
Как отвечать на сложные вопросы о данных с помощью данных Oncrawl вне Oncrawl
Опубликовано: 2022-01-04Одним из преимуществ Oncrawl для корпоративного SEO является полный доступ к необработанным данным. Независимо от того, подключаете ли вы свои данные SEO к BI или рабочему процессу обработки данных, проводите собственный анализ или работаете в соответствии с рекомендациями по безопасности данных для вашей организации, необработанные данные SEO и аудита веб-сайтов могут служить многим целям.
Сегодня мы рассмотрим, как использовать данные Oncrawl для ответа на сложные вопросы о данных.
Что такое сложный вопрос данных?
Сложные вопросы данных — это вопросы, на которые нельзя ответить простым поиском в базе данных, но для получения ответа требуется обработка данных.
Вот несколько распространенных примеров «сложных» вопросов о данных, которые часто возникают у SEO-специалистов:
- Создание списка всех ссылок, указывающих на страницы, которые перенаправляют на другие страницы со статусом 404.
- Создание списка всех ссылок и их анкорного текста, указывающего на страницы в сегментации на основе метрик, отличных от URL.
Как отвечать на сложные вопросы о данных в Oncrawl
Структура данных Oncrawl построена таким образом, чтобы почти все сайты могли искать данные почти в реальном времени. Это включает в себя хранение разных типов данных в разных наборах данных, чтобы гарантировать, что время поиска в интерфейсе сведено к минимуму. Например, мы храним все данные, связанные с URL-адресами, в одном наборе данных: код ответа, количество исходящих ссылок, тип присутствующих структурированных данных, количество слов, количество органических посещений… И мы храним все данные, связанные со ссылками, в отдельном наборе данных: цель ссылки, источник ссылки, якорный текст…
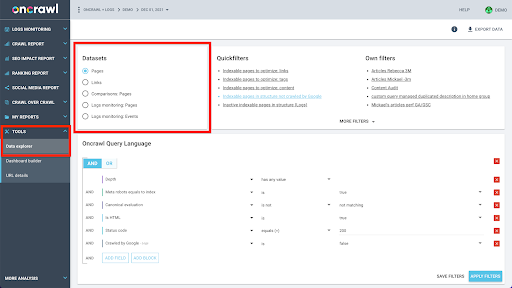
Объединение этих наборов данных требует сложных вычислений и не всегда поддерживается в интерфейсе приложения Oncrawl. Если вы заинтересованы в поиске чего-то, что требует фильтрации одного набора данных, чтобы найти что-то в другом, мы рекомендуем манипулировать необработанными данными самостоятельно.
Поскольку вам доступны все данные Oncrawl, существует множество способов объединения наборов данных и выражения сложных запросов.
В этой статье мы рассмотрим один из них, используя Google Cloud и BigQuery, который подходит для очень больших наборов данных, с которыми сталкиваются многие наши клиенты при изучении данных для сайтов с большим объемом страниц.
Что вам понадобится
Чтобы следовать методу, который мы обсудим в этой статье, вам потребуется доступ к следующим инструментам:
- при сканировании
- API Oncrawl с экспортом больших данных
- Облачное хранилище Google
- Большой запрос
- Скрипт Python для передачи данных из Oncrawl в BigQuery (мы создадим его в этой статье).
Прежде чем начать, вам потребуется доступ к завершенному отчету о сканировании в Oncrawl.
Как использовать данные Oncrawl в Google BigQuery
План сегодняшней статьи таков:
- Во-первых, мы удостоверимся, что Google Cloud Storage настроен на получение данных от Oncrawl.
- Затем мы будем использовать скрипт Python для запуска экспорта больших данных Oncrawl, чтобы экспортировать данные из заданного сканирования в корзину Google Cloud Storage. Мы будем экспортировать два набора данных: страницы и ссылки.
- Когда это будет сделано, мы создадим набор данных в Google BigQuery. Затем мы создадим таблицу из каждого из двух экспортов в наборе данных BigQuery.
- Наконец, мы будем экспериментировать с запросом отдельных наборов данных, а затем обоих наборов данных вместе, чтобы найти ответ на сложный вопрос.
Настройка в Google Cloud для получения данных Oncrawl
Чтобы запустить это руководство в специальной изолированной среде, мы рекомендуем вам создать новый проект Google Cloud, чтобы изолировать его от существующих текущих проектов.
Начнем с дома Google Cloud.
С вашей домашней страницы Google Cloud у вас есть доступ ко многим вещам в дополнение к облачному хранилищу. Нас интересуют сегменты облачного хранилища, которые доступны на уровне облачного хранилища Google Cloud Platform: 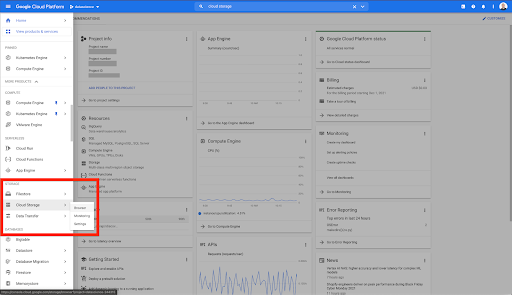
Вы также можете получить доступ к браузеру Cloud Storage напрямую по адресу https://console.cloud.google.com/storage/browser.
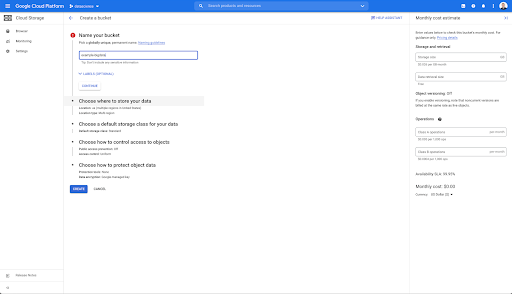
Затем вам нужно создать корзину облачного хранилища и предоставить правильные разрешения, чтобы учетная запись службы Oncrawl могла выполнять запись в нее под выбранным вами префиксом.
Сегмент Google Cloud Storage будет служить временным хранилищем для экспорта больших данных из Oncrawl до их загрузки в Google BigQuery.
В этом сегменте я также создал две папки: «ссылки» и «страницы»: 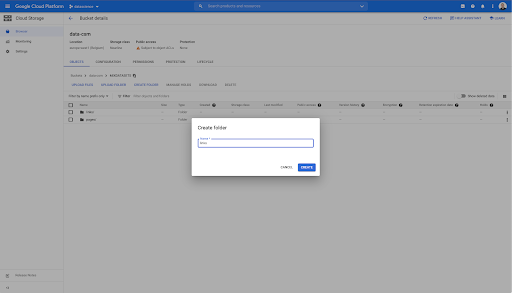
Экспорт наборов данных из Oncrawl
Теперь, когда мы настроили место для сохранения данных, нам нужно экспортировать их из Oncrawl. Экспорт в корзину Google Cloud Storage с помощью Oncrawl особенно прост, поскольку мы можем экспортировать данные в нужном формате и сохранять их прямо в корзину. Это исключает любые дополнительные действия.
Создание ключа API
Экспорт данных из Oncrawl в формате Parquet для BigQuery потребует использования ключа API для программных действий с API от имени владельца учетной записи Oncrawl. Приложение Oncrawl позволяет пользователям создавать именованные ключи API, чтобы ваша учетная запись всегда была хорошо организована и чиста. Ключи API также связаны с различными разрешениями (областями действия), чтобы вы могли управлять ключами и их назначением.
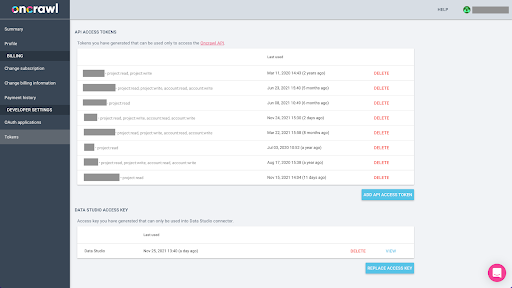
Назовем наш новый ключ «Ключ сеанса знаний». Для функции экспорта больших данных требуются права на запись в учетной записи, поскольку мы создаем экспорт данных. Для этого нам нужно иметь доступ на чтение к проекту и доступ на чтение и запись к учетной записи.
Теперь у нас есть новый ключ API, который я скопирую в буфер обмена.
Обратите внимание, что из соображений безопасности у вас есть возможность скопировать ключ только один раз . Если вы забыли скопировать ключ, вам нужно будет удалить ключ и создать новый.
Создание вашего Python-скрипта
Для этого я создал блокнот Google Colab, но я поделюсь приведенным ниже кодом, чтобы вы могли создать свои собственные инструменты или блокнот.
1. Сохраните свой ключ API в глобальной переменной
Во-первых, мы загружаем среду и объявляем ключ API в глобальной переменной с именем «Token Oncrawl». Затем мы готовимся к остальной части эксперимента:
#@title Доступ к API Oncrawl
#@markdown Предоставьте ниже свой токен API, чтобы разрешить этому блокноту доступ к вашим данным Oncrawl:
# ВАШ ТОКЕН ДЛЯ ONCRAWL API
ONCRAWL_TOKEN = "" #@param {тип: "строка"}
!pip установить тюрьму
из IPython.display импортировать clear_output
clear_output()
print('Все загружено.') 
2. Создайте раскрывающийся список, чтобы выбрать проект Oncrawl, с которым вы хотите работать.
Затем, используя этот ключ, мы хотим иметь возможность выбрать проект, с которым мы хотим поиграть, получив список проектов и создав выпадающий виджет из этого списка. Запустив второй блок кода, выполните следующие шаги:
- Мы вызовем Oncrawl API, чтобы получить список проектов в учетной записи, используя только что отправленный ключ API.
- Получив список проектов из ответа API, мы форматируем его как список, используя имя проекта, а также начальный URL-адрес проекта.
- Мы сохраняем идентификатор проекта, который был предоставлен в ответе.
- Мы создаем раскрывающееся меню и показываем его под блоком кода.
#@title Выберите веб-сайт для анализа, выбрав соответствующий проект Oncrawl.
запросы на импорт
импортная тюрьма
импортировать ipywidgets как виджеты
импортировать json
# Получить список проектов
response = request.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
лимит=1000,
sort = 'имя: по возрастанию'
),
headers={ 'Авторизация': 'Носитель' +ONCRAWL_TOKEN }
)
json_res = ответ.json()
#подготовить раскрывающийся список, чтобы пользователь мог выбрать проект
проекты = []
для элемента в json_res['projects']:
project.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
вывод = виджеты.Вывод()
выпадающее_цель = виджеты. Выпадающее меню (параметры = проекты, описание = "Проект: ")
def dropdown_project_eventhandler (изменение):
вывод.clear_output()
с выходом:
дисплей (проекты)
dropdown_purpose.observe (dropdown_project_eventhandler, имена = 'значение')
дисплей (выпадающее_цель) В появившемся раскрывающемся меню вы можете увидеть полный список проектов, к которым имеет доступ ключ API. 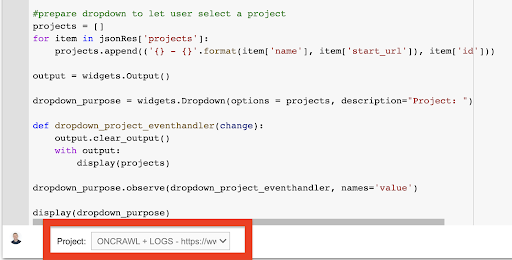
Для сегодняшней демонстрации мы используем демонстрационный проект на основе веб-сайта Oncrawl.
3. Создайте раскрывающийся список, чтобы выбрать профиль сканирования в рамках проекта, с которым вы хотите работать.
Далее мы решим, какой профиль сканирования использовать. Мы хотим выбрать профиль сканирования в рамках этого проекта. Демонстрационный проект имеет множество различных конфигураций сканирования: 
В данном случае мы рассматриваем проект, который команды Oncrawl часто используют для экспериментов, поэтому я выберу профиль сканирования, используемый маркетинговой командой для мониторинга производительности веб-сайта Oncrawl. Так как предполагается, что это самый стабильный профиль сканирования, сегодня это хороший выбор для эксперимента.
Чтобы получить профиль сканирования, мы будем использовать API Oncrawl, чтобы запрашивать последнее сканирование в каждом отдельном профиле сканирования в проекте:
- Мы готовимся запросить Oncrawl API для данного проекта.
- Мы запросим все результаты сканирования в порядке убывания в соответствии с датой их создания.
запросы на импорт
импортировать json
импортировать ipywidgets как виджеты
project_id = раскрывающееся_цель.значение
# Получить сведения о проектах (включая все обходы в проекте)
проект = запросы.получить("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Авторизация': 'Носитель' +ONCRAWL_TOKEN }).json()
# Группировать обходы по профилю обхода (название обхода)
Crawls_by_config = {}
пытаться:
для обхода в проекте['crawls']:
если сканировать['status'] в ["done"]:
если crawl['crawl_config']['name'] отсутствует в crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
если len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[сканирование['crawl_config']['имя']]['crawl_ids'].append(сканирование['id'])
if crawl['status'] == "в архиве":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = True
кроме Исключения как e:
поднять исключение («ошибка {}, {}». формат (е, проект))
# Создаем список для выпадающего списка
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) для k, v в crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Конфигурации обхода: ")
def dropdown_cc_eventhandler (изменение):
вывод.clear_output()
с выходом:
отображение (crawls_by_config)
если len(crawls_by_config.values()) == 0:
print('В этом проекте не найдено живое сканирование')
dropdown_crawl_configs.observe (dropdown_cc_eventhandler, имена = 'значение')
дисплей (dropdown_crawl_configs)Когда этот код запускается, API Oncrawl ответит нам списком обходов по убыванию свойства «создано в».
Затем, поскольку мы хотим сосредоточиться только на завершенных обходах, мы пройдемся по списку обходов. Для каждого сканирования со статусом «выполнено» мы будем сохранять имя профиля сканирования и идентификатор сканирования.
Мы сохраним не более одного профиля обхода, чтобы не открывать слишком много обходов.
Результатом является новое раскрывающееся меню, созданное из списка профилей сканирования в проекте. Мы выберем тот, который нам нужен. Это займет последнее сканирование, проведенное маркетинговой командой: 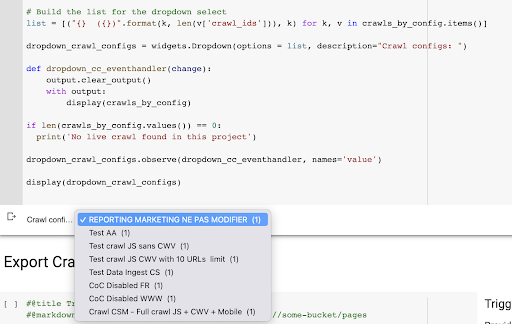
4. Идентифицируйте последнее сканирование с профилем, который мы хотим использовать.
У нас уже есть идентификатор сканирования, связанный с последним сканированием в выбранном профиле. Он скрыт в словаре объектов «crawl_by_config». 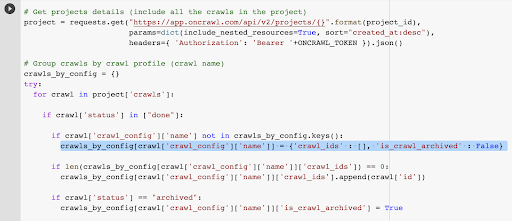
Вы можете легко проверить это в интерфейсе: Найдите последний завершенный обход в этом анализе профиля. 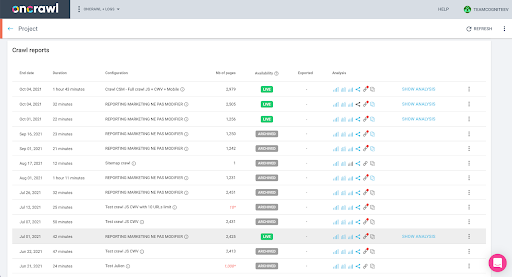
Если мы нажмем, чтобы просмотреть анализ, мы увидим, что идентификатор обхода заканчивается на E617. 
Давайте просто запишем идентификатор обхода для сегодняшней демонстрации.
Конечно, если вы уже знаете, что делаете, вы можете пропустить шаги, которые мы только что рассмотрели, чтобы вызвать Oncrawl API, чтобы получить список проектов и список обходов по профилю обхода: у вас уже есть идентификатор обхода из интерфейс, и этот идентификатор - все, что вам нужно для запуска экспорта.
Шаги, которые мы выполнили до сих пор, просто упрощают процесс получения последнего обхода заданного профиля обхода данного проекта с учетом того, к чему имеет доступ ключ API. Это может быть полезно, если вы предоставляете это решение другим пользователям или хотите его автоматизировать.
5. Экспорт результатов сканирования
Теперь посмотрим на команду экспорта:
#@title Активировать экспорт больших данных
#@markdown Укажите свой сегмент GCS и префикс gs://some-bucket/pages
# ВАШЕ ВЕДРО GCS
gcs_bucket = #@param {тип: "строка"}
gcs_prefix = #@param {тип: "строка"}
# Получить идентификатор последнего обхода из заданного проекта/профиля обхода
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Шаблон полезной нагрузки для запроса на экспорт данных
полезная нагрузка = {
"данные_экспорт": {
"тип_данных": "страница",
"resource_id": last_crawl_id,
"output_format": "паркет",
«цель»: «гкс»,
"целевые_параметры": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Активировать экспорт
export = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Авторизация': 'Носитель' + ONCRAWL_TOKEN }).json()
# Показать ответ API
дисплей (экспорт)
# Сохраняем идентификатор экспорта для использования в будущем
export_id = экспорт['data_export']['id']Мы хотим экспортировать в корзину Cloud Storage, которую мы настроили ранее.
В рамках этого мы собираемся экспортировать страницы для последнего идентификатора обхода:
- Последний идентификатор обхода получается из списка идентификаторов обхода, который хранится где-то в словаре «crawls_by_config», созданном на шаге 3.
- Мы хотим выбрать тот, который соответствует раскрывающемуся меню на шаге 4, поэтому мы используем атрибут value раскрывающегося меню.
- Затем мы извлекаем атрибут crawl_ID. Это список. Мы сохраним в списке 50 лучших элементов. Нам нужно сделать это, потому что на шаге 2, как вы помните, когда мы создавали словарь crawls_by_config, мы сохраняли только один идентификатор обхода для каждого имени конфигурации.
Я настроил поля ввода, чтобы упростить предоставление корзины и префикса Google Cloud Storage или папки, куда мы хотим отправить экспорт. 
В целях демонстрации сегодня мы будем писать в папку «смешанный набор данных» в одной из папок, которые я уже настроил. Когда мы настроим нашу корзину в Google Cloud Storage, вы помните, что я подготовил папки для экспорта «ссылок» и для экспорта «страниц».
Для первого экспорта мы хотим экспортировать страницы в папку «pages» для последнего идентификатора обхода, используя формат файла Parquet. 
В приведенных ниже результатах вы увидите полезные данные, которые должны быть отправлены в конечную точку экспорта данных, которая является конечной точкой для запроса экспорта больших данных с использованием ключа API:
# Шаблон полезной нагрузки для запроса на экспорт данных
полезная нагрузка = {
"данные_экспорт": {
"тип_данных": "страница",
"resource_id": last_crawl_id,
"output_format": "паркет",
«цель»: «гкс»,
"целевые_параметры": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
Он содержит несколько элементов, в том числе тип набора данных, который вы хотите экспортировать. Вы можете экспортировать набор данных страницы, набор данных ссылок, набор данных кластеров или набор данных структурированных данных. Если вы не знаете, что можно сделать, вы можете ввести здесь ошибку, и при вызове API вы получите сообщение о том, что выбор типа данных должен быть либо страницей, либо ссылкой, либо кластером, либо структурированными данными. Сообщение выглядит так:

{'fields': [{'message': 'Неверный выбор. Должен быть одним из «страница», «ссылка», «кластер», «структурированные_данные».',
'имя': 'тип_данных',
'тип': 'invalid_choice'}],
'тип': 'invalid_request_parameters'}
В целях сегодняшнего эксперимента мы будем экспортировать набор данных страницы и набор данных ссылок в отдельных экспортах.
Начнем с набора данных страницы. Когда я запускаю этот блок кода, я распечатываю вывод вызова API, который выглядит так:
{'data_export': {'data_type': 'страница',
'export_failure_reason': Нет,
«идентификатор»: «ХХХХХХХХХХХХ»,
'output_format': 'паркет',
'output_format_parameters': Нет,
'output_row_count': нет,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'статус': 'ЗАПРОШЕН',
'цель': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/страниц/'}}}
Это позволяет мне видеть, что экспорт был запрошен.
Если мы хотим проверить статус экспорта, это очень просто. Используя идентификатор экспорта, который мы сохранили в конце этого блока кода, мы можем запросить статус экспорта в любое время с помощью следующего вызова API:
# СТАТУС ЭКСПОРТА
export_status = request.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Авторизация': 'Носитель' +ONCRAWL_TOKEN }).json ()
дисплей (статус_экспорта)
Это укажет статус как часть возвращаемого объекта JSON:
{'data_export': {'data_type': 'страница',
'export_failure_reason': Нет,
«идентификатор»: «ХХХХХХХХХХХХ»,
'output_format': 'паркет',
'output_format_parameters': Нет,
'output_row_count': нет,
'output_size_in_bytes': нет,
'requested_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'статус': 'ЭКСПОРТ',
'цель': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/страниц/'}}} Когда экспорт завершится ( 'status': 'DONE' ), мы можем вернуться в Google Cloud Storage.
Если мы заглянем в наше ведро и перейдем в папку «ссылки», здесь еще ничего нет, потому что мы экспортировали страницы. 
Однако, когда мы смотрим в папку «страницы», мы видим, что экспорт прошел успешно. У нас есть файл Parquet: 
На этом этапе набор данных страниц готов к импорту в BigQuery, но сначала мы повторим шаги, описанные выше, чтобы получить файл Parquet для ссылок:
- Обязательно установите префикс ссылок.
- Выберите тип данных «ссылка».
- Запустите этот блок кода еще раз, чтобы запросить второй экспорт.

Это создаст файл Parquet в папке «links».
Создание наборов данных BigQuery
Пока идет экспорт, мы можем двигаться вперед и начать создавать наборы данных в BigQuery и импортировать файлы Parquet в отдельные таблицы. Потом мы вместе сядем за столы.
Сейчас мы хотим поиграть с Google Big Query, который доступен как часть Google Cloud Platform. Вы можете использовать панель поиска в верхней части экрана или перейти непосредственно на https://console.cloud.google.com/bigquery.
Создание набора данных для вашей работы
Нам нужно создать набор данных в Google BigQuery: 
Вам нужно будет указать имя набора данных и выбрать место, где будут храниться данные. Это важно, потому что это определяет, где обрабатываются данные, и не может быть изменено. Это может иметь значение, если ваши данные содержат информацию, подпадающую под действие GDPR или других законов о конфиденциальности. 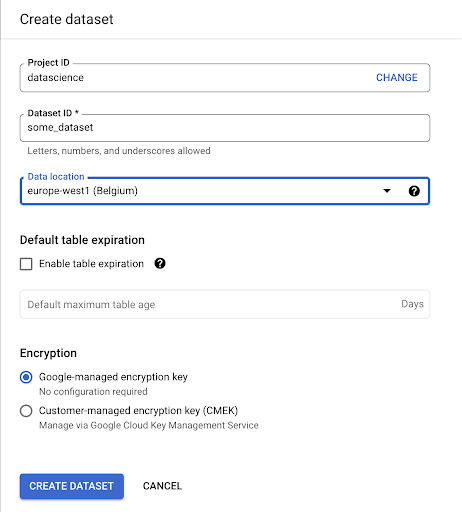
Этот набор данных изначально пуст. Когда вы откроете его, вы сможете создать таблицу, поделиться набором данных, скопировать, удалить и так далее.
Создание таблиц для ваших данных
Мы создадим таблицу в этом наборе данных. 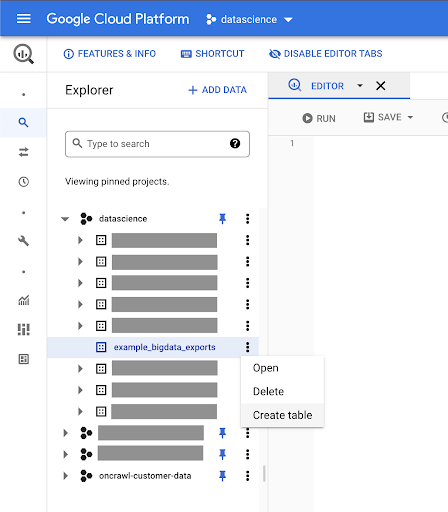
Вы можете либо создать пустую таблицу, а затем предоставить схему. Схема — это определение столбцов в таблице. Вы можете определить свою собственную или просмотреть Google Cloud Storage, чтобы выбрать схему из файла.
Мы будем использовать этот последний вариант. Мы перейдем к нашей корзине, а затем к папке «pages». Давайте выберем файл pages. Существует только один файл, поэтому мы можем выбрать только один, но если бы при экспорте было создано несколько файлов, мы могли бы выбрать их все. 
Когда мы выбираем файл, он автоматически определяет, что он находится в формате файла Parquet. Мы хотим создать таблицу с именем «страницы», и схема будет определяться исходным файлом. 
Когда мы загружаем файл Parquet, он встраивает схему. Другими словами, определение столбцов создаваемой нами таблицы будет выводиться из схемы, которая уже существует в файле Parquet. Вот где на самом деле происходит часть волшебства.
Давайте просто двинемся вперед и просто создадим таблицу из файла Parquet. 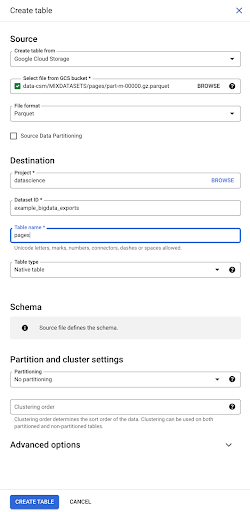
На левой боковой панели теперь мы видим, что в нашем наборе данных появилась таблица, а это именно то, что нам нужно:
Итак, теперь у нас есть схема таблицы pages со всеми полями, которые были автоматически выведены из файла Parquet. У нас есть Inrank, глубина страницы, если страница редирект и так далее и тому подобное: 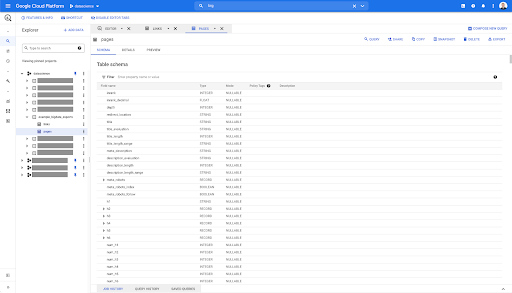
Большинство этих полей такие же, как те, которые доступны в Data Studio через коннектор Oncrawl Data Studio, и такие же, как те, которые вы видите в обозревателе данных в интерфейсе Oncrawl. 
Однако есть некоторые отличия. Когда мы играем с необработанным экспортом больших данных, у вас есть все необработанные данные.
- В Студии данных некоторые поля переименовываются, некоторые поля скрываются, а некоторые поля добавляются, например статус.
- В обозревателе данных некоторые поля являются так называемыми «виртуальными полями», что означает, что они могут быть своего рода ярлыком для базового поля. Эти виртуальные поля, доступные в обозревателе данных, не будут перечислены в схеме, но их можно воссоздать на основе того, что доступно в файле Parquet.
Давайте теперь закроем эту таблицу и сделаем это снова для ссылок.
Для таблицы ссылок схема немного меньше. 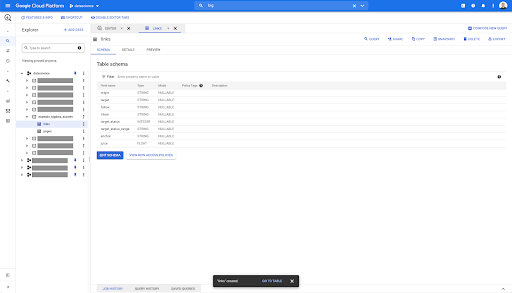
Он содержит только следующие поля:
- Происхождение ссылки,
- Цель ссылки,
- Следующее свойство,
- Внутреннее свойство,
- Целевой статус,
- Диапазон целевого состояния,
- Якорный текст и
- Сок или акции, купленные по ссылке.
В любой таблице в BigQuery, когда вы нажимаете на вкладку предварительного просмотра, у вас есть предварительный просмотр таблицы без запроса к базе данных: 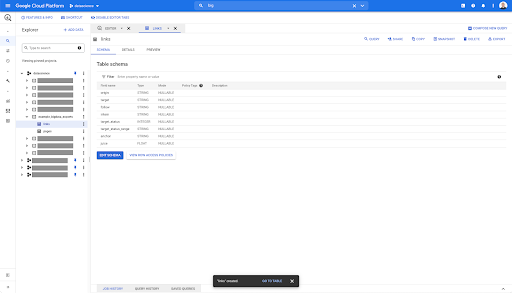
Это дает вам быстрый просмотр того, что доступно в нем. В предварительном просмотре приведенной выше таблицы ссылок у вас есть предварительный просмотр каждой отдельной строки и всех столбцов.
В некоторых наборах данных Oncrawl вы можете увидеть некоторые строки, которые охватывают несколько строк. У меня нет примера для вас, но если это так, то это потому, что некоторые поля содержат список значений. Например, в списке заголовков h2 на странице одна строка будет охватывать несколько строк в Big Query. Мы рассмотрим это позже, если увидим пример.
Создание запроса
Если вы никогда не создавали запрос в BigQuery, сейчас самое время поиграть с ним, чтобы ознакомиться с тем, как он работает. BigQuery использует SQL для поиска данных.
Как работают запросы
В качестве примера, давайте посмотрим на все URL-адреса и их индексы…
ВЫБЕРИТЕ URL, ранг...
из набора данных страниц…
ВЫБЕРИТЕ URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages`...
где код состояния страницы 200…
ВЫБЕРИТЕ URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages`, ГДЕ status_code = 200 ...
и сохранить только первые 10 результатов:
ВЫБЕРИТЕ URL, inrank ИЗ `datascience-oncrawl.example_bigdata_exports.pages`, ГДЕ status_code = 200 LIMIT 10
Когда мы запустим этот запрос, мы получим первые 10 строк списка страниц, где код состояния равен 200.
Любое из этих свойств можно изменить. f я хочу 1000 строк вместо 10, я могу установить 1000 строк:
ВЫБЕРИТЕ URL, inrank ИЗ `datascience-oncrawl.example_bigdata_exports.pages`, ГДЕ status_code = 200 LIMIT 1000
Если я хочу отсортировать, я могу сделать это с помощью «order-by»: это даст мне все строки, упорядоченные по убыванию Inrank.
ВЫБЕРИТЕ URL, inrank ИЗ `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Это мой первый запрос. Я могу сохранить его, если захочу, что даст мне возможность повторно использовать этот запрос позже, если я захочу: 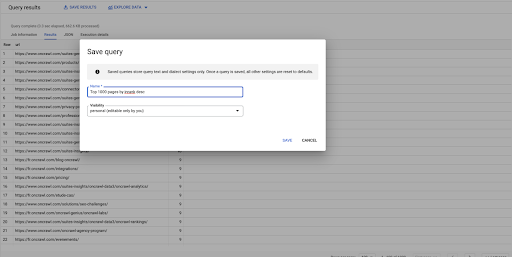
Использование запросов для ответа на простые вопросы: Список всех внутренних ссылок на страницы со статусом 301.
Теперь, когда мы знаем, как составить запрос, давайте вернемся к нашей исходной задаче.
Мы хотели ответить на вопросы о данных, будь то простые или сложные. Давайте начнем с простого вопроса, например «какие все внутренние ссылки ведут на страницы со статусом 301 (перенаправлено) и где их найти?»
Создание нового запроса
Мы начнем с изучения того, как это работает.
Мне понадобятся столбцы для следующих элементов из базы данных «links»:
- Источник
- Цель
- Код состояния цели
ВЫБЕРИТЕ источник, цель, target_status ИЗ `datascience-oncrawl.example_bigdata_exports.links`
Я хочу ограничить их только внутренними ссылками, но давайте представим, что я не помню имя столбца или значение, указывающее, является ли ссылка внутренней или внешней. Я могу перейти к схеме, чтобы посмотреть ее, и использовать предварительный просмотр для просмотра значения: 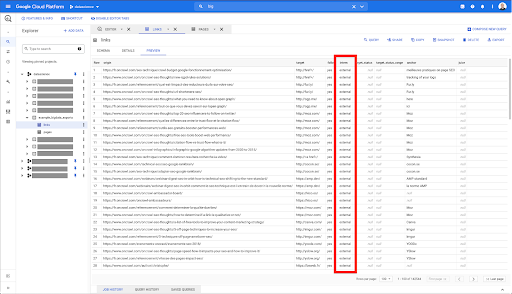
Это говорит мне о том, что столбец называется «внутренний», а возможный диапазон значений — «внешний» или «внутренний».
В своем запросе я хочу указать «где стажер является внутренним» и пока ограничить результаты первыми 100:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links`, WHERE стажер LIKE 'internal' LIMIT 100
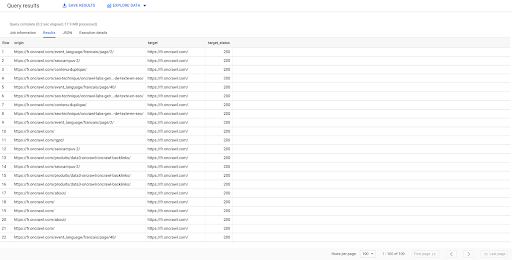
Результат выше показывает список ссылок с их целевым статусом. У нас только внутренние ссылки, а их у нас 100, как указано в запросе.
Если мы хотим, чтобы только внутренние ссылки указывали на перенаправленные страницы, мы могли бы сказать «где стажер, как внутренний и целевой статус, равен 301»:
ВЫБЕРИТЕ источник, цель, target_status ИЗ `datascience-oncrawl.example_bigdata_exports.links`, ГДЕ стажер НРАВИТСЯ 'внутренний' И target_status = 301
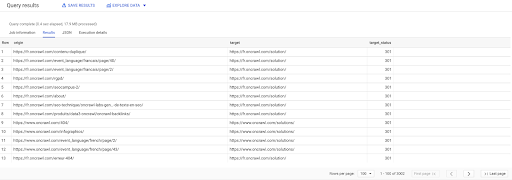
Если мы не знаем, сколько из них существует, мы можем запустить этот новый запрос, и мы увидим, что существует 3002 внутренних ссылки с целевым статусом 301.
Соединение таблиц: нахождение финальных кодов статуса ссылок, указывающих на перенаправленные страницы
На веб-сайте у вас часто есть ссылки на страницы, которые перенаправляются. Мы хотим знать код состояния страницы, на которую они перенаправляются (или конечный целевой URL).
В одном наборе данных у вас есть информация о ссылках: исходная страница, целевая страница и ее код состояния (например, 301), но не URL-адрес, на который указывает перенаправленная страница. А в другом у вас есть информация о редиректах и их конечных целях, но нет исходной страницы, где была найдена ссылка на них.
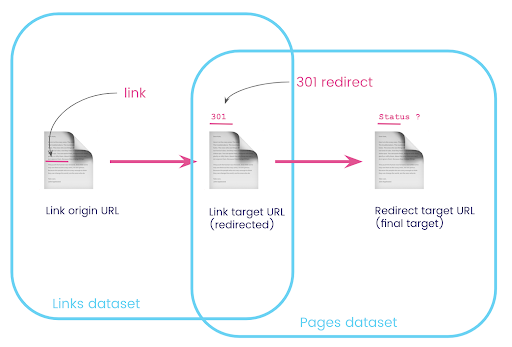
Давайте разберем это:
Во-первых, нам нужны ссылки на редиректы. Давайте запишем это. Мы хотим:
- Происхождение.
- Цель. Цель должна иметь код состояния 301.
- Конечная цель перенаправления.
Другими словами, в наборе данных ссылок мы хотим:
- Происхождение ссылки
- Цель ссылки
В наборе данных страниц нам нужно:
- Все цели, которые перенаправлены
- Конечная цель перенаправления
Это даст нам такой запрос:
ВЫБЕРИТЕ URL, final_redirect_location, final_redirect_status ИЗ `datascience-oncrawl.example_bigdata_exports.pages` КАК страницы, ГДЕ status_code = 301 ИЛИ status_code = 302
Это должно дать мне первую часть уравнения.
Теперь мне нужны все ссылки на страницу, которые являются результатами только что созданного запроса, используя псевдонимы для моих наборов данных и соединяя их по целевому URL-адресу ссылки и URL-адресу страницы. Это соответствует перекрывающейся области двух наборов данных на диаграмме в начале этого раздела.
ВЫБРАТЬ ссылки.оригин, страницы.url, страницы.final_redirect_location, страницы.final_redirect_status ИЗ `datascience-oncrawl.example_bigdata_exports.pages` страницы AS ПРИСОЕДИНИТЬСЯ `datascience-oncrawl.example_bigdata_exports.links` ссылки AS НА ссылки.цель = страницы.url КУДА страницы.status_code = 301 ИЛИ страницы.status_code = 302 СОРТИРОВАТЬ ПО происхождение ASC
В результатах запроса я могу переименовать столбцы, чтобы было понятнее, но я уже вижу, что у меня есть ссылка со страницы в первом столбце, которая ведет на страницу во втором столбце, которая, в свою очередь, перенаправляется на страницу в третьем столбце. В четвертом столбце у меня есть код состояния конечной цели: 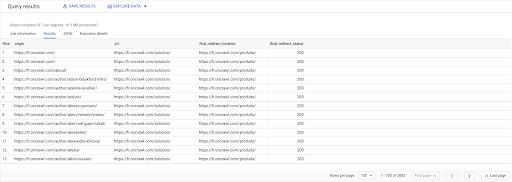
Теперь я могу сказать, какие ссылки ведут на перенаправленные страницы, которые не разрешаются в 200 страниц. Например, это могут быть ошибки 404, что дает мне приоритетный список ссылок для исправления.
Ранее мы видели, как сохранить запрос. Мы также можем сохранить результаты до 16000 строк результатов: 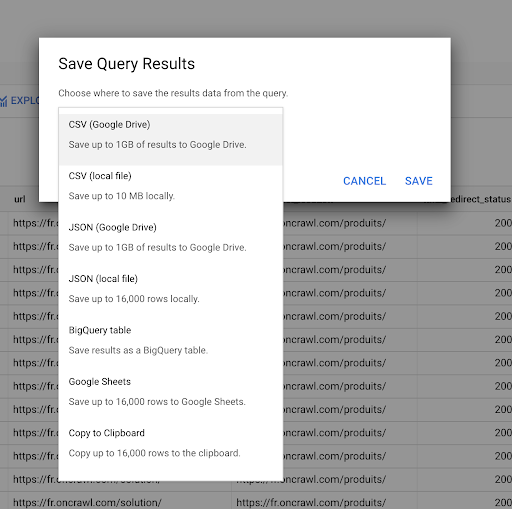
Затем мы можем использовать эти результаты по-разному. Вот несколько примеров:
- Мы можем сохранить это как файл CSV или JSON локально.
- Мы можем сохранить его как электронную таблицу Google Sheets и поделиться ею с остальной командой.
- Мы также можем экспортировать его непосредственно в Студию данных.
Данные как стратегическое преимущество
Со всеми этими возможностями стратегически легко использовать ответы на ваши сложные вопросы. Возможно, у вас уже есть опыт подключения результатов BigQuery к Data Studio или другим платформам визуализации данных, или у вас уже может быть процесс, который передает информацию команде инженеров или даже в рабочий процесс бизнес-аналитики или анализа данных.
Если вы включили шаги, описанные в этой статье, как часть процесса, помните, что вы можете автоматизировать все шаги в BigQuery: все действия, которые мы выполнили в этой статье, также доступны через BigQuery API. Это означает, что их можно запускать программно как часть скрипта или пользовательского инструмента.
Какими бы ни были ваши следующие шаги, первым шагом всегда является доступ к исходным данным SEO и веб-сайта. Мы считаем, что этот доступ к данным является одной из самых важных частей технического анализа: с Oncrawl у вас всегда будет полный доступ к необработанным данным.
Доступ к данным также означает, что вы можете выйти за рамки возможностей интерфейса Oncrawl и изучить все взаимосвязи между вашими данными, какими бы сложными ни были вопросы, которые вы задаете.