
Введение в анализ файла журнала SEO
Опубликовано: 2021-05-17Анализ логов — это наиболее тщательный способ анализа того, как поисковые системы читают наши сайты. Каждый день SEO-специалисты, специалисты по цифровому маркетингу и специалисты по веб-аналитике используют инструменты, которые показывают диаграммы о трафике, поведении пользователей и конверсиях. SEO-специалисты обычно пытаются понять, как Google сканирует их сайт через Google Search Console.
Итак… зачем SEO-специалисту анализировать другие инструменты, чтобы проверить, правильно ли поисковая система читает сайт? Хорошо, давайте начнем с основ.
Что такое лог-файлы?
Файл журнала — это файл, в котором веб-сервер записывает строку для каждого отдельного ресурса на веб-сайте, запрашиваемого ботами или пользователями. Каждая строка содержит данные о запросе, которые могут включать:
IP-адрес вызывающего абонента, дата, требуемый ресурс (страница, .css, .js, …), пользовательский агент, время отклика, …
Ряд будет выглядеть примерно так:
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "www.***.it" "-"
Сканируемость и возможность обновления
Каждая страница имеет три основных SEO-статуса:
- доступный для сканирования
- индексируемый
- ранжируемый
С точки зрения анализа журнала мы знаем, что страница для индексации должна быть прочитана ботом. Точно так же контент, уже проиндексированный поисковой системой, должен быть повторно просканирован, чтобы обновиться в индексах поисковой системы.
К сожалению, в Google Search Console у нас нет такого уровня детализации: мы можем проверить, сколько раз Googlebot читал страницу на сайте за последние три месяца и как быстро отвечал веб-сервер.
Как мы можем проверить, прочитал ли бот страницу? Разумеется, с помощью лог-файлов и анализатора лог-файлов.
Зачем SEO-специалистам анализировать лог-файлы?
Анализ файла журнала позволяет специалистам по поисковой оптимизации (и системным администраторам тоже) понять:
- Именно то, что читает бот
- Как часто бот его читает
- Сколько стоит сканирование с точки зрения затраченного времени (мс)
Инструмент анализа журналов позволяет анализировать журналы, группируя информацию по «пути», по типу файла или по времени отклика. Отличный инструмент анализа журналов также позволяет нам объединять информацию, полученную из файлов журналов, с другими источниками данных, такими как Google Search Console (клики, показы, средние позиции) или Google Analytics.
Анализатор журнала сканирования
 Учить больше
Учить большеЧто искать в лог-файлах?
Одна из основных важных частей информации в файлах журналов — это то, чего нет в файлах журналов. Я не шучу. Первый шаг к пониманию того, почему страница не проиндексирована или не обновлена до последней версии, — проверить, прочитал ли ее бот (например, Googlebot).
После этого, если страница часто обновляется, может быть важно проверить, как часто бот читает страницу или раздел сайта.
Следующий шаг — проверить, какие страницы чаще всего читают боты. Отслеживая их, вы можете проверить, являются ли эти страницы:
- заслуживают того, чтобы его так часто читали
- или их читают так часто, потому что что-то на странице вызывает постоянные неконтролируемые изменения
Например, несколько месяцев назад на сайте, над которым я работал, очень часто бот читал странный URL. Бот показал, что эта страница была получена из URL-адреса, созданного скриптом JS, и что эта страница была отмечена некоторыми значениями отладки, которые менялись каждый раз при загрузке страницы… После этого открытия хороший SEO-специалист наверняка найдет правильное решение, чтобы исправить это. дыра в краулинговом бюджете.
Сканирующий бюджет
Бюджет сканирования? Что это такое? У каждого сайта есть свой метафорический бюджет, связанный с поисковыми системами и их ботами. Да: Google устанавливает своего рода бюджет для вашего сайта. Это нигде не записано, но «вычислить» можно двумя способами:
- проверка отчета статистики сканирования Google Search Console
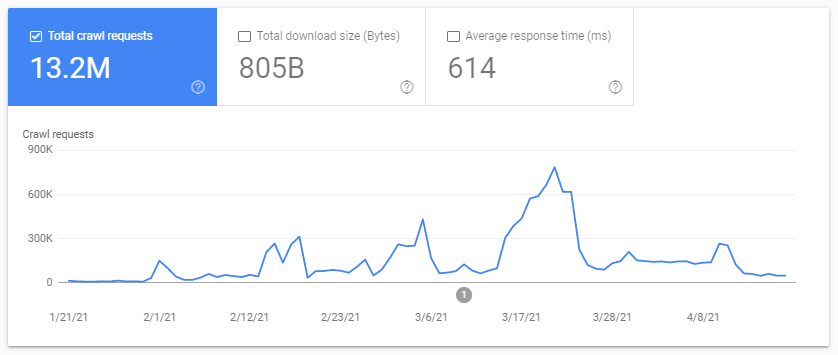
- проверка файлов журналов, поиск ( фильтрация ) их с помощью пользовательского агента, содержащего «Googlebot» ( вы получите наилучшие результаты, если убедитесь, что эти пользовательские агенты соответствуют правильным IP-адресам Google… )
Бюджет обхода увеличивается, когда сайт обновляется интересным контентом, или когда он регулярно обновляет контент, или когда сайт получает хорошие обратные ссылки.
То, как расходуется краулинговый бюджет на вашем сайте, можно контролировать:
- внутренние ссылки (follow/nofollow тоже!)
- без индекса / канонический
- robots.txt (осторожно: это «блокирует» пользовательский агент)
Страницы зомби
Для меня «зомби-страницы» — это все страницы, которые не имели органического трафика или посещений ботами в течение значительного периода времени, но имеют внутренние ссылки, указывающие на них.
Этот тип страницы может использовать слишком большой краулинговый бюджет и может получить ненужный рейтинг страницы из-за внутренних ссылок. Эту ситуацию можно решить:
- Если эти страницы полезны для пользователей, которые заходят на сайт, мы можем установить для них значение noindex и установить внутренние ссылки на них как nofollow ( или использовать disallow robots.txt, но будьте осторожны с этим… )
- Если эти страницы бесполезны для пользователей, которые приходят на сайт, мы можем удалить их (и вернуть код состояния 410 или 404) и удалить все внутренние ссылки.
С помощью Oncrawl мы можем создать «отчет о зомби» на основе:
- показы GSC
- клики GSC
- сеансы GA
Мы также можем использовать события журнала для обнаружения зомби-страниц: например, мы можем определить фильтр событий 0. Один из самых простых способов сделать это — создать сегментацию. В приведенном ниже примере я фильтрую все страницы по следующим критериям: нет обращений робота Googlebot, но есть Inrank (это означает, что эти страницы имеют внутренние ссылки, указывающие на них). 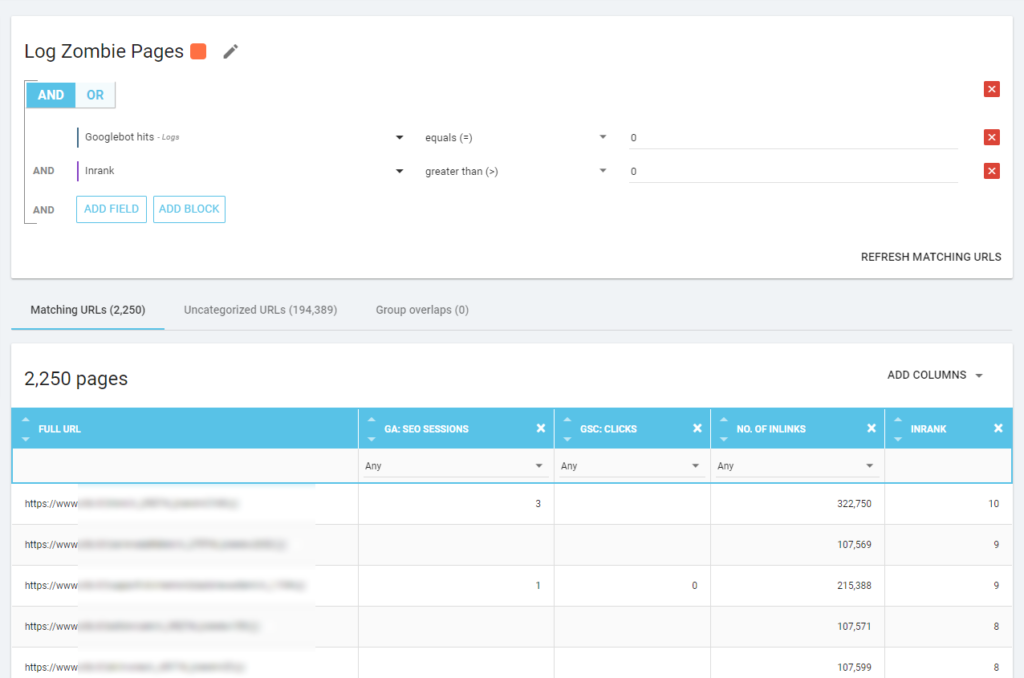
Итак, теперь мы можем использовать эту сегментацию во всех отчетах Oncrawl. Это позволяет нам получать информацию из любого графика, например: сколько «страниц-зомби журнала» возвращают код состояния 200? 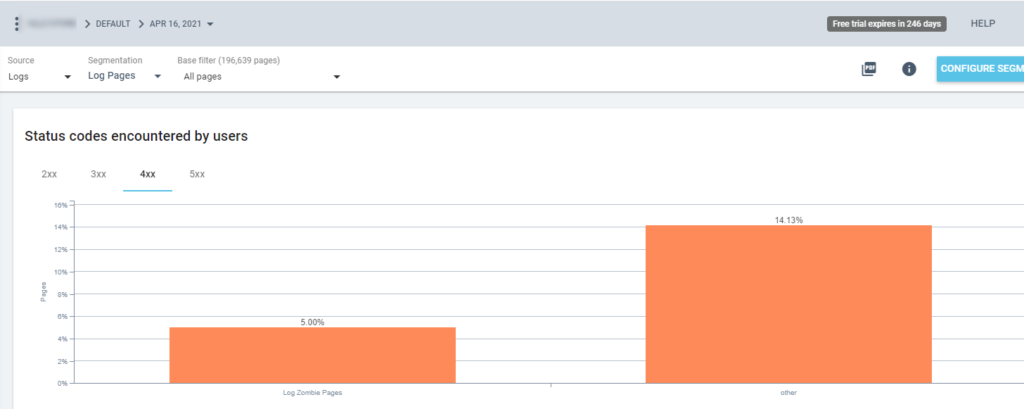
Страницы-сироты
Для меня «страницы-сироты», на которые стоит обратить внимание, — это все страницы, которые имеют высокую ценность по важным показателям (сеанс GA, показ GSC, обращения к журналу, …), которые не имеют внутренних ссылок, указывающих на них, чтобы поделиться рангом страницы. и указать важность страницы.
Как и в случае со «Зомби-страницами», для создания отчета на основе журнала лучше всего создать новую сегментацию. 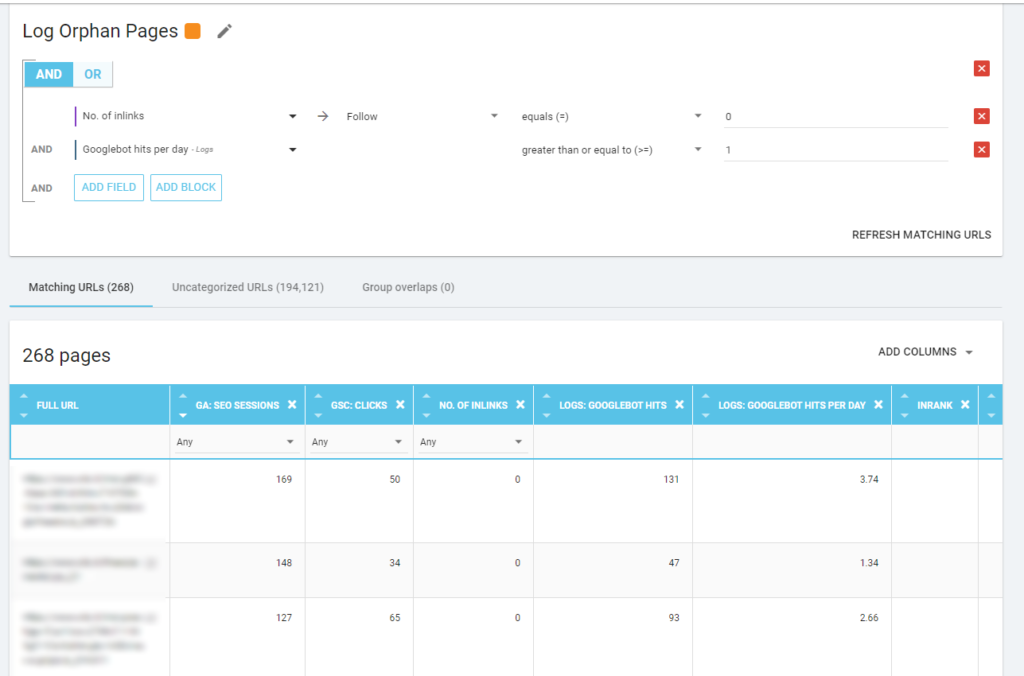
ВАУ, сколько страниц с сессиями и переходами и без инлинков!
При проверке отчета, основанного на «Нулевых внутренних ссылках», обратите внимание на статус сканирования: удалось ли Oncrawl просканировать весь сайт или только несколько страниц? Это можно увидеть на главной странице проекта: 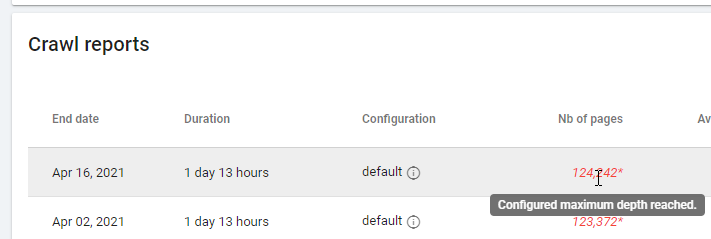
Если достигнута максимальная глубина:

- Проверьте конфигурацию сканирования
- Проверьте структуру вашего сайта
Файлы журнала и Oncrawl
Что предлагает Oncrawl на панелях мониторинга по умолчанию?
Живой журнал
Эта информационная панель полезна для проверки ключевой информации о том, как боты читают ваши сайты, как только боты посещают сайт и до того, как информация из лог-файлов будет полностью обработана. Чтобы получить максимальную отдачу от этого, я рекомендую часто загружать файлы журнала: вы можете сделать это через FTP, через коннекторы, такие как для Amazon S3, или вы можете сделать это вручную через веб-интерфейс.
Первая диаграмма показывает, как часто ваш сайт читается и каким ботом. В примере, который вы можете увидеть ниже, мы можем сравнить доступ с рабочего стола к мобильному. В данном случае мы отправляли в Oncrawl лог-файлы, отфильтрованные только для робота Googlebot: 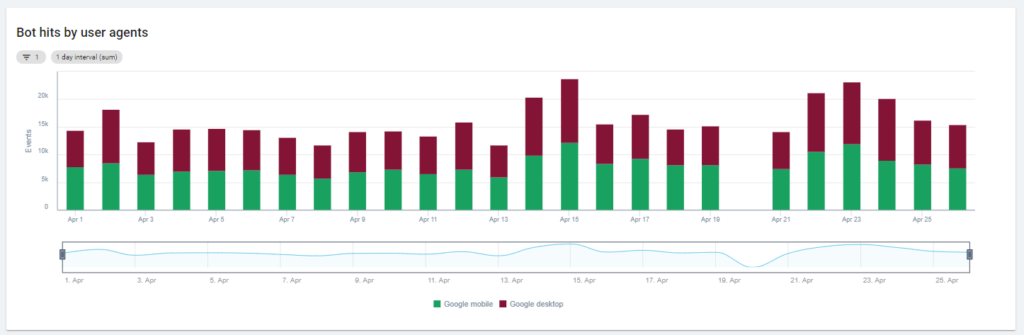
Интересно, что количество мобильных прочтений по-прежнему очень велико: это нормально? Это зависит от… Анализируемый нами сайт все еще находится в индексе «сначала мобильные», но это не полностью адаптивный веб-сайт: это веб-сайт с динамическим обслуживанием (как его называет Google), и Google по-прежнему проверяет обе версии!
Еще одна интересная диаграмма — «Посещения ботами по группам страниц». По умолчанию Oncrawl создает группы на основе URL-адресов. Но мы можем установить группы вручную, чтобы сгруппировать URL-адреса, которые наиболее целесообразно анализировать вместе. 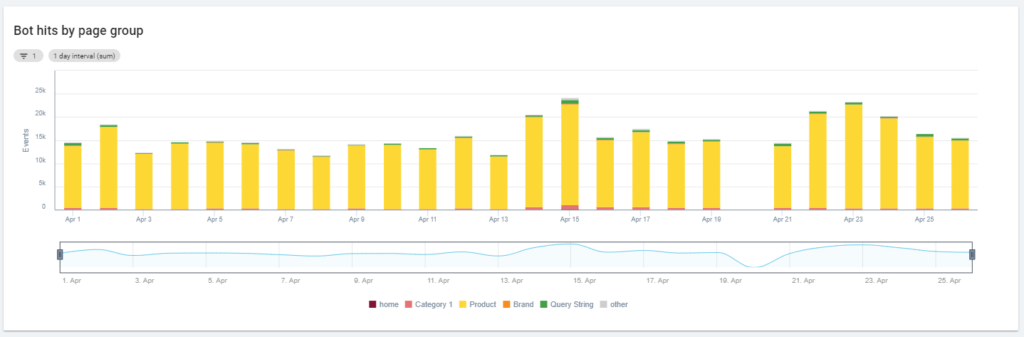
Как видите, желтый выигрывает! Он представляет URL-адреса с путем к продукту, поэтому это нормально, что он оказывает такое сильное влияние, особенно с учетом того, что у нас есть платные торговые кампании Google.
И… да, мы только что подтвердили, что Google использует стандартного робота Googlebot для проверки статуса продукта, связанного с лентой продавца!
Поведение при сканировании
На этой панели отображается информация, аналогичная «Живой журнал», но эта информация была полностью обработана и агрегирована по дням, неделям или месяцам. Здесь вы можете установить период даты (начало/конец), который может вернуться во времени настолько далеко, насколько вы хотите. Есть две новые диаграммы для дальнейшего анализа журнала:
- Поведение при сканировании: чтобы проверить соотношение между просканированными страницами и новыми просканированными страницами.
- Частота сканирования в день
Лучший способ прочитать эти диаграммы — связать результаты с действиями на сайте:
- Вы перемещали страницы?
- Вы обновили некоторые разделы?
- Вы публиковали новый контент?
SEO влияние
Для SEO важно следить за тем, читают ли боты оптимизированные страницы или нет. Как мы уже писали о «страницах-сиротах», важно убедиться, что самые важные/обновляемые страницы читаются ботами, чтобы самая последняя информация была доступна поисковым системам для ранжирования.
Oncrawl использует понятие «Активные страницы» для обозначения страниц, которые получают органический трафик из поисковых систем. Исходя из этой концепции, он показывает некоторые основные числа, такие как:
- SEO-посещения
- SEO-активные страницы
- Коэффициент SEO-активности (доля активных страниц среди всех просканированных страниц)
- Свежий рейтинг (среднее время, которое проходит между первым чтением страницы ботом и первым органическим посещением)
- Активные страницы не просканированы
- Новые активные страницы
- Частота сканирования активных страниц в день
В соответствии с философией Oncrawl, одним щелчком мыши мы можем углубиться в информационное озеро, отфильтрованное по метрике, на которую мы нажали! Например: какие активные страницы не просканированы? Один клик… 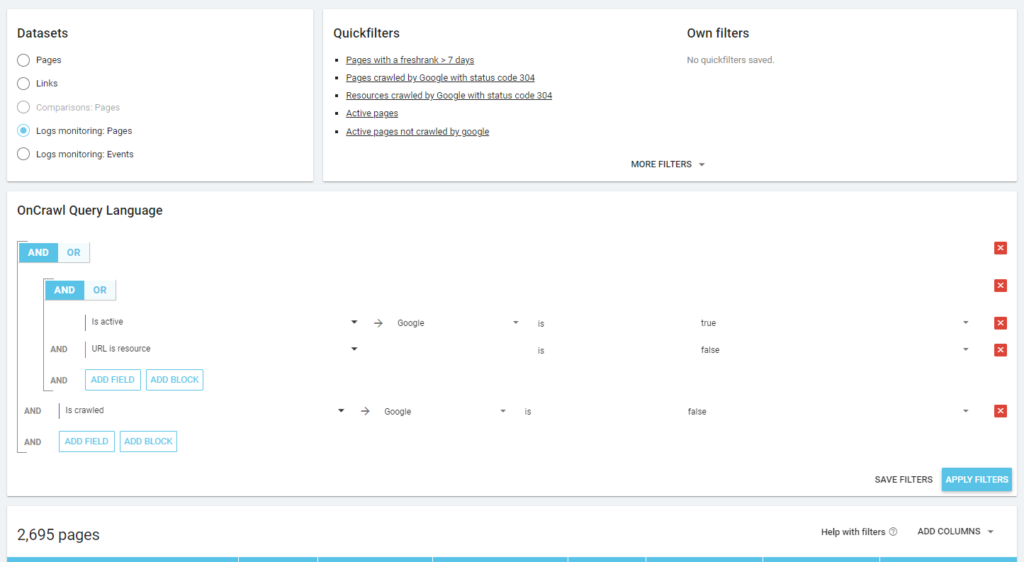
Исследование здравомыслия
Этот последний дашборд позволяет нам проверить качество сканирования бо, или, точнее, насколько хорошо сайт представляется поисковым системам:
- Анализ кода состояния
- Анализ кода состояния по дням
- Анализ кода состояния по группе страниц
- Анализ времени отклика
Для хорошей SEO-работы обязательно:
- уменьшить количество ответов 301 по внутренним ссылкам
- удалить ответы 404/410 из внутренних ссылок
- оптимизировать время отклика, потому что качество сканирования Googlebot напрямую связано со временем отклика: попробуйте сократить время отклика на своем сайте вдвое, и вы увидите (через несколько дней), что количество просканированных страниц удвоится.
Наука об анализе журналов и обозревателе данных Oncrawl
До сих пор мы видели стандартные отчеты Oncrawl и то, как их использовать для получения пользовательской информации посредством сегментации и групп страниц.
Но суть анализа логов заключается в том, чтобы понять, как найти что-то не так. Обычно отправной точкой анализа является проверка пиков и сравнение их с трафиком и с вашими целями:
- самые просматриваемые страницы
- наименее просматриваемые страницы
- наиболее просматриваемые ресурсы (не страницы)
- частота сканирования по типу файла
- влияние кодов состояния 3xx / 4xx
- влияние кодов состояния 5xx
- медленнее сканируемые страницы
- …
Вы хотите пойти глубже? Хорошо… вам нужно добавить данные. И Oncrawl предлагает действительно мощный инструмент, такой как Data Explorer.
Как вы можете видеть на предыдущем снимке экрана (активные страницы не просканированы), вы можете создавать любые нужные вам отчеты на основе вашей системы анализа.
Например:
- Страницы с худшим органическим трафиком и большим количеством обхода ботами
- страницы с лучшим органическим трафиком, которые слишком много сканируются ботами
- более медленные страницы с большим количеством показов в поисковой выдаче
- …
Ниже вы можете увидеть, как я проверил, какие страницы чаще всего просматриваются в зависимости от количества сеансов SEO: 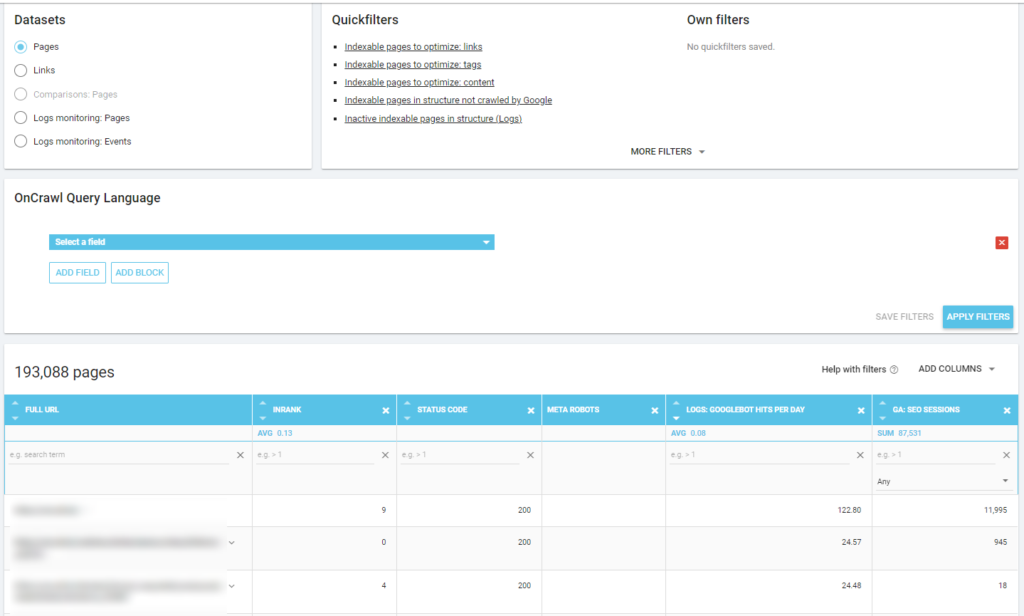
Выводы
Анализ журнала не является строго техническим: чтобы сделать это наилучшим образом, нам нужно объединить технические навыки, навыки SEO и маркетинговые навыки.
Слишком часто анализ исключается из «контрольного списка SEO», потому что у наших клиентов нет доступа к файлам журналов или потому что это может быть дорогостоящим анализом.
Реальность такова, что журналы — это единственные источники, которые действительно позволяют проверить, где боты находятся на наших сайтах, и узнать, как наши серверы реагируют на них.
Такой инструмент, как Oncrawl, может значительно снизить технические требования: просто загрузите файлы журналов и начните их анализировать!