
Автоматическое извлечение понятий и ключевых слов из текста (часть I: традиционные методы)
Опубликовано: 2022-02-22В отделе исследований и разработок Oncrawl мы все чаще стремимся улучшить семантическое содержание ваших веб-страниц. Используя модели машинного обучения для обработки естественного языка (NLP), мы можем детально сравнивать содержимое ваших страниц, создавать автоматические сводки, дополнять или исправлять теги ваших статей, оптимизировать контент в соответствии с вашими данными Google Search Console и т. д.
В предыдущей статье мы говорили об извлечении текстового содержимого из HTML-страниц. На этот раз мы хотели бы поговорить об автоматическом извлечении ключевых слов из текста. Эта тема будет разделена на два поста:
- первый будет охватывать контекст и так называемые «традиционные» методы с несколькими конкретными примерами
- второй, который скоро появится, будет иметь дело с более семантическими подходами, основанными на преобразователях и методах оценки, чтобы сравнить эти разные методы.
Контекст
Помимо названия или аннотации, что может быть лучше для определения содержания текста, научной статьи или веб-страницы, чем с помощью нескольких ключевых слов. Это простой и очень эффективный способ определить тему и концепции более длинного текста. Это также может быть хорошим способом классифицировать серию текстов: идентифицировать их и сгруппировать по ключевым словам. Сайты, предлагающие научные статьи, такие как PubMed или arxiv.org, могут предлагать категории и рекомендации на основе этих ключевых слов.
Ключевые слова также очень полезны для индексации очень больших документов и для поиска информации, области знаний, хорошо известной поисковым системам.
Отсутствие ключевых слов является повторяющейся проблемой при автоматической категоризации научных статей [1]: многим статьям не назначены ключевые слова. Следовательно, необходимо найти методы автоматического извлечения понятий и ключевых слов из текста. Чтобы оценить релевантность автоматически извлеченного набора ключевых слов, наборы данных часто сравнивают ключевые слова, извлеченные алгоритмом, с ключевыми словами, извлеченными несколькими людьми.
Как вы понимаете, это общая проблема поисковых систем при категоризации веб-страниц. Лучшее понимание автоматизированных процессов извлечения ключевых слов позволяет лучше понять, почему веб-страница позиционируется по тому или иному ключевому слову. Он также может выявить семантические пробелы, которые мешают ему хорошо ранжироваться по ключевому слову, на которое вы нацелились.
Очевидно, что есть несколько способов извлечь ключевые слова из текста или абзаца. В этом первом посте мы опишем так называемые «классические» подходы.
[Электронная книга] Data SEO: следующее большое приключение
 Читать электронную книгу
Читать электронную книгуОграничения
Тем не менее, у нас есть некоторые ограничения и предпосылки в выборе алгоритма:
- Метод должен уметь извлекать ключевые слова из одного документа. Для некоторых методов требуется полный корпус, т.е. несколько сотен или даже тысяч документов. Хотя эти методы могут использоваться поисковыми системами, они не будут полезны для одного документа.
- Мы находимся в случае неконтролируемого машинного обучения. У нас нет под рукой набора данных на французском, английском или других языках с аннотированными данными. Другими словами, у нас нет тысяч документов с уже извлеченными ключевыми словами.
- Метод должен быть независимым от домена/лексического поля документа. Мы хотим иметь возможность извлекать ключевые слова из любого типа документа: новостных статей, веб-страниц и т. д. Обратите внимание, что некоторые наборы данных, в которых уже есть ключевые слова, извлеченные для каждого документа, часто относятся к предметной области медицины, информатики и т. д.
- Некоторые методы основаны на моделях POS-тегов, т.е. способности модели НЛП идентифицировать слова в предложении по их грамматическому типу: глагол, существительное, определитель. Определение важности ключевого слова, которое является существительным, а не определителем, явно актуально. Однако в зависимости от языка модели POS-тегов иногда бывают очень неравномерного качества.
О традиционных методах
Мы различаем так называемые «традиционные» методы и более современные, которые используют НЛП — методы обработки естественного языка — такие методы, как встраивание слов и контекстуальное встраивание. Эта тема будет раскрыта в следующем посте. Но сначала вернемся к классическим подходам, выделим два из них:
- статистический подход
- графовый подход
Статистический подход будет в основном основываться на частоте слов и их совпадении. Мы начинаем с простых гипотез для построения эвристики и извлечения важных слов: очень часто встречающееся слово, ряд последовательных слов, которые встречаются несколько раз, и т. д. Методы на основе графа построят граф, где каждый узел может соответствовать слову, группе слов. слова или предложения. Тогда каждая дуга может представлять вероятность (или частоту) появления этих слов вместе.
Вот несколько методов:
- на основе статистики
- TF-IDF
- ГРАБЛИ
- ЯКЕ
- на основе графика
- TextRank
- TopicRank
- Одноранговый
Во всех приведенных примерах используется текст, взятый с этой веб-страницы: Jazz au Tresor: John Coltrane – Impressions Graz 1962.
Статистический подход
Мы познакомим вас с двумя методами Rake и Yake. В контексте SEO вы, возможно, слышали о методе TF-IDF. Но поскольку для этого требуется корпус документов, мы не будем здесь его рассматривать.
ГРАБЛИ
RAKE расшифровывается как Rapid Automatic Keyword Extraction. В Python есть несколько реализаций этого метода, включая rake-nltk. Оценка каждого ключевого слова, которое также называется ключевой фразой, поскольку оно содержит несколько слов, основана на двух элементах: частоте слов и сумме их совпадений. Состав каждой ключевой фразы очень прост, он состоит из:
- разрезать текст на предложения
- разрезать каждое предложение на ключевые фразы
В следующем предложении мы возьмем все группы слов, разделенные элементами пунктуации или стоп-словами:
Незадолго до этого Колтрейн вел квинтет с Эриком Долфи на его стороне и Реджи Уоркманом на контрабасе.
Это может привести к следующим ключевым фразам:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Обратите внимание, что стоп-слова представляют собой серию очень часто встречающихся слов, таких как « the », « in », «and» or « it ». Поскольку классические методы часто основаны на подсчете частоты встречаемости слов, важно тщательно выбирать стоп-слова. В большинстве случаев нам не нужны такие слова, как >"to" , "the" or "of" в предложениях ключевых фраз. Действительно, эти стоп-слова не связаны с конкретным лексическим полем и поэтому гораздо менее релевантны, чем, например, слова « jazz » или « saxophone ».

Как только мы выделили несколько ключевых фраз-кандидатов, мы присваиваем им баллы в соответствии с частотой слов и совпадением. Чем выше оценка, тем более релевантными должны быть ключевые фразы.
Попробуем быстро с текстом из статьи о Джоне Колтрейне.
# фрагмент python для rake из rake_nltk импортировать грабли # предположим, что у вас уже есть статья в переменной 'text' rake = Rake (стоп-слова = FRENCH_STOPWORDS, max_length = 4) rake.extract_keywords_from_text(текст) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Вот первые 5 ключевых фраз:
«австрийское национальное общественное радио», «лирические вершины небеснее», «грац имеет две особенности», «тенор-саксофон Джона Колтрейна», «только записанная версия»
У этого метода есть несколько недостатков. Во-первых, это важность выбора стоп-слов, поскольку они используются для разделения предложения на ключевые фразы-кандидаты. Во-вторых, когда ключевые фразы слишком длинные, они часто будут иметь более высокий балл из-за совпадения присутствующих слов. Чтобы ограничить длину ключевых фраз, мы установили метод с max_length=4 .
ЯКЕ
YAKE расшифровывается как «Еще один экстрактор ключевых слов». Этот метод основан на следующей статье YAKE! Извлечение ключевых слов из отдельных документов с использованием нескольких локальных функций, датированное 2020 годом. Это более новый метод, чем RAKE, авторы которого предложили реализацию Python, доступную на Github.
Мы будем, как и в случае с RAKE, полагаться на частотность и совпадение слов. Авторы также добавят несколько интересных эвристик:
- мы будем различать слова в нижнем регистре и слова в верхнем регистре (либо первая буква, либо все слово). Будем считать здесь, что слова, начинающиеся с заглавной буквы (кроме начала предложения), более релевантны, чем другие: имена людей, городов, стран, брендов. Это тот же принцип для всех слов с заглавной буквы.
- оценка каждой ключевой фразы-кандидата будет зависеть от ее позиции в тексте. Если ключевые фразы-кандидаты появятся в начале текста, они будут иметь более высокий балл, чем если бы они появились в конце. Например, в новостных статьях важные понятия часто упоминаются в начале статьи.
# фрагмент python для yake из yake импортировать KeywordExtractor как Yake yake = yake(lan="fr", стоп-слова=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(текст)
Как и в случае с RAKE, вот 5 лучших результатов:
«Treasure Jazz», «Джон Колтрейн», «Впечатления Грац», «Грац», «Колтрейн»
Несмотря на некоторые дублирования некоторых слов в некоторых ключевых фразах, этот метод кажется довольно интересным.
Графический подход
Этот тип подхода не слишком далек от статистического подхода в том смысле, что мы также будем вычислять совпадения слов. Суффикс Rank, связанный с именами некоторых методов, таких как TextRank , основан на принципе алгоритма PageRank для расчета популярности каждой страницы на основе ее входящих и исходящих ссылок.
[Электронная книга] Автоматизация SEO с помощью Oncrawl
 Читать электронную книгу
Читать электронную книгуTextRank
Этот алгоритм взят из статьи TextRank: Наведение порядка в текстах от 2004 года и основан на тех же принципах, что и алгоритм PageRank . Однако вместо того, чтобы строить график со страницами и ссылками, мы построим график со словами. Каждое слово будет связано с другими словами в соответствии с их совпадением.
В Python есть несколько реализаций. В этой статье я расскажу о pytextrank. Мы сломаем одно из наших ограничений в отношении POS-тегов. Ведь при построении графа мы не будем включать в узлы все слова. Учитываются только глаголы и существительные. Подобно предыдущим методам, использующим стоп-слова для фильтрации нерелевантных кандидатов, алгоритм TextRank использует слова грамматического типа.
Вот пример части графика, который будет построен алгоритмом: 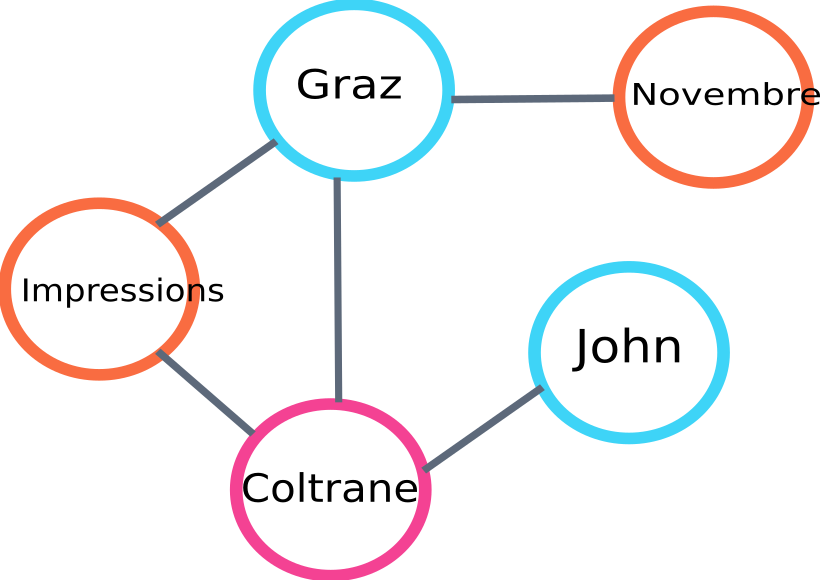
пример графика текстового рейтинга
Вот пример использования в Python. Обратите внимание, что в этой реализации используется конвейерный механизм библиотеки spaCy. Именно эта библиотека умеет делать POS-теги.
# фрагмент python для pytextrank
импортировать просторный
импортировать pytextrank
# загрузить французскую модель
nlp = spacy.load("fr_core_news_sm")
# добавить pytextrank в канал
nlp.add_pipe ("textrank")
документ = нлп (текст)
textrank_keyphrases = doc._.phrases
Вот топ-5 результатов:
«Копенгаг», «ноябрь», «Впечатления Грац», «Грац», «Джон Колтрейн»
Помимо извлечения ключевых фраз, TextRank также извлекает предложения. Это может быть очень полезно для составления так называемых «извлекающих сводок» — этот аспект не будет рассматриваться в этой статье.
Выводы
Из трех апробированных здесь методов последние два кажутся нам вполне соответствующими теме текста. Чтобы лучше сравнить эти подходы, мы, очевидно, должны были бы оценить эти разные модели на большем количестве примеров. Действительно, существуют показатели для измерения релевантности этих моделей извлечения ключевых слов.
Списки ключевых слов, созданные с помощью этих так называемых традиционных моделей, обеспечивают прекрасную основу для проверки правильности таргетинга ваших страниц. Кроме того, они дают первое приблизительное представление о том, как поисковая система может понимать и классифицировать контент.
С другой стороны, другие методы, использующие предварительно обученные модели NLP, такие как BERT, также могут использоваться для извлечения понятий из документа. В отличие от так называемого классического подхода, эти методы обычно позволяют лучше уловить семантику.
Различные методы оценки, контекстные встраивания и преобразователи будут представлены во второй статье на эту тему!
Вот список ключевых слов, извлеченных из этой статьи одним из трех упомянутых методов:
«методы», «ключевые слова», «ключевые фразы», «текст», «извлеченные ключевые слова», «обработка естественного языка»
Библиографические ссылки
- [1] Улучшенное автоматическое извлечение ключевых слов с учетом дополнительных лингвистических знаний, Анетт Халт, 2003 г.
- [2] Автоматическое извлечение ключевых слов из отдельных документов, Стюарт Роуз и др. др., 2010 г.
- [3] БЛЯДЬ! Извлечение ключевых слов из отдельных документов с использованием нескольких локальных функций, Ricardo Campos et. ал, 2020
- [4] TextRank: Наведение порядка в текстах, Rada Mihalcea et. др., 2004 г.
Начните бесплатную 14-дневную пробную версию
 Начать пробную версию
Начать пробную версию