
Подлинность, Dalle-2 и Midjourney, а также наше восхищение изображениями и произведениями искусства, созданными искусственным интеллектом
Опубликовано: 2022-08-04Эта статья о технологиях, лежащих в основе таких платформ, как Dalle-2 и Midjourney, и о том, почему создатели Open AI потенциально должны платить вам деньги, а не взимать с вас плату…
Все больше и больше людей в Интернете называют Dalle-2 и Open AI мошенничеством. Причина в том, что Dalle-2 теперь внезапно превращается в монетизированный сервис, где вам нужно покупать кредиты, если вы используете платформу сверх бета-лимита.
DALLE 2 — лишь одна из многих новых платформ, предлагающих вам доступ к контенту, созданному искусственным интеллектом, и утверждающих, что вы можете использовать его в коммерческих целях. Другие платформы включают Midjourney, Jasper Art, Nightcafe, Starry AI и Craiyon. Мы сосредоточимся на Dalle 2 в этом сообщении в блоге, но они почти идентичны, когда речь идет о юридических проблемах и проблемах.
Мошенничество, на наш взгляд, довольно жесткое утверждение, но есть очевидная проблема в использовании данных, созданных другими людьми (фото, видео, аннотации, люди на изображениях и т. д.), а затем в начале продажи обратно тем же людям.
Многие из нас могут не заметить эту проблему, потому что мы просто очарованы новой технологией. Что-то совершенно понятное.
Однако, несмотря на то, что DALL-E 2, в конце концов, представляет собой лишь передовую машину для распознавания образов, ее выход не является нейтральным, и образы не исходят из свежего воздуха.
Они основаны на множестве данных, где необходимо задать множество юридических вопросов. Вопросы, которые важны для вас как для потенциального пользователя создаваемых вами изображений.
 Изображение создано DALLE-2
Изображение создано DALLE-2
AI-модели нельзя сравнивать с людьми
Вы должны начать с прочтения этой блестящей статьи в Engadget, прежде чем рассматривать возможность использования изображений DALL-E 2 в коммерческих целях.
В статье Engadget отмечают еще одну очень важную вещь. А именно тот факт, что DALL-E 2 и OpenAI НЕ отказываются от своего права на коммерциализацию изображений, которые пользователи создают с помощью DALL-E. По сути, это означает, что вы можете создавать изображения, которые они затем будут продавать другим на коммерческой основе.
Это показывает, что намерения сильно отличаются от иногда используемой аналогии, когда промоутеры DALLE-2 сравнивают его со студентом, читающим работу признанного автора. В этом примере учащийся может изучить авторские стили и шаблоны, а затем найти их применимыми в других контекстах и повторно использовать их там.
Однако речь идет не о человеческом мозге, использующем творческую память для создания новых творческих произведений. Речь идет о машине распознавания образов, повторно использующей и в некоторых случаях воспроизводящей обучающие данные в изображениях, которые затем используются или даже продаются на коммерческой основе. Это просто два разных мира – и в переносном, и в буквальном смысле.
 Реальное фото из реального мира
Реальное фото из реального мира
Обещание подлинности JumpStory
Эта статья предназначена для людей, которые хотят глубже понять, как работает эта новая технология генерации изображений ИИ. Но прежде чем мы начнем, несколько слов о том, почему JumpStory в настоящее время не создает подобную машину.
Конечно, нам неоднократно задавали этот вопрос. Не в последнюю очередь с учетом того, что мы уже используем ИИ в нашей компании, и поскольку у нас есть доступ к миллионам подлинных изображений.
Однако для нас это не технологическая дискуссия, а этическая. Обсуждение, результатом которого стало наше Обещание подлинности.
Мы принципиально против будущего, в котором изображения, созданные ИИ, станут нормой, а не исключением. Назовите нас старомодными, но мы верим, что НАСТОЯЩИЙ мир прекрасен.
Мы гордимся тем, что на наших фото и видео изображены настоящие люди разных форм и размеров. Мы не против использования ИИ, но мы не думаем, что его следует использовать для создания поддельных людей или реальностей.
Такие технологии, как синтетический носитель и DALL-E 2, могут быть привлекательными на первый взгляд, но они также представляют реальный риск. Они рискуют стереть границы между реальным и фальшивым, что станет серьезной угрозой доверию между людьми.
Вот почему JumpStory не использует искусственный интеллект для создания поддельных изображений, а вместо этого использует ИИ для определения того, какие изображения являются оригинальными, подлинными и, конечно же, законными для использования в коммерческих целях.

Это изображения, которые вы найдете с помощью нашего сервиса, и мы назвали наш подход «Подлинный интеллект».
Понимание того, как генерируются изображения AI
На данный момент хватит о JumpStory и юридических проблемах с DALL-E 2. Давайте посмотрим, как ИИ-изображения генерируются на таких платформах, как DALLE-2, Imagen, Crayion (ранее Dall-E Mini), Midjourney и т. д.… Используя DALLE-2 в качестве наиболее разрекламированного примера в настоящее время.
Начнем с того, что DALLE-2 может выполнять разные виды задач, но в этом блоге мы сосредоточимся на задаче генерации изображений.
Как это работает, так это то, что текстовое приглашение вводится в текстовый кодировщик. Этот кодировщик обучен отображать подсказку в пространстве представления. После этого так называемая априорная модель сопоставляет закодированный текст с соответствующей кодировкой изображения, которая фиксирует семантическую информацию подсказки кодирования текста.
(Если это уже становится немного гиковским, мне очень жаль, но дальше будет еще хуже)
Последним шагом для кодировщика изображений является создание изображения, которое визуализирует семантическую информацию, полученную кодировщиком. Это основы таких машин, как Open AI.
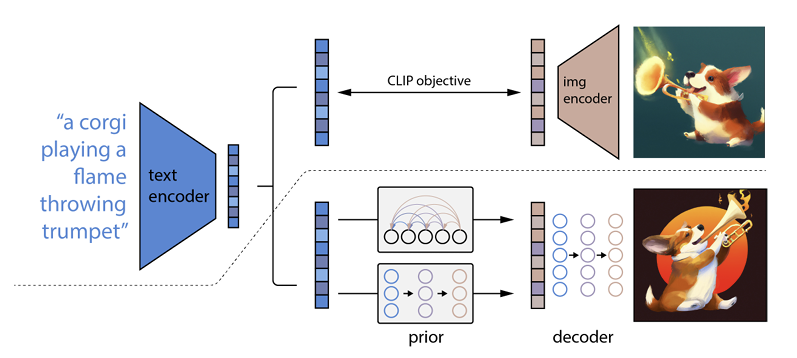
Отношения между текстом и визуальными эффектами
DALL-E 2 и подобные технологии часто называют генераторами преобразования текста в изображение. Причина в их способности получать текстовый ввод и выводить изображение.
Вот пример: «Астронавт верхом на лошади в стиле Энди Уорхола:

источник: ДАЛЛЕ-2
То, что здесь происходит, основано на модели Open AI под названием CLIP. CLIP — это сокращение от «Contrastive Language-Image Pre-training» и представляет собой очень сложную модель, обученную на миллионах изображений и подписей.
В чем CLIP особенно хорош, так это в понимании того, насколько конкретный текст относится к конкретному изображению. Ключевым моментом здесь является не подпись, а то, насколько определенная подпись связана с определенным изображением.
Эта технология называется «контрастной», и CLIP может изучать семантику естественного языка. Способ, которым CLIP научился этому, заключается в процессе, целью которого является (теперь цитируя технологическую документацию): «одновременно максимизировать косинусное сходство между N правильно закодированными парами изображение/заголовок и минимизировать косинусное сходство между N 2 – N неправильно закодированным изображением. пары /caption».
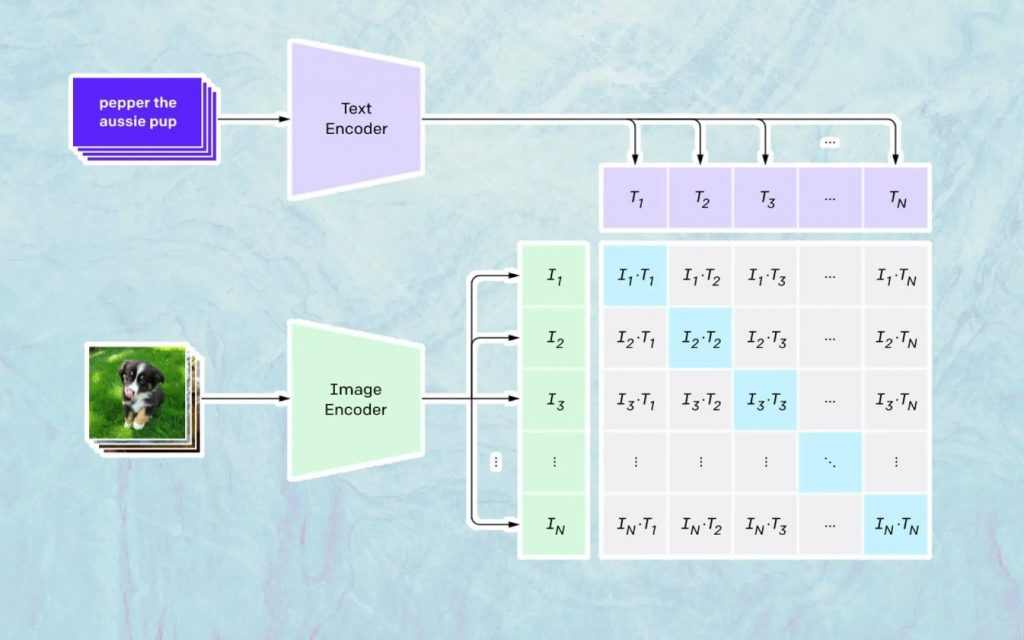
Создание изображений
Как описано выше, модель CLIP изучает пространство представления, в котором она может определить, как связаны кодировки изображений и текстов.
Следующая задача — использовать это пространство для генерации изображений. Для этой цели компания Open AI разработала еще одну модель под названием GLIDE, которая может использовать входные данные из CLIP и, используя диффузионную модель, выполнять генерацию изображений.
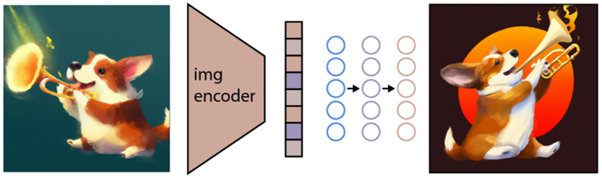
Чтобы кратко объяснить, что такое диффузионная модель, скажем, что это модель, которая учится генерировать данные, обращая вспять процесс постепенного зашумления. Извините за то, что теперь это становится очень техническим, поэтому процитирую описание, найденное в документации Open AI:
«Процесс зашумления рассматривается как параметризованная цепь Маркова, которая постепенно добавляет шум к изображению, чтобы испортить его, что в конечном итоге (асимптотически) приводит к чистому гауссову шуму. Диффузионная модель учится перемещаться назад по этой цепочке, постепенно удаляя шум в течение ряда временных шагов, чтобы обратить этот процесс вспять».

Если вы хотите еще глубже погрузиться в технологию, рекомендуем прочитать эту прекрасную статью Райана О'Коннора.