
Evaluarea calității previziunilor CausalImpact
Publicat: 2022-02-15CausalImpact este unul dintre cele mai populare pachete utilizate în experimentarea SEO. Popularitatea sa este de înțeles.
Experimentarea SEO oferă informații interesante și modalități pentru SEO de a raporta despre valoarea muncii lor.
Cu toate acestea, acuratețea oricărui model de învățare automată depinde de informațiile de intrare pe care le oferă.
Pur și simplu, intrarea greșită poate returna o estimare greșită.
În această postare, vom arăta cât de fiabil (și nesigur) poate fi CausalImpact. De asemenea, vom învăța cum să devenim mai încrezători în rezultatele experimentelor dvs.
În primul rând, vom oferi o scurtă prezentare generală a modului în care funcționează CausalImpact. Apoi, vom discuta despre fiabilitatea estimărilor CausalImpact. În cele din urmă, vom afla despre o metodologie care poate fi utilizată pentru a estima propriile rezultate ale experimentelor SEO.
Ce este CausalImpact și cum funcționează?
CausalImpact este un pachet care utilizează statistici bayesiene pentru a estima efectul unui eveniment în absența unui experiment. Această estimare se numește inferență cauzală.
Inferența cauzală estimează dacă o schimbare observată a fost cauzată de un anumit eveniment.
Este adesea folosit pentru a evalua performanța experimentelor SEO.
De exemplu, când i se oferă data unui eveniment, CausalImpact (CI) va folosi punctele de date înainte de intervenție pentru a prezice punctele de date după intervenție. Apoi va compara predicția cu datele observate și va estima diferența cu un anumit prag de încredere.
În plus, grupurile de control pot fi folosite pentru a face predicțiile mai precise.
Diferiți parametri vor avea, de asemenea, un impact asupra acurateței predicției:
- Dimensiunea datelor de testare.
- Durata perioadei anterioare experimentului.
- Alegerea grupului de control cu care trebuie comparat.
- Hiperparametrii de sezonalitate.
- Numărul de iterații.
Toți acești parametri ajută la furnizarea de mai mult context modelului și la sporirea fiabilității acestuia.
Oncrawl BI
 Descoperi
DescoperiDe ce este importantă evaluarea acurateții experimentelor SEO?
În ultimii ani, am analizat multe experimente SEO și ceva m-a frapat.
De multe ori, utilizarea diferitelor grupuri de control și intervale de timp pe seturi de teste și date de intervenție identice a dat rezultate diferite.
Pentru ilustrare, mai jos sunt două rezultate ale aceluiași eveniment.
Primul a returnat o scădere semnificativă statistic. 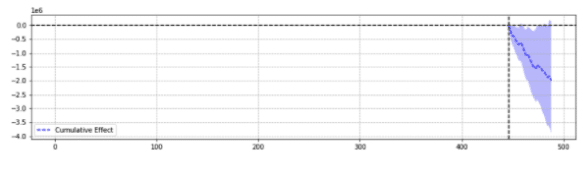
Al doilea nu a fost semnificativ statistic. 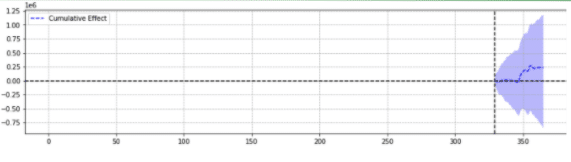
Mai simplu spus, pentru același eveniment, au fost returnate rezultate diferite pe baza parametrilor aleși.
Trebuie să ne întrebăm care predicție este corectă.
În cele din urmă, „semnificativ statistic” nu ar trebui să sporească încrederea în estimările noastre?
Definiții
Pentru a înțelege mai bine lumea experimentelor SEO, cititorul ar trebui să fie conștient de conceptele de bază ale experimentelor SEO:
- Experiment : o procedură întreprinsă pentru a testa o ipoteză. În cazul inferenței cauzale, are o anumită dată de începere.
- Grup de testare : un subset de date la care se aplică o modificare. Poate fi un întreg site sau o porțiune a site-ului.
- Grup de control : un subset de date la care nu s-a aplicat nicio modificare. Puteți avea unul sau mai multe grupuri de control. Acesta poate fi un site separat din aceeași industrie sau o porțiune diferită a aceluiași site.
Exemplul de mai jos va ajuta la ilustrarea acestor concepte:
Modificarea titlului (experimentului) ar trebui să crească CTR organic cu 1% (ipoteză) din paginile de produse din cinci orașe (grup de testare). Estimările vor fi îmbunătățite folosind un titlu neschimbat pentru toate celelalte orașe (grup de control).
Pilonii unei predicții exacte ale experimentului SEO
- Pentru simplitate, am compilat câteva informații interesante pentru profesioniștii SEO care învață cum să îmbunătățească acuratețea experimentelor:
- Unele intrări în CausalImpact vor returna estimări greșite, chiar și atunci când sunt semnificative din punct de vedere statistic. Aceasta este ceea ce numim „false pozitive” și „false negative”.
- Nu există o regulă generală care să reglementeze ce control să fie utilizat împotriva unui set de testare. Este necesar un experiment pentru a defini cele mai bune date de control de utilizat pentru un anumit set de testare.
- Utilizarea CausalImpact cu controlul corect și lungimea potrivită a datelor pre-perioade poate fi foarte precisă, eroarea medie fiind de până la 0,1%.
- Alternativ, utilizarea CausalImpact cu un control greșit poate duce la o rată de eroare puternică. Experimentele personale au arătat variații semnificative statistic de până la 20%, când de fapt nu a existat nicio schimbare.
- Nu totul poate fi testat. Unele grupuri de testare aproape niciodată nu returnează estimări precise.
- Experimentele cu sau fără grupuri de control au nevoie de date diferite înainte de intervenție.
Nu toate grupurile de testare vor returna estimări precise
Unele grupuri de testare vor returna întotdeauna predicții inexacte. Ele nu trebuie folosite pentru experimentare.
Grupurile de testare cu variații mari anormale de trafic returnează adesea rezultate nesigure.
De exemplu, în același an, un site a suferit o migrare a site-ului, a fost afectat de pandemia covid și o parte a site-ului a fost „neindexată” timp de 2 săptămâni din cauza unei erori tehnice. Experimentele pe acel site vor oferi rezultate nesigure.
Rezultatele de mai sus au fost adunate printr-o serie extinsă de teste realizate folosind metodologia descrisă mai jos.
Când nu se utilizează grupuri de control
- Utilizarea unui control în locul unui simplu pre-post poate crește de până la 18 ori precizia estimării.
- Utilizarea datelor cu 16 luni înainte a fost la fel de precisă ca utilizarea a 3 ani.
Când utilizați grupuri de control
- Utilizarea controlului corect este adesea mai bună decât utilizarea mai multor comenzi. Cu toate acestea, un singur control crește riscurile de predicție greșită în cazurile în care traficul controlului variază foarte mult.
- Alegerea controlului potrivit poate crește precizia de 10 ori (de exemplu, unul raportând +3,1% și celălalt +4,1% când de fapt era +3%).
- Cele mai multe modele de trafic corelate între datele de testare și datele de control nu înseamnă neapărat estimări mai bune.
- Utilizarea datelor cu 16 luni înainte NU a fost la fel de precisă ca utilizarea a 3 ani.
Atenție la lungimea datelor înainte de experimente
Interesant este că atunci când experimentezi cu grupuri de control, utilizarea datelor cu 16 luni înainte poate provoca o rată de eroare foarte intensă.
De fapt, erorile pot fi la fel de mari precum estimarea unei creșteri de trei ori a traficului atunci când nu au existat modificări reale.
Cu toate acestea, utilizarea a 3 ani de date a eliminat rata de eroare. Acest lucru vine în contrast cu experimentele simple pre-post, în care rata de eroare nu a fost crescută prin creșterea duratei de la 16 la 36 de luni.
Asta nu înseamnă că folosirea controalelor este rea. Este chiar dimpotrivă.
Pur și simplu arată modul în care adăugarea controlului afectează predicțiile.

Acesta este cazul când există variații mari în grupul de control.
Acest lucru este important în special pentru site-urile web care au avut variații anormale de trafic în ultimul an (eroare tehnică critică, pandemie de COVID etc.).
Cum se evaluează predicția impactului cauzal?
Acum, nu există niciun scor de precizie construit în biblioteca CausalImpact. Deci, trebuie dedus altfel.
Se poate observa modul în care alte modele de învățare automată estimează acuratețea predicțiilor lor și își dă seama că Sum of Squares Errors (SSE) este o măsură foarte comună.
Suma erorilor pătratelor, sau suma reziduală a pătratelor, calculează suma tuturor (n) diferențelor dintre așteptările (yi) și rezultatele reale (f(xi)), la pătrat. 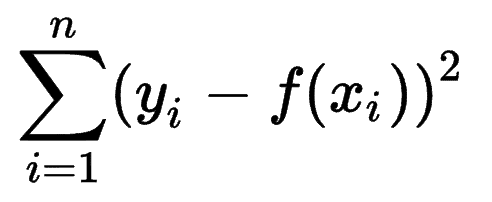
Cu cât SSE este mai mic, cu atât rezultatul este mai bun.
Provocarea este că, cu experimentele pre-post privind traficul SEO, nu există rezultate reale.
Deși nu au fost făcute modificări la fața locului, este posibil ca unele modificări să fi avut loc în afara controlului dumneavoastră (de exemplu, actualizarea algoritmului Google, un nou concurent etc.). Nici traficul SEO nu variază cu un număr fix, ci variază progresiv în sus și în jos.
Specialiștii SEO se pot întreba cum să depășească provocarea.
Prezentarea variațiilor false
Pentru a fi sigur de mărimea variației cauzate de un eveniment, experimentatorul poate introduce variații fixe în diferite momente de timp și poate vedea dacă CausalImpact a estimat cu succes modificarea.
Și mai bine, expertul SEO poate repeta procesul pentru diferite grupuri de testare și de control.
Folosind Python, au fost introduse variații fixe ale datelor la diferite date de intervenție pentru post-perioada.
Apoi a fost estimată suma erorilor pătratelor între variația raportată de CausalImpact și variația introdusă.
Ideea este asa:
- Alegeți un test și date de control.
- Introduceți intervenții false în datele reale la date diferite (de exemplu, creștere cu 5%).
- Comparați estimările CausalImpact cu fiecare dintre variațiile introduse.
- Calculați Suma Pătratelor Erori (SSE).
- Repetați pasul 1 cu mai multe controale.
- Alegeți controlul cu cel mai mic SSE pentru experimente din lumea reală
Metodologia
Cu metodologia de mai jos, am creat un tabel pe care l-am putea folosi pentru a identifica care control a avut cele mai bune și cele mai slabe rate de eroare în diferite momente.
În primul rând, alegeți un test și date de control și introduceți variații de la -50% la 50%.
Apoi, rulați CausalImpact (CI) și scădeți variațiile raportate de CI la variația pe care ați introdus-o efectiv.
După aceea, calculați pătratele acestor diferențe și însumați toate valorile.
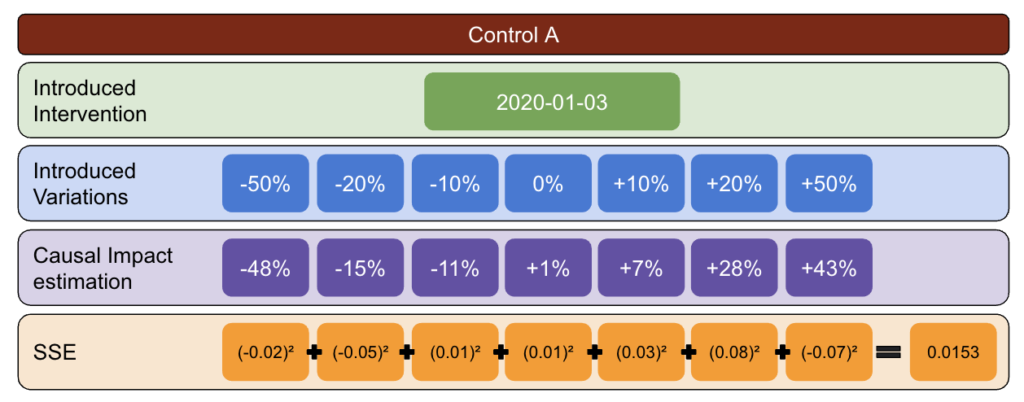
Apoi, repetați același proces la date diferite pentru a reduce riscul unei părtiniri cauzate de o variație reală la o anumită dată.
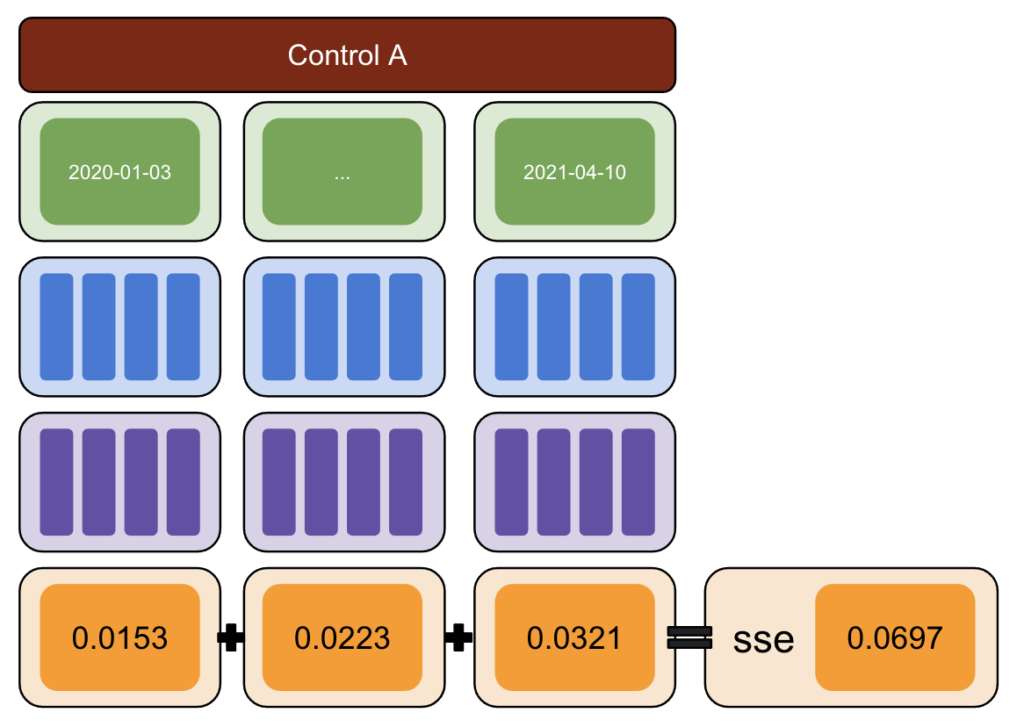
Din nou, repetați cu mai multe grupuri de control.
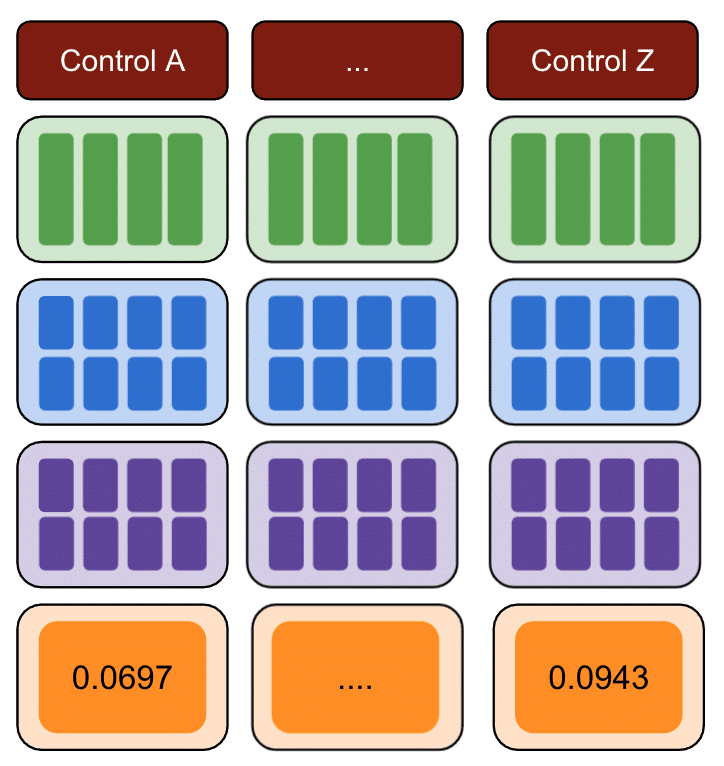
În cele din urmă, controlul cu cea mai mică sumă de erori de pătrate este cel mai bun grup de control de utilizat pentru datele de testare.
Dacă repetați fiecare dintre pașii pentru fiecare dintre datele de testare, rezultatul va varia.
Pe tabelul rezultat, fiecare rând reprezintă un grup de control, fiecare coloană reprezintă un grup de testare. Datele din interior sunt SSE.
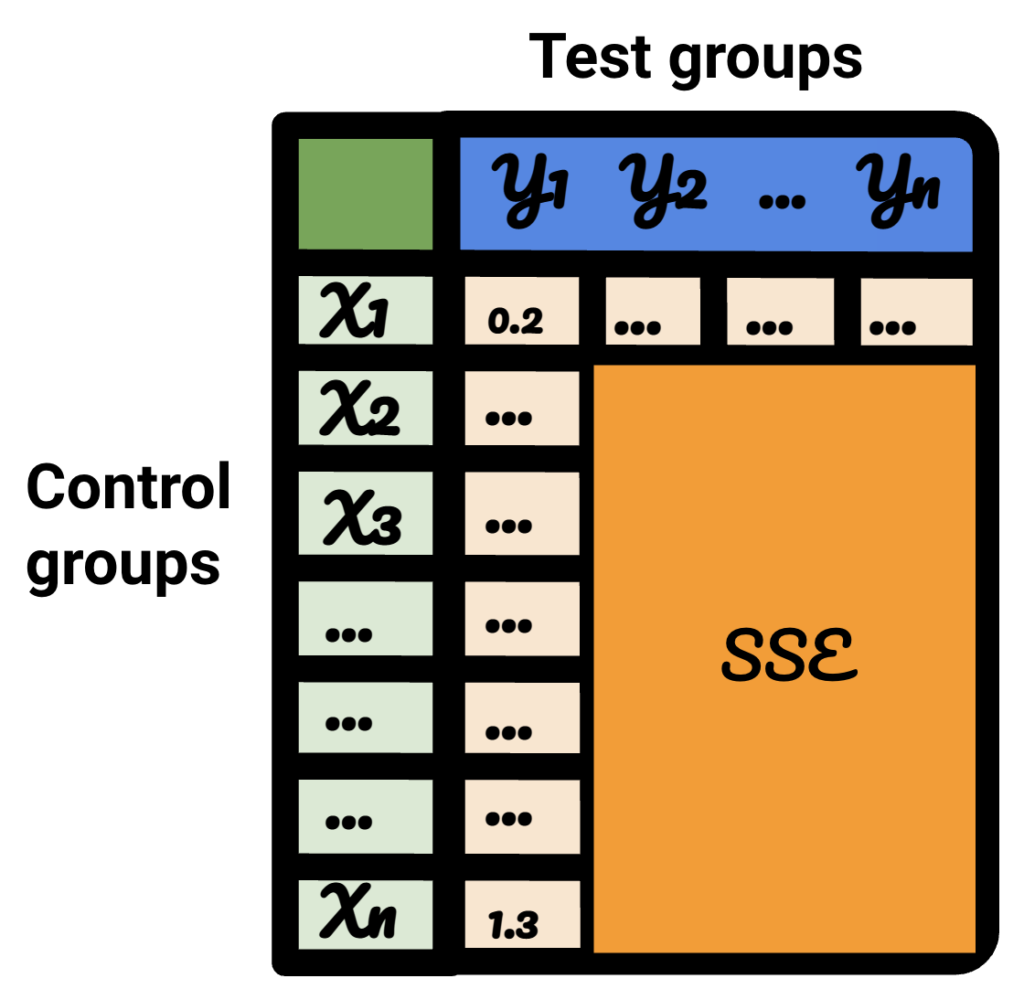
Sortând acel tabel, sunt acum încrezător că, pentru fiecare dintre grupurile de testare, pot selecta cel mai bun grup de control pentru acesta.
Ar trebui să folosim sau nu grupurile de control?
Dovezile arată că utilizarea grupurilor de control ajută la obținerea unor estimări mai bune decât simpla pre-post.
Totuși, acest lucru este adevărat numai dacă alegem grupul de control potrivit.
Cât de lungă ar trebui să fie perioada de estimare?
Răspunsul la asta depinde de controalele pe care le selectăm.
Când nu se utilizează un control, experimentul cu 16 luni înainte pare suficient.
Când utilizați un control, utilizarea doar a 16 luni poate duce la rate masive de eroare. Folosirea timpului de 3 ani ajută la reducerea riscului de interpretare greșită.
Ar trebui să folosim un control sau mai multe comenzi?
Răspunsul la această întrebare depinde de datele testului.
Datele de testare foarte stabile pot funcționa bine în comparație cu mai multe controale. În acest caz, acest lucru este bun, deoarece utilizarea multor controale face ca modelul să fie mai puțin afectat de fluctuațiile nebănuite ale unuia dintre controale.
Pe alte seturi de date, utilizarea mai multor controale poate face modelul de 10-20 de ori mai puțin precis decât utilizarea unuia singur.
Lucru interesant în comunitatea SEO
CausalImpact nu este singura bibliotecă care poate fi folosită pentru testarea SEO și nici metodologia de mai sus nu este singura soluție pentru testarea acurateței acesteia.
Pentru a afla soluții alternative, citiți câteva dintre articolele incredibile împărtășite de oamenii din comunitatea SEO.
În primul rând, Andrea Volpini a scris o lucrare interesantă despre măsurarea eficienței SEO folosind analiza CausalImpact.
Apoi, Daniel Heredia a acoperit pachetul Facebook Prophet pentru prognoza traficului SEO cu Prophet și Python.
În timp ce biblioteca Profetului este mai potrivită pentru prognoză decât pentru experimente, merită să înveți diferite biblioteci pentru a obține o înțelegere fermă a lumii predicțiilor.
În cele din urmă, am fost foarte mulțumit de prezentarea lui Sandy Lee la Brighton SEO, unde a împărtășit informații despre Data Science for SEO Testing și a ridicat câteva dintre capcanele testării SEO.
Lucruri de luat în considerare atunci când faceți experimente SEO
- Instrumentele de testare divizată SEO de la terțe părți sunt grozave, dar pot fi și inexacte. Fii minuțios atunci când alegi soluția.
- Deși am scris despre asta în trecut, nu puteți face experimente de testare divizată SEO cu Managerul de etichete Google, cu excepția cazului în partea de server. Cel mai bun mod este de a implementa prin intermediul CDN-urilor.
- Fiți îndrăzneți când testați. Modificările mici nu sunt de obicei preluate de CausalImpact.
- Testarea SEO nu ar trebui să fie întotdeauna prima ta alegere.
- Există alternative la testarea modificărilor mai mici, cum ar fi etichetele de titlu. Teste A/B Google Ads sau teste A/B pe platformă. Testele A/B reale sunt mai precise decât testul divizat SEO și oferă, de obicei, mai multe informații despre calitatea titlurilor tale.
Rezultate reproductibile
În acest tutorial, am vrut să mă concentrez asupra modului în care se poate îmbunătăți acuratețea experimentelor SEO fără sarcina de a ști cum să codificați. Mai mult, sursa datelor poate varia, iar fiecare site este diferit.
Prin urmare, codul Python pe care l-am folosit pentru a produce acest conținut nu a făcut parte din domeniul de aplicare al acestui articol.
Cu toate acestea, cu logica, puteți reproduce experimentele de mai sus.
Concluzie
Dacă ai avea doar o singură concluzie din acest articol, ar fi că analiza CausalImpact poate fi foarte precisă, dar poate fi întotdeauna departe.
Este foarte important pentru SEO care doresc să folosească acest pachet pentru a înțelege cu ce au de-a face. Rezultatul propriei mele călătorii este că nu aș avea încredere în CausalImpact fără a testa mai întâi acuratețea modelului pe datele de intrare.