
Înțelegerea inteligenței artificiale: cum am predat limbajul natural al computerelor
Publicat: 2023-11-28Expresia „inteligență artificială” a fost folosită în legătură cu computerele încă din anii 1950, dar până în ultimul an, majoritatea oamenilor au crezut probabil că AI era încă mai mult SF decât realitate tehnologică.
Apariția ChatGPT de la OpenAI în noiembrie 2022 a schimbat brusc percepția oamenilor cu privire la ceea ce era capabilă învățarea automată – dar ce anume a fost la ChatGPT care a făcut lumea să se ridice și să realizeze că inteligența artificială este aici într-un mod mare?
Într-un cuvânt, limba – motivul pentru care ChatGPT s-a simțit ca un salt atât de remarcabil înainte a fost din cauza modului în care părea fluent în limbajul natural într-un mod în care niciun chatbot nu a mai fost vreodată.
Aceasta marchează o nouă etapă remarcabilă a „prelucrării limbajului natural” (NLP), capacitatea computerelor de a interpreta limbajul natural și de a genera răspunsuri convingătoare. ChatGPT este construit pe un „model de limbă mare” (LLM), care este un tip de rețea neuronală care utilizează învățarea profundă instruită pe seturi de date masive care pot procesa și genera conținut.
„Cum a reușit un program de calculator să obțină o asemenea fluență lingvistică?”
Dar cum am ajuns aici? Cum a obținut un program de calculator o asemenea fluență lingvistică? Cum sună atât de uman?
ChatGPT nu a fost creat în vid – s-a construit pe nenumărate inovații și descoperiri diferite din ultimele decenii. Seria de descoperiri care au condus la ChatGPT au fost toate repere în informatică, dar este posibil să le vedem ca mimând etapele prin care oamenii dobândesc limbajul.
Cum învățăm limba?
Pentru a înțelege cum AI a ajuns în această etapă, merită să luăm în considerare natura învățării limbilor în sine – începem cu cuvinte unice și apoi începem să le combinăm în secvențe mai lungi până când putem comunica concepte, idei și instrucțiuni complexe.
De exemplu, unele etape comune ale dobândirii limbajului la copii sunt:
- Etapa holofrastică: Între 9-18 luni, copiii învață să folosească cuvinte unice care descriu nevoile sau dorințele lor de bază. Comunicarea cu un singur cuvânt înseamnă că se pune accent pe claritate în detrimentul completității conceptuale. Dacă unui copil îi este foame, nu va spune „Vreau ceva de mâncare” sau „Mi-e foame”, ci va spune pur și simplu „mâncare” sau „lapte”.
- Etapa cu două cuvinte: în timpul vârstei de 18-24 de luni, copiii încep să folosească gruparea simplă a două cuvinte pentru a-și îmbunătăți abilitățile de comunicare. Acum își pot comunica sentimentele și nevoile cu expresii precum „mai multă mâncare” sau „citește cartea”.
- Etapa telegrafică: Între 24-30 de luni copiii încep să înșire mai multe cuvinte împreună pentru a forma fraze și propoziții mai complexe. Numărul de cuvinte folosite este încă mic, dar încep să apară ordinea corectă a cuvintelor și mai multă complexitate. Copiii încep să învețe construcția de bază a propozițiilor, cum ar fi „Vreau să-i arăt mamii”.
- Etapa cu mai multe cuvinte: După 30 de luni, copiii încep să treacă la etapa cu mai multe cuvinte. În această etapă, copiii încep să folosească propoziții mai corecte din punct de vedere gramatical și mai complexe și cu mai multe propoziții. Aceasta este etapa finală a dobândirii limbajului, iar copiii comunică în cele din urmă cu propoziții complexe, cum ar fi „Dacă plouă, vreau să rămân și să mă joc”.
Una dintre primele etape cheie în achiziția limbii este capacitatea de a începe să folosești cuvinte individuale într-un mod foarte simplu. Așadar, primul obstacol pe care trebuie să-l depășească cercetătorii AI a fost cum să antreneze modele pentru a învăța asocieri simple de cuvinte.
Model 1 – Învățarea cuvintelor individuale cu Word2Vec (hârtia 1 și lucrarea 2)
Unul dintre primele modele de rețele neuronale care a încercat să învețe asocierile de cuvinte în acest fel a fost Word2Vec, dezvoltat de Tomaš Mikolov și un grup de cercetători de la Google. A fost publicat în două lucrări în 2013 (ceea ce arată cât de repede s-au dezvoltat lucrurile în acest domeniu).
Aceste modele au fost antrenate prin învățarea să asocieze cuvinte care au fost utilizate în mod obișnuit împreună. Această abordare s-a bazat pe intuiția primilor pionieri lingvistici, cum ar fi John R. Firth, care a remarcat că semnificația ar putea fi derivată din asociere de cuvinte: „Veți cunoaște un cuvânt după compania pe care o păstrează.”
Ideea este că cuvintele care au un înțeles semantic similar tind să apară mai frecvent împreună. Cuvintele „pisici” și „câini” ar apărea, în general, mai frecvent împreună decât cu cuvinte precum „mere” sau „calculatoare”. Cu alte cuvinte, cuvântul „pisică” ar trebui să fie mai asemănător cu cuvântul „câine” decât „pisica” cu „măr” sau „computer”.
Lucrul interesant despre Word2Vec este modul în care a fost instruit să învețe aceste asocieri de cuvinte:
- Ghiciți cuvântul țintă: modelului i se dă un număr fix de cuvinte ca intrare cu cuvântul țintă lipsă și a trebuit să ghicească cuvântul țintă lipsă. Acest lucru este cunoscut sub numele de Continuous Bag Of Words (CBOW).
- Ghiciți cuvintele din jur: modelului i se dă un singur cuvânt și apoi este însărcinat să ghicească cuvintele din jur. Acest lucru este cunoscut sub numele de Skip-Gram și este abordarea opusă CBOW prin faptul că prezicem cuvintele din jur.
Un avantaj al acestor abordări este că nu trebuie să aveți date etichetate pentru a antrena modelul – etichetarea datelor, de exemplu, descrierea textului ca „pozitiv” sau „negativ” pentru a preda analiza sentimentelor, este o muncă lentă și laborioasă, până la urmă.
Unul dintre cele mai surprinzătoare lucruri despre Word2Vec au fost relațiile semantice complexe pe care le-a capturat printr-o abordare de instruire relativ simplă. Word2Vec scoate vectori care reprezintă cuvântul de intrare. Efectuând operații matematice pe acești vectori, autorii au reușit să arate că vectorii de cuvinte nu au capturat doar elemente similare din punct de vedere sintactic, ci și relații semantice complexe.
Aceste relații sunt legate de modul în care sunt folosite cuvintele. Exemplul pe care l-au notat autorii a fost relația dintre cuvinte precum „Rege” și „Regina” și „Bărbat” și „Femeie”.
Dar, deși a fost un pas înainte, Word2Vec a avut limite. Avea o singură definiție per cuvânt – de exemplu, știm cu toții că „bancă” poate însemna lucruri diferite, în funcție de dacă intenționați să țineți una sau să pescuiți dintr-unul. Nu-i păsa lui Word2Vec, doar avea o definiție a cuvântului „bancă” și o folosea în toate contextele.
Mai presus de toate, Word2Vec nu a putut procesa instrucțiuni sau chiar propoziții. Putea să ia doar un cuvânt ca intrare și să scoată o „încorporare a cuvântului” sau o reprezentare vectorială, pe care a învățat-o pentru acel cuvânt. Pentru a construi pe baza acestui singur cuvânt, cercetătorii au trebuit să găsească o modalitate de a înșira două sau mai multe cuvinte împreună într-o secvență. Ne putem imagina acest lucru ca fiind similar cu stadiul de două cuvinte al dobândirii limbajului.
Modelul 2 – Învățarea secvențelor de cuvinte cu RNN-uri și Secvențe de text
Odată ce copiii au început să stăpânească utilizarea unui singur cuvânt, ei încearcă să pună cuvinte împreună pentru a exprima gânduri și sentimente mai complexe. În mod similar, următorul pas în dezvoltarea NLP a fost dezvoltarea capacității de a procesa secvențe de cuvinte. Problema procesării secvențelor de text este că nu au lungime fixă. Lungimea unei propoziții poate varia de la câteva cuvinte la un paragraf lung. Nu toată secvența va fi importantă pentru sensul și contextul general. Dar trebuie să fim capabili să procesăm întreaga secvență pentru a ști care părți sunt cele mai relevante.
Acolo au apărut rețelele neuronale recurente (RNN).
Dezvoltat în anii 1990, un RNN funcționează prin procesarea intrării sale într-o buclă în care ieșirea de la pașii anteriori este transportată prin rețea pe măsură ce iterează fiecare pas din secvență.
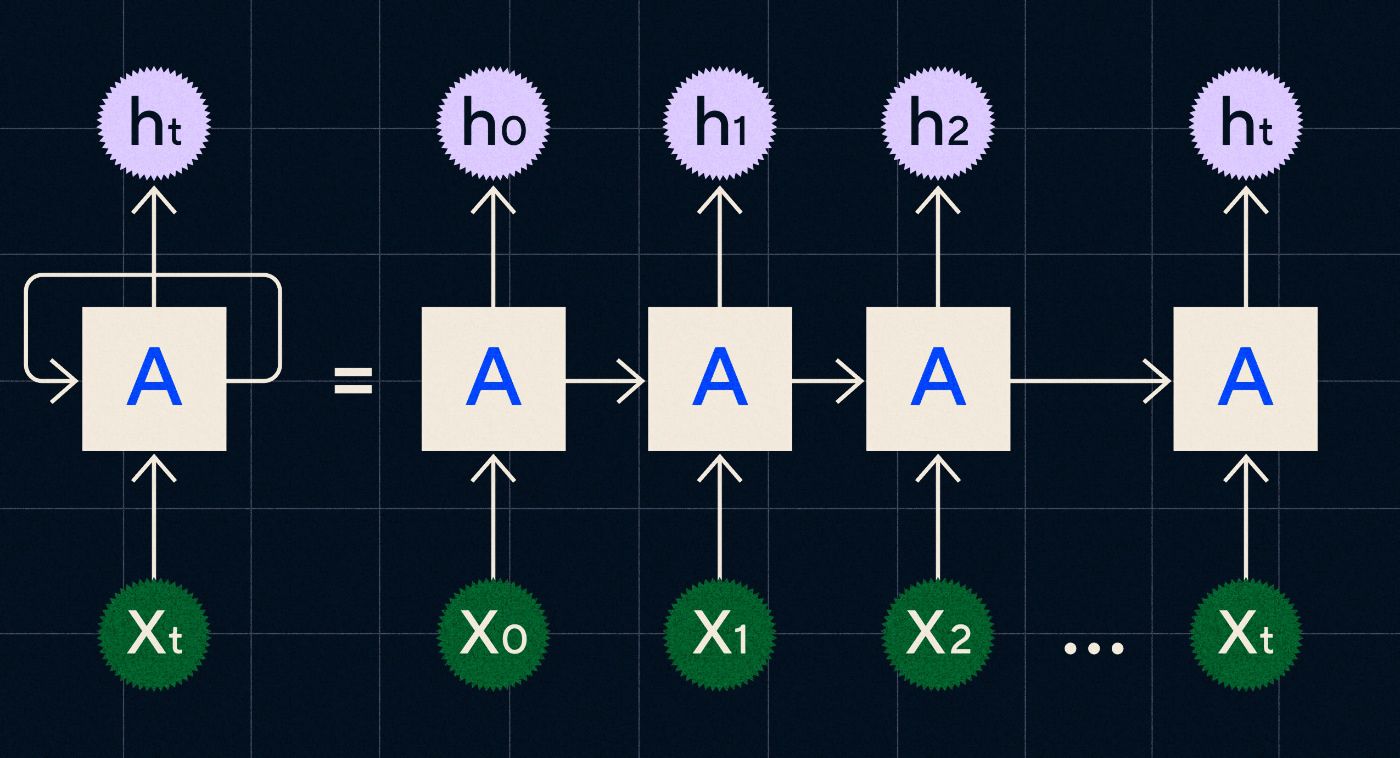
Sursa: postarea pe blog a lui Christopher Olah pe RNNs
Diagrama de mai sus arată cum să imaginezi un RNN ca o serie de rețele neuronale (A) în care rezultatul pasului anterior (h0, h1, h2…ht) este transmis la pasul următor. În fiecare pas, o nouă intrare (X0, X1, X2 … Xt) este, de asemenea, procesată de rețea.
RNN-urile (și în special rețelele de memorie pe termen scurt, sau LSTM, un tip special de RNN introdus de Sepp Hochreiter și Jurgen Schmidhuber în 1997) ne-au permis să creăm arhitecturi de rețele neuronale care ar putea îndeplini sarcini mai complexe, cum ar fi traducerea.
În 2014, a fost publicată o lucrare de Ilya Sutskever (un co-fondator al OpenAI), Oriol Vinyals și Quoc V Le la Google, care descrie modelele Sequence to Sequence (Seq2Seq). Această lucrare a arătat cum ați putea antrena o rețea neuronală să preia un text de intrare și să returneze o traducere a acelui text. Vă puteți gândi la acesta ca la un exemplu timpuriu al unei rețele neuronale generative, în care îi oferiți un prompt și returnează un răspuns. Cu toate acestea, sarcina a fost rezolvată, așa că, dacă a fost instruită în traducere, nu ați putea să-i „provocați” să facă altceva.
Amintiți-vă că modelul anterior, Word2Vec, putea procesa doar cuvinte individuale. Deci, dacă i-ați transmite o propoziție de genul „dentistul mi-a tras dintele”, ar genera pur și simplu un vector pentru fiecare cuvânt, ca și cum ar fi fără legătură.
Cu toate acestea, ordinea și contextul sunt importante pentru sarcini precum traducerea. Nu puteți traduce doar cuvinte individuale, trebuie să analizați secvențe de cuvinte și apoi să afișați rezultatul. Aici RNN-urile au permis modelelor Seq2Seq să proceseze cuvintele în acest fel.
Cheia modelelor Seq2Seq a fost proiectarea rețelei neuronale, care a folosit două RNN-uri spate în spate. Unul a fost un codificator care a transformat intrarea din text într-o încorporare, iar celălalt a fost un decodor care a luat ca intrare înglobarea rezultată de codificator:
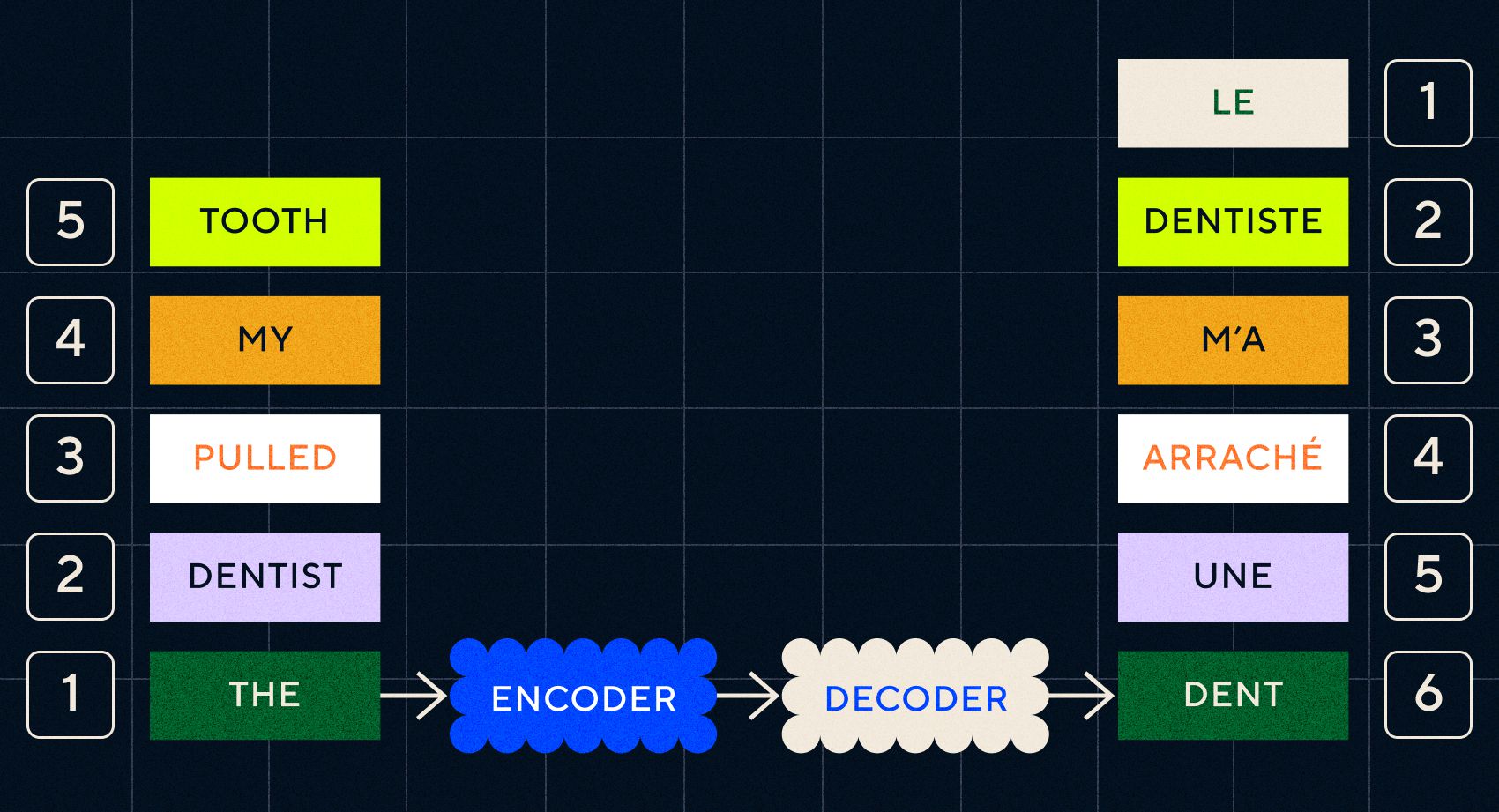
Odată ce codificatorul a procesat intrările în fiecare pas, apoi începe să treacă ieșirea către decodor, care transformă înglobările într-un text tradus.
Putem vedea odată cu evoluția acestor modele că încep să semene, într-o formă simplă, cu ceea ce vedem astăzi cu ChatGPT. Cu toate acestea, putem vedea și cât de limitate au fost aceste modele în comparație. Ca și în cazul dezvoltării proprii a limbajului, pentru a îmbunătăți cu adevărat abilitățile lingvistice trebuie să știm exact la ce să fim atenți pentru a crea fraze și propoziții mai complexe.
Model 3 – Învățare prin atenție și scalare cu Transformers
Am observat mai devreme că etapele telegrafice au fost cele în care copiii au început să creeze propoziții scurte cu două sau mai multe cuvinte. Un aspect cheie al acestei etape a însuşirii limbajului este că copiii încep să înveţe cum să construiască propoziţii adecvate.
Modelele RNN și Seq2Seq au ajutat modelele lingvistice să proceseze mai multe secvențe de cuvinte, dar erau încă limitate în lungimea propozițiilor pe care le puteau procesa. Pe măsură ce lungimea propoziției crește, trebuie să fim atenți la majoritatea lucrurilor din propoziție.
De exemplu, luați următoarea propoziție „Era atât de multă tensiune în cameră încât ați putea să o tăiați cu un cuțit”. Se întâmplă multe acolo. Pentru a ști că nu tăiem literalmente ceva cu un cuțit aici, trebuie să legăm „tăiat” cu „tensiune” mai devreme în propoziție.
Pe măsură ce lungimea propoziției crește, devine mai dificil să știi la ce cuvinte se referă la care pentru a deduce sensul propriu-zis. Aici RNN-urile au început să întâlnească limite și aveam nevoie de un nou model pentru a trece la următoarea etapă de achiziție a limbajului.
„Gândiți-vă să încercați să rezumați o conversație pe măsură ce aceasta devine din ce în ce mai lungă cu o limită fixă de cuvinte. La fiecare pas începi să pierzi din ce în ce mai multe informații”
În 2017, un grup de cercetători de la Google a publicat o lucrare care a propus o tehnică care să permită mai bine modelelor să acorde atenție contextului important dintr-o bucată de text.
Ceea ce au dezvoltat a fost o modalitate prin care modelele de limbaj pot căuta mai ușor contextul de care aveau nevoie în timp ce procesează o secvență de introducere a textului. Ei au numit această abordare „arhitectură transformatoare” și a reprezentat cel mai mare salt înainte în procesarea limbajului natural de până acum.
Acest mecanism de căutare face mai ușor pentru model să identifice care dintre cuvintele anterioare a oferit mai mult context cuvântului curent care este procesat. RNN-urile încearcă să ofere context prin transmiterea unei stări agregate a tuturor cuvintelor care au fost deja procesate la fiecare pas. Gândiți-vă să încercați să rezumați o conversație pe măsură ce aceasta devine din ce în ce mai lungă cu o limită fixă de cuvinte. La fiecare pas începi să pierzi din ce în ce mai multe informații. În schimb, transformatorii au ponderat cuvintele (sau jetoanele, care nu sunt cuvinte întregi, ci părți de cuvinte) pe baza importanței lor pentru cuvântul curent în ceea ce privește contextul său. Acest lucru a făcut mai ușor să proceseze secvențe din ce în ce mai lungi de cuvinte fără blocajele observate în RNN-uri. Acest nou mecanism de atenție a permis, de asemenea, ca textul să fie procesat în paralel și nu secvenţial ca un RNN.
Așa că imaginați-vă o propoziție de genul „Animalul nu a traversat strada pentru că era prea obosit”. Pentru un RNN ar trebui să reprezinte toate cuvintele anterioare la fiecare pas. Pe măsură ce numărul de cuvinte între „el” și „animal” crește, devine mai dificil pentru RNN să identifice contextul adecvat.

Cu arhitectura transformatorului, modelul are acum capacitatea de a căuta cuvântul care se referă cel mai probabil la „el”. Diagrama de mai jos arată modul în care modelele de transformatoare sunt capabile să se concentreze pe partea „animalului” a textului în timp ce încearcă să proceseze o propoziție.
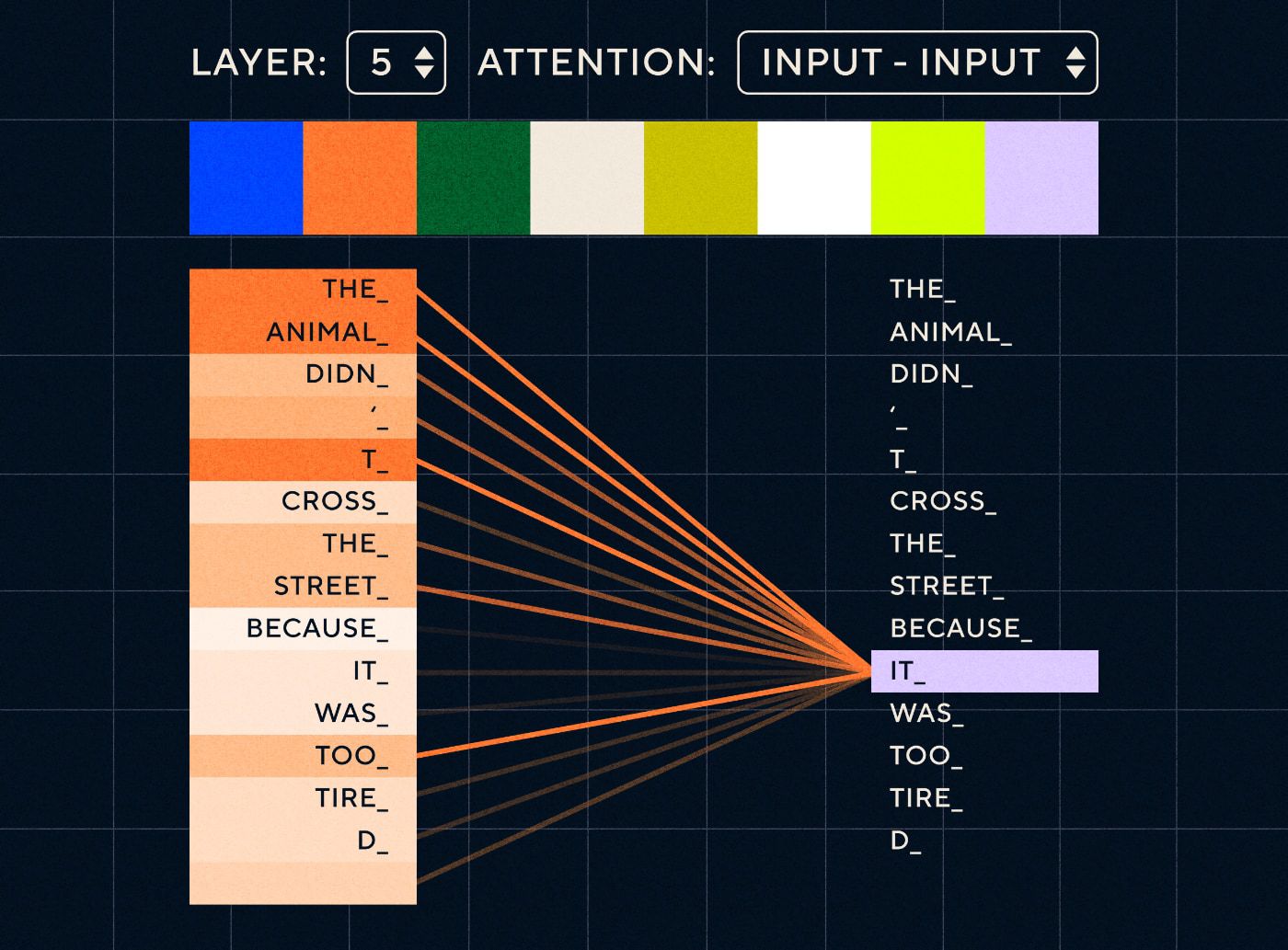
Sursa: The Illustrated Transformer
Diagrama de mai sus arată atenția la nivelul 5 al rețelei. La fiecare strat, modelul își construiește înțelegerea propoziției și „acordă atenție” unei anumite părți a intrării pe care o consideră mai relevantă pentru pasul pe care îl procesează în acel moment, adică acordă mai multă atenție „pentru animal” pentru „ea” din acest strat. Sursa: Transformerul ilustrat
Gândiți-vă la asta ca la o bază de date în care poate prelua cuvântul cu cel mai mare scor care este cel mai probabil legat de „el”.
Odată cu această dezvoltare, modelele de limbaj nu s-au limitat la analizarea unor secvențe textuale scurte. În schimb, puteți utiliza secvențe de text mai lungi ca intrări. Știm că expunerea copiilor la mai multe cuvinte prin intermediul „conversației antrenate” ajută la îmbunătățirea dezvoltării limbajului lor.
În mod similar, cu noul mecanism de atenție, modelele de limbaj au putut analiza mai multe și variate tipuri de date de instruire textuală. Acestea au inclus articole Wikipedia, forumuri online, Twitter și orice alte date text pe care le-ați putea analiza. Ca și în cazul dezvoltării copilăriei, expunerea la toate aceste cuvinte și utilizarea lor în contexte diferite a ajutat modelele lingvistice să dezvolte capacități lingvistice noi și mai complicate.
În această fază am început să vedem o cursă de scalare în care oamenii aruncau din ce în ce mai multe date asupra acestor modele pentru a vedea ce ar putea învăța. Aceste date nu trebuiau să fie etichetate de oameni – cercetătorii puteau pur și simplu să răzuiască internetul și să-l alimenteze modelului și să vadă ce a învățat.
„Modele precum BERT au doborât fiecare record de procesare a limbajului natural disponibil. De fapt, seturile de date de testare care au fost folosite pentru aceste sarcini au fost mult prea simple pentru aceste modele de transformatoare.”
Modelul BERT (Bidirectional Encoder Representations from Transformers) merită o mențiune specială din câteva motive. A fost unul dintre primele modele care a folosit caracteristica de atenție care este nucleul arhitecturii Transformer. În primul rând, BERT era bidirecțională, deoarece putea privi textul atât în stânga, cât și în dreapta intrării curente. Acest lucru era diferit de RNN-urile care puteau procesa textul numai secvenţial de la stânga la dreapta. În al doilea rând, BERT a folosit, de asemenea, o nouă tehnică de antrenament numită „mascare”, care, într-un fel, a forțat modelul să învețe semnificația diferitelor intrări prin „ascunderea” sau „mascarea” jetoane aleatoare pentru a se asigura că modelul nu poate „trișa” și concentrați-vă pe un singur token în fiecare iterație. Și, în cele din urmă, BERT ar putea fi ajustat pentru a îndeplini diferite sarcini NLP. Nu a trebuit să fie antrenat de la zero pentru aceste sarcini.
Rezultatele au fost uimitoare. Modele precum BERT au doborât fiecare record de procesare a limbajului natural disponibil. De fapt, seturile de date de testare care au fost utilizate pentru aceste sarcini au fost mult prea simple pentru aceste modele de transformatoare.
Acum aveam capacitatea de a antrena modele mari de limbaj care au servit drept modele de bază pentru noi sarcini de procesare a limbajului natural. Anterior, oamenii își antrenau modelele de la zero. Dar acum modelele pre-antrenate precum BERT și modelele GPT timpurii erau atât de bune încât nu avea rost să o faci singur. De fapt, aceste modele au fost atât de bune pe care oamenii le-au descoperit că puteau îndeplini sarcini noi cu relativ puține exemple – au fost descrise ca „învățători puțini”, similar cu modul în care majoritatea oamenilor nu au nevoie de prea multe exemple pentru a înțelege concepte noi.
Acesta a fost un punct de inflexiune masiv în dezvoltarea acestor modele și a capacităților lor lingvistice. Acum trebuia doar să ne îmbunătățim instrucțiunile de crafting.
Model 4 – Instrucțiuni de învățare cu InstructGPT
Unul dintre lucrurile pe care copiii le învață în etapa finală a achiziției limbajului, etapa cu mai multe cuvinte, este capacitatea de a folosi cuvinte funcționale pentru a conecta elementele purtătoare de informații dintr-o propoziție. Cuvintele funcționale ne vorbesc despre relația dintre diferitele cuvinte dintr-o propoziție. Dacă dorim să creăm instrucțiuni, atunci modelele de limbaj vor trebui să fie capabile să creeze propoziții cu cuvinte de conținut și cuvinte funcționale care captează relații complexe. De exemplu, următoarea instrucțiune are cuvintele funcție evidențiate cu caractere aldine:
- „ Vreau să scrii o scrisoare…”
- „Spune -mi ce părere ai despre textul de mai sus ”
Dar înainte de a putea încerca să antrenăm modele lingvistice să urmeze instrucțiunile, trebuia să înțelegem exact ce știau deja despre instrucțiuni.
GPT-3 de la OpenAI a fost lansat în 2020. A fost o privire de ce erau capabile aceste modele, dar încă mai trebuia să înțelegem cum să deblocăm capacitățile de bază ale acestor modele. Cum am putea interacționa cu aceste modele pentru a le face să îndeplinească diferite sarcini?
De exemplu, GPT-3 a arătat că creșterea dimensiunii modelului și a datelor de formare au permis ceea ce autorii au numit „meta-învățare” – aici modelul lingvistic dezvoltă un set larg de abilități lingvistice, dintre care multe au fost neașteptate și le poate folosi. abilități de a înțelege o anumită sarcină.
„Modelul ar fi capabil să înțeleagă intenția din instrucțiune și să execute sarcina, mai degrabă decât să prezică pur și simplu următorul cuvânt?”
Amintiți-vă, GPT-3 și modelele lingvistice anterioare nu au fost concepute pentru a dezvolta aceste abilități – ele au fost în mare parte antrenate doar să prezică următorul cuvânt dintr-o secvență de text. Dar, prin progresele cu RNN, Seq2Seq și rețelele de atenție, aceste modele au putut procesa mai mult text, în secvențe mai lungi și să se concentreze mai bine pe contextul relevant.
Vă puteți gândi la GPT-3 ca la un test pentru a vedea cât de departe am putea duce asta. Cât de mari am putea face modelele și cât de mult text le-am putea alimenta? Apoi, după ce am făcut asta, în loc să furnizăm modelului un text de intrare pentru ca acesta să fie completat, am putea folosi textul de intrare ca instrucțiune. Modelul ar fi capabil să înțeleagă intenția din instrucțiune și să execute sarcina, mai degrabă decât să prezică pur și simplu următorul cuvânt? Într-un fel, a fost ca și cum ai încerca să înțeleg în ce stadiu de achiziție a limbajului au ajuns aceste modele.
Acum descriem acest lucru drept „îndemn”, dar în 2020, la momentul apariției lucrării, acesta era un concept foarte nou.
Halucinații și aliniere
Problema cu GPT-3, după cum știm acum, a fost că nu a fost grozav să se lipească îndeaproape de instrucțiunile din textul introdus. GPT-3 poate urma instrucțiunile, dar își pierde atenția cu ușurință, poate înțelege doar instrucțiuni simple și tinde să inventeze lucruri. Cu alte cuvinte, modelele nu sunt „aliniate” cu intențiile noastre. Deci problema acum nu este atât de mult despre îmbunătățirea capacității de limbaj a modelelor, cât mai degrabă capacitatea lor de a urma instrucțiunile.
Este de remarcat faptul că GPT-3 nu a fost niciodată antrenat cu adevărat pe instrucțiuni. Nu i s-a spus ce este o instrucțiune, sau cum diferă de alt text sau cum ar trebui să urmeze instrucțiunile. Într-un fel, a fost „păcălit” să urmeze instrucțiuni, făcându-l să „finalizeze” un prompt ca și alte secvențe de text. Drept urmare, OpenAI trebuia să antreneze un model care să fie mai capabil să urmeze instrucțiunile ca un om. Și au făcut acest lucru într-o lucrare care a fost intitulată în mod adecvat Training modele lingvistice pentru a urma instrucțiunile cu feedback uman, publicate la începutul anului 2022. InstructGPT s-ar dovedi a fi un precursor al ChatGPT mai târziu în același an.
Pașii descriși în acea lucrare au fost folosiți și pentru a instrui ChatGPT. Instruirea a urmat 3 pași principali:
- Pasul 1 – Reglați fin GPT-3: Deoarece GPT-3 părea să se descurce atât de bine cu învățare cu puține lovituri, gândirea a fost că ar fi mai bine dacă ar fi reglat fin pe exemple de instrucțiuni de înaltă calitate. Scopul a fost de a facilita alinierea intenției din instrucțiune cu răspunsul generat. Pentru a face acest lucru, OpenAI a determinat etichetatorii umani să creeze răspunsuri la unele solicitări care au fost trimise de persoane care folosesc GPT-3. Folosind instrucțiuni reale, autorii sperau să surprindă o „distribuție” realistă a sarcinilor pe care utilizatorii încercau să le îndeplinească GPT-3. Acestea au fost folosite pentru a ajusta GPT-3 pentru a-l ajuta să-și îmbunătățească capacitatea de răspuns prompt.
- Pasul 2 – Determină-i pe oameni să clasifice noul și îmbunătățit GPT-3: pentru a evalua noua instrucțiune GPT-3 reglată fin, etichetatorii au evaluat acum performanța modelelor pe diferite solicitări fără răspuns predefinit. Clasamentul a fost legat de factori importanți de aliniere, cum ar fi a fi util, sincer și nu toxic, părtinitor sau dăunător. Deci, dați modelului o sarcină și evaluați-i performanța pe baza acestor valori. Rezultatul acestui exercițiu de clasare a fost apoi folosit pentru a antrena un model separat pentru a prezice ce rezultate ar prefera etichetatorii. Acest model este cunoscut ca model de recompensă (RM).
- Pasul 3 – Utilizați RM pentru a vă instrui pe mai multe exemple: în cele din urmă, RM a fost folosit pentru a antrena noul model de instrucțiuni pentru a genera mai bine răspunsuri care sunt aliniate cu preferințele umane.
Este dificil să înțelegeți pe deplin ce se întâmplă aici cu Reinforcement Learning From Human Feedback (RLHF), modele de recompensă, actualizări de politici și așa mai departe.
O modalitate simplă de a gândi este că este doar o modalitate de a le permite oamenilor să genereze exemple mai bune despre cum să urmeze instrucțiunile. De exemplu, gândiți-vă la cum ați încerca să învățați un copil să spună mulțumiri:
- Părinte: „Când cineva îți dă X, spui mulțumesc”. Acesta este pasul 1, un exemplu de set de date de solicitări și răspunsuri adecvate
- Părinte: „Acum, ce-i spui lui Y aici?”. Acesta este pasul 2 în care îi cerem copilului să genereze un răspuns și apoi părintele îl va evalua. "Da este bine."
- În cele din urmă, în întâlnirile ulterioare, părintele va recompensa copilul pe baza exemplelor bune sau rele de răspunsuri în scenarii similare în viitor. Acesta este pasul 3, în care are loc comportamentul de întărire.
La rândul său, OpenAI susține că tot ceea ce face este pur și simplu să deblocheze capabilități care erau deja prezente în modele precum GPT-3, „dar au fost greu de obținut doar prin inginerie promptă”, așa cum spune lucrarea.
Cu alte cuvinte, ChatGPT nu învață cu adevărat capabilități „ noi ”, ci pur și simplu învață o „ interfață ” lingvistică mai bună pentru a le utiliza.
Magia limbajului
ChatGPT se simte ca un salt magic înainte, dar este de fapt rezultatul progresului tehnologic minuțios de-a lungul deceniilor.
Privind unele dintre evoluțiile majore din domeniul AI și NLP din ultimul deceniu, putem vedea cum ChatGPT „stă pe umerii giganților”. Modelele anterioare au învățat mai întâi să identifice sensul cuvintelor. Apoi modelele ulterioare au pus aceste cuvinte împreună și le-am putea antrena să îndeplinească sarcini precum traducerea. Odată ce au putut procesa propozițiile, am dezvoltat tehnici care au permis acestor modele de limbaj să proceseze tot mai mult text și să dezvolte capacitatea de a aplica aceste învățari la sarcini noi și neprevăzute. Și apoi, cu ChatGPT, am dezvoltat în sfârșit capacitatea de a interacționa mai bine cu aceste modele, specificând instrucțiunile noastre într-un format de limbaj natural.
„Deoarece limbajul este vehiculul pentru gândurile noastre, predarea computerelor cu toată puterea limbajului va duce la, ei bine, inteligență artificială independentă?”
Cu toate acestea, evoluția NLP dezvăluie o magie mai profundă la care suntem de obicei orbi - magia limbajului în sine și modul în care noi, ca oameni, o dobândim.
Există încă multe întrebări deschise și controverse despre modul în care copiii învață limba în primul rând. Există, de asemenea, întrebări despre dacă există o structură de bază comună pentru toate limbile. Au evoluat oamenii pentru a folosi limbajul sau este invers?
Lucrul curios este că, pe măsură ce ChatGPT și descendenții săi își îmbunătățesc dezvoltarea lingvistică, aceste modele pot ajuta să răspundă la unele dintre aceste întrebări importante.
În cele din urmă, deoarece limbajul este vehiculul pentru gândurile noastre, predarea computerelor cu toată puterea limbajului va duce la, ei bine, inteligență artificială independentă? Ca întotdeauna în viață, mai sunt atât de multe de învățat.
