
[Webinar Digest] SEO în orbită: noi perspective asupra conținutului duplicat
Publicat: 2019-11-20Webinarul Noi perspective asupra conținutului duplicat este episodul final din seria SEO in Orbit și a fost difuzat pe 24 iunie 2019. În acest episod, alăturați-vă ambasadorului OnCrawl Omi Sido și Alexis Sanders în timp ce explorează problema conținutului duplicat. Aceștia abordează întrebări precum: Cum influențează factorii de clasare și tehnologiile de căutare în evoluție modul în care gestionăm conținutul duplicat? Și: Ce ne rezervă viitorul pentru conținut similar de pe web?
SEO in Orbit este prima serie de seminarii web care trimite SEO în spațiu. De-a lungul seriei, am discutat despre prezentul și viitorul SEO tehnic cu unii dintre cei mai buni specialiști SEO și am trimis sfaturile lor de top în spațiu pe 27 iunie 2019.
Urmărește reluarea aici:
Vă prezentăm pe Alexis Sanders
Alexis Sanders lucrează ca manager tehnic de cont SEO la Merkle. Echipa tehnică SEO asigură acuratețea, fezabilitatea și scalabilitatea recomandărilor tehnice ale agenției pe toate verticalele. Ea este colaboratoare la blogul Moz și creatoarea provocării TechnicalSEO.expert și a podcastului SEO în laborator.
Acest episod a fost găzduit de Omi Sido. Omi este un vorbitor internațional experimentat și este cunoscut în industrie pentru umorul și capacitatea sa de a oferi informații utile pe care publicul le poate începe imediat să le folosească. De la consultanță SEO cu unele dintre cele mai mari companii de telecomunicații și turism din lume până la gestionarea SEO internă la HostelWorld și Daily Mail, lui Omi îi place să se scufunde în date complexe și să găsească punctele luminoase. În prezent, Omi este senior SEO tehnic la Canon Europa și ambasador OnCrawl.
Ce este conținutul duplicat?
Omi oferă următoarea definiție a conținutului duplicat:
Conținut duplicat care este similar sau aproape similar cu conținutul care se află pe o adresă URL diferită pe același (sau pe un alt) site web.
Mitul pedepsei pentru conținut duplicat
Nu există nicio penalizare pentru conținut duplicat.
Aceasta este o problemă de performanță. Nu dorim ca un bot să se uite la două adrese URL specifice și să creadă că sunt două conținuturi diferite care pot fi clasate unul lângă celălalt.
Alexis compară înțelegerea site-ului dvs. de către un robot cu imaginile lui Joey din 10 lucruri pe care le urăsc despre tine: este imposibil ca un robot să găsească o diferență materială între cele două versiuni.

Vrei să eviți să ai două exact aceleași lucruri care trebuie să concureze unul cu celălalt într-o situație de clasare în motoarele de căutare. În schimb, doriți să aveți o experiență unică, consolidată, care să se poată clasa și să performeze în motoarele de căutare.
Diferența dintre ceea ce văd utilizatorii și roboții
Un utilizator poate vedea o singură adresă URL convingătoare, dar un bot poate vedea în continuare mai multe versiuni care îi arată în esență la fel.
– Efect asupra bugetului de accesare cu crawlere pentru site-uri foarte mari
Pentru site-urile care sunt foarte mari, cum ar fi Zillow sau Walmart, bugetul de accesare cu crawlere poate varia în funcție de pagini.
După cum a discutat Alexis într-un articol din 2018 bazat pe o prezentare a lui Frederic Dubut la SMX East, bugetele sunt stabilite la diferite niveluri – la niveluri de subdomeniu, la diferite niveluri de server. Motoarele de căutare, fie Google sau Bing, vor să fie crawlere politicoase; nu doresc să încetinească performanța pentru utilizatorii reali. Ori de câte ori simt o schimbare în performanță, se vor retrage. Acest lucru se poate întâmpla la diferite niveluri, nu doar la nivelul site-ului.
Dacă aveți un site masiv, doriți să vă asigurați că oferiți cea mai consolidată experiență care este relevantă pentru utilizatorii dvs.
Conținutul duplicat este un conținut sau o problemă tehnică?
În ciuda cuvântului „conținut” în „conținut duplicat”, este parțial o problemă tehnică.
– Surse de duplicare – [07:50]
Există mulți factori care pot provoca dublarea. Chiar și o listă parțială poate părea să dureze pentru totdeauna:
- Pagini repetitive
- Site-uri de montaj
- URL-uri HTTP vs HTTPS
- Subdomenii diferite
- Cazuri diferite
- Extensii de fișiere diferite
- Bara oblica de la urma
- Pagini de index
- Parametrii URL
- Fațete
- Sortează
- Versiune pentru imprimantă
- Pagina de intrare
- Inventar
- Conținut sindicalizat
- Comunicate PR
- Republicarea conținutului
- Conținut plagiat
- Conținut localizat
- Conținut subțire
- Numai-imagini
- Căutare internă pe site
- Site mobil separat
- Conținut neunic
- …
– Distribuția problemelor între SEO tehnic și conținut
De fapt, aceste surse de conținut duplicat pot fi împărțite în surse tehnice și de dezvoltare și surse bazate pe conținut, iar unele care se încadrează într-o zonă de suprapunere între cele două.
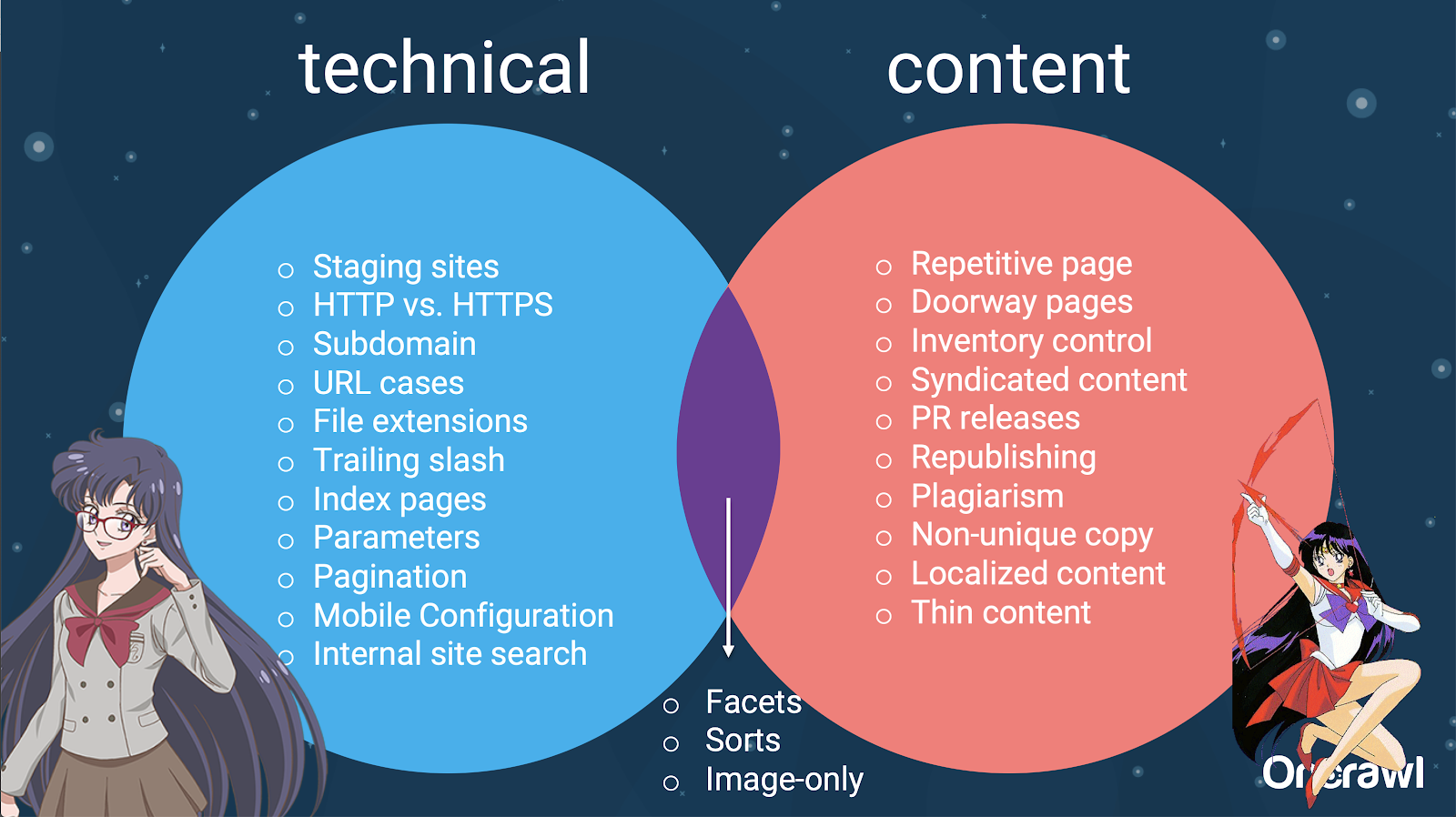
Acest lucru face ca conținutul duplicat să fie o problemă între echipe, ceea ce face parte din ceea ce îl face atât de interesant.
Cum să găsiți conținut duplicat
Majoritatea conținutului duplicat este neintenționat. Pentru Omi, acest lucru indică faptul că există o responsabilitate comună între echipele de conținut și cele tehnice pentru găsirea și remedierea conținutului duplicat.
– Instrumentul preferat al lui Omi: Gramatical
Grammarly este instrumentul preferat al lui Omi pentru a găsi conținut duplicat – și nici măcar nu este un instrument SEO. El folosește verificatorul de plagiat. El îi cere editorului de conținut să verifice dacă o nouă bucată de conținut a fost deja publicată în altă parte.
– Volumul conținutului duplicat neintenționat
Problema conținutului duplicat neintenționat este una cu care inginerii sunt foarte familiarizați. Într-o carte numită Introduction to Information Retrieval (2008), care este în mod clar depășită, ei au estimat că aproximativ 40% din web la acea vreme era duplicat.

– Strategii de prioritizare pentru tratarea conținutului duplicat
Pentru a trata conținutul duplicat, ar trebui să:
- Începeți prin a vă cunoaște călătoria utilizatorului, ceea ce vă va ajuta să înțelegeți unde se potrivește fiecare conținut. Acest lucru poate fi extrem de greu de realizat, mai ales când site-urile web au fost create acum 20 de ani, când nu știam cât de mari vor deveni sau cum se vor extinde. Cunoașterea unde se află utilizatorul dvs. în orice moment al călătoriei sale vă va ajuta să stabiliți priorități în unii dintre pașii următori.
- Veți avea nevoie de o ierarhie care să funcționeze, pentru a oferi un loc pentru fiecare tip de conținut. Înțelegerea arhitecturii dvs. informaționale este într-adevăr la vârf în pașii de a trata conținutul duplicat.
- Prioritizează conținutul duplicat care afectează performanța. Lista parțială a surselor de mai sus este mult prea lungă pentru a fi ceva pe care îl puteți ataca în mod realist dintr-o dată.
- Ocupați-vă de duplicarea 100%.
- Semnalează conținut duplicat
- Alegeți strategic cum să gestionați duplicarea: consolidați, creați, ștergeți, optimizați
- Ocupați-vă de conținutul furat

– Instrumente: Utilizarea segmentării în OnCrawl
Lui Alexis îi place foarte mult capacitatea de a vă segmenta site-ul web în OnCrawl, ceea ce vă permite să vă scufundați în lucruri care sunt semnificative pentru dvs.
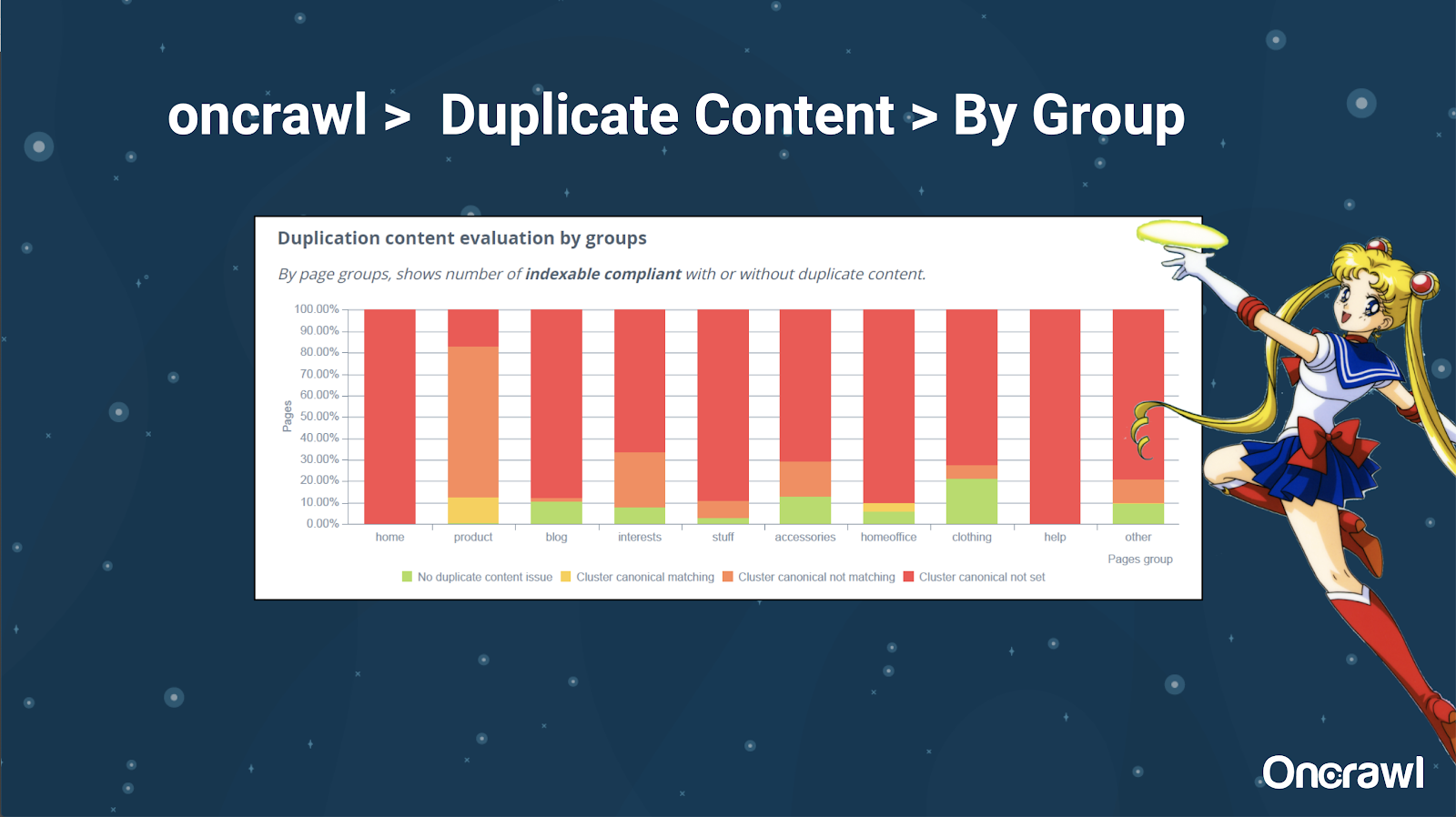
Tipuri diferite de pagini au cantități diferite de duplicare; aceasta vă permite să obțineți o vedere a secțiunilor care au cele mai multe probleme. În exemplul de mai sus, site-ul necesită multă atenție.
– Instrumente: căutare Google și GSC
De asemenea, puteți verifica dacă există conținut duplicat folosind motorul de căutare însuși. În Google puteți:
- Folosiți ghilimele directe
- Utilizați site: căutări
- Folosind operatori suplimentari precum inurl:, intitle: sau filetype:

Google Search Console a adăugat, de asemenea, un raport de conținut duplicat, care este foarte util pentru a identifica ceea ce Google consideră că este conținut duplicat din partea lor.
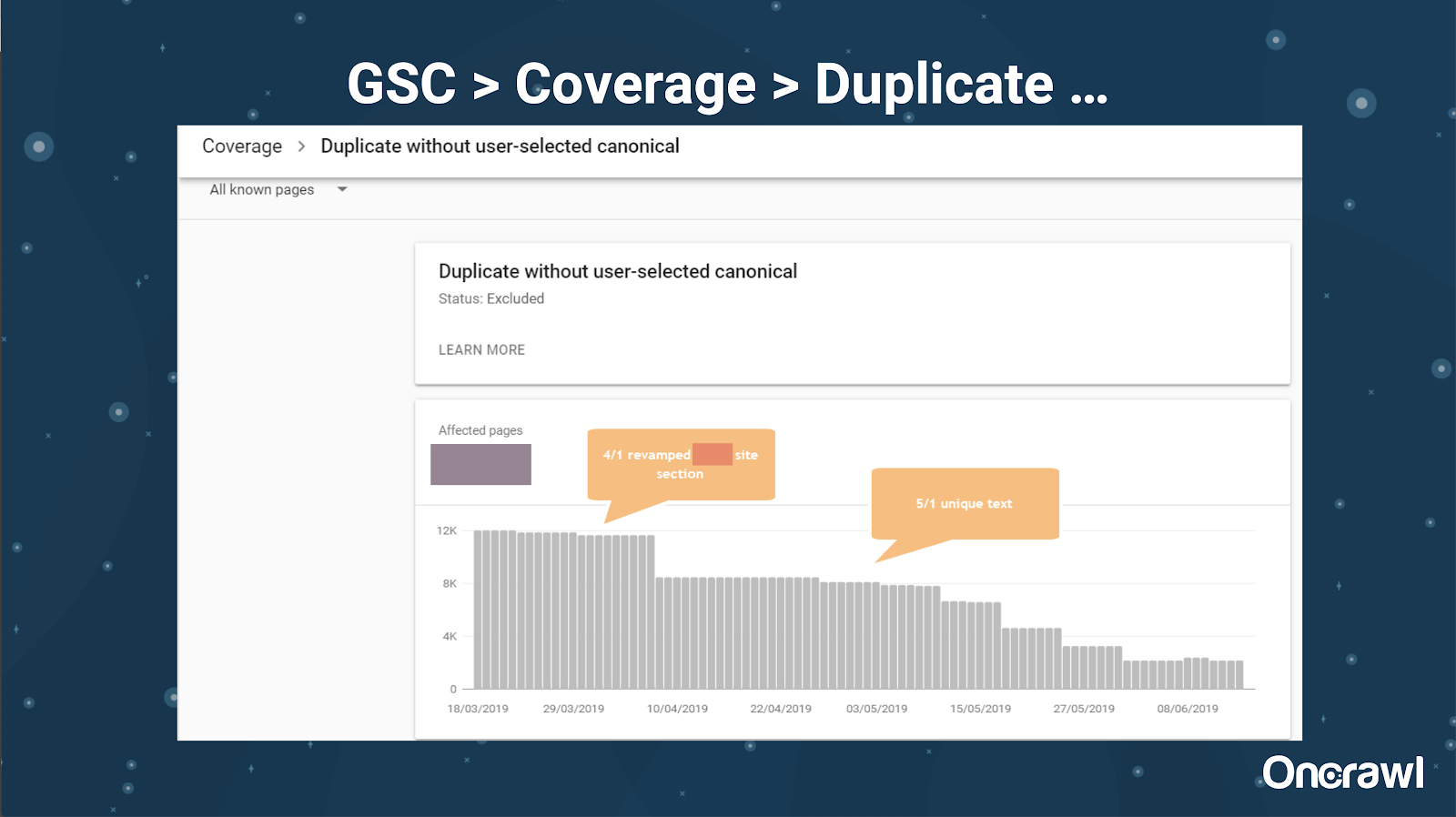
– Instrumente: instrumente de plagiat
La fel ca Omi, Alexis folosește și diferite instrumente de plagiat:
Quetext
Noplag
PaperRater
Gramatical
CopyScape
Vrei să te asiguri că conținutul tău nu este doar original, ci și din perspectiva unui bot, că nu este perceput ca extras dintr-o altă sursă.
Acestea vă pot ajuta, de asemenea, să găsiți segmente dintr-un articol care ar putea fi similare cu conținutul din altă parte de pe internet.
Alexis iubește cum avem aceste instrumente care ne permit să fim „empatici față de roboții motoarelor de căutare”, deoarece niciunul dintre noi nu este roboți. Când instrumentele ne dau semnale că conținutul este prea asemănător, chiar dacă știm că există o diferență, acesta este un semn bun că există ceva în care să cercetăm.

– Instrumente: instrumente pentru densitatea cuvintelor cheie
Două exemple de instrumente de densitate a cuvintelor cheie pe care Alexis le folosește sunt:
TagCrowd
SEObook
Probleme depind de tipul de site
Rezolvarea conținutului duplicat depinde într-adevăr de tipul de conținut pe care îl publicați și de tipul de problemă cu care vă confruntați. Blogurile nu se confruntă cu aceleași cazuri de conținut duplicat ca și site-urile de comerț electronic, de exemplu.
Cazuri memorabile
Alexis împărtășește cazuri recente ale clienților în care a găsit probleme memorabile de conținut duplicat.
– Site foarte mare: rezultate după adăugarea de conținut unic
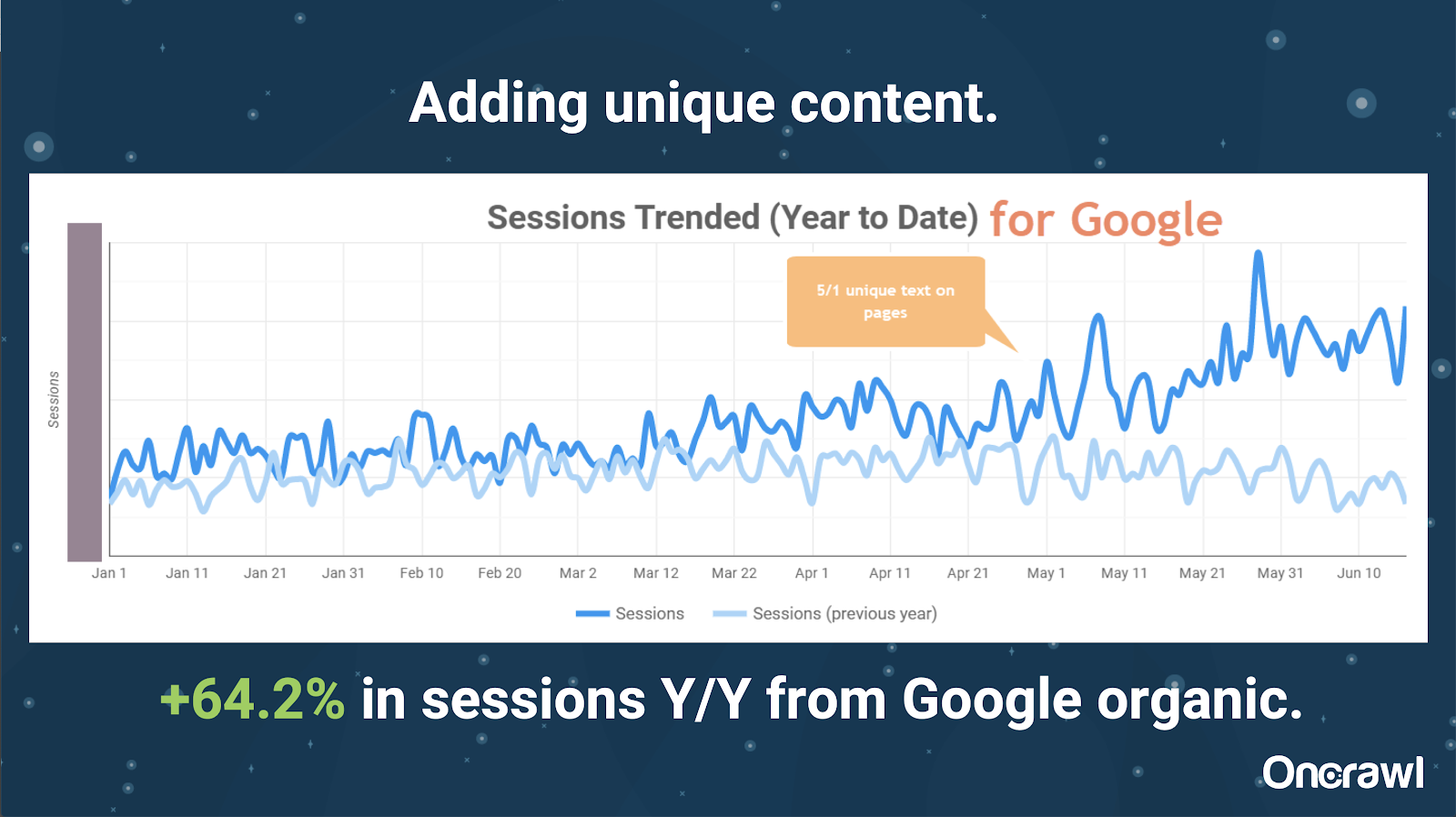
Acest site era foarte mare și are probleme legate de bugetul de accesare cu crawlere. Are 86 de milioane de pagini care nu au fost încă indexate și doar aproximativ 1% din paginile sale au fost indexate.
Acesta este un site imobiliar, așa că o mare parte din conținut nu este deosebit de unic și multe dintre paginile lor sunt foarte, foarte asemănătoare. Alexis a ajuns să adauge conținut pe pagină pentru a adăuga informații specifice locației pentru a diferenția paginile. A fost surprinzător cât de repede aceasta a produs rezultate. (Acestea sunt doar date organice Google.)
Pentru Alexis, acesta este un studiu de caz destul de generic. Oricât de mult vorbim despre EAT și lucruri similare astăzi, acest lucru demonstrează că, de îndată ce motoarele de căutare văd conținutul ca unic și valoros, acesta este în continuare recompensat.

Pe acest site, o problemă accidentală a etichetei canonice a cauzat că aproximativ 250 de pagini au fost trimise la un protocol greșit.
Acesta este un caz în care etichetele canonice au indicat pagina principală greșită, împingând paginile HTTP în locul paginii HTTPS.
Schimbări în ultimele 18 luni
Alexis a scris un articol foarte complet, Conținut duplicat și rezoluție strategică, cu aproximativ 18 luni înainte de acest webinar. SEO se schimbă rapid și trebuie să vă reînnoiți și să vă reevaluați în mod constant cunoștințele.
Pentru Alexis, majoritatea celor menționate în articol sunt și astăzi relevante, cu excepția rel=next/prev. Totuși, ea speră că va înceta să mai fie relevantă în următorii cinci până la zece ani.
Probleme tehnice tratate de dezvoltatori: prea manuale
Multe dintre problemele legate de conținutul duplicat care sunt gestionate de dezvoltatori sunt mult prea manuale. Alexis consideră că acestea ar trebui gestionate în schimb de CMS-uri și Adobe. De exemplu, nu ar trebui să parcurgeți manual și să vă asigurați că toate canonicalele sunt setate și coerente.
– Oportunități de automatizare/notificare
Există multe oportunități de automatizare în domeniul problemelor tehnice cu conținut duplicat. Pentru a da un exemplu: ar trebui să fim capabili să detectăm imediat dacă vreo legătură se îndreaptă către HTTP atunci când ar trebui să ajungă la HTTPS și să le corectăm.
– Vechimea site-ului și infrastructura moștenită ca obstacol
Unele sisteme back-end sunt mult prea vechi pentru a suporta anumite modificări și automatizări. Este extrem de dificil să migrați un CMS vechi la unul nou. Omi oferă exemplul migrării site-urilor web Canon către un CMS nou, personalizat. Nu numai că a fost scump, dar le-a luat 12 luni.
Rel prev/next și comunicare de la Google
Uneori, comunicarea de la Google este puțin confuză. Omi citează un exemplu în care, în aplicarea rel=prev/next, clientul său a înregistrat o creștere semnificativă a performanței în 2018, în ciuda anunțului Google din 2019 că aceste etichete nu au fost folosite de ani de zile.
– Lipsa unor soluții universale
Dificultatea cu SEO este că ceea ce o persoană observă care se întâmplă pe site-ul său web nu este neapărat același cu ceea ce vede un alt SEO pe propriul site; nu există un SEO universal.
Capacitatea Google de a face anunțuri pertinente pentru toți SEO ar trebui să fie recunoscută ca o faptă majoră, chiar și unele dintre declarațiile lor sunt greșite, ca în cazul rel=next/prev.
Speranțe pentru viitorul managementului conținutului duplicat
Speranțele lui Alexis pentru viitor:
- Conținut duplicat mai puțin bazat pe tehnică (cum înțeleg CMS-urile).
- Mai multă automatizare (testare unitară și testare externă). De exemplu, instrumente precum OnCrawl ar putea să vă acceseze cu crawlere în mod regulat site-ul și să vă anunțe de îndată ce observă anumite erori.
- Detectează automat paginile și tipurile de pagini cu similaritate mare pentru scriitori și managerii de conținut. Acest lucru ar automatiza unele dintre verificările care se fac manual în prezent în instrumente precum Grammarly: când cineva încearcă să publice, CMS-ul ar trebui să spună „acesta este cam similar – ești sigur că vrei să publici asta?” Există o mulțime de valoare în privința site-urilor web individuale, precum și a comparației între site-uri web.
- Google continuă să-și îmbunătățească sistemele și detectarea existente.
- Poate un sistem de alertă pentru a escalada problema cu Google care nu utilizează canonica potrivită. Ar fi util să poți alerta Google cu privire la problemă și să o rezolvi.
Avem nevoie de instrumente mai bune, instrumente interne mai bune, dar sperăm că, pe măsură ce Google își dezvoltă sistemele, ei vor adăuga elemente care să ne ajute puțin.
Trucurile tehnice preferate ale lui Alexis
Alexis are câteva trucuri tehnice preferate:
- Instanță de computer la distanță EC2. Aceasta este o modalitate foarte bună de a accesa un computer real pentru accesări cu crawlere foarte mari sau orice lucru care necesită multă putere de calcul. Este extrem de rapid odată ce îl setați. Doar asigurați-vă că îl reziliați când ați terminat, deoarece costă bani.
- Verificați primul instrument de testare mobil. Google a menționat că aceasta este cea mai precisă imagine a ceea ce se uită. Se uită la DOM.
- Comutați agentul utilizator la Googlebot. Acest lucru vă va oferi o idee despre ceea ce văd cu adevărat Googlebots.
- Folosind instrumentul robots.txt de la TechnicalSEO.com. Acesta este unul dintre instrumentele lui Merkle, dar lui Alexis îi place foarte mult, deoarece robots.txt poate fi uneori foarte confuz.
- Utilizați un analizor de jurnal.
- Realizat cu verificarea htaccess de la Love.
- Utilizarea Google Data Studio pentru a raporta modificări (sincronizarea Foi de calcul cu actualizări, filtrarea fiecărei pagini după actualizări relevante).
Dificultăți tehnice SEO: robots.txt
Robots.txt este cu adevărat confuz.
Este un fișier arhaic care pare că ar trebui să accepte RegEx, dar nu.
Are reguli de prioritate diferite pentru regulile de respingere și de permis, care pot deveni confuze.
Boți diferiți pot ignora lucruri diferite, chiar dacă nu ar trebui să o facă.
Ipotezele tale despre ceea ce este corect nu sunt întotdeauna corecte.

Întrebări și răspunsuri
– HSTS: este necesar protocolul split?
Trebuie să aveți tot HTTPS pentru conținut duplicat dacă aveți HSTS.
– Conținutul tradus este conținut duplicat?
Adesea, atunci când utilizați hreflang, îl folosiți pentru a dezambigua între versiunile localizate în aceeași limbă, cum ar fi o pagină în limba engleză din SUA și cea irlandeză. Alexis nu ar lua în considerare acest conținut duplicat, dar ea ar recomanda cu siguranță să vă asigurați că aveți etichetele hreflang configurate corect pentru a indica că aceasta este aceeași experiență, optimizată pentru diferite audiențe.
– Puteți utiliza etichete canonice în loc de redirecționări 301 pentru o migrare HTTP/HTTPS?
Ar fi util să verificați ce se întâmplă de fapt în SERP-uri. Instinctul lui Alexis este de a spune că ar fi în regulă, dar depinde de modul în care se comportă Google. În mod ideal, dacă acestea sunt exact aceeași pagină, ați dori să utilizați un 301, dar ea a văzut etichetele canonice funcționând în trecut pentru acest tip de migrare. Ea chiar a văzut că asta se întâmplă accidental.
Din experiența lui Omi, el ar sugera cu tărie folosirea 301s pentru a evita problemele: dacă migrați site-ul web, ați putea la fel de bine să îl migrați corect pentru a evita erorile actuale și viitoare.
– Efectul titlurilor de pagini duplicate
Să presupunem că aveți un titlu care este foarte asemănător pentru diferite locații, dar conținutul este foarte diferit. Deși acesta nu este conținut duplicat pentru Alexis, ea consideră că motoarele de căutare tratează acest lucru ca un lucru de tip „general”, iar titlurile sunt ceva care poate fi folosit pentru a identifica zonele cu posibile probleme.
Aici este posibil să doriți să utilizați o căutare [site: + intitle: ].
Cu toate acestea, doar pentru că aveți aceeași etichetă de titlu, nu va cauza o problemă de conținut duplicat.
Ar trebui să urmăriți în continuare titluri și meta descrieri unice, chiar și pe pagini paginate sau pe alte pagini foarte asemănătoare. Acest lucru nu se datorează conținutului duplicat, ci se referă mai degrabă la modul în care doriți să optimizați modul în care vă prezentați paginile în SERP-uri.
Sfat de top
„Conținutul duplicat este atât o provocare tehnică, cât și o provocare de marketing de conținut.”
SEO în Orbit a mers în spațiu
Dacă ați ratat călătoria noastră în spațiu pe 27 iunie, prindeți-o aici și descoperiți toate sfaturile pe care le-am trimis în spațiu.