
Crawl over Crawl acum disponibil
Publicat: 2019-11-21Funcția noastră Crawl over Crawl vă permite să comparați două accesări cu crawlere diferite și să afișeze evoluțiile accesării cu crawlere .
În 2016, s-a bazat pe versiunea noastră anterioară despre „Tendințe”, care ți-a oferit oportunitatea de a identifica tendințele globale între diferitele accesări cu crawlere. Acum puteți accesa vizualizări complete ale îmbunătățirilor dvs. SEO și puteți evidenția diferențele dintre accesările cu crawlere pe o anumită temă . Actualizarea Crawl over Crawl a inclus noi tipuri de grafice pentru a vă citi datele.
În 2019, funcția Crawl over Crawl s-a îmbunătățit. Acum puteți examina:
- Două versiuni ale unui site web care conțin pagini identice sau similare, cum ar fi site-uri web de producție vs.
- Același site web în două momente diferite în timp, cum ar fi înainte și după o modificare a site-ului.
Compararea a două versiuni ale unui site web
Pentru a compara două site-uri web, OnCrawl analizează adresa URL de pornire pe care o furnizați pentru două accesări cu crawlere diferite pentru a determina diferențele dintre adresele web ale diferitelor site-uri. Se presupune că aceste două versiuni ale site-ului web conțin același (sau aproape același) conținut. Aceasta înseamnă că majoritatea adreselor URL din cele două domenii, foldere sau subdomenii pe care le comparați trebuie să fie aceleași .
Iată câteva exemple de site-uri care pot fi comparate:
| Utilizare caz | Crawl 1 – Adresa URL de pornire | Crawl 2 – Adresa URL de pornire |
|---|---|---|
| Site-uri de producție vs | https://www.example.com | http://staging.example.com/site/ |
| Site-uri desktop vs mobile | https://www.example.com | https://m.example.com |
| Versiuni regionale | https://www.example.com/en-us/ | https://www.example.com/en-ca/ |
| Versiuni regionale | https://www.example.com | https://www.example.co.uk |
Pentru diferențele complexe între adresele URL de pornire, potrivirea automată poate să nu fie suficientă. Dacă acesta este cazul, veți vedea o eroare la configurarea accesării cu crawlere care vă solicită să contactați OnCrawl prin chat. Putem anula potrivirea automată pentru a ne adapta la cazul dvs. specific.
Compararea unui site web în două momente diferite în timp
Pentru a compara un site web în două momente diferite în timp, cum ar fi înainte și după o îmbunătățire sau o schimbare majoră a site-ului, va trebui să furnizați:
- Aceleași adrese URL de pornire
- Aceeași amploare de accesare cu crawlere (aceleași reguli de explorare a subdomeniului)
Cum să configurați un Crawl peste Crawl
Puteți rula un Crawl peste Crawl între două accesări cu crawlere existente sau puteți solicita compararea cu o accesare cu crawlere anterioară atunci când creați una nouă. Mai multe informații despre crearea Crawl over Crawls pot fi găsite în baza de cunoștințe OnCrawl.
Cum să citiți un Crawl peste Crawl sunburst
Citiți o explozie ca o plăcintă tradițională. Aceste grafice sunt foarte utile pentru a urmări evoluția unui site web , acces cu crawlere după accesare cu crawlere sau pentru a verifica diferențele dintre două versiuni ale unui site web (între o versiune live și în timpul unei restructurari, de exemplu).
Această diagramă circulară pe mai multe niveluri vă permite să comparați două accesări cu crawlere în funcție de o anumită temă:
- Primul nivel și cercul interior : arată paginile aparținând primului acces cu crawlere (crawl-ul mai vechi).
- Al doilea nivel și cerc exterior : arată paginile celui de-al doilea crawl (cel mai nou) care corespund fiecărui segment al cercului interior.
Deci, puteți găsi cu ușurință, de exemplu, pagini indexabile în primul crawler care nu mai sunt în al doilea și invers.
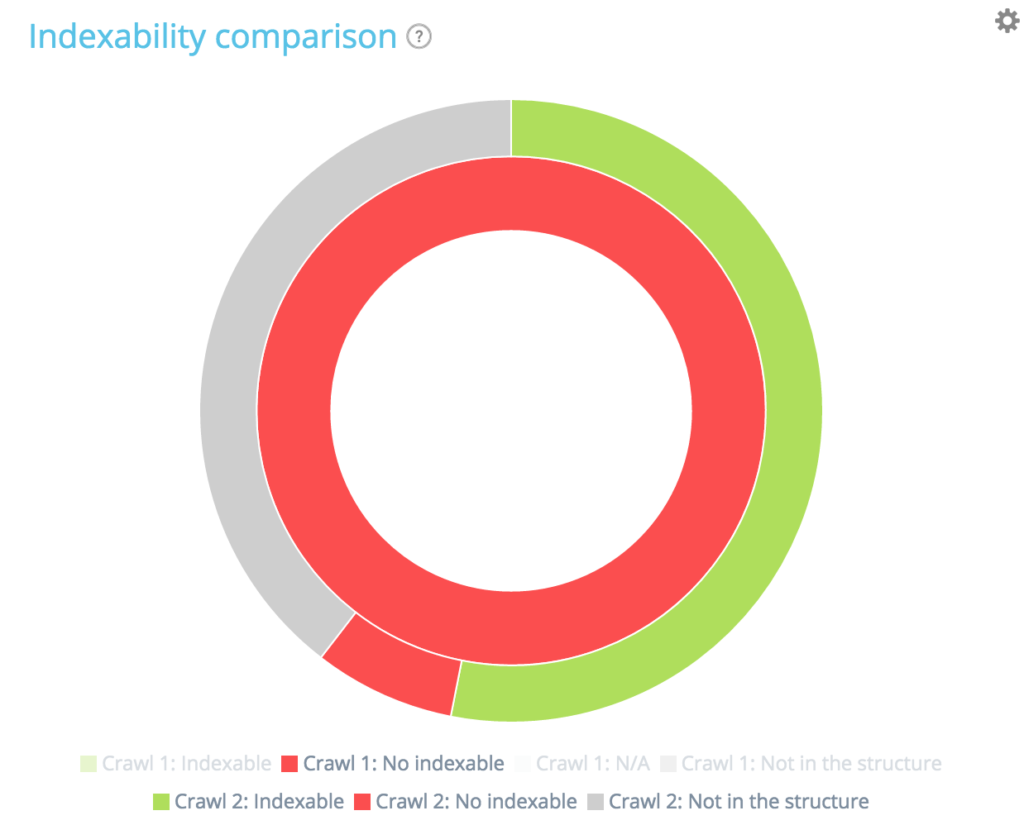
În această diagramă, cercul interior arată repartiția paginilor din primul punct de vedere al accesării cu crawlere (cel mai vechi). Puteți vedea că există pagini indexabile, nu pagini indexabile și pagini care nu au fost în primul acces cu crawlere, dar apar în al doilea (secțiunea gri).
Apoi, pentru fiecare secțiune a cercului interior, puteți vedea repartiția paginilor unei anumite secțiuni în al doilea crawler. Secțiunea interioară gri înseamnă că acele pagini nu au existat în primul acces cu crawlere, ci apar în al doilea (secțiunea exterioară verde și roșie aparținând celei interioare gri).

Secțiunile gri înseamnă că paginile sunt noi sau nu existente în structură, în funcție de cercul din care aparțin.
Făcând clic pe legendă, puteți decide ce date doriți să afișați sau pe care doriți să vă concentrați. Crawl 2 oferă o vedere mai globală.
Să aruncăm o privire la cercul interior.
Distribuția paginilor din primul acces cu crawlere în funcție de indexabilitatea acestora
 Prima accesare cu crawlere conține 10 854 de pagini indexabile și 177 de pagini fără indexare. 1 661 de pagini au fost găsite doar în al doilea crawler.
Prima accesare cu crawlere conține 10 854 de pagini indexabile și 177 de pagini fără indexare. 1 661 de pagini au fost găsite doar în al doilea crawler.
Acum aruncați o privire la cercul exterior. Pentru fiecare segment al primului cerc găsim distribuția acestor pagini în al doilea crawler.
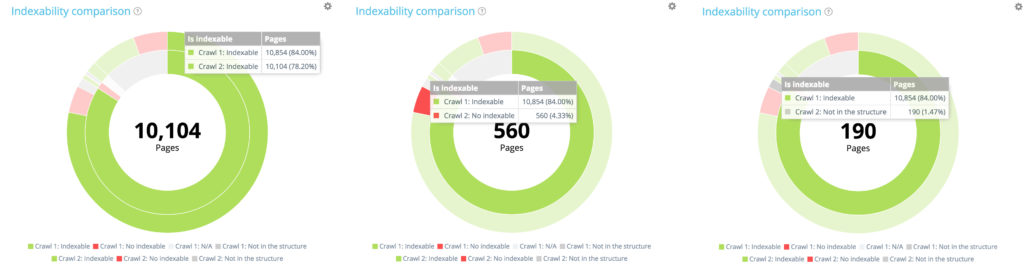
Dintre cele 10 854 de pagini indexabile din primul acces cu crawlere, doar 10 104 sunt încă indexabile în al doilea. 560 sunt acum neindexabile și 190 de pagini nu mai făceau parte din site-ul web care poate fi accesat cu crawlere la momentul celei de-a doua accesări cu crawlere.
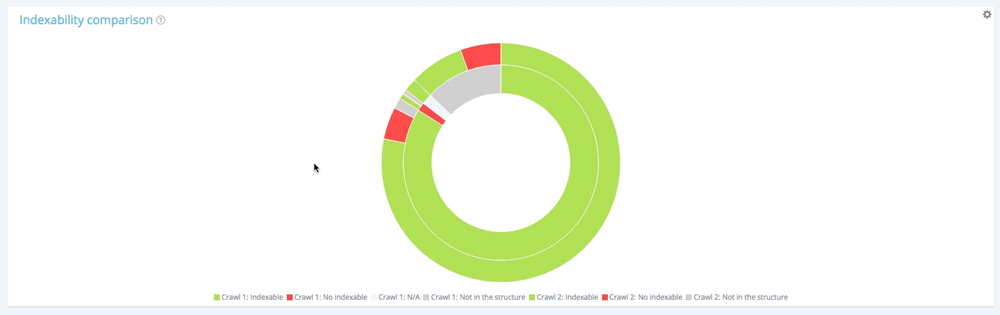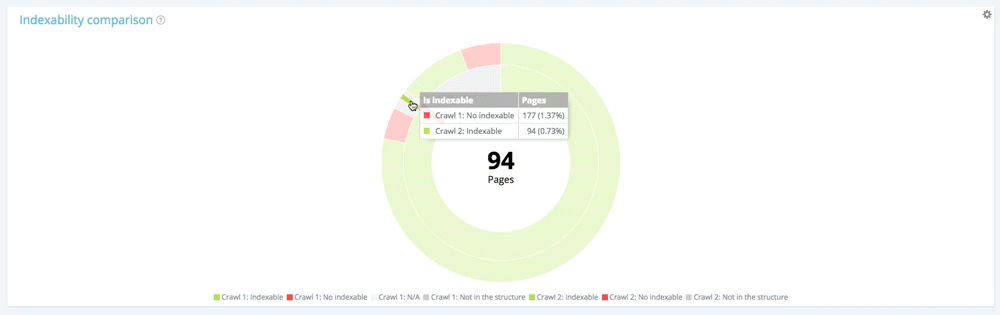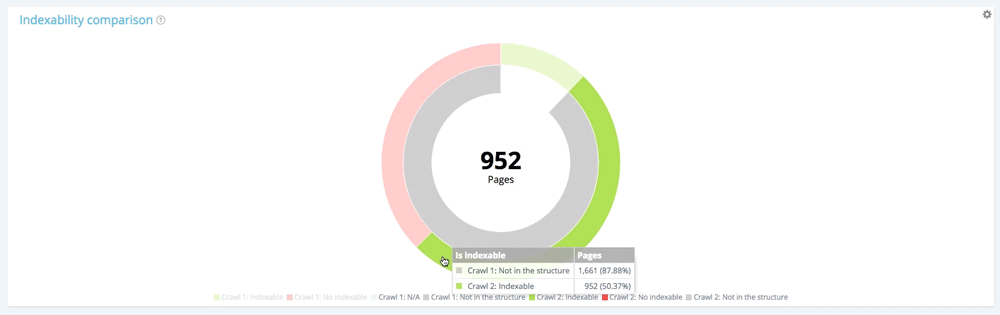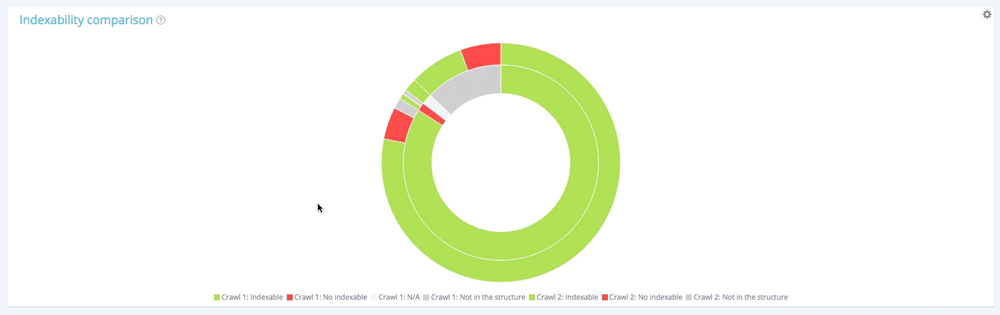
Să ne concentrăm pe o mică secțiune: pagini neindexabile în prima accesare cu crawlere
Folosind legenda pentru a ascunde paginile indexabile și paginile care nu se află în structura site-ului la momentul primei accesări cu crawlere, ne putem concentra numai pe paginile neindexabile din prima accesare cu crawlere.
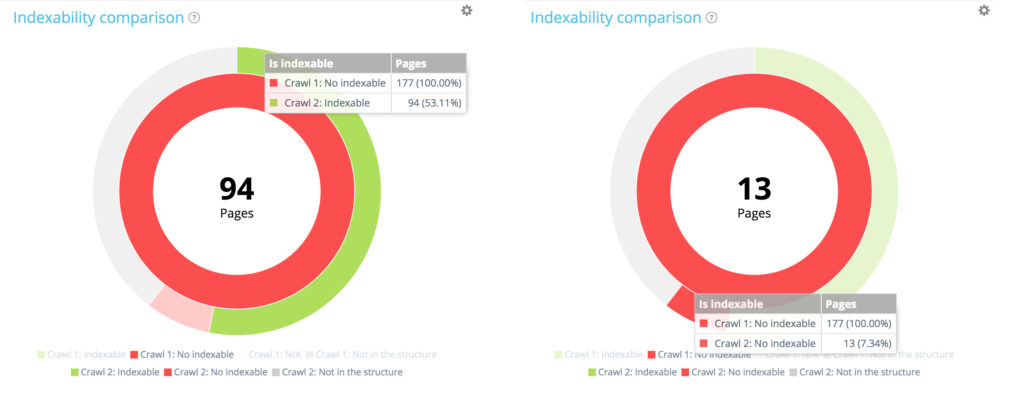 Dintre cele 177 de pagini neindexabile din primul acces cu crawlere, 94 sunt acum indexabile în al doilea și 13 rămân indexabile.
Dintre cele 177 de pagini neindexabile din primul acces cu crawlere, 94 sunt acum indexabile în al doilea și 13 rămân indexabile.
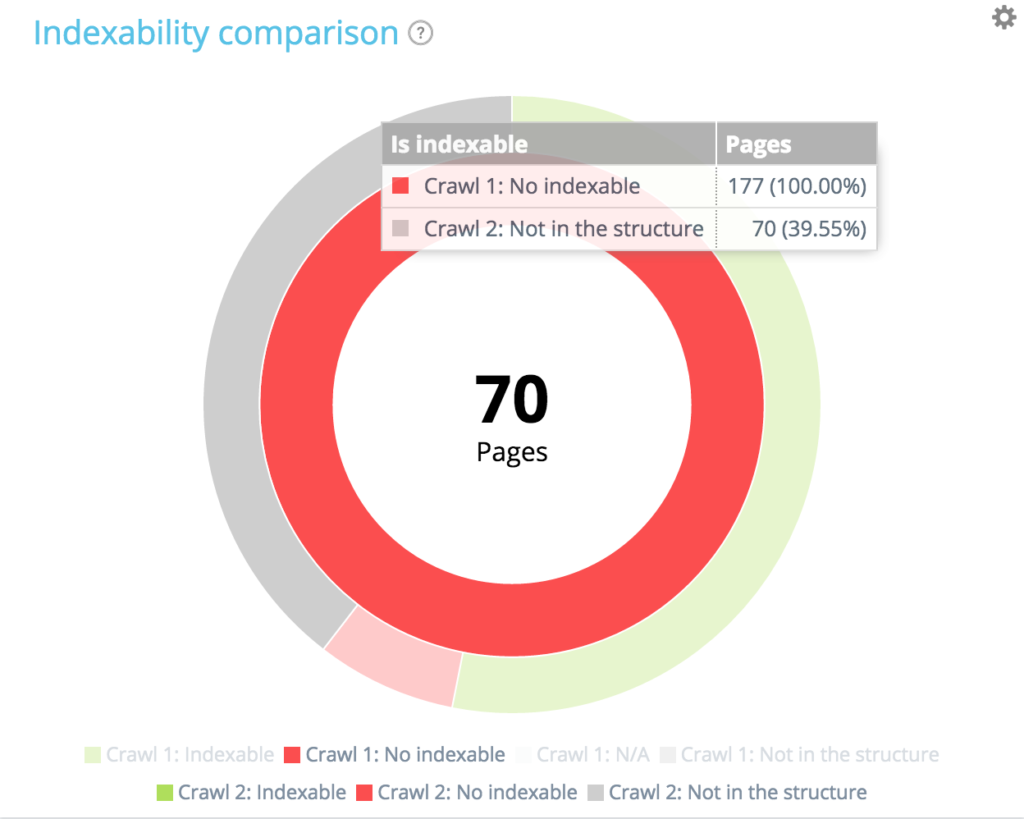
Din cele 177 de pagini neindexabile din primul accesare cu crawlere, 70 nu mai sunt prezente în al doilea accesare cu crawlere. 94 + 13 + 70 = 177. Găsim defalcarea așteptată a celor 177 de pagini neindexabile din primul acces cu crawlere.
Concentrați-vă pe pagini noi: paginile găsite numai în a doua accesare cu crawlere
Acum să folosim legenda pentru a ascunde atât paginile indexabile, cât și cele neindexabile de la prima accesare cu crawlere și să arătăm numai paginile care nu făceau parte din structura site-ului în timpul acestei accesări cu crawlere. Acest lucru vă permite să vedeți starea paginilor noi în ceea ce privește indexarea.
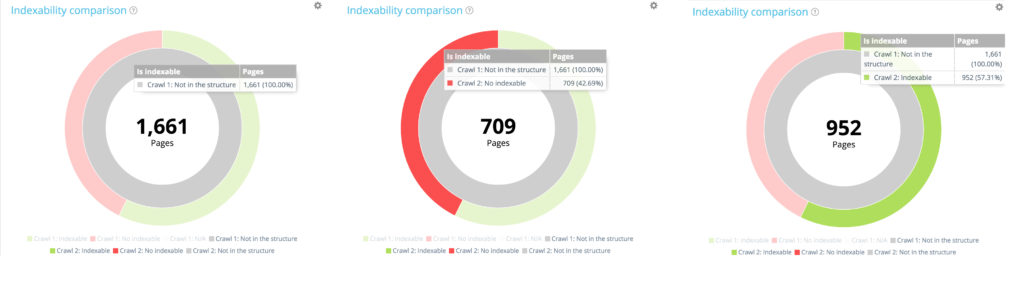
Toate paginile noi: 1 661 pagini.
Din cele 1 661 de pagini nou create, 709 nu sunt indexabile.
Din cele 1661 de pagini nou create, 952 sunt indexabile.
Rezumat: toate paginile din a doua accesare cu crawlere
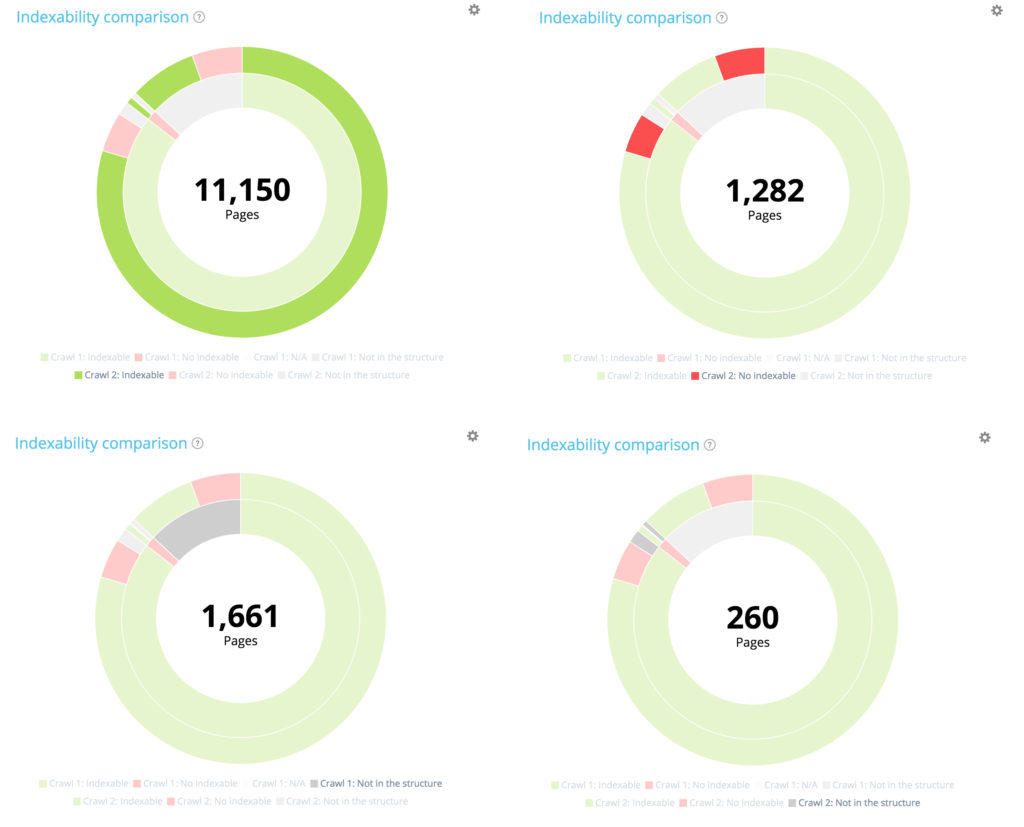 10 104 pagini au fost indexabile la prima accesare cu crawlere. 11 150 sunt acum indexabile în al doilea. 177 de pagini nu au fost indexabile în primul acces cu crawlere, dar 1 282 sunt acum neindexabile în al doilea.
10 104 pagini au fost indexabile la prima accesare cu crawlere. 11 150 sunt acum indexabile în al doilea. 177 de pagini nu au fost indexabile în primul acces cu crawlere, dar 1 282 sunt acum neindexabile în al doilea.
Au fost create 1661 de pagini și 260 de pagini au fost șterse din structură.
Crawl over Crawl: date disponibile
Această nouă caracteristică este împărțită pe expertize în afaceri și între următoarele file:
- Structura
- Legătura internă
- Conţinut
- Coduri de stare
- Performanţă
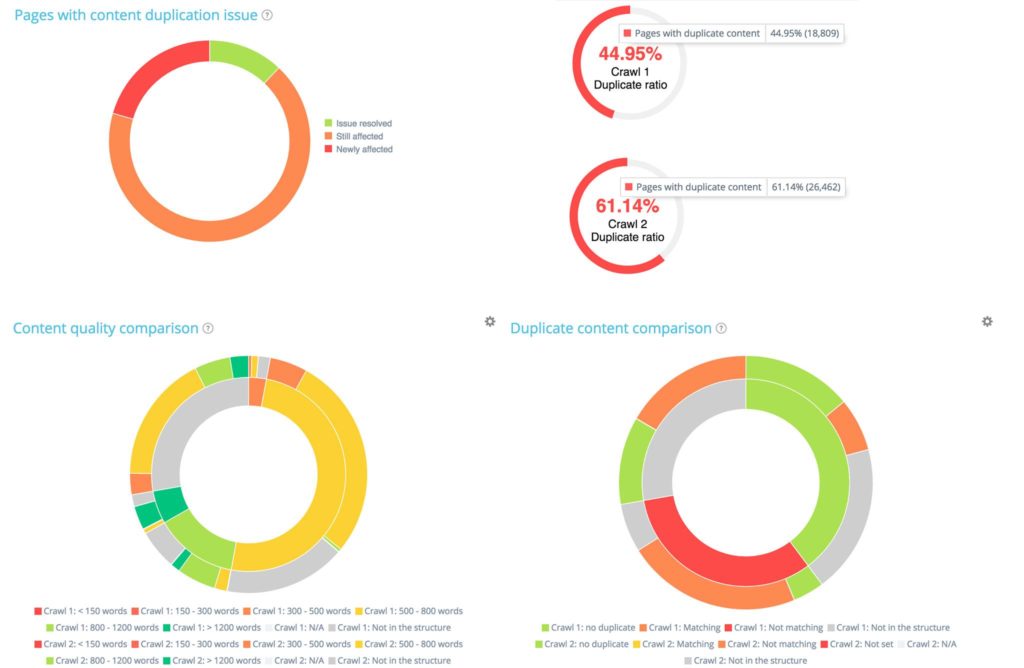
De exemplu, în secțiunea „Conținut”, veți găsi o atenție deosebită asupra diferențelor de duplicare dintre cele două accesări cu crawlere:
De asemenea, puteți analiza modul în care profunzimea paginii dvs. diferă între cele două accesări cu crawlere. În graficul de mai jos, puteți vedea diferențele de adâncime:
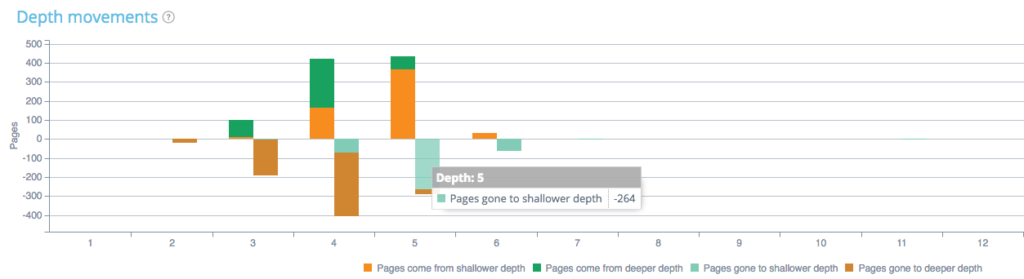
De exemplu, dacă ne uităm la adâncimea 5, putem vedea pagini care au trecut la o adâncime mai mică sau mai adâncă sau pagini care provin de la o adâncime mai mică sau mai adâncă între crawl 1 și 2. Aici, 264 de pagini care au fost în crawl 1 și în depth 5 au ajuns la o adâncime mai mică (adâncimea 4, 3 sau 2).
Aceasta este doar o prezentare generală a ceea ce este disponibil. Exploratorul nostru de date vă permite, de asemenea, să explorați peste 700 de valori pentru comparații cu crawlere.