
Javascript: Cum se testează implementarea SSR și/sau Pre-rendarea cu Oncrawl?
Publicat: 2021-09-13Diagnosticarea problemelor SEO cu implementarea JavaScript a unui site nu este întotdeauna ușoară. Când optați pentru Redare pe server sau Pre-rendare pentru roboți, sarcina poate deveni și mai complexă.
Trebuie să vă asigurați că versiunea oferită boților Google este completă, că toate elementele javascript au fost executate pe partea serverului și sunt prezente în html-ul accesat cu crawlere de către bot.
În acest articol, vom vedea cum să testați rapid și ușor redarea JS a tuturor paginilor dvs. utilizând Oncrawl.
SEO și JS
Înainte de a începe cu practica, să trecem rapid peste interesul pentru SEO al serverului de randare (SSR) și pre-randarea elementelor javascript ale unui site.
JS și Google: bune practici
În mod implicit, redarea HTML a javascriptului este realizată de client, adică de browserul dumneavoastră web. Când solicitați o pagină care conține elemente JS, browserul dumneavoastră este cel care execută acest cod javascript pentru a afișa pagina completă. Aceasta se numește Client-Side Rendering (CSR).
Pentru Google aceasta este o problemă deoarece necesită mult timp și mai ales resurse. Îl forțează să treacă prin pagina ta de două ori, o dată pentru a prelua codul, apoi a doua oară după redarea HTML-ului JS.
Ca o consecință directă a CSR pentru SEO dvs., conținutul complet al paginilor dvs. nu va fi vizibil imediat de Google și, prin urmare, poate întârzia indexarea acestora. În plus, bugetul de accesare cu crawlere care este acordat site-ului dvs. este, de asemenea, afectat, deoarece paginile dvs. trebuie accesate cu crawlere de două ori.
SSR (redare pe partea serverului)
În cazul SSR, redarea HTML a javascript-ului se face pe server pentru toți vizitatorii site-ului, oameni și roboți. În consecință, Google nu trebuie să gestioneze conținutul în JS, deoarece primește direct codul HTML complet în momentul accesării cu crawlere. Acest lucru corectează defectul de javascript în SEO.
Pe de altă parte, costul resurselor pentru a realiza această redare pe partea serverului poate fi important. Aici intervine a treia opțiune, pre-rendarea.
Pre-randare
În această configurație hibridă, execuția JS se face pe partea clientului pentru toți vizitatorii (CSR), cu excepția roboților motorului de căutare. Un conținut HTML pre-redat este servit roboților Google pentru a păstra avantajele SEO ale SSR, dar și avantajele economice ale CSR.
Această practică care la prima vedere ar putea fi considerată ca desimulare (oferirea de versiuni diferite boților și vizitatorilor unei pagini web) este de fapt o idee a Google care este foarte recomandată. Putem ghici cu ușurință de ce.
Cum se testează redarea Javascript cu Oncrawl?
Există multe modalități de a diagnostica erorile SEO în implementarea JS. Folosind Oncrawl, veți putea testa automat toate paginile dvs. fără a fi nevoie să faceți nicio comparație manuală.
Oncrawl poate accesa cu crawlere un site rulând javascript pe partea client. Ideea este de a lansa două accesări cu crawlere și de a genera o comparație între:
- O accesare cu crawlere cu redarea JS activată
- Un acces cu crawlere cu redarea JS dezactivată
Apoi, pentru a măsura prin mai multe valori diferențele dintre aceste două accesări cu crawlere, semn că o parte a javascript-ului nu este executată pe partea serverului.
Rețineți că, în cazul redării prealabile, a doua accesare cu crawlere trebuie efectuată cu un user-agent Google pentru a accesa cu crawlere versiunea prerandată a site-ului.
Acest test se poate face în trei pași:
- Creați profilurile de accesare cu crawlere
- Accesați cu crawlere site-ul cu fiecare profil și generați un acces cu crawlere peste crawlere
- Analizați rezultatele
Creați profilurile de accesare cu crawlere
Profilul cu JS
Din pagina proiectului, faceți clic pe „+ Configurați un nou acces cu crawlere” .
Acest lucru vă va duce la pagina de setări de accesare cu crawlere. Se afișează setările implicite de accesare cu crawlere. Puteți fie să le modificați, fie să creați o nouă configurație de accesare cu crawlere.
Un profil de accesare cu crawlere este un set de setări care a fost salvat sub un nume pentru utilizare ulterioară.
Pentru a crea un nou profil de accesare cu crawlere, faceți clic pe butonul albastru „+ Creare profil de accesare cu crawlere” din colțul din dreapta sus.
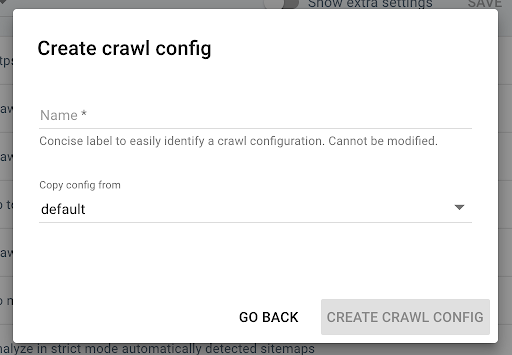
Numiți-l „Accesați cu crawlere cu JS” și copiați profilul dvs. obișnuit de accesare cu crawlere (de exemplu, implicit).
Pentru a activa JS pe acest nou profil, trebuie să afișați parametrii suplimentari care sunt ascunși implicit. Pentru a le accesa, faceți clic pe butonul „Afișați setări suplimentare” din partea de sus a paginii.
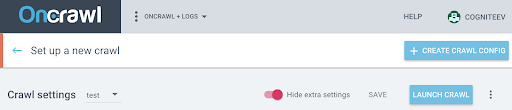
Apoi accesați Setările suplimentare și faceți clic pe „Activați” în opțiunea Crawl JS.
Notă: Nu uitați să vă adaptați viteza de accesare cu crawlere la capacitatea serverelor site-ului dvs., deoarece Oncrawl va efectua mai multe apeluri pe adresă URL pentru a executa elementele în Javascript. Viteza ideală este cea pe care serverul și arhitectura site-ului dvs. o pot suporta cel mai bine. Dacă viteza de accesare cu crawlere a OnCrawl este prea mare, este posibil ca serverul dvs. să nu poată ține pasul.
Profilul fără JS
Pentru acest al doilea profil de accesare cu crawlere, urmați aceiași pași și debifați caseta de activare JS .
Notă: este important să aveți două profiluri cu un domeniu de aplicare identic pentru ca comparația să fie semnificativă.
Dacă site-ul dvs. este în Redare pe server, treceți la pasul următor.
Dacă site-ul dvs. este în pre-rendare bazat pe roboții Google, ar trebui să ne trimiteți o solicitare de modificare a agentului de utilizator pentru accesare cu crawlere. Odată creat profilul, trimiteți-ne un mesaj prin Intercom direct în aplicație, astfel încât să putem înlocui agentul utilizator Oncrawl cu un agent utilizator bot Google.
Începeți perioada de încercare gratuită de 14 zile
 Începeți procesul
Începeți procesulLansați crawlurile și generați un Crawl over Crawl
Odată ce cele două profiluri au fost create, trebuie doar să vă accesați site-ul cu crawlere pe rând cu aceste două profiluri. Pentru a fi mai ușor, puteți utiliza funcția de programare cu crawlere.

Programați o accesare cu crawlere
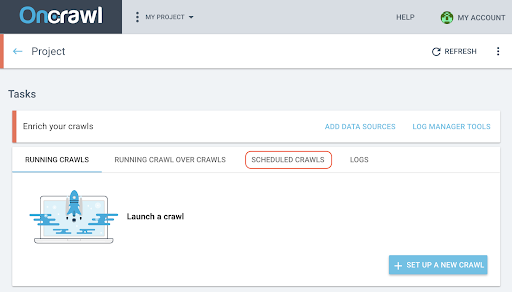
- Pe pagina proiectului, faceți clic pe fila „Crawlări programate” din partea de sus a casetei de urmărire a accesului cu crawlere.
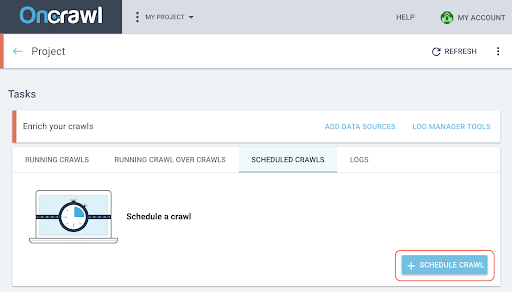
- Faceți clic pe „+ Programați accesarea cu crawlere” pentru a programa o nouă accesare cu crawlere.
- Apoi va trebui să alegeți:
- Profilul de accesare cu crawlere pe care doriți să-l utilizați pentru accesarea cu crawlere viitoare
- Frecvența de repetare a accesului cu crawlere, alegeți „Doar o dată”.
- Data, ora (în format de 24 de ore) și fusul orar (în funcție de oraș) când doriți să înceapă accesarea cu crawlere.
- Faceți clic pe „programați accesarea cu crawlere” .
Odată ce ambele analize ale accesărilor cu crawlere sunt disponibile, trebuie să generați un acces cu crawlere. 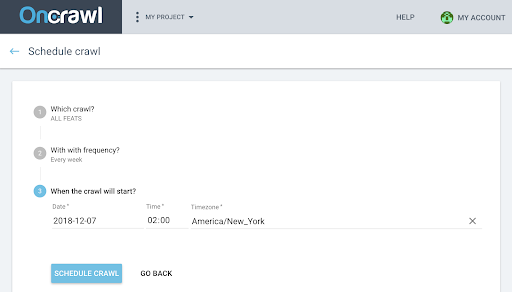
Generați un Crawl peste Crawl
- Din pagina de pornire a proiectului, lansați o crawlere peste crawlere:
- Sub „Sarcini”, faceți clic pe fila „Executarea cu crawlere peste crawleri” .
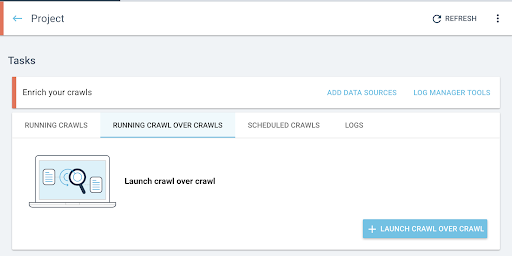
- Faceți clic pe „+ Începeți accesarea cu crawlere peste accesare cu crawlere” .
- Selectați cele două accesări cu crawlere pe care doriți să le comparați.
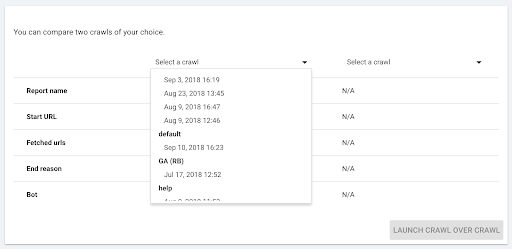
Când faceți clic pe „+ Run Crawl Over Crawl” , Oncrawl analizează diferențele dintre cele două accesări cu crawlere existente și adaugă raportul Crawl Over Crawl la rezultatele analizei celor două accesări cu crawlere.
Puteți urmări progresul acestei accesări cu crawlere peste accesare cu crawlere în fila „Începeți accesarea cu crawlere peste crawlere” de pe pagina de pornire a proiectului. Deoarece accesarea cu crawlere este deja încheiată, accesarea cu crawlere excesivă va omite starea „Crawling” și va începe direct cu „Analiză”.
Analizați rezultatele
Accesați raportul de accesare cu crawlere peste următoarele trei vizualizări:
- Structura
- Conţinut
- Legătura internă
De asemenea, puteți descărca tabloul de bord personalizat.
Ce valori să vă uitați?
Pagina accesată cu crawlere, număr mediu de cuvinte pe pagină și raport mediu text/cod
Primul indicator Pagina accesată cu crawlere vă arată imediat dacă cele două profiluri au accesat cu crawlere același număr de pagini.
Dacă diferența nu este semnificativă, puteți verifica doi indicatori pe pagină:
- Numărul mediu de cuvinte pe pagină
- Raportul mediu text/cod
Aceste două valori vor evidenția o diferență în conținutul html cu sau fără execuție javascript din partea clientului.
Dacă în medie există mai puține cuvinte pe pagină, înseamnă că o parte a conținutului paginii nu este disponibilă fără redarea JS.
În mod similar, dacă raportul dintre text este mai mic, înseamnă că o parte din conținutul paginii nu este disponibil fără redarea JS.
Raportul dintre text și cod măsoară cât de mult din conținutul unei pagini este vizibil (text) și cât este de conținut codificat (cod). Cu cât procentul raportat este mai mare, cu atât pagina conține mai mult text în comparație cu cantitatea de cod.
Depth, Inrank și Inlinks
Puteți analiza apoi valorile legate de rețeaua internă care sunt mai sensibile. Faptul că o mică parte din conținutul paginii nu este disponibilă fără redarea JS nu este neapărat problematic pentru SEO, dar dacă îți afectează rețeaua internă, consecințele asupra accesului cu crawlere a site-ului tău și a bugetului de accesare cu crawlere sunt mai importante.
Comparați adâncimea medie, Inrank-ul mediu, numărul mediu de Inlink-uri și outlink-uri interne.
O adâncime medie în creștere, o scădere medie a inrank și un număr mediu în scădere de inlink-uri și outlink-uri sunt indicatori ai existenței blocurilor mesh gestionate în JS nepre-rendate pe partea de server. Ca urmare, unele dintre linkuri nu sunt disponibile imediat pentru botul Google.
Acest lucru poate avea consecințe asupra întregului site sau a unei părți a acestuia. Apoi este necesar să studiem aceste modificări pe grupe de pagini pentru a identifica dacă unele tipuri de pagini sunt dezavantajate de această plasă javascript.
Exploratorul de date vă va permite să vă jucați cu filtrele pentru a evidenția aceste elemente.
Mergeți mai departe cu exploratorul de date și cu detaliile URL
În exploratorul de date
Când vă uitați la datele Crawl over Crawl în exploratorul de date, veți vedea două coloane de adrese URL: una pentru adresele URL Crawl 1 și una pentru URL-urile Crawl 2.
Puteți adăuga apoi fiecare dintre valorile menționate mai sus (pagini accesate cu crawlere, număr de cuvinte, raport text-cod, adâncime, inrank, legături) de două ori fiecare pentru a afișa valoarea Crawl 1 și Crawl 2 una lângă alta.
Folosind filtrele, veți putea identifica adresele URL cu cele mai mari diferențe.
detalii URL
Dacă ați identificat diferențe între versiunea SSR și/sau prerendată și versiunea redată pe partea clientului, atunci va trebui să intrați în mai multe detalii pentru a înțelege ce elemente JS nu sunt optimizate pentru SEO.
Făcând clic pe o pagină din exploratorul de date, comutați la detaliile URL și apoi puteți vizualiza codul sursă așa cum este văzut de Oncraw făcând clic pe fila „Afișați sursa”.
Apoi puteți prelua codul HTML făcând clic pe Copiați sursa HTML.
În stânga sus, puteți trece de la o accesare cu crawlere la alta pentru a prelua cealaltă versiune a codului.
Folosind un instrument de comparare a codului html, puteți compara cele două versiuni ale unei pagini, cu JS și fără JS executate pe partea clientului. În rest, depinde de tine!