
Создание инструментов для анализа производительности контента
Опубликовано: 2020-09-03Контент — одна из основных движущих сил стратегии входящего маркетинга, а SEO — неотъемлемая часть этой работы. Как правило, это будет охватывать основы SEO на странице: структуру статьи, размещение ключевых слов, метатеги, теги заголовков, альтернативный текст, заголовки, структурированные данные и использование форматирования для создания неформально структурированных данных в списках и таблицах.
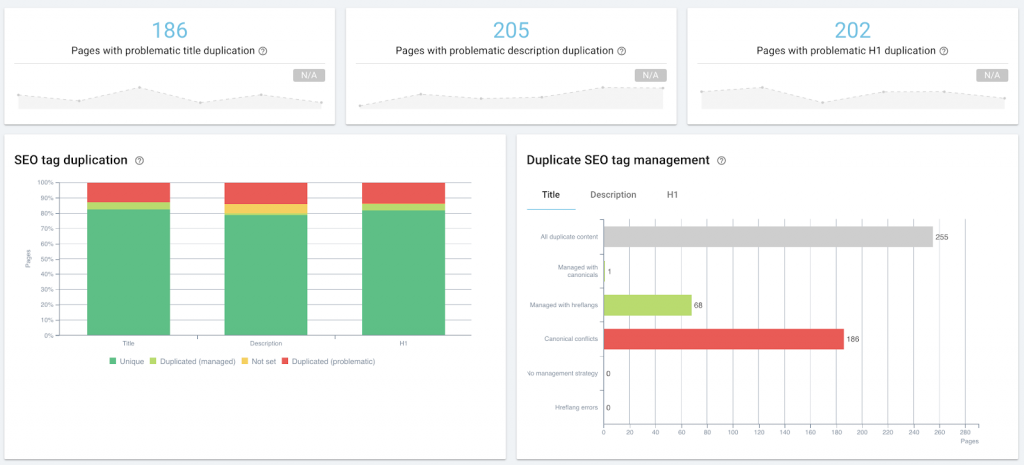
Аудит SEO на странице как часть управления контентом с помощью OnCrawl.
Это относится к техническому SEO, когда вы начинаете массовую оптимизацию или мониторинг, будь то с помощью аудита сайта или регулярного сканирования, с помощью машинных метаописаний на естественном языке, тегов управления фрагментами или внедрения структурированных данных.
Однако пересечение технического SEO и контент-маркетинга еще больше, когда речь идет об эффективности контента: мы рассматриваем одни и те же первичные данные, такие как рейтинг страницы в поисковой выдаче или количество кликов, показов и сеансов. Мы можем реализовать одни и те же решения или использовать одни и те же инструменты.
Что такое эффективность контента?
Производительность контента — это измеримый результат того, как аудитория взаимодействует с контентом. Если контент стимулирует входящий трафик, то показатели этого трафика отражают, насколько хорошо или плохо этот контент выполняет свою работу. Каждая контент-стратегия должна, исходя из конкретных целей, определять свои конкретные KPI. Большинство из них будут включать следующие показатели:
- Насколько виден контент в поиске (показы в поисковой выдаче)
- Насколько релевантен контент поисковым системам (рейтинг в поисковой выдаче)
- Насколько релевантным поисковики считают поисковый список контента (клики из поисковой выдачи)
- Сколько человек просматривают контент (посещения или сеансы в аналитическом решении).
- Сколько людей взаимодействуют с контентом таким образом, который способствует достижению бизнес-целей (отслеживание конверсий).
Все идет нормально.
Сложность в том, чтобы поставить курсор: какие цифры означают, что у вас хорошая производительность контента? Что нормально? А как понять, что что-то не так?
Ниже я поделюсь своим экспериментом по созданию «доказательства концепции» низкотехнологичного инструмента, который поможет ответить на эти вопросы.
Зачем нужен стандарт производительности контента?
Вот некоторые из вопросов, на которые я хотел ответить в рамках моего собственного обзора контент-стратегии:
- Есть ли разница между собственным контентом и гостевыми постами с точки зрения производительности?
- Есть ли темы, которые мы продвигаем, которые не работают?
- Как я могу идентифицировать «вечнозеленые» посты, не дожидаясь трех лет, чтобы увидеть, привлекают ли они еженедельный трафик?
- Как я могу определить незначительные повышения от стороннего продвижения, например, когда в информационном бюллетене появляется сообщение, которое не было на нашем радаре продвижения, чтобы немедленно адаптировать нашу собственную стратегию продвижения и извлечь выгоду из повышения видимости?
Однако, чтобы ответить на любой из этих вопросов, вам нужно знать, как выглядит «нормальная» производительность контента на сайте, с которым вы работаете. Без этого базового уровня невозможно количественно сказать, хорошо ли работает конкретная часть или тип контента (лучше, чем базовый уровень) или нет.
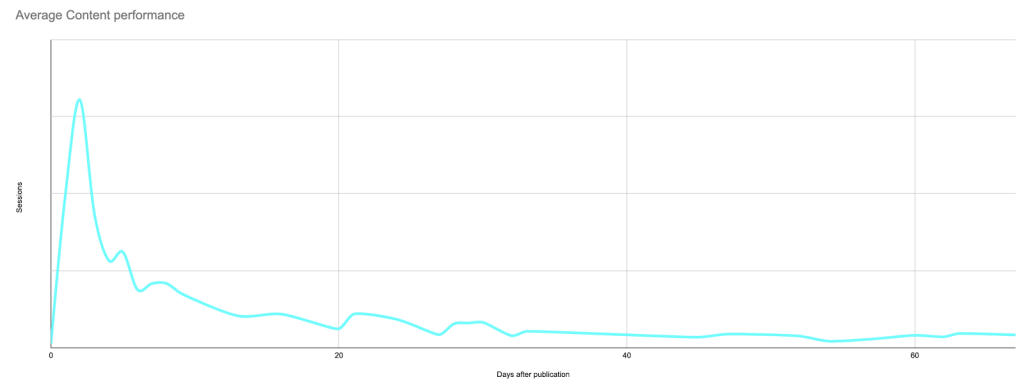
Самый простой способ установить базовый уровень — посмотреть среднее количество сеансов в день после публикации для каждой статьи, где нулевой день — это дата публикации.
Это создаст примерно такую кривую, показывающую пик первоначального интереса (и, возможно, результаты любого вашего продвижения, если вы не ограничили свой анализ сеансами только от поисковых систем), за которым следует длинный хвост низкий процент:
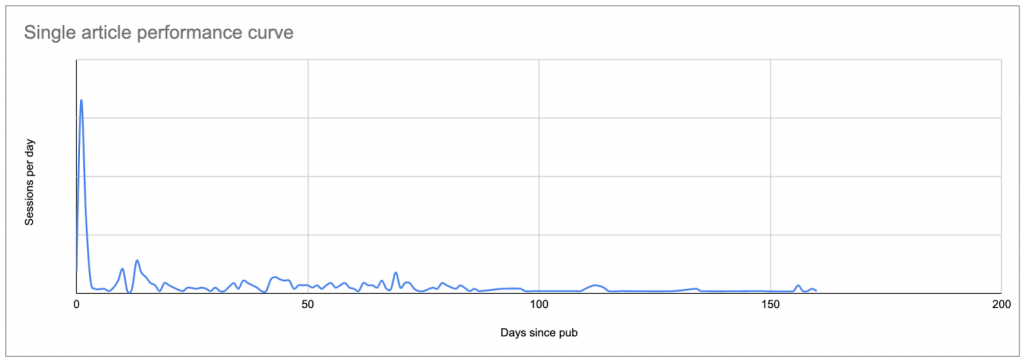
Реальные данные для типичного поста: пик на дату публикации или вскоре после нее, за которым следует длинный хвост, который во многих случаях в конечном итоге приводит к большему количеству сеансов, чем первоначальный пик.
Как только вы узнаете, как выглядит кривая каждого сообщения, вы можете сравнить каждую кривую с другими и установить, что является «нормальным», а что нет.
Если у вас нет инструмента для этого, это головная боль.
Когда я начинал этот проект, моей целью было использовать Google Sheets для создания доказательства концепции, прежде чем я решил изучить достаточно Python, чтобы изменить то, как я оцениваю производительность контента.
Разобьем процесс на этапы и этапы:
- Найдите свой базовый уровень
- Перечислите контент, который вы хотите изучить
– Узнайте, сколько сеансов каждый элемент контента получил каждый день
- Заменить дату в списке сессий на количество дней с момента публикации
– Рассчитайте «нормальную» кривую для использования в качестве базовой линии. - Определите контент, который не похож на базовый уровень
- Держите его в курсе
Найдите базовый уровень эффективности вашего контента
Перечислите контент, который вы хотите изучить
Для начала вам нужно составить список контента, который вы хотите изучить. Для каждого фрагмента контента вам понадобится URL-адрес и дата публикации.
Вы можете получить этот список, как хотите, независимо от того, составляете ли вы его вручную или используете автоматизированный метод.
Я использовал скрипт приложений, чтобы получить каждый URL-адрес контента и дату его публикации непосредственно из CMS (в данном случае WordPress) с помощью API, и записал результаты в таблицу Google. Если вам не нравятся скрипты или API, это все еще относительно просто; вы можете найти несколько примеров в Интернете о том, как это сделать для WordPress.
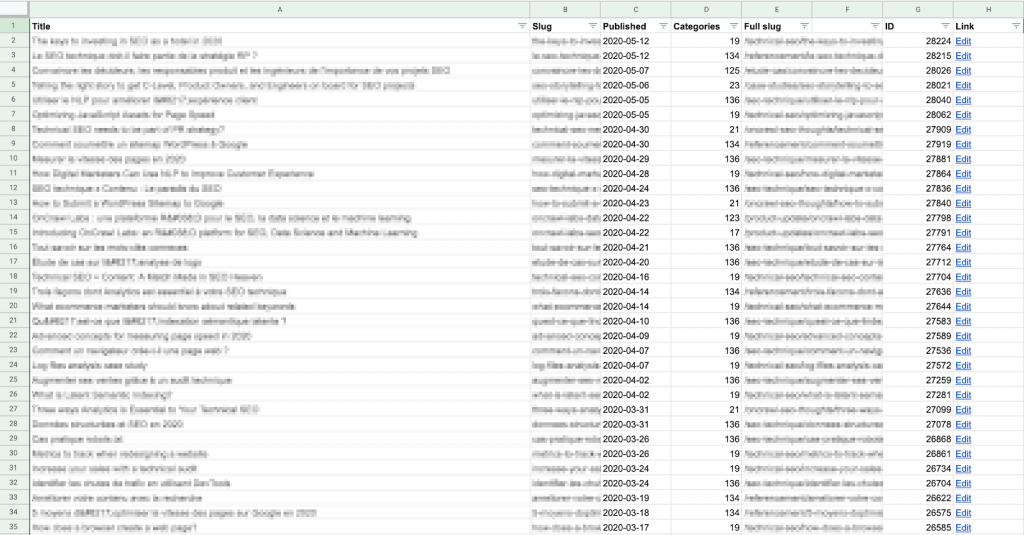
Имейте в виду, что вы захотите сравнить эти данные с данными сеанса для каждой публикации, поэтому вам необходимо убедиться, что «слаг» на этом листе соответствует формату URL-пути, предоставленному вашим аналитическим решением.
Я считаю, что проще создать полный ярлык (URL-путь) здесь, в столбце E выше, чем изменять данные, полученные из Google Analytics. Кроме того, он требует меньше вычислительных ресурсов: в этом списке меньше строк!

Пример формулы для создания полного URL-адреса для этого сайта: найдите номер категории, предоставленный CMS, в таблице и верните имя категории, которое помещается перед слагом статьи, соответствующее шаблону URL-адреса для этого сайта (https://site .com/categoryName/articleSlug/)
Если у вас нет доступа к серверной части, вы можете создать свой список, собрав эту информацию с самого вашего сайта, например, во время сканирования. Затем вы можете экспортировать нужные данные в формате CSV и импортировать их в таблицу Google.
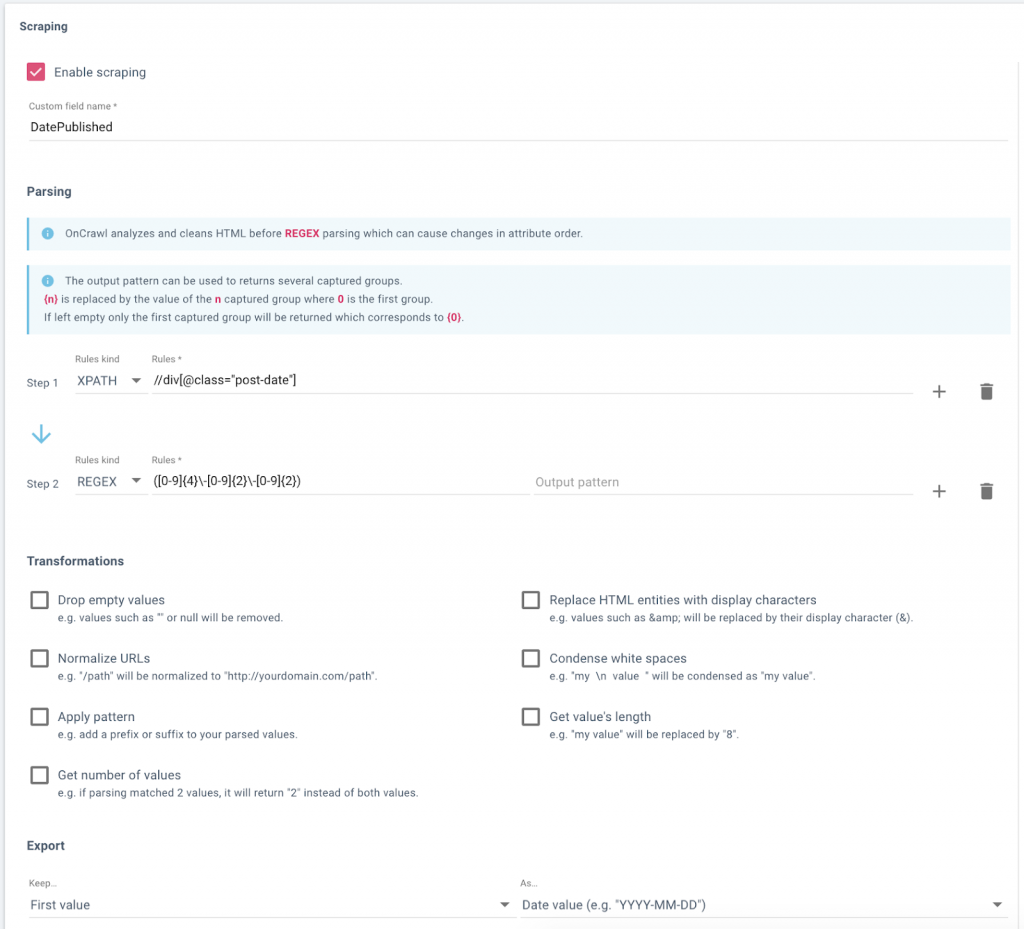
Настройка поля данных в OnCrawl для извлечения дат публикации из блога веб-сайта.
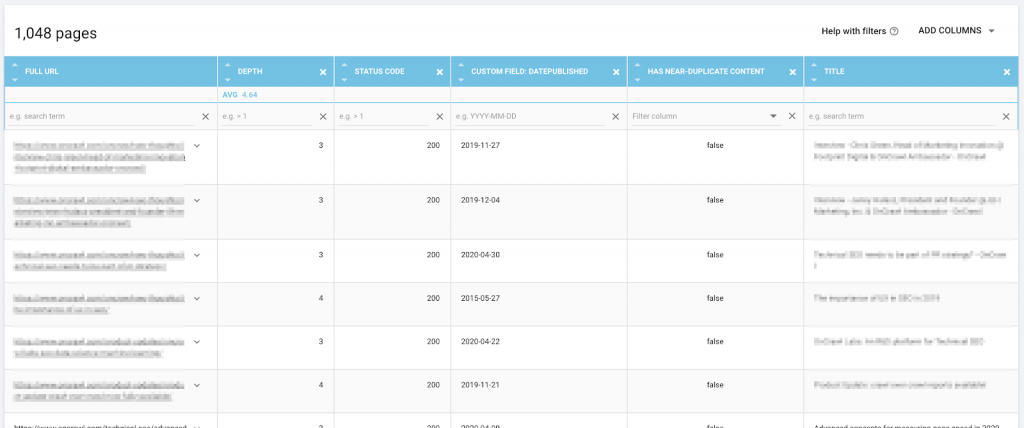
Данные, включая URL-адрес и дату публикации, в обозревателе данных OnCrawl готовы к экспорту.
Узнайте, сколько сеансов в день заработал каждый элемент контента
Далее вам нужен список сессий на единицу контента и в день. Другими словами, если контенту 30 дней, и в течение этого периода его посещали каждый день, вы хотите, чтобы для него было 30 строк, и так далее для остального контента.
Для этого вам понадобится отдельный лист в том же документе.
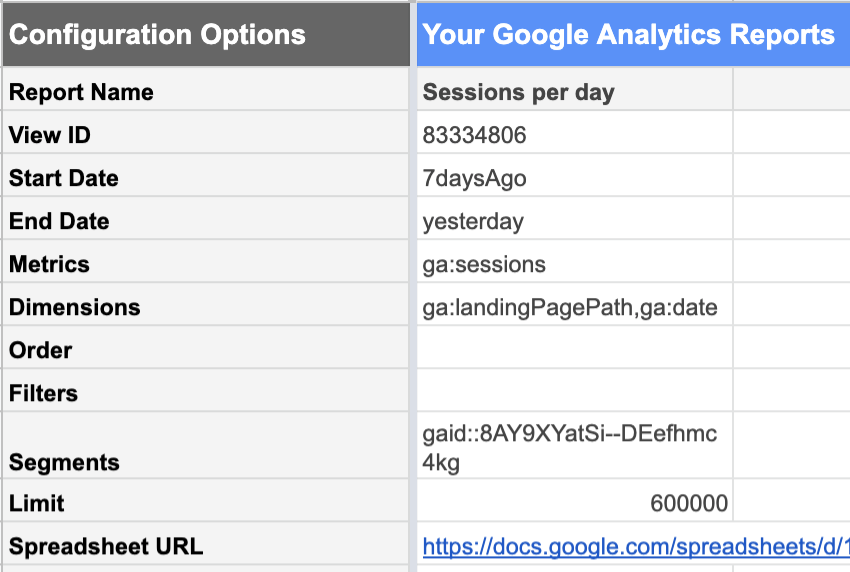
Дополнение Google Analytics к Google Sheets делает это относительно простым.
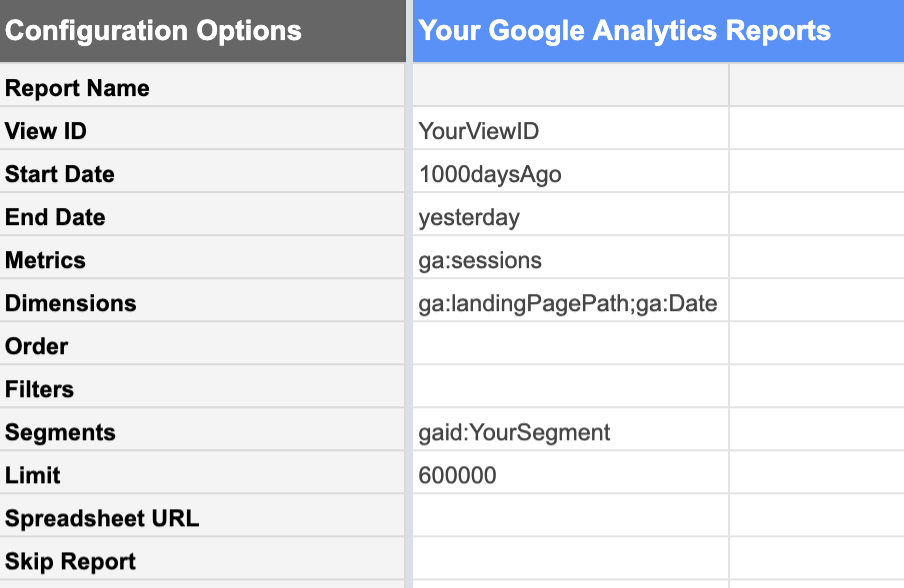
Из представления Google Analytics с нужными вам данными вы можете запросить отчет о:
| Даты | Метрики | Габаритные размеры |
|---|---|---|
| 1000 дней назад До вчерашнего дня. Сегодняшние данные еще не полны, потому что день еще не закончился. Если вы включите его, он не будет выглядеть как «нормальный» полный день и снизит всю вашу статистику. | Сессии Нас интересует количество сеансов. | Целевые страницы Здесь перечислены сеансы для каждой целевой страницы отдельно.Дата Это перечисляет сеансы для каждой даты отдельно, а не дает нам общее количество дней за 1000. |
На этом этапе чрезвычайно полезно использовать сегменты ваших данных Google Analytics . Например, вы можете ограничить свой отчет сегментом, содержащим только URL-адреса контента, которые вы хотите проанализировать, а не весь сайт. Это значительно уменьшает количество строк в результирующем отчете и значительно упрощает работу с данными в Google Таблицах.
Кроме того, если вы намерены смотреть только на органическую производительность исключительно для целей SEO, ваш сегмент должен исключать каналы приобретения, которые нельзя отнести к работе SEO: рефералы, электронная почта, социальные сети…
Не забудьте убедиться, что предел достаточно высок, чтобы вы не усекли свои данные по ошибке.
Подсчитать количество дней с момента публикации
Чтобы рассчитать количество дней с момента публикации для каждой точки данных в статье, мы должны соединить (или, если вы являетесь пользователем Data Studio, «смешать») данные из отчета о сеансах с данными в вашем списке частей контента. .
Для этого используйте URL-адрес или путь URL-адреса в качестве ключа. Это означает, что URL-адрес должен быть отформатирован одинаково как в таблице CMS, так и в отчете Google Analytics.
Я создал отдельную таблицу, чтобы удалить любые параметры с целевой страницы в своем отчете Analytics. Вот как я настроил свои столбцы:
- Целевая страница
Извлекает параметры из URL-слага в отчете Google Analytics.
Пример формулы:

- Дата
Дата записи сеансов из отчета Analytics.
Пример формулы:

- Сессии
Дата записи сеансов из отчета Analytics.
Пример формулы:

- Дней после публикации
Ищет дату публикации для этого URL-адреса в столбце таблицы CSM, которую мы только что создали, и вычитает ее из даты, когда эти сеансы были записаны. Если URL-адрес не может быть найден в таблице CMS, сообщает о пустой строке, а не об ошибке.
Пример формулы:
![]()
Обратите внимание, что мой ключ поиска — полный URL-адрес — не является самым левым столбцом в моих данных; Мне пришлось переместить столбец E перед столбцом C для целей ВПР.
Если у вас слишком много строк, чтобы заполнить это вручную, вы можете использовать сценарий, подобный приведенному ниже, чтобы скопировать содержимое первой строки и заполнить следующие 3450 или около того:
функция ЗаполнитьВниз() {
электронная таблица var = SpreadsheetApp.getActive();
электронная таблица.getRange('F2').activate();
Spreadsheet.getActiveRange().autoFill(spreadsheet.getRange('F2:F3450), SpreadsheetApp.AutoFillSeries.DEFAULT_SERIES);
};Рассчитайте «нормальное» количество сеансов в день после публикации
Чтобы рассчитать количество обычных сеансов, я использовал довольно простую сводную таблицу в сочетании с графиком. Для простоты я начал с просмотра среднего количества сеансов в день после публикации.

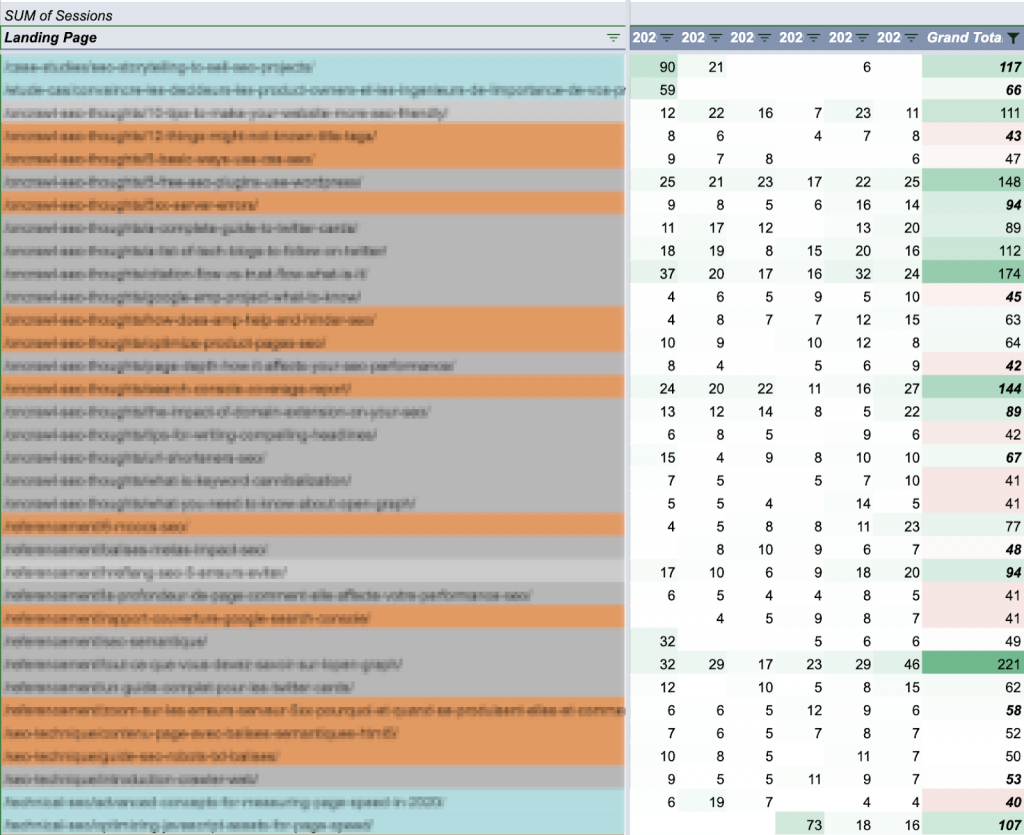
Вот среднее значение по сравнению с медианой сеансов за 1000 дней после публикации. Здесь мы начинаем (?) видеть ограничения Google Таблиц как проекта визуализации данных:
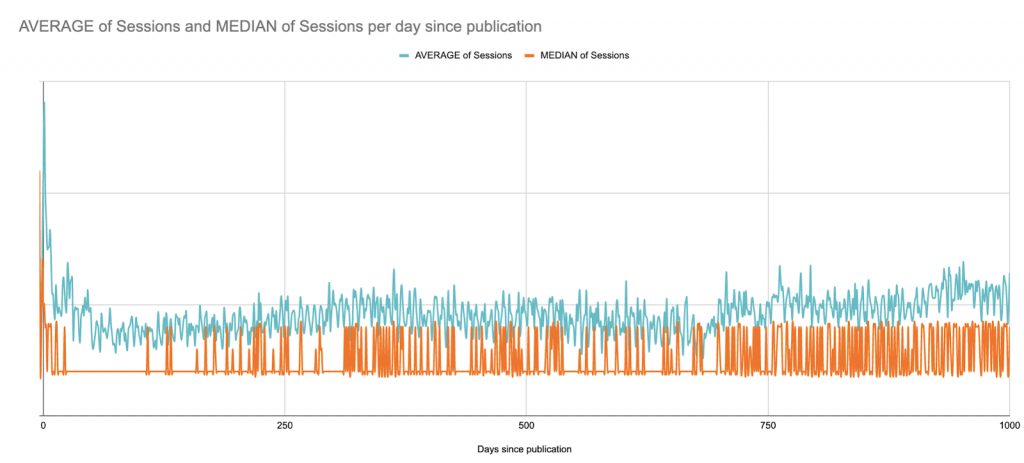
Это сайт B2B с пиками сеансов в будние дни по всему сайту; он публикует статьи несколько раз в неделю, но всегда в одни и те же дни. Вы почти можете видеть недельные паттерны.
В этом случае для целей визуализации, вероятно, было бы лучше посмотреть на скользящие средние значения за 7 дней, но вот быстрая версия, которая просто сглажена по неделям с момента публикации:

Несмотря на этот долгосрочный взгляд, для следующих шагов я ограничу график 90 днями после публикации, чтобы позже оставаться в пределах ограничений Google Sheets:
Поиск аномалий
Теперь, когда мы знаем, как выглядит средний пост в любой день, мы можем сравнить любой пост с базовым уровнем, чтобы выяснить, является ли он более или менее эффективным.
Это быстро выходит из-под контроля, если вы делаете это вручную. Каламбуры в сторону, давайте хотя бы попытаемся что-то автоматизировать.
Каждое сообщение (которое старше 90 дней) необходимо сравнивать с базовым уровнем, который мы только что установили для каждого дня в нашем 90-дневном окне.
Для этого доказательства концепции я рассчитал процентную разницу от среднего дневного значения.
Для тщательного анализа вам нужно посмотреть на стандартное отклонение сеансов в день и установить, сколько стандартных отклонений производительности отдельной части контента отличается от базового уровня. Количество сеансов, которое составляет три стандартных отклонения от средней производительности, с большей вероятностью будет аномалией, чем отклонение от среднего значения за этот день более чем на X%.
Я использовал сводную таблицу, чтобы выбрать каждый фрагмент контента (с сеансами за последние 90 дней), который имеет хотя бы один день аномалий за этот период:
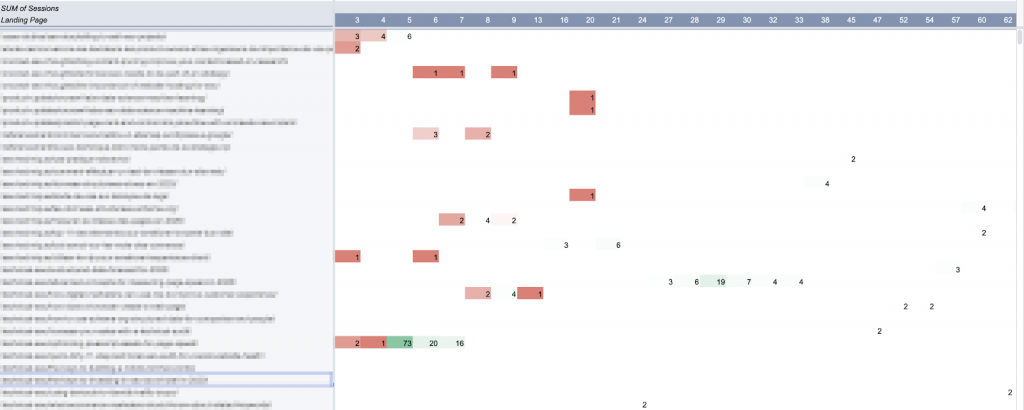
В Google Таблицах сводные таблицы не могут создавать более 100 столбцов. Отсюда ограничение 90 дней для этого анализа.
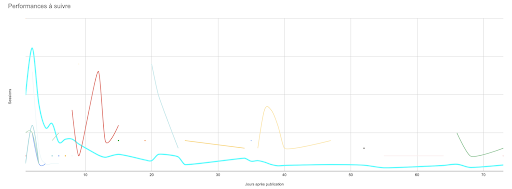
Я начертил эту таблицу. (В идеале я хотел бы нарисовать всю 90-дневную кривую для каждой из этих статей, но я также хотел бы, чтобы лист реагировал, если я нажму на кривую.)
Поддержание актуальности: автоматизация обновлений
Здесь есть три основных элемента:
- Базовый уровень
- Фрагменты контента, которые вы хотите отслеживать
- Производительность этих частей контента
К сожалению, ни один из них не является статичным.
Теоретически средняя производительность будет расти по мере того, как вы будете лучше ориентироваться и продвигать свой контент. Это означает, что вам нужно время от времени пересчитывать базовый уровень.
И если на вашем веб-сайте есть сезонные пики и спады, возможно, стоит посмотреть средние значения за более короткие периоды времени или за один и тот же период каждый год, а не создавать объединение, как мы сделали здесь.
По мере того, как вы будете публиковать больше контента, вы также захотите отслеживать новый контент.
И когда мы захотим посмотреть дату сеанса на следующей неделе, у нас ее не будет.
Другими словами, эту модель нужно обновлять более или менее часто. Есть несколько способов автоматизировать обновления, а не перестраивать весь инструмент с нуля каждый раз, когда вам интересно взглянуть.
Проще всего реализовать, вероятно, планирование еженедельного обновления сеансов аналитики и одновременное получение новых сообщений (с датами их публикации).
Используемый нами отчет Google Analytics можно легко запланировать для автоматического запуска через регулярные промежутки времени. Недостатком является то, что он перезаписывает прошлые отчеты. Если вы не хотите запускать и управлять полным отчетом, вы можете ограничить его более коротким периодом времени.
Для моих целей я обнаружил, что просмотр 7-дневного окна дает мне достаточно информации для работы, не будучи слишком устаревшей.
Отслеживание вечнозеленых постов за пределами 90-дневного окна
Используя данные, которые мы сгенерировали ранее, скажем, удалось определить, что большинство постов в среднем проводят около 50 сеансов в неделю.
Поэтому имеет смысл следить за любой публикацией, еженедельные сеансы которой превышают 50, независимо от даты публикации:
Статьи окрашены по периоду публикации: последние 90 дней (синий), прошлый год (оранжевый) и наследие (серый). Еженедельные итоги имеют цветовую кодировку, сравнивая их с целью сеанса 50.
Разделение общего количества сеансов в день в течение недели позволяет легко провести различие между вечнозелеными публикациями с довольно стабильной производительностью и активностью, связанной с событиями, с неравномерной производительностью:
![]()
Вечнозеленый контент (постоянная производительность ±20 в день)
![]()
Вероятная внешняя реклама (общая низкая производительность за пределами краткосрочного пика)
Что вы будете делать с этой информацией, будет зависеть от вашей контент-стратегии. Возможно, вы захотите подумать о том, как эти сообщения конвертируют потенциальных клиентов на вашем веб-сайте, или сравните их с вашим профилем обратных ссылок.
Ограничения Google Sheets для анализа контента
Google Таблицы, как вы, вероятно, уже заметили, являются чрезвычайно мощным, но ограниченным инструментом для такого рода анализа. Именно из-за этих ограничений я предпочел не делиться с вами шаблоном: его адаптация к вашему случаю потребует много работы, но результаты, которые вы можете получить, по-прежнему являются лишь приближениями, нарисованными широкими мазками.
Вот некоторые из основных моментов, по которым эта модель не работает:
- Слишком много формул.
Если у вас много (скажем, тысячи) активных URL-адресов контента, это может быть очень медленным. В моих сценариях еженедельного обновления я заменяю многие формулы их значениями после их расчета, чтобы файл действительно реагировал, когда я открываю его позже для анализа. - Статическая базовая линия.
По мере того, как производительность моего контента улучшается, у меня просто появляется больше фрагментов контента, которые «сверхэффективны». Базовый уровень необходимо пересчитывать каждые несколько месяцев, чтобы учесть эволюцию. Эту проблему можно легко решить, используя неконтролируемую модель машинного обучения для расчета средних значений (или даже пропуская этот шаг и напрямую определяя аномалии). - «Неверная» база.
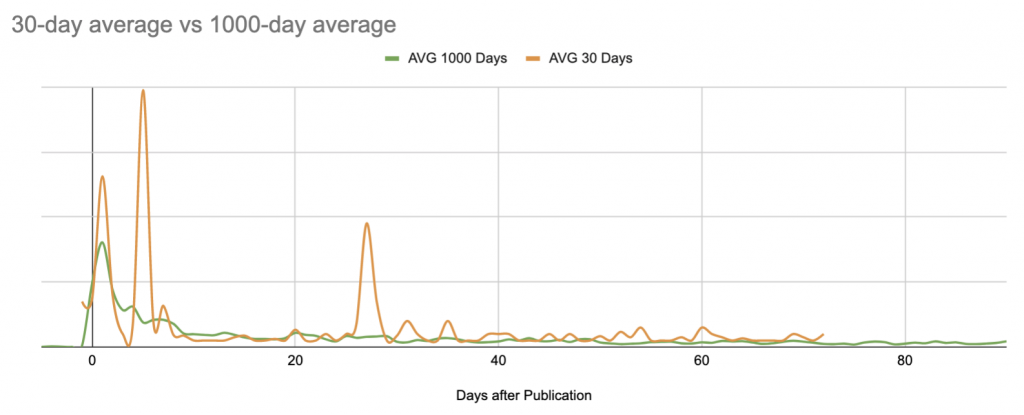
Базовый уровень не учитывает сезонные изменения или инциденты в масштабах сайта. Он также очень чувствителен к экстремальным событиям, особенно если вы ограничиваете свои расчеты более коротким периодом времени:
Статистически необоснованный анализ выбросов.
В частности, если у вас не так много сеансов в день для каждого элемента контента, заявление о том, что разница в 10% от среднего значения представляет собой необычную производительность, немного поверхностно.
Произвольный предел до 90 дней анализа.
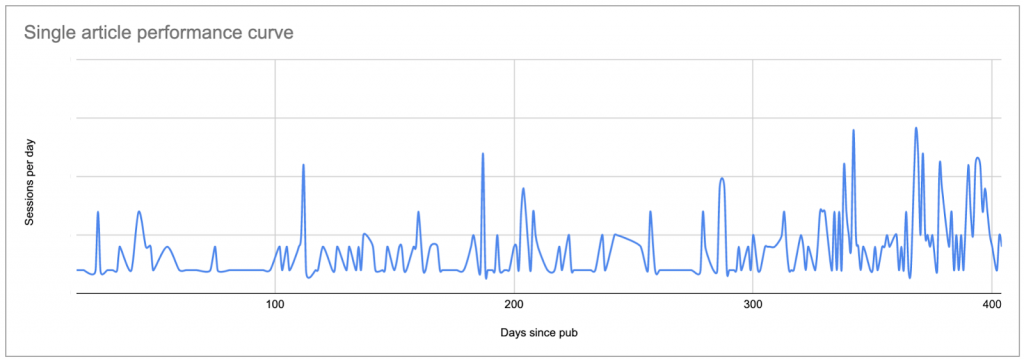
Любой произвольный предел является проблемой. В этом случае это мешает мне понять эффективность вечнозеленого контента и делает меня слепым к любым пикам в их эффективности, хотя я знаю из Google Analytics, что очень старые части иногда получают внезапный всплеск внимания или что некоторые статьи постоянно привлекают внимание по мере того, как они стареют. Это не видно в инструменте, но это видно, если вы начертите их кривую:
- Проблемы с длиной листа.
Для некоторых моих формул и сценариев требуется диапазон ячеек. По мере роста сайта и строк в отчете о сеансах эти диапазоны необходимо обновлять. (Но они не могут превышать количество строк на листе, иначе некоторые из них будут создавать ошибки.) - Невозможность построения полных кривых для каждой части контента.
Давай, я хочу все увидеть! - Ограниченная интерактивность с графическими результатами.
Если вы когда-нибудь пытались выбрать одну точку (или кривую) на графике с несколькими кривыми в Google Sheets… вы знаете, о чем я говорю. Это еще хуже, когда у вас есть более двадцати кривых на одном графике, и все цвета начинают выглядеть одинаково. - Возможность пропуска неэффективного контента без сеансов.
Используя метод, который я представил здесь, трудно идентифицировать контент, который постоянно не имеет сеансов. Поскольку он никогда не появляется в отчете Google Analytics, он не используется в остальной части рабочего процесса (пока). Контент, который постоянно не работает, приносит мало пользы, поэтому, если вы не ищете страницы для сокращения, неэффективный контент, возможно, не будет иметь места в отчете о производительности. - Неспособность адаптироваться к анализу в реальном времени.
Хотя повторный запуск сценариев создания отчетов, усреднения и публикации обновлений не требует больших трудозатрат, это все же ручные действия вне еженедельного запрограммированного обновления. Если еженедельное обновление будет в среду, а вы спросите меня во вторник, как дела, я не могу просто свериться с таблицей. - Ограничения на расширение.
Добавление оси анализа, например ранжирования или отслеживания ключевых слов, или даже параметров фильтрации по географическому региону, в этот отчет было бы обременительным. Это не только усугубит некоторые из существующих проблем, но также будет крайне сложно реализовать удобочитаемую и действенную визуализацию.
Вывод?
Выполнение тех же типов вычислений в среде машинного обучения или программного обеспечения решит почти все эти проблемы. Это был бы гораздо лучший способ выполнения полусложных операций с большим набором данных. Кроме того, существуют отличные библиотеки, которые используют машинное обучение для надежного обнаружения аномалий на основе заданного набора данных; есть лучшие инструменты для визуализации данных.
Выводы по эффективности контента
Анализ производительности контента, даже с использованием примитивных и ошибочных методов, усиливает оповещение и принятие решений на основе данных в стратегии контента.
Конкретно говоря, понимание производительности контента — это то, что позволяет вам:
- Поймите ценность первоначальных рекламных акций по сравнению с длинной активностью
- Быстро находите неэффективные посты
- Извлекайте выгоду из внешней рекламной деятельности, чтобы увеличить охват
- Легко распознать, что делает определенные посты такими успешными
- Определите определенных авторов или определенные темы, которые постоянно превосходят других
- Определите, когда SEO начинает влиять на сеансы
Эти данные лежат в основе обоснованных решений о продвижении контента, а также о том, когда и как, выборе тем, профилировании аудитории и многом другом.
Наконец, эксперименты, подобные этому, показывают, что любая область, для которой вы можете получить данные, имеет потенциальное применение для навыков кодирования, сценариев и машинного обучения. Но вам не нужно отказываться от создания собственных инструментов, если у вас нет всех этих навыков.