
Clustering semantic de cuvinte cheie în Python
Publicat: 2021-04-19Într-o lume plină de mituri de marketing digital, credem că găsim soluții practice la problemele de zi cu zi este ceea ce avem nevoie.
La PEMAVOR, împărtășim întotdeauna expertiza și cunoștințele noastre pentru a îndeplini nevoile pasionaților de marketing digital. Prin urmare, postăm adesea scripturi Python gratuite pentru a vă ajuta să vă creșteți rentabilitatea investiției.
Clusteringul nostru de cuvinte cheie SEO cu Python a deschis calea către obținerea de noi perspective pentru proiecte SEO mari, cu doar mai puțin de 50 de linii de coduri Python.
Ideea din spatele acestui script a fost să vă permită să grupați cuvinte cheie fără să plătiți „taxe exagerate” pentru... ei bine, știm cine...
Dar ne-am dat seama că acest scenariu nu este suficient de unul singur. Este nevoie de un alt script, astfel încât voi, băieți, să vă puteți înțelege mai bine cuvintele cheie: trebuie să puteți „ grupa cuvintele cheie după semnificație și relații semantice. ”
Acum, este timpul să ducem Python pentru SEO cu un pas mai departe.
Date oncrawl³
 Află mai multe
Află mai multeModul tradițional de grupare semantică
După cum știți, metoda tradițională pentru semantică este să construiți modele word2vec , apoi să grupați cuvintele cheie cu Distanța lui Word Mover .
Dar aceste modele necesită mult timp și efort pentru a construi și a antrena. Prin urmare, am dori să vă oferim o soluție mai simplă. 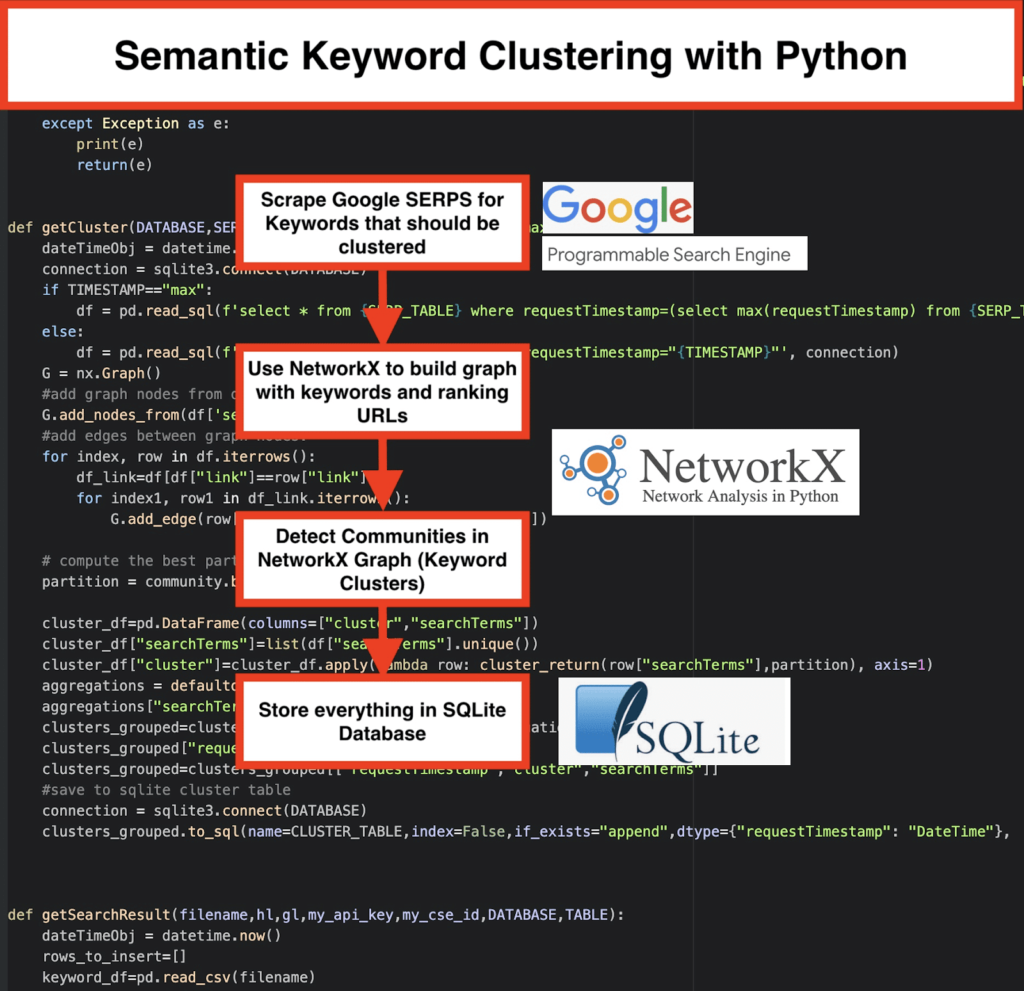
Rezultatele SERP Google și descoperirea semanticii
Google folosește modele NLP pentru a oferi cele mai bune rezultate de căutare. Este ca și cum ar fi deschisă cutia Pandorei și nu o știm exact.
Cu toate acestea, în loc să ne construim modelele, putem folosi această casetă pentru a grupa cuvintele cheie după semantică și semnificație.
Iată cum o facem:
️ Mai întâi, veniți cu o listă de cuvinte cheie pentru un subiect.
️ Apoi, răzuiți datele SERP pentru fiecare cuvânt cheie.
️ În continuare, se creează un grafic cu relația dintre paginile de clasare și cuvintele cheie.
️ Atâta timp cât aceleași pagini se clasează pentru cuvinte cheie diferite, înseamnă că sunt legate împreună. Acesta este principiul de bază din spatele creării clusterelor de cuvinte cheie semantice.
Este timpul să punem totul laolaltă în Python
Scriptul Python oferă următoarele funcții:
- Folosind motorul de căutare personalizat Google, descărcați SERP-urile pentru lista de cuvinte cheie. Datele sunt salvate într-o bază de date SQLite . Aici, ar trebui să configurați un API de căutare personalizat.
- Apoi, utilizați cota gratuită de 100 de solicitări zilnic. Dar oferă și un plan plătit pentru 5 USD la 1000 de misiuni dacă nu doriți să așteptați sau dacă aveți seturi mari de date.
- Este mai bine să mergeți cu soluțiile SQLite dacă nu vă grăbiți – rezultatele SERP vor fi atașate la tabel la fiecare rulare. (Pur și simplu luați o nouă serie de 100 de cuvinte cheie când aveți din nou cotă a doua zi.)
- Între timp, trebuie să configurați aceste variabile în Scriptul Python .
- CSV_FILE="keywords.csv” => stocați-vă cuvintele cheie aici
- LIMBA = „ro”
- ȚARA = „ro”
- API_KEY="xxxxxxx"
- CSE_ID="xxxxxxx"
- Rularea
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)va scrie rezultatele SERP în baza de date. - Clusteringul se face de networkx și modulul de detectare a comunității. Datele sunt preluate din baza de date SQLite – clusteringul este apelat cu
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Rezultatele Clustering pot fi găsite în tabelul SQLite – atâta timp cât nu schimbați, numele este „keyword_clusters” în mod implicit.
Mai jos, veți vedea codul complet:
# Clustering semantic de cuvinte cheie de către Pemavor.com # Autor: Stefan Neefischer ([email protected]) din googleapiclient.discovery import build importa panda ca pd import Levenshtein de la datetime import datetime din fuzzywuzzy import fuzz din urllib.parse import urlparse din tld import get_tld import langid import json importa panda ca pd import numpy ca np import networkx ca nx comunitate de import import sqlite3 import matematică import io din colecții import defaultdict def cluster_return(termen de căutare, partiție): returnare partiție[searchTerm] def language_detection(str_lan): lan=langid.classify(str_lan) return lan[0] def extract_domain(url, remove_http=True): uri = urlparse(url) dacă remove_http: nume_domeniu = f"{uri.netloc}" altceva: nume_domeniu = f"{uri.netloc}://{uri.netloc}" returnează nume_domeniu def extract_mainDomain(url): res = get_tld(url, as_object=True) retur res.fld def fuzzy_ratio(str1,str2): return fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): returnează fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): încerca: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='interogări(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() return res cu excepția excepției ca e: print(e) întoarcere(e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): încerca: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='interogări(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() return res cu excepția excepției ca e: print(e) întoarcere(e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() conexiune = sqlite3.connect(BAZA DE DATE) dacă TIMESTAMP="max": df = pd.read_sql(f'select * din {SERP_TABLE} unde requestTimestamp=(selectează max(requestTimestamp) din {SERP_TABLE})', conexiune) altceva: df = pd.read_sql(f'select * din {SERP_TABLE} unde requestTimestamp="{TIMESTAMP}"', conexiune) G = nx.Graph() #adăugați noduri de grafic din coloana cadru de date G.add_nodes_from(df['searchTerms']) #adăugați muchii între nodurile graficului: pentru index, rând în df.itrows(): df_link=df[df["link"]==rând["link"]] pentru index1, rândul 1 în df_link.itrows(): G.add_edge(rând[„Condiții de căutare”], rândul 1[„Termeni de căutare’]) # calculează cea mai bună partiție pentru comunitate (clustere) partiție = community.best_partition(G) cluster_df=pd.DataFrame(columns="cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df[„cluster”]=cluster_df.apply(rând lambda: cluster_return(rând[„termeni de căutare”], partiție), axa=1) agregari = defaultdict() agregari["searchTerms"]=' | '.a te alatura clusters_grouped=cluster_df.groupby(„cluster”).agg(agregations).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #salvare în tabelul cluster sqlite conexiune = sqlite3.connect(BAZA DE DATE) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(nume fișier,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() rows_to_insert=[] keyword_df=pd.read_csv(nume fișier) cuvinte cheie=keyword_df.iloc[:,0].tolist() pentru interogarea în cuvinte cheie: dacă hl=="implicit": rezultat = google_search_default_language(interogare, my_api_key, my_cse_id,gl) altceva: rezultat = google_search(interogare, my_api_key, my_cse_id,hl,gl) dacă „articole” în rezultat și „interogări” în rezultat: pentru poziția în interval (0,len(rezultat["articole"])): rezultat["articole"][poziție]["poziție"]=poziție+1 rezultat["articole"][position]["main_domain"]= extract_mainDomain(rezultat["articole"][poziție]["link"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(rezult["items"][position]["snippet"]) pentru poziția în interval (0,len(rezultat["articole"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":rezultat["interogări"]["cerere"][0]["totalResults"],"link":rezultat["articole"][poziție]["link"], „displayLink”:rezultat[„articole”][poziție][”displayLink”],”main_domain”:rezultat[„articole”][poziție][„domeniul_principal”], „poziție”:rezultat[„articole”][poziție][„poziția”], „fragment”:rezultat[„articole”][poziție][„fragment”], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], „snippet_matchScore_token”:rezultat[„articole”][poziție][”snippet_matchScore_token”],”title”:rezultat[„articole”][poziție][„titlu”], „title_matchScore_order”:rezultat[„articole”][poziție][”title_matchScore_order”],”title_matchScore_token”:rezultat[„articole”][poziție][”title_matchScore_token”], }) df=pd.DataFrame(rows_to_insert) #salvați rezultatele serp în baza de date sqlite conexiune = sqlite3.connect(BAZA DE DATE) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) #################################################################### #################################################################### ########################################## #Citește-mă: # #################################################################### #################################################################### ########################################## #1 - Trebuie să configurați un motor de căutare personalizat Google. # # Vă rugăm să furnizați cheia API și ID-ul de căutare. # # Setați, de asemenea, țara și limba în care doriți să monitorizați rezultatele SERP. # # Dacă nu aveți încă o cheie API și un ID de căutare, # # puteți urma pașii din secțiunea Cerințe preliminare din această pagină https://developers.google.com/custom-search/v1/overview#prerequisites # # # #2- De asemenea, trebuie să introduceți numele bazei de date, tabelului serp și tabelului cluster pentru a fi utilizate pentru salvarea rezultatelor. # # # #3- introduceți numele fișierului csv sau calea completă care conține cuvinte cheie care vor fi folosite pentru serp # # # #4 - Pentru gruparea cuvintelor cheie, introduceți marcajul de timp pentru rezultatele serp care vor fi folosite pentru grupare. # # Dacă trebuie să grupați rezultatele ultimei serp, introduceți „max” pentru marcajul de timp. # # sau puteți introduce un anumit marcaj de timp, cum ar fi „2021-02-18 17:18:05.195321” # # # #5- Răsfoiți rezultatele prin browserul DB pentru programul Sqlite # #################################################################### #################################################################### ########################################## #csv nume de fișier care au cuvinte cheie pentru serp CSV_FILE="keywords.csv" # determina limba LANGUAGE = "ro" #determine orașul ȚARA = „ro” Cheia api json de căutare personalizată #google API_KEY="INTRODUCEȚI CHEIA AICI" #ID motor de căutare CSE_ #sqlite numele bazei de date DATABASE="keywords.db" #numele tabelului pentru a salva rezultatele serp pe acesta SERP_TABLE="keywords_serps" # rulați serp pentru cuvinte cheie getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #numele tabelului pe care rezultatele clusterului îl vor salva. CLUSTER_TABLE="clustere de cuvinte cheie" #Vă rugăm să introduceți marca temporală, dacă doriți să creați clustere pentru un anumit marcaj temporal #Dacă trebuie să faceți clustere pentru ultimul rezultat serp, trimiteți-l cu valoarea „max”. #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="max" #run clustere de cuvinte cheie conform rețelelor și algoritmilor comunității getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Rezultatele SERP Google și descoperirea semanticii
Sperăm că v-a plăcut acest script cu scurtătura sa pentru a vă grupa cuvintele cheie în grupuri semantice fără a vă baza pe modele semantice. Deoarece aceste modele sunt adesea atât complexe, cât și costisitoare, este important să ne uităm la alte modalități de a identifica cuvintele cheie care au proprietăți semantice.
Tratând împreună cuvintele cheie legate semantic, puteți acoperi mai bine un subiect, puteți lega mai bine articolele de pe site-ul dvs. între ele și puteți crește rangul site-ului dvs. pentru un anumit subiect.