
Breadcrumb SEO, Python 3 и Oncrawl: на пути к автоматизации!
Опубликовано: 2021-04-14Давайте узнаем, как автоматически создавать сегментацию на основе хлебных крошек с помощью OnCrawl и Python 3.
Что такое сегментация в Oncrawl?
Oncrawl использует сегментацию для разделения набора страниц на группы. Это позволяет очень легко анализировать данные из отчетов о сканировании, анализа журналов и других отчетов перекрестного анализа, в которых данные сканирования смешиваются с Google Analytics, Google Search Console, AT Internet, Adobe Analytics или Majestic для обратных ссылок.
Почему важно создавать сегменты?
После завершения обхода самым важным делом будет создание пользовательской сегментации. Это позволяет вам читать анализ с точки зрения, которая лучше всего подходит для вашего сайта и его структуры.
Есть много способов сегментировать страницы вашего сайта, и нет правильного или неправильного способа сделать это. Например, можно отслеживать структуру вашего сайта на основе структуры URL.
Например, такой URL-адрес « https://www.mydomain.com/news/canada/politics » можно легко сегментировать следующим образом:
- Группа для изоляции главной страницы
- Группа для всех новостей
- Подгруппа для каталога Канады
- Подгруппа для каталога «Политика».
Как видите, для сегментации можно создать до 3 уровней глубины. Это позволяет вам сосредоточиться на определенных группах или подгруппах в вашем SEO-анализе, не переключая сегментацию.
Как создать базовую сегментацию?
Вы должны знать, что Oncrawl сам позаботится о создании первой сегментации. Это основано на «Первом пути» или первом каталоге, который встречается в URL-адресах.
Это позволяет вам иметь доступ к анализу, как только сканирование будет завершено.
Возможно, эта сегментация не отражает структуру вашего сайта или вы хотите проанализировать ситуацию под другим углом.
Итак, вы собираетесь создать новую сегментацию, используя то, что мы называем OQL, что означает язык запросов Oncrawl. Это похоже на SQL, только намного проще и интуитивно понятнее: 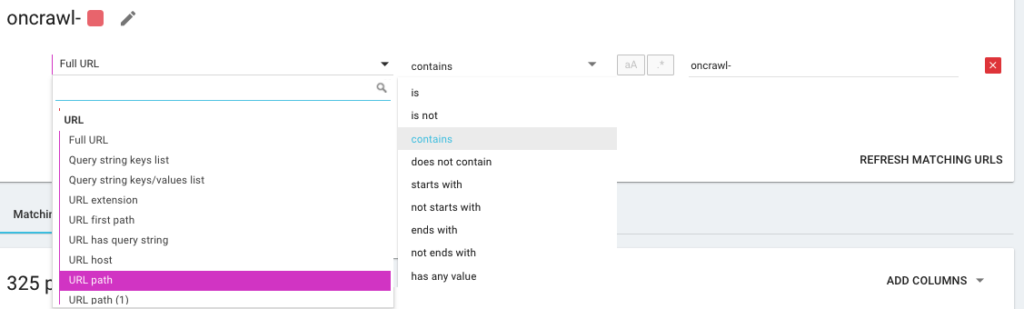
Также можно использовать операторы условия И/ИЛИ, чтобы быть как можно более точными: 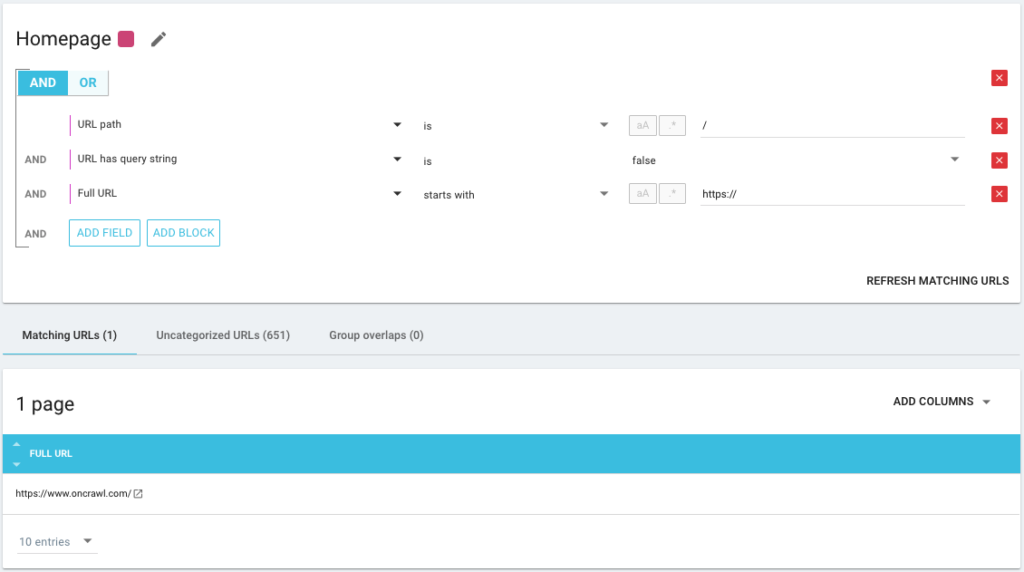
Сегментирование моих страниц с использованием различных методов
Использование других KPI
Сегментация на основе URL-адресов — это хорошо, но было бы идеально, если бы мы могли также комбинировать другие ключевые показатели эффективности, например, группировать URL-адреса, начинающиеся с /car-rental/ и чей H1 имеет выражение « Агентства по аренде автомобилей » и другую группу, где H1 будет « Агентства по аренде коммунальных услуг », возможно ли это?
Да, это возможно! Во время создания ваших сегментов в вашем распоряжении все KPI, которые мы используем, и не только от сканера, но и от коннекторов. Это делает создание сегментации очень мощным и позволяет вам иметь совершенно разные углы анализа!
Например, мне нравится создавать сегментацию с использованием средней позиции URL-адресов благодаря коннектору Google Search Console.
Таким образом, я могу легко идентифицировать URL-адреса глубоко в моей структуре, которые все еще работают, или URL-адреса рядом с моей домашней страницей, которые находятся на странице 2 Google.
Я вижу, есть ли на этих страницах дублированный контент, пустой тег title, достаточно ли на них ссылок… Я также вижу, как ведет себя Googlebot на этих страницах. Частота сканирования — это хорошо или плохо? Короче говоря, это помогает мне расставлять приоритеты и принимать решения, которые реально повлияют на мое SEO и рентабельность инвестиций.
Данные при сканировании³
 Учить больше
Учить большеИспользование приема данных
Если вы не знакомы с нашей функцией приема данных, я предлагаю вам сначала прочитать эту статью на эту тему. Это еще один очень мощный инструмент, позволяющий добавлять в Oncrawl внешние источники данных.
Например, вы можете добавить данные из SEMrush, Ahrefs, Babbar.tech… Преимущество в том, что вы можете группировать свои страницы по метрикам, взятым из этих инструментов, и проводить свой анализ на основе интересующих вас данных, даже если это не так. изначально в Oncrawl.
Недавно я работал с глобальной гостиничной группой. Они используют метод внутренней оценки, чтобы узнать, правильно ли заполнены записи отеля, есть ли в них изображения, видео, контент и т. д. Они определяют процент выполнения, который мы использовали для перекрестного анализа данных сканирования и файла журнала.
Результат позволяет нам узнать, тратит ли робот Googlebot больше времени на правильно заполненные страницы, узнать, не являются ли некоторые страницы с показателем более 90% слишком глубокими, не получают достаточно ссылок… Это позволяет нам показать, что чем выше оценка, чем больше посещений получают страницы, тем больше они изучаются Google и тем выше их позиция в поисковой выдаче Google. Непреодолимый аргумент, побуждающий владельцев отелей заполнять список своих отелей!
Создайте сегментацию на основе следа SEO-хлебных крошек
Это тема данной статьи, так что давайте перейдем к сути дела. Иногда сложно сегментировать страницы вашего сайта, если структура URL-адресов не привязывает страницы к определенному каталогу. Это часто бывает с сайтами электронной коммерции, где все страницы продуктов находятся в корне. Поэтому по URL-адресу невозможно узнать, к какой группе принадлежит страница.
Чтобы сгруппировать страницы вместе, мы должны найти способ идентифицировать группу, к которой они принадлежат. Поэтому у нас возникла идея получить навигационную цепочку каждого URL-адреса и классифицировать их на основе значений в поисковой цепочке, используя функцию Scraper, предлагаемую Oncrawl.
Поиск хлебных крошек SEO с помощью Oncrawl
Как мы видели выше, мы настроим правило парсинга для извлечения следа хлебных крошек. В большинстве случаев это довольно просто, потому что мы можем получить информацию в div , тогда поля каждого уровня находятся в
ul и li списки: 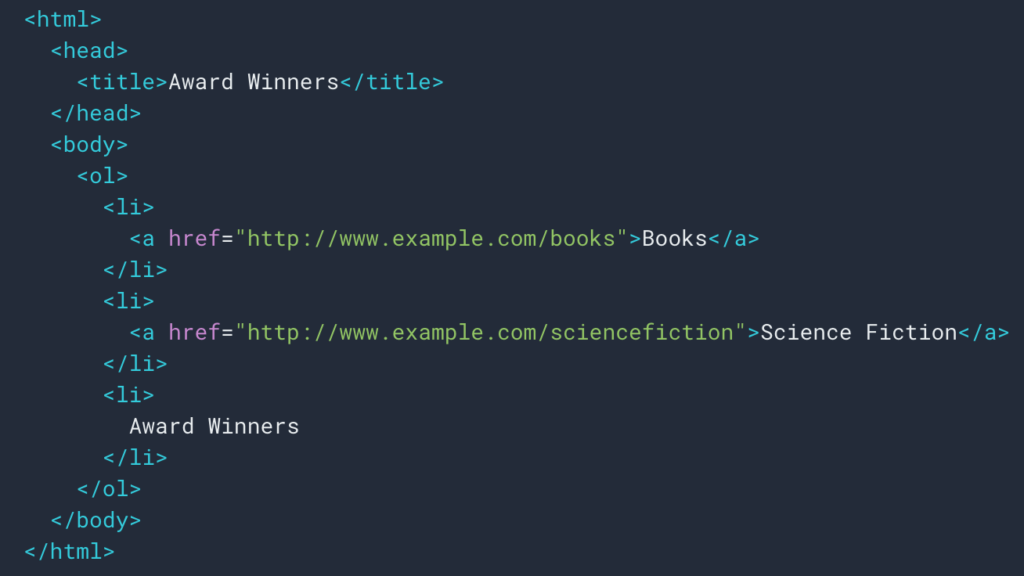
Иногда мы также можем легко получить информацию благодаря структурированному типу данных Breadcrumb. Так будет легко получить значение поля «имя» для каждой позиции. 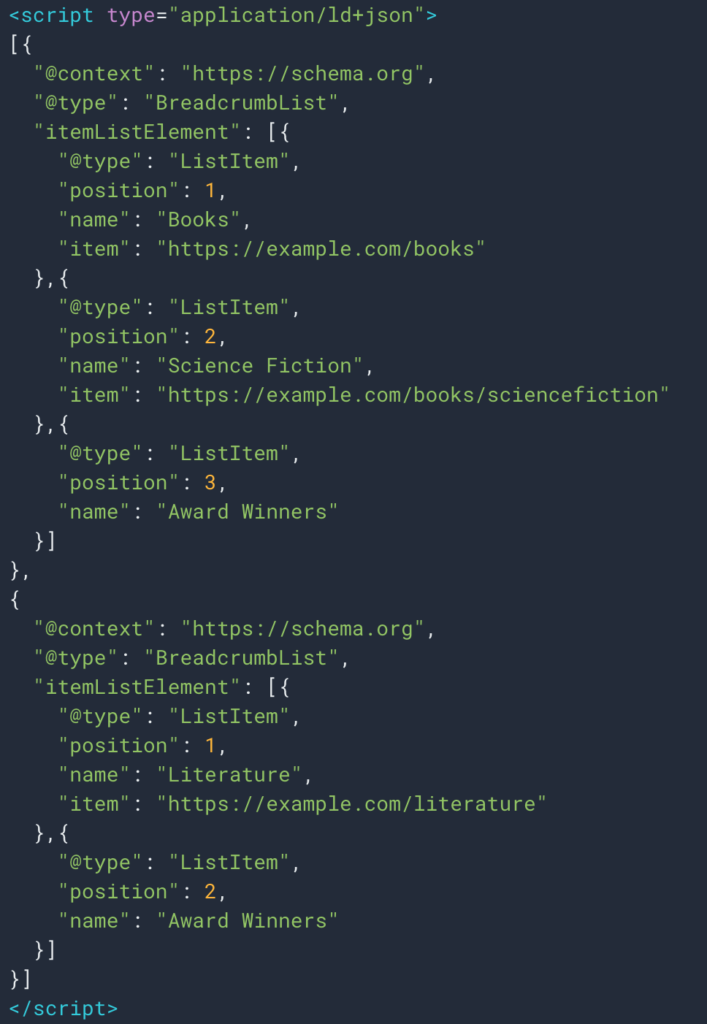
Вот пример правила очистки, которое я использую: 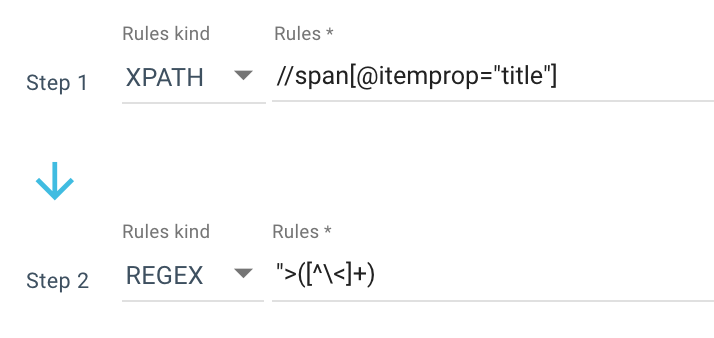
Или это правило: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

Таким образом, я получаю весь span itemprop=”title” с помощью Xpath, а затем использую регулярное выражение для извлечения всего, что следует после “> , что не является > символом. Если вы хотите узнать больше о Regex, я предлагаю вам прочитать эту статью на эту тему и нашу Шпаргалку по Regex.
На выходе я получаю несколько таких значений: 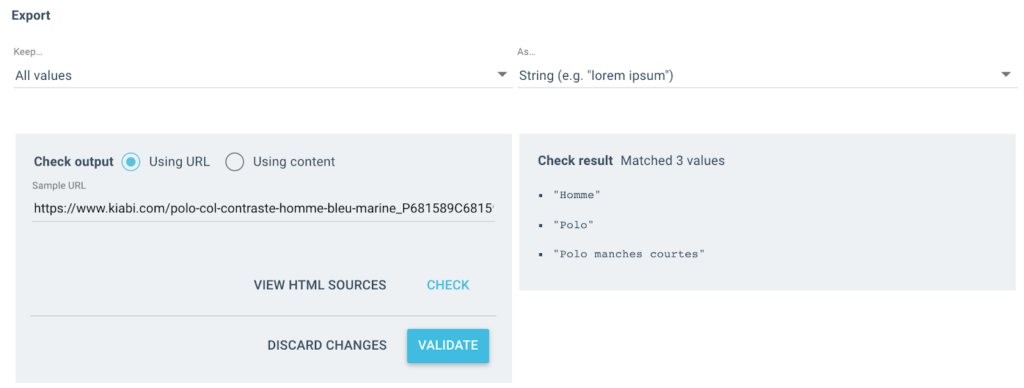
Для протестированного URL-адреса у меня будет поле «Breadcrumb» с 3 значениями:
- мужчина
- рубашка поло
- Поло с короткими рукавами
импортировать json
импортировать случайный
запросы на импорт
# Аутентичный
# Два способа, с x-oncrawl-token, чем вы можете получить в заголовках запросов из браузера
# или с токеном API здесь: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Установите идентификатор сканирования там, где есть настраиваемое поле хлебных крошек
ПОЛЗТИ_
# Обновите запрещенные элементы хлебных крошек, которые вы не хотите получать при сегментации
FORBIDDEN_BREADCRUMB_ITEMS = ('Пополнение',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
для v в FORBIDDEN_BREACRUMB_ITEMS.split(',')
]
определение случайного_цвета():
случайное_число = случайное.randint(0, 16777215)
шестнадцатеричное_число = строка (шестнадцатеричное (случайное_число))
hex_number = hex_number[2:].ljust(6, '0')
вернуть f'#{hex_number}'
определение value_to_group (значение):
возвращаться {
'цвет': random_color(),
'имя': значение,
'oql': {'или': [{'поле': ['custom_Breadcrumb', 'равно', значение]}]}
}
def walk_dict (словарь, уровень = 0):
рет = {
"значок": "приборная панель",
"мобильный": Ложь,
"имя": "Хлебные крошки"
}Теперь, когда правило определено, я могу запустить сканирование, и Oncrawl автоматически извлечет значения навигационной цепочки и свяжет их с каждым просканированным URL-адресом.
Автоматизируйте создание многоуровневой сегментации с помощью Python
Теперь, когда у меня есть все значения хлебных крошек SEO для каждого URL-адреса, мы будем использовать скрипт Python для автоматизации SEO в Google Colab, чтобы автоматически создать сегментацию, совместимую с Oncrawl.
Для самого скрипта мы используем 3 библиотеки:
- json (для создания нашей сегментации, написанной в Json)
- CSV
- случайный (для генерации шестнадцатеричных цветовых кодов для каждой группы)
После запуска скрипт автоматически позаботится о создании сегментации в вашем проекте! 
Предварительный просмотр данных в анализах
Теперь, когда наша сегментация создана, можно получить доступ к различным анализам с сегментированным представлением, основанным на моей навигационной цепочке. 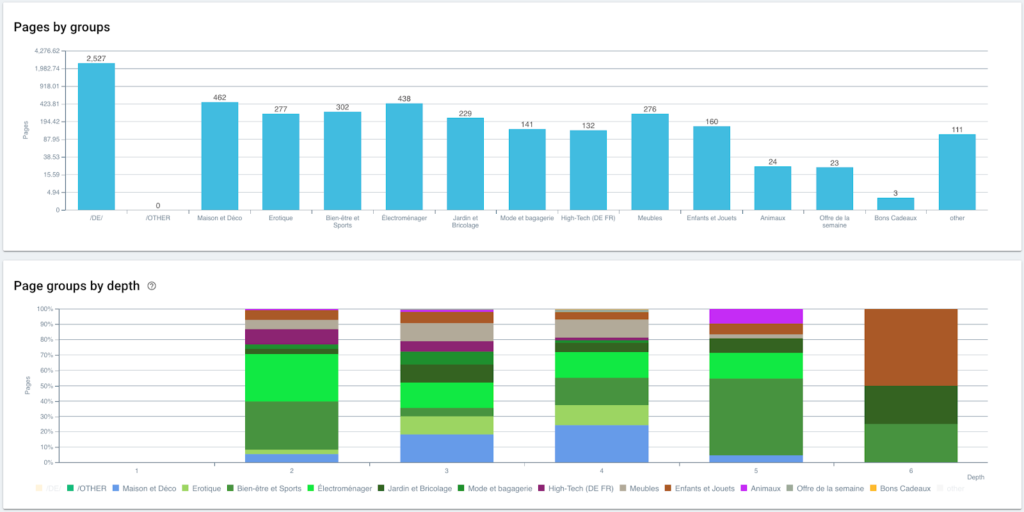
Распределение страниц по группам и по глубине
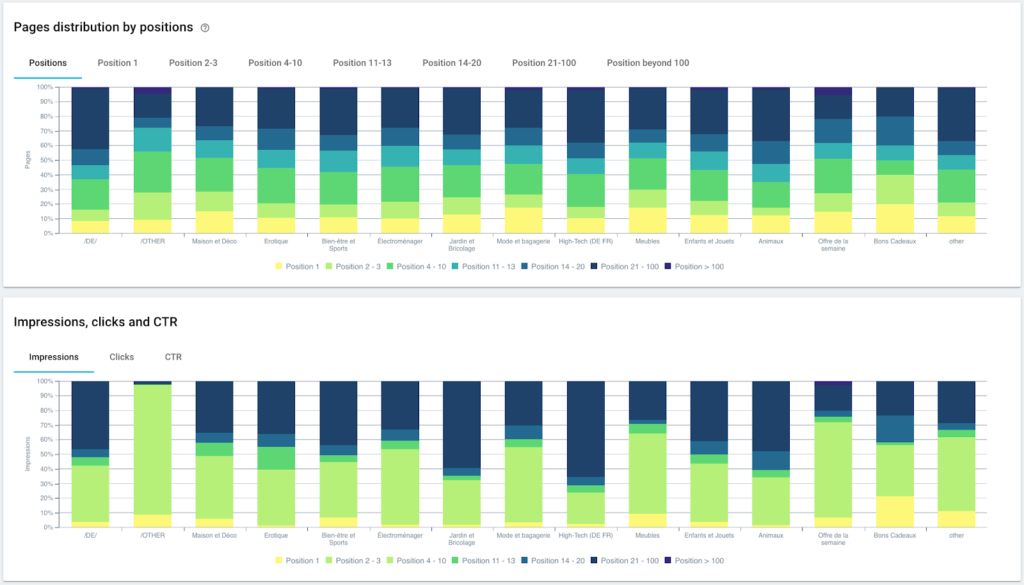
Рейтинг производительности (GSC)
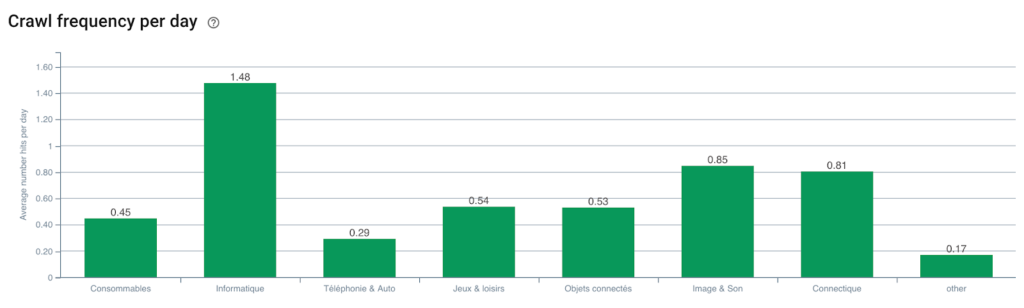
Частота сканирования Googlebot
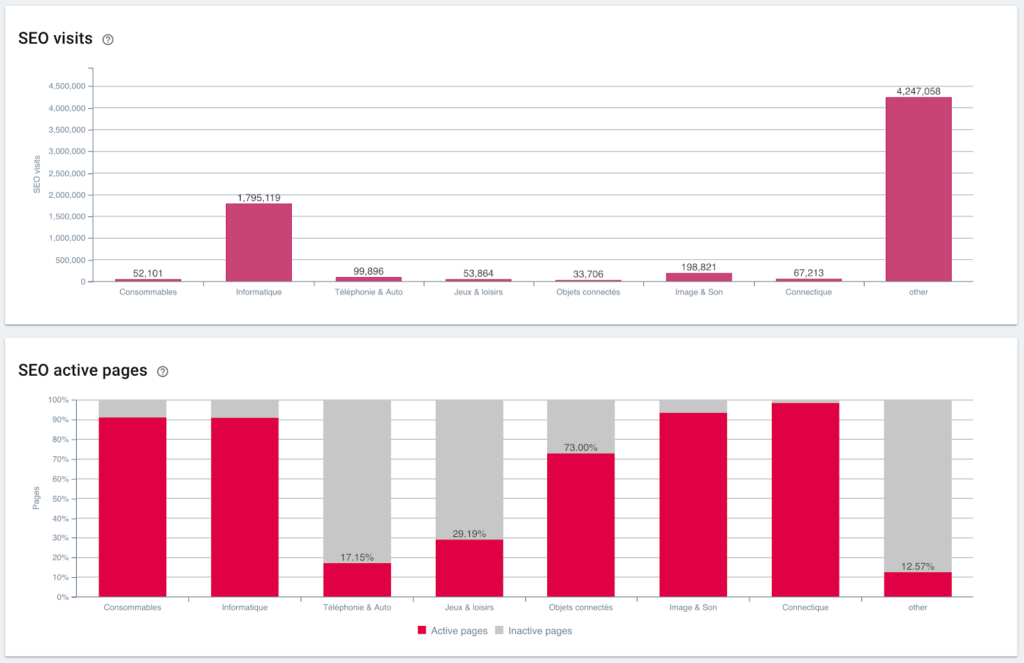
SEO-посещения и соотношение активных страниц
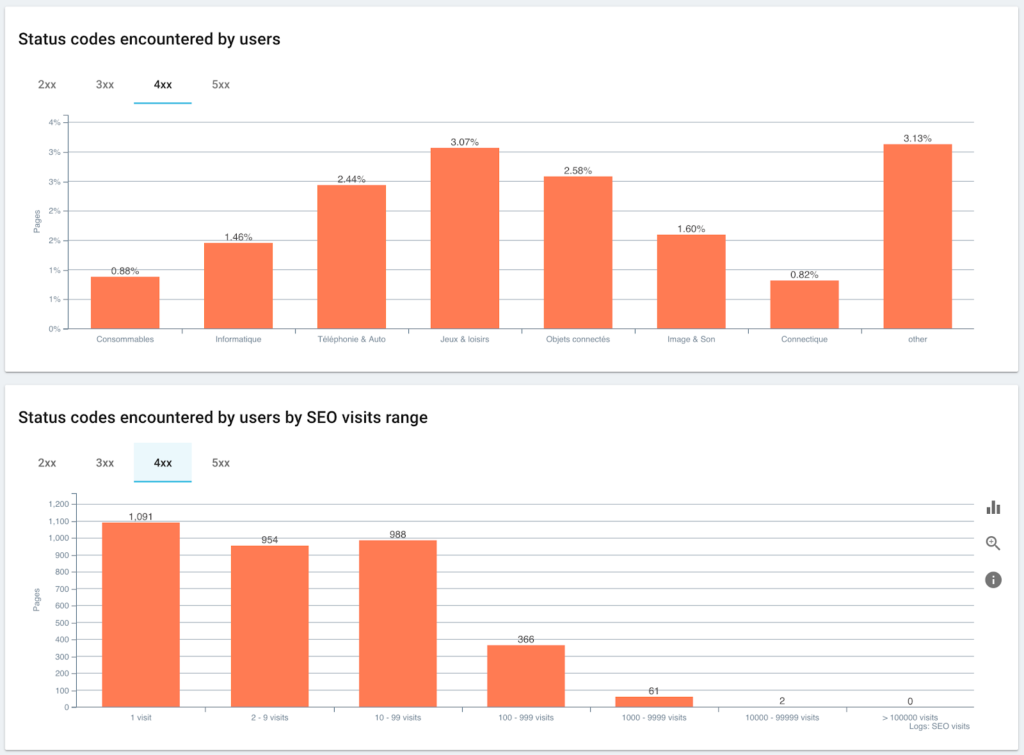
Коды состояния, с которыми сталкиваются пользователи, по сравнению с сеансами SEO
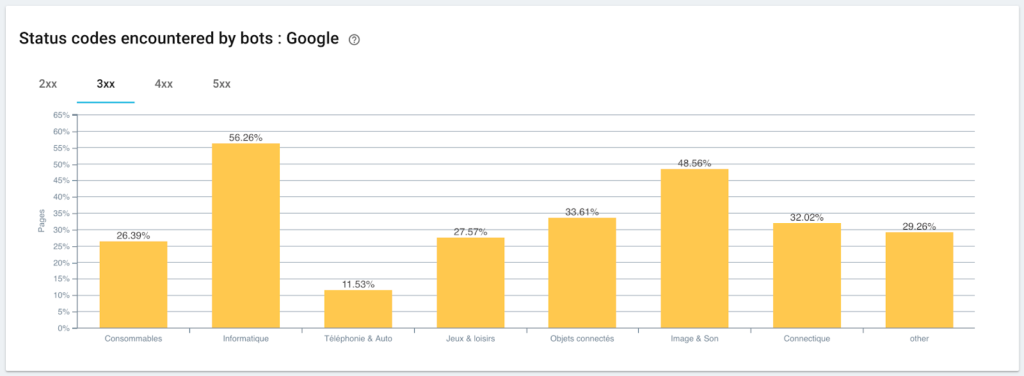
Мониторинг кодов состояния, обнаруженных роботом Googlebot
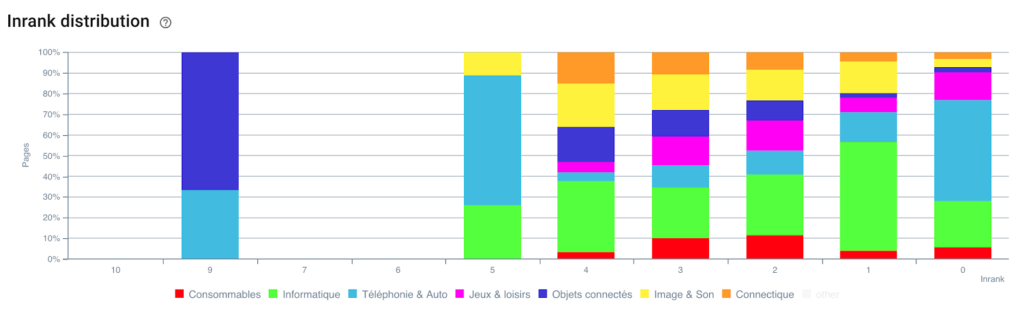
Распределение Inrank
И вот мы только что автоматически создали сегментацию благодаря скрипту, использующему Python и OnCrawl. Все страницы теперь сгруппированы в соответствии с навигационной цепочкой, и это на 3 уровнях глубины: 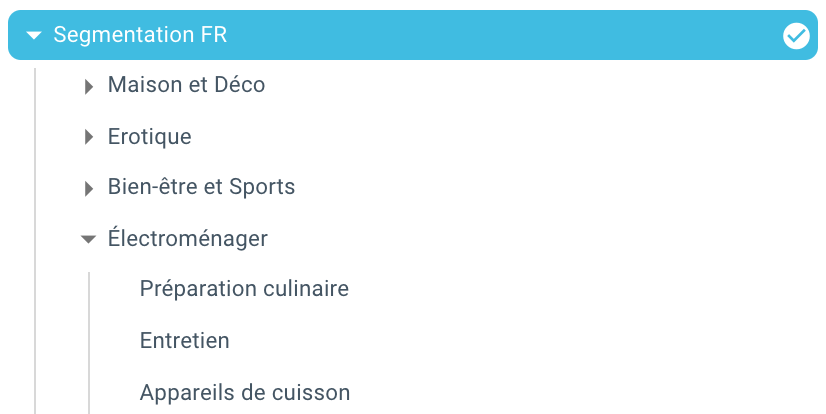
Преимущество заключается в том, что теперь мы можем отслеживать различные KPI (сканирование, глубина, внутренние ссылки, бюджет сканирования, сеансы SEO, посещения SEO, эффективность рейтинга, время загрузки) для каждой группы и подгруппы страниц.
Будущее SEO с Oncrawl
Вы, вероятно, думаете, что это здорово иметь эту возможность «из коробки», но у вас не обязательно есть время, чтобы сделать все это. Хорошая новость заключается в том, что мы работаем над непосредственной интеграцией этой функции в ближайшем будущем.
Это означает, что вскоре вы сможете автоматически создавать сегментацию любого удаленного поля или поля из Data Ingest простым щелчком мыши. И это сэкономит вам массу времени, а также позволит провести невероятный перекрестный SEO-анализ.
Представьте, что вы можете извлечь любые данные из исходного кода ваших страниц или интегрировать любой KPI для каждого URL-адреса. Единственным ограничением является ваше воображение!
Например, вы можете получить цену продажи продуктов и увидеть глубину, Inrank, обратные ссылки, краулинговый бюджет в соответствии с ценой.
Но мы также можем получить имена авторов ваших статей в СМИ и посмотреть, кто работает лучше всего, и применить методы написания, которые работают лучше всего.
Мы можем получить обзоры и рейтинги ваших продуктов и посмотреть, доступны ли лучшие продукты за минимальное количество кликов, получают ли они достаточное количество ссылок, имеют ли они обратные ссылки, хорошо ли они сканируются роботом Googlebot и т. д.
Мы можем интегрировать ваши бизнес-данные, такие как оборот, маржа, коэффициент конверсии, ваши расходы на Google Ads.
Теперь вам нужно представить, как вы можете сопоставить данные, чтобы расширить свой анализ и принять правильные решения по SEO.
Вы хотите протестировать автоматическую сегментацию на навигационной цепочке? Свяжитесь с нами через чат прямо из Oncrawl.
Приятного ползания!