
Utilizarea Python și a Sitemap-urilor pentru a audita strategiile de conținut
Publicat: 2020-10-08Interesul pentru ceea ce se poate face în numele SEO cu bibliotecile Python nu mai este un secret. Cu toate acestea, majoritatea oamenilor cu puțină experiență în programare întâmpină dificultăți în importarea și utilizarea unui număr mare de biblioteci sau în împingerea, rezultate dincolo de ceea ce poate face orice crawler obișnuit sau instrument SEO.
Acesta este motivul pentru care o bibliotecă Python creată special pentru SEO, SEM, SMO, verificare SERP și analiza conținutului este utilă pentru toată lumea.
În acest articol, vom arunca o privire la câteva dintre lucrurile care pot fi făcute cu Biblioteca Advertools Python pentru SEO, creată și dezvoltată de Elias Dabbas, și pentru care văd un potențial mare în SEO, PPC și capabilități de codare într-un timp foarte scurt. De asemenea, vom folosi scripturi Python personalizate împreună cu alte biblioteci Python într-un mod educațional și adaptativ.
Vom examina ceea ce poate fi învățat pentru SEO dintr-un hartă site datorită funcției sitemap_to_df a lui Elias Dabbas, care ajută la descărcarea și analiza sitemap-urilor XML (Un hartă site-ului este un document în format XML folosit pentru a raporta URL-uri care pot fi accesate cu crawlere și indexabile către motoarele de căutare.)
Acest articol vă va arăta cum puteți scrie coduri Python personalizate pentru analiza diferitelor site-uri web în funcție de structura lor diferită, cum să interpretați datele în termeni de SEO și cum să gândiți ca un motor de căutare când vine vorba de profiluri de conținut, URL-uri și structuri de site. .
Analizarea dimensiunii și strategiei de conținut a unui site web pe baza sitemapului acestuia
Harta site-ului este o componentă a unui site web care poate capta multe tipuri diferite de date, cum ar fi frecvența cu care un site publică conținut, categorii de conținut, datele de publicare, informații despre autor, subiectul conținutului...
În condiții normale, puteți răzui un sitemap cu scrapy, îl puteți converti într-un DataFrame cu Pandas și îl puteți interpreta cu multe biblioteci auxiliare diferite, dacă doriți.
Dar în acest articol, vom folosi doar Advertools și unele metode și atribute ale bibliotecii Pandas. Unele biblioteci vor fi activate pentru a vizualiza datele pe care le-am dobândit.
Să intrăm direct și să selectăm un site web pentru a-și folosi harta site-ului pentru a concluziona câteva informații importante despre SEO.
Extragerea și crearea de cadre de date din sitemap-uri cu Advertools
În Advertools, puteți descoperi, răsfoi și combina toate sitemapurile unui site web cu o singură linie de cod.
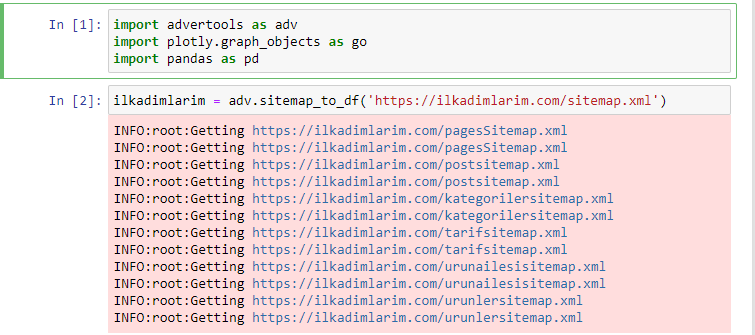
Îmi place să folosesc Jupyter Notebook în loc de un editor de cod obișnuit sau IDE.
În prima celulă am importat Pandas și Advertools pentru colectarea și organizarea datelor și Plotly.graph_objects pentru vizualizarea datelor.
Comanda adv.sitemap_to_df('sitemap address') pur și simplu colectează toate sitemap-urile și le unifică ca DataFrame.
Dacă procedați la fel folosind Pandas și Advertools, puteți descoperi ce adresă URL este disponibilă în ce hartă site.
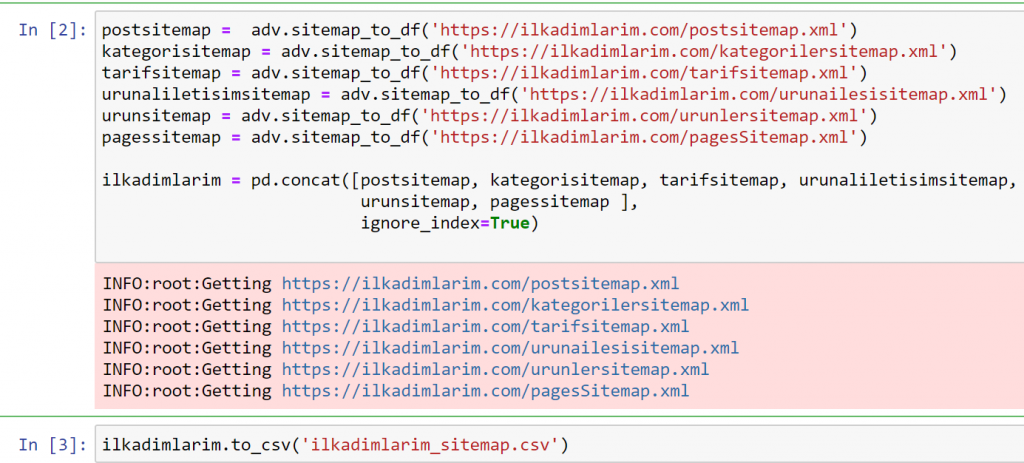
În exemplul de mai sus, am extras aceleași sitemap-uri separat și apoi le-am combinat cu comanda pd.concat și am transferat rezultatul în CSV. Exemplul anterior a folosit fișierul index sitemap, caz în care funcția merge pentru a prelua toate celelalte sitemap. Deci, aveți opțiunea de a selecta anumite hărți de site, așa cum am făcut aici, dacă sunteți interesat de o anumită secțiune a site-ului.
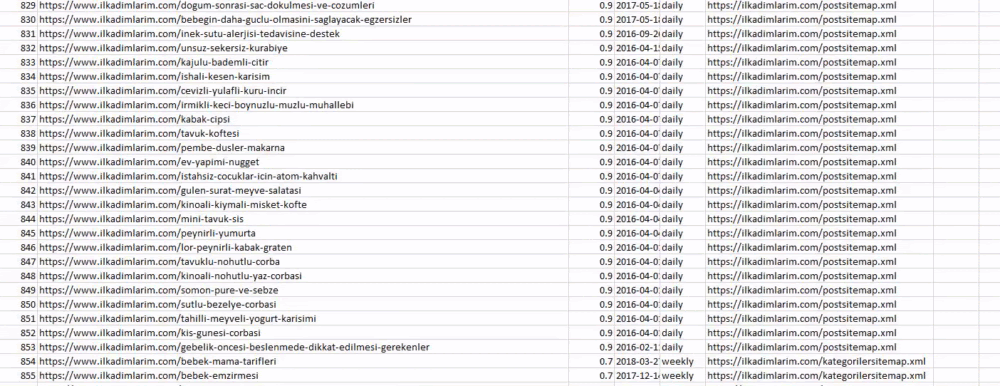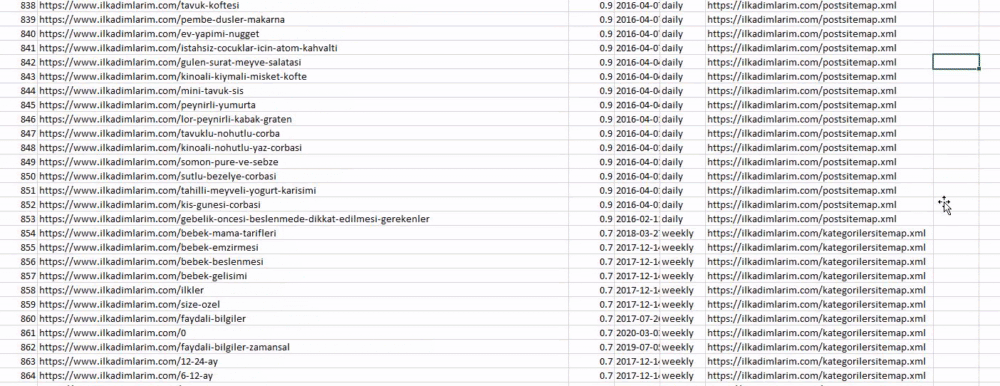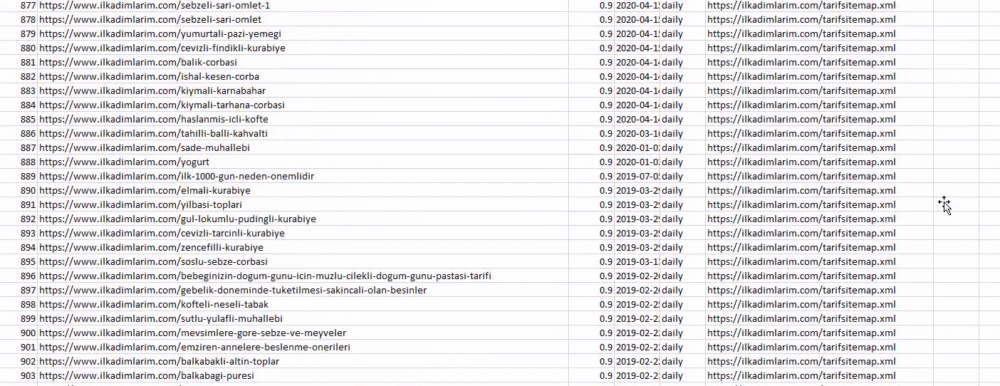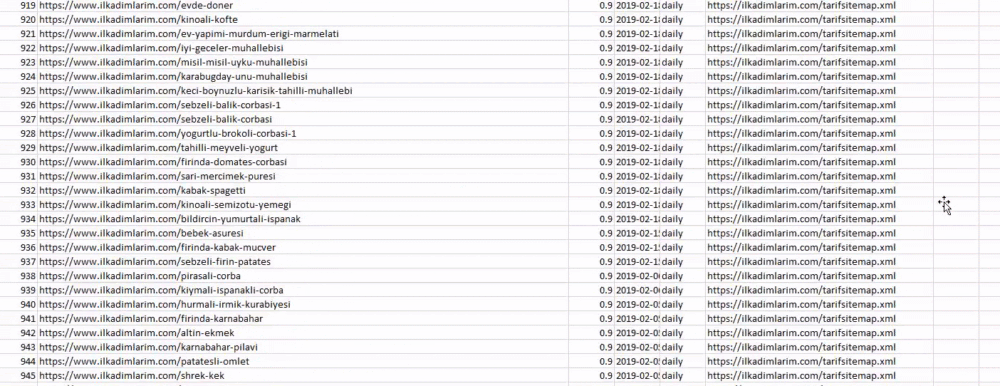
Puteți vedea mai sus o coloană cu nume diferite de sitemap. ignore_index=Secțiunea adevărată este pentru ordonarea ordonată a numerelor de index ale diferitelor DataFrame, dacă le-ați îmbinat pe mai multe.
Date oncrawl³
 Află mai multe
Află mai multeCurățarea și pregătirea cadrului de date ale sitemapului pentru analiza conținutului cu Python
Pentru a înțelege profilul de conținut al unui site web printr-o hartă a site-ului, trebuie să-l pregătim pentru a revizui DataFrame-ul pe care l-am obținut cu Advertools.
Vom folosi câteva comenzi de bază din biblioteca Pandas pentru a ne modela datele:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns = 'Nenumit: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
„Ilkadimlarim” înseamnă „primii mei pași” în turcă și, după cum vă puteți imagina, este un site pentru bebeluși, sarcină și maternitate.
Am efectuat trei operații cu aceste linii.
- Fără nume: Am eliminat o coloană goală numită 0 din DataFrame. De asemenea, dacă utilizați „index = False” cu funcția pd.to_csv() , nu veți vedea această coloană „Unnamed 0” la început.
- Am convertit datele din coloana Ultima modificare în Data Ora.
- Am adus coloana „lastmod” în poziția de index.
Mai jos puteți vedea versiunea finală a DataFrame.
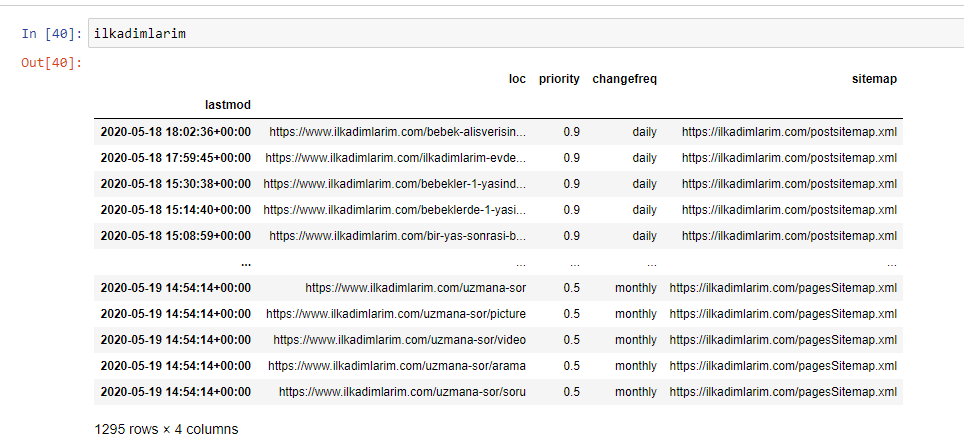
Știm că Google nu folosește informații de prioritate și de frecvență din hărțile site-ului. Ei o numesc „un sac de zgomot”. Dar dacă acordați importanță performanței site-ului dvs. pentru alte motoare de căutare, s-ar putea să vă fie util să le examinați și pe acestea. Personal, nu îmi pasă foarte mult de aceste date, dar tot nu trebuie să le elimin din DataFrame.
Avem nevoie de încă o linie de cod pentru a clasifica sitemapurile într-o altă coloană.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
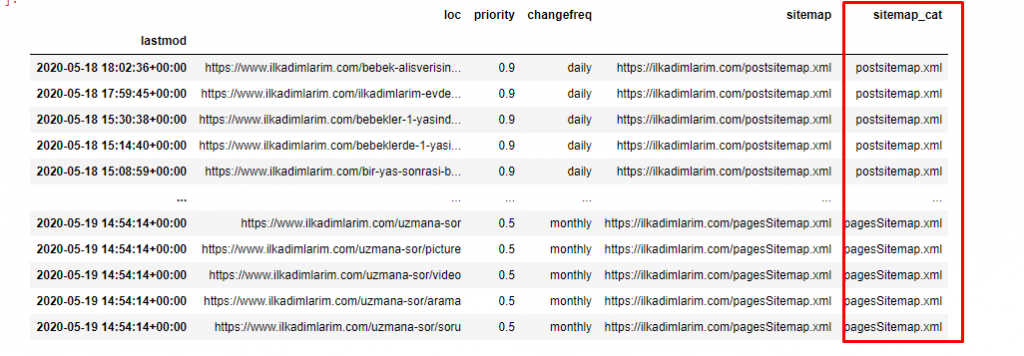
În Pandas, puteți adăuga coloane sau rânduri noi la un DataFrame sau le puteți actualiza cu ușurință. Am creat o nouă coloană cu fragment de cod DataFrame['new_columns'] . DataFrame['nume_coloană'].str ne permite să efectuăm diferite operații prin modificarea tipului de date dintr-o coloană. Împărțim șirul de date din coloana aferentă .split ('/') la caracterul / și le punem într-o listă. Cu .str [număr] , creăm conținutul noii coloane selectând un anumit element din acea listă.
Analiza profilului de conținut în funcție de numărul și tipurile de sitemap
După ce punem sitemapurile într-o coloană diferită în funcție de tipurile lor, putem verifica ce % din conținut se află în fiecare sitemap. Astfel, putem face și o inferență despre care parte a site-ului este mai importantă.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['nume_coloană'] selectează coloana pe care vrem să facem un proces.
- value_counts() numără frecvența valorilor din coloană.
- normalize=True ia raportul valorilor în zecimală.
- Facem mai ușor de citit prin mărirea numerelor zecimale cu *100.
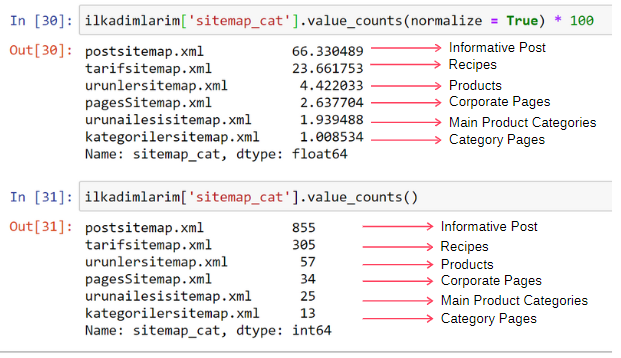
Vedem că 65% din conținut se află în Sitemap-ul Post și 23% este în Sitemap-ul Rețetei. Sitemap-ul produsului are doar 2% din conținut.
Acest lucru arată că avem un site web care trebuie să creeze conținut informativ pentru un public larg pentru a-și comercializa propriile produse. Să verificăm dacă teza noastră este corectă.
Înainte de a continua, trebuie să schimbăm numele coloanei ilkadimlarim['sitemap_cat'] în 'URL_Count' cu codul de mai jos:
ilkadimlarim.rename(columns={'sitemap_cat': 'URL_Count'}, inplace=True)
- Funcția rename() este utilă pentru a modifica numele coloanelor sau indexurilor pentru conectarea datelor și semnificația acestora la un nivel mai profund.
- Am schimbat numele coloanei pentru a fi permanent datorită atributului „inplace=True” .
- De asemenea, puteți modifica stilurile de litere ale coloanelor și indexurilor dvs. cu ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . Aceasta scrie doar primele litere ca majuscule ale fiecărei coloane din Ilkadimlarim.

Acum, putem continua.
Pentru a vedea aceste informații într-un singur cadru, puteți folosi codul de mai jos:
(ilkadimlarim['sitemap_cat']
.value_counts()
.to_frame()
.assign(procentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percentage='{:.1%}')))
- to_frame() este folosit pentru a încadra valorile măsurate prin value_counts() în coloana selectată.
- assign() este folosit pentru a adăuga anumite valori la cadru.
- lambda se referă la funcții anonime din Python.
- Aici, funcția Lambda și tipurile de sitemap sunt împărțite la numărul total de sitemap prin metoda Pandas div() .
- style() determină modul în care sunt scrise valorile finale specificate.
- Aici, setăm câte cifre sunt scrise după punct cu metoda format() .
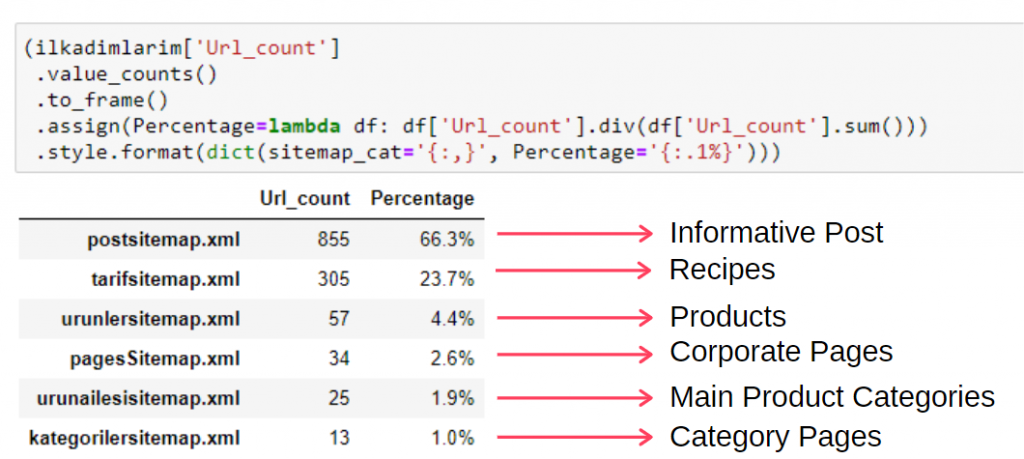
Astfel, vedem importanța marketingului de conținut pentru acest site web. De asemenea, putem verifica tendințele lor de publicare a articolelor pe an cu două rânduri de cod unice pentru a examina situația lor mai profund.
Examinarea și vizualizarea tendințelor de publicare de conținut pe an prin Sitemap-uri și Python
Am făcut potrivirea conținutului și intenției site-ului web examinat în funcție de categoriile sitemap-ului, dar încă nu am făcut o clasificare bazată pe timp. Vom folosi metoda resample() pentru a realiza acest lucru.
post_pe_lună = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample este o metodă din biblioteca Pandas. resample('A') verifică seria de date pentru un DataFrame anual. Timp de săptămâni, puteți folosi „W”, luni de zile, puteți folosi „M”.
Loc aici simbolizează indexul; count înseamnă că doriți să numărați suma exemplelor de date.
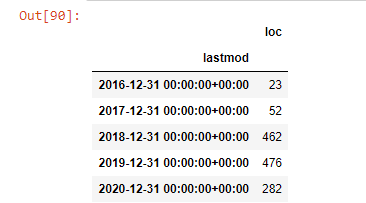
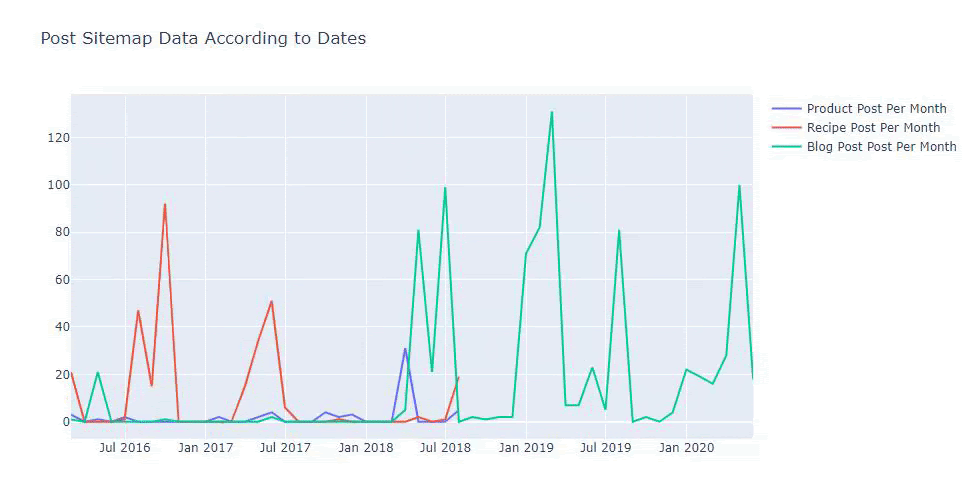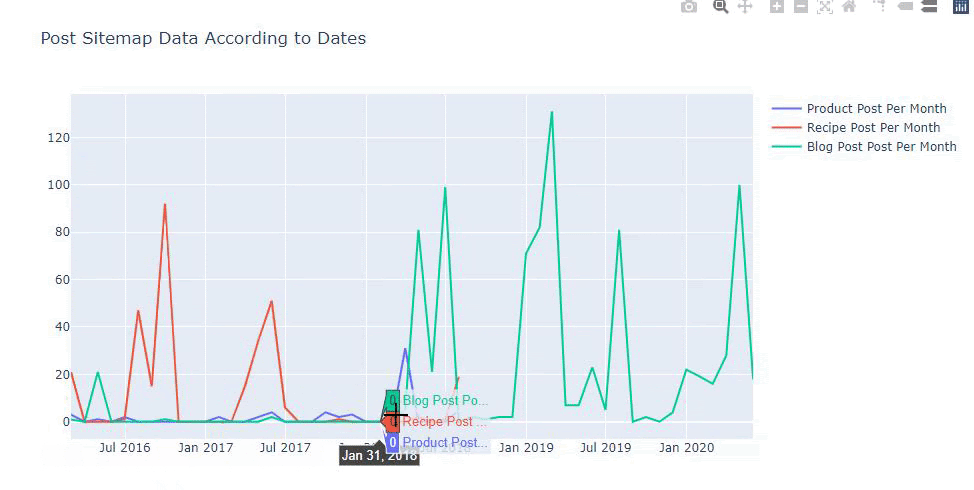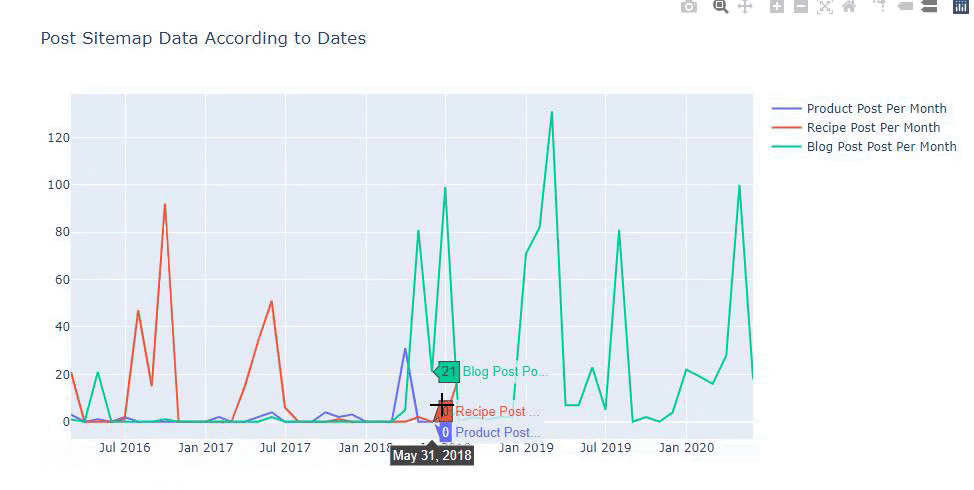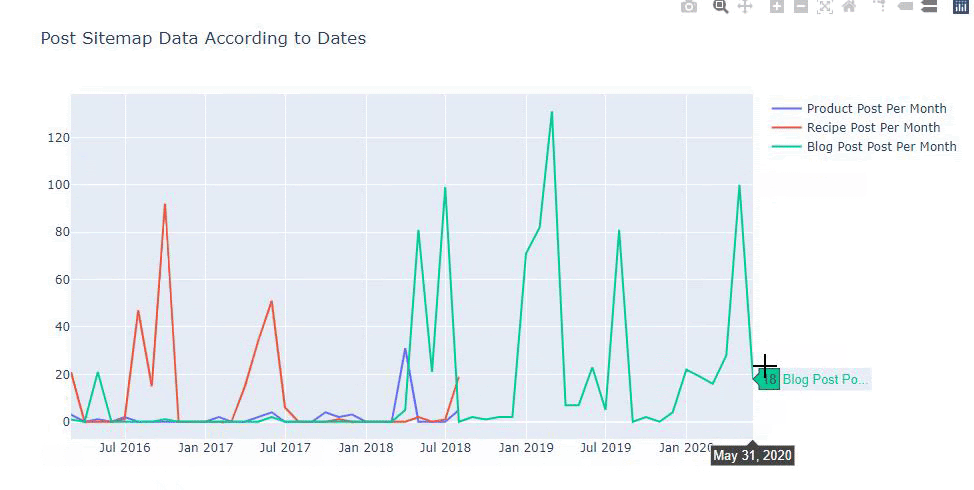
Vedem că au început să publice articole în 2016, dar tendința lor principală de publicare a crescut după 2017. Putem pune și asta într-o grafică cu ajutorul Plotly Graph Objects.
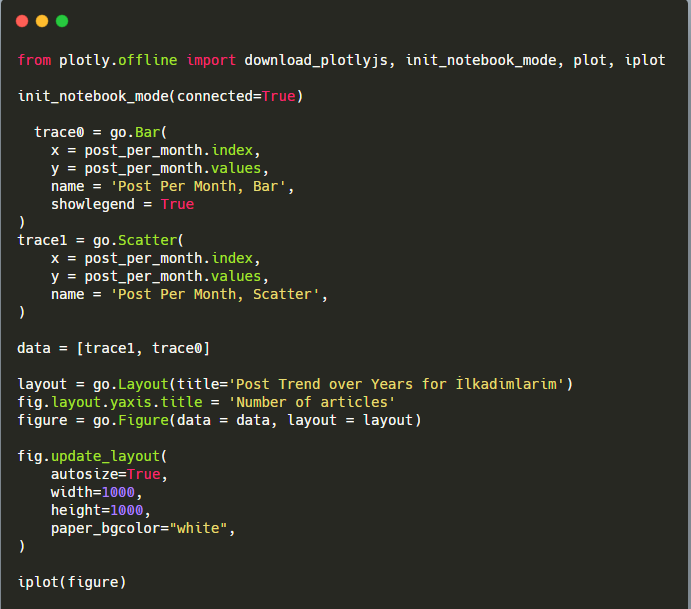
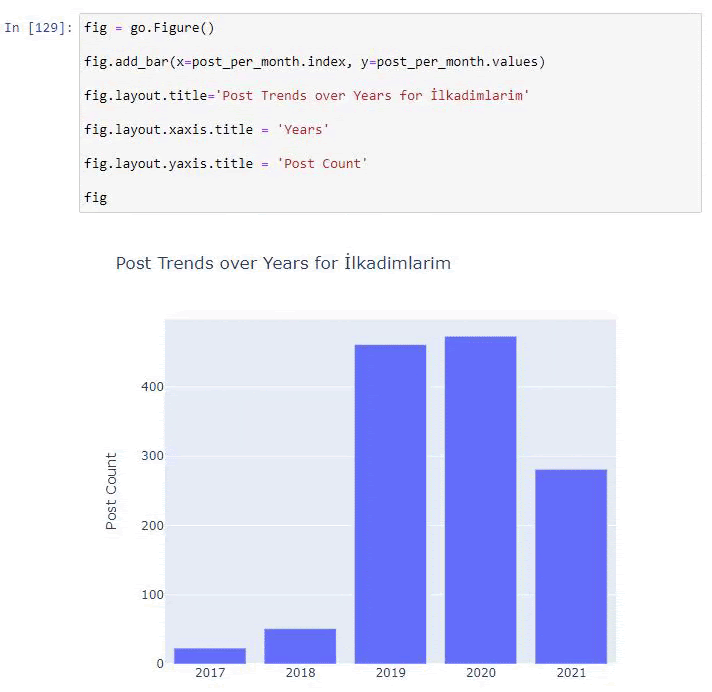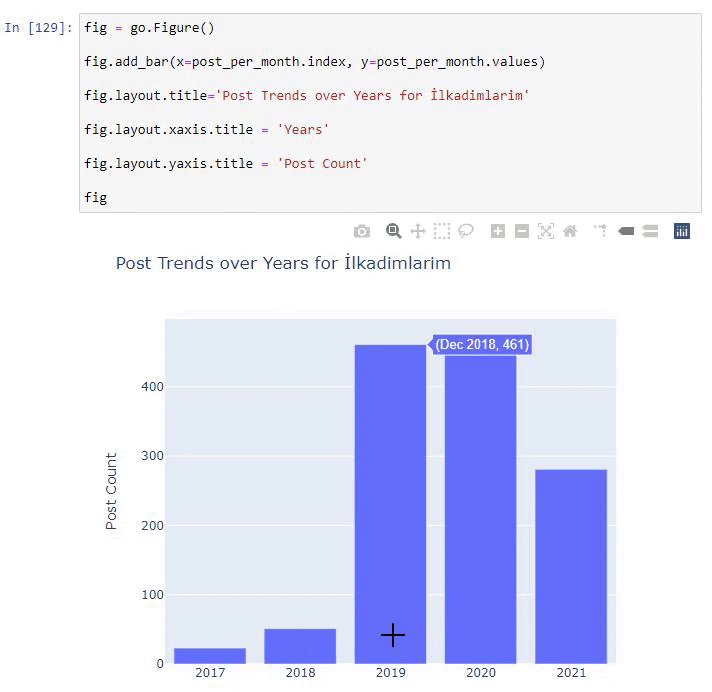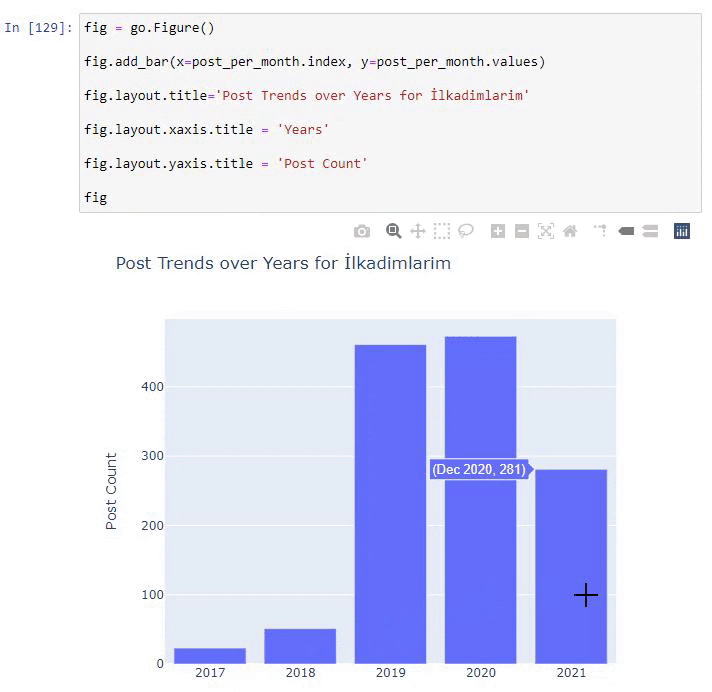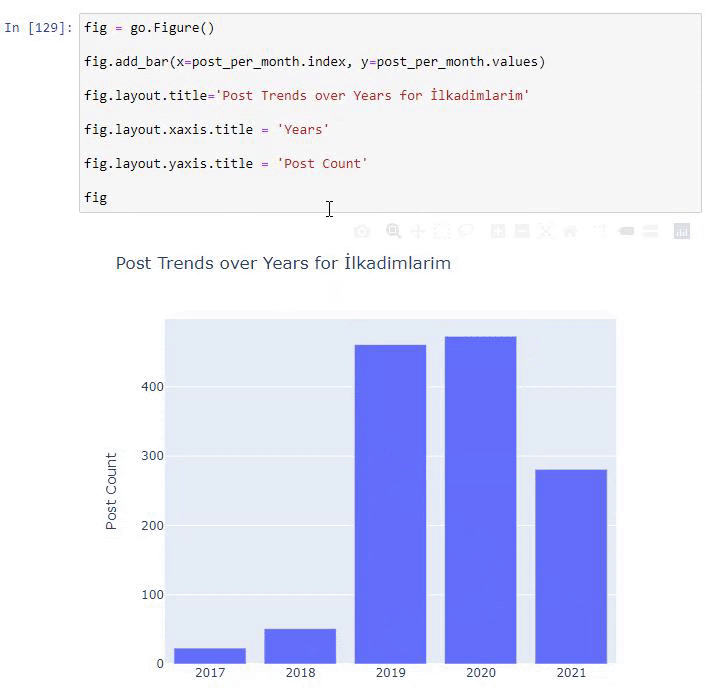
Explicația acestui fragment de cod Plotly Bar Plot:
- fig = go.Figure() este pentru crearea unei figuri.
- fig.add_bar() este pentru adăugarea unui barplot în figură. De asemenea, determinăm ce axe X și Y vor fi în paranteze.
- Fig.layout este pentru crearea unui titlu general pentru figură și axe.
- La ultima linie apelăm graficul pe care l-am creat cu comanda fig, care este egală cu go.Figure()
Mai jos, veți găsi aceleași date pe lună, cu diagramă de dispersie și diagramă cu bare:
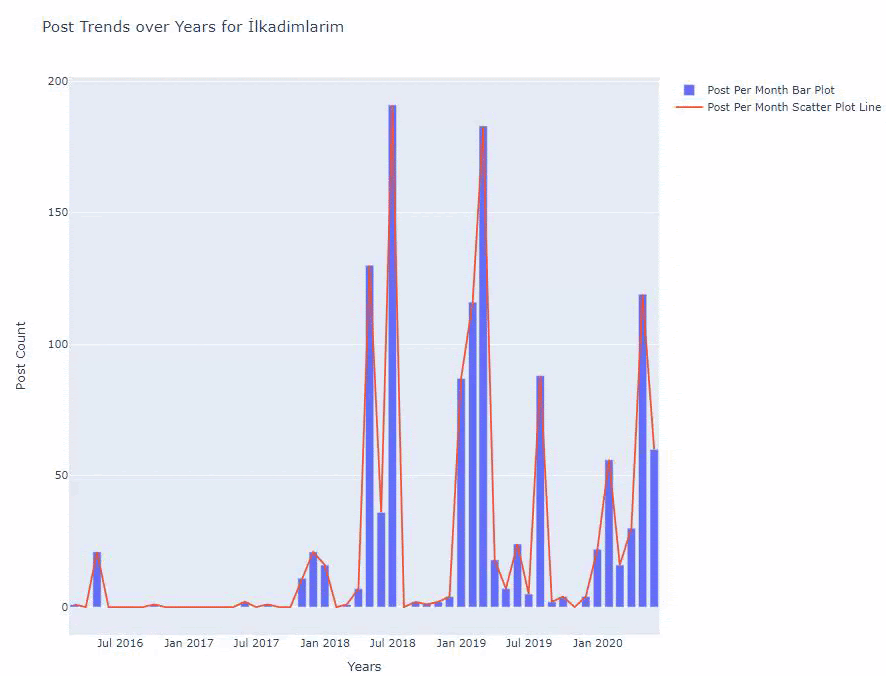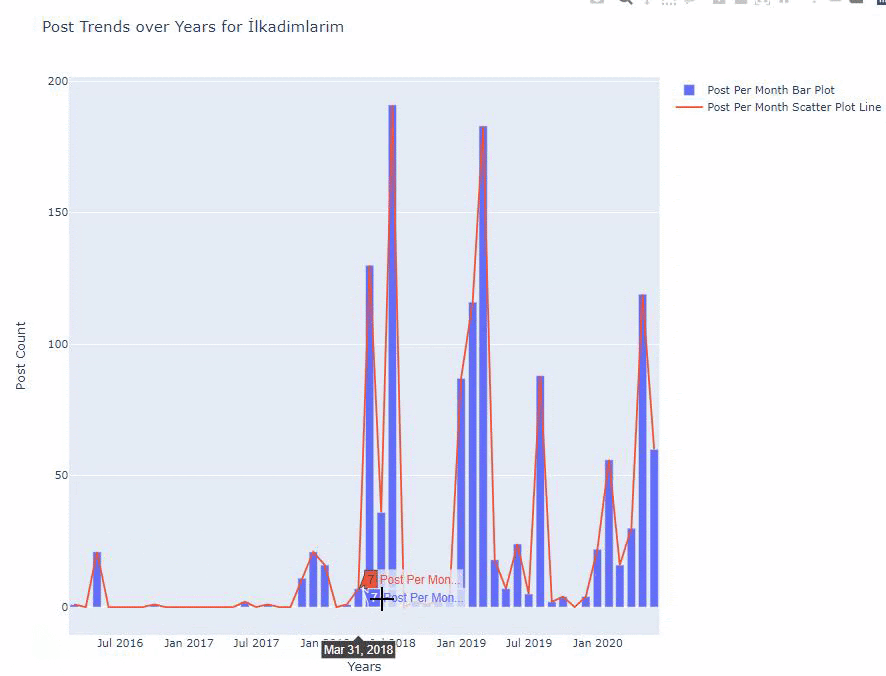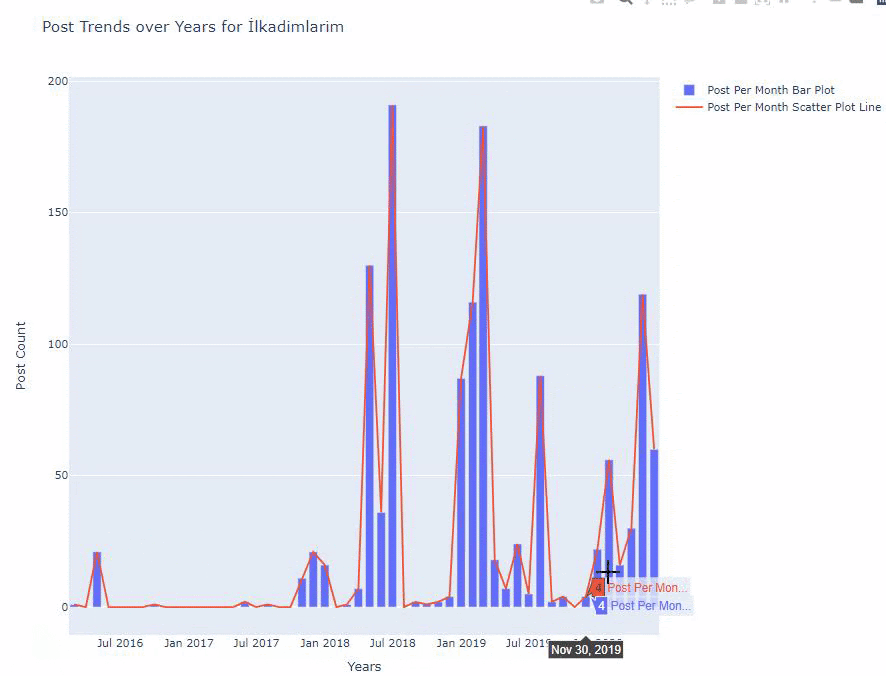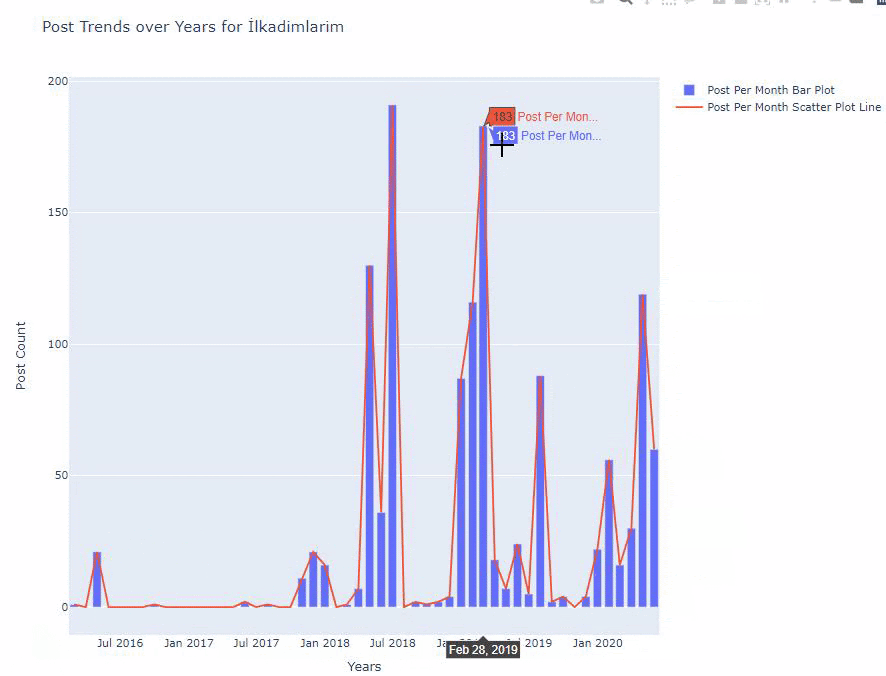
Iată codurile pentru a crea această figură:
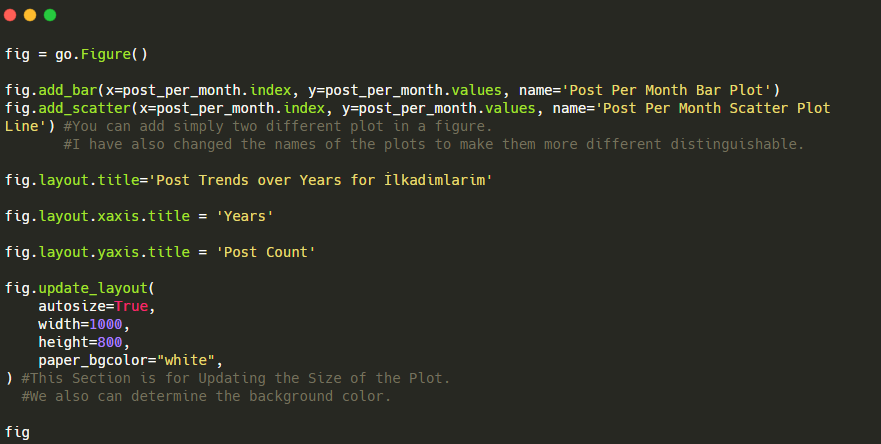
Am adăugat un al doilea plot cu fig.add_scatter() și am schimbat, de asemenea, numele folosind atributul name. fig.update_layout() este pentru a schimba dimensiunea și culoarea de fundal a parcelei.
De asemenea, puteți schimba modul de trecere cu mouse-ul, distanța dintre bare și multe altele. Cred că este suficient să partajăm doar codurile, deoarece explicarea fiecărui cod aici separat ne poate determina să ne îndepărtăm de subiectul principal.
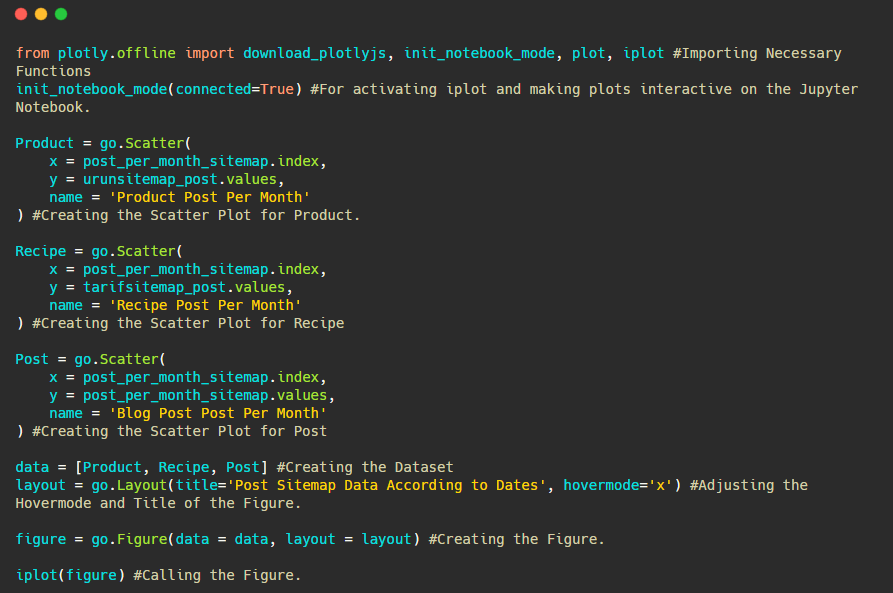
De asemenea, putem compara tendințele de publicare de conținut ale concurenților în funcție de categorii precum mai jos:
Această diagramă a fost creată cu a doua metodă, după cum puteți vedea, nu există nicio diferență, dar una dintre ele este destul de simplă.
Pentru a diagrama frecvența și tendința publicării conținutului din trei sitemap-uri separate, trebuie să plasăm sitemap-ul, care are cel mai lung interval, pe axa X. Astfel, putem compara frecvența cu care site-ul web pe care îl examinăm publică fiecare tip diferit de conținut pentru diferite intenții de căutare.
Când examinați codurile relevante de mai jos, veți vedea că nu diferă mult de cele de mai sus.
Pentru a crea un grafic de dispersie cu mai multe axe Y, puteți utiliza codul de mai jos.
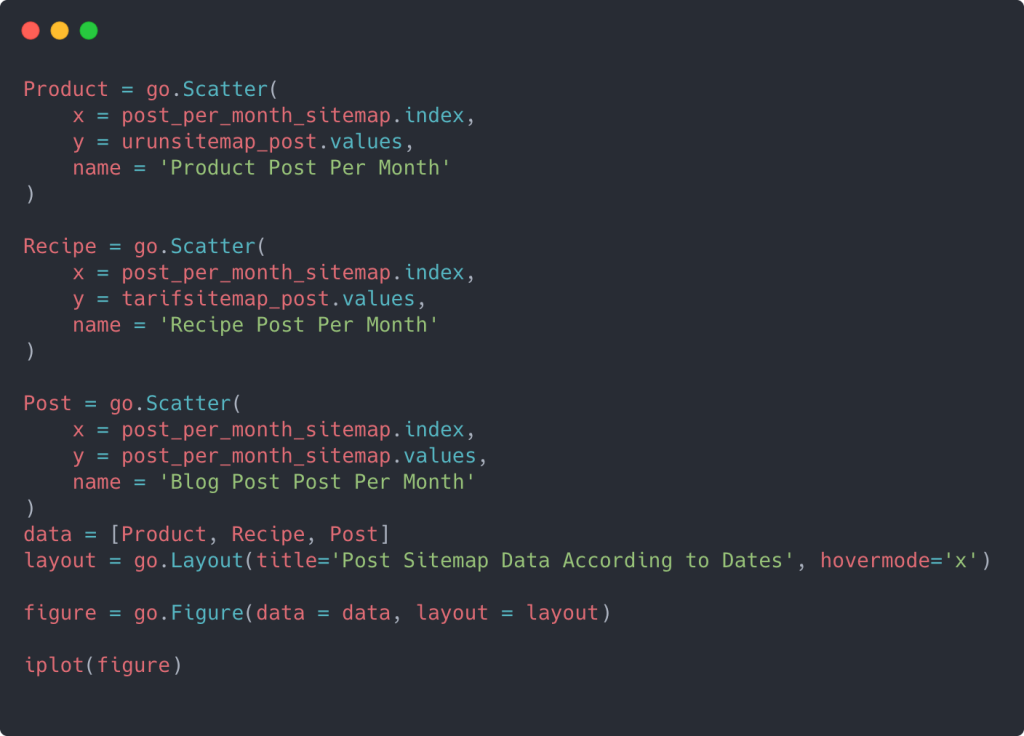
Există și alte metode, cum ar fi unificarea diferitelor hărți de site și utilizarea unei bucle for pentru ca coloanele să utilizeze mai multe axe Y în diagrama de dispersie, dar pentru un site atât de mic nu avem nevoie de asta. În cea mai mare parte, ar fi mai logic să folosiți această metodă pe site-uri web cu sute de hărți de site.
De asemenea, deoarece site-ul web este mic, graficul poate părea superficial, dar după cum veți vedea mai târziu în articolul de pe un site web cu milioane de adrese URL, astfel de grafice sunt o modalitate excelentă de a compara diferite site-uri, precum și de a compara diferite categorii ale acelasi site web.
Examinarea și vizualizarea categoriilor de conținut, a intențiilor și a tendințelor de publicare cu Sitemaps și Python
În această secțiune, vom verifica dacă au scris un număr mare de conținut într-un anumit domeniu de cunoaștere pentru a comercializa un număr mic de produse, ceea ce am spus la începutul articolului. Datorită acestui fapt, putem vedea dacă au sau nu un parteneriat de conținut cu alte mărci.
Pentru a arăta ce mai poate fi găsit pe sitemap-urile, vom continua să săpăm puțin. Putem obține, de asemenea, unele informații din partea „loc” a hărții site-ului, cum ar fi altele.
Nu există o defalcare a categoriilor în adresele URL ale Ilkadimlarim. Dacă un site web are o defalcare a categoriilor în adresele sale URL, putem afla multe mai multe despre distribuția de conținut. Dacă nu, putem accesa aceleași date scriind cod suplimentar, dar doar cu mai puțină siguranță.
În acest moment, vă puteți imagina cât de mult mai puțin costisitoare defalcările URL fac ca motoarele de căutare care accesează cu crawlere miliarde de site-uri să vă înțeleagă site-ul.
a = ilkadimlarim['loc'].str.contains(„bebek|hamile|haftalik”)
Bebek: iubito
Hamile: însărcinată
Haftalik: săptămânal sau „săptămâni de sarcină”
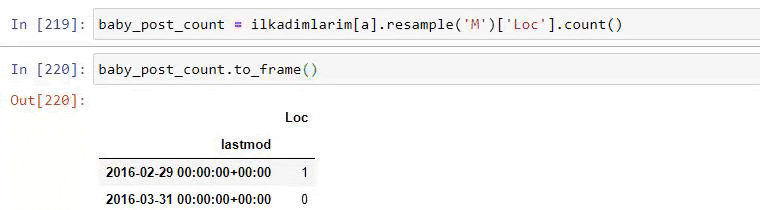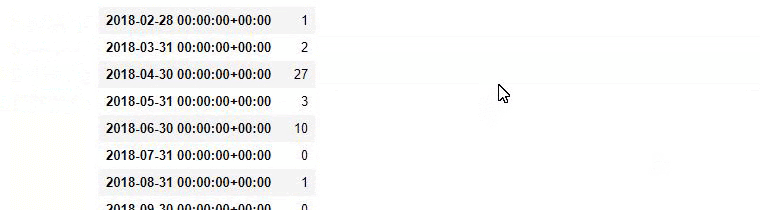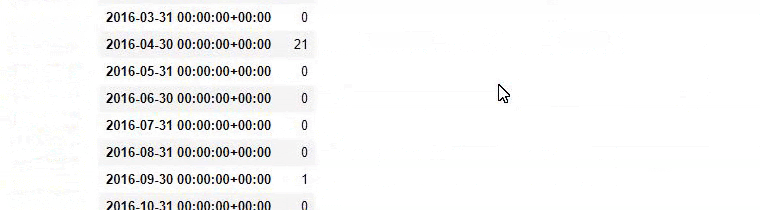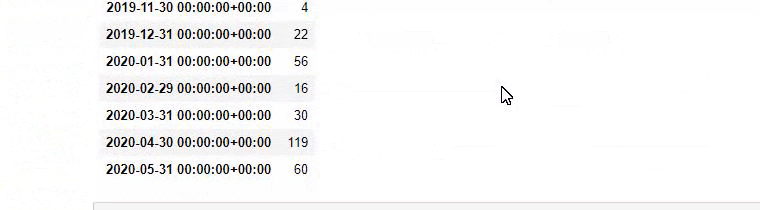
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Metoda str() aici ne permite din nou să setăm coloana în care selectăm anumite operații.
Cu metoda contains() , determinăm datele pentru a verifica dacă sunt incluse în datele convertite într-un șir.
Aici, „|” între termeni înseamnă „sau” .
Apoi atribuim datele pe care le-am filtrat unei variabile și folosim metoda resample() pe care am folosit-o mai devreme.
metoda count , pe de altă parte, măsoară ce date sunt utilizate și de câte ori.
Rezultatul obținut cu count() este din nou inclus cu to_frame() .
De asemenea, str.contains() preia valorile Regex în mod implicit, ceea ce înseamnă că puteți crea condiții de filtrare mai complicate cu mai puțin cod.
Cu alte cuvinte, în acest moment, atribuim adresele URL care conțin cuvintele „bebeluș”, „săptămânal”, „însărcinată” unei variabile în ilkadimlarim și apoi punem data publicării URL-urilor în condițiile adecvate pentru acest filtru creat într-un cadru.
Apoi facem același lucru pentru adresele URL care conțin cuvântul „aptamil”. Aptamil este numele unui produs de nutriție pentru bebeluși introdus de Ilkadimlarim. Prin urmare, putem acorda atenție și densității de difuzare a conținutului informativ și comercial.
Și este posibil să vedeți cele două grupuri de conținut diferite publicând programe de-a lungul anilor pentru diferite intenții de căutare, cu mai multă siguranță și informații precise din adrese URL.
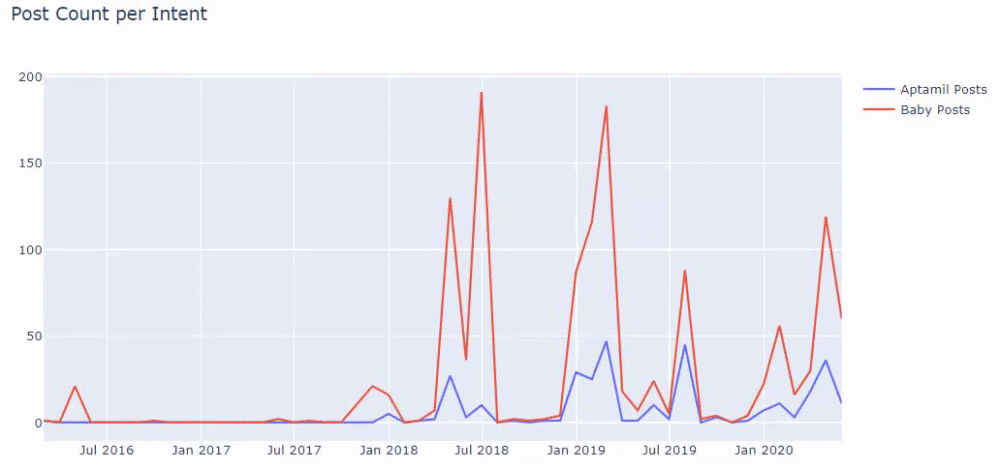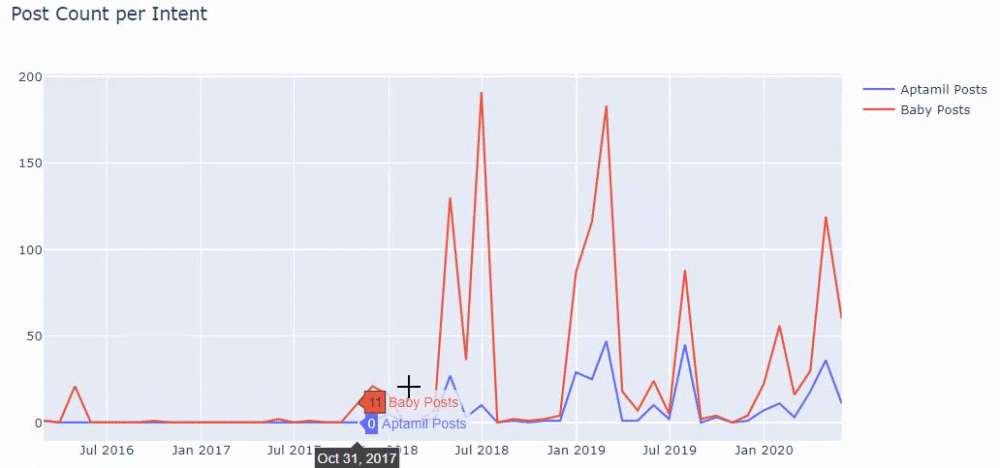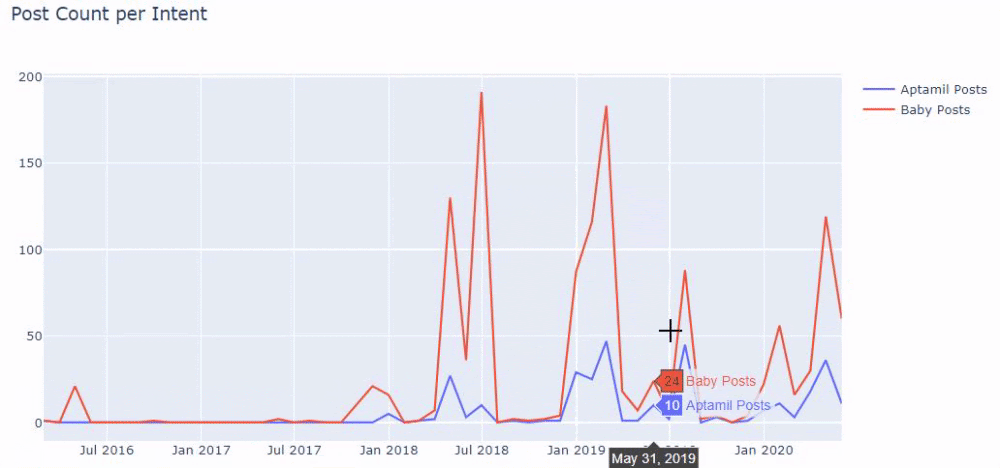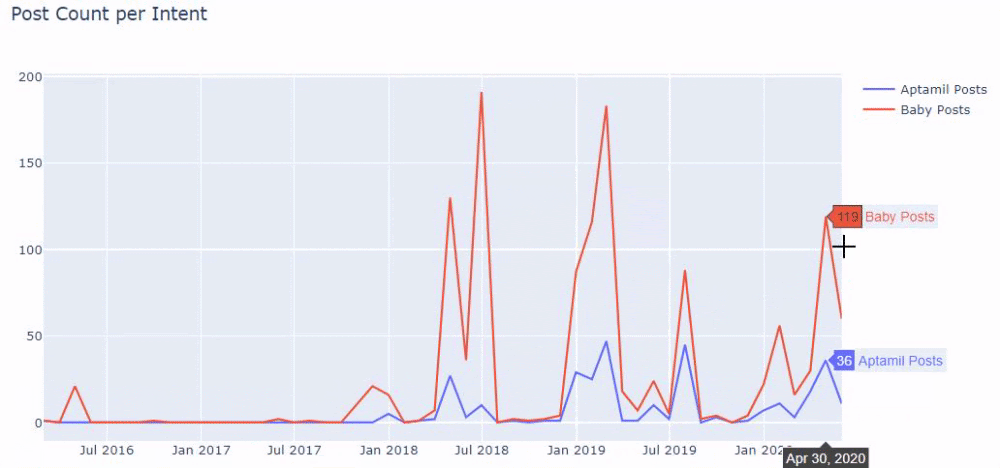
Codul pentru producerea acestei diagrame nu a fost partajat deoarece este același cu cel folosit pentru diagrama precedentă
Cu ajutorul operatorilor de căutare de pe Google, obțin 38 de rezultate când vreau paginile în care cuvântul Aptamil este folosit în text anchor la Ilkadimlarim.com. Un număr important din aceste pagini sunt informative și leagă conținut comercial.
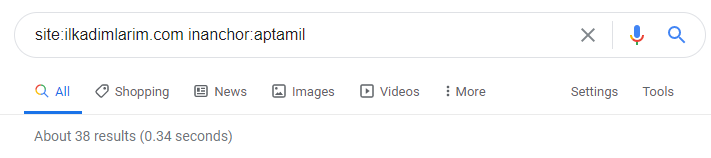
Teza noastră a fost dovedită.
„Primii mei pași” folosește sute de conținut informativ despre maternitate, îngrijirea copilului și sarcină pentru a ajunge la publicul țintă. „Ilkadimlarim” leagă paginile care conțin produse Aptamil din acest conținut și direcționează utilizatorii acolo.
Profilul de conținut comparativ și analiza strategiei de conținut prin sitemap-uri cu Python
Acum, dacă doriți, să facem același lucru pentru o companie din aceeași industrie și să facem o comparație pentru a înțelege aspectul general al acestei industrii și diferențele de strategie dintre aceste două mărci.

Ca un al doilea exemplu, am ales Prima.com.tr, care este Pampers, dar folosește marca Prima în Turcia. Deoarece Prima are un singur sitemap, nu vom putea clasifica în funcție de sitemap, dar cel puțin au diferite pauze în adresele URL. Deci suntem foarte norocoși: va trebui să scriem mai puțin cod.
Imaginează-ți cât de mai costisitoare sunt algoritmii pe care Google trebuie să-i ruleze pentru tine atunci când faci un site greu de înțeles! Acest lucru vă poate ajuta să faceți calculul costului cu crawlere să fie mai tangibil în mintea dvs., chiar și doar în ceea ce privește structura URL.
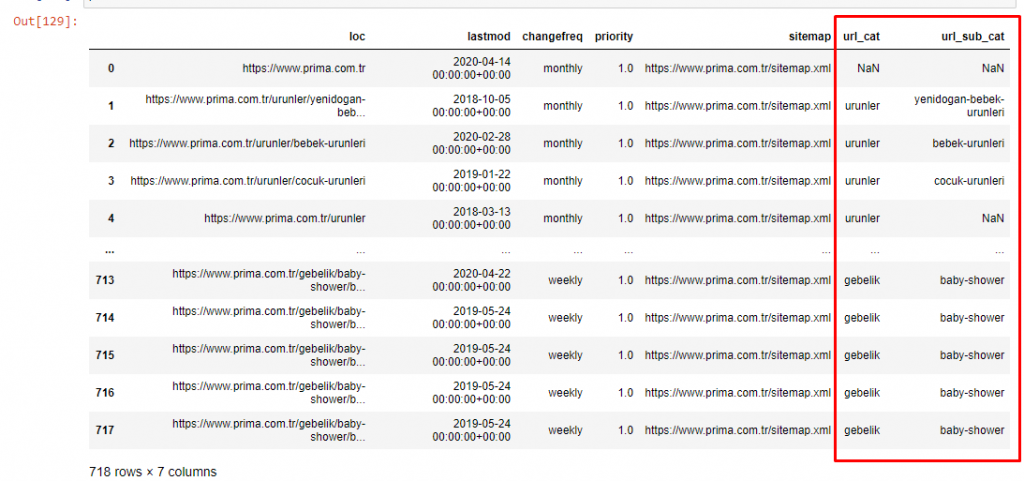
Pentru a nu crește și mai mult volumul articolului, nu plasăm codurile proceselor care sunt similare cu cele pe care le-am făcut deja.
Acum, putem examina distribuția categoriilor de conținut pe categorii de adrese URL și subcategorii URL. Vedem că au o cantitate excesivă de pagini web corporative. Aceste pagini web corporative sunt plasate în secțiunea „prima-hakkinda” („Despre Prima”). Dar când le verific cu Python, văd că și-au unificat produsele și paginile web corporative într-o singură categorie. Puteți vedea distribuția lor de conținut mai jos:

Putem face același lucru pentru următoarele subcategorii.
Este interesant de observat că Prima folosește „gebelik” (sarcină în turcă), care este o variantă a „hamilelik” (sarcină în arabă), și ambele înseamnă perioada de sarcină.

Acum vedem o clasificare mai profundă a conținutului lor. 9,2% din conținut este despre sarcina sănătoasă, 7,3% despre procesul de creștere al bebelușilor, 8,3% din conținut este despre activități care pot fi făcute cu bebelușii, 0,7% despre ordinea de somn a bebelușilor. Există chiar și subiecte precum dentiția cu 3,9%, securitatea bebelușului cu 1,9% și dezvăluirea unei sarcini familiei cu 1,4%. După cum puteți vedea, puteți cunoaște o industrie doar cu adrese URL și procentul de distribuție al acestora.
Aceasta nu este clasificarea perfectă, dar cel puțin putem vedea mentalitatea și tendințele de marketing de conținut ale concurenților noștri, precum și conținutul site-ului lor în funcție de categorii. Acum să verificăm frecvența publicării conținutului pe lună.
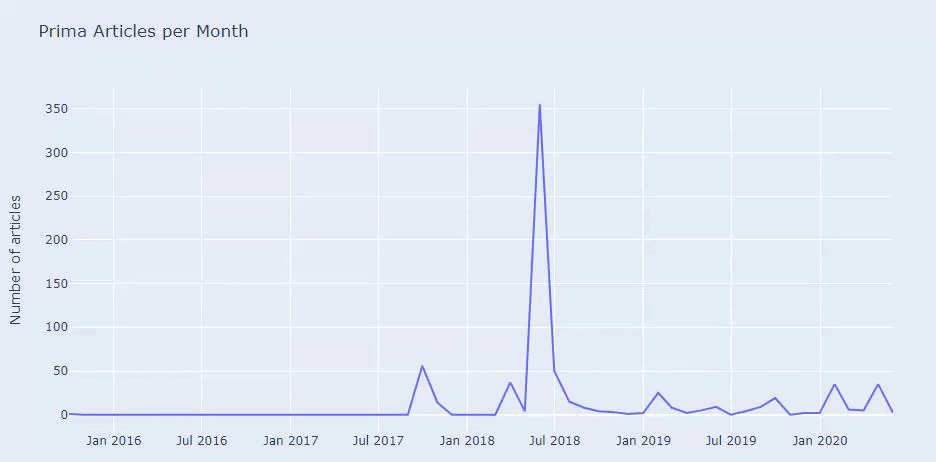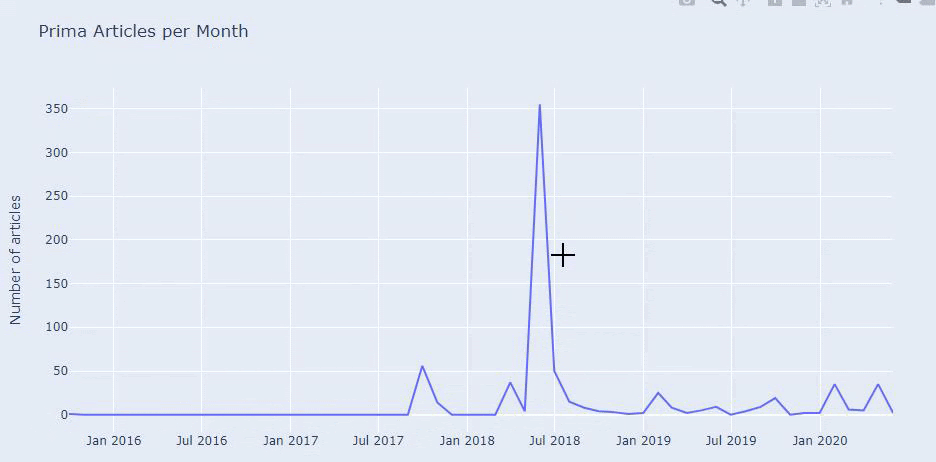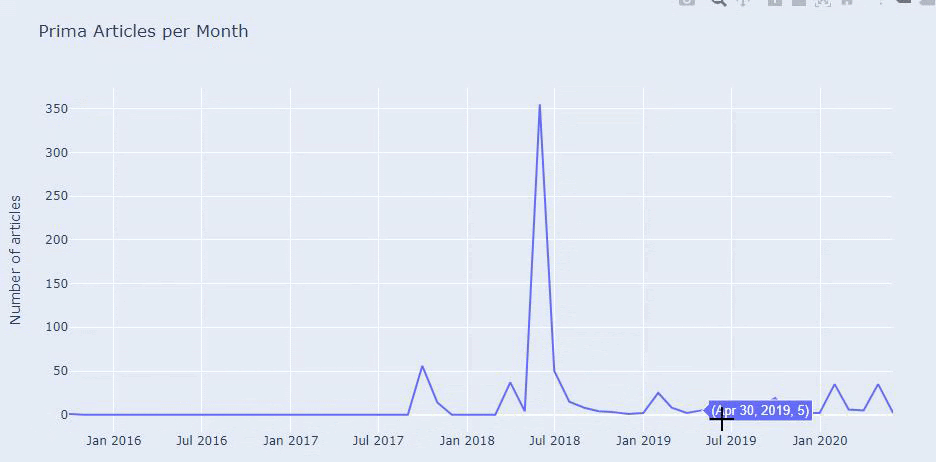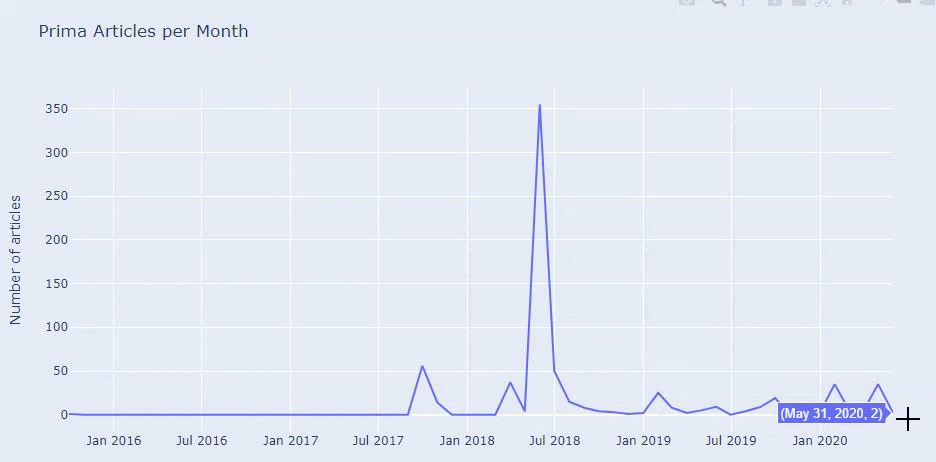
Vedem că au publicat 355 de articole în iulie 2018 și conform Sitemap-ului, conținutul lor nu a fost reîmprospătat de atunci. De asemenea, putem compara tendințele lor de publicare de conținut în funcție de categorii de-a lungul anilor. După cum puteți vedea, conținutul lor este localizat în principal în patru categorii diferite și cele mai multe dintre ele sunt publicate în aceeași lună.
Înainte de a continua, trebuie să spun că este posibil ca datele sitemap să nu fie întotdeauna corecte. De exemplu, este posibil ca datele Lastmod să fi fost actualizate pentru toate adresele URL, deoarece au reînnoit toate sitemapurile la această dată. Pentru a ocoli acest lucru, putem de asemenea să verificăm dacă nu și-au schimbat conținutul de atunci folosind Wayback Machine.
Chiar dacă pare suspect, aceste date pot fi reale. Multe companii din Turcia au tendința de a da un număr mare de comenzi și de a publica conținut cu un moment înainte. Când verific numărul lor de cuvinte cheie, văd un salt în această perioadă de timp. Deci, dacă efectuați un profil de conținut comparativ și o analiză de strategie, ar trebui să vă gândiți și la aceste probleme.
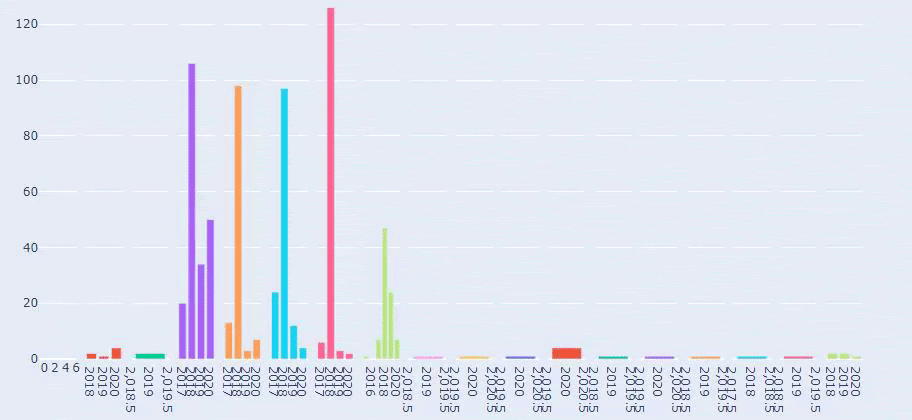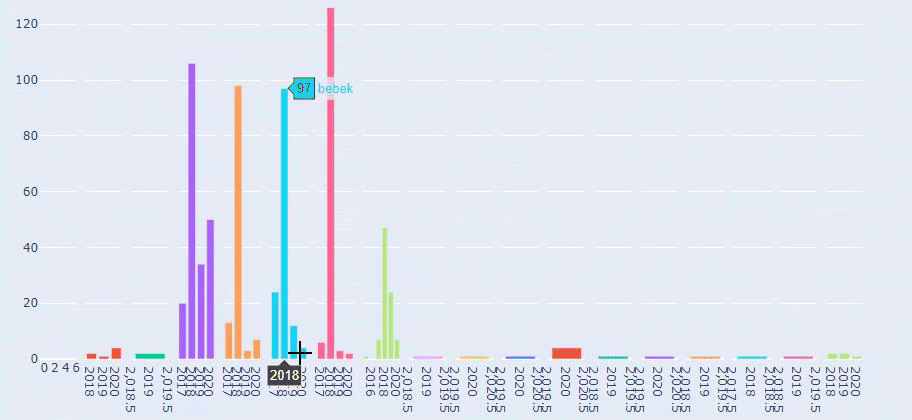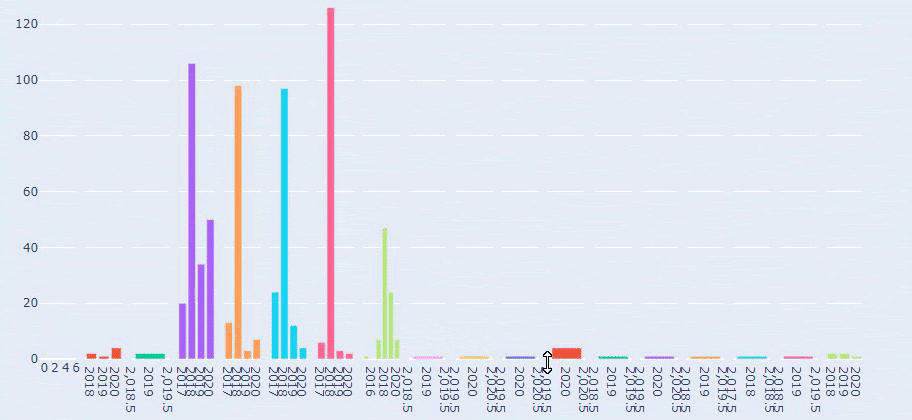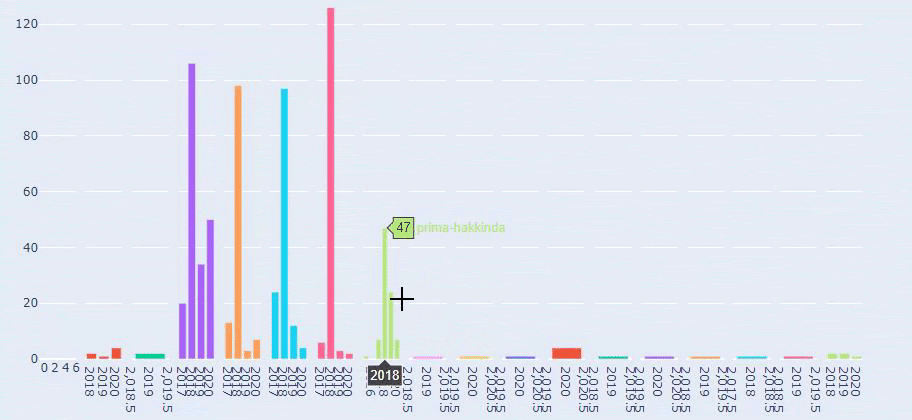
Aceasta este o comparație între tendințele de publicare a conținutului fiecărei categorii de-a lungul anilor pentru Prima.com.tr
Acum, putem compara categoriile de conținut ale celor două site-uri web și tendințele lor de publicare.
Când ne uităm la frecvența de publicare a articolelor de către Prima despre creșterea bebelușului, sarcină și maternitate, vedem o asemănare cu Ilkadimlarim:
- Majoritatea articolelor au fost publicate la un moment dat.
- Nu au fost actualizate de mult.
- Numărul de produse și pagini a fost foarte scăzut în comparație cu numărul de pagini de conținut informativ.
- Recent, tocmai au adăugat produse noi pe site-urile lor.
Putem considera aceste patru caracteristici ca fiind mentalitatea implicită a industriei și putem folosi aceste puncte slabe în favoarea campaniei noastre. La urma urmei, calitatea cere prospețime (după cum a afirmat Amit Singhal, Google Fellow).
În acest moment, vedem, de asemenea, că industria nu este familiarizată cu comportamentul Googlebot. În loc să încărcați 250 de piese de conținut într-o zi și apoi să nu faceți modificări timp de un an, este mai bine să adăugați periodic conținut nou și să actualizați în mod regulat conținutul vechi. Astfel, poți menține calitatea conținutului, Googlebot poate înțelege mai ușor site-ul tău, iar valorile frecvenței cererii de crawlere vor fi mai mari decât concurenții tăi.
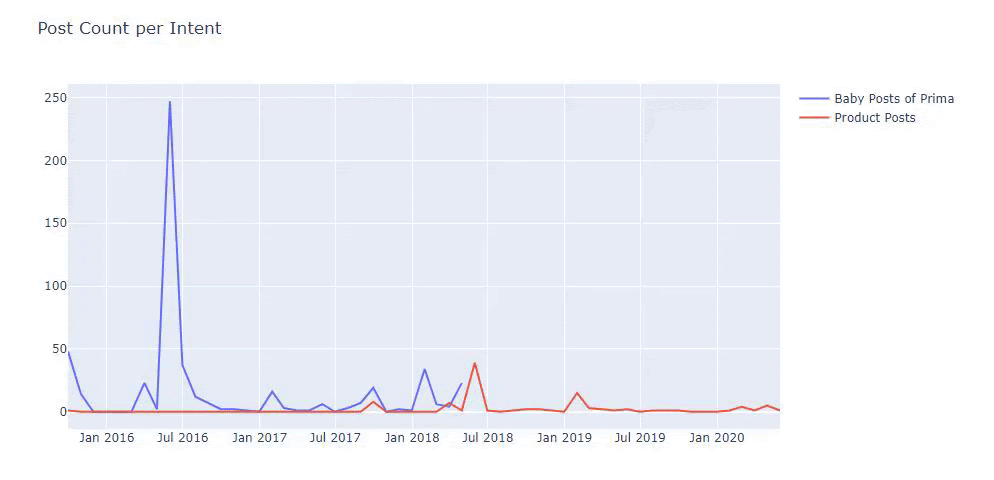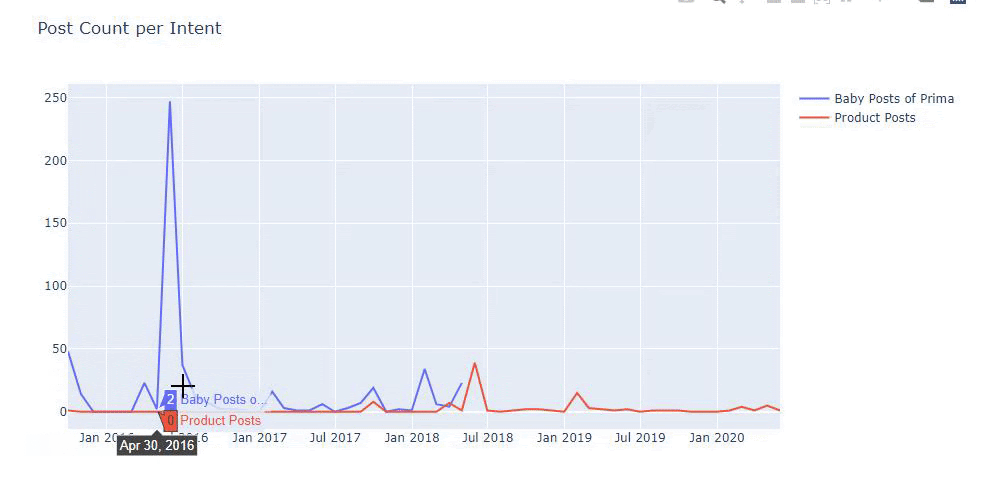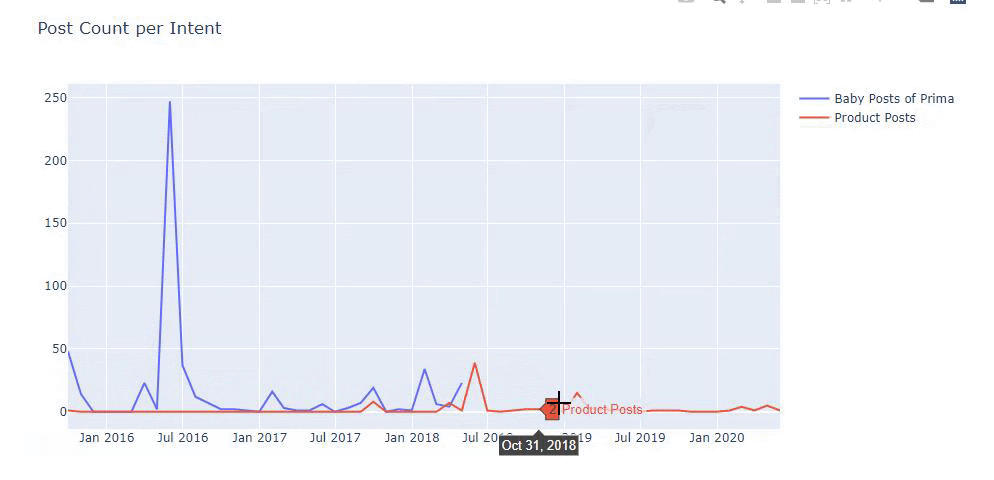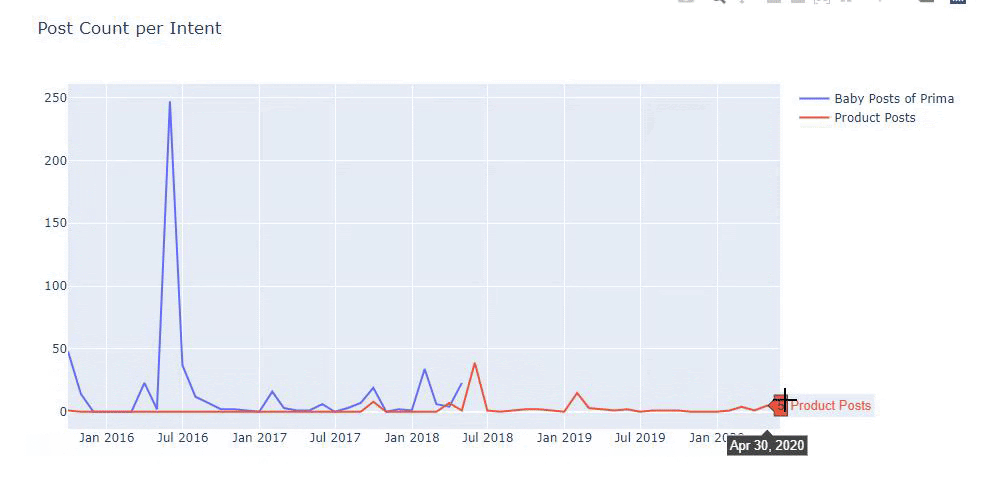
Am folosit metodele anterioare pentru a face distincția între paginile de produs și cele informative și am profilat cele mai utilizate cuvinte în URL-uri. Baby Posts aici înseamnă că acestea sunt conținut informativ.
După cum puteți vedea, au adăugat 247 de conținut într-o singură zi. De asemenea, nu au publicat sau reîmprospătat conținut informativ de peste un an și doar adaugă ocazional câteva pagini de produse noi.
Acum să comparăm tendințele lor de publicare într-o singură cifră, dar cu două parcele diferite. Am folosit codurile de mai jos pentru a crea această figură:
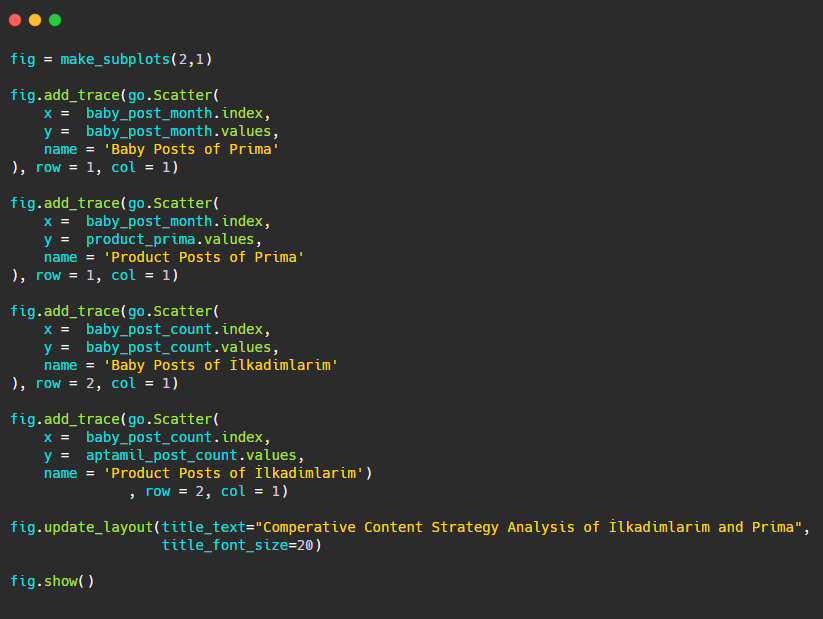
Deoarece această grafică este diferită de cele anterioare, am vrut să vă arăt codul. Aici, două parcele separate sunt plasate în aceeași figură. Pentru aceasta, metoda make_subplots a fost apelată cu comanda de la plotly.subplots import make_subplots.
A fost creată ca o figură cu două rânduri și o coloană cu make_subplots (2,1) .
Prin urmare, col și rând sunt scrise la sfârșitul urmelor și sunt specificate pozițiile acestora. Este un sistem pe care oricine familiarizat cu sistemul grid în CSS îl poate recunoaște cu ușurință.
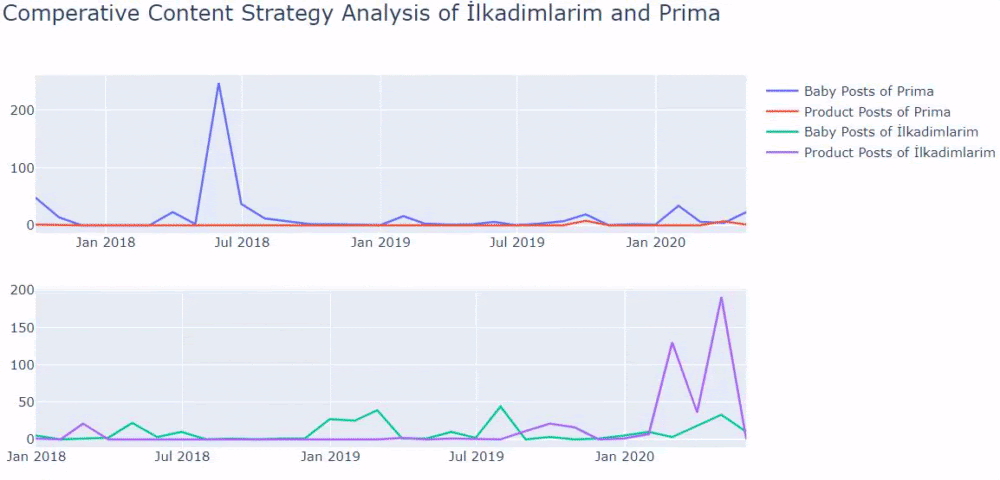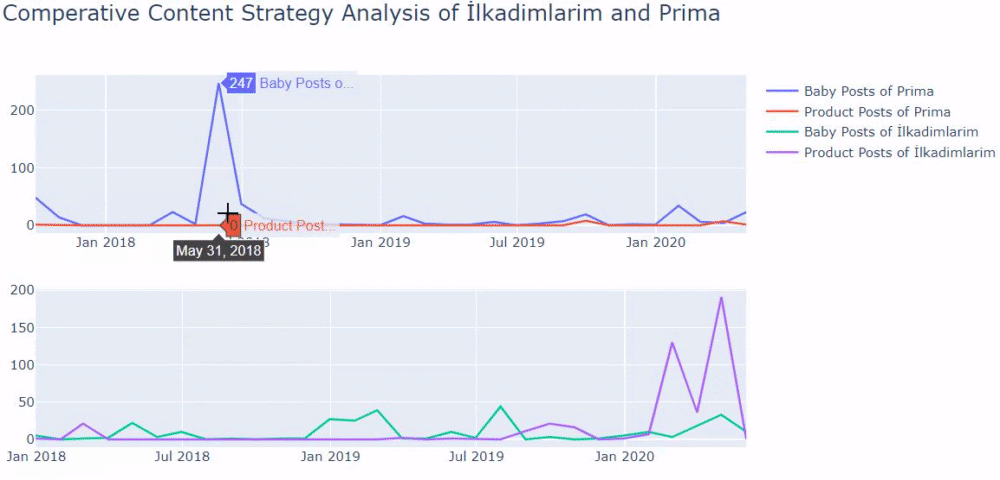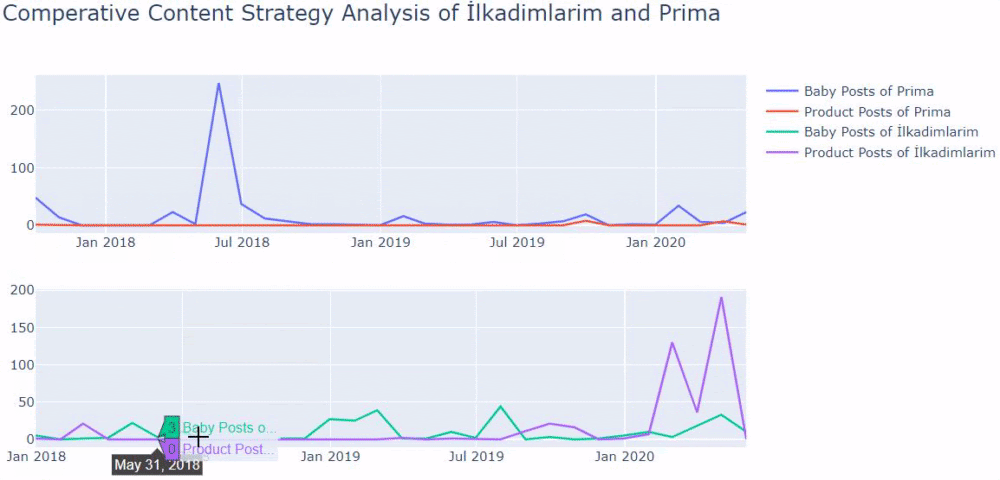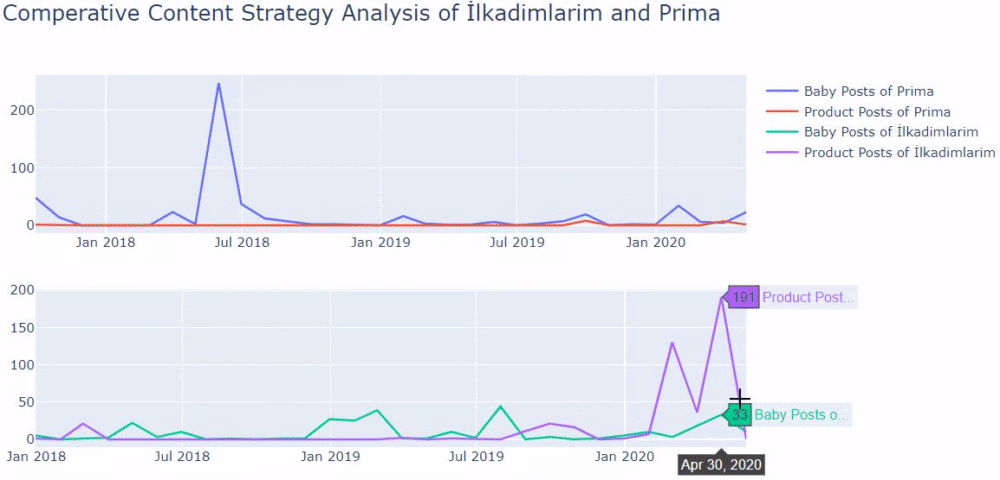
Dacă aveți un client din același sector, puteți utiliza aceste date pentru a crea o strategie de conținut, pentru a vedea punctele slabe ale concurenților și rețeaua lor de interogări/pagini de destinație prin SERP. De asemenea, puteți înțelege ce cantitate de conținut ar trebui să publicați în același domeniu de cunoștințe sau pentru aceeași intenție de utilizator.
Înainte de a încheia ceea ce putem învăța din hărțile de site ca parte a unei analize a strategiei de conținut, putem examina un ultim site web cu un număr mult mai mare de adrese URL dintr-o altă industrie.
Analiza strategiei de conținut a entităților web de știri peste monede cu Python și Sitemaps
În această secțiune vom folosi graficul hărții Seaborn și, de asemenea, câteva metode mai sofisticate de încadrare și extragere a datelor.

Elias Dabbas are o Arhivă Kaggle interesantă și cu adevărat utilă în ceea ce privește Data Science și SEO. Luna aceasta, a deschis o nouă secțiune Kaggle Dataset pentru site-urile de știri din Turcia, pentru ca eu să scriu codurile necesare și să efectuez o analiză a strategiei de conținut cu Advertools prin sitemap-uri.
Înainte de a începe să folosesc aceste tehnici pe Kaggle, aș dori să arăt câteva exemple despre ceea ce s-ar întâmpla dacă am folosi aceleași tehnici pe entități web mai mari în acest articol.
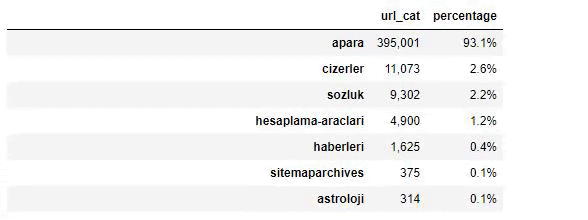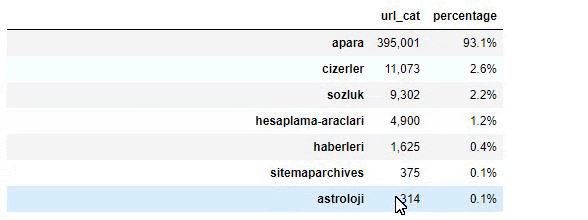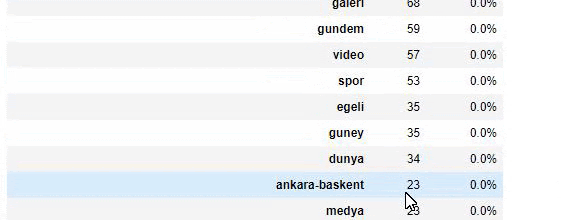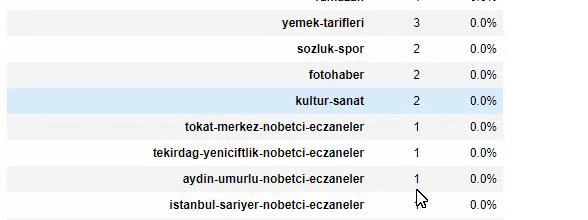
Când analizăm conținutul Ziarului Sabah, vedem că o parte semnificativă a conținutului acestuia (81%) se află într-o categorie numită „apara”. De asemenea, au câteva categorii mari pentru astrologie, calcul, dicționar, vreme și știri despre lume. (Para înseamnă banii în turcă)
Pentru Sabah Newspaper, putem analiza și conținutul cu sitemap-uri pe care le-am colectat doar cu Advertools, dar din moment ce ziarul în cauză este foarte mare, nu l-am preferat din cauza numărului mare de sitemap-uri și a conținutului diferitelor sitemap-uri care conțin aceeași URL Categorie.
Mai jos puteți vedea și excesul de sitemap-uri cu Advertools.
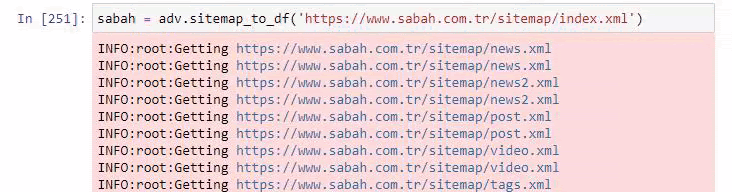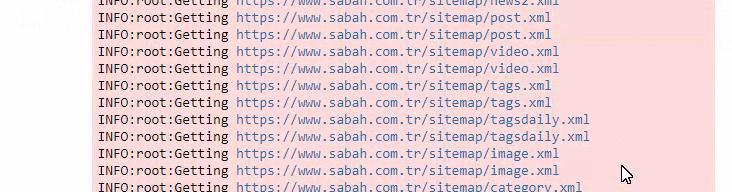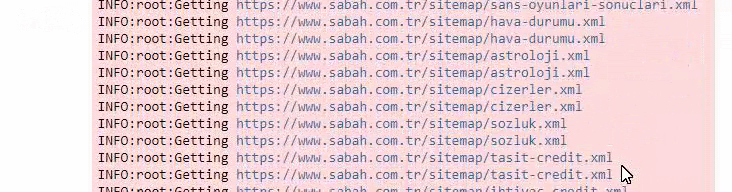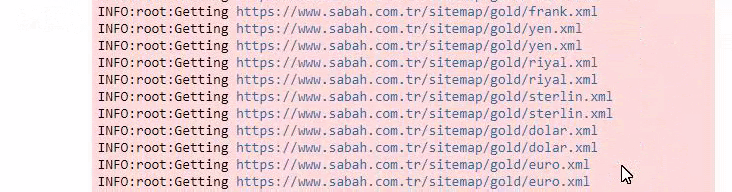
S-ar putea să vedem că au sitemap-uri diferite pentru aceleași categorii URL, cum ar fi Aur, Credit, Monede, Etichete, Orele de rugăciune și Orele de lucru ale farmaciei etc...
Pe scurt, putem obține aceste detalii concentrându-ne pe subcategorii de URL-uri. În loc să unificați diferite sitemap-uri prin variabile. Deci, am unificat toate sitemapurile cu metoda sitemap_to_df() de la Advertools, ca la începutul articolului.
De asemenea, putem folosi un alt set de funcții create de Elias Dabbas pentru a crea cadre de date mai bune. Dacă verificați funcțiile dataset_utitilites, puteți vedea câteva exemple. Codul de mai jos oferă totalul și procentul unei expresii regex URL specificate împreună cu suma cumulativă prin stilizare.
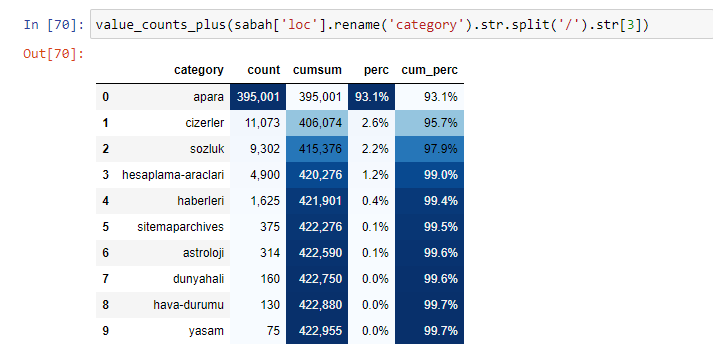
Dacă facem același lucru cu o defalcare sub-URL a Ziarului Sabah, vom obține următorul rezultat.
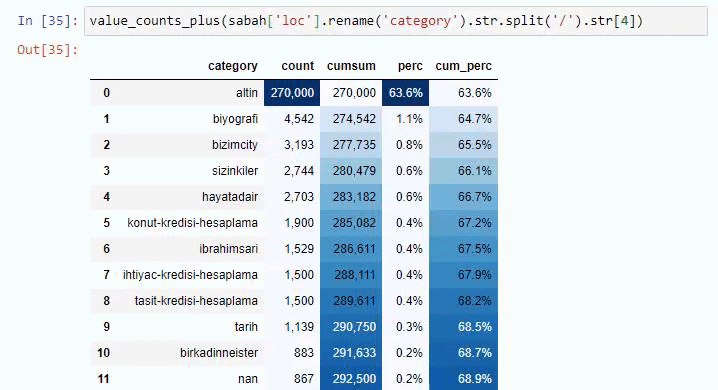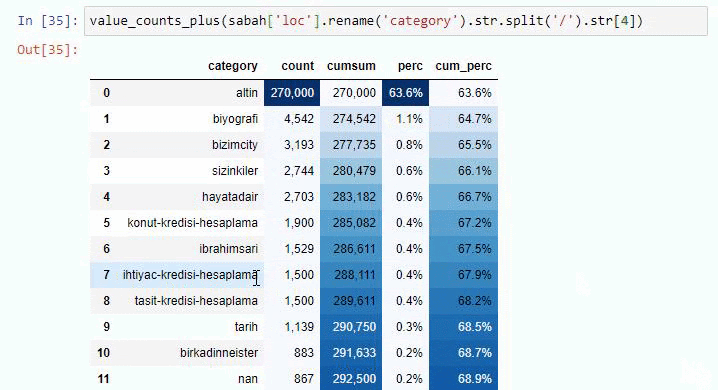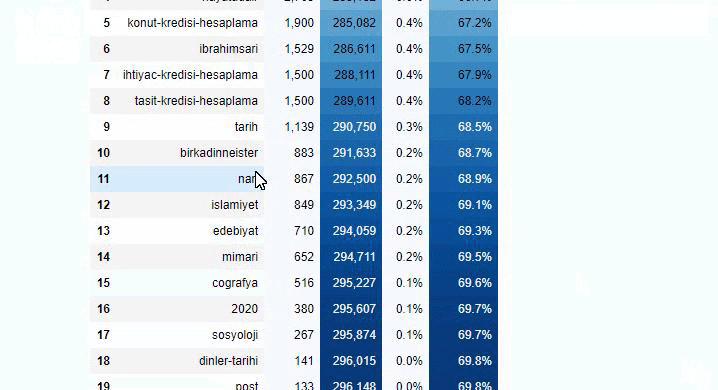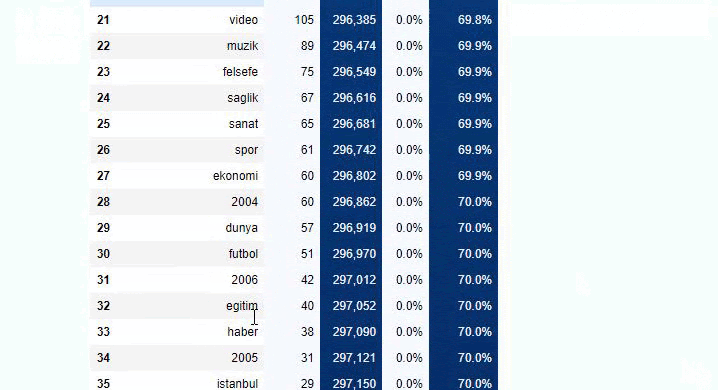
Puteți crește numărul de linii pe care funcția în cauză le va scoate prin schimbarea liniei de mai jos. De asemenea, dacă examinați conținutul funcției, veți vedea că este similară cu cele pe care le-am folosit anterior.
În sub-breakings, vedem diferite defalcări precum „Istoria religiei”, „Biografie”, „Nume de orașe”, „Fotbal”, „Bizimcity (Caricatură)”, „Credit ipotecar”. Cea mai mare defalcare este în categoria „Aur”.
Deci, cum poate un ziar să aibă 295.000 de adrese URL pentru prețurile aurului?
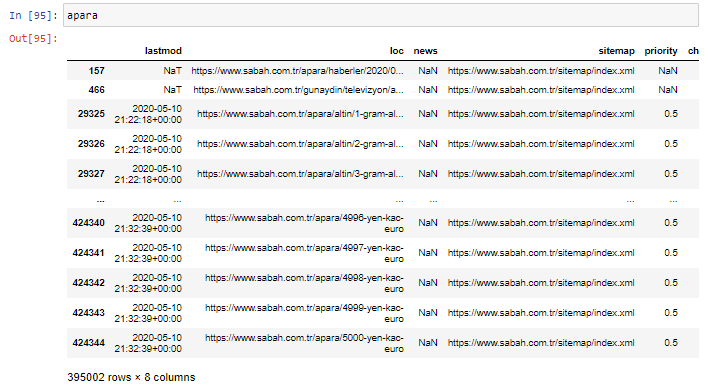
În primul rând, arunc într-o variabilă toate adresele URL care conțin „apara” din prima defalcare URL a Ziarului Sabah.
apara = sabah[sabah['loc'].str.contains('apara')]
Iată rezultatul:
De asemenea, putem filtra coloanele cu metoda .filter():
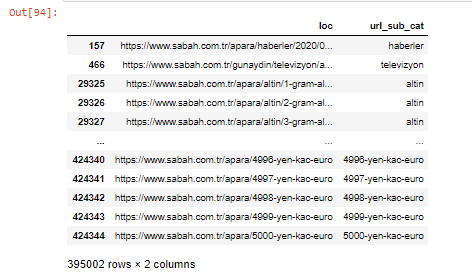
Acum, putem vedea în partea de jos a DataFrame de ce Sabah Newspaper are o cantitate excesivă de adrese URL Apara, deoarece au deschis diferite pagini web pentru fiecare sumă de calcul valutar, cum ar fi 5000 de euro, 4999 de euro, 4998 de euro și multe altele...
Dar, înainte de orice concluzie, trebuie să fim siguri, deoarece peste 250.000 dintre aceste adrese URL aparțin categoriei „altin (aur)”.
apara.filter(['loc', 'url_sub_cat' ]).tail(60) ne va arăta ultimele 60 de rânduri ale acestui cadru de date:

Putem face același lucru pentru defalcarea adresei URL de aur în cadrul grupului Apara.
aur = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
În acest moment, vedem că Sabah Newspaper a deschis 5000 de pagini diferite pentru a converti fiecare monedă în dolar, euro, aur și TL (lire turcești). Există o pagină de calcul separată pentru fiecare unitate de bani între 1 și 5000. Puteți vedea mai jos exemplul primelor 85 și ultimelor 85 de linii ale grupului de aur. A fost deschisă o pagină separată pentru fiecare gram de preț de aur.


Nu avem nicio îndoială că aceste pagini sunt inutile, cu o mulțime de conținut duplicat și excesiv de mari, dar Sabah Newspaper este un site atât de puternic, încât Google continuă să îl arate în aproape fiecare interogare, clasament de top.
În acest moment, putem vedea, de asemenea, că Toleranța costurilor cu crawlere este mare pentru un site de știri vechi cu autoritate ridicată.
Cu toate acestea, acest lucru nu explică de ce categoria de aur are mai multe adrese URL decât altele.
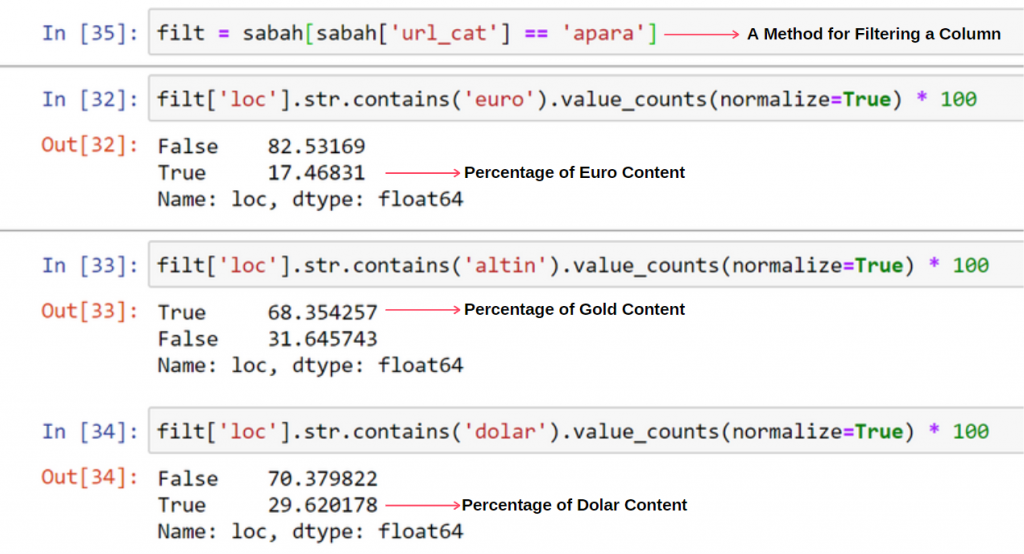
Nu văd nimic ciudat că valorile suprapuse se adună mai mult de 100%.
Dacă nu îmi lipsește ceva?
După cum veți observa, când adăugăm toate valorile adevărate, obținem rezultatul de 115,16%. Motivul pentru aceasta este mai jos.
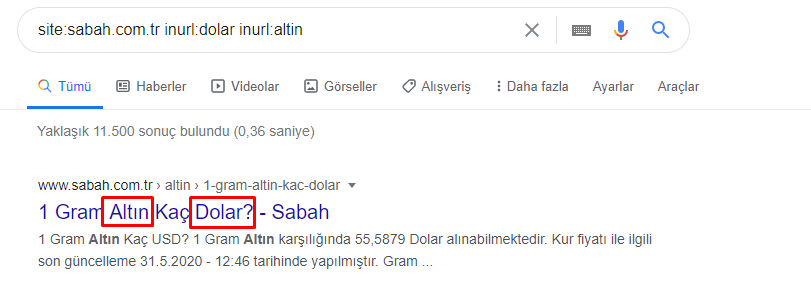
Chiar și grupul principal are o intersecție unul cu celălalt astfel. Am putea analiza și aceste intersecții, dar ar putea face obiectul unui alt articol.
Vedem că 68% din conținutul grupului de adrese URL Apara sunt legate de GOLD.
Pentru a înțelege mai bine această situație, primul lucru pe care trebuie să-l facem este să scanăm URL-urile din refracția aurului.
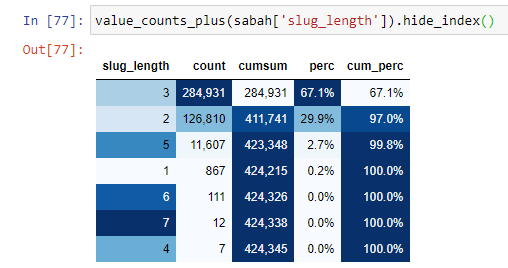
Când clasificăm adresele URL în funcție de cantitatea de „/” pe care o au de la secțiunea rădăcină, vedem că numărul de adrese URL cu maxim 3 pauze este mare. Când analizăm aceste adrese URL, vedem că 270.000 dintre cele 3 adrese URL slug_length sunt în categoria Gold.
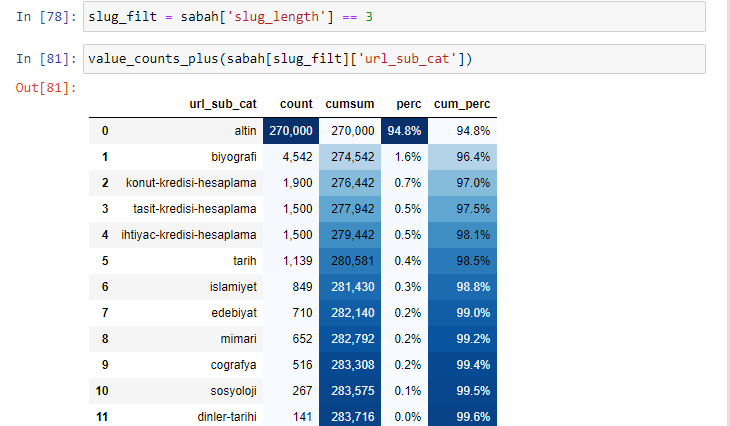
morning_filt = morning ['slug_length'] == 3 Înseamnă că le primești doar pe cele care sunt egale cu 3 din grupul de date de tip de date int într-o anumită coloană a unui anumit cadru de date. Apoi, pe baza acestor informații, încadrăm adresele URL care sunt convenabile condiției cu numărul, sumele și ratele de agregare cu suma cumulativă.
Când extragem cele mai frecvent utilizate cuvinte din URL-urile de aur, întâlnim cuvinte care reprezintă „plin”, „republică”, „sfert”, „gram”, „jumătate”, „strămoș”. Tipurile de aur Ata și Republic sunt unice pentru Turcia. Unul dintre ei reprezintă Suveranitatea Turciei, iar celălalt este Fondatorul Republicii, Kemal Ataturk. De aceea, volumele lor de căutare de interogări sunt mari.
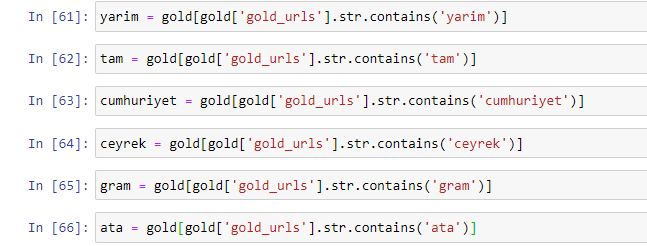
În primul rând, am eliminat cuvintele comune găsite în adresele URL și le-am atribuit unor variabile separate. În continuare, vom folosi aceste variabile în Gold DataFrame pentru a crea coloane specifice tipurilor lor.
După ce creăm coloane noi prin variabile, trebuie să le filtram împreună cu valori booleene.
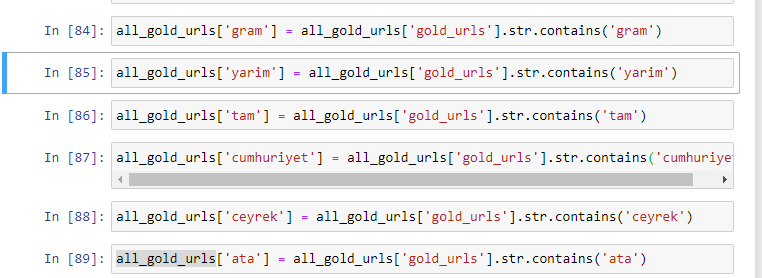
După cum puteți vedea, am putut clasifica toate adresele URL de aur cu 270.000 de rânduri și 6 coloane. Principalul motiv pentru numărul mare de pagini specifice aurului este că dolarul sau euro nu au tipuri separate, în timp ce aurul are tipuri separate. În același timp, diversitatea de încrucișare a paginilor între aur și diferite valute este mai mare decât alte valute, datorită încrederii lor tradiționale în poporul turc.
După părerea mea, toate tipurile de pagini de aur ar trebui distribuite în mod egal, nu?
Putem testa cu ușurință acest lucru cu funcția Seaborn Heatmap.
import seaborn ca sns
import matplotlib.pyplot ca plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
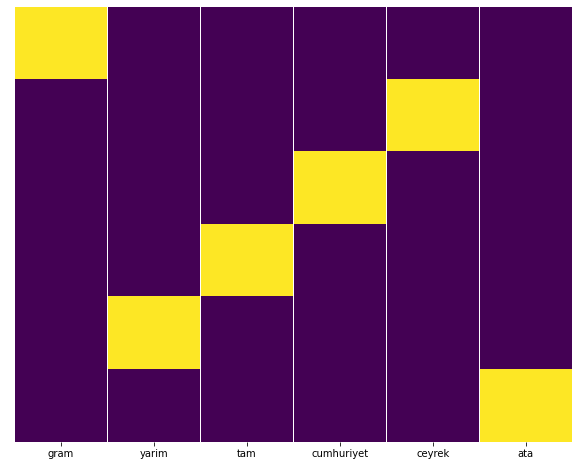
Aici, pe harta termică, adevărurile din fiecare coloană sunt pur și simplu marcate. După cum se poate vedea, dimensiunea fiecăruia este simetrică între ele și este ordonată pe hartă.
Astfel, am luat o perspectivă largă asupra politicii de conținut a ziarului Sabah.com.tr despre monede și calculul valutar.
În viitor, voi scrie site-uri de știri turcești și strategiile lor de conținut bazate pe Sitemaps Kaggle, care a fost lansat de Elias Dabbas, dar în acest articol am vorbit destul despre ceea ce poate fi descoperit atât pe site-urile mari, cât și pe cele mici, cu sitemap-uri. .
Concluzie și concluzii
Cred că am văzut cât de ușor este să înțelegi un site web, datorită unei structuri URL netede și semantice. De asemenea, ar trebui să ne amintim cât de valoroasă poate fi o structură URL adecvată pentru Google.
În viitor, vom vedea o mulțime de SEO care sunt din ce în ce mai familiarizați cu știința datelor, vizualizarea datelor, programarea front-end și multe altele... Văd acest proces ca un început al schimbării inevitabile: decalajul dintre SEO și dezvoltatori va fi complet închis. in cativa ani.
Cu Python, puteți duce acest tip de analiză și mai departe: este posibil să obțineți date de la înțelegerea opiniilor politice ale unui site de știri, la cine scrie despre ce, cât de des și cu ce sentimente. Prefer să nu intru aici, deoarece aceste procese sunt mai mult despre știința datelor pură decât SEO (și acest articol este deja destul de lung).
Dar dacă sunteți interesat, există multe alte tipuri de audituri care pot fi efectuate prin Sitemaps și Python, cum ar fi verificarea codurilor de stare ale URL-urilor dintr-un sitemap.
Aștept cu nerăbdare să experimentez și să partajez alte sarcini SEO pe care le puteți face cu Python și Advertools.