
Cum să modelezi un fragment în epoca Google ca editor
Publicat: 2019-10-22Google se consideră un editor de conținut de mult timp, deși tendința a devenit greu de ignorat în ultimii ani. Acest lucru a fost parțial facilitat de progresele în învățarea automată și de noile funcții ale paginii cu rezultate ale motorului de căutare (SERP).
„Google ca editor de conținut” este o problemă potențială pentru mulți proprietari de site-uri web, deoarece prezintă o alegere dificilă. Ar trebui să te:
- Protejați-vă conținutul și riscați să fiți exclus din rezultatele Google?
- Oferiți Google surse de conținut gratuite, știind că este posibil ca Google să nu trimită vizitatori pe site-ul dvs.?
Noile etichete de gestionare a fragmentelor care intră în vigoare la sfârșitul lunii octombrie 2019 pot fi văzute ca o declarație de intenție a Google. Ele reprezintă, de asemenea, un pas în direcția corectă, oferind proprietarilor de site-uri un mijloc de a-și proteja conținutul și de a controla modul în care paginile lor apar în SERP-uri.
De ce să vă faceți griji pentru conținutul de calitate?
Proprietățile Google încă furnizează aproximativ 60% din traficul către site-uri web, în funcție de verticală, așa că a nu juca jocul Google are un efect negativ potențial enorm asupra vizibilității și traficului unui site web. Dar, în același timp, prin intermediul EAT și al Quality Rater Guidelines, Google a stabilit clar că conținutul de calitate este ceea ce caută utilizatorii de internet și că site-urile web trebuie să investească în producerea acestuia pentru a supraviețui.
Acea investiție în conținut unic, de înaltă calitate este ceva pe care proprietarul unui site ar trebui să-l protejeze în mod natural. Prin oferirea de conținut, site-urile web permit altor furnizori (în acest caz: motoarele de căutare) să profite de timpul, banii și expertiza lor.
Cum folosește Google conținutul?
Google folosește, remixează și rescrie conținutul pentru a oferi răspunsuri la întrebările puse de utilizatorii motoarelor de căutare. Aceste răspunsuri sunt afișate în multe forme pe SERP-uri.
Listări cu rezultatele căutării sau „fragmente”
Google compune un fragment pentru o anumită pagină web în rezultatele căutării, folosind diferite elemente desenate inițial din pagina web însăși:
- eticheta <title>
- Etichetă <meta description="Text fragment”>
- Marcare Schema.org pentru datele structurate acceptate
- URL
- Favicon (în rezultatele mobile din unele regiuni)
Astăzi, puține dintre acestea sunt folosite așa cum sunt. Google își rezervă dreptul de a înlocui favicon-ul. Google afirmă în mod explicit că „generarea lor de titluri și descrieri de pagini este complet automatizată și... [Google folosește] o serie de surse diferite pentru aceste informații, inclusiv informații descriptive din titlu și metaetichete pentru fiecare pagină”. În cele din urmă, Google a început să suprime URL-urile din SERP-uri, așa cum sa văzut în testele recente.
Eliminarea de către Google a adreselor URL din SERP poate ajuta puțin TLD-urile „rele”.
Dacă nu vă puteți da seama dacă este un .io, .org, .net, .ie etc etc, nu puteți părăsi lor și faceți clic pe acel .com care pare mai legitim. S-ar putea să nu fie un impact uriaș, dar ar putea fi unul subtil, care devine mai mare în timp. pic.twitter.com/CcQ2E0lVtZ
– Ross Hudgens (@RossHudgens) 21 octombrie 2019
Fragmente recomandate
Google creează fragmente recomandate, care apar înaintea listelor cu rezultatele căutării, extragând conținut dintr-o pagină web care pare să răspundă la întrebarea celui care caută. Au existat diverse episoade de fragmente prezentate care au apărut fără o atribuire (sau fără o atribuire vizibilă sau ușor accesibilă) în februarie și iunie 2019. În fiecare caz, Google a condamnat intenția de a ocoli drepturile editorilor și a susținut că lipsa atribuirii a fost o eroare.
Definiții, vreme și mâncare
Căutarea definițiilor de dicționar sau a vremii într-o anumită locație oferă un răspuns în caseta de completare automată, fără atribuire și fără a fi nevoie să executați o căutare.
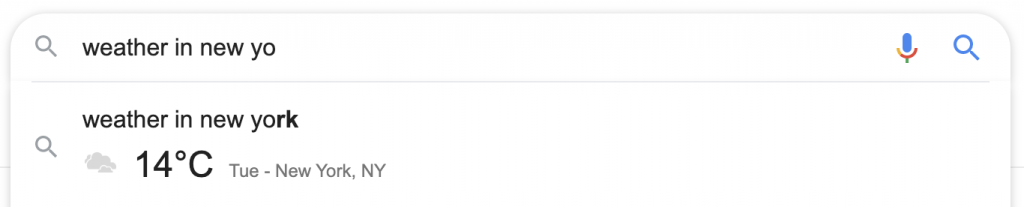
În cazul unei definiții, dacă butonul de căutare este apăsat, este disponibilă definiția completă, cu sunet, sinonime și alte caracteristici în SERP. Cel care caută nu trebuie să viziteze site-ul dicționarului Oxford, iar atribuirea Oxford apare în text mic gri sub caseta de definiție.
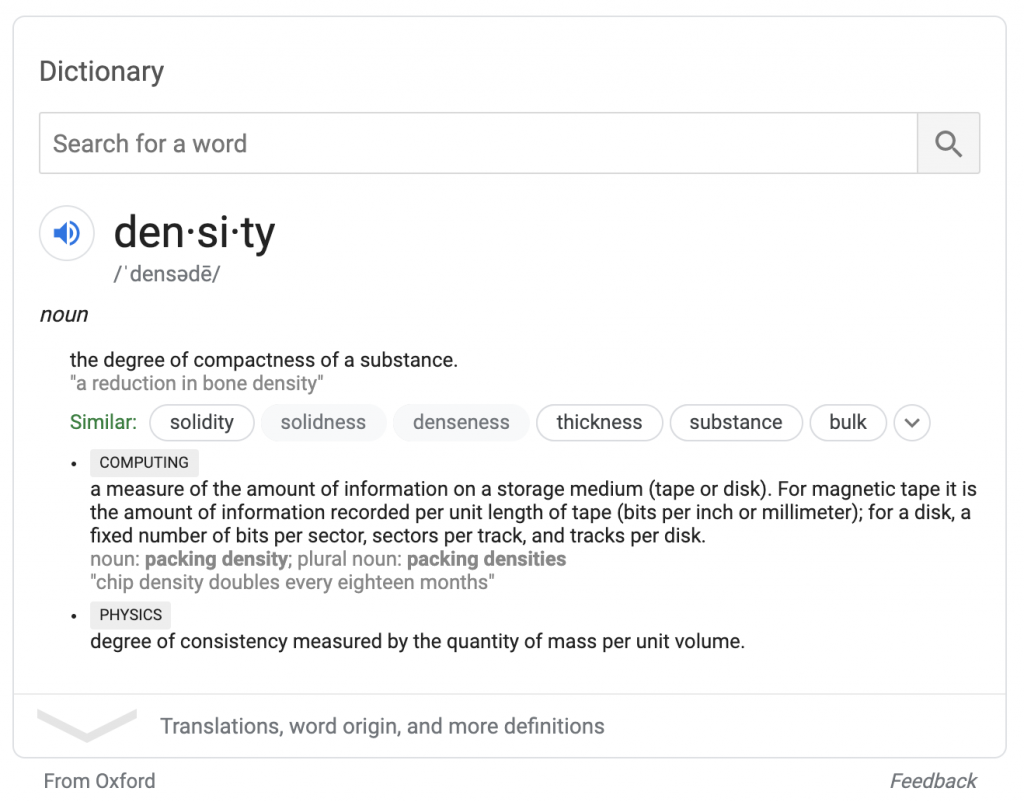
Căutările complete de vreme oferă o casetă de prognoză similară bazată pe datele de la weather.com. Ca și atribuirea Oxford, atribuirea weather.com apare sub casetă; Căutătorii pot interacționa cu datele din casetă fără a vizita vreodată weather.com.
Un alt rezultat similar de căutare este pentru datele nutriționale și compoziția alimentelor:
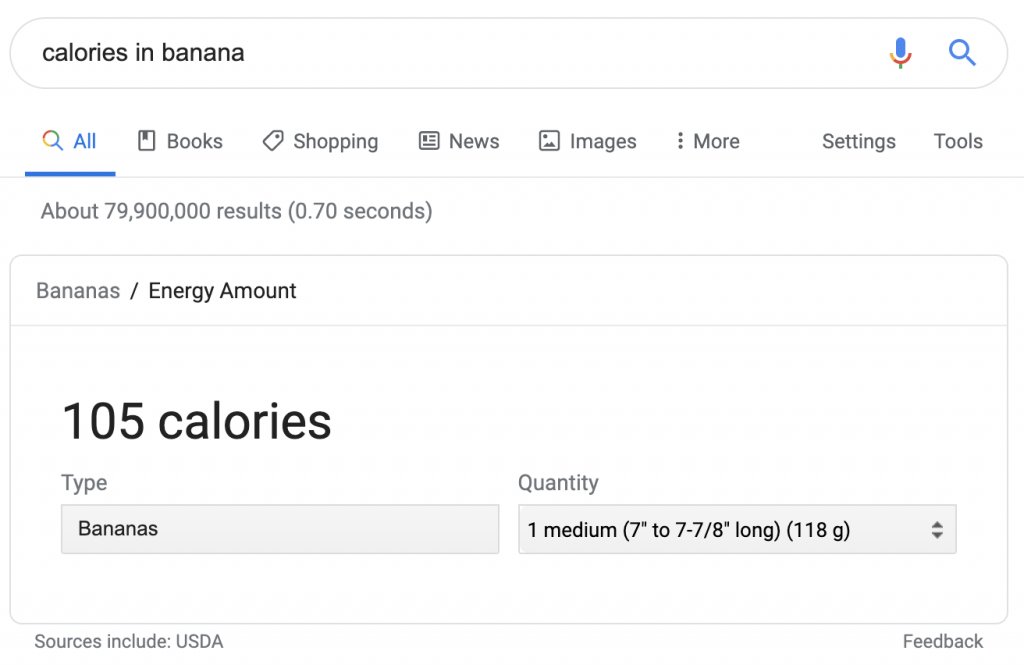
Cu toate acestea, în acest caz, atribuirea este listată ca „sursele includ”. Dacă sunt folosite alte surse, acestea nu sunt vizibile sau accesibile.
Rezultate orientate pe local
Multe rezultate legate de activitatea locală provin, de asemenea, din diverse surse pentru a crea un SERP care oferă o varietate de informații agregate și adunate. În loc să viziteze site-uri web diferite, un utilizator poate, de exemplu, să vadă lista de filme care rulează în prezent în apropierea lor, să caute orele de spectacol în diferite cinematografe și să găsească detalii – recenzii, rezumate și multe altele – despre filmele individuale. În niciun moment, cel care caută nu trebuie să părăsească SERP-ul selectat de Google.
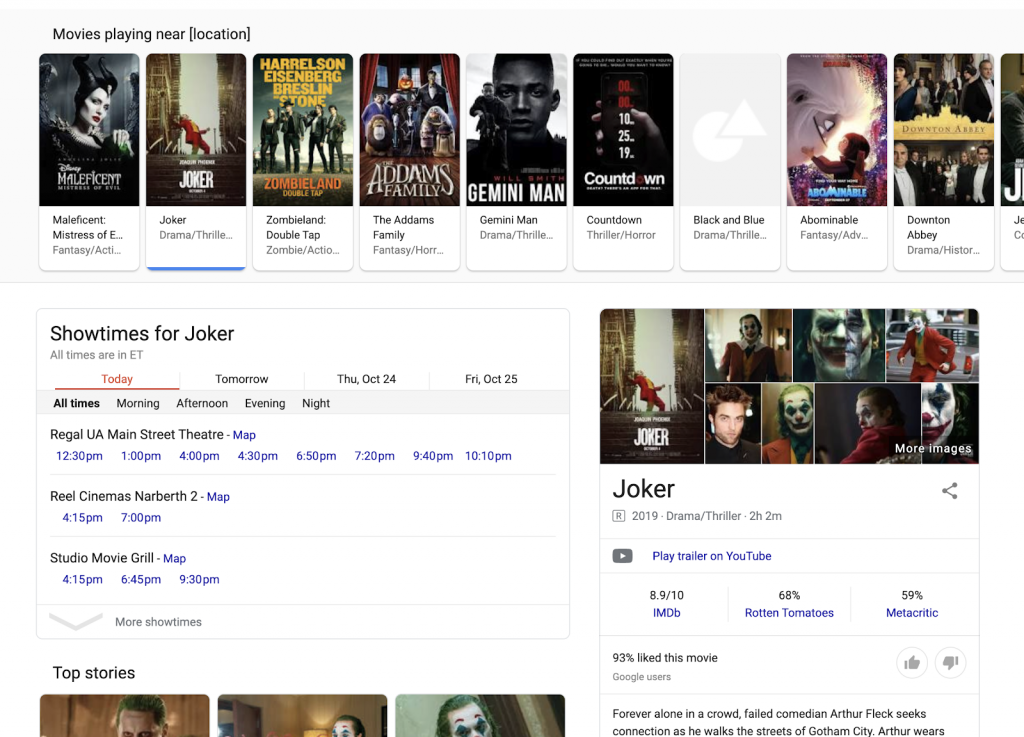
Acest tip de SERP se extinde în multe domenii diferite, inclusiv în călătorii.
Povești AMP
Poveștile AMP oferă un mod „axat pe poveste” pentru „consumul de știri pe mobil”. Acestea sunt un exemplu al modului în care indexarea bazată pe entități a îmbunătățit capacitatea Google de a extrage conținut din diferite surse și de a-l remixa. În unele povești create de Google pentru aparițiile celebrităților, Google a asociat o imagine dintr-o sursă cu text din alta, de exemplu.
Panouri de cunoștințe
Panourile de cunoștințe sunt „casete de informații care apar pe Google atunci când căutați entități” care fac parte din Knowledge Graph de la Google. Informațiile afișate în aceste panouri sunt extrase din mai multe surse, pe care Google le listează ca:
- parteneri de date care furnizează date autorizate pe anumite subiecte, cum ar fi filme sau muzică
- surse web deschise
- entități verificate care au sugerat modificări ale faptelor în propriile panouri de cunoștințe
- o previzualizare a rezultatelor Google Images pentru entitate
Google a indicat anterior că Knowledge Graph se bazează pe surse precum Wikipedia/Wikidata, CIA World Factbook, date structurate pe web-ul public, Google My Business și multe altele.
Ele pot afișa, de asemenea, entități asociate, permițând utilizatorilor de căutare să navigheze prin Knowledge Graph fără a părăsi site-ul web al motorului de căutare.
Alte caracteristici SERP
Alte caracteristici SERP includ elemente de predicție a interogărilor care încearcă să răspundă sau să redirecționeze activitatea de căutare fără a trimite utilizatorul de căutare pe un alt site web. Exemplele includ răspunsurile fără rezultate în căutarea mobilă sau completarea automată, precum și casetele „People also ask” (PAA).


Exemplu de căutare fără rezultate (mobil), care se afișează ca răspuns direct în caseta de completare automată de pe desktop
Gestionarea conținutului în rezultatele căutării
Markup Schema.org
Cu puțin control direct asupra celorlalte elemente care formează o listă de căutare, SEO s-au sprijinit masiv pe puterea fragmentelor îmbogățite prin marcajul Schema.org pentru a face listele lor să iasă în evidență pe SERP-uri.
Cu toate acestea, Google a luat măsuri represive împotriva utilizării abuzive a markupurilor bogate, inclusiv a stelelor de recenzie și a marcajului Întrebări frecvente:
Stelele Google Review din rezultatele căutării au scăzut cu 14% de la actualizare:
— Site-urile financiare au scăzut cu 46%
— Site-urile imobiliare au scăzut cu 46%
— Site-urile de lege și guvern au scăzut cu 28%Date noi prin @dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
– Cyrus (@CyrusShepard) 24 septembrie 2019
Pentru a nu avea SERP-uri pline de rezultate #FAQ, #Google pare să fi stabilit limita la 3 rezultate de întrebări frecvente #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
— AJ Ghergich (@SEO) 8 octombrie 2019
Indicații explicite despre conținutul care nu poate fi utilizat
În această săptămână, Google lansează etichete de gestionare a fragmentelor care pot fi folosite pentru a indica lui Google câteva limite cu privire la ceea ce poate fi folosit pentru a crea fragmentul de pagină în SERP-uri.
Noile etichete de management au două limitări principale:
- Acestea nu se aplică datelor structurate (markup Schema.org) de pe pagina . Datele structurate Schema.org acceptate de Google sunt întotdeauna eligibile pentru afișare în rezultatele căutării.
- Acestea pot împiedica utilizarea paginii dvs. în anumite „funcții speciale” din SERP-uri, inclusiv fragmente recomandate , dacă nu îndeplinesc lungimile minime cerute de caracteristica SERP. Deoarece lungimea variază în funcție de limbă, Google nu publică lungimile minime pentru fragmentele prezentate. În continuare, „[c]ei care nu doresc să apară conținut ca fragmente prezentate pot experimenta cu lungimi maxime mai mici ale fragmentelor.”
Proprietarii de site-uri web au două opțiuni pentru a implementa aceste etichete:
1. Meta-roboți etichete
Începând de la sfârșitul lunii octombrie, în întreaga lume, aceste meta-etichete roboți pot fi adăugate la pagina <head> sau în antetul HTTP x-robots.
- <meta name="roboți” content=" nosnippet „> – nu afișați textul fragmentului pentru această pagină. O miniatură de imagine poate fi folosită în continuare.
- <meta name="robots” content=" max-snippet: 50″> – setați lungimea maximă în număr de caractere pentru fragment. Lungimea unui fragment de „0” este echivalentul „nosnippet”; o lungime a fragmentului de „-1” este interpretată în sensul că nu există nicio limită pentru lungimea fragmentului.
- <meta name="robots” content=" max-video-preview: 3″> – setați durata maximă, în secunde, pentru o previzualizare video. O lungime a videoclipului de „0” va împiedica afișarea previzualizărilor video; o lungime video de „-1” este interpretată în sensul că nu există nicio limită pentru lungimea previzualizării videoclipului.
- <meta name="robots” content=" max-image-preview: standard”> – setați dimensiunea maximă a imaginii pentru imaginile din această pagină. Opțiunile sunt: „niciunul”, „standard” sau „mari”.
Puteți folosi mai mult de un operator de gestionare a fragmentelor în aceeași etichetă meta robots. Separați fiecare operator printr-o virgulă.
2. Atribut HTML Data-nosnippet
La sfârșitul anului 2019, un nou atribut HTML va fi recunoscut de Google: data-nosnippet . Poate fi aplicat etichetelor <span>, <div> sau <selection>.
Atributul data-nosnippet împiedică afișarea textului din eticheta la care este aplicat în fragmentul de pagină.
Permisiune explicită pentru reutilizarea conținutului pentru presa europeană din Franța
Remixarea și republicarea conținutului de știri de către Google depășește deja limitele legii drepturilor de autor în unele locații. Franța a fost recent în centrul atenției:
Din cauza modificărilor aduse legislației privind drepturile de autor din Franța, Căutarea Google nu va afișa fragmente de text sau miniaturi de imagini pentru publicațiile de presă europene afectate din Franța, cu excepția cazului în care site-ul web a implementat metaetichete pentru a permite previzualizările căutării. (Sursă)
Cu alte cuvinte, Google va exclude din rezultatele căutării din Franța orice publicație europeană care nu îi permite în mod explicit să republiceze și eventual să remixe conținut.
În mod ironic, mijloacele de acordare a permisiunii nu sunt deosebit de clare: singura etichetă meta-roboți permisivă în mod explicit este „toate”, care „este valoarea implicită și nu are efect dacă este listată în mod explicit”, cu excepția, acum, pentru SERP-urile franceze.
În caz contrar, editorii pot indica o lipsă de limită a lungimii previzualizărilor textului și video doar printr-o convenție care nu este inclusă în anunțul privind gestionarea fragmentelor sau pot impune limite arbitrare pentru a semnala că nu doresc să interzică previzualizările de căutare. .
Mersul pe frânghie
Fiecare site web va trebui să găsească echilibrul potrivit între protejarea conținutului său și modelarea prezenței sale pe SERP-urile Google.
Pe măsură ce Google se comportă din ce în ce mai mult ca un editor de conținut, ne putem aștepta la mai multe funcții SERP cu atribuții minime, precum și la mai multe țări în care legea drepturilor de autor – menită să protejeze proprietarii și creatorii de conținut – are un impact asupra a ceea ce Google poate și nu poate afișa.
Ceea ce cred că este interesant, totuși, sunt implicațiile legate de drepturile de autor ale acestui lucru... Oamenii se plâng de faptul că G preia conținut fără permisiune – etichetele fragmentelor vor fi permisiunea tacită. Va trece mult până când vor fi solicitate?
— Jenny Halasz (@jennyhalasz) 15 octombrie 2019
Din fericire, noile instrumente de gestionare a fragmentelor oferă proprietarilor de site-uri web începuturile unei casete de instrumente pentru a modela care părți – și cât de mult – din conținutul lor poate fi reutilizată de Google pe SERP-uri.
Deocamdată, cred că va fi înțelept să implementăm etichete de gestionare a fragmentelor, după caz, pe site-urile web cu conținut original substanțial, deși mă tem că etichetele care sunt doar restrictive nu vor fi utile pentru toate site-urile web. În ciuda acestui avertisment, există încă modalități de a le folosi pentru a optimiza experiența pe SERP-uri și pentru a obține mai mult trafic.
Cred că oamenii vor adopta noile etichete. Cred că există destul de multe oportunități de a „contura” un fragment cu acele etichete pentru a oferi o experiență mai bună decât ceea ce Google extrage automat și pentru a optimiza valorile CTR.
— Kevin_Indig (@Kevin_Indig) 16 octombrie 2019
Aștept cu nerăbdare să văd experimentele în diferite verticale pentru a găsi ceea ce funcționează cel mai bine.