
5 советов по экономии времени с помощью OnCrawl
Опубликовано: 2017-06-21Как воспользоваться расширенными функциями OnCrawl для повышения эффективности ежедневного SEO-мониторинга.
OnCrawl — это мощный инструмент SEO, который помогает отслеживать и оптимизировать видимость веб-сайтов электронной коммерции, онлайн-издателей или приложений для поисковых систем. Инструмент был построен на одном простом принципе: помогите менеджерам по трафику сэкономить время в процессе анализа и в ежедневном управлении SEO-проектами.
Помимо того, что это инструмент аудита на месте, основанный на платформе SaaS, поддерживаемой API, объединяющей все данные веб-сайтов, он также является анализатором журналов, который упрощает извлечение и анализ данных из файлов сервера журналов.
Возможности OnCrawl достаточно широки, но ими нужно овладеть. В этой статье мы поделимся пятью советами по экономии времени при ежедневном использовании нашего поискового робота и анализатора журналов.
1 # Как классифицировать URL-адреса HTTP и HTTPS
Миграция HTTPS — горячая тема в сфере SEO. Чтобы идеально справиться с этим ключевым шагом, важно точно следовать поведению ботов на обоих протоколах.
Опыт показывает, что ботам требуется больше или меньше времени, чтобы полностью переключиться с HTTP на HTTPS. В среднем этот переход занимает несколько недель или месяцев, в зависимости от внешних и внутренних факторов, связанных с качеством сайта и миграцией.
Чтобы точно понять этап перехода, когда ваш краулинговый бюджет сильно влияет на ваш бюджет, разумно отслеживать обращения ботов. Таким образом, необходимо анализировать журналы сервера. Бот, как обычный пользователь, оставляет отметки на каждой странице, ресурсе и запросе, который он делает. Ваши журналы владеют портами, которые доставили эти вызовы. Таким образом, вы можете проверить качество миграции вашего HTTPS-сайта.
Методы настройки выделенного набора групп страниц http и https
На домашней странице расширенного проекта вы можете найти в правом верхнем углу кнопку «Настройки». Затем выберите меню «Настроить группу страниц». Оказавшись здесь, создайте новый «Создать набор групп» и назовите его «HTTP против HTTPS».
Чтобы получить доступ к своим журналам, важно выбрать параметр «Я хочу использовать этот набор на панелях мониторинга журналов и перекрестного анализа» .
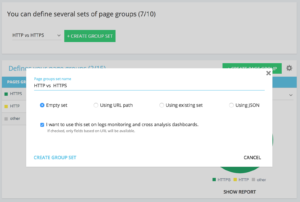
- HTTPS: «Полный URL» / «начать с» / https
- HTTP: «Полный URL» / «не начинать с» / https
После сохранения вы получите доступ к просмотру своей миграции HTTPS (если вы добавили порт запроса в строки журнала. Вы можете ознакомиться с нашим руководством).
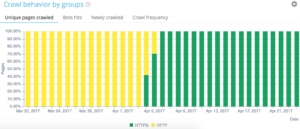
Наши QuickFilters можно найти в обозревателе данных. Они были созданы для облегчения доступа к некоторым важным показателям SEO, таким как ссылки, указывающие на 404, 500 или 301/302, слишком медленные или слишком плохие страницы и т. д.
Вот полный список:
- 404 ошибки
- 5xx ошибок
- Активные страницы
- Активные страницы, не просканированные Google
- Активные страницы с кодом состояния, обнаруженным Google, отличным от 200
- Канонический не соответствует
- Канонический не установлен
- Индексируемые страницы
- Нет индексируемых страниц
- Сиротские активные страницы
- Страницы-сироты
- Страницы, просканированные Google
- Страницы, просканированные Google и OnCrawl
- Страницы в структуре, не просканированные Google
- Страницы, указывающие на ошибки 3xx
- Страницы, указывающие на ошибки 4xx
- Страницы, указывающие на ошибки 5xx
- Страницы с плохим h1
- Страницы с плохим h2
- Страницы с плохим мета-описанием
- Страницы с плохим заголовком
- Страницы с проблемами дублирования HTML
- Страницы с менее чем 10 входящими ссылками
- Редирект 3xx
- Слишком тяжелые страницы
- Слишком медленные страницы
Но иногда эти QuickFilters не отвечают всем вашим бизнес-задачам. В этом случае вы можете начать с одного из них и создать свой «Собственный фильтр», добавив элементы в фильтр и сохранив их, чтобы быстро находить свои фильтры при каждом подключении к инструменту.
Например, из ссылок, указывающих на 4xx, вы можете отфильтровать ссылки с пустым якорем: «Якорь» / «есть» / «» и сохранить этот фильтр. После сохранения его можно изменять столько раз, сколько необходимо.
Теперь у вас есть прямой доступ к этому конкретному «Быстрому фильтру» в списке «Выберите быстрый фильтр» в нижней части «Собственной» части, как показано на снимке экрана ниже.
3 # Как настроить настраиваемые поля, связанные с DataLayer?
Например, вы можете использовать сегментацию связанных типов страниц при определении тегов инструментов аналитики. Этот конкретный код очень интересен для сегментации или сопоставления данных из OnCrawl с вашими внешними данными.
Чтобы вы могли создать «основной столбец» для своего анализа, мы можем извлечь эти фрагменты кода во время сканирования и вернуть их как тип данных вашего проекта.
Параметр «Пользовательские поля» позволяет извлечь любой элемент из страниц исходного кода благодаря регулярному выражению или XPath. Эти языки имеют свои собственные определения и правила. Вы можете найти информацию о XPath здесь и о регулярном выражении здесь.

Вариант использования 1: извлечение данных уровня данных из исходного кода страниц
Код для анализа:

Решение. Используйте «регулярное выражение»: s.prop2=»([^»]+)» / Извлечь: моно-значение / Формат поля: значение

- Найдите строку символов s.prop2="
- Очистить все символы, кроме " (первый символ после данных для извлечения)
- Строка для извлечения может быть найдена перед закрытием «
После обхода в проводнике данных вы найдете в столбцах sProp2, sProp3 или в вашем поле Имя извлеченные данные:

Используйте XPATH
Код для анализа:
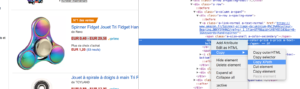
Вам просто нужно скопировать/вставить элемент Xpath, который вы хотите очистить, прямо из анализатора кода Chrome. Будьте осторожны, если код отображается в JavaScript, вам нужно будет настроить собственный проект очистки. Язык Xpath очень мощный, и им может быть сложно манипулировать, поэтому, если вам нужна помощь, позвоните нашим специалистам.
Вариант использования 3: проверка наличия тега аналитики на этапе приема
Используйте регулярное выражение
Код для анализа:

Решение. Используйте «регулярное выражение»: «_setAccount», «UA-364863-11» / Извлечение: проверьте, существуют ли
Вы получите в Data Explorer «true», если строка найдена, «false» — наоборот.
4 # Как визуализировать частоту сканирования Google для каждой части вашего сайта
Краулинговый бюджет лежит в основе любой SEO-задачи. Он тесно связан с концепцией «Важность страницы» и с планированием сканирования Google. Мы знаем, что эти принципы, представленные в патенте Google с 2012 года, позволяют обществу Маунтин-Вью оптимизировать ресурсы, предназначенные для веб-сканирования.
Google не тратит одинаковую энергию на каждую часть вашего сайта. Частота сканирования каждой части вашего веб-сайта дает вам точное представление о важности ваших страниц для Google.
Важные страницы чаще сканируются ботами Google, потому что краулинговый бюджет тесно связан с навыками ранжирования страниц.
Проекты OnCrawl Advanced позволяют просматривать бюджет сканирования в разделах «Мониторинг журнала» / «Поведение при сканировании» / «Поведение при сканировании по группам».
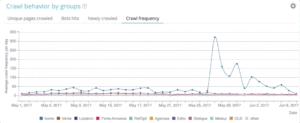
Вы можете видеть, что группа «Домашняя страница» имеет самую высокую частоту сканирования. Это нормально, потому что Google постоянно ищет новые статьи, и они обычно перечислены на главной странице. Идея важности страницы тесно связана с концепцией Google Freshness. Ваша домашняя страница является наиболее важной страницей для определения приоритетов вашего краулингового бюджета Google. Затем оптимизация распространяется на другие страницы по глубине и популярности.
Однако трудно увидеть разницу в частоте. Таким образом, вам нужно щелкнуть группы, которые вы хотите удалить (щелкнув легенду), и увидеть, как отображаются данные.
5# Как проверить коды состояния из списка URL-адресов после миграции
Если вы хотите быстро проверить коды состояния из набора URL-адресов, можно изменить настройки нового обхода:
- Добавьте все начальные URL-адреса (кнопка «Добавить начальный URL-адрес»)
- Определить максимальную глубину до 1
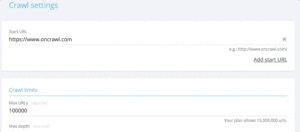
Это пользовательское сканирование вернет качественные данные об этом наборе URL-адресов.
Вы сможете проверить, правильно ли настроены перенаправления, или проследить за изменением кодов состояния с течением времени. Подумайте о преимуществах регулярного сканирования, вы сможете автоматически следовать старым URL-адресам.
Почему бы вам не создать автоматизированную информационную панель с помощью нашего API и не создать автоматизированный мониторинг тестирования по этим аспектам.
Мы надеемся, что эти лайфхаки помогут вам повысить эффективность использования OnCrawl. У нас еще есть много продвинутых трюков, чтобы показать вам. Пожалуйста, поделитесь с нами в Твиттере, например, своими #oncrawlhacks, мы рады, что наши пользователи могут получать такое же удовольствие, как и мы, с нашим инструментом.