
7 eșecuri SEO văzute în sălbăticie (și cum le puteți evita)
Publicat: 2022-06-12
Primim adesea întrebări de la oameni care se întreabă de ce site-ul lor nu este clasat sau de ce nu este indexat de motoarele de căutare.
Recent, am dat peste mai multe site-uri cu erori majore care ar putea fi remediate cu ușurință, dacă proprietarii ar ști să caute. În timp ce unele greșeli de SEO sunt destul de complexe, iată câteva dintre erorile adesea trecute cu vederea de „trântire a capului”.
Așa că verifică aceste gafe SEO - și cum poți evita să le faci singur.
Eșecul SEO nr. 1: Probleme Robots.txt
Fișierul robots.txt are multă putere. Ea instruiește roboții motoarelor de căutare ce să excludă din indexurile lor.
În trecut, am văzut site-uri care au uitat să elimine o singură linie de cod din acel fișier după o reproiectare a site-ului și să-și introducă întregul site în rezultatele căutării.
Așa că, atunci când un site de flori a evidențiat o problemă, am început cu una dintre primele verificări pe care le fac întotdeauna pe un site - uită-te la fișierul robots.txt.
Am vrut să știu dacă robots.txt-ul site-ului blochează motoarele de căutare de la indexarea conținutului lor. Dar în loc de fișierul text așteptat, am văzut o pagină care se oferă să livreze flori către Robots.Txt.
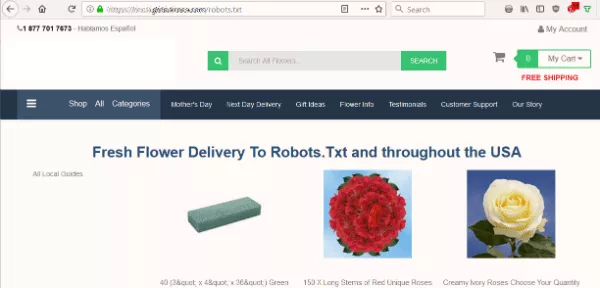
Site-ul nu avea robots.txt, care este primul lucru pe care îl caută un bot când accesează cu crawlere un site. Asta a fost prima lor greșeală. Dar să luăm acel fișier ca destinație... chiar?
Eșecul SEO nr. 2: Generarea automată a devenit sălbatică
În al doilea rând, site-ul genera automat conținut prostii. Probabil că i-ar livra lui Moș Crăciun sau orice text pe care l-am pus în URL.
Am rulat un instrument Verificați pagina serverului pentru a vedea ce stare afișa pagina generată automat. Dacă ar fi un 404 (nu găsit), atunci roboții ar ignora pagina așa cum ar trebui. Cu toate acestea, antetul serverului paginii a dat starea 200 (OK). Drept urmare, paginile false dădeau motoarele de căutare undă verde pentru a fi indexate.
Motoarele de căutare doresc să vadă conținut unic și semnificativ pe pagină. Deci, indexarea acestor non-pagini le-ar putea afecta SEO.
Eșecul SEO nr. 3: Erori canonice
Apoi, am verificat să văd ce părere au motoarele de căutare despre acest site. Ar putea să acceseze cu crawlere și să indexeze paginile?
Privind codul sursă al diferitelor pagini, am observat o altă eroare majoră.
Fiecare pagină avea un element de link canonic care indică înapoi către pagina de pornire:
<link rel="canonical” href="https://www.domain.com/” />
Cu alte cuvinte, motoarelor de căutare li se spunea că fiecare pagină este de fapt o copie a paginii de pornire. Pe baza acestei etichete, boții ar trebui să ignore restul paginilor de pe acel domeniu.
Din fericire, Google este suficient de inteligent pentru a afla când aceste etichete sunt probabil folosite din greșeală. Deci încă indexa unele dintre paginile site-ului. Dar această solicitare canonică universală nu a ajutat SEO site-ului.
Cum să evitați aceste eșecuri SEO
Pentru greșelile multiple ale site-ului de flori, iată remediile:
- Aveți un fișier robots.txt valid pentru a le spune motoarele de căutare cum să acceseze cu crawlere și să indexeze site-ul. Chiar dacă este un fișier gol, ar trebui să existe la rădăcina domeniului dvs.
- Generați un element de link canonic adecvat pentru fiecare pagină. Și nu îndreptați spre o pagină pe care doriți să o indexați.
- Afișați o pagină 404 personalizată atunci când adresa URL a unei pagini nu există. Asigurați-vă că returnează un cod de server 404 pentru a oferi motoarelor de căutare un mesaj clar.
- Fiți atenți la paginile generate automat. Evitați să produceți prostii sau pagini duplicate pentru motoarele de căutare și utilizatori.
Chiar dacă nu întâmpinați o problemă cu site-ul, acestea sunt puncte bune de revizuit periodic, doar pentru a fi în siguranță.
Ah, și nu puneți niciodată o etichetă canonică pe pagina dvs. 404 , în special îndreptând spre pagina dvs. de pornire... doar nu.
Eșecul SEO #4: Clasamentul peste noapte în cădere liberă
Uneori, o simplă schimbare poate fi o greșeală costisitoare. Această poveste vine dintr-o experiență cu unul dintre clienții noștri SEO.
Când extensia .org a numelui lor de domeniu a devenit disponibilă, au luat-o. Până acum, bine. Dar următoarea lor mișcare a dus la dezastru.
Ei au creat imediat o redirecționare 301 care direcționează .org nou achiziționat către site-ul lor principal .com. Raționamentul lor a avut sens - să capteze vizitatori captivanți care ar putea introduce extensia greșită.
Dar a doua zi, ne-au sunat, frenetici. Traficul lor pe site a fost inexistent. Nu aveau idee de ce.
Câteva verificări rapide au dezvăluit că clasamentele lor de căutare au dispărut de pe Google peste noapte. Nu a fost nevoie de prea multe întrebări și răspunsuri pentru a afla ce s-a întâmplat.
Au pus redirecționarea fără a lua în considerare riscul. Am făcut câteva săpături și am descoperit că .org avea un trecut sordid.

Proprietarul anterior al site-ului .org l-a folosit pentru spam. Odată cu redirecționarea, Google a alocat toată această otravă site-ului principal al companiei! Ne-a luat doar două zile să restabilim poziția site-ului în Google.
Cum să evitați acest eșec SEO
Cercetați întotdeauna profilul link-ului și istoricul oricărui nume de domeniu sub care vă înregistrați.
Un consultant SEO calificat poate face acest lucru. Există, de asemenea, instrumente pe care le puteți rula pentru a vedea ce schelete ar putea zace în dulapul site-ului.
Ori de câte ori iau un domeniu nou, îmi place să-l las să stea latent timp de șase luni până la un an cel puțin înainte de a încerca să fac ceva din el. Vreau ca motoarele de căutare să diferențieze clar noua încarnare a site-ului meu de viața anterioară. Este o precauție suplimentară pentru a vă proteja investiția.
Eșecul SEO nr. 5: Pagini care nu vor dispărea
Uneori, site-urile pot avea o problemă diferită - prea multe pagini în indexul de căutare.
Motoarele de căutare rețin uneori pagini care nu mai sunt valabile. Dacă oamenii ajung pe pagini de eroare atunci când vin din rezultatele căutării, este o experiență proastă pentru utilizator.
Unii proprietari de site-uri, din frustrare, listează adresele URL individuale în fișierul robots.txt. Ei speră că Google va lua indiciu și va înceta să le indexeze.
Dar această abordare eșuează! Dacă Google respectă robots.txt, atunci nu va accesa cu crawlere acele pagini. Deci, Google nu va vedea niciodată starea 404 și nu va afla că paginile sunt invalide.
Cum să evitați această greșeală SEO
Prima parte a remedierii este să nu interziceți aceste adrese URL în robots.txt. VREI ca boții să se acceseze cu crawlere și să știe ce adrese URL ar trebui să fie eliminate din indexul de căutare.
După aceea, configurați o redirecționare 301 pe vechea adresă URL. Trimiteți vizitatorul (și motoarele de căutare) la cea mai apropiată pagină de înlocuire de pe site. Acest lucru are grijă de vizitatorii dvs., indiferent dacă provin din căutare sau dintr-un link direct.
Eșecul SEO nr. 6: Echititatea linkurilor pierdute
Am urmat un link de pe site-ul unei universități și am fost întâmpinat cu o eroare 404 (negăsită).
Acest lucru nu este neobișnuit, cu excepția faptului că linkul era către /home.html — fosta adresă URL a paginii de pornire a site-ului.
La un moment dat, trebuie să-și fi schimbat arhitectura site-ului și să fi șters vechiul /home.html, pierzând redirecționarea în shuffle.
În mod ironic, pagina lor 404 spune că puteți începe de la început de la pagina de pornire, ceea ce încercam să ajung în primul rând.
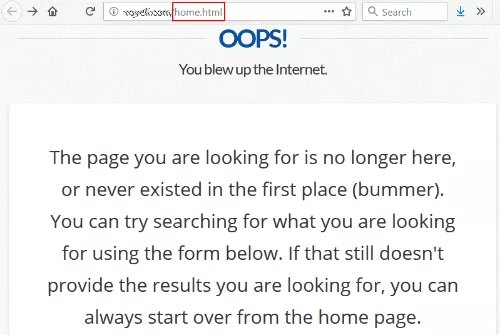
Este un pariu destul de sigur că acest site i-ar plăcea să aibă un link frumos de la o universitate respectată care merge la pagina lor de pornire. Și realizarea acestui lucru este în întregime în controlul lor. Nici măcar nu trebuie să contacteze site-ul care leagă.
Cum să remediați această eroare
Pentru a remedia acest link, trebuie doar să pună o redirecționare 301 care indică /home.html către pagina de pornire curentă. (Consultați articolul nostru despre cum să configurați o redirecționare 301 pentru instrucțiuni.)
Pentru credit suplimentar, accesați Google Search Console și examinați Raportul privind starea acoperirii indexului. Uitați-vă la toate paginile care sunt raportate ca returnând o eroare 404 și lucrați la remedierea cât mai multor erori posibil aici.
Eșecul SEO #7: Eșecul de copiere/lipire
Se lansează reproiectarea site-ului, etichetele canonice sunt instalate și noul Manager de etichete Google este instalat. Totuși, există încă probleme de clasare. De fapt, o nouă pagină de destinație nu afișează niciun vizitator în Google Analytics.
Echipa de dezvoltare răspunde că a făcut totul ca la carte și a urmat exemplele la literă.
Au exact dreptate. Ei au urmat exemplele - inclusiv lăsând codul exemplu! După ce au copiat și lipit, dezvoltatorii au uitat să introducă propriile informații despre site-ul țintă.
Iată trei exemple pe care analiștii noștri le-au întâlnit în codul site-ului web:
- <link rel="canonical” href="http://example.com/”>
- „analyticsAccountNumber”: „UA-123456-1”
- _gaq.push(['_setAccount', 'UA-000000-1']);
Cum să evitați acest eșec SEO
Când lucrurile nu funcționează corect, priviți dincolo de doar „acest element este în codul sursă?” Este posibil ca codurile de validare, numerele de cont și adresele URL adecvate să nu fi fost niciodată specificate în codul dvs. HTML.
Se întâmplă greșeli, iar oamenii sunt doar oameni. Sper că aceste exemple vă vor ajuta să evitați gafele SEO similare. În beneficiul dumneavoastră, am creat un Ghid SEO aprofundat care prezintă sfaturi SEO și cele mai bune practici.
Dar unele probleme de SEO sunt mai complexe decât credeți. Dacă aveți probleme de indexare, atunci suntem aici pentru a vă ajuta. Sunați-ne sau completați formularul nostru de solicitare și vă vom contacta.
Vă place această postare? Vă rugăm să vă abonați la blogul nostru pentru a primi postări noi în căsuța dvs. de e-mail.