
Cheile pentru construirea unui Robots.txt care funcționează
Publicat: 2020-02-18Boții, cunoscuți și sub denumirea de Crawlers sau Spiders, sunt programe care „călătoresc” pe Web în mod automat de la un site la altul, folosind link-urile drept drum. Deși întotdeauna au prezentat anumite curiozități, fișierele robot.txt pot fi instrumente foarte eficiente. Motoarele de căutare precum Google și Bing folosesc roboți pentru a accesa cu crawlere conținutul web. Fișierul robots.txt oferă îndrumări diferiților roboți cu privire la paginile pe care nu ar trebui să le acceseze cu crawlere pe site-ul dvs. Puteți, de asemenea, să vă conectați la sitemap-ul dvs. XML din robots.txt, astfel încât botul să aibă o hartă a fiecărei pagini pe care ar trebui să o acceseze cu crawlere.
De ce este util robots.txt?
robots.txt limitează cantitatea de pagini pe care un bot trebuie să le acceseze cu crawlere și să le indexeze în cazul roboților motoarelor de căutare. Dacă doriți să evitați ca Google să acceseze cu crawlere paginile de administrator, le puteți bloca pe robots.txt pentru a încerca să păstrați o pagină departe de serverele Google.
Pe lângă împiedicarea indexării paginilor, robots.txt este excelent pentru optimizarea bugetului de accesare cu crawlere. Bugetul de accesare cu crawlere este numărul de pagini pe care Google a determinat că le va accesa cu crawlere pe site-ul dvs. De obicei, site-urile web cu mai multă autoritate și mai multe pagini au un buget de accesare cu crawlere mai mare decât site-urile web cu un număr redus de pagini și cu autoritate redusă. Deoarece nu știm cât buget de accesare cu crawlere este alocat site-ului nostru, dorim să profităm la maximum de acest timp, permițând Googlebot să ajungă la cele mai importante pagini în loc să acceseze cu crawlere paginile pe care nu dorim să le indexăm.
Un detaliu foarte important pe care trebuie să-l știți despre robots.txt este că, deși Google nu va accesa cu crawlere paginile care sunt blocate de robots.txt, acestea pot fi indexate dacă pagina este legată de un alt site web. Pentru a preveni corect indexarea paginilor dvs. și apariția în rezultatele Căutării Google, trebuie să protejați cu parolă fișierele de pe serverul dvs., să utilizați metaeticheta noindex sau antetul de răspuns sau să eliminați pagina în întregime (răspundeți cu 404 sau 410). Pentru mai multe informații despre accesarea cu crawlere și controlul indexării, puteți citi ghidul robots.txt al lui OnCrawl.
[Studiu de caz] Gestionarea accesării cu crawlere a botului Google
 Citiți studiul de caz
Citiți studiul de cazSintaxa corectă Robots.txt
Sintaxa robots.txt poate fi uneori puțin complicată, deoarece diferiți crawler-uri interpretează diferit sintaxa. De asemenea, unii crawler-uri fără reputație văd directivele robots.txt ca sugestii și nu ca o regulă clară pe care trebuie să o respecte. Dacă aveți informații confidențiale pe site-ul dvs., este important să utilizați protecția prin parolă, pe lângă blocarea crawlerelor folosind robots.txt
Mai jos am enumerat câteva lucruri pe care trebuie să le țineți cont atunci când lucrați la robots.txt:
- Fișierul robots.txt trebuie să locuiască sub domeniu și nu într-un subdirector. Crawlerele nu verifică fișierele robots.txt în subdirectoare.
- Fiecare subdomeniu are nevoie de propriul fișier robots.txt:
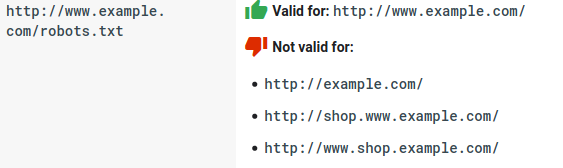
- Robots.txt face distincție între majuscule și minuscule:
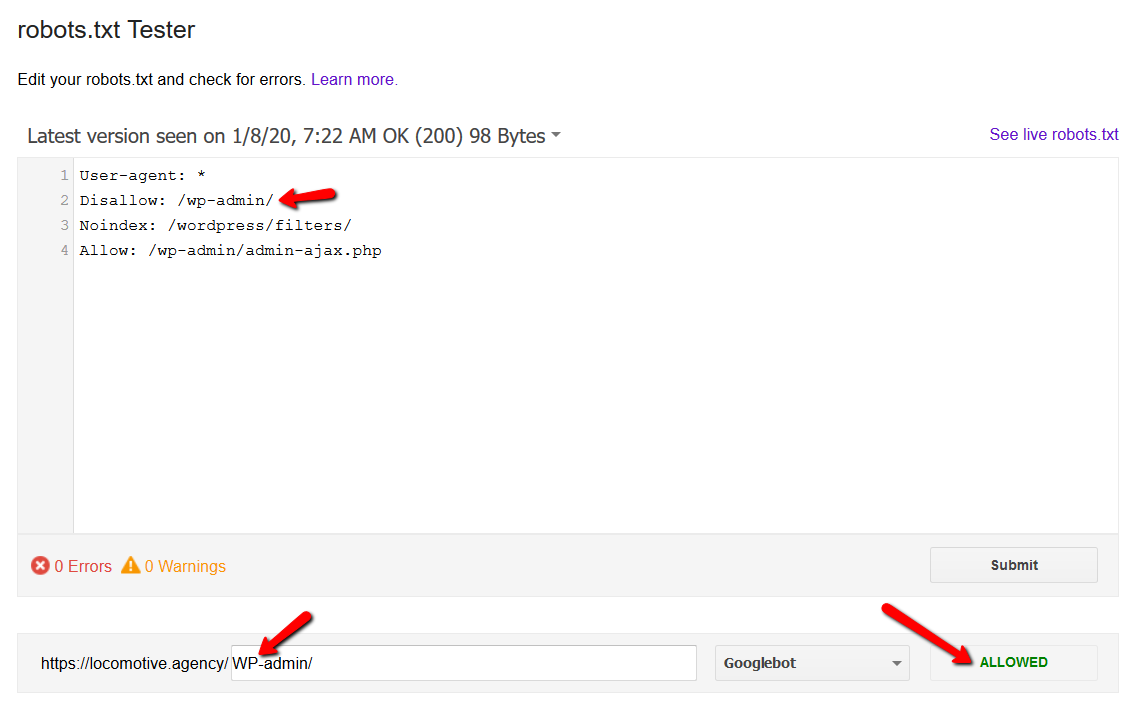
- Directiva noindex: Când utilizați noindex în robots.txt, va funcționa în același mod ca disallow. Google va opri accesarea cu crawlere a paginii, dar o va păstra în indexul său. @jroakes și cu mine am creat un test în care am folosit directiva Noindex pe articolul /wordpress/filters/ și am trimis pagina în Google. Puteți vedea în captura de ecran de mai jos că arată că adresa URL a fost blocată:
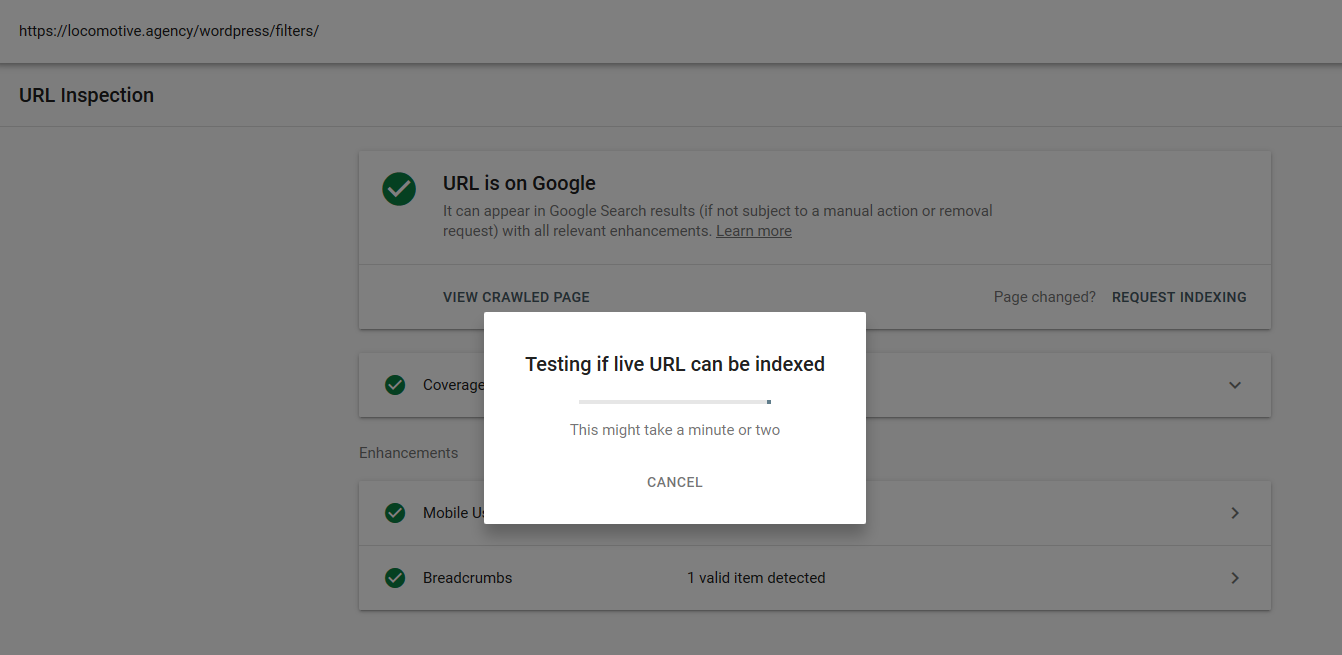
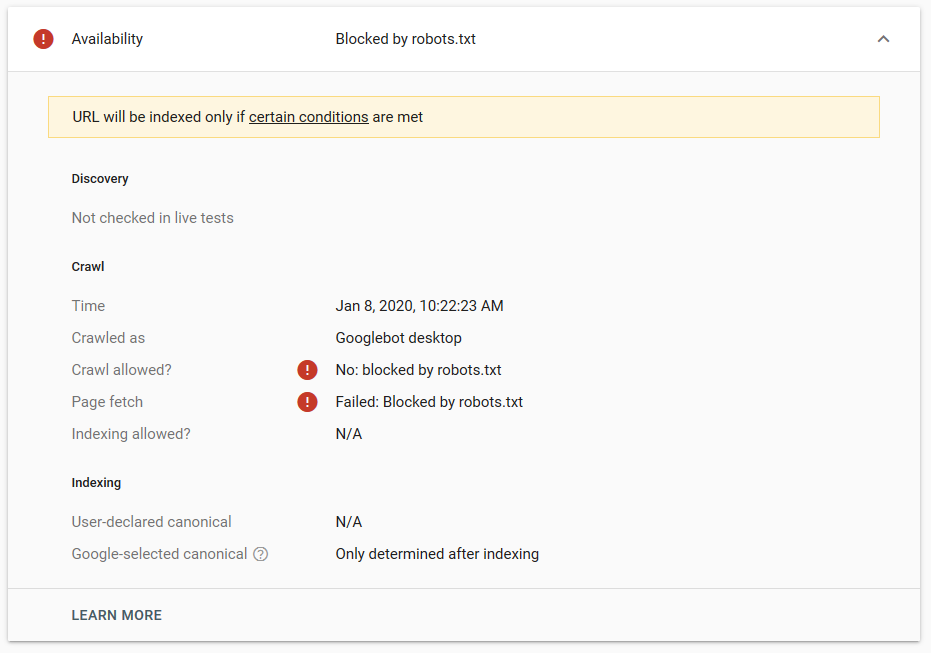

Am făcut mai multe teste în Google și pagina nu a fost niciodată eliminată din index:
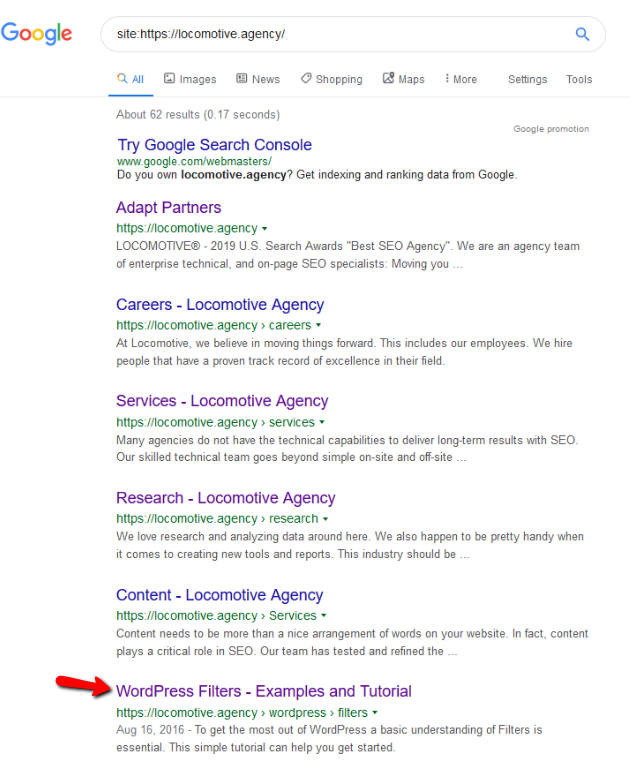
A existat o discuție anul trecut despre directiva noindex care funcționează în robots.txt, eliminând pagini, dar Google. Iată un subiect în care Gary Illyes a declarat că va dispărea. La acest test putem observa că soluția Google este în vigoare, deoarece directiva noindex nu a eliminat pagina din rezultatele căutării.
Recent, a existat un alt thread interesant pe twitter de la Christian Oliveira, unde a împărtășit câteva detalii de luat în considerare atunci când lucrați la robots.txt.
- Dacă dorim să avem reguli și reguli generice numai pentru Googlebot, trebuie să duplicăm toate regulile generice din setul de reguli User-agent: Google bot. Dacă nu sunt incluse, Googlebot va ignora toate regulile:

- Un alt comportament confuz este că prioritatea regulilor (în interiorul aceluiași grup User-agent) nu este determinată de ordinea acestora, ci de lungimea regulii.
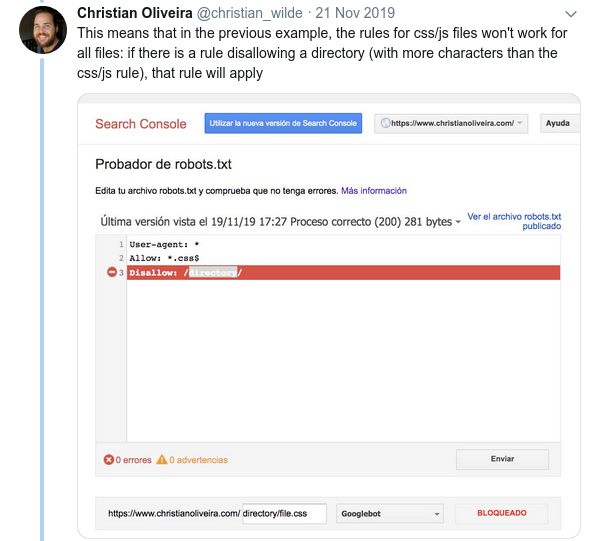
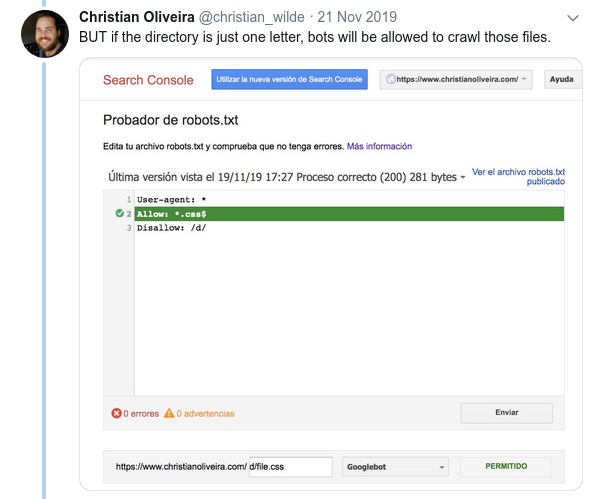
- Acum, când aveți două reguli, cu aceeași lungime și comportament opus (una permițând accesul cu crawling și cealaltă interzicând-o), se aplică regula mai puțin restrictivă:
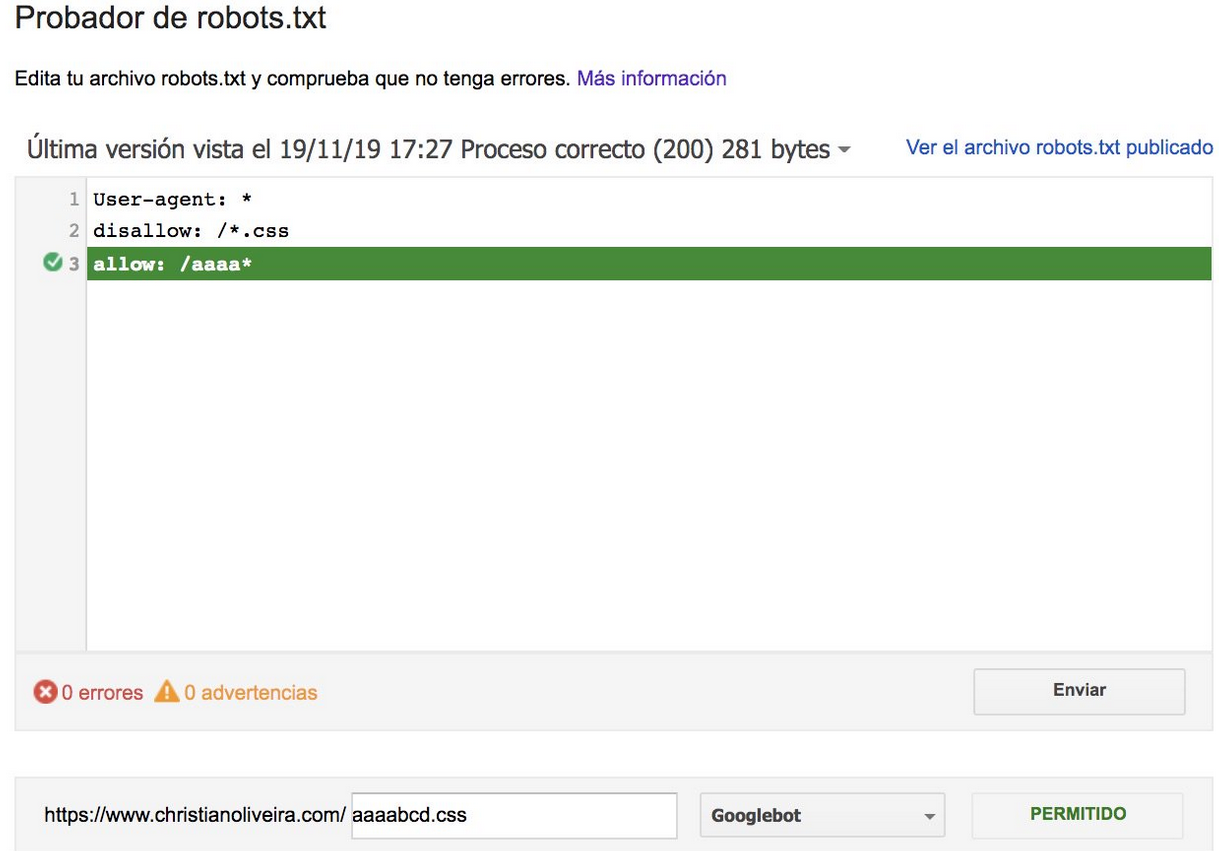
Pentru mai multe exemple, vă rugăm să citiți specificațiile robots.txt furnizate de Google.
Instrumente pentru testarea Robots.txt
Dacă doriți să testați fișierul robots.txt, există mai multe instrumente care vă pot ajuta și, de asemenea, câteva depozite github dacă doriți să vă creați propriile:
- Distilat
- Google a lăsat aici instrumentul de testare robots.txt din vechea Google Search Console
- Pe Python
- Pe C++
Exemplu de rezultate: utilizarea eficientă a unui fișier Robots.txt pentru comerțul electronic
Mai jos am inclus un caz în care lucram cu un site Magento care nu avea un fișier robots.txt. Magento, precum și alte CMS au pagini de administrare și directoare cu fișiere pe care nu dorim ca Google să le acceseze cu crawlere. Mai jos, am inclus un exemplu de câteva dintre directoarele pe care le-am inclus în robots.txt:
# # Directoare generale Magento Nu permiteți: / aplicație / Nu permite: / descărcator / Nu permite: / erori / Nu permite: / include / Nu permiteți: / lib / Nu permiteți: / pkginfo / Disallow: / shell / Nu permiteți: / var / # # Nu indexați pagina de căutare și categoriile de linkuri neoptimizate Nu permiteți: /catalog/product_compare/ Nu permiteți: /catalog/category/view/ Nu permiteți: /catalog/product/view/ Nu permiteți: /catalog/produs/galerie/ Nu permiteți: /catalogsearch/
Numărul imens de pagini care nu erau menite să fie accesate cu crawlere le afecta bugetul de accesare cu crawlere, iar Googlebot nu ajungea să acceseze cu crawlere toate paginile de produse de pe site.
Puteți vedea în imaginea de mai jos cum au crescut paginile indexate după 25 octombrie, când a fost implementat robots.txt:
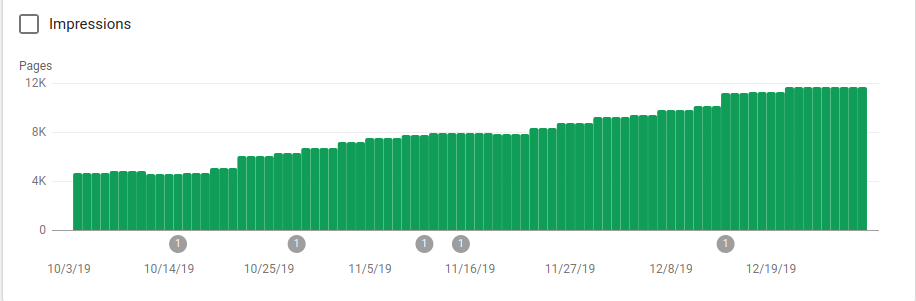
Pe lângă blocarea mai multor directoare care nu erau menite să fie accesate cu crawlere, roboții au inclus un link către hărțile site-urilor. În captura de ecran de mai jos puteți vedea cum a crescut numărul de pagini indexate în comparație cu paginile excluse:
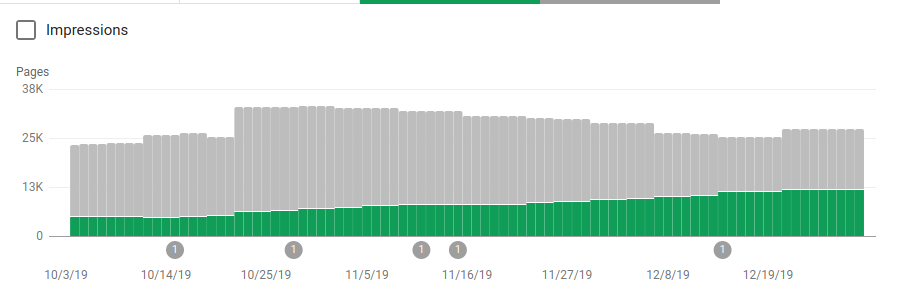
Există o tendință pozitivă pe paginile valide indexate, așa cum se arată prin barele verzi și o tendință negativă pe paginile excluse reprezentate de barele gri.
Încheierea
Importanța robots.txt poate fi uneori subestimată și, după cum puteți vedea din această postare, există o mulțime de detalii care trebuie luate în considerare atunci când creați unul. Dar munca dă roade: am arătat câteva dintre rezultatele pozitive pe care le puteți obține din configurarea corectă a unui robots.txt.