
5 веских причин объединить данные сканирования и журналов
Опубликовано: 2018-03-27Понимание данных файлов журналов в SEO все больше растет в сообществе SEO. Лог-файлы на самом деле являются единственным качественным представлением того, что происходит на веб-сайте. Но мы все еще должны быть в состоянии заставить их говорить эффективно.
Точные посещения SEO и поведение ботов присутствуют в ваших файлах журнала. С другой стороны, данные из вашего отчета о сканировании могут дать хорошее представление о вашей локальной производительности. Вам необходимо объединить файлы журналов и данные сканирования, чтобы выделить новые измерения при анализе вашего веб-сайта.
Эта статья покажет вам пять отличных способов объединения данных сканирования и файлов журнала. Очевидно, что вы можете использовать гораздо больше.
1# Обнаружение потерянных страниц и оптимизация краулингового бюджета
Что такое потерянная страница? Если URL-адрес появляется в журналах, но не входит в архитектуру сайта, этот URL-адрес называется потерянным.
У Google колоссальный индекс! Со временем он сохранит все URL-адреса, которые он уже обнаружил на вашем веб-сайте, даже если они больше не присутствуют в архитектуре (изменение слагов, удаленные страницы, полная миграция сайта, внешние ссылки с ошибкой или преобразованы). Очевидно, что разрешение Google сканировать эти так называемые потерянные страницы может повлиять на оптимизацию вашего краулингового бюджета. Если устаревшие URL-адреса потребляют ваш краулинговый бюджет, это предотвращает более регулярное сканирование других URL-адресов и обязательно повлияет на вашу поисковую оптимизацию.
При сканировании вашего веб-сайта OnCrawl просматривает все ссылки, чтобы детально изучить всю архитектуру вашего сайта. С другой стороны, во время мониторинга файлов журналов OnCrawl собирает данные о посещениях ботов Google и посещениях SEO.
Разница между URL-адресами, известными Google, и теми, которые связаны в архитектуре, может быть очень важной. SEO-оптимизация, направленная на исправление забытых или неработающих ссылок и уменьшение числа потерянных страниц, имеет важное значение.
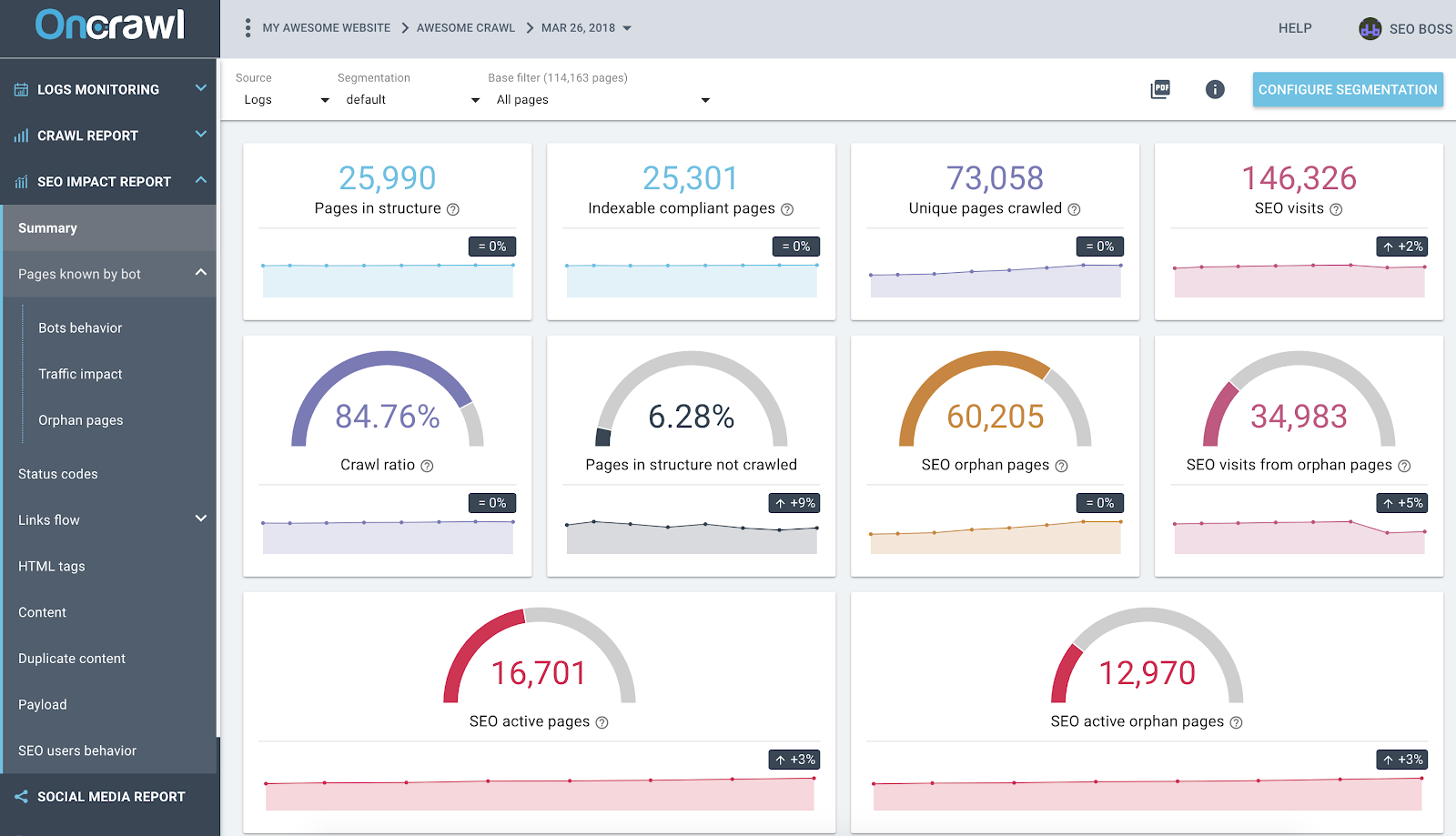
Отчет OnCrawl SEO Impact на основе журналов и перекрестного анализа данных сканирования
На приведенном выше снимке экрана показано современное состояние ваших журналов и данных сканирования. Вы можете быстро заметить, что:
- 25 990 страниц в структуре — найдено нашим краулером и с учетом всех ссылок, по которым он переходил на сайте;
- Google сканирует 73 058 страниц — это в 3 раза больше, чем в структуре;
- Коэффициент сканирования 84% — (страницы, просканированные OnCrawl + активные страницы из журналов + страницы, просканированные Google) / страницы, просканированные Google;
- Более 6% внутренних страниц не сканируются — просто нажмите на черное ведро, чтобы увидеть список этих страниц в проводнике данных;
- 60 тыс. страниц-сирот — дельта между страницами в структуре и страницами, просканированными Google;
- 34 000 SEO-посещений этих страниц — похоже, проблема с внутренними ссылками!
Передовой опыт: OnCrawl дает вам преимущество в изучении данных, стоящих за каждым графиком или показателем, просто щелкнув по ним. Таким образом, вы получите загружаемый список URL-адресов, которые напрямую отфильтрованы по области, которую вы изучаете.
2# Узнайте, какие URL потребляют больше всего (или меньше всего) краулингового бюджета
Все события, связанные с посещениями ботов Google, известны платформе данных OnCrawl. Это позволяет вам знать — для каждого URL — все данные, собранные по времени.
В обозревателе данных вы можете добавить для каждого URL-адреса столбцы обращений ботов (за период 45 дней) и обращений по дням и по ботам, что является средним значением за день. Эта информация полезна для оценки расходования краулингового бюджета Google. Вы часто обнаружите, что этот бюджет не является одинаковым на всех сайтах.
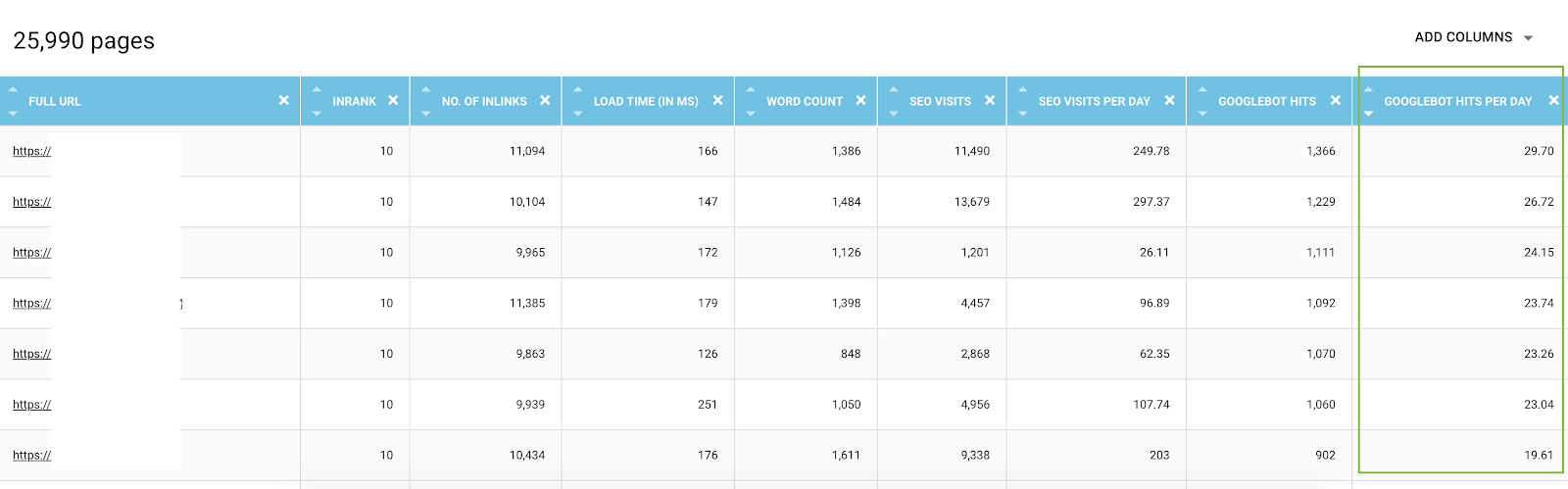
Список всех URL-адресов из обозревателя данных с показателями сканирования и отфильтрованными по обращениям ботов по дням
На самом деле, некоторые факторы могут инициировать или уменьшить краулинговый бюджет. Затем мы составили список наиболее важных показателей в этой статье о важности страницы Google. Глубина, количество ссылок, которые ведут на страницу, количество ключевых слов, скорость страницы, InRank (внутренняя популярность) влияют на сканирование ботов. Вы узнаете больше в следующем параграфе.
3 # Знайте свои лучшие SEO-страницы, свои худшие SEO-страницы и определяйте факторы успеха страниц.
При использовании обозревателя данных у вас есть доступ к ключевым показателям страниц, но сравнивать сотни строк и показателей вместе может быть сложно. Использование столбцов для сегментации обращений ботов по дням и посещений SEO по дням — ваш союзник в анализе данных.
- Загрузите файлы CS — Bot Hits by Day и CS — SEO посещения по дням в формате JSON;
- Добавьте их как новые сегменты.
Фактически, вы можете создать сегментацию на основе этих двух значений, полученных в результате анализа журнала, чтобы иметь первое распределение ваших страниц по группам. Но вы также можете фильтровать каждую группу этих сегментов, чтобы быстро определить — в каждом отчете OnCrawl — какие страницы не достигают ожидаемых значений.
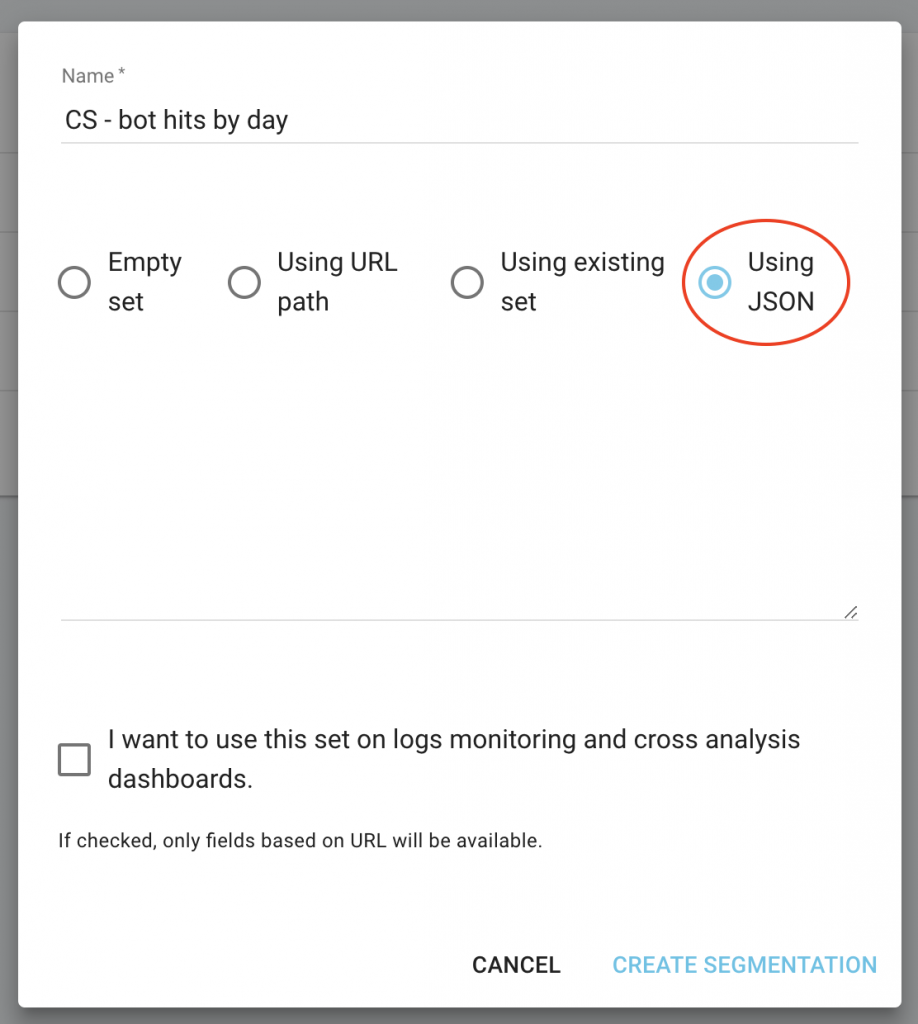
На главной странице вашего проекта нажмите кнопку «Настроить сегментацию».

Затем создайте новую сегментацию

Используйте импорт JSON, выбрав емкость «Используя JSON», и скопируйте/вставьте загруженные файлы.

Теперь вы можете переключать сегменты с помощью верхнего меню в каждом отчете.
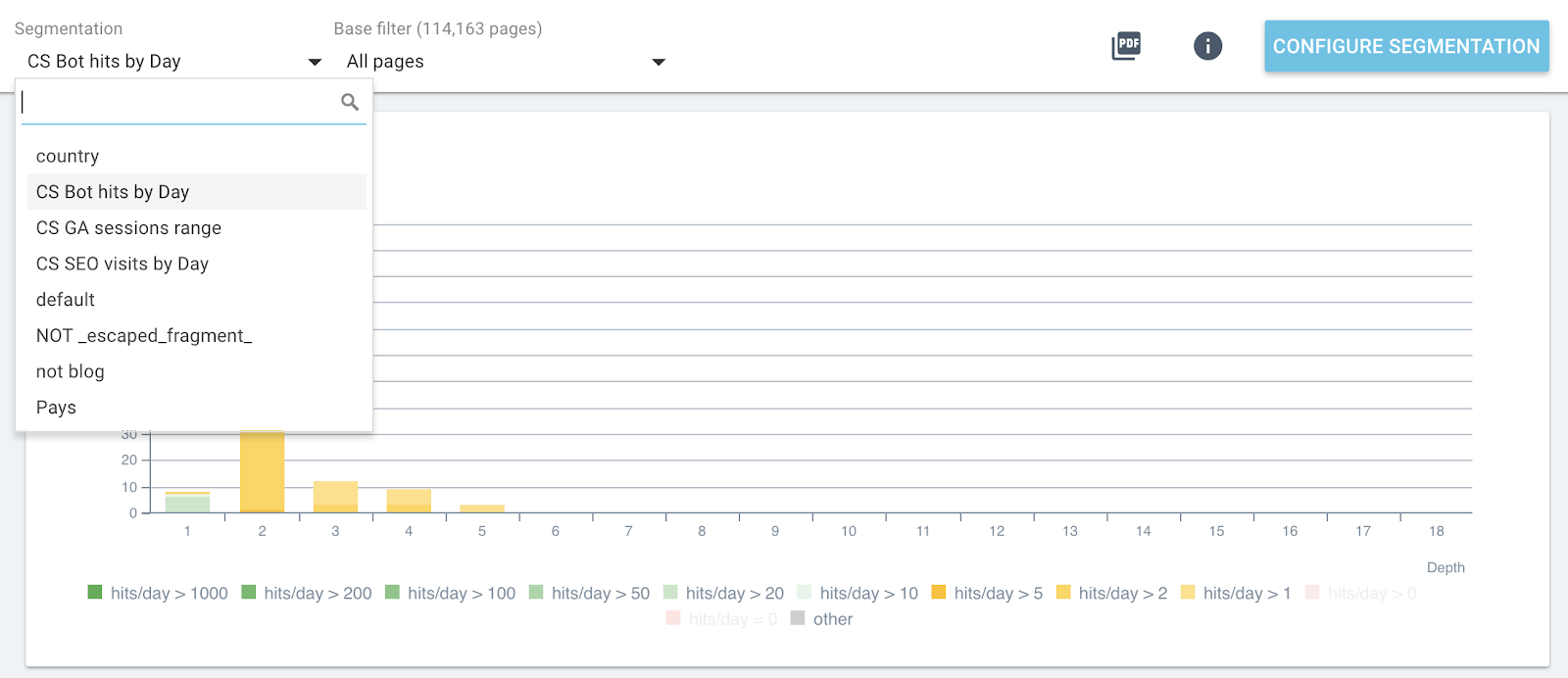
Изменение сегментации в реальном времени во всех отчетах OnCrawl
Это даст вам на каждом графике влияние метрик, которые вы анализируете, и связанных со страницами, сгруппированными по посещениям ботов или посещениям SEO.
В следующем примере мы использовали эти сегменты, чтобы понять влияние внутренней популярности InRank на основе силы ссылок по глубине. Более того, обращения ботов и посещения SEO коррелируют на одной оси.
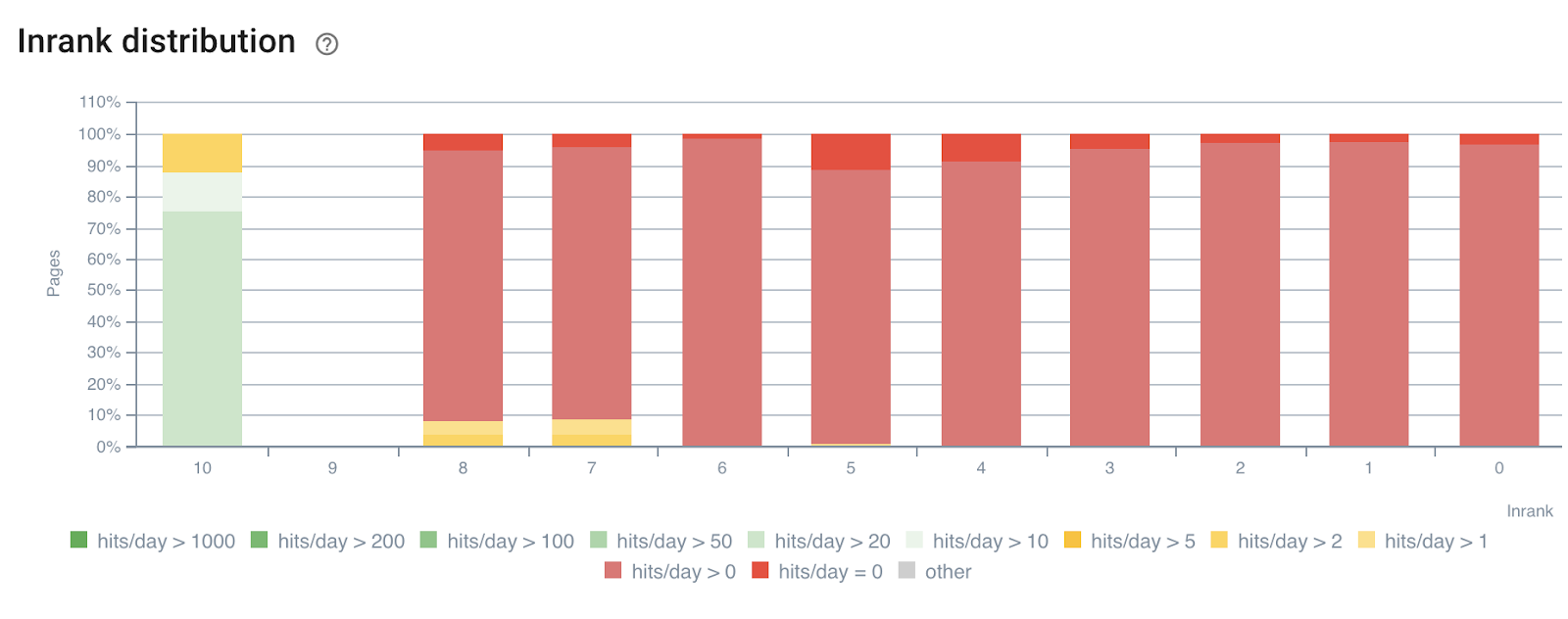
Распределение InRank по посещениям ботов по дням
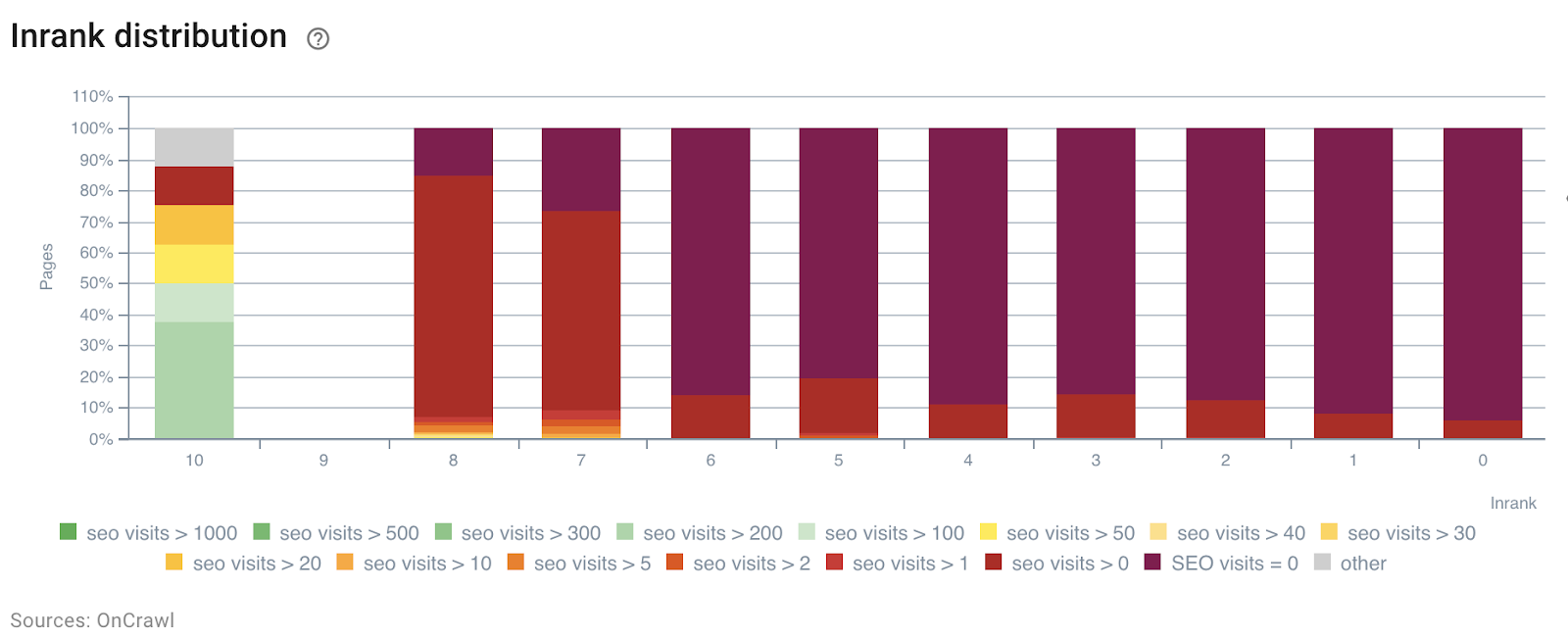
Распределение InRank по SEO-посещениям по дням
Глубина (количество кликов с главной страницы) явно влияет как на количество обращений ботов, так и на посещения SEO.
Точно так же каждую группу страниц можно выбрать независимо, чтобы выделить данные с наиболее популярных или посещаемых страниц.
Это позволяет быстро определить страницы, которые могли бы работать лучше, если бы они были оптимизированы, например, количество слов на странице, глубину или количество входящих ссылок.
Просто выберите правильную сегментацию и группу страниц, которые вы хотите проанализировать.
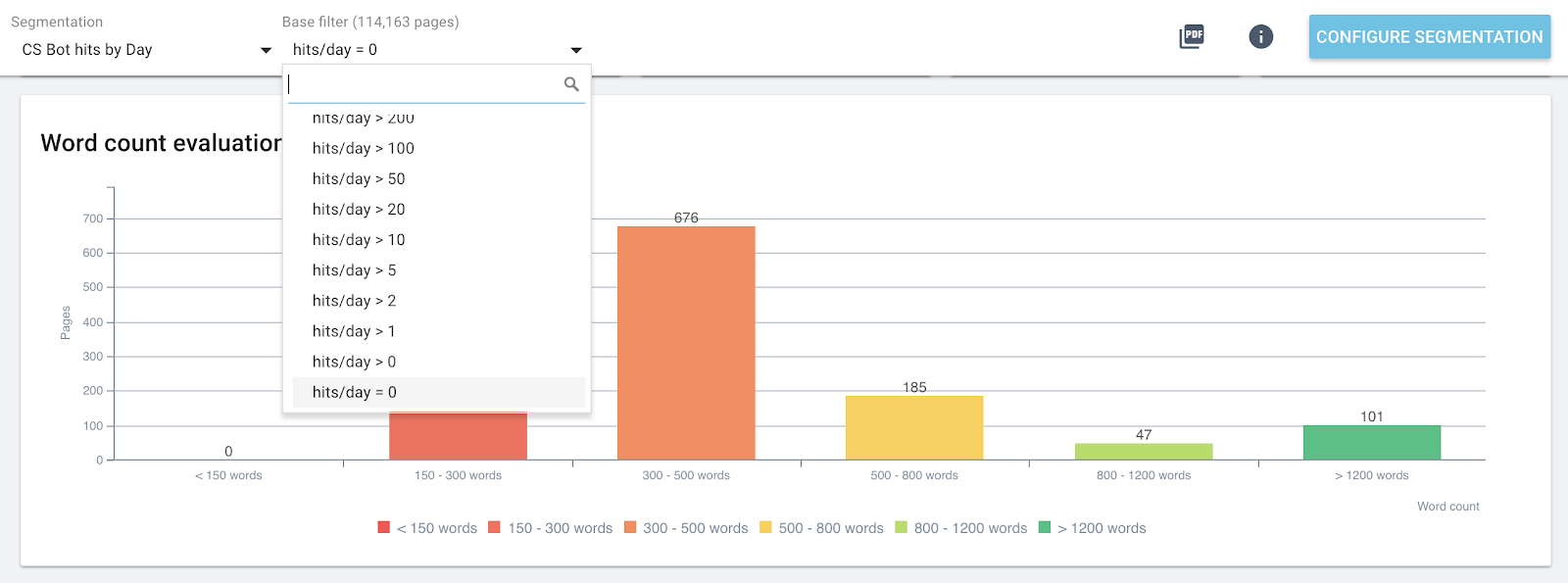
Распределение слов на странице для группы, содержащей 0 ботов, посещенных за день
4# Определите пороговые значения, чтобы максимизировать краулинговый бюджет и SEO-посещения.
Чтобы пойти дальше, отчет о влиянии SEO — перекрестный анализ данных сканирования и журналов — может определять пороговые значения, которые помогают увеличить количество посещений SEO, частоту сканирования или обнаружение страниц.
Влияние количества слов на частоту сканирования
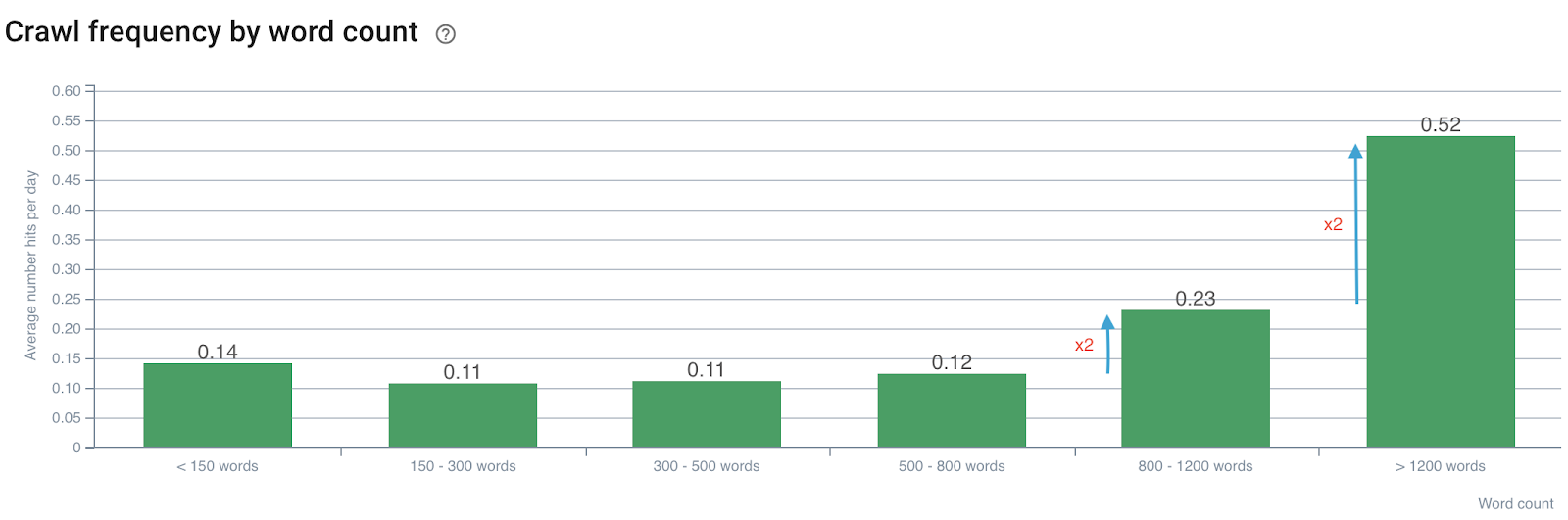
Частота сканирования по количеству слов
Отметим, что частота сканирования удваивается, когда количество слов превышает 800. Затем она также удваивается, когда количество слов на странице превышает 1200 слов.
Влияние количества внутренних ссылок на коэффициент сканирования
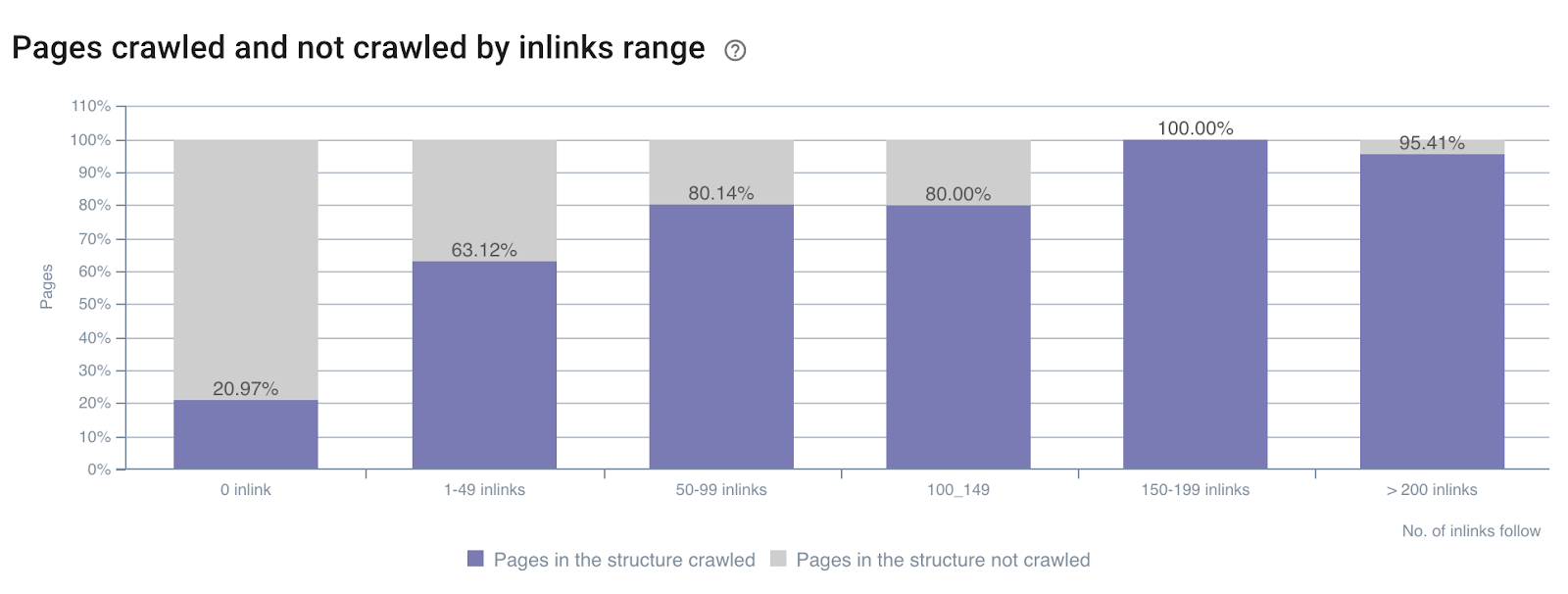
Коэффициент сканирования по количеству внутренних ссылок по всему сайту
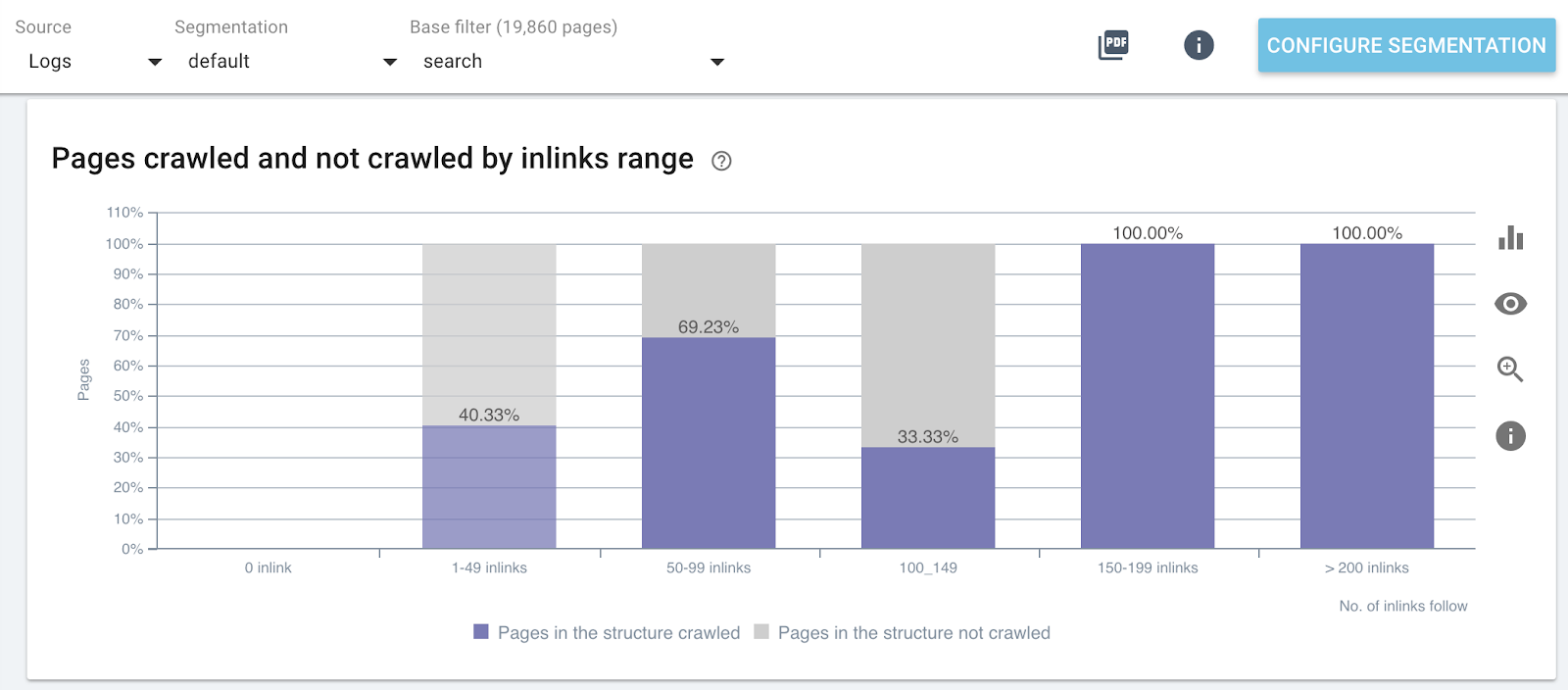
Коэффициент сканирования по количеству внутренних ссылок на определенные части веб-сайта (страницы поиска)
Влияние глубины на активность страниц
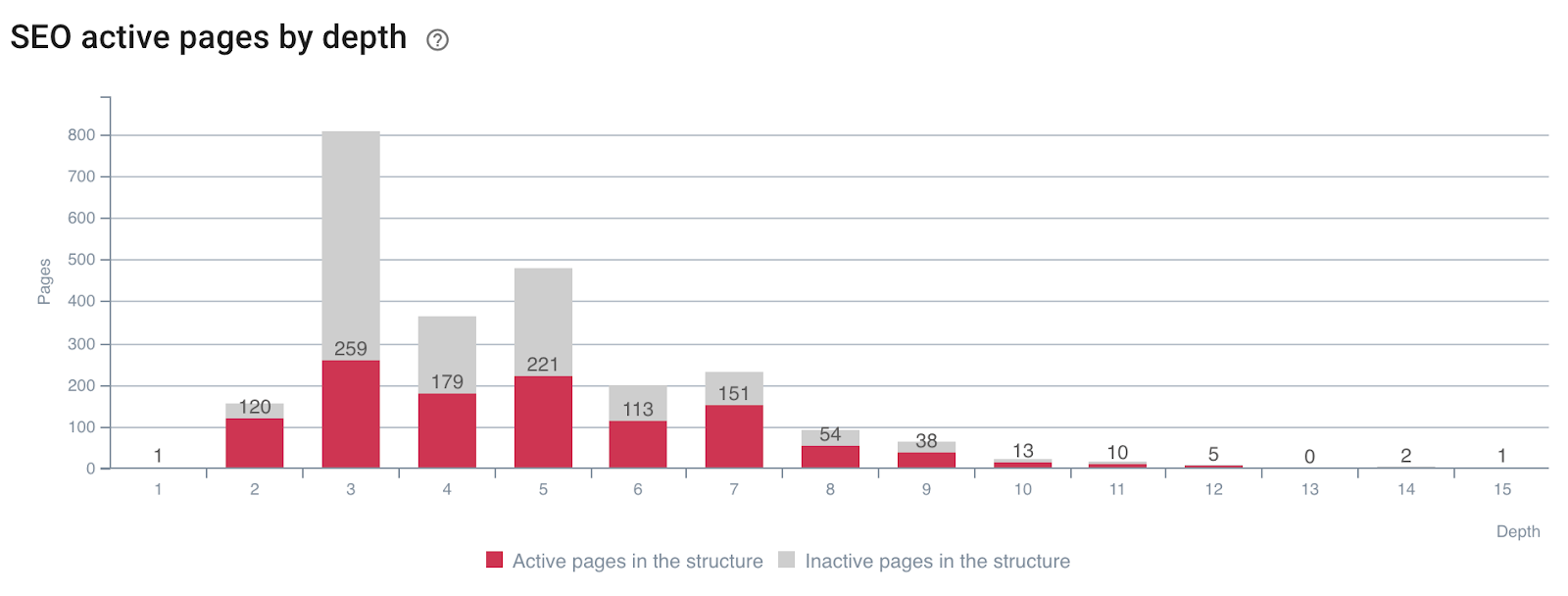
Страницы, генерирующие SEO-посещения (или нет) по глубине
Вы можете видеть, что наличие правильных показателей сайта во время сканирования и данных журналов пересечения позволяет вам сразу определить, какие SEO-оптимизации необходимы для управления сканированием Google и улучшения ваших SEO-посещений.
5. Определите, как факторы ранжирования SEO влияют на частоту сканирования.
Представьте, если бы вы могли знать, на какие значения ориентироваться, чтобы максимизировать SEO? Именно для этого и создан перекрестный анализ данных! Это позволяет вам точно определить для каждой метрики, при каком пороге частота сканирования, скорость сканирования или активность максимальны.
Мы видели выше — в примере о количестве слов на странице и частоте обхода — что существуют триггерные значения частоты обхода. Эти пробелы необходимо анализировать и сравнивать для каждого типа страниц, потому что мы ищем всплески в поведении ботов или посещениях SEO.
Как те, что представлены ниже:
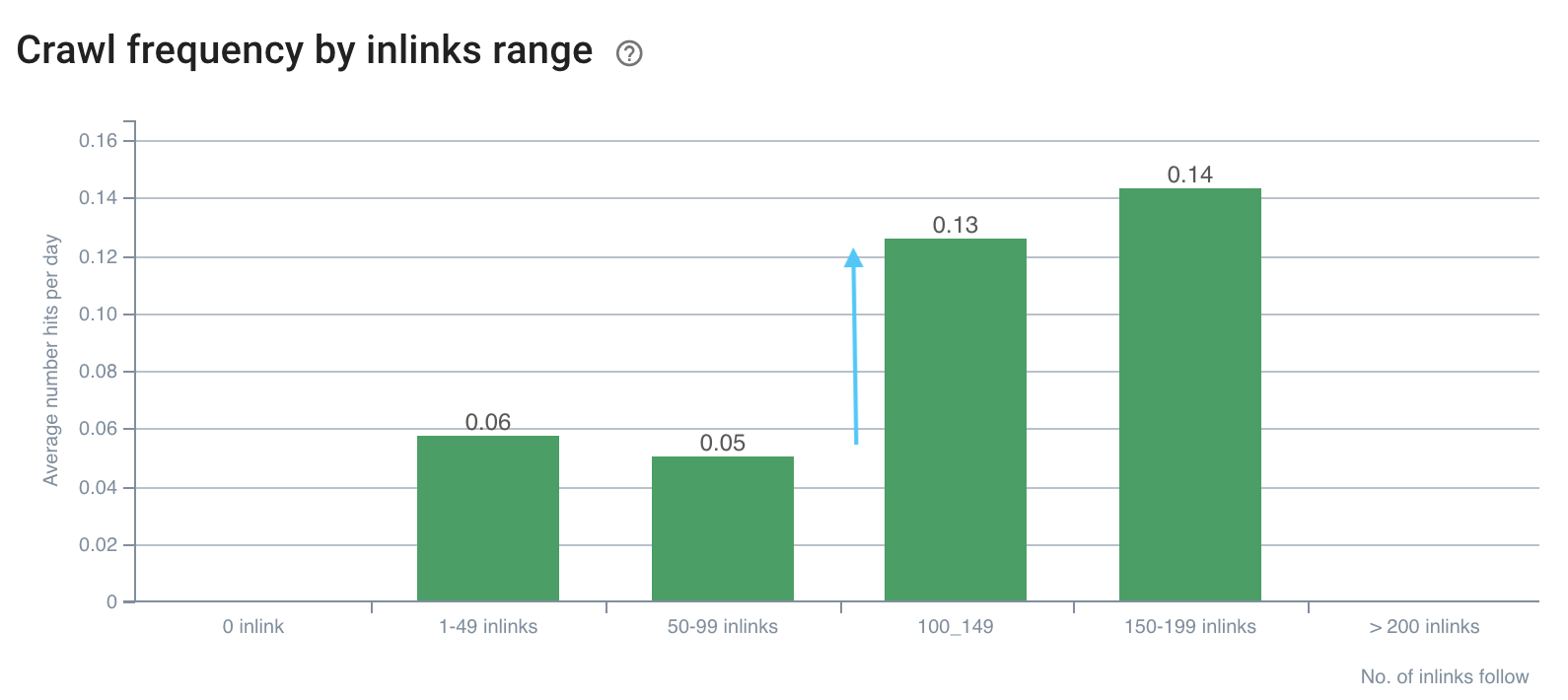
Частота сканирования отстает от 100+ внутренних ссылок.
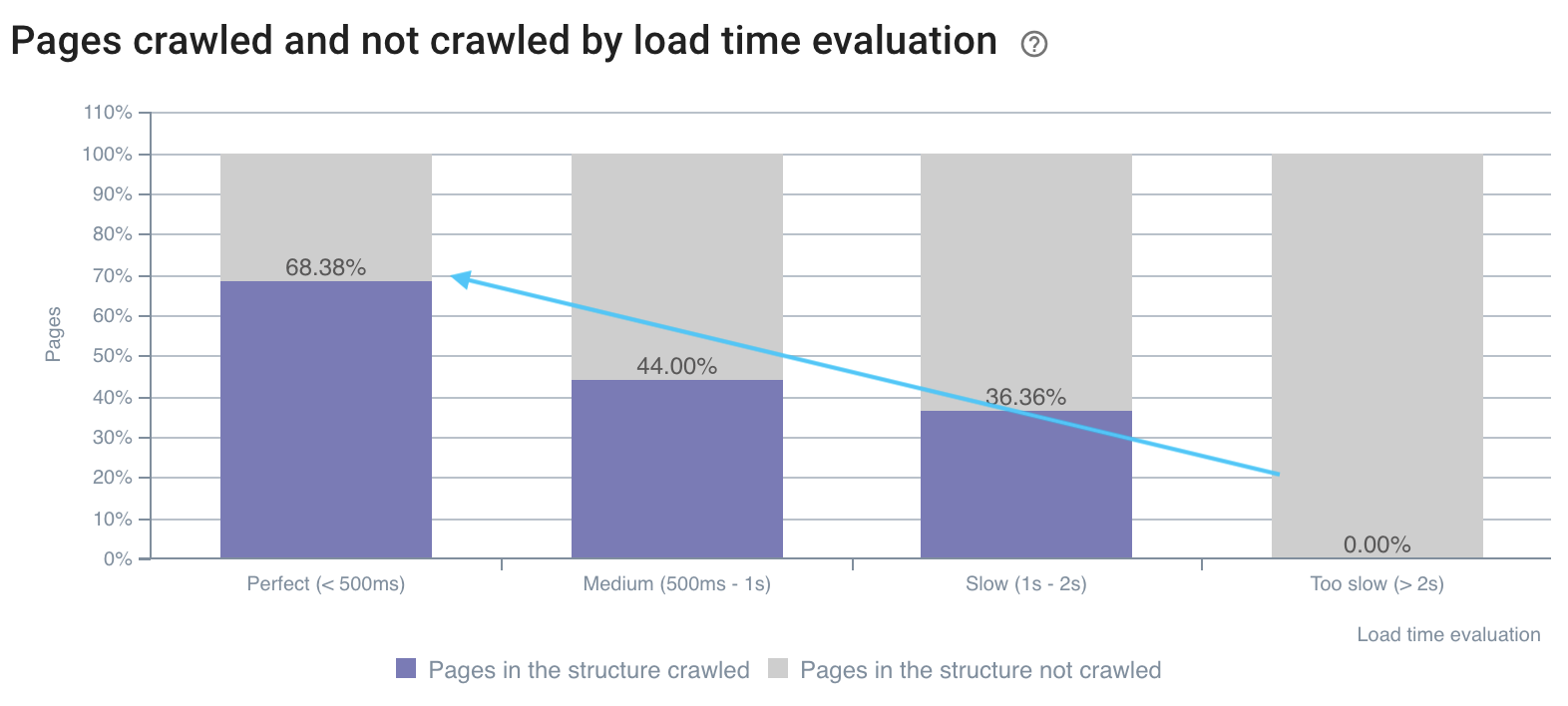
Скорость сканирования лучше на быстрых страницах
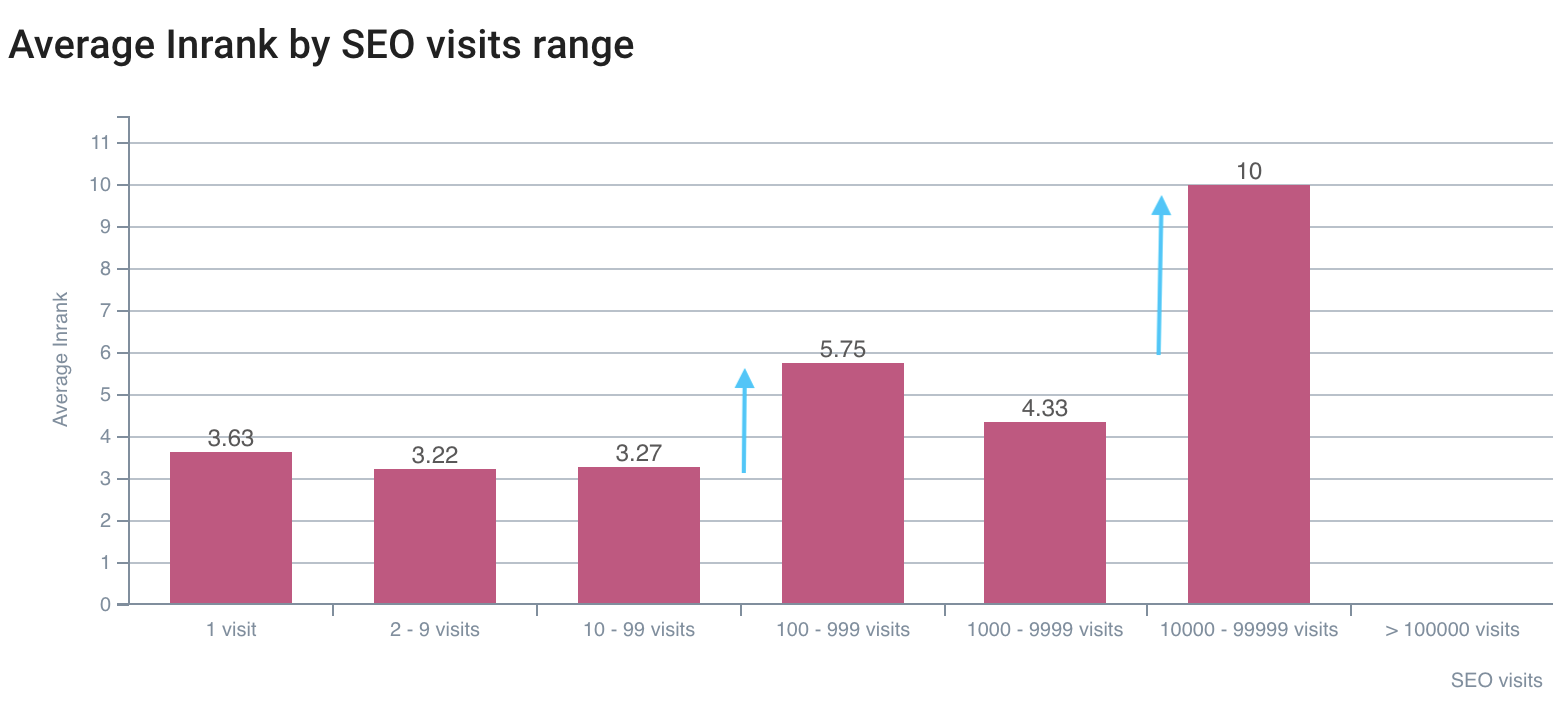
Первый разрыв по SEO-посещениям — на InRank 5,75, лучший — на InRank 10 (домашняя страница)
Объединение данных сканирования и журналов позволяет вам открыть черный ящик Google и точно определить влияние ваших показателей на сканирование и посещения ботами. Внедряя свои оптимизации на основе этого анализа, вы можете улучшить SEO во время каждого из ваших выпусков. Это расширенное использование долговечно, поскольку вы можете обнаруживать новые значения, которые необходимо достичь при каждом анализе перекрестных данных.
Какими еще приемами с перекрестным анализом данных вы хотели бы поделиться?