
8 распространенных ошибок, обнаруженных во время SEO-аудита
Опубликовано: 2019-02-26После проведения SEO-аудита веб-сайтов более 10 лет я провел аудит многих веб-сайтов. В последние несколько лет я заметил неприятную тенденцию среди некоторых очень распространенных ошибок, которые допускают владельцы веб-сайтов. В конечном итоге мне приходится указывать на эти самые ошибки почти в каждом SEO-аудите, который я проводил за последний год или около того. Ошибки — это то, что я бы назвал распространенными ошибками веб-сайта и веб-дизайна — это проблемы веб-сайта, а не проблемы поисковой оптимизации. Тем не менее, эти проблемы влияют на трафик веб-сайта и его видимость в результатах поиска. Поэтому я должен указать на них во время технического SEO-аудита, который я провожу для клиентов.
Я называю эти ошибки распространенными ошибками, потому что 8 из 10 технических SEO-аудитов, которые я проводил за последние два года, имеют как минимум 80 процентов этих проблем. Я не возражаю против того, чтобы веб-сайты имели эти проблемы до того, как они пришли ко мне для аудита поисковой оптимизации. Я могу списать это на безопасность работы в качестве консультанта по SEO. Тем не менее, давайте рассмотрим эти 8 распространенных ошибок, с которыми я сталкиваюсь во время SEO-аудита. Проверьте, не совершает ли ваш сайт какие-либо из этих ошибок. Если да, то использование OnCrawl поможет выявить и устранить эти проблемы. Ниже я подробно описал каждую проблему, объяснил, почему она важна, и как использование OnCrawl может помочь вам решить эту проблему.
1. Плохой переход с HTTP на HTTPs
2. Дублирование контента
3. Мегаменю и внутренние ссылки
4. Проблемы со структурой сайта
5. Потерянный контент и страницы
6. Проблемы со ссылками, плохие и некачественные ссылки
7. Чрезмерная оптимизация или отсутствие оптимизации
8. Неправильное использование кода или директив
Распространенная ошибка: плохой переход с HTTP на HTTPs
Я вижу эту ошибку не только во время SEO-аудита, но и просто просматривая веб-страницы. Основным индикатором наличия проблемы является значок сломанного замка в браузере. Если вы посещаете веб-сайт со сломанным символом блокировки, значит, на сайте есть эта проблема. Когда веб-сайты перемещаются с HTTP на HTTPs (с незащищенной на безопасную версию (SSL), каждое упоминание и внутренняя ссылка в доменном имени должны быть изменены на HTTPs. Это означает, что если исходный код веб-сайта ссылается на изображение ( на всех сайтах есть изображения), он должен загружать это изображение через HTTP, а не через HTTP. Если он ссылается на HTTP следующим образом:
< img src="https://www.oncrawl.com/images/logo.png" alt="Логотип OnCrawl" />
на странице, где появляется этот код, будет отображаться символ сломанного замка. URL-адрес для OnCrawl.com должен быть HTTP, а не HTTP, как показано выше. Другой связанной с этим проблемой могут быть внутренние ссылки и то, как страницы ссылаются друг на друга на веб-сайте. Правильно перенесенный веб-сайт с HTTP на HTTPS всегда будет ссылаться с одной страницы на другую, используя URL-адрес HTTPS в ссылке, а не HTTP. Если ссылки на сайте такие:
< a href=" https://www.oncrawl.com/support/">Связаться со службой поддержки
и ссылку на URL-адрес HTTP, то, скорее всего, это вызовет постоянное перенаправление 301, перенаправляющее посетителей на https://www.oncrawl.com/support/, который является HTTP-версией этой страницы. Когда вы сканируете веб-сайт с помощью OnCrawl, OnCrawl сообщит о МНОЖЕСТВЕ перенаправлений. Это не хорошо. Правильный переход веб-сайта с HTTP на HTTPs приведет к отсутствию перенаправлений на веб-сайте при его сканировании.
Как исправить эту распространенную ошибку
Вообще говоря, все внутренние ссылки вашего сайта и ссылки на полный URL-адрес вашего сайта в исходном коде вашего сайта должны указывать на HTTP-версию вашего сайта, а не на HTTP. Если вы используете WordPress, вы можете выполнить поиск по всей базе данных вашего сайта в поисках URL-адреса HTTP вашего сайта (включая доменное имя) и заменить его версией HTTPs. Вы также можете сделать это в других CMS, у которых есть база данных. Для получения дополнительной информации я недавно рассказывал об этом в предыдущей статье OnCrawl под названием «Обеспечение бесперебойной миграции вашего домена» (https://www.oncrawl.com/technical-seo/domain-migration/).
Распространенная ошибка: повторяющиеся проблемы с контентом
Проблемы с дублирующимся контентом довольно распространены, и на самом деле очень сложно сделать ваш сайт на 100% свободным от дублированного контента. Если у вас есть основная навигация на вашем сайте, она будет отображаться на всех страницах сайта, поэтому обычно присутствует хотя бы часть дублированного контента. Тем не менее, одна из распространенных ошибок, с которыми я сталкиваюсь, — это когда на сайте будет абзац текста (или даже больше!), Который появляется на всех страницах сайта. Например, у вас может быть абзац текста «о вашей компании» в нижнем колонтитуле сайта. На самом деле это не вызывает большой проблемы, если только на вашем сайте нет страниц, на которых меньше контента, чем этот абзац текста в нижнем колонтитуле сайта. Если абзац в нижнем колонтитуле состоит из 200 слов, а остальная часть страницы содержит менее 200 слов (что является распространенным явлением), то текст нижнего колонтитула будет перевешивать другой контент на странице. Это может стать проблемой, если на вашем сайте несколько страниц.
На одном веб-сайте, который я проверял, была боковая панель с недавними отзывами клиентов. Он прокручивал отзывы, поэтому посетители видели только один отзыв за раз. Обычно это не было бы проблемой, но исходный код страницы содержал более 30 отзывов, которые она «прокручивала». Весь текст всех 30 отзывов загружается на каждую страницу сайта. Это было буквально более 3500 слов содержания в отзывах. Ни на одной странице сайта не было более 3500 слов. Итак, каждая отдельная страница сайта содержала одни и те же 3500 слов контента. Мы убрали отзывы с боковой панели, и рейтинг сайта и трафик взлетели до небес.
Технически штраф за дублирование контента на вашем сайте не предусмотрен, за исключением случаев, когда дублированный контент настолько плох, что требует штрафа от Google за спам. Это довольно редко, если вы копируете страницы и/или веб-сайты, то вы, вероятно, уже знаете о дублирующемся контенте. Большинство сайтов намеренно не дублируют свой контент, поэтому могут возникнуть проблемы со сканированием. Сайт может легко израсходовать свой «краулинговый бюджет», тратя его на дублированный контент. Важно направить сканеры поисковых систем на сканирование уникальных страниц с лучшим содержанием.
Как исправить эту распространенную ошибку
Используйте функцию OnCrawl Duplicate Content в отчете о сканировании, чтобы узнать о количестве дублированного контента на вашем сайте. Например, если на сайте есть повторяющиеся теги заголовков, дублирующиеся теги метаописания и дублирующиеся теги заголовков, вы можете выяснить, являются ли эти страницы дубликатами или нет. Некоторые сайты WordPress будут генерировать дубликаты страниц с тегами, категориями и заархивированными страницами, такими как страницы по дате.
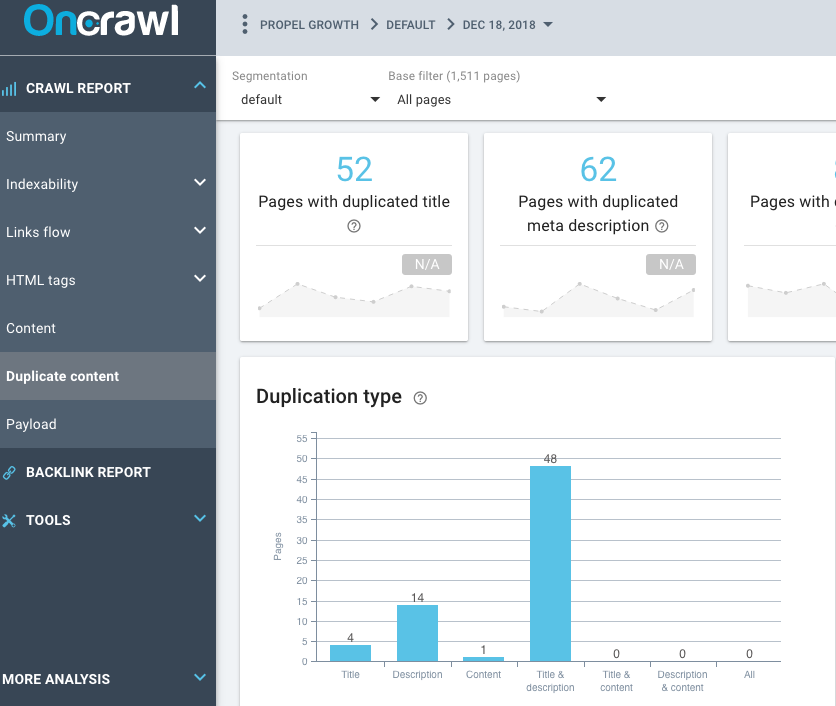
Распространенная ошибка: мегаменю
Сколько ссылок есть на сайте в их навигации? Я буквально видел сотни ссылок (более 200-300 ссылок) в главной навигации одного сайта. Мало того, что посетителям сайта тяжело пытаться найти то, что они ищут, это не очень хорошо для SEO в целом. Это мегаменю, когда на сайте есть более 10 выпадающих основных элементов, и каждый из этих выпадающих основных элементов имеет более 10 элементов, а некоторые даже имеют элементы подменю. В конечном итоге это означает, что у вас есть более 100 страниц, ссылающихся друг на друга. Это 100 страниц, ссылающихся напрямую на 100 страниц.
Сайты, подобные этому, могут быть легко (и должны быть) переоценены, поскольку структура сайта не очень хорошо категоризирована. Один сайт, на котором я провел SEO-аудит, — это сайт электронной коммерции с более чем 300 000 страниц продуктов. На сайте продается офисная мебель, а также церковная мебель и тренажеры. Вы можете буквально оказаться на странице о церковных скамьях, а затем сразу перейти на страницу о ковриках для йоги. Я не знаю никого, кто покупал бы церковные скамьи и коврики для йоги одновременно.
Это экстремальный пример, но основная навигация имеет раскрывающиеся меню, позволяющие кому-то напрямую переходить на страницы по этим темам (на которые ссылается сайт). Думайте о веб-сайте как о нескольких различных «тематических» областях или мини-сайтах на одном более крупном веб-сайте. Есть домашняя страница, но эта домашняя страница должна ссылаться только на основные категории. Эти страницы категорий должны затем ссылаться на страницы в этой категории. Затем перейдите к подкатегории, а затем вниз на страницу продукта. Посетители должны щелкнуть другую категорию, прежде чем они смогут перейти непосредственно на страницу, не относящуюся к теме.
Связывать 200 страниц с 200 страницами в навигации никогда не бывает хорошо. Если это мегаменю, то его нужно исправить, а это значит, что оно связано с общими проблемами структуры сайта, которые также возникают на сайте.
Как исправить эту распространенную ошибку
Есть несколько вещей, которые вам нужно пересмотреть, чтобы начать избавляться от мегаменю сайта. Взгляните на внутреннюю структуру сайта, просмотрите разрозненные темы (если они вообще существуют на сайте) и просмотрите свои кластеры контента. Подобные страницы должны ссылаться на похожие страницы (страницы по той же теме).

Распространенная ошибка: проблемы со структурой сайта
На самом деле это очень похоже на проблему мегаменю. Если на сайте есть мегаменю, то оно не настроено таким образом, чтобы структура сайта была идеальной. Как я упоминал ранее, структура сайта должна быть настроена таким образом, чтобы похожие темы были сгруппированы вместе. Довольно редко на сайте должна быть страница, связанная с подтемой, а затем с категорией, и все же иметь сотни внутренних ссылок, указывающих на нее. Есть ли на сайте страницы-сироты? Выявлены ли в отчете OnCrawl после сканирования сайта потерянные страницы с трафиком и рейтингом, которые не являются частью структуры сайта?
Как исправить эту распространенную ошибку
Взгляните на внутренние отчеты о популярности, которые создает OnCrawl, просмотрите группы страниц по глубине, распределение Inrank и поток Inrank. Есть ли у сайта мегаменю на главной странице сайта? Ссылается ли мегаменю на страницы подкатегорий? Это не должно. В главном меню на главной странице сайта должно быть небольшое количество страниц категорий.
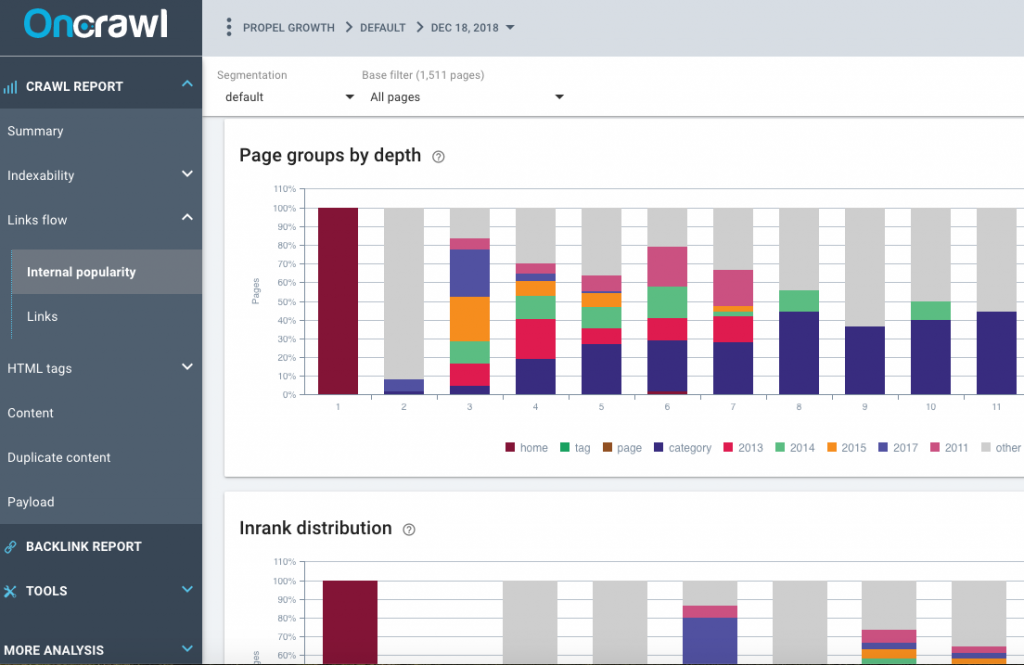
Есть ли четкие темы или разделы сайта? Это потребует ручного просмотра сайта, вы сможете довольно легко сказать, есть ли мегаменю со всеми страницами на сайте или есть разделы. Еще одна проблема, которую следует рассмотреть, — это раздел «Ссылки» отчета OnCrawl.

Обратите внимание на среднее количество внутренних ссылок на страницу и среднее количество внутренних фолловеров на странице. Как правило, входящих ссылок на страницы должно быть больше, чем исходящих. Если эти цифры очень близки или исходящих ссылок больше, чем входящих, то это может быть проблема со структурой сайта. Есть ли на сайте страницы с менее чем 10 ссылками для перехода? Есть ли страницы-сироты, не являющиеся частью структуры сайта?
Распространенная ошибка: потерянный контент и страницы
Страницы-сироты встречаются чаще, чем вы думаете. Страницы-сироты — это просто: когда поисковый робот начинал с домашней страницы сайта и переходил от ссылки к ссылке на сайте, он не мог найти ссылку на страницу-сироту. Страницы-сироты обнаруживаются OnCrawl, потому что он анализирует данные Google Analytics, данные Google Search Console и (надеюсь) данные файла журнала вашего сайта. OnCrawl находит страницы, на которые нет ссылок на сайте, и идентифицирует их как страницы-сироты. На самом деле они более распространены, чем вы могли бы ожидать, потому что мы склонны переделывать наши веб-сайты и оставлять страницы на веб-сервере, но не ссылаться на них. Это может быть старая версия сайта или контент, который не подходит для включения в новую версию сайта. Но, тем не менее, страницы все еще существуют на сайте, даже если они не связаны напрямую с текущего общедоступного сайта. Такое случается — страницы-сироты могут иметь большой трафик и высокий рейтинг.
Как исправить эту распространенную ошибку
Есть несколько способов решить эту проблему. На самом деле, если вы предоставите OnCrawl правильные данные, такие как Google Analytics, Majestic, Google Search Console и данные файла журнала, он очень хорошо идентифицирует потерянные страницы. Итак, предоставьте OnCrawl все эти данные, если у вас есть к ним доступ. Файлы журнала могут быть очень важны, так как они могут раскрывать другие данные, такие как ошибки 404 и перенаправления, которые помогут вам восстановить потерянный трафик и ранжирование.
Чтобы исправить эту распространенную ошибку, определите важные потерянные страницы, а затем правильно свяжите их на сайте. Если есть ссылки с других веб-сайтов, ведущих на ваш веб-сайт, вы можете определить это с помощью данных о ссылках Majestic.com. Ссылки на страницы-сироты, на которые есть ссылки по всему сайту, могут правильно передавать InRank и PageRank другим страницам сайта, помогая ему ранжироваться.
Распространенная ошибка: проблемы со ссылками, плохие и некачественные ссылки
Взгляните на числа Majestic Domain Trust Flow и Domain Citation Flow. Вообще говоря, Trust Flow должен быть выше Citation Flow как минимум на 10 пунктов. Если поток цитирования выше, чем поток доверия, у вас могут быть низкокачественные ссылки, ведущие на веб-сайт. Как правило, у вас должны быть хорошие, качественные ссылки, указывающие на ваш веб-сайт, а не множество низкокачественных, ненадежных сайтов, ссылающихся на ваш веб-сайт. Обычно на ваш веб-сайт указывают ссылки более низкого качества, поскольку мы не можем контролировать всех, кто ссылается на наш сайт. Однако мы можем контролировать некоторые ссылки.
Как исправить эту распространенную ошибку
Потратьте время, чтобы просмотреть все ссылки на ваш сайт. Также просмотрите список страниц, на которые есть ссылки. Есть ли страницы со ссылками, которые в настоящее время не разрешаются? Может быть, есть старая страница, которой больше не существует, на которой есть ссылки? Либо верните эту страницу контента по тому же URL-адресу, либо 301 перенаправьте эту страницу на другую связанную страницу по той же теме — таким образом вы восстановите эти ссылки.
Распространенная ошибка: чрезмерная оптимизация или отсутствие оптимизации
Еще одна распространенная ошибка, которую я вижу все время, — это оптимизация страницы, которая, кажется, была сделана более 10 лет назад, или SEO, выполненное на сайте, который следует стандартам SEO 10-летней давности. Текущие передовые методы SEO не соблюдаются, и обычно это включает в себя наполнение ключевыми словами, плохо написанные метаданные, такие как плохо написанные теги заголовков или метатеги описания, или даже неправильное использование тегов заголовков.
Как исправить эту распространенную ошибку
Исправить эту распространенную ошибку довольно легко — изучите передовые методы написания тегов заголовков, метаданных и используйте приемлемые методы кодирования HTML. Упорядоченные списки, маркированные списки, использование полужирного шрифта, курсива, а также правильные размеры и цвета шрифта являются обязательными в наши дни. Очистка HTML-кода и использование правильного кода разметки, такого как код Schema.org и код JSON-LD, может иметь большое значение для повышения рейтинга и увеличения трафика поисковых систем.
Распространенная ошибка: неправильное использование кода или директив
Использование слишком большого количества или использование неподходящего или неправильного кода Schema.org может привести к ручным действиям со стороны Google. Хотя структурированные данные хороши, они должны быть реализованы правильно, иначе могут быть серьезные последствия — они могут иметь для вас неприятные последствия. Многие сайты не используют никакой структурированной разметки, и в настоящее время это просто упущенная возможность.
Другие связанные с этим проблемы могут включать неправильную реализацию кода или даже наличие конфликтующих директив на страницах. Например, если вы используете канонический тег на странице, не запрещайте поисковым системам сканировать эту страницу в файле robots.txt. Если они не могут просканировать страницу, они не увидят канонический тег.
Другие неправильные реализации кода или конфликтующие директивы, которые я обычно вижу:
- неправильное использование rel next/prev
- неправильные директивы канонических тегов
- неправильные директивы robots.txt
Как исправить эту распространенную ошибку
Честно говоря, чтобы иметь возможность обнаруживать и устранять эти проблемы, вы должны понимать, что делает каждая из этих директив и почему они используются. Вам не нужно быть программистом, чтобы понимать код schema.org, но вы должны иметь общее представление о том, почему и когда он используется. Я не кодер, но я могу копировать и вставлять код, и существует множество генераторов кода, которые помогут вам сделать это правильно.
SEO-краулер OnCrawl
 Учить больше
Учить большеВ заключение
Мы все совершаем ошибки, и, к счастью, все эти ошибки легко исправить, что может привести к более оптимизированному сайту, гораздо более удобному для поисковых систем и удобному для посетителей сайту. Надлежащий SEO-аудит, даже если он будет проведен самостоятельно на вашем собственном веб-сайте, наверняка выявит одну или несколько из этих распространенных ошибок. Я лично проверил свои собственные сайты и обнаружил проблемы, о которых я не знал, но смог исправить после того, как такие инструменты, как OnCrawl, указали мне на них. И тем не менее, мы должны выбрать наши сражения, так как некоторые из обнаруженных проблем могут быть не такими важными, как другие.