
De ce ne-am mutat la calcularea fără server pentru a implementa versiuni personalizate
Publicat: 2018-11-22
Fotografie de panoumas nikhomkhai de la Pexels
Ca parte a angajamentului nostru de a împuternici agenții de marketing cu performanță să facă mai mult, cu mai puțin, fără griji , echipele de la TUNE caută mereu noi modalități de a servi clienții noștri. În acest caz, echipa noastră de inginerie de soluții a descoperit o tehnologie care simplifică modul în care implementează și acceptă versiuni personalizate pe platforma noastră. Ca rezultat, acum pot petrece mai mult timp (și mai puțini bani) lucrând cu mai mulți clienți pentru a construi soluțiile de care au nevoie.
La TUNE, ne mândrim cu furnizarea unei platforme flexibile și cuprinzătoare de marketing cu performanță, care permite rețelelor și agenților de publicitate să-și gestioneze campaniile de marketing digital, relațiile cu editorii, plățile și multe altele - direct din cutie, fără a fi nevoie să scrie o singură linie de cod. . Dar uneori, ca și în cazul altor sisteme SaaS complet gestionate, clienții noștri necesită configurații personalizate, funcționalități sau integrări care pot fi realizate doar prin suflecarea mânecilor și pornirea vechiului editor de cod. Recent, am trecut la o nouă tehnologie care schimbă modul în care construim aceste soluții: calculul fără server.
În această postare, voi trece prin problemele pe care le-am întâlnit cu dezvoltarea personalizată, pașii pe care i-am luat pentru a configura procesul nostru de construire fără server și modul în care această nouă metodologie rezolvă provocările legate de cost și scară.
Provocare: ține pasul cu cererea de soluții personalizate
Când am început prima dată echipa de inginerie de soluții la TUNE, am tratat fiecare build personalizată de client ca pe o build separată. Cele mai multe dintre aceste versiuni aveau o componentă front-end, care de obicei era implementată ca o pagină personalizată pe platforma noastră și o componentă back-end care consta dintr-un server, o bază de date și orice altă infrastructură necesară pentru a menține serverele la zi. -data si operationala.
La început, această metodologie a funcționat pentru noi. Având o echipă mică, slabă, cu câteva versiuni personalizate complexe, metoda noastră de furnizare și configurare a unui server diferit pentru fiecare versiune a funcționat pentru noi. Ne-a permis să creăm experiențe uimitoare pentru clienții noștri.
Dar, pe măsură ce numărul de versiuni a crescut, începeam să întâmpinăm probleme:
- Prea multe servere! După cum vă puteți imagina, furnizarea a minimum două casete pe build ne-a determinat să avem prea multe servere. Numărul mare de servere și toate durerile care le însoțesc (cum ar fi actualizările de securitate și backup-urile) ne costau mai mult timp decât am vrea să admitem.
- Țineți acele servere activate. Cu fiecare server fiind propria sa entitate, eram responsabili să ne asigurăm că fiecare server este întotdeauna activ și operațional.
- PHP nu este pentru mine. Majoritatea versiunilor noastre sunt realizate dintr-o imagine de bază Docker PHP. Dar, pe măsură ce echipa noastră a crescut, știam că forțarea oamenilor să-și scrie versiunile clienților în PHP 5.0 atunci când erau vrăjitori Python nu avea niciun sens.
- Asta devine scump. Cu toate serverele noastre implementate pe ec2/RDS, începeam să vedem un cost lunar semnificativ.
- Siguranța pe primul loc. Deoarece aceste servicii gestionau date sensibile ale clienților, a trebuit să oferim o metodă de autentificare pentru adresele URL publice pentru a asigura securitatea acelor date.
- Crons sunt duri. O mulțime de servicii back-end constau din scripturi cron și nu aveam o modalitate eficientă de a le gestiona.
Odată cu apariția acestor provocări, am știut că trebuie să găsim o modalitate mai simplă și mai eficientă din punct de vedere al costurilor de a oferi funcționalități back-end pentru versiunile clienților noștri. Dar, după multe dezbateri și fără un lider clar pentru o soluție, începeam să rămânem fără idei. (În plus, având în vedere că cererea pentru noi versiuni personalizate crește ca nebun, timpul nu a fost cu siguranță de partea noastră.)
Soluție: computerul fără server pentru salvare
Dacă nu ați auzit de calcularea fără server , s- ar putea să vă întrebați același lucru pe care l-am fost noi când am auzit prima dată despre el. Cum poți executa cod fără un server? (Nu vă faceți griji; înțelegerea dvs. fundamentală despre programare este încă corectă și nu, nu am abuzat de specialul happy hour înainte de a scrie asta.)
„Fără server” este un termen cu adevărat confuz pentru o nouă tehnologie, deoarece – să nu fim prosti – cu siguranță există încă un server care execută cod. Deci, ce este exact serverless?
Serverless computing este un model de execuție cloud computing în care furnizorul de cloud acționează ca server, gestionând dinamic alocarea resurselor mașinii. – Wikipedia
Soluțiile cloud fără server vă permit să construiți și să rulați aplicații și servicii fără a vă gândi la necazurile asociate cu serverele. În esență, computerul fără server vă permite să faceți ceea ce faceți cel mai bine: să scrieți cod.
Procesul de configurare fără server
Pentru a vă arăta esențialul modului în care funcționează tehnologia fără server, voi parcurge pașii pe care i-am folosit pentru a configura această funcționalitate.
Notă: Există mulți furnizori de cloud cu funcționalitate serverless. În acest exemplu, folosim AWS Lambda .

- Mai întâi, creați o nouă funcție Lambda și selectați „ Blueprints ”. Apoi, tastați „ http ” în câmpul de cuvinte cheie și selectați fie punctul Python, fie Node microservice-http-endpoint. (Planurile sunt blocuri de cod prefabricate menite să facă dezvoltarea mai rapidă. Cât de minunat este asta?) După ce ați făcut o selecție, faceți clic pe „ Configurare ”.
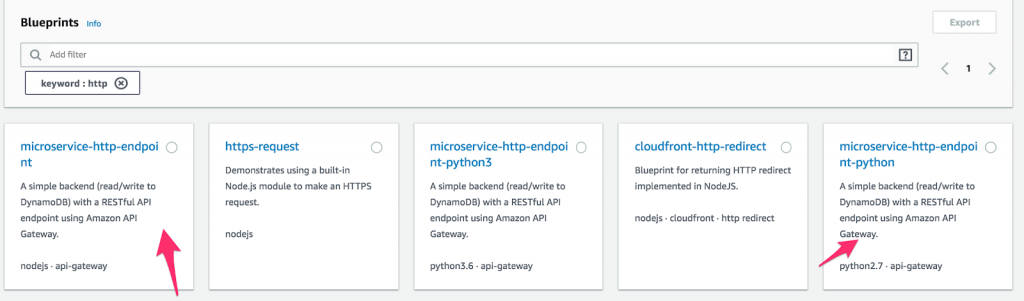
Cum să configurați o funcție pe AWS Lambda.
- Adăugați un nume de funcție și un rol. Apoi selectați un declanșator API Gateway cu opțiunea de securitate „ Deschidere cu cheie API ”. Acest gateway API va furniza o adresă URL publică care va declanșa funcția Lambda. Adăugarea cheii API oferă o metodă de autentificare, care este foarte recomandată.
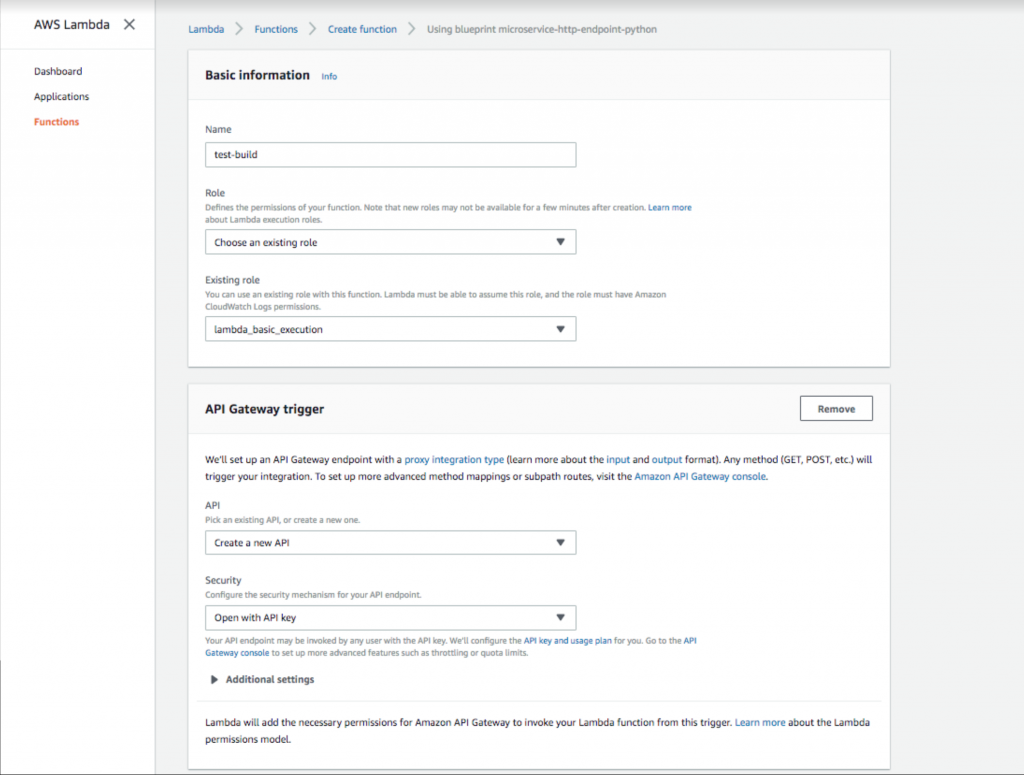
Configurarea unei chei gateway API deschise în AWS Lambda.
- Odată ce ați creat funcția, acum puteți face configurații pentru codul dvs. După cum puteți vedea, planul v-a oferit deja un cârlig de punct de intrare cool care vă permite să interacționați cu un tabel Dynamo (dacă doriți să adăugați o bază de date). Orice se află sub lambda_handler va fi executat când URL-ul public este încărcat. Deoarece adăugăm și o bază de date, să mergem la Dynamo și să creăm una.
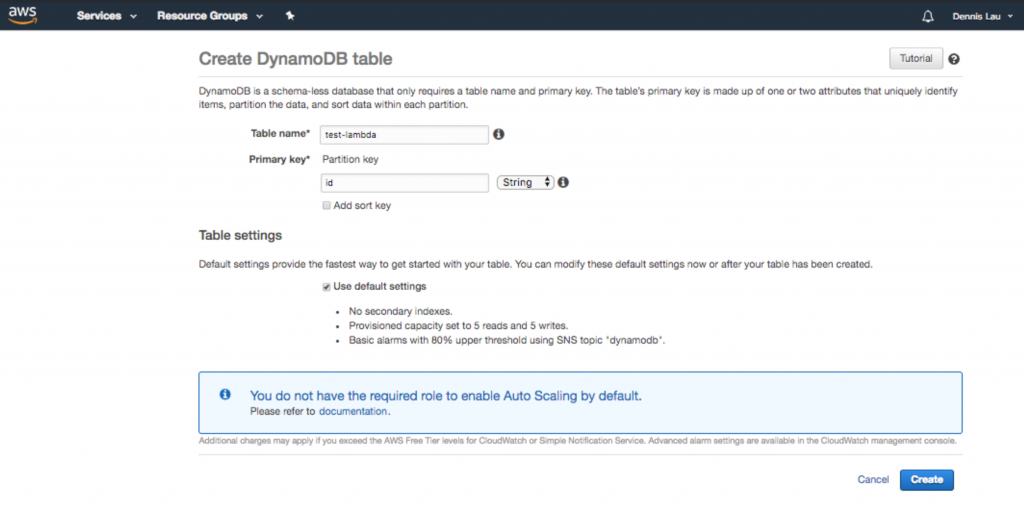
Crearea unui tabel de bază de date Dynamo în AWS Lambda.
- Odată ce tabelul Dynamo este creat, să facem un apel la această funcție Lambda de la o adresă URL publică. Reveniți la funcția dvs. și faceți clic pe pictograma „ API Gateway ” din partea de sus. Ar trebui să vedeți că punctul final și cheia API au fost deja create pentru dvs.
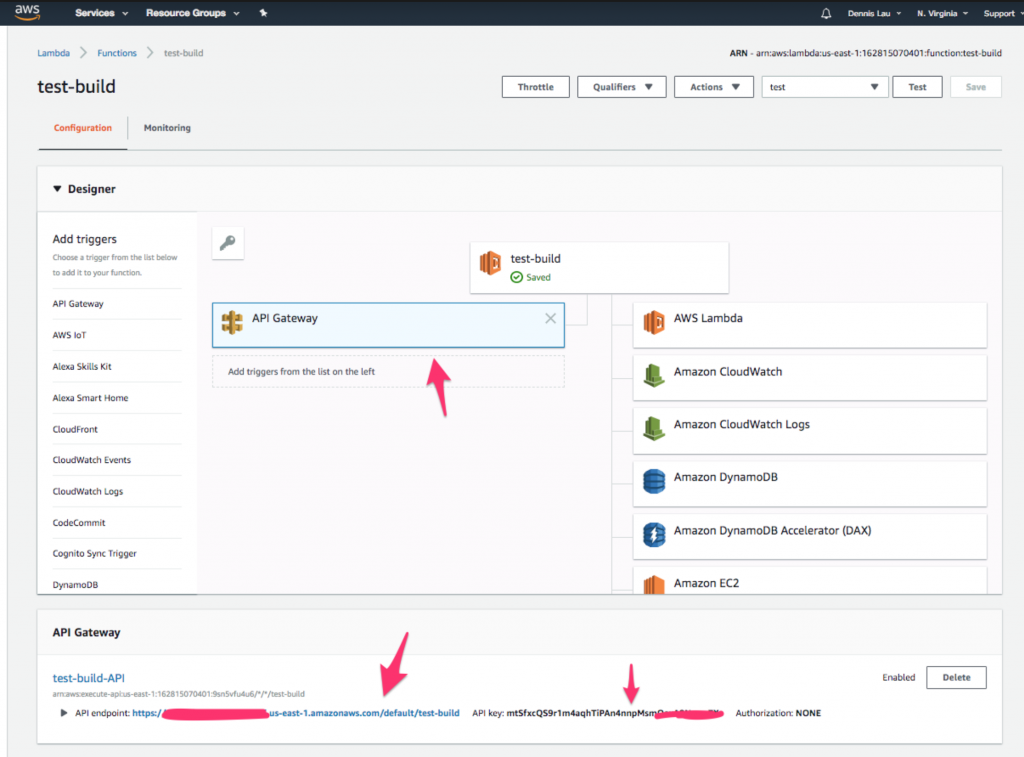
Unde găsiți pictograma API Gateway în funcțiile AWS Lambda.
- Acum deschideți terminalul și adăugați cheia API sub antetul „ x-api-key” , apoi adăugați numele tabelului pe care l-ați creat sub parametrul șir de interogare TableName .

Introduceți cheia și numele bazei de date în terminal pentru a finaliza.
- Mai întâi, creați o nouă funcție Lambda și selectați „ Blueprints ”. Apoi, tastați „ http ” în câmpul de cuvinte cheie și selectați fie punctul Python, fie Node microservice-http-endpoint. (Planurile sunt blocuri de cod prefabricate menite să facă dezvoltarea mai rapidă. Cât de minunat este asta?) După ce ați făcut o selecție, faceți clic pe „ Configurare ”.
Asta e! Acum aveți un back-end funcțional și securizat conectat la o bază de date. Tot ce a fost nevoie de cinci pași simpli.
Cum ne-a abordat computerul fără server provocările
Acum că v-am arătat cum să configurați versiuni fără server, să aruncăm o privire și să vedem cum se comportă acest model bazat pe cloud față de lista noastră de verificare a problemelor.
- Prea multe servere! Fără server... adică nu mai există servere, nu?
- Țineți acele servere activate. Deoarece computerul fără server este gestionat de furnizorul de cloud, aveți beneficiul de a avea acești furnizori (împreună cu metodele lor întărite în luptă și dovedite) pentru a vă monitoriza serverele. Pentru cei dintre voi care doresc să joace Sherlock Holmes, puteți vedea, de asemenea, toate jurnalele de server rezultate de funcția dvs. pe Cloudwatch .
- PHP nu este pentru mine. Modelele fără server vă permit să scrieți în C#, Python, NodeJS, Go și chiar Java.
- Asta devine scump. Cu soluțiile fără server, costurile sunt măsurate pe baza timpului de execuție (la 100 de milisecunde) și a cantității de date transferate. Spre deosebire de plata pe lună, care include timpul în care serverele tale stau inactiv, plătești doar pentru ceea ce folosești. Cu costuri de până la 0,000000208 USD per 100 ms de execuție, calculul fără server vă poate economisi o sumă semnificativă de numerar.
- Siguranța pe primul loc. Este sigur fără server? Cu un sistem de autentificare cu chei API încorporat, pariați că este.
- Crons sunt duri. Cu un sistem de management cron construit nativ pe Cloudwatch, trebuie doar să setați o fereastră de timp și să uitați de ea. Cloudwatch se ocupă de toate înregistrările și execuția.
Gânduri finale
Pentru echipa Solutions Engineering de la TUNE, trecerea la calcularea fără server a fost o schimbare a jocului. Ușurința în utilizare, economiile de costuri și caracteristicile prietenoase cu agilitatea au schimbat modul în care gestionăm toate noile modele ale clienților. Soluțiile bazate pe cloud fără server sunt setate să schimbe lumea computerului pe server. Nu știu despre tine, dar un lucru este sigur: echipa TUNE Solutions Engineering este pregătită.
Pentru a afla mai multe despre platforma TUNE și serviciile de dezvoltare personalizate pe care le oferim, vizitați pagina noastră de Servicii profesionale .