
Împuternicirea securității bancare: învățarea automată pentru detectarea fraudelor
Publicat: 2023-11-14Cu fiecare oportunitate vine o amenințare. Trecerea către digitalizare în industria bancară a îmbunătățit experiența clienților și a extins bazele de clienți către populații care anterior nu erau bancare. Dezavantajul a fost că tranzacțiile online și soluțiile de plată digitală au deschis noi căi de exploatare pentru fraudatori.
Descoperirile unui sondaj privind fraudele KMPG indică faptul că atacurile cibernetice cresc ca frecvență și severitate, rezultând pierderi de miliarde de dolari.
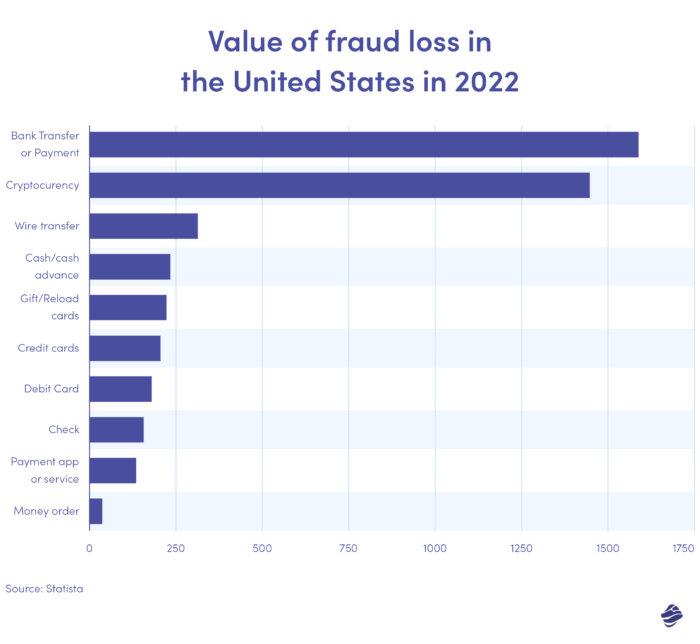
Graficul de mai sus ilustrează valoarea pierderilor prin fraudă prin metoda de plată în Statele Unite în 2022. Transferurile bancare și plățile au fost cele mai mari, cu o pierdere de 1,59 miliarde USD.
Aceste pierderi au forțat instituțiile bancare să adopte noi soluții pentru a detecta, a atenua și a preveni frauda financiară. O astfel de metodă este inteligența artificială (AI), în special învățarea automată.
În acest articol, vom discuta tot ce trebuie să știți despre învățarea automată pentru detectarea fraudelor , inclusiv beneficiile și aplicațiile din viața reală.
Evoluția detectării fraudelor
Detectarea tradițională a fraudelor urmează o abordare bazată pe reguli. După cum sugerează și numele, acesta funcționează conform unui set de reguli sau condiții care determină dacă o tranzacție este autentică sau frauduloasă. Condițiile comune includ locația (cumpărarea se află în afara zonei obișnuite a utilizatorului?) și frecvența (numărul și tipul de achiziție sunt uzuale pentru utilizator?).
O tranzacție are loc doar atunci când îndeplinește condițiile. De exemplu, un client din Ohio are brusc o taxă POS în Noua Zeelandă. Locația se află în afara codului de zonă al utilizatorului, astfel încât sistemul semnalează tranzacțiile ca fiind frauduloase.
Există mai multe dezavantaje la acest tip de sistem de detectare a fraudei.
- Produce un număr mare de fals pozitive. Aici blocați plățile de la clienții autentici.
- Este inflexibil. Abordarea bazată pe reguli utilizează rezultate fixe, ceea ce face dificilă adaptarea la tendințele din domeniul bancar digital. Trebuie să schimbați regulile pentru a prinde noi forme de fraudă.
- Nu se scalează. Când datele cresc, crește și efortul necesar pentru a le preveni. Orice modificare a sistemului se face manual, ceea ce îl face costisitor și consumator de timp.
Detectarea fraudei bazată pe reguli funcționează. Cu toate acestea, dezavantajele sale îl fac nepotrivit pentru mediile digitale moderne. Nu poate recunoaște tipare și se bazează pe intervenția umană.
Mai mult, hackerii nu respectă un program de 9-5 și pot implementa metode sofisticate precum falsificarea locației și uzurparea identității comportamentului clienților pentru a păcăli sistemele de detectare a fraudelor. Prin urmare, aveți nevoie de un sistem la fel de înalt dezvoltat, care funcționează 24/7.
Intrați în învățarea automată.
Învățarea automată este o inteligență artificială (AI) care utilizează date pentru a antrena algoritmi de detectare a fraudei pentru a descoperi modele și relații de date, pentru a obține informații și pentru a face predicții.
Sunteți deja familiarizat cu învățarea automată, chiar dacă nu o știți. De exemplu, ori de câte ori interacționați cu o postare pe Instagram, furnizați algoritmului informații despre tipul de conținut care vă place. Apoi caută aplicația pentru conținut similar de adăugat în feed.
Cum va transforma învățarea automată detectarea fraudelor
Detectarea fraudei în domeniul bancar, folosind învățarea automată, schimbă deja industria, cu o identificare mai rapidă, mai flexibilă și mai precisă a fraudei și un răspuns la fraudă.
Sistemul AI analizează modelele din datele clienților și schimbă automat regulile pe baza amenințărilor istorice și emergente.
Vă amintiți taxa POS din Noua Zeelandă pe care am menționat-o mai devreme? Detectarea fraudei folosind învățarea automată ar considera că același card bancar are o achiziție pentru un zbor către acea locație. Prin urmare, noul debit este cel mai probabil legitim.
Două modele sunt folosite pentru a antrena algoritmi pentru a detecta frauda: învățarea automată supravegheată și învățarea automată nesupravegheată.
Învățare automată supravegheată
Modelul de învățare supravegheată furnizează algoritmilor cantități mari de date etichetate ca fraudă sau non-fraudă. Algoritmul studiază aceste exemple și învață ce modele și relații disting tranzacțiile legitime de cele frauduloase.
Acest model de învățare necesită timp, deoarece necesită etichetarea manuală a datelor. În plus, seturile dvs. de date trebuie să fie corect etichetate și bine organizate. O tranzacție etichetată incorect va afecta acuratețea algoritmului.
În plus, învață doar din intrările incluse în setul de antrenament. Prin urmare, tranzacțiile prin funcțiile aplicației mobile banking recent lansate, care nu făceau parte din datele istorice, nu vor fi semnalate. Acum există o lacună pe care fraudătorii trebuie să o exploateze.
Învățare automată nesupravegheată
Modelul de învățare nesupravegheat folosește aport uman minim. Algoritmul învață modele și relații din cantități mari de date neetichetate, grupând seturi de date pe baza asemănărilor și diferențelor.
Obiectivul este de a identifica activități neobișnuite care nu sunt incluse în setul de date de antrenament. Astfel, învățarea nesupravegheată începe acolo unde învățarea supravegheată scade și detectează noi fraude.
Rețineți că nu trebuie să alegeți între un model de învățare automată supravegheat sau nesupravegheat. Le puteți folosi împreună (model de învățare semi-supravegheată) sau independent.
Beneficiile utilizării ML pentru detectarea fraudelor
Am făcut aluzie la beneficiile detectării fraudelor folosind învățarea automată în domeniul bancar, dar haideți să le discutăm în continuare.
- Viteză
Calculele de învățare automată au loc rapid și dau decizii de fraudă în timp real. În timp ce algoritmii bazați pe reguli decid și în timp real, ei se bazează pe reguli scrise pentru a semnala frauda.
Ce se întâmplă în scenariile noi fără reguli predefinite? Aceasta duce la fals pozitive sau fals negative.
Învățarea automată detectează automat noi modele, analizând activitatea obișnuită a clienților și calculând rezultatele adecvate în milisecunde.
- Precizie
Sistemele de detectare bazate pe reguli blochează tranzacțiile autentice sau le permit pe cele frauduloase deoarece nu detectează nuanțe în comportamentul clienților.
Sistemele de învățare automată iau în considerare variabile dincolo de regulile scrise, de exemplu, comportamentul fraudulos cunoscut. Aceste variabile ajută la contextualizarea tranzacției, scăzând rata de fals pozitive.
- Flexibilitate
Învățarea automată este flexibilă și reactivă. Capacitatea de auto-învățare permite acestui sistem să se adapteze la noile scenarii și să detecteze noi amenințări. Sistemele bazate pe reguli sunt rigide și nu au capacități de învățare. Prin urmare, poate răspunde activităților frauduloase numai conform unor reguli predefinite.
- Eficienţă
Algoritmii de învățare automată pot analiza mii de date de tranzacție pe secundă. În loc să cheltuiască forța de muncă și costurile generale pentru investigarea cazurilor de fraudă scăzute până la moderate, învățarea automată poate procesa fraude repetitive sau clare. Le permite specialiștilor în fraudă să se concentreze pe modele complexe care necesită înțelegere umană.
- Scalabilitate
Volumul crescut de date pune presiune asupra sistemelor bazate pe reguli. Noile reguli sporesc complexitatea sistemului, făcându-l dificil de întreținut. Orice eroare sau contradicție poate face întregul model ineficient.
Sistemele de învățare automată sunt opusul. Nu numai că asimilează volume mari de date noi, dar se îmbunătățesc.
Tehnici de învățare automată utilizate în detectarea fraudelor
Înainte de a examina diferiții algoritmi utilizați în detectarea fraudelor AI, să vedem cum funcționează sistemul.
Primul pas este introducerea datelor. Precizia modelului depinde de volumul și calitatea datelor. Cu cât adăugați mai multe date de înaltă calitate, cu atât modelul devine mai precis.
În continuare, modelul analizează datele și extrage caracteristicile cheie care descriu comportamentele normale față de cele frauduloase. Aceste caracteristici includ identitatea clientului (e-mail sau număr de telefon), locația (IP sau adresa de livrare), metodele de plată (numele titularului cardului și țara de origine) și multe altele.
Al treilea pas este antrenarea algoritmului (cu mai multe date) pentru a distinge între tranzacțiile autentice și cele frauduloase. Modelul primește un set de date de antrenament și prezice probabilitatea de fraudă în diferite cazuri. Odată ce algoritmul este suficient antrenat, sunteți gata să-l lansați.
Acum, să ne uităm la diferiții algoritmi pe care îi puteți folosi.
1. Regresie logistică
Regresia logistică este un algoritm de învățare supravegheată. Acesta calculează probabilitatea de fraudă la scară binară – fraudă sau non-fraudă – pe baza parametrilor modelului.
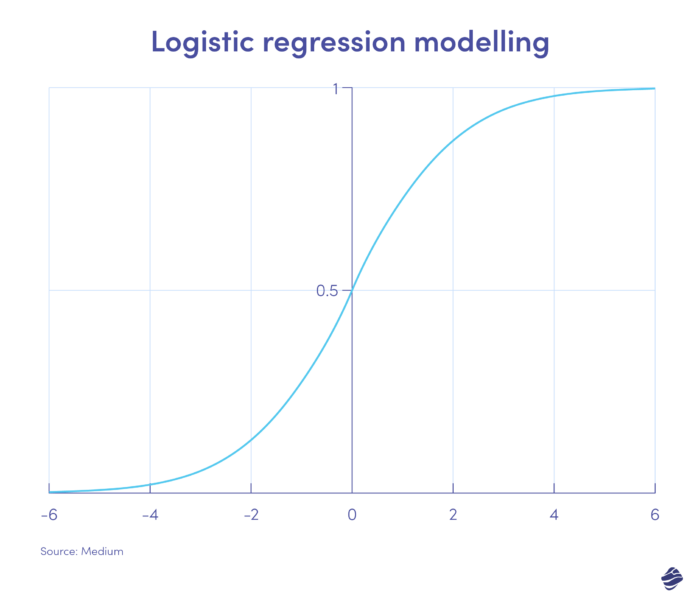
Tranzacțiile care se încadrează în partea pozitivă a graficului sunt cel mai probabil frauduloase, în timp ce cele din partea negativă sunt cel mai probabil legitime.
2. Arborele de decizie
Un arbore de decizie este un algoritm de învățare supravegheată, dar merge mai departe decât algoritmii de regresie logistică. Este o structură de decizie ierarhică care analizează datele în niveluri pentru a determina dacă o tranzacție este autentică sau frauduloasă.
Mai jos este o ilustrare a unui arbore de decizie pentru detectarea fraudelor cu cardul de credit.
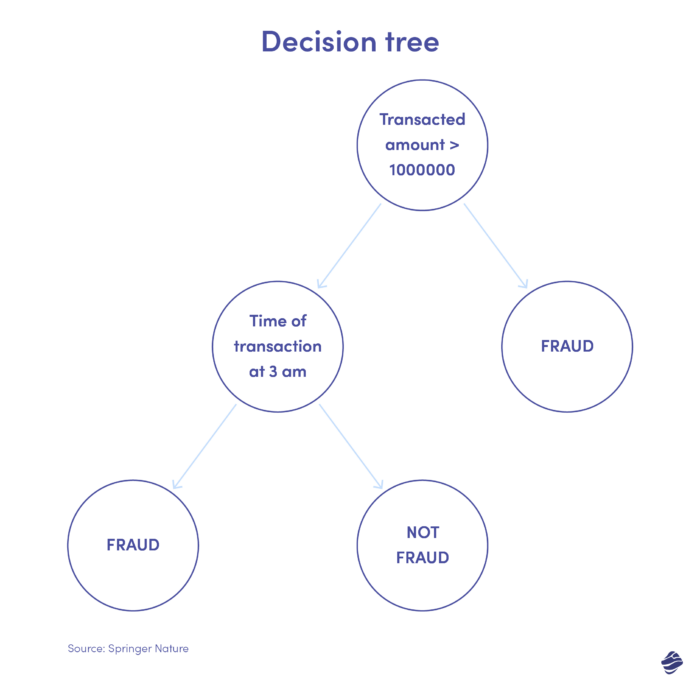
Condiția pentru a identifica dacă tranzacția este frauduloasă este valoarea tranzacției. Dacă valoarea tranzacției depășește un prag stabilit, algoritmul o consideră frauduloasă. Dacă nu, arborele verifică o altă condiție – timpul tranzacției. Dacă ora este neobișnuită (aici, 3 dimineața), este probabil să fie o fraudă. Dacă nu, verifică o altă condiție. Merge pe.
3. Pădurea aleatorie
Pădurea aleatorie este o combinație de mulți arbori de decizie, în care fiecare arbore de decizie verifică diferite condiții – identitate, locație etc.
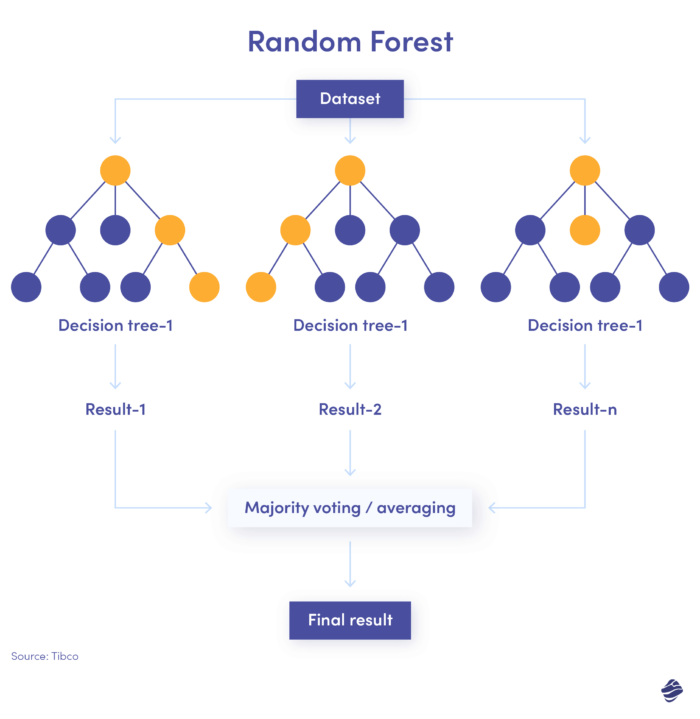
După verificarea tuturor parametrilor, fiecare sub-arbore oferă o decizie. Totalul combinat determină dacă tranzacția este autentică sau frauduloasă.
4. Rețele neuronale
Rețelele neuronale sunt algoritmi complexi, nesupravegheați. Inspirate de creierul uman, rețelele neuronale procesează datele în mai multe straturi pentru a extrage caracteristici de nivel înalt. Acest algoritm merge mână în mână cu deep learning, care poate recunoaște modele în imagini, text, audio și alte date.

Iată o versiune simplificată a unei rețele neuronale.
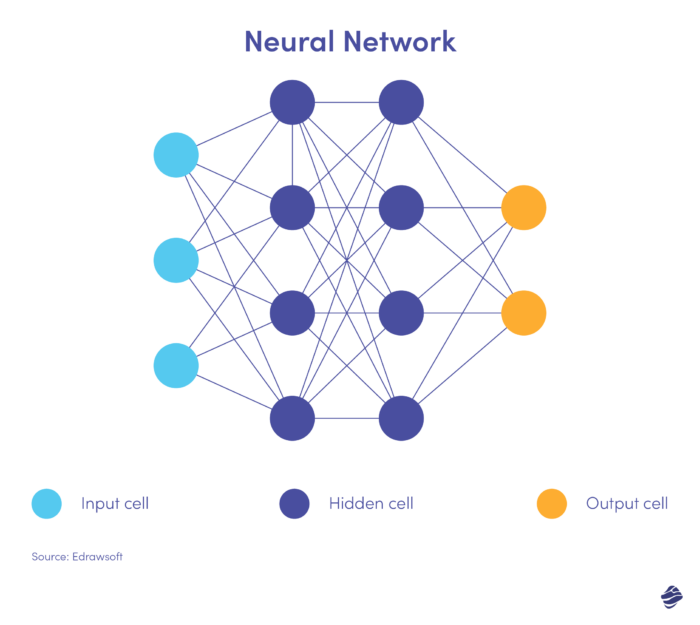
O rețea neuronală are trei straturi: intrare, ascuns și ieșire. Stratul de intrare procesează datele, stratul ascuns analizează datele din stratul de intrare pentru a identifica modele ascunse, iar stratul de ieșire clasifică datele.
Rețelele neuronale profunde au mai multe straturi ascunse. Sunt excelente pentru identificarea relațiilor neliniare și pentru detectarea scenariilor de fraudă fără precedent.
5. Suport mașină vectorială
Mașinile vectoriale suport (SVM) sunt algoritmi de învățare supravegheați care prezic, clasifică și detectează valori aberante.
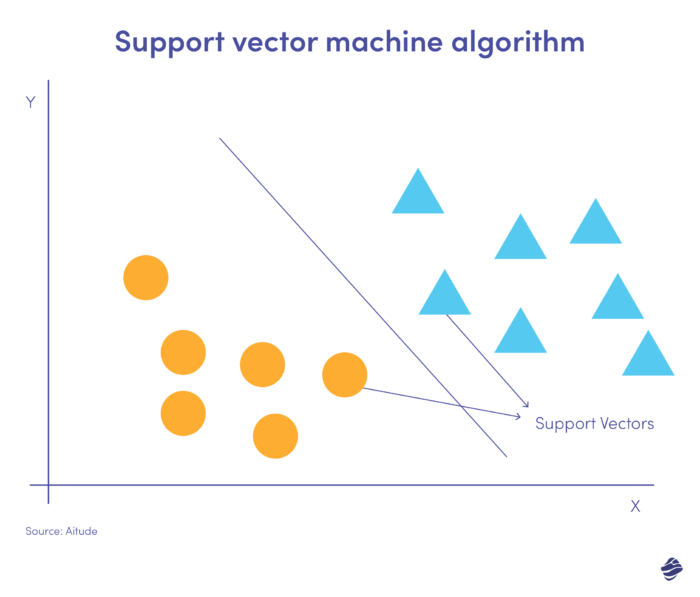
Această ilustrație liniară SVM arată două seturi de date separate printr-o linie dreaptă numită hiperplan. Este limita de decizie care clasifică datele drept fraudă versus non-fraudă.
Punctele de date mai departe de hiperplan sunt ușor de clasificat. Vectorii suport (cel mai aproape de hiperplan) sunt greu de clasificat. Aceste valori aberante pot afecta poziția hiperplanului dacă sunt eliminate.
6. K-cel mai apropiat vecin
K-nearest neighbor (KNN) este un algoritm de învățare supravegheată. Funcționează pe ipoteza că articole similare există aproape unul de celălalt.
Mai jos este o ilustrație simplă.
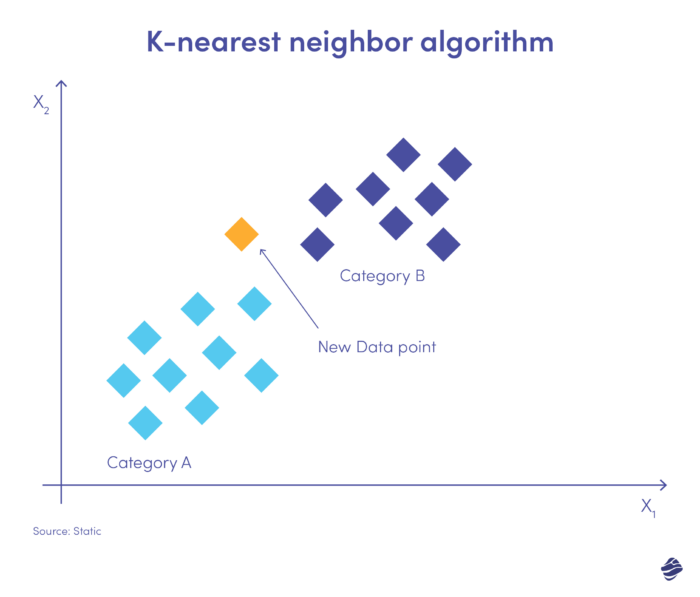
Noua intrare de date trebuie plasată fie în categoria A, fie în categoria B. Algoritmul calculează distanța dintre punctele de date folosind o ecuație matematică numită distanța euclidiană. Noul punct de date se încadrează în grupul cu cei mai mulți vecini. Dacă cel mai apropiat set de date este etichetat „fraudă”, tranzacția respectivă este clasificată drept frauduloasă.
Navigarea provocărilor și a considerațiilor strategice
La fel ca orice tehnologie, există probleme în creștere asociate cu integrarea învățării automate pentru detectarea fraudelor. Iată câteva provocări comune cu care vă puteți confrunta.
Infrastructură inadecvată
Multe sisteme bancare nu pot analiza cantități mari de date complexe. În plus, majoritatea datelor sunt izolate și găzduite în spații de stocare separate.
Din păcate, nu există o soluție rapidă pentru această problemă. Trebuie să investești în hardware și software adecvat.
Va trebui să colaborați cu o agenție de dezvoltare de aplicații Fintech cu experiență și să configurați o infrastructură pentru a selecta automat algoritmii adecvați pentru anumite seturi de date, a importa date brute și a le pregăti pentru învățarea automată, a vizualiza datele, a testa algoritmul și multe altele.
Calitatea și securitatea datelor
Calitatea datelor este o problemă importantă pentru instituțiile financiare care doresc să implementeze învățarea automată pentru detectarea fraudelor. Modelele de învățare automată nu fac diferența între datele bune și cele rele. Deci, dacă algoritmul este contaminat cu date irelevante sau incomplete, acuratețea modelului dvs. va fi incorectă.
Soluțiile de absorbție de date precum Amazon Kinesis colectează, curățează și transformă datele brute, făcându-le potrivite pentru modelele de învățare automată. Odată ce datele sunt curățate și organizate, trebuie să separați datele sensibile și cele insensibile. Criptați informațiile confidențiale și stocați-le în unități securizate. De asemenea, ar trebui să limitați accesul la aceste date.
Lipsa de talent
În ciuda a ceea ce oamenii se tem, învățarea automată nu fură locuri de muncă. Este chiar invers. Încă avem nevoie de analiști de fraudă pentru a gestiona cazuri complexe care necesită perspectivă și experiență umană. De asemenea, învățarea automată este o tehnologie nouă și nu există destui experți în domeniu.
Aceasta este o veste bună pentru cei care caută un loc de muncă, dar nu și pentru instituțiile care nu pot valorifica întregul potențial al învățării automate. Puteți depăși această viteză prin parteneriat cu companii cu setul de abilități de a implementa învățarea automată.
Studii de caz de detectare a fraudelor în domeniul bancar folosind învățarea automată
Acum, să ne uităm la exemple din viața reală de detectare a fraudelor în domeniul bancar folosind învățarea automată.
Detectarea fraudei
Danske Bank este o corporație financiară multinațională daneză. Este cea mai mare bancă din Danemarca și o bancă lider de retail din Europa de Nord. În cadrul sistemului de detectare bazat pe reguli, banca s-a străduit să atenueze frauda. A avut o rată de detectare a fraudelor de 40% și o rată de fals pozitive de 99,5%.
Lucrând cu Teradata, o companie de software de date, Danske a integrat un software de învățare profundă pentru a ajuta la identificarea potențialelor activități frauduloase. Rezultatul a fost o reducere cu 60% a valorilor false pozitive și o creștere cu 50% a valorilor pozitive adevărate.
Împotriva spălării de bani
OakNorth este o bancă comercială de creditare din Marea Britanie, care furnizează servicii financiare de afaceri și personale companiilor de dezvoltare. Banca a avut un proces de screening fracturat, cu un furnizor pentru controale împotriva spălării banilor și altul pentru clienți. În plus, screening-urile pentru persoanele expuse politic (PEP) au generat o mulțime de fals pozitive.
Lucrând cu ComplyAdvantage, o companie de detectare a fraudei și AML, banca a integrat o soluție de screening și monitorizare continuă pentru a eficientiza conformitatea și a consolida datele. Acest lucru a facilitat transferul rapid de date între operațiunile de creditare și de economisire ale băncii.
Subscriere de credit
Hawaii USA Credit Union este cea mai mare uniune de credit din Hawaii și una dintre cele mai bune uniuni de credit ale revistei Forbes. A vrut să fie competitivă față de companiile Fintech și să-și dezvolte portofoliul de împrumuturi personale fără a crește riscul.
Lucrând cu Zest AI, uniunea de credit și-a automatizat procesele de luare a deciziilor folosind un model de împrumut personal bazat pe inteligență artificială. Modelul a folosit 278 de variabile pentru a oferi informații mai profunde decât sistemul de punctare a creditelor VantageScore. Rezultatul a fost o creștere cu 21% a ratei de aprobări și o rată de fraudă de 0% implicită/solicitare de împrumut.
Considerații cheie atunci când utilizați ML pentru detectarea fraudelor
În timp ce detectarea fraudelor în domeniul bancar folosind învățarea automată este eficientă, este și descurajantă. Aceste sisteme necesită o mulțime de date precise, sau modelele nu funcționează așa cum ar trebui.
Așadar, iată câteva sfaturi pentru a optimiza procesul de învățare automată.
1. Limitați numărul de variabile de intrare
Pe parcursul acestui articol, am spus mai mult este mai mult. Acest lucru rămâne adevărat în ceea ce privește volumul de date. Cu toate acestea, mai puțin este mai mult cu numărul de variabile de detectare a fraudei.
Caracteristicile tipice de luat în considerare atunci când se investighează frauda includ:
- adresa IP
- Adresa de e-mail
- Adresa de transport
- Valoarea medie a comenzii/tranzacțiilor
Beneficiul mai puține funcții este un timp mai scurt de antrenament al algoritmului. De asemenea, evitați problemele de suprapunere sau seturi de date irelevante.
2. Asigurați conformitatea cu reglementările
Prevenirea fraudei este o parte a securității datelor. Celălalt este confidențialitatea datelor. Multe țări au legi cu privire la modul în care instituțiile pot colecta, utiliza și stoca datele clienților. Există Legea privind protecția informațiilor personale (PIPL) din China, Legea privind confidențialitatea consumatorilor din California (CCPA) și Regulamentul general privind protecția datelor (GDPR) al Uniunii Europene, pentru a numi câteva.
Aceste legi au implicații pentru datele utilizate în învățarea automată. Principiul principal în majoritatea reglementărilor privind respectarea confidențialității datelor este notificarea/consimțământul. Trebuie să notificați și să primiți permisiunea de a utiliza datele clienților în alte scopuri decât solicitările utilizatorilor, inclusiv date pentru antrenarea algoritmilor de învățare automată.
Cea mai simplă modalitate de a asigura respectarea standardelor de confidențialitate este utilizarea partenerilor tehnici cu caracteristici conforme cu reglementările. De exemplu, ar trebui să vă asociați cu o companie de dezvoltare de aplicații bancare care înțelege cum să mențină confidențialitatea și securitatea datelor.
3. Setați un prag rezonabil
Regulile privind valoarea tranzacției au cerințe minime pentru a declanșa un răspuns de acceptare sau respingere. Vrei un prag care să echilibreze securitatea și experiența utilizatorului. Dacă pragul este prea strict, riscați să blocați tranzacțiile legitime. Dacă pragul este prea lax, veți crește rata fraudelor de succes.
Calculați-vă apetitul pentru risc pentru a găsi echilibrul potrivit. Nivelurile de risc diferă pentru fiecare instituție financiară sau produs. De exemplu, o ofertă bancară de microcreditare poate stabili un prag ridicat pentru împrumuturile de valoare mică. O bancă comercială nu poate fi la fel de generoasă cu împrumuturile ipotecare.
Anticipând viitorul
Viitorul este acum, dar doar 17% dintre organizații folosesc învățarea automată în programele antifraudă. Nu fi lăsat în urmă.
Iată câteva descoperiri la care vă puteți aștepta în securitatea băncii dvs. prin învățarea automată.
- Profilare dispozitiv : identificați diferitele dispozitive care se conectează la rețeaua dvs. bancară, analizând caracteristicile și comportamentele oricărui dispozitiv dat.
- Detectarea automată a anomaliilor și răspunsul : identificați comportamentul fraudulos de la dispozitivele cunoscute și izolați sistemele afectate.
- Detectare zi zero : identificați vulnerabilitățile necunoscute anterior și programele malware pentru a proteja organizațiile de atacurile cibernetice.
- Mascarea datelor : detectează automat și anonimizează datele confidențiale.
- Informații la scară : identificați tendințele de fraudă pe mai multe dispozitive și locații.
- Politică inovatoare : utilizați informații despre învățarea automată pentru a determina politicile de securitate relevante.
Indiferent dacă sunteți o instituție de gestionare a averii sau o uniune de credit, inteligența artificială și învățarea automată oferă oportunități enorme pentru detectarea fraudelor.
Cu toate acestea, este esențial să ne amintim că hackerii folosesc și aceste tehnologii pentru a evita măsurile de protecție. Actualizați-vă modelele de învățare automată pentru a fi în fața acestor atacuri. De asemenea, vă puteți consolida securitatea bazată pe inteligență artificială cu inteligență umană veche.