогах, но затем почти мгновенно делящиеся этим контентом на стороннем веб-сайте, таком как Medium.com.
Medium — отличный сайт для перепрофилирования существующего контента для охвата более широкой аудитории, но следует соблюдать осторожность при подходе к этому.
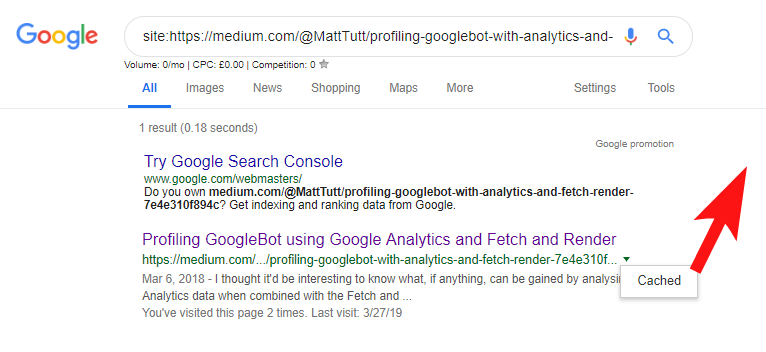
При импорте контента из WordPress на Medium во время этого процесса Medium будет использовать URL-адрес вашего веб-сайта в качестве своего канонического тега. Таким образом, теоретически это должно помочь отдать должное содержанию вашего веб-сайта как первоисточнику.
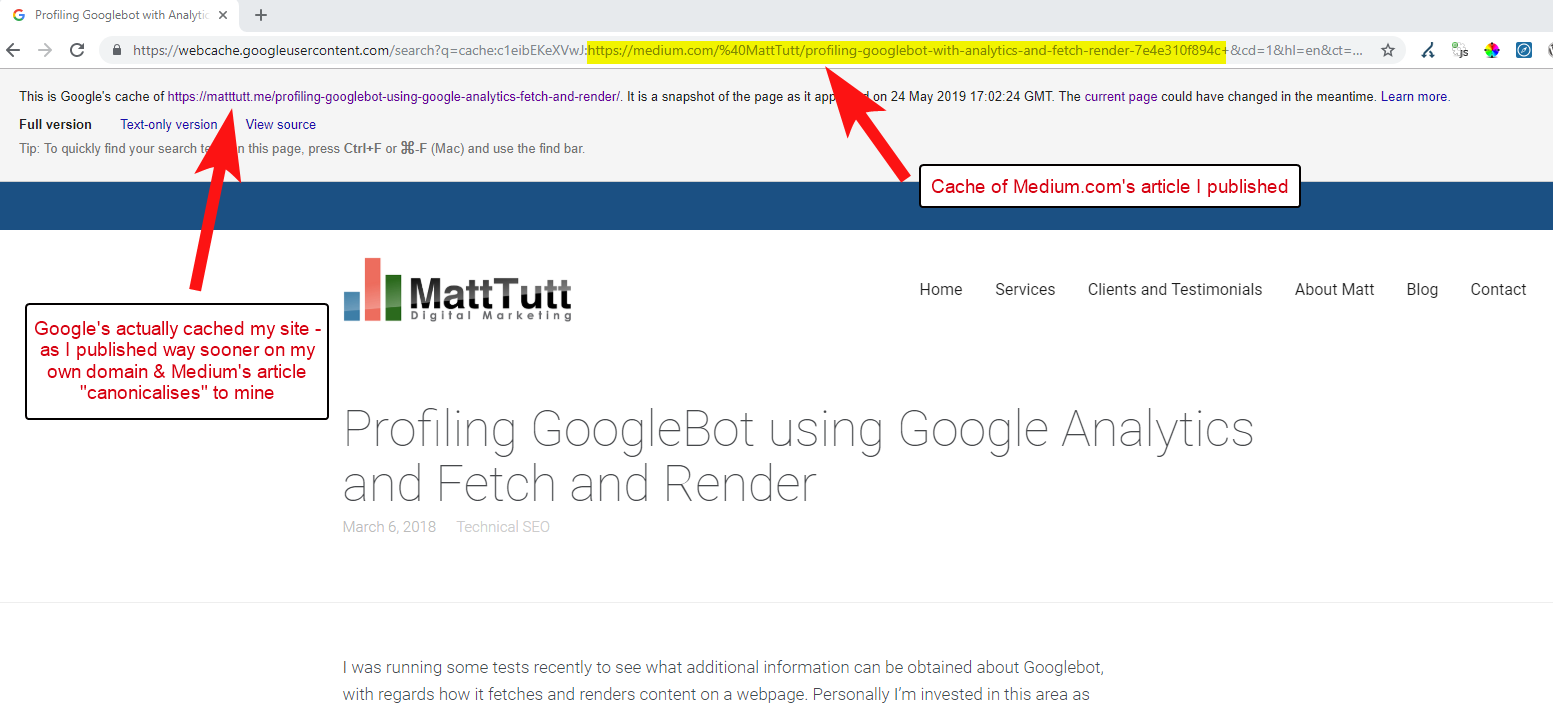
Судя по некоторым моим анализам, это не всегда работает так.
Я считаю, что это так, потому что, когда статья публикуется на Medium без предварительного предоставления времени Google для сканирования и индексации статьи в вашем домене, если статья будет хорошо принята на Medium (что немного удачно), ваш контент получит проиндексированы и связаны с сайтом Medium, несмотря на то, что они канонически указывают на ваш.
Как только контент будет добавлен на Medium (и особенно если он популярен), вы можете практически гарантировать, что этот фрагмент будет скопирован и повторно опубликован в Интернете в другом месте почти мгновенно, поэтому ваш контент снова будет дублироваться в другом месте.
Пока все это происходит, есть вероятность, что, если ваш домен довольно мал с точки зрения полномочий, у Google может даже не быть возможности просканировать и проиндексировать опубликованный вами контент — и может даже случиться так, что элемент рендеринга сканирование/индексирование еще не завершено, или используется тяжелый JavaScript, вызывающий большую задержку между сканированием, рендерингом и индексированием этого контента.
Я видел ситуации, когда крупная компания публикует отличную статью, но на следующий день они публикуют ее в качестве размышления в огромном отраслевом новостном блоге. Вдобавок к этому на их сайте была проблема, из-за которой контент дублировался (и индексировался) на https://domain.com и https://www.domain.com.
Через несколько дней после публикации при поиске в Google точной фразы статьи в кавычках сайта компании нигде не было видно. Вместо этого авторитетный отраслевой блог оказался на первом месте, а следующие позиции заняли другие переиздатели.
В этом случае контент был связан с отраслевым блогом, поэтому любые ссылки, которые получит статья, будут приносить пользу этому веб-сайту, а не первоначальному издателю.
Если вы собираетесь повторно использовать контент где-либо в Интернете, он, вероятно, будет проиндексирован, вам действительно следует подождать, пока вы не будете полностью уверены, что он был проиндексирован Google в вашем собственном домене.
Вероятно, вы усердно работаете над созданием и обработкой своего контента — не выбрасывайте все это, слишком стремясь повторно опубликовать в другом месте!
8 – Неверная конфигурация AMP (отсутствует объявление URL-адреса AMP)
Только несколько клиентов, которым я помогал, решили попробовать AMP, возможно, на основании некоторых из множества тематических исследований, посвященных его использованию, финансируемых Google.
Иногда я даже не подозревал, что у клиента вообще была AMP-версия своего сайта — в отчетах Google Analytics появлялся какой-то странный трафик, — где AMP-версия сайта ссылалась на не-AMP-версию сайта.
В этом случае версии AMP-страниц были настроены неправильно, поскольку в заголовке не-AMP-страниц отсутствовала ссылка на URL.

Не сообщая поисковым системам, что страница AMP существует по определенному URL-адресу, нет особого смысла вообще настраивать AMP — дело в том, что она индексируется и возвращается в SERPS для мобильных пользователей.
Добавление ссылки на вашу не-AMP-страницу — важный способ рассказать Google о AMP-странице, и важно помнить, что канонические теги на AMP-страницах не должны ссылаться на самих себя: они ссылаются на не-AMP-страницу.
И хотя это не совсем техническое SEO-соображение, стоит отметить, что вам все равно нужно включать код отслеживания на страницы AMP, если вы хотите иметь возможность сообщать о любом трафике и информации о поведении пользователей.
Как правило, в рамках моих SEO-аудитов мне также нравится проводить некоторые базовые проверки реализации аналитики — в противном случае предоставленные вам данные могут оказаться не такими уж полезными, особенно если была настроена ложная аналитика.
9 — Устаревшие домены, которые перенаправляют 302 или образуют цепочку перенаправлений.
При работе с крупным независимым гостиничным брендом в США, который за последние несколько лет претерпел несколько ребрендингов (что довольно часто встречается в индустрии гостеприимства), важно отслеживать, как ведут себя предыдущие запросы на доменное имя.
Это легко забыть, но это может быть простая полурегулярная проверка попытки сканирования их старого сайта с помощью такого инструмента, как OnCrawl, или даже стороннего сайта, который проверяет коды состояния и перенаправления.
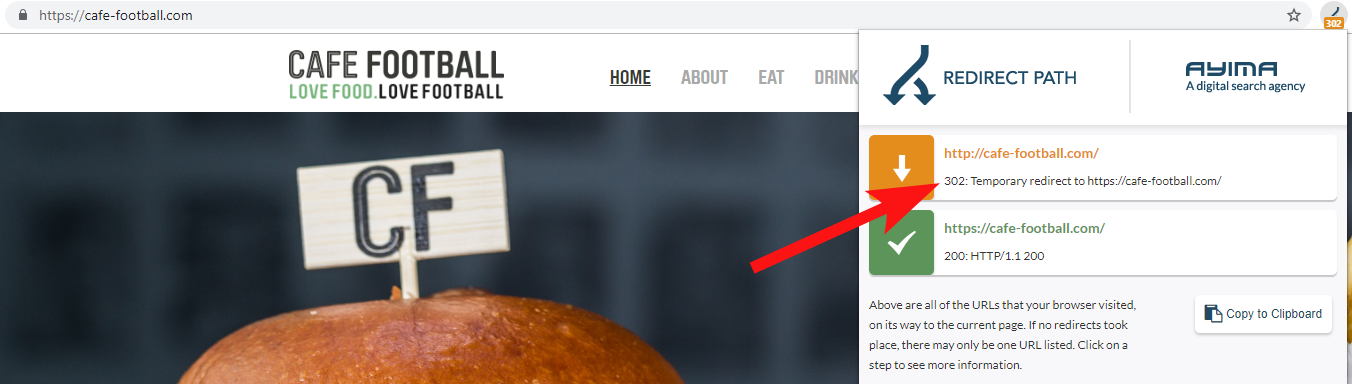
Чаще всего вы обнаружите, что домен 302 перенаправляет на конечный пункт назначения (здесь всегда лучше всего подходит 301) или 302 на не-WWW-версию URL-адреса, прежде чем перейти через еще несколько перенаправлений, прежде чем попасть на конечный URL-адрес.
Джон Мюллер из Google заявлял ранее, что они выполняют только 5 перенаправлений, прежде чем сдаться, в то время как также известно, что при каждом пройденном перенаправлении часть значения ссылки теряется. По этим причинам я предпочитаю использовать 301 редиректы, которые настолько чисты, насколько это возможно.
Redirect Path от Ayima — отличное расширение для браузера Chrome, которое покажет вам статусы перенаправления, когда вы просматриваете веб-страницы.
Еще один способ, которым я обнаружил старые доменные имена, принадлежащие клиенту, — это поиск в Google его номера телефона, использование кавычек с точным соответствием или частей их адреса.
Такой бизнес, как отель, не часто меняет адрес (по крайней мере, его часть), и вы можете найти старые каталоги / бизнес-профили, которые ссылаются на старый домен.
Использование инструмента обратных ссылок, такого как Majestic или Ahrefs, также может выявить некоторые старые ссылки с предыдущих доменов, так что это тоже хороший вариант, особенно если вы не контактируете с клиентом напрямую.
10. Плохая работа с контентом внутреннего поиска
На самом деле это тема, о которой я писал ранее здесь, в OnCrawl, но я включаю ее снова, потому что я все еще очень часто вижу проблемный внутренний контент, который появляется «в дикой природе».
Я начал эту статью с рассказа о проблеме с директивой Pingdom robots.txt, которая со стороны выглядела как исправление, предотвращающее сканирование и индексацию выводимого ими контента.
Любой сайт, который предоставляет Google результаты внутреннего поиска в качестве контента или выводит много пользовательского контента, должен очень внимательно относиться к тому, как они это делают.
Если сайт отправляет результаты внутреннего поиска в Google очень прямым образом, это может привести к тому или иному ручному наказанию. Google, скорее всего, воспримет это как плохой пользовательский опыт — они ищут X, а затем попадают на сайт, где им затем приходится вручную фильтровать то, что они хотят.
Я считаю, что в некоторых случаях может быть нормально обслуживать внутренний контент, это просто зависит от контекста и обстоятельств. Например, сайт вакансий может захотеть предоставить последние результаты поиска работы, которые обновляются почти ежедневно, поэтому им почти приходится с этим сталкиваться.
Действительно, это известный пример сайта вакансий, который, возможно, заходит слишком далеко, генерируя любой контент на основе популярных поисковых запросов (см. ниже, что может произойти, если вы используете эту тактику).
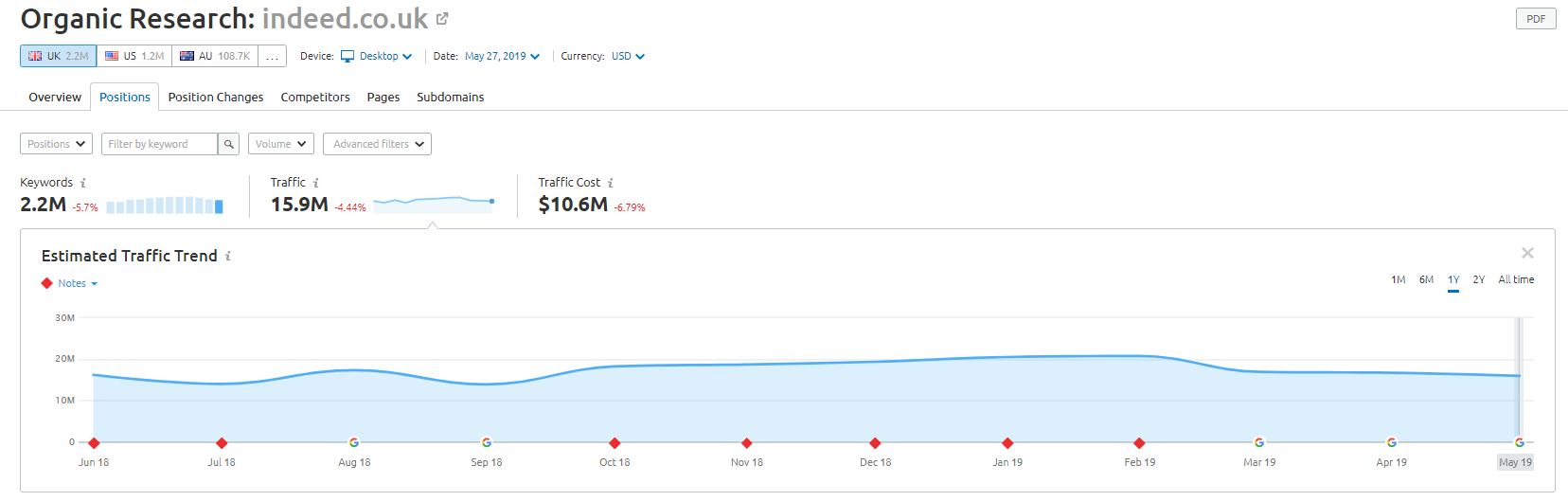
Несмотря на это, хотя, согласно данным SEMRush, их органический трафик работает отлично, но это тонкая грань, и такое поведение подвергает вас высокому риску штрафа Google.
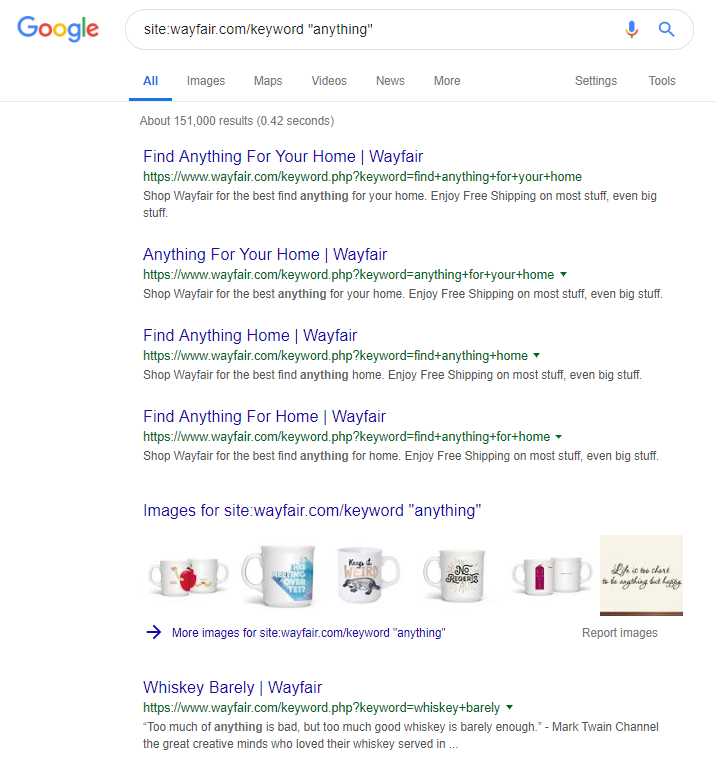
Интернет-магазин Wayfair.com — еще один бренд, который любит плыть по ветру. С миллионами проиндексированных URL-адресов (и большим количеством автоматически сгенерированных URL-адресов ключевых слов) они отлично справляются с органическим трафиком, но они рискуют быть оштрафованными за предоставление контента поисковым системам таким образом.
Внедрив надлежащую структуру сайта, которая включает в себя категоризацию всего контента, создание различных иерархий родительских и дочерних элементов, даже использование тегов или других пользовательских таксономий, вы можете помочь клиентам и поисковым роботам в навигации.
Использование трюков, подобных описанным выше, может помочь в краткосрочной перспективе, но маловероятно, что это поможет вам в долгосрочной перспективе. Поэтому очень важно с самого начала создать правильную структуру сайта или, по крайней мере, правильно спланировать ее заранее.
Подведение итогов
10 ошибок, обсуждаемых в этой статье, являются одними из наиболее распространенных технических проблем, с которыми я сталкиваюсь во время аудита сайта.
Исправление этих ошибок на вашем сайте — это первый шаг к тому, чтобы убедиться, что ваш сайт технически исправен. Как только эти проблемы будут исправлены, технический аудит может сосредоточиться на проблемах, характерных для вашего сайта.