
Hacking The Topic Graph cu Wikipedia și API-ul Google Language
Publicat: 2019-08-27Unul dintre diapozitivele mele preferate din ultimii zece ani a fost realizat de Mark Johnstone în 2014, în timp ce era încă cu Distilled. Pachetul s-a numit Cum să produc idei de conținut mai bune și l-am folosit ca biblie pentru câțiva ani în timp ce construiam echipe pentru a face munca grea de promovare a conținutului.
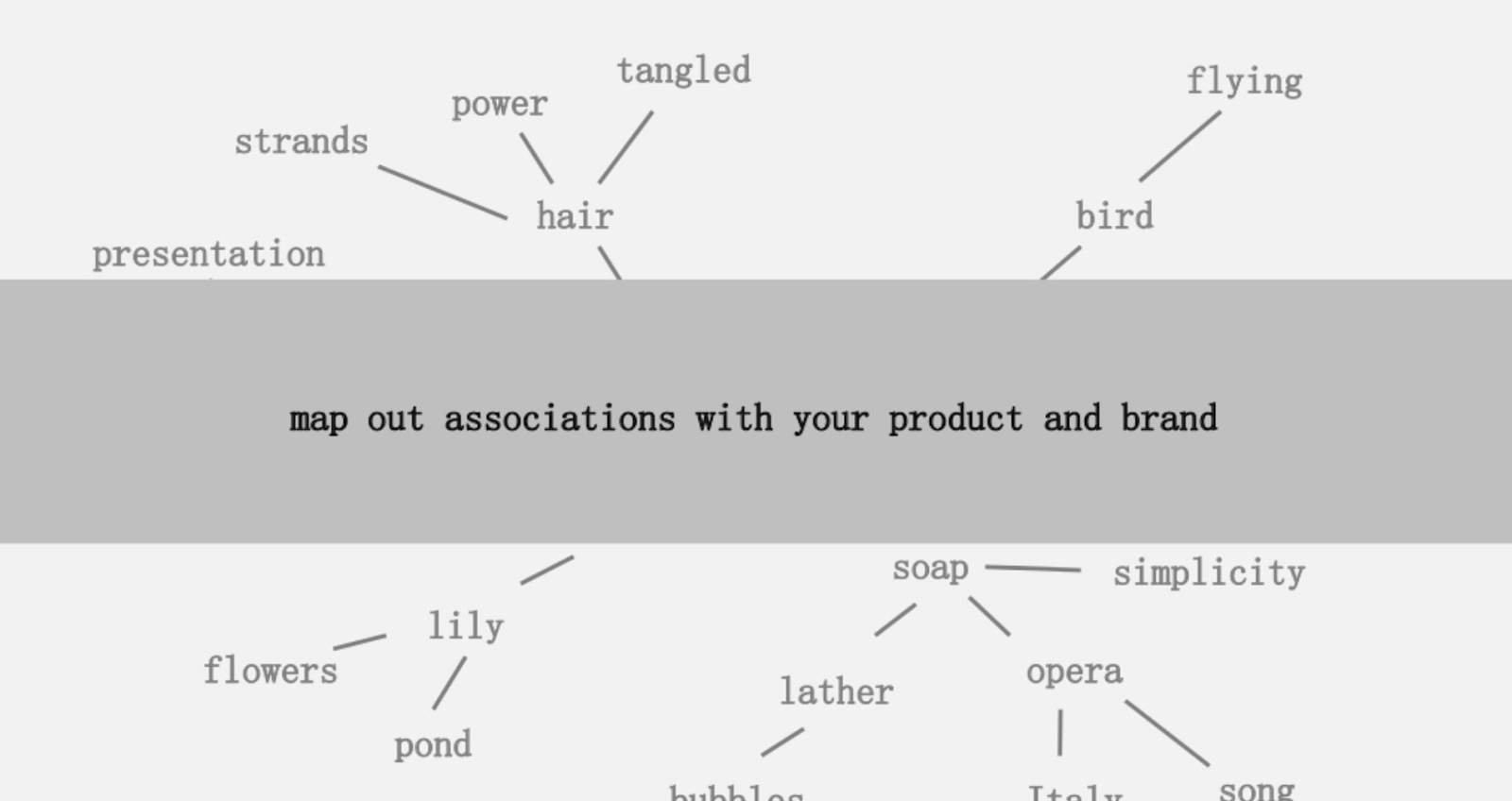
Una dintre ideile oferite a fost de a crea o cartografiere vizuală a conexiunii dintre cuvintele asociate cu produsul sau marca dvs., astfel încât să puteți face retragere și să căutați modalități de a combina asocierile în ceva interesant. Scopul este producerea de idei, pe care el le definește ca „ o combinație nouă de elemente anterior neconectate într-un mod care adaugă valoare”.
În acest articol, adoptăm o abordare cu mult mai mult a creierului stâng, utilizând Python, API-ul Google Language, împreună cu Wikipedia, pentru a explora asociațiile de entități care există dintr-un subiect de bază. Scopul este o vedere la nivel înalt a relațiilor dintre entități de-a lungul graficului subiectului. Acest articol nu este pentru cititorul obișnuit. Cititorii care sunt familiarizați cu Python și au cel puțin un nivel de bază de capacitate de codare îl vor găsi mult mai instructiv.
Ideea
Urmând ideea de cartografiere a lui Mark Johnstone, m-am gândit că ar fi interesant să las Google și Wikipedia să definească o structură a subiectului pornind de la un subiect de bază sau o pagină web. Scopul este de a construi maparea relațiilor cu subiectul principal din punct de vedere vizual, într-un grafic asemănător arborelui care poate fi revizuit pentru a căuta conexiuni și, eventual, a genera idei de conținut. Următoarea imagine reprezintă ideea inițială de design.
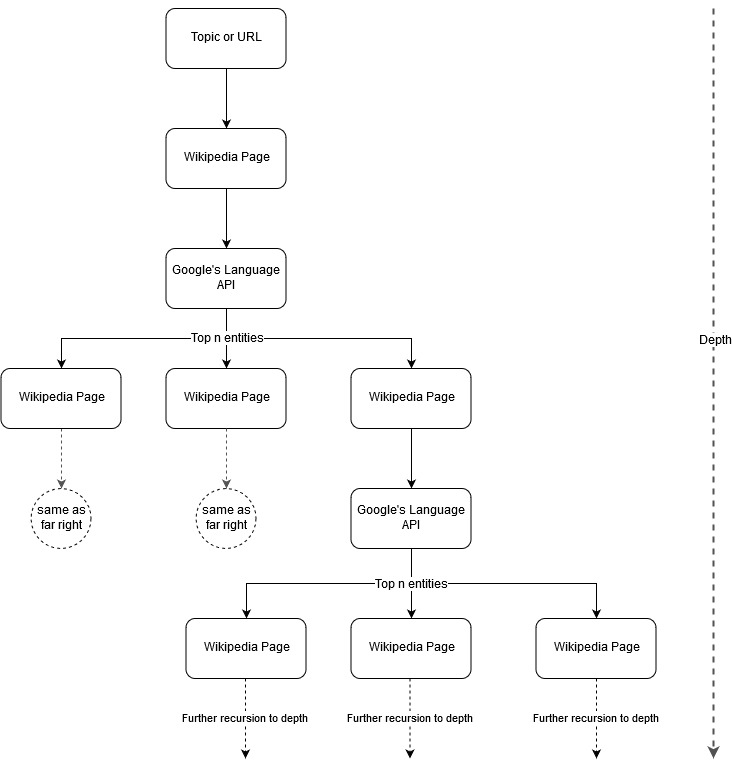
În esență, dăm instrumentului un subiect sau o adresă URL și lăsăm API-ului Google Language să selecteze primele n (3 în exemplele noastre) entități (care includ URL-uri Wikipedia) pentru fiecare pagină de entitate și continuăm recursiv să construim un grafic de rețea pentru fiecare entitate găsită. până la o adâncime maximă.
Contextul instrumentelor utilizate
API-ul Google Language
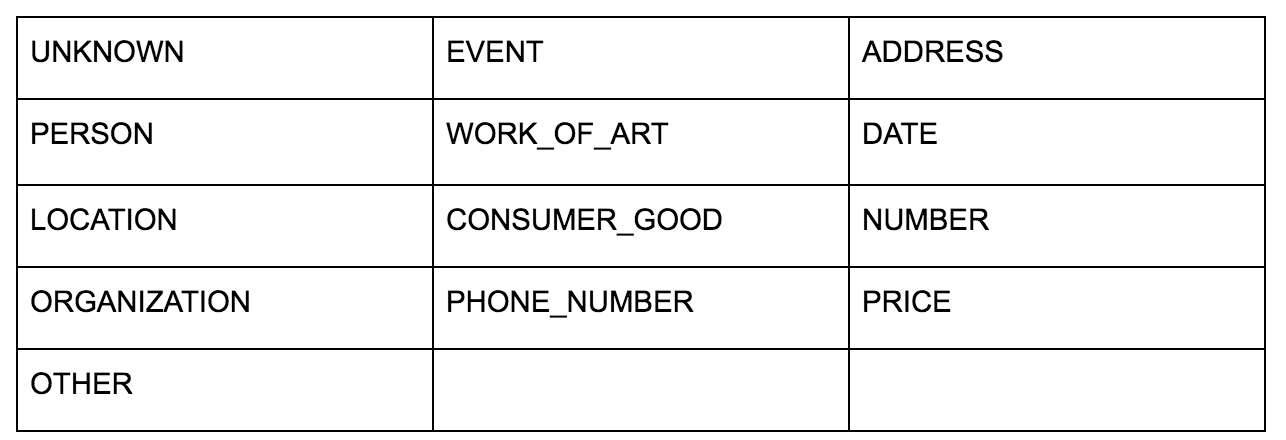
Google Language API vă permite să-l transmiteți fie text simplu, fie HTML și returnează în mod magic toate entitățile diferite asociate cu conținutul. API-ul face mai mult decât atât, dar pentru această analiză ne vom concentra doar pe această porțiune. Iată o listă cu tipurile de entități pe care le returnează:
Identificarea entităților a fost o parte fundamentală a procesării limbajului natural (NLP) pentru o lungă perioadă de timp, iar terminologia corectă pentru sarcină este Named Entity Recognition (NER). NER este o sarcină dificilă, deoarece multe cuvinte au semnificații diferite în funcție de contextul utilizat, astfel încât instrumentele NLP sau API-urile trebuie să înțeleagă contextul complet din jurul termenilor pentru a le putea identifica în mod corespunzător ca o anumită entitate.
Am oferit o imagine de ansamblu destul de detaliată a acestui API și a entităților în special, într-un articol de pe opensource.com, dacă doriți să ajungeți la un anumit context înainte de a termina acest articol.
O caracteristică interesantă a API-ului Google Language este, pe lângă găsirea de entități relevante, marchează, de asemenea, cât de legate sunt acestea de documentul general (solience) și, pentru unii, furnizează un articol Wikipedia (graficul de cunoștințe) conexe reprezentând entitatea.
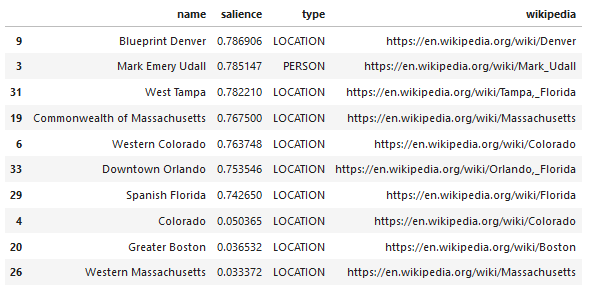
Iată un exemplu de ieșire a ceea ce returnează API-ul (sortat după importanță):
Dezvoltator Oncrawl
 Află mai multe
Află mai multePiton
Python este un limbaj software care a devenit popular în spațiul științei datelor datorită unui set mare și în creștere de biblioteci care facilitează ingerarea, curățarea, manipularea și analiza seturilor mari de date. Beneficiază, de asemenea, de un mediu colaborativ numit notebook-uri Jupyter, care permite utilizatorilor să testeze și să adnoteze cu ușurință codul, fără efort.
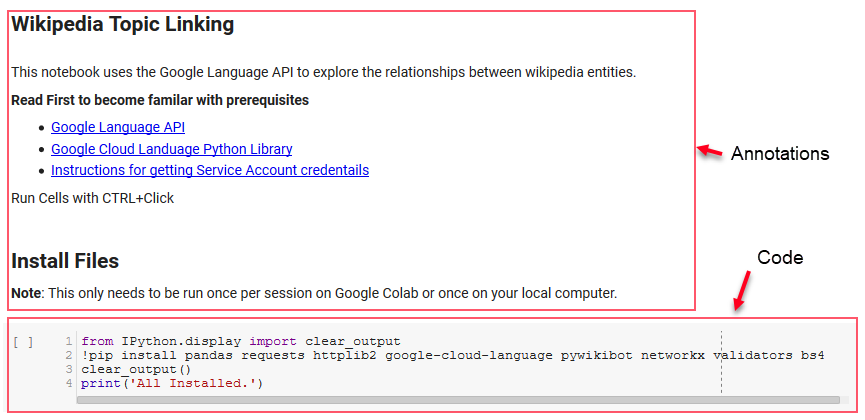
Pentru această revizuire, vom folosi câteva biblioteci cheie care ne vor permite să facem câteva lucruri interesante cu datele NLP ale Google.
- Pandas: Gândiți-vă să puteți scrie script Microsoft Excel pentru a citi, salva, analiza sau rearanja foile de calcul și vă faceți o idee despre ceea ce face Pandas. Panda este uimitor. (legătură)
- Networkx: Networkx este un instrument pentru construirea graficelor de noduri și muchii care definesc relațiile dintre noduri. De asemenea, are suport încorporat pentru trasarea graficelor, astfel încât acestea să fie ușor de vizualizat. (legătură)
- Pywikibot: Pywikibot este o bibliotecă care vă permite să interacționați cu Wikipedia pentru a căuta, edita, găsi relații etc., cu tot conținutul pentru fiecare site Wikipedia. (legătură)
Procesul
Partajăm aici un blocnotes Google Colab care poate fi folosit pentru a urmări. (Mulțumiri speciale lui Tyler Reardon pentru verificarea corectă a articolului și a acestui caiet.)
Configurare
Primele celule din blocnotes se ocupă de instalarea unor biblioteci, de a pune acele biblioteci disponibile pentru Python și de a furniza un fișier de acreditări și de configurare pentru API-ul Google Language și, respectiv, Pywikibot. Iată toate bibliotecile pe care trebuie să le instalăm pentru a ne asigura că instrumentul poate rula:
- panda
- cereri
- httplib2
- google-cloud-language
- pywikibot
- networkx
- validatori
- Bs4
Notă: cea mai grea parte a capacității de a rula acest notebook este obținerea acreditărilor de la Google pentru a accesa API-urile lor. Pentru cei fără experiență în acest lucru, va dura aproximativ o oră pentru a-și da seama. Am conectat Instrucțiunile pentru obținerea acreditărilor contului de serviciu din partea de sus a blocnotesului pentru a vă ajuta. Mai jos este un exemplu despre cum l-am inclus pe al nostru.
Funcții pentru Win
În celula indicată de „Definiți unele funcții pentru Google NLP”, dezvoltăm opt funcții care se ocupă de lucruri precum interogarea API-ului Language, interacțiunea cu Wikipedia, extragerea textului paginii web și construirea și trasarea graficelor. Funcțiile sunt în esență mici unități de cod care preiau anumite date de setări, lucrează și produc ceva. Toate funcțiile sunt comentate pentru a spune variabilele pe care le preiau și ce produc.

Testarea API-ului
Următoarele două celule preiau o adresă URL, extrag textul din URL și extrag entitățile din API-ul Google Language. Unul trage numai entitățile care au URL-uri Wikipedia, iar celălalt trage toate entitățile din pagina respectivă.
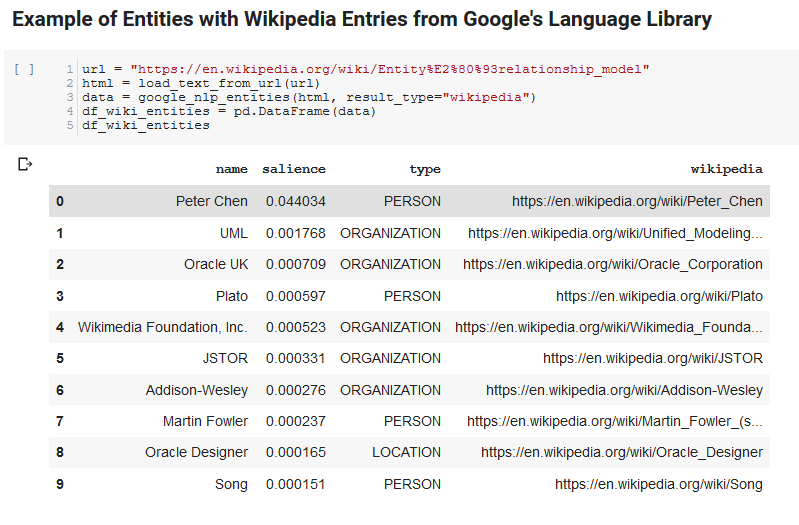
Acesta a fost un prim pas important doar pentru a corecta porțiunea de extragere a conținutului și pentru a înțelege cum a funcționat API-ul Language și a returnat datele.
Networkx
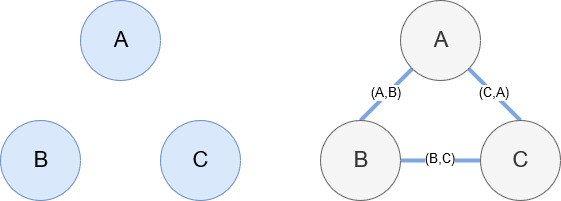
Networkx, așa cum am menționat mai devreme, este o bibliotecă minunată cu care se joacă destul de intuitiv. În esență, trebuie să îi spui care sunt nodurile tale și cum sunt conectate nodurile. De exemplu, în imaginea de mai jos, dăm Networkx trei noduri (A,B,C). Apoi îi spunem Networkx că sunt conectate prin muchii (A,B), (B,C), (C,A) care definesc relațiile dintre noduri. Pentru utilizarea noastră, entitățile cu URL-uri Wikipedia vor fi nodurile, iar marginile sunt definite de noi entități care se găsesc pe o pagină de entitate curentă. Deci, dacă examinăm pagina Wikipedia pentru Entitatea A și pe pagina respectivă, Entitatea B este descoperită, atunci aceasta este o margine între Entitatea A și Entitatea B.
Punând totul împreună
Următoarea secțiune a caietului se numește Wikipedia Topic Branching by URL. Aici se întâmplă magia. Mai devreme definisem o funcție specială (recurse_entities) care recurge prin paginile de pe Wikipedia urmând noi entități definite de API-ul Google pentru limbaj. Am adăugat, de asemenea, o funcție foarte dificil de înțeles (hierarchy_pos) pe care am ridicat-o din Stack Overflow, care face o treabă bună de a prezenta un grafic asemănător arborelui cu multe noduri. În celula de mai jos, definim intrarea ca „Search Engine Optimization” și specificăm o adâncime de 3 (aceasta este câte pagini urmează recursiv) și o limită de 3 (aceasta este câte entități extrage pe pagină).
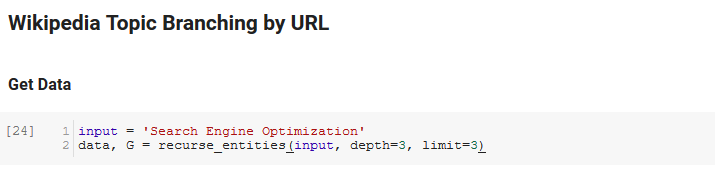
Rulându-l pentru termenul „Search Engine Optimization” putem vedea următoarea cale pe care a urmat-o instrumentul, începând de la pagina de Search Engine Optimization a Wikipedia (Nivel 0) și urmând, recursiv, paginile până la adâncimea maximă specificată (3).

Apoi luăm toate entitățile găsite și le adăugăm la un Pandas DataFrame, ceea ce face foarte ușor să salvați ca CSV. Sortăm aceste date după importanță (care este cât de importantă este entitatea pentru pagina pe care a fost găsită), dar acest scor este puțin înșelător în acest context, deoarece nu vă spune cât de legată este entitatea de termenul dvs. inițial (" Optimizare motor de căutare"). Vom lăsa această lucrare în continuare cititorului.

În cele din urmă, trasăm graficul construit de instrument pentru a arăta conexiunea tuturor entităților. În celula de mai jos, parametrii pe care îi puteți transmite funcției sunt: ( G : Graficul construit anterior de funcția recurse_entities, w: lățimea diagramei, h: înălțimea diagramei, c: procentul circular al plot și nume de fișier: fișierul PNG care este salvat în folderul imagini.)

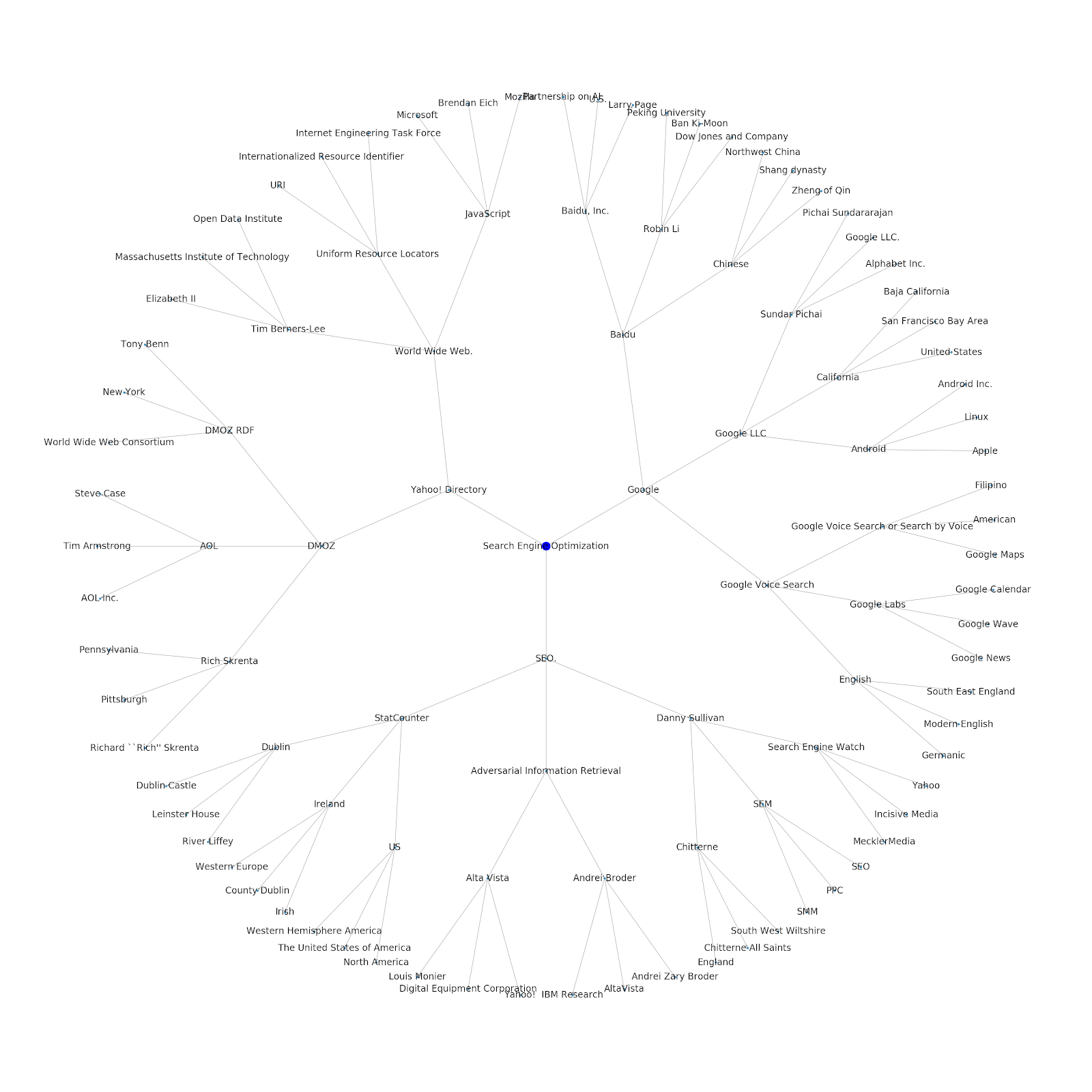
Am adăugat posibilitatea de a-i oferi fie un subiect de bază, fie o adresă URL de bază. În acest caz, ne uităm la entitățile asociate cu articolul Google's Indexing Issues Continue But This One Is Different
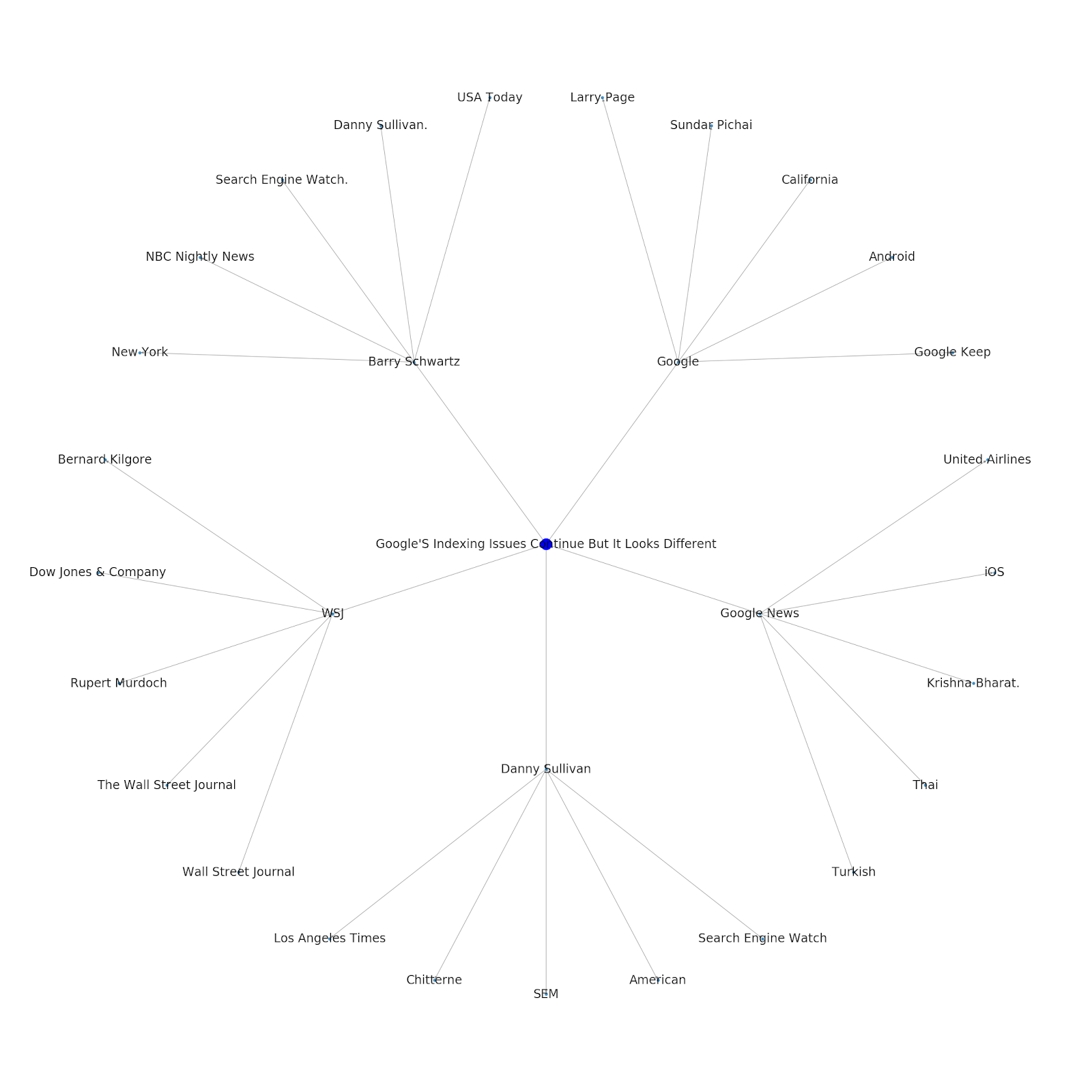
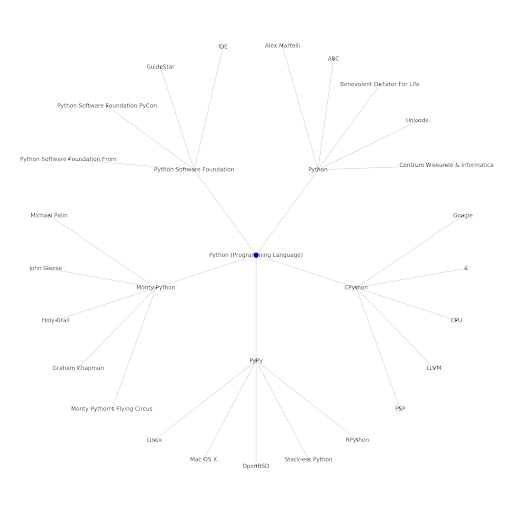
Iată graficul entității Google/Wikipedia pentru Python.
Ce inseamna asta
Înțelegerea stratului tematic al internetului este interesantă din punct de vedere SEO, deoarece te obligă să te gândești la modul în care lucrurile sunt conectate și nu doar la interogări individuale. Deoarece Google folosește acest strat pentru a potrivi afinitățile individuale ale utilizatorilor cu subiectele, așa cum s-a menționat în reintroducerea Google Discover, poate deveni un flux de lucru mai important pentru SEO centrat pe date. În graficul „Python” de mai sus, se poate deduce că familiaritatea unui utilizator cu subiectele legate de un subiect inițial poate fi o măsură rezonabilă a nivelului său de expertiză cu subiectul inițial.
Exemplul de mai jos arată doi utilizatori cu evidențierea verde care arată interesul lor istoric sau afinitatea cu subiectele conexe. Utilizatorul din stânga, înțelegând ce este un IDE și înțelegând ce înseamnă PyPy și CPython, ar fi un utilizator mult mai experimentat cu Python, decât cineva care știe că este o limbă, dar nu mult altceva. Acest lucru ar fi ușor de transformat în scoruri numerice pentru fiecare subiect, pentru fiecare utilizator.

Concluzie
Scopul meu azi a fost să împărtășesc un proces destul de standard prin care trec pentru a testa și revizui eficiența diferitelor instrumente sau API-uri folosind Jupyter Notebooks. Explorarea graficului subiectului este incredibil de interesantă și sperăm că instrumentele partajate vă oferă avantajul de care aveți nevoie pentru a începe să explorați singur. Cu aceste instrumente, puteți construi grafice de subiecte care explorează multe niveluri de relație, limitate doar la nivelul cotei Google Language API (care este de 800.000 pe zi). (Actualizare: prețul se bazează pe unități de 1.000 de caractere unicode trimise către API și este gratuit pentru până la 5.000 de unități. Deoarece articolele Wikipedia pot fi lungi, doriți să urmăriți cheltuielile. Sfat pentru John Murch pentru că a subliniat acest lucru.) Dacă îmbunătățești caietul sau găsești cazuri interesante, sper să mă anunți. Mă puteți găsi la @jroakes pe Twitter.