
Înțelegerea raportului de acoperire Search Console
Publicat: 2019-08-15Introducere în raportul de acoperire și modul de interpretare a datelor
Raportul privind acoperirea Search Console oferă informații despre paginile de pe site-ul dvs. care au fost indexate și enumeră adresele URL care au prezentat probleme în timp ce Googlebot încearcă să le acceseze cu crawlere și să le indexeze.
Pagina principală din raportul de acoperire arată adresele URL de pe site-ul dvs. grupate după stare:
- Eroare: pagina nu este indexată. Există mai multe motive pentru aceasta, paginile care răspund cu 404, pagini soft 404, printre altele.
- Valabil cu avertismente: pagina este indexată dar are probleme.
- Valabil: pagina este indexată.
- Exclus: Pagina nu este indexată, Google respectă regulile de pe site, cum ar fi etichetele noindex în robots.txt sau metaetichetele, etichetele canonice etc. care împiedică indexarea paginilor.
Acest raport de acoperire oferă mult mai multe informații decât vechea consolă de căutare Google. Google a îmbunătățit cu adevărat datele pe care le partajează, dar mai sunt unele lucruri care trebuie îmbunătățite.
După cum puteți vedea mai jos, Google arată un grafic cu numărul de adrese URL din fiecare categorie. Dacă există o creștere bruscă a erorilor, puteți vedea barele și chiar le puteți corela cu afișările pentru a determina dacă o creștere a adreselor URL cu erori sau avertismente poate reduce numărul de afișări.

După lansarea unui site sau după ce creați secțiuni noi, doriți să vedeți un număr tot mai mare de pagini indexate valide. Este nevoie de câteva zile pentru ca Google să indexeze paginile noi, dar puteți utiliza instrumentul de inspecție a URL-ului pentru a solicita indexarea și pentru a reduce timpul pentru Google pentru a vă găsi noua pagină.

Cu toate acestea, dacă observați un număr în scădere de adrese URL valide sau observați creșteri bruște, este important să lucrați la identificarea adreselor URL în secțiunea Erori și să remediați problemele enumerate în raport. Google oferă un rezumat bun al acțiunilor de efectuat atunci când există creșteri ale erorilor sau avertismentelor.
Google oferă informații despre erorile și câte adrese URL au această problemă:

Rețineți că Google Search Console nu afișează informații 100% exacte. De fapt, au existat mai multe rapoarte despre erori și anomalii de date. În plus, consola de căutare Google necesită timp pentru a se actualiza, se știe că datele sunt în urmă cu 16 până la 20 de zile. De asemenea, raportul va afișa uneori mai mult de 1000 de pagini cu erori sau categorii de avertismente, așa cum puteți vedea în imaginea de mai sus, dar vă permite doar să vedeți și să descărcați un eșantion de 1000 de adrese URL pe care să le auditați și să verificați.
Cu toate acestea, acesta este un instrument excelent pentru a găsi probleme de indexare pe site-ul dvs.:
Când faceți clic pe o anumită eroare, veți putea vedea pagina cu detalii care listează exemple de adrese URL:

După cum puteți vedea în imaginea de mai sus, aceasta este pagina de detalii pentru toate adresele URL care răspund cu 404. Fiecare raport are un link „Aflați mai multe” care vă duce la o pagină de documentație Google care oferă detalii despre eroarea respectivă. Google oferă, de asemenea, un grafic care arată numărul de pagini afectate de-a lungul timpului.
Puteți face clic pe fiecare adresă URL pentru a inspecta adresa URL care este similară cu vechea funcție „preluare ca Googlebot” din vechea Consolă de căutare Google. De asemenea, puteți testa dacă pagina este blocată de robots.txt
După ce remediați adresele URL, puteți solicita Google să le valideze, astfel încât eroarea să dispară din raport. Ar trebui să acordați prioritate remedierii problemelor care se află în starea de validare „eșuată” sau „nu a început”.
Este important de menționat că nu trebuie să vă așteptați ca toate adresele URL de pe site-ul dvs. să fie indexate. Google afirmă că scopul webmasterului ar trebui să fie indexarea tuturor adreselor URL canonice. Paginile duplicat sau alternative vor fi clasificate ca fiind excluse, deoarece au conținut similar cu pagina canonică.
Este normal ca site-urile să aibă mai multe pagini incluse în categoria excluse. Majoritatea site-urilor web vor avea mai multe pagini fără metaetichete de index sau blocate prin robots.txt. Când Google identifică o pagină duplicată sau alternativă, trebuie să vă asigurați că acele pagini au o etichetă canonică care indică adresa URL corectă și să încercați să găsiți echivalentul canonic în categoria validă.
Google a inclus un filtru drop-down în partea din stânga sus a raportului, astfel încât să puteți filtra raportul pentru toate paginile cunoscute, toate paginile trimise sau adresele URL dintr-un anumit sitemap. Raportul implicit include toate paginile cunoscute care includ toate adresele URL descoperite de Google. Toate paginile trimise includ toate adresele URL pe care le-ați raportat printr-un sitemap. Dacă ați trimis mai multe sitemap-uri, puteți filtra după adrese URL din fiecare sitemap.
[Studiu de caz] Măriți bugetul de accesare cu crawlere pe paginile strategice
 Citiți studiul de caz
Citiți studiul de cazErori, avertismente, adrese URL valide și excluse
Eroare
- Eroare de server (5xx): serverul a returnat o eroare 500 când Googlebot a încercat să acceseze cu crawlere pagina.
- Eroare de redirecționare: când Googlebot a accesat cu crawlere adresa URL, a apărut o eroare de redirecționare, fie pentru că lanțul era prea lung, a existat o buclă de redirecționare, adresa URL a depășit lungimea maximă a adresei URL sau a existat o adresă URL greșită sau goală în lanțul de redirecționare.
- Adresa URL trimisă blocată de robots.txt: adresele URL din această listă sunt blocate de fișierul dvs. robts.txt.
- Adresa URL trimisă marcată „noindex”: adresele URL din această listă au o etichetă meta robots „noindex” sau un antet http.
- Adresa URL trimisă pare să fie un soft 404: o eroare soft 404 apare atunci când o pagină care nu există (a fost eliminată sau redirecționată) afișează utilizatorului un mesaj „pagină negăsită”, dar nu reușește să returneze un cod de stare HTTP 404. Soft 404 se întâmplă și atunci când paginile sunt redirecționate către pagini nerelevante, de exemplu o pagină care redirecționează către pagina principală în loc să returneze un cod de stare 404 sau să se redirecționeze către o pagină relevantă.
- Adresa URL trimisă returnează o solicitare neautorizată (401): pagina trimisă pentru indexare returnează un răspuns HTTP neautorizat 401.
- Adresa URL trimisă nu a fost găsită (404): pagina a răspuns cu o eroare 404 Not Found când Googlebot a încercat să acceseze pagina cu crawlere.
- Adresa URL trimisă are o problemă de accesare cu crawlere: Googlebot a întâmpinat o eroare de accesare cu crawlere în timpul accesării cu crawlere a acestor pagini, care nu se încadrează în niciuna dintre celelalte categorii. Va trebui să verificați fiecare adresă URL și să determinați care ar fi putut fi problema.
Avertizare
- Indexat, deși blocat de robots.txt: pagina a fost indexată deoarece Googlebot a accesat-o prin link-uri externe care indică spre pagină, dar pagina este blocată de robots.txt. Google marchează aceste adrese URL ca avertismente, deoarece nu sunt siguri dacă pagina ar trebui să fie blocată de apariția în rezultatele căutării. Dacă doriți să blocați o pagină, ar trebui să utilizați o metaetichetă „noindex” sau să utilizați un antet de răspuns HTTP noindex.
Dacă Google este corect și adresa URL a fost blocată incorect, ar trebui să actualizați fișierul robots.txt pentru a permite Google să acceseze cu crawlere pagina.
Valabil
- Trimis și indexat: adresele URL pe care le-ați trimis la Google prin sitemap.xml pentru indexare și au fost indexate.
- Indexat, netrimis în sitemap: URL-ul a fost descoperit de Google și indexat, dar nu a fost inclus în sitemap. Este recomandat să vă actualizați harta site-ului și să includeți fiecare pagină pe care doriți să o acceseze cu crawlere și să le indexeze Google.
Exclus
- Exclus de eticheta „noindex”: când Google a încercat să indexeze pagina, a găsit o etichetă meta robots „noindex” sau un antet HTTP.
- Blocat de instrumentul de eliminare a paginii: cineva a trimis o solicitare la Google pentru a nu indexa această pagină utilizând solicitarea de eliminare a adresei URL din Google Search Console. Dacă doriți ca această pagină să fie indexată, conectați-vă la Google Search Console și eliminați-o din lista de pagini eliminate.
- Blocat de robots.txt: fișierul robots.txt are o linie care exclude accesarea cu crawlere a adresei URL. Puteți verifica ce linie face acest lucru utilizând testerul robots.txt.
- Blocat din cauza unei solicitări neautorizate (401): La fel ca în categoria Eroare, paginile de aici revin cu un antet HTTP 401.
- Anomalie de accesare cu crawlere: aceasta este un fel de categorie generală, adresele URL de aici fie răspund cu coduri de răspuns la nivel 4xx sau 5xx; Aceste coduri de răspuns împiedică indexarea paginii.
- Accesat cu crawlere – momentan nu este indexat: Google nu oferă un motiv pentru care adresa URL nu a fost indexată. Ei sugerează retrimiterea adresei URL pentru indexare. Cu toate acestea, este important să verificați dacă pagina are conținut subțire sau duplicat, este canonizată la o altă pagină, are o directivă noindex, valorile arată o experiență proastă a utilizatorului, timpul mare de încărcare a paginii etc. Ar putea fi mai multe motive pentru care Google nu vrea să indexeze pagina.
- Descoperit – momentan neindexat: Pagina a fost găsită, dar Google nu a inclus-o în indexul său. Puteți trimite adresa URL pentru indexare pentru a accelera procesul, așa cum am menționat mai sus. Google afirmă că motivul tipic pentru care se întâmplă acest lucru este că site-ul a fost supraîncărcat și Google a reprogramat accesarea cu crawlere.
- Pagina alternativă cu etichetă canonică adecvată: Google nu a indexat această pagină deoarece are o etichetă canonică care indică o adresă URL diferită. Google a respectat regula canonică și a indexat corect adresa URL canonică. Dacă ați vrut ca această pagină să nu fie indexată, atunci nu este nimic de reparat aici.
- Duplicat fără canonic selectat de utilizator: Google a găsit duplicate pentru paginile enumerate în această categorie și niciuna nu utilizează etichete canonice. Google a selectat o versiune diferită ca etichetă canonică. Trebuie să examinați aceste pagini și să adăugați o etichetă canonică care să indice adresa URL corectă.
- Duplicat, Google a ales un alt canon canonic decât utilizator: adresele URL din aceste categorii au fost descoperite de Google fără o solicitare explicită de accesare cu crawlere. Google le-a găsit prin link-uri externe și a stabilit că există o altă pagină care face un canonic mai bun. Google nu a indexat aceste pagini din acest motiv. Google recomandă marcarea acestor adrese URL ca duplicate ale codului canonic.
- Negăsit (404): când Googlebot încearcă să acceseze aceste pagini, el răspunde cu o eroare 404. Google afirmă că aceste adrese URL nu au fost trimise, aceste adrese URL au fost găsite prin link-uri externe care indică aceste adrese URL. Este o idee bună să redirecționați aceste adrese URL către pagini similare pentru a profita de echitatea linkurilor și, de asemenea, pentru a vă asigura că utilizatorii ajung pe o pagină relevantă.
- Pagina eliminată din cauza unei plângeri legale: cineva a reclamat aceste pagini din cauza unor probleme legale, cum ar fi o încălcare a drepturilor de autor. Puteți contesta aici plângerea juridică depusă.
- Pagina cu redirecționare: aceste adrese URL sunt redirecționate, prin urmare sunt excluse.
- Soft 404: După cum s-a explicat mai sus, aceste adrese URL sunt excluse, deoarece ar trebui să răspundă cu un 404. Verificați paginile și asigurați-vă că, dacă au un mesaj „negăsit”, acestea să răspundă cu un antet HTTP 404.
- Adresa URL trimisă duplicat, neselectată ca canonică: asemănător cu „Google a ales un alt canonic decât utilizatorul”, cu toate acestea, adresele URL din această categorie au fost trimise de dvs. Este o idee bună să vă verificați sitemapurile și să vă asigurați că nu sunt incluse pagini duplicat.
Cum să utilizați datele și elementele de acțiune pentru îmbunătățirea site-ului
Lucrând la o agenție, am acces la o mulțime de site-uri diferite și la rapoartele lor de acoperire. Am petrecut timp analizând erorile pe care Google le raportează în diferitele categorii.
A fost util să găsiți probleme cu canonizarea și conținutul duplicat, totuși, uneori, întâlniți discrepanțe precum cea raportată de @jroakes:

Se pare că Google Search Console > Inspecție URL > Test live raportează incorect toate fișierele JS și CSS ca accesare cu crawlere permisă: Nu: blocat de robots.txt. Testați aproximativ 20 de fișiere pe 3 domenii. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16 iulie 2019
AJ Koh, a scris un articol grozav la scurt timp după ce noua Consolă de căutare Google a devenit disponibilă, unde explică că valoarea reală a datelor este utilizarea lor pentru a picta o imagine a sănătății pentru fiecare tip de conținut de pe site-ul dvs.:
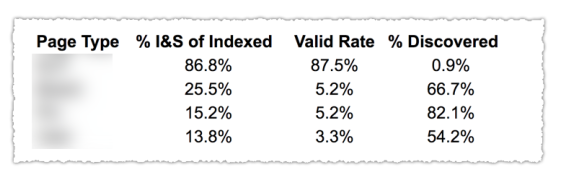
După cum puteți vedea în imaginea de mai sus, adresele URL din diferitele categorii din raportul de acoperire au fost clasificate în funcție de șablon de pagină, cum ar fi blog, pagină de serviciu etc. Utilizarea mai multor sitemap-uri pentru diferite tipuri de adrese URL poate ajuta la această sarcină, deoarece Google permite pentru a filtra informațiile de acoperire după harta site-ului. Apoi a inclus trei coloane cu următoarele informații % din paginile indexate și trimise, Rata validă și % din descoperite.
Acest tabel vă oferă cu adevărat o imagine de ansamblu excelentă asupra stării de sănătate a site-ului dvs. Acum, dacă doriți să explorați diferitele secțiuni, vă recomand să revizuiți rapoartele și să verificați de două ori erorile pe care le prezintă Google.
Puteți descărca toate adresele URL prezentate în diferite categorii și puteți utiliza OnCrawl pentru a verifica starea lor HTTP, etichetele canonice etc. și pentru a crea o foaie de calcul precum aceasta:
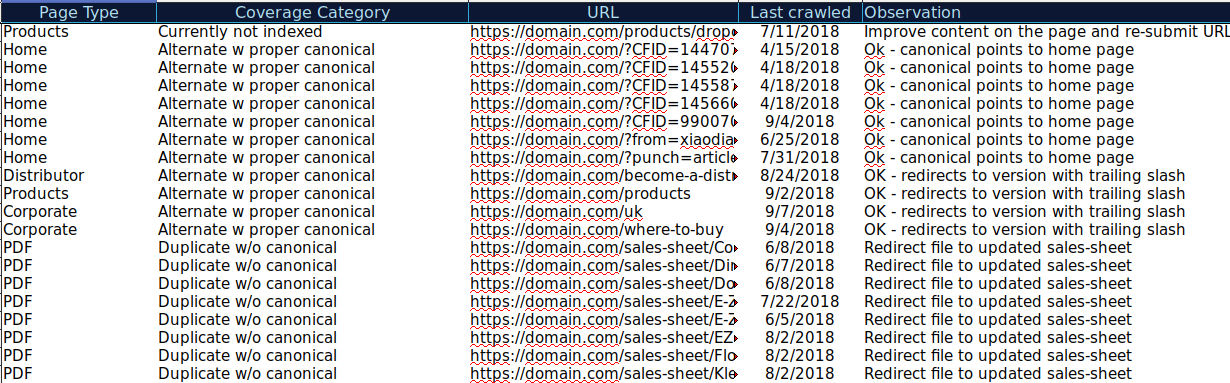
Organizarea datelor dvs. în acest mod vă poate ajuta să urmăriți problemele, precum și să adăugați elemente de acțiune pentru adresele URL care trebuie îmbunătățite sau remediate. De asemenea, puteți bifa adresele URL care sunt corecte și nu sunt necesare măsuri de acțiune în cazul acelor adrese URL cu parametri cu implementarea corectă a etichetelor canonice.
Începeți perioada de încercare gratuită de 14 zile
 Începeți procesul
Începeți procesulPuteți chiar să adăugați mai multe informații la această foaie de calcul din alte surse, cum ar fi ahrefs, Majestic și Google Analytics cu integrările OnCrawl. Acest lucru vă va permite să extrageți date despre linkuri, precum și date despre trafic și conversie pentru fiecare dintre adresele URL din Google Search Console. Toate aceste date vă pot ajuta să luați decizii mai bune cu privire la ce să faceți pentru fiecare pagină, de exemplu, dacă aveți o listă de pagini cu 404s, puteți lega aceasta cu backlink-uri pentru a determina dacă pierdeți vreun link de la domeniile care leagă la pagini sparte de pe site-ul dvs. Sau puteți verifica paginile indexate și cât de mult trafic organic obțin. Puteți identifica paginile indexate care nu primesc trafic organic și puteți lucra la optimizarea lor (îmbunătățirea conținutului și a gradului de utilizare) pentru a ajuta la generarea de mai mult trafic către pagina respectivă.
Cu aceste date suplimentare, puteți crea un tabel rezumat pe o altă foaie de calcul. Puteți folosi formula =COUNTIF(interval, criterii) pentru a număra adresele URL din fiecare tip de pagină (acest tabel poate completa tabelul sugerat de AJ Kohn mai sus). De asemenea, puteți utiliza o altă formulă pentru a adăuga backlink, vizite sau conversii pe care le-ați extras pentru fiecare adresă URL și să le afișați în tabelul rezumativ cu următoarea formulă =SUMIF (interval, criterii, [sum_range]). Ai obține ceva de genul acesta:
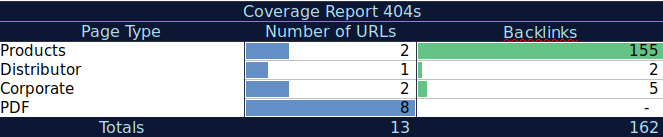
Îmi place foarte mult să lucrez cu tabele rezumative care îmi pot oferi o imagine rezumată a datelor și mă pot ajuta să identific secțiunile pe care trebuie să mă concentrez mai întâi asupra remedierii.
Gânduri finale
La ce trebuie să vă gândiți când lucrați la remedierea problemelor și vă uitați la datele din acest raport este: Este site-ul meu optimizat pentru accesare cu crawlere? Sunt paginile mele indexate și valide în creștere sau scădere? Paginile cu erori cresc sau scad? Permit Google să petreacă timp pe adresele URL care vor aduce mai multă valoare utilizatorilor mei sau găsește o mulțime de pagini fără valoare? Cu răspunsurile la aceste întrebări, puteți începe să faceți îmbunătățiri site-ului dvs., astfel încât Googlebot să-și poată cheltui bugetul de accesare cu crawlere în pagini care pot oferi valoare utilizatorilor dvs. în loc de pagini fără valoare. Puteți folosi robots.txt pentru a îmbunătăți eficiența accesării cu crawlere, pentru a elimina adresele URL fără valoare atunci când este posibil sau pentru a utiliza etichete canonice sau noindex pentru a preveni conținutul duplicat.
Google continuă să adauge funcționalități și să actualizeze acuratețea datelor la diferitele rapoarte din consola de căutare Google, așa că sperăm că vom continua să vedem mai multe date în fiecare dintre categoriile din raportul de acoperire, precum și alte rapoarte în Google Search Console.