
Audit SEO tehnic rapid și murdar în 11 pași pentru sănătatea generală a site-ului
Publicat: 2020-02-27SEO tehnic contează pentru că este punctul de plecare al oricărui proiect. Din punctul de vedere al unui expert SEO, fiecare site web este un proiect nou. Un site web ar trebui să aibă o bază solidă pentru a obține rezultate bune și a atinge cel mai important KPI în SEO, cum ar fi clasamentele.
De fiecare dată când încep cu un proiect nou, primul lucru pe care îl fac este un audit tehnic SEO. De cele mai multe ori, rezolvarea problemelor tehnice poate obține rezultate uimitoare de îndată ce site-ul este accesat din nou cu crawlere.
Este amuzant pentru mine când oamenii vorbesc despre conținut și mai mult conținut, dar nu spun o vorbă despre SEO tehnic. Un lucru este sigur, sănătatea site-ului și SEO tehnic sunt două lucruri importante care vor fi cruciale în 2020. Nu vreau să spun că conținutul nu este important. Este, dar fără a remedia problemele tehnice de pe un site web, nu cred că conținutul poate aduce rezultate.
Am văzut cazuri în care paginile importante au fost blocate de directive din fișierul robots.txt, sau cele mai importante pagini de categorii sau servicii sunt sparte sau blocate de meta-roboți precum noindex, nofollow. Cum este posibil să ai succes fără a stabili priorități prin remedierea acestor probleme?
Poate fi surprinzător să vedem că numărul de SEO care nu știu să identifice problemele tehnologice pe care să le raporteze specialiștilor în dezvoltare web să fie remediat. Mi-am amintit că, când lucram în domeniul corporativ, am creat o fișă de verificare a auditului Tech SEO pentru a fi folosită de echipa mea. În acel moment, mi-am dat seama că a avea la îndemână o fișă de remediere rapidă ca aceasta poate ajuta enorm o echipă și poate genera un impuls rapid pentru un client. De aceea, consider de maximă importanță să investești într-un instrument/software care te poate ajuta cu diagnosticarea și recomandările tehnice SEO.
Să începem procesul practic despre cum să desfășurăm un audit rapid SEO tehnologic, care va face o mare diferență. Acesta este un exercițiu rapid care vă va lua aproximativ o oră, chiar dacă nu sunteți un profesionist. Pentru mine, folosirea unui instrument Tech SEO precum OnCrawl pentru a avansa rapid toate lucrurile în cinci minute fără a fi nevoie să fac toată munca manuală îmi face viața mai ușoară.
Voi trece peste cele mai importante lucruri de verificat atunci când efectuez un Audit Tehnic SEO. Există mai multe lucruri pe care le putem verifica pentru problemele de pe pagină, dar vreau să mă concentrez doar pe lucruri care vor crea probleme de indexare și risipa de buget cu crawlere. Prioritizarea acesteia este modalitatea de a vă asigura că cele mai importante pagini vor fi accesate cu crawlere de Googlebot.
- Indexarea
- Fișierul Robots.txt
- Etichetă meta roboți
- erori 4xx
- Sitemaps
- HTTP/HTTPS (securitatea site-ului web, conținut mixt și probleme de conținut duplicat)
- Paginare
- 404 pagina
- Adancimea si structura sitului
- Lanțuri lungi de redirecționare
- Implementarea etichetelor canonice
1) Indexare
Acesta este primul lucru de verificat. De multe ori indexarea poate fi afectată de configurația unui plugin sau de orice greșeală minoră, dar impactul asupra găsirii poate fi uriaș, deoarece astăzi există peste 6,16 miliarde de pagini web indexate. Trebuie să înțelegeți că orice motor de căutare face un efort și chiar și Google trebuie să acorde prioritate celei mai relevante pagini pentru experiența utilizatorului. Dacă nu vă gândiți să faceți lucrurile mai ușor pentru Googlebot, concurența dvs. va face acest lucru și va câștiga mult mai multă încredere care vine cu un site web sănătos.
Când există probleme de indexare, problemele de sănătate ale site-ului dvs. se vor reflecta în pierderea traficului organic. Procesul de indexare înseamnă că un motor de căutare accesează cu crawlere o pagină web și organizează informațiile care ulterior le oferă în SERP. Rezultatele depind de relevanța pentru intenția utilizatorului. Dacă o pagină web nu poate sau are probleme cu crawlingul, acest lucru va favoriza alte pagini din aceeași nișă pentru a avea un avantaj.
Folosind operatori de căutare, de exemplu:
Site: www.abc.com
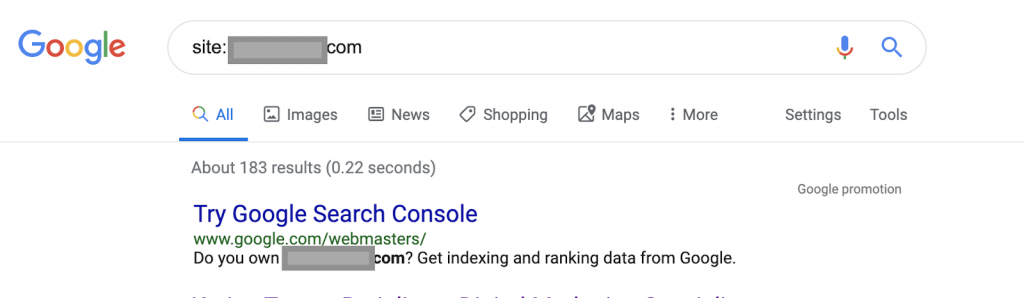
Interogarea va returna 183 de pagini indexate de Google. Aceasta este o estimare aproximativă a numărului de pagini indexate de Google. Puteți verifica Google Search Console pentru numărul exact.
De asemenea, ar trebui să utilizați un crawler web precum OnCrawl pentru a lista toate paginile la care are acces Google. Acesta arată un număr diferit, după cum puteți vedea mai jos:
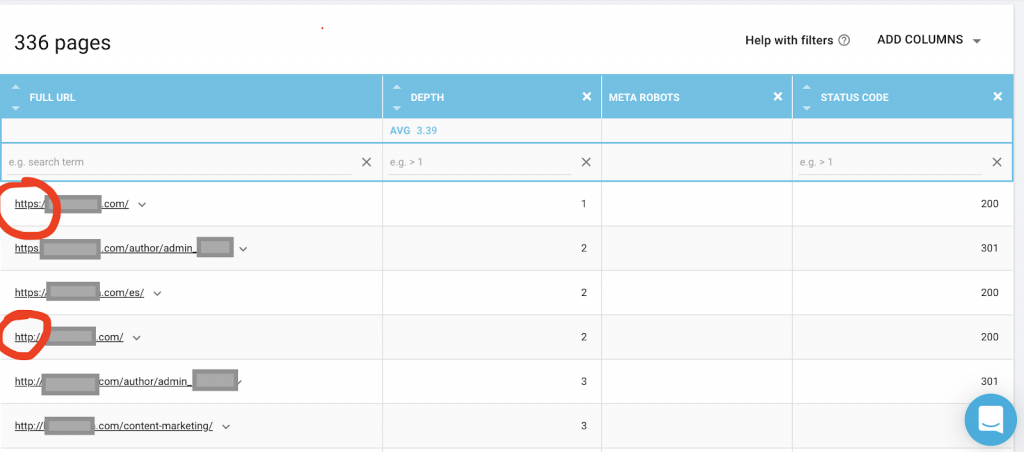
Acest site web are aproape de două ori mai multe pagini care pot fi accesate cu crawlere decât paginile indexate.
Acest lucru ar putea dezvălui o problemă de conținut duplicat sau chiar o problemă cu versiunea de securitate a site-ului web între problema HTTP și HTTPS. Voi vorbi despre asta mai târziu în acest articol.
În acest caz, site-ul web a fost migrat de la HTTP la HTTPS. Putem vedea în OnCrawl că paginile HTTP au fost redirecționate. Atât versiunile HTTP, cât și cele HTTPS sunt încă accesibile pentru Googlebot și poate accesa cu crawlere toate paginile duplicate, în loc să prioritizeze cele mai importante pagini pe care proprietarul dorește să le clasifice, provocând o risipă de buget de accesare cu crawlere.
O altă problemă comună printre site-urile web neglijate sau site-urile mari, cum ar fi site-urile de comerț electronic, sunt problemele de conținut mixt. Pentru a scurta povestea, problemele apar atunci când pagina dvs. securizată are resurse precum fișiere media (cel mai frecvent: imagini) încărcate din versiunea nesecurizată.
Cum se remediază:
Puteți cere unui dezvoltator web să forțeze toate paginile HTTP la versiunea HTTPS și să redirecționeze adresele HTTP către HTTPS o dată folosind un cod de stare 301.
Pentru probleme de conținut mixt, puteți verifica manual sursa paginii și căuta resurse încărcate ca „src=http://example.com/media/images”, ceea ce este aproape o nebunie să faceți acest lucru în special pentru site-urile web mari. De aceea trebuie să folosim un instrument tehnic SEO.
2) Fișier Robots.txt:
Fișierul robots.txt le spune agenților cu crawlere ce pagini nu ar trebui să acceseze cu crawlere. Ghidul de specificații Robots.txt indică faptul că formatul fișierului trebuie să fie text simplu, cu o dimensiune maximă de 500 KB.
Voi recomanda adăugarea sitemap-ului la robots.txt.file. Nu toată lumea face asta, dar cred că este o practică bună. Fișierul robots.txt trebuie să fie plasat pe serverul dvs. găzduit în public_html și merge după domeniul rădăcină.
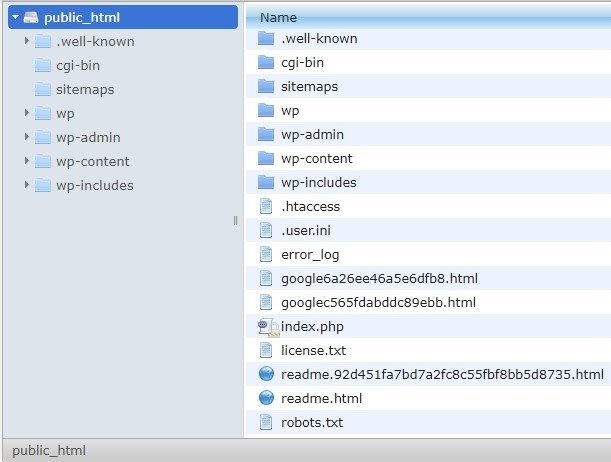
Putem folosi directive din fișierul robots.txt pentru a preveni ca motoarele de căutare să acceseze cu crawlere pagini inutile sau pagini cu informații sensibile, cum ar fi pagina de administrare, șabloanele sau coșul de cumpărături (/cart, /checkout, /login, foldere precum /tag utilizate în bloguri) , prin adăugarea acestor pagini în fișierul robots.txt.
Sfat : Asigurați-vă că nu veți bloca folderul fișierelor media, deoarece acest lucru va exclude imaginile, videoclipurile sau alte media găzduite de dvs. de la indexare. Media poate fi foarte importantă pentru relevanța paginii, precum și pentru clasarea organică și traficul pentru imagini sau videoclipuri.
3) Eticheta Meta Robots
Aceasta este o bucată de cod HTML care indică motoarele de căutare dacă să acceseze cu crawlere și să indexeze o pagină, cu toate linkurile din acea pagină. Eticheta HTML merge în capul paginii dvs. web. Există 4 etichete HTML comune pentru roboți:
- Fără urmărire
- Urma
- Index
- Fără index
Când nu sunt prezente etichete meta-roboți, motoarele de căutare vor urmări și indexează conținutul în mod implicit.
Puteți folosi orice combinație care se potrivește cel mai bine nevoilor dvs. De exemplu, folosind OnCrawl, am descoperit că o „pagină de autor” de pe acest site web nu are meta-roboți. Aceasta înseamnă că în mod implicit direcția este („urmare, indexare”)
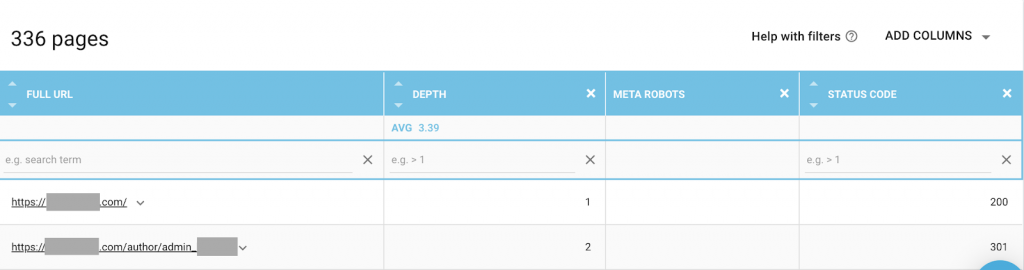
Acesta ar trebui să fie ("noindex, nofollow").
De ce?
Fiecare caz este diferit, dar acest site este un mic blog personal. Există un singur autor care publică pe blog, iar domeniul este numele autorului. În acest caz, pagina „autor” nu oferă informații suplimentare, chiar dacă este generată de platforma de blogging.
Un alt scenariu poate fi un site web unde categoriile de pe blog sunt importante. Când proprietarul dorește să se claseze pentru categorii pe blogul său, atunci meta-roboții ar trebui să fie ("urmăriți, indexați") sau implicit în paginile categoriei.
Într-un scenariu diferit, pentru un site web mare și binecunoscut, unde experții mari SEO scriu articole care sunt urmate de comunitate, numele autorului în Google acționează ca un brand. În acest caz, probabil că ați dori să indexați câteva nume de autori.
După cum puteți vedea, meta-roboții pot fi utilizați în multe moduri diferite.
Cum se remediază:
Cereți unui dezvoltator web să schimbe eticheta meta robot după cum aveți nevoie. În cazul de mai sus pentru un site web mic, o pot face singur mergând la fiecare pagină și schimbând-o manual. Dacă utilizați WordPress, puteți schimba acest lucru din setările RankMath sau Yoast.
4) Erori 4xx:
Acestea sunt erori pe partea clientului și pot fi 401, 403 și 404.
- 404 Pagina nu a fost găsită:
Această eroare apare atunci când o pagină nu este disponibilă la adresa URL indexată. Ar fi putut fi mutată sau ștearsă, iar vechea adresă nu a fost redirecționată corespunzător folosind funcția de server web 301. Erorile 404 sunt o experiență proastă pentru utilizatori și reprezintă o problemă tehnică SEO care ar trebui rezolvată. Este un lucru bun să verificați des pentru 404 și să le remediați, și să nu le lăsați să fie încercate din nou și din nou pentru că agenții de crawling își irosesc bugetul.
Cum se remediază:
Trebuie să găsim adresele care returnează 404 și să le reparăm folosind redirecționări 301 dacă conținutul încă există. Sau, dacă sunt imagini, pot fi înlocuite cu altele noi păstrând același nume de fișier.
- 401 Neautorizat
Aceasta este o problemă de permisiune. Eroarea 401 apare de obicei atunci când este necesară autentificarea, cum ar fi numele de utilizator și parola.
Cum se remediază:
Iată două opțiuni: Prima este de a bloca pagina de motoarele de căutare folosind robots.txt. A doua opțiune este de a elimina cerința de autentificare.
- 403 Interzis
Această eroare este similară cu eroarea 401. Eroarea 403 se întâmplă deoarece pagina are linkuri care nu sunt accesibile publicului.

Cum se remediază:
Modificați cerința de pe server pentru a permite accesul la pagină (doar dacă aceasta este o greșeală). Dacă aveți nevoie ca această pagină să fie inaccesibilă, eliminați toate linkurile interne și externe din pagină.
- 400 Solicitare proastă
Acest lucru se întâmplă atunci când browserul nu poate comunica cu serverul web. Această eroare se întâmplă de obicei pentru sintaxa URL greșită.
Cum se remediază:
Găsiți linkuri către aceste adrese URL și remediați sintaxa. Dacă acest lucru nu poate fi remediat, va trebui să contactați dezvoltatorul web pentru a le remedia.
Notă: Putem găsi 400 de erori cu instrumente sau în Google Console

5) Sitemaps
Harta site-ului este o listă cu toate adresele URL pe care le conține site-ul web. Deținerea unei hărți de site îmbunătățește capacitatea de găsire, deoarece îi ajută pe crawlerii să găsească și să înțeleagă conținutul dvs.
Avem diferite tipuri de hărți de site și trebuie să ne asigurăm că toate sunt în stare bună.
Sitemap-urile pe care ar trebui să le avem sunt:
- Harta site-ului HTML: aceasta va fi pe site-ul dvs. web și va ajuta utilizatorii să navigheze și să găsească paginile de pe site-ul dvs
- Harta site-ului XML: acesta este un fișier care va ajuta motoarele de căutare să acceseze cu crawlere site-ul dvs. (ca cea mai bună practică ar trebui inclus în fișierul robots.txt).
- Harta site-ului video XML: la fel ca mai sus.
- Harta site-ului XML de imagini: este, de asemenea, la fel ca mai sus. Se recomandă să creați sitemap-uri separate pentru imagini, videoclipuri și conținut.
Pentru site-urile mari, este recomandat să aveți mai multe sitemap-uri pentru o mai bună accesare cu crawlere, deoarece sitemaps-urile nu trebuie să conțină mai mult de 50.000 de adrese URL.
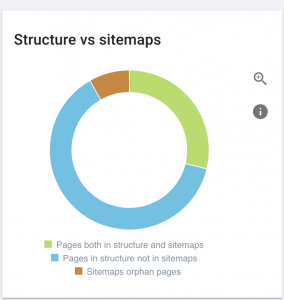
Acest site are probleme cu harta site-ului.
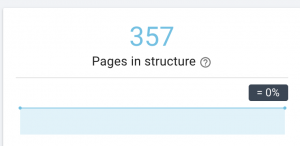
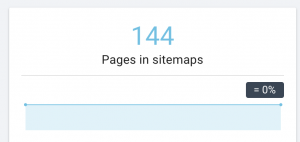
Cum o reparăm:
Remediem acest lucru generând diferite sitemap-uri pentru: conținut, imagini și videoclipuri. Apoi, le trimitem prin Google Search Console și, de asemenea, creăm un sitemap HTML pentru site-ul web. Nu avem nevoie de un dezvoltator web pentru asta. Putem folosi orice instrument online gratuit pentru a genera sitemap-uri.
6) HTTP/HTTPS (conținut duplicat)
Multe site-uri web au aceste probleme ca urmare a migrării de la HTTP la HTTPS. Dacă acesta este cazul, site-ul web va afișa versiuni HTTP și HTTPS în motoarele de căutare. Ca o consecință a acestei probleme tehnice comune, clasamentele sunt diluate. Aceste probleme generează, de asemenea, probleme de conținut duplicat.
![]()

Cum se remediază:
Solicitați unui dezvoltator web să remedieze această problemă forțând tot HTTP la HTTPS.
Notă : Nu redirecționați niciodată tot HTTP către pagina de pornire HTTPS, deoarece va genera erori 404. (Ar trebui să spuneți acest lucru dezvoltatorului web; amintiți-vă că nu sunt SEO.)
7) Paginare
Aceasta este utilizarea unei etichete HTML („rel = prev” și „rel = next”) care stabilește relații între pagini și le arată motoarelor de căutare că conținutul care este prezentat în diferite pagini ar trebui identificat sau legat de una singură. Paginarea este folosită pentru a limita conținutul pentru UX și greutatea unei pagini pentru partea tehnică, păstrându-le sub 3MB. Putem folosi un instrument gratuit pentru a verifica paginarea.
Paginarea ar trebui să aibă referințe auto-canonice și să indice „rel = prev” și „rel = next”. Singurele informații duplicate vor fi meta titlul și meta descrierea, dar acestea pot fi modificate de dezvoltatori pentru a crea un mic algoritm, astfel încât fiecare pagină să aibă un meta titlu și meta descriere generate.
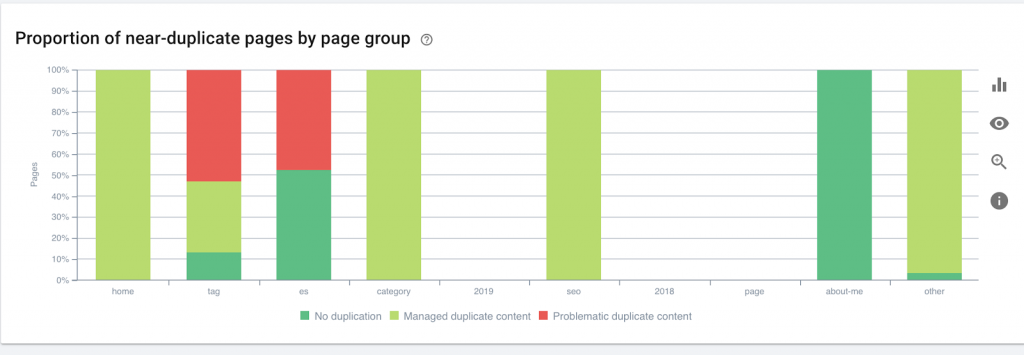
Cum se remediază:
Cereți unui dezvoltator web să implementeze etichete HTML de paginare cu etichetă autocanonică.
Oncrawl SEO Crawler
 Decouvrir
Decouvrir8) Pagina personalizată 404 negăsită
Un răspuns 404 este, așa cum am discutat anterior, o eroare „ Negăsit ” care aduce utilizatorii la un link întrerupt sau la o pagină inexistentă. Aceasta este o oportunitate de a redirecționa utilizatorii către locul potrivit. Există exemple grozave de 404 pagini personalizate. Acesta este un must-have.
Iată un exemplu de pagină personalizată 404 grozavă:

Cum se remediază:
Creați o pagină 404 personalizată: gândiți-vă la ceva uimitor de adăugat la ea. Faceți din această eroare o oportunitate pentru afacerea dvs.
9) Adâncimea/structura amplasamentului
Adâncimea paginii este numărul de clicuri pe care se află pagina dvs. din domeniul rădăcină. John Mueller de la Google a spus că „paginile mai apropiate de pagina de pornire au mai multă greutate”. De exemplu, să ne imaginăm că pagina de aici necesită următoarea navigare pentru a fi accesată:

Pagina „covoare” se află la 4 clicuri distanță de pagina de pornire. Este recomandat să nu aveți pagini situate la mai mult de 4 clicuri distanță de casă, deoarece motoarele de căutare au greu să acceseze cu crawlere paginile mai adânci.
Acest grafic arată grupul de pagini după adâncime. Ne ajută să înțelegem dacă structura unui site web trebuie reelaborată.
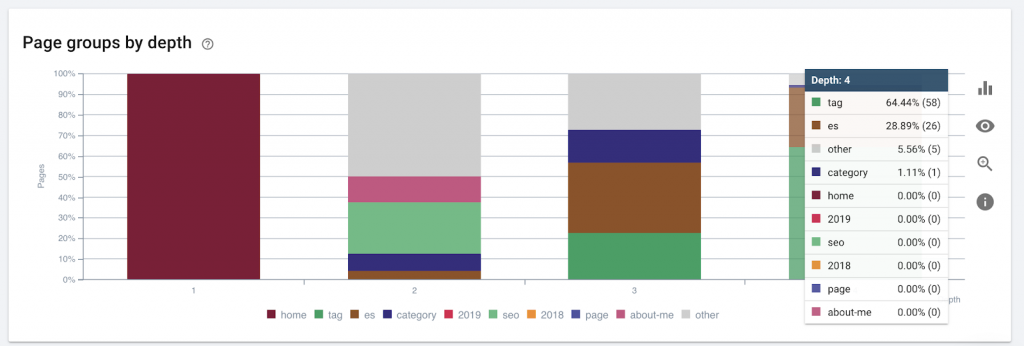
Cum se remediază:
Paginile care sunt cele mai importante ar trebui să fie cele mai apropiate de pagina de pornire pentru UX, pentru acces ușor de către utilizatori și pentru o mai bună structură a site-ului. Este foarte important să luați în considerare acest lucru în momentul creării unei structuri de site web sau al restructurarii unui site web.
10. Lanțuri de redirecționare
Un lanț de redirecționare este atunci când are loc o serie de redirecționări între adrese URL. Aceste lanțuri de redirecționare pot crea și bucle. De asemenea, prezintă probleme pentru Googlebot și risipă bugetul de accesare cu crawlere.
Putem identifica lanțuri de redirecționări utilizând calea de redirecționare a extensiei Chrome sau în OnCrawl.
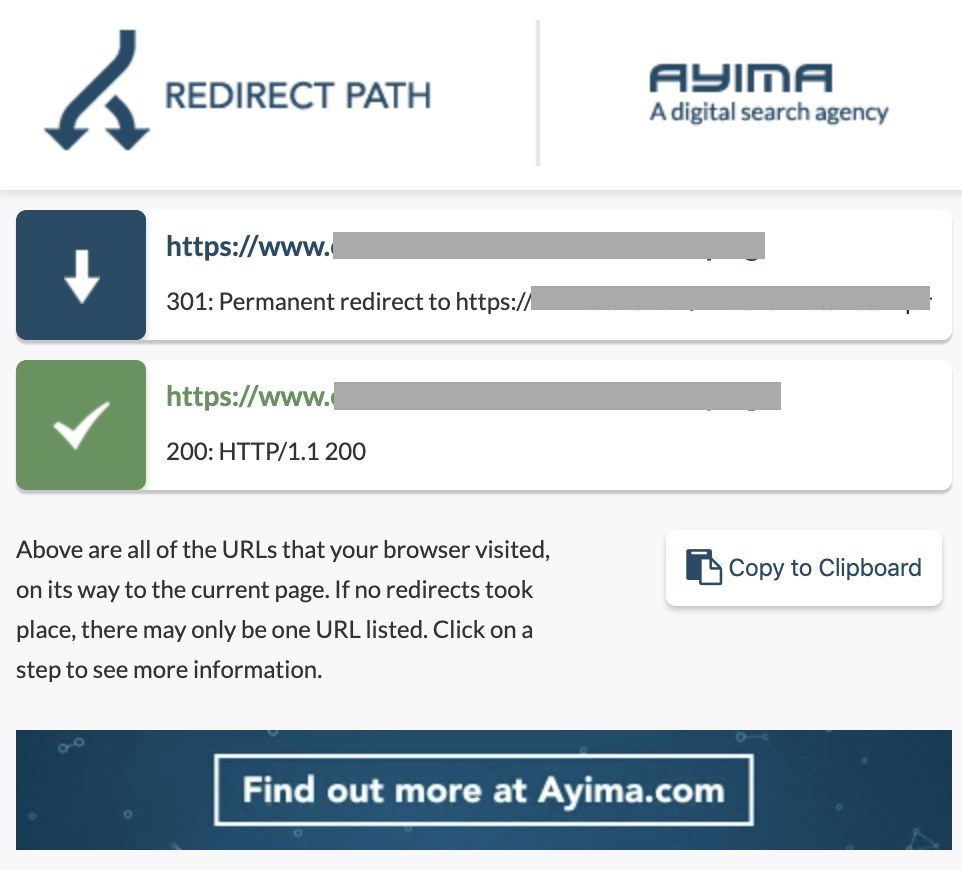
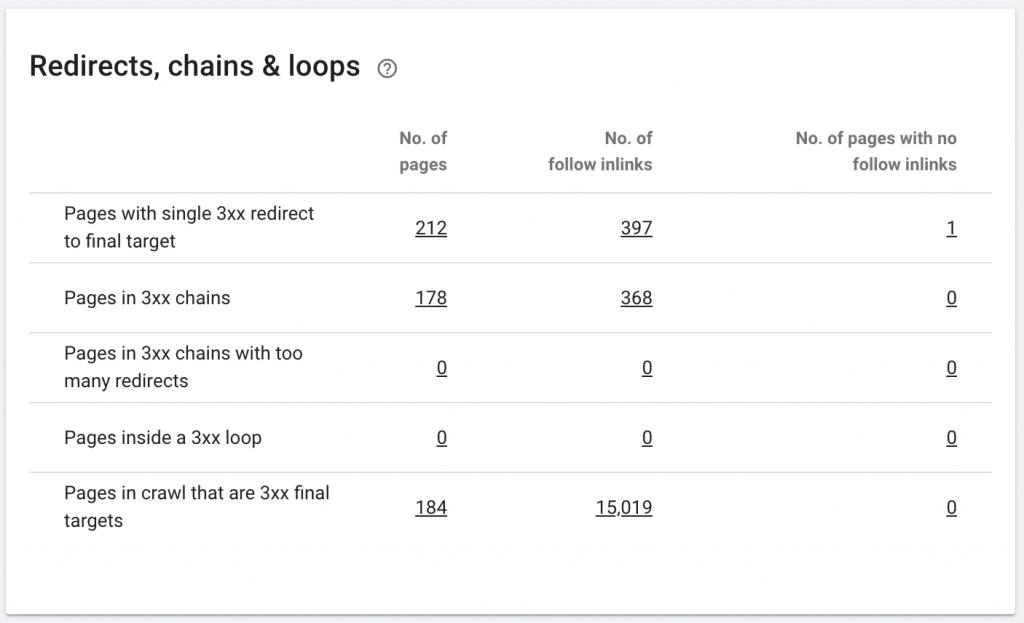
Cum se remediază:
Remedierea acestui lucru este foarte ușoară dacă lucrați cu un site web WordPress. Doar mergeți la redirecționare și căutați lanțul - ștergeți toate legăturile implicate în lanț dacă acele modificări au avut loc cu mai mult de 2-3 luni în urmă și lăsați ultima redirecționare la adresa URL curentă. Dezvoltatorii web pot ajuta, de asemenea, în acest sens, făcând toate modificările necesare în fișierul .htacces, dacă este necesar. Puteți verifica și modifica lanțurile lungi de redirecționare din pluginurile dvs. SEO.
11) Canonice
O etichetă canonică le spune motoarelor de căutare că adresa URL este o copie a unei alte pagini. Aceasta este o problemă mare care este prezentă pe multe site-uri web. Neimplementarea canonicilor în mod corect sau implementarea lor deloc va crea probleme de conținut duplicat.
Canonicalele sunt utilizate în mod obișnuit pe site-urile de comerț electronic unde un produs poate fi găsit de mai multe ori în diferite categorii, cum ar fi: dimensiune, culoare etc.

Puteți utiliza OnCrawl pentru a afla dacă paginile dvs. au etichete canonice și dacă sunt sau nu implementate corect. Apoi puteți explora și corecta orice problemă.
Cum o reparăm:
Putem rezolva problemele canonice utilizând Yoast SEO dacă lucrăm în WordPress. Mergem la tabloul de bord WordPress și apoi la Yoast -setting – advanced.
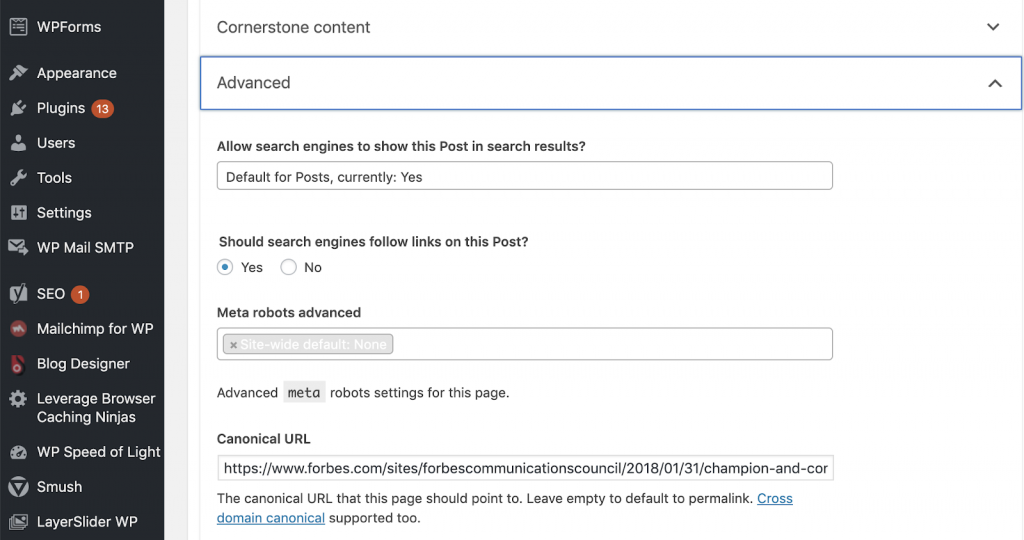
Derularea propriului audit
SEO care doresc să înceapă să se scufunde pe SEO tehnic au nevoie de un ghid cu pași rapidi de urmat pentru a îmbunătăți sănătatea SEO. Vorbind despre SEO tehnic cu John Shehata, vicepreședintele Audience Grow la Conde Nast și fondatorul NewzDash de Ziua Globală de Marketing din New York, în octombrie 2019.
Iată ce mi-a spus:
„Mulți oameni din industria SEO nu sunt tehnici. Acum, nu orice SEO înțelege cum să codeze și este greu să le ceri oamenilor să facă acest lucru. Unele companii, ceea ce fac este să angajeze dezvoltatori și să-i antreneze să devină SEO pentru a îndeplini decalajul tehnic SEO.”
După părerea mea, SEO care nu au cunoștințele complete de cod se pot descurca grozav la Tech SEO știind cum să desfășoare un audit, identificând elemente cheie, raportând, solicitând dezvoltatorilor web implementarea și, în final, testând modificările.
Sunteți gata să începeți? Descărcați lista de verificare pentru aceste probleme de top.
