
Cum să automatizezi modelarea mixului de marketing cu o foaie de calcul pentru fluxul de date MMM
Publicat: 2022-06-16Modelarea mixului de marketing sau MMM cunoaște o renaștere, la peste 60 de ani de când a intrat în uz comun. Spre deosebire de majoritatea metodelor de atribuire de marketing, MMM nu necesită date la nivel de utilizator, în loc să modeleze ce canale merită credit pentru vânzări prin maparea statistică a creșterilor și scăderilor cheltuielilor la acțiuni și evenimente din canalele dvs. de marketing. Trecând de la regresia liniară simplă la tehnici precum regresia ridge sau metodele bayesiene, modelarea mixului de marketing este reinventată pentru epoca modernă.

Doriți să aflați mai multe despre MMM?
Citiți argumentele pro și contra despre modelarea mixului de marketing și modelarea atribuirii
Cu toate acestea, există obstacole majore de depășit. Construirea unui model poate dura între 3 și 6 luni, potrivit Meta/Facebook, care lucrează la biblioteca sa open-source MMM din octombrie 2021. Potrivit estimărilor sale, aproximativ 50% din timp este petrecut cu colectarea și curățarea datelor înainte de începerea modelării. . Acest lucru se potrivește cu experiența mea la Recast și anterior cu cea a lui Harry, precum și cu rezultatele unui studiu CrowdFlower care a constatat că 60% din timpul științei datelor este petrecut cu curățarea și organizarea datelor.
Înainte rapid >>
- Curățarea datelor
- Construirea unui model de mix de marketing
- Modelare automată
Curățarea datelor reprezintă 60% din muncă și cum să o faci 0%
Pentru a construi un model precis, aveți nevoie de datele dvs. într-un format specific. Pregătirea datelor necesită timp, așa că proiectele MMM durează mai mult decât este necesar. Acest lucru face ca MMM o abilitate specializată și costisitoare, astfel încât majoritatea companiilor pot construi doar unul sau două modele pe an. Dacă puteți automatiza procesul folosind un instrument precum Supermetrics pentru a construi un flux de date MMM, puteți actualiza regulat modelul dvs., permițându-vă să vă optimizați mai bine bugetul de marketing.
Format de date tabelar
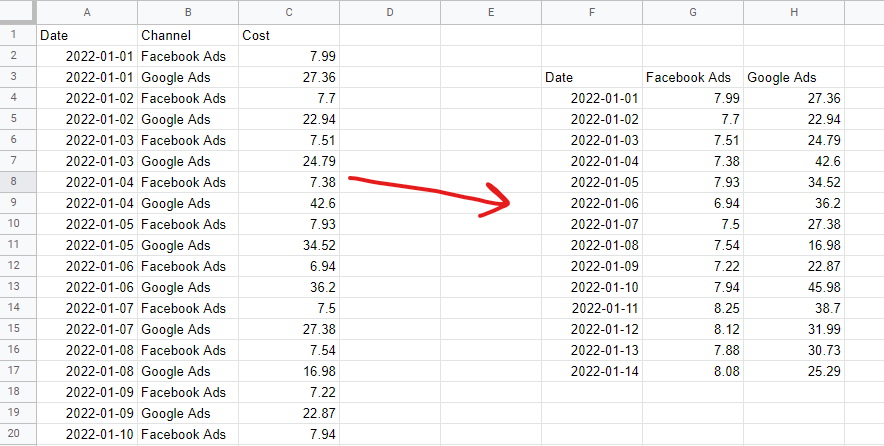
Pentru a construi un model de mix de marketing, trebuie să aveți datele prezentate într-un format tabelar nestivuit. Aceasta înseamnă un rând per observație – de obicei zile sau săptămâni – și o coloană pentru fiecare „funcție” model – de obicei cheltuieli media și variabile organice sau externe. Datele categorice - de exemplu, o listă de sărbători naționale - trebuie să fie codificate în variabile fictive - 1 când este acea sărbătoare, 0 când nu este.
Surse de date asociate
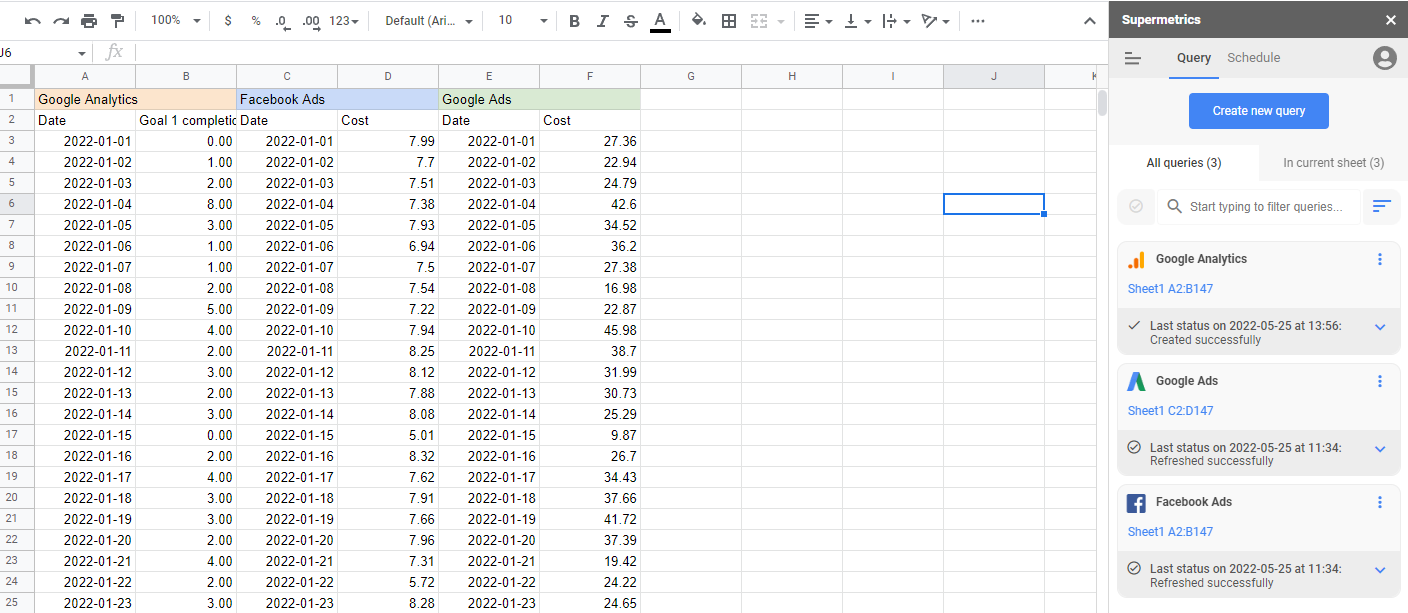
Pentru a construi un model de atribuire de marketing, trebuie să aveți toate datele de marketing într-un singur loc. Acesta este ceea ce Supermetrics se ocupă automat pentru dvs. Cu peste 90 de conectori, toate cheltuielile, evenimentele și activitățile dvs. de marketing pot fi reunite într-un singur loc, manipulate după cum este necesar și apoi exportate în formatul și locația de care aveți nevoie.
Se exportă în Foi de calcul Google
Odată ce aveți un cont Supermetrics, trebuie pur și simplu să mergeți la Extensii > Suplimente > Obțineți suplimente și să le instalați. Vă va cere să vă autentificați cu contul dvs. Google conectat la contul dvs. Supermetrics, iar apoi bara laterală va apărea în meniul de extensii.
După ce ați făcut acest lucru, puteți lansa bara laterală – dacă nu este deja lansată – și puteți face clic pentru a crea o nouă interogare. Interogările reprezintă modul în care decideți ce date să extrageți și din ce conturi. Când selectați una dintre platformele de anunțuri precum Facebook Ads și Google Ads, vă va solicita să vă autentificați și să acordați acces Supermetrics.
Apoi veți alege contul din care doriți să extrageți date și intervalul de date. În cele din urmă, alegeți valorile — de obicei costul sau afișările pentru MMM — și parametrii — selectați doar data pentru a fi în concordanță cu formatul tabelar.
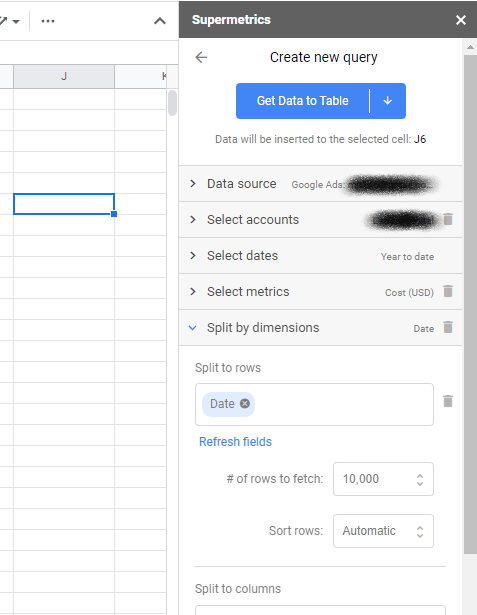
Opțional, este posibil să doriți să adăugați un filtru dacă trebuie să selectați un anumit set de campanii. De exemplu, dacă ați avut „YT:” în numele campaniilor dvs. YouTube, poate doriți să le selectați ca sursă separată, apoi să duplicați interogarea și să filtrați pentru fiecare dintre celelalte tipuri de campanii.
După ce ați terminat interogarea, asigurați-vă că ați selectat celula în care doriți să atragă datele și faceți clic pe „Obțineți date în tabel”. Dacă faceți o greșeală, duplicați interogarea și puneți-o la locul potrivit, ștergând-o pe cealaltă.
Mi se pare util să pun numele fiecărei surse într-o celulă deasupra tabelului, astfel încât să știu de unde extrag datele. Rezultatul ar trebui să arate astfel:
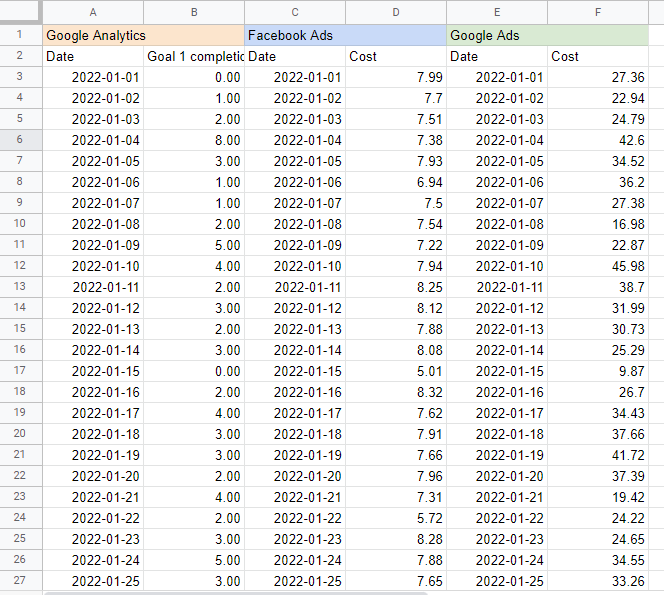
Crearea unui model de mix de marketing în Foi de calcul Google
Modelarea mixului de marketing este un instrument puternic de atribuire, dar este de fapt mai accesibil decât credeți. Majoritatea practicienilor folosesc cod personalizat și statistici avansate, dar puteți face elementele de bază într-o după-amiază cu nimic mai mult decât Excel sau Foi de calcul Google.
Regresia liniară cu funcția LINEST
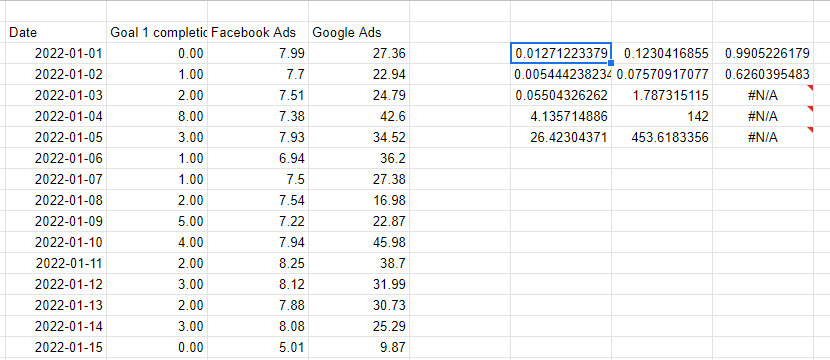
Excel și Google Sheets oferă ambele o metodă simplă, funcția LINEST, pentru a face regresia liniară cu mai multe variabile. LINEST funcționează prin trecerea coloanei pe care încercăm să o prezicem, apoi a mai multor coloane reprezentând variabilele pe care le folosim pentru a face predicția. Ultimii doi parametri sunt dacă vrem o linie de interceptare - de obicei 1 pentru da - și dacă vrem ca rezultatul să fie verbos - care să conțină toate statisticile pentru model, nu doar coeficienții.
Rețineți că variabilele X pe care le folosim pentru a face predicția trebuie să fie consecutive, așa că tocmai am făcut referire la coloanele din stânga pentru a repeta valorile unul lângă celălalt.
Reprognoza cu coeficienți de model
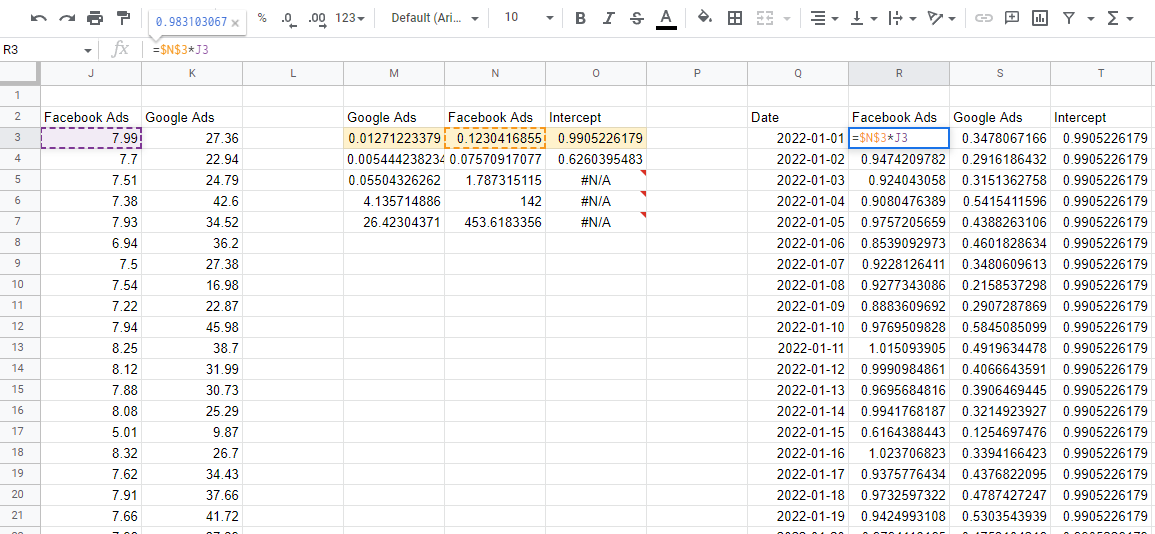
Acum că avem un model, trebuie să folosim coeficienții pentru a estima impactul fiecărui canal. Dacă luăm rândul de sus de numere, aceștia sunt coeficienții și îi înmulțim cu valorile de intrare corespunzătoare din datele noastre - vom obține contribuția fiecărei variabile la vânzările totale.

Un lucru la care trebuie să aveți grijă este că LINEST scoate coeficienții înapoi. Prima valoare care începe de la stânga este întotdeauna ultima variabilă introdusă, apoi continuă în ordine inversă până când ajungeți la ultima valoare, care este interceptarea. Dacă adunați toate aceste valori de contribuție, vă oferă predicțiile din model, pe care le puteți compara cu valorile reale pentru a vă asigura că modelul este corect.
Verificarea valorilor de acuratețe a modelului
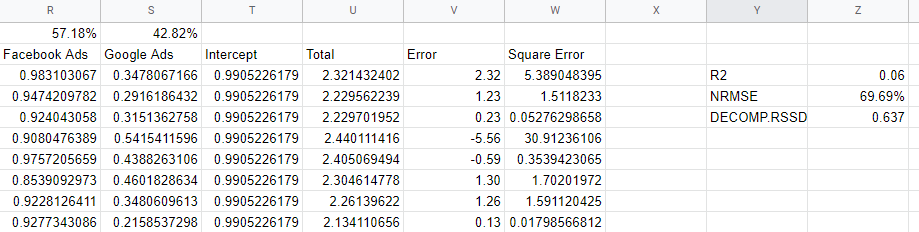
Cum știm dacă modelul nostru este fiabil? Modelul ar trebui să se potrivească bine datelor, ar trebui să poată prezice date noi pe care nu le-a văzut și ar trebui să aibă coeficienți plauzibili. Mai multe valori de validare surprind aceste cerințe.
Verificați funcțiile din șablon pentru a vedea cum să calculați aceste valori.
Pentru a utiliza șablonul, accesați „Fișier” > „Fă o copie” > „Lansați Supermetrics” din lista de suplimente > duplicați acest fișier pentru alt cont și apoi continuați la selectarea contului.
R2 sau R-Squared este o măsură a cât de mult din variația datelor este explicată de model și este între 0 și 1: un model bun ar fi peste 0,7, dar orice se apropie de 1 este probabil suspect. Aproape de 0, așa cum este modelul nostru, este un semn că nu includem suficiente variabile în modelul nostru și că trebuie să încorporăm lucruri precum canale organice, sărbători și factori macroeconomici.
„Eroarea pătrată medie a rădăcinii normalizate” este modul în care măsurăm acuratețea și este găsită luând diferența dintre predicțiile modelului și valorile reale, apoi găsind rădăcina valorilor pătrate ca procent din valoarea reală. În mod ideal, acest lucru se face pe baza unor date nevăzute - un grup reținut - dar în modelul nostru simplu, doar am calculat eroarea față de datele din eșantion.
Procedura de rădăcină și pătrat gestionează valorile negative pentru noi și acționează pentru a penaliza erorile cu adevărat mari. Acest lucru poate fi interpretat ca procentul modelului este oprit în orice zi, deci este o măsură utilă, intuitivă.
Plauzibilitatea este un subiect mare și, de obicei, este ceva asupra căruia un analist ar trebui să aibă ultimul cuvânt. Cu toate acestea, este util să aveți o valoare pe care să o puteți calcula programatic, astfel încât să înțelegeți cât de mult se abate modelul în ceea ce privește constatările sale de la mixul dvs. actual de canale.
Decomp RSSD este o măsură inventată de echipa Robyn de la Facebook, care a măsurat diferența dintre alocarea curentă a cheltuielilor și canalele care au generat cele mai mari efecte, așa cum a prezis modelul. Dacă modelul spunea că cel mai mare canal al tău nu a generat de fapt atât de multe vânzări, atunci ai avea un RSSD Decomp ridicat.
În cazul nostru, avem o valoare mare de 0,6 deoarece modelul acordă prea mult credit Facebook-ului, ceea ce reprezintă o sumă mică de cheltuială.
Livrarea automată și la scară de MMM-uri
Modelarea mixului de marketing este una dintre acele activități care este infinit scalabilă. Puteți obține rezultate decente într-o după-amiază cu Excel sau Google Sheets și Supermetrics, așa cum am făcut aici, dar puteți petrece și 3 luni cu o echipă de 6 cercetători care scriu cod personalizat cu algoritmi sofisticați precum Bayesian MCMC pentru a construi ceva mai mult robust și precis.
Există o listă de verificare a funcțiilor care sunt incluse în construirea unui model avansat, dintre care unele necesită cunoștințe avansate de statistică. Adăugați în combinație mai mulți ingineri de date scumpi pentru construirea conductelor de date dacă nu utilizați Supermetrics pentru a automatiza acea parte pentru dvs.
Doriți să aflați mai multe despre automatizarea mixurilor de modelare?
Consultați articolul nostru de modelare a mixului de marketing automatizat
Fii avertizat: MMM este greu. Puteți cheltui 500 USD, 5.000 USD sau 50.000 USD pe modelare și puteți vedea rezultate extrem de diferite în ceea ce privește acuratețea și robustețea. Ceea ce contează cu adevărat este costul de oportunitate al alocarii greșite a cheltuielilor de marketing.
Dacă cheltuiți 10.000 USD pe lună, atunci un model de foaie de calcul o dată pe trimestru va fi bine. Cu toate acestea, dacă cheltuiți peste 100.000 USD pe lună, chiar și reducerea cu 5% vă poate costa zeci de mii de dolari pe parcursul unui an.
Nu sunteți sigur de ce model de acces la date aveți nevoie pentru feedul dvs. MMM?
Consultați articolul nostru pentru a-l alege pe cel potrivit pentru afacerea dvs
Atunci are sens să investești în modelare mai avansată. Efectuați o analiză build vs buy pentru a decide între o soluție personalizată construită pe biblioteci open-source, cum ar fi Robyn de la Facebook, sau un software avansat de atribuire, precum cel pe care l-am construit la Recast.
Despre autor
Michael Kaminsky este un econometrician calificat cu experiență în domeniul sănătății și economia mediului. El a construit anterior echipa de științe de marketing la brandul de îngrijire pentru bărbați Harry's înainte de a co-fonda Recast.

Îmbunătățiți performanța afacerii dvs
combinând marketingul și business intelligence în depozitul dvs. de date