
O introducere în crawler-ul web
Publicat: 2016-03-08Când vorbesc cu oamenii despre ceea ce fac și despre ce este SEO, de obicei o înțeleg destul de repede sau acționează așa cum o fac. O structură bună a site-ului, un conținut bun, backlink-uri bune de susținere. Dar uneori, devine ceva mai tehnic și ajung să vorbesc despre motoarele de căutare care vă accesează site-ul web și de obicei le pierd...
De ce accesați cu crawlere un site web?
Crawling-ul web a început ca o cartografiere a internetului și a modului în care fiecare site web a fost conectat unul la altul. A fost folosit și de motoarele de căutare pentru a descoperi și indexa noi pagini online. Crawlerele web au fost, de asemenea, folosite pentru a testa vulnerabilitatea site-ului web, testând un site web și analizând dacă a fost detectată vreo problemă.
Acum puteți găsi instrumente care vă accesează cu crawlere site-ul web pentru a vă oferi informații. De exemplu, OnCrawl furnizează date referitoare la conținutul dvs. și SEO la fața locului sau Majestic, care oferă informații despre toate linkurile care trimit către o pagină.
Crawlerele sunt folosite pentru a colecta informații care pot fi apoi utilizate și procesate pentru a clasifica documentele și pentru a oferi informații despre datele colectate.
Construirea unui crawler este accesibilă oricui cunoaște un pic de cod. Cu toate acestea, realizarea unui crawler eficient este mai dificilă și necesită timp.
Cum functioneazã ?
Pentru a accesa cu crawlere un site web sau web, mai întâi aveți nevoie de un punct de intrare. Roboții trebuie să știe că site-ul dvs. există, pentru a putea veni să-l arunce o privire. În vremuri, ați fi trimis site-ul dvs. la motoarele de căutare pentru a le spune că site-ul dvs. era online. Acum puteți construi cu ușurință câteva link-uri către site-ul dvs. și Voila sunteți la curent!
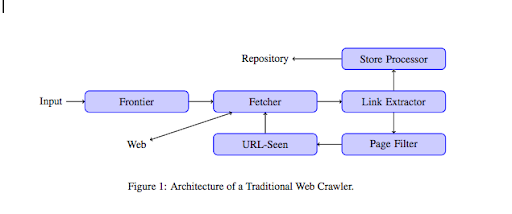
Odată ce un crawler ajunge pe site-ul dvs. web, acesta vă analizează întregul conținut rând cu linie și urmărește fiecare dintre linkurile pe care le aveți, fie că sunt interne sau externe. Și așa mai departe până când ajunge pe o pagină fără mai multe linkuri sau dacă întâlnește erori precum 404, 403, 500, 503.
Dintr-un punct de vedere mai tehnic, un crawler lucrează cu un seed (sau o listă) de URL-uri. Aceasta este transmisă unui Fetcher care va prelua conținutul unei pagini. Acest conținut este apoi mutat într-un extractor de linkuri care va analiza HTML și va extrage toate linkurile. Aceste link-uri sunt trimise atât către un procesor Store care, după cum spune și numele, le va stoca. Aceste adrese URL vor trece, de asemenea, printr-un filtru de pagină care va trimite toate linkurile interesante către un modul văzut de URL. Acest modul detectează dacă adresa URL a fost deja văzută sau nu. Dacă nu, este trimis către Fetcher care va prelua conținutul paginii și așa mai departe.
Rețineți că unele conținuturi sunt imposibil de accesat cu crawlere pentru păianjeni, cum ar fi Flash. Javascript este acum accesat cu crawlere corect de GoogleBot, dar din când în când nu accesează cu crawlere nimic. Imaginile nu sunt conținut pe care Google îl poate accesa cu crawlere, dar a devenit suficient de inteligent pentru a începe să le înțeleagă!
Dacă roboților nu li se spune contrariul, ei vor târâi totul. Aici fișierul robots.txt devine foarte util. Le spune crawler-urilor (poate fi specific pentru fiecare crawler, adică GoogleBot sau MSN Bot – aflați mai multe despre roboți aici) ce pagini nu pot accesa cu crawlere. Să presupunem, de exemplu, că aveți navigare folosind fațete, s-ar putea să nu doriți ca roboții să le acceseze cu crawlere pe toate, deoarece au puțină valoare adăugată și vor folosi bugetul de accesare cu crawlere. Folosirea acestei linii simple te va ajuta să împiedici orice robot să se târască
Agent utilizator: *
Nu permiteți: /folder-a/
Acest lucru le spune tuturor roboților să nu acceseze cu crawlere folderul A.
Agent utilizator: GoogleBot
Nu permiteți: /repertoriu-b/
Pe de altă parte, acesta specifică faptul că numai Google Bot nu poate accesa cu crawlere folderul B.
De asemenea, puteți utiliza indicația în HTML care le spune roboților să nu urmeze un anumit link folosind eticheta rel="nofollow". Unele teste au arătat că chiar și utilizarea etichetei rel="nofollow” pe un link nu va bloca Googlebot să-l urmărească. Acest lucru este în contradicție cu scopul său, dar va fi util în alte cazuri.
[Studiu de caz] Creșteți vizibilitatea prin îmbunătățirea accesării cu crawlere a site-ului web pentru Googlebot
 Citiți studiul de caz
Citiți studiul de caz
Ați menționat bugetul de accesare cu crawlere, dar care este acesta?
Să presupunem că aveți un site web care a fost descoperit de motoarele de căutare. Ei vin în mod regulat pentru a vedea dacă ați făcut actualizări pe site-ul dvs. web și ați creat pagini noi.
Fiecare site web are propriul buget de accesare cu crawlere, în funcție de mai mulți factori, cum ar fi numărul de pagini pe care le are site-ul dvs. web și sănătatea sa (dacă are multe erori, de exemplu). Vă puteți face cu ușurință o idee rapidă despre bugetul de accesare cu crawlere, conectându-vă la Search Console.
Bugetul dvs. de accesare cu crawlere va fixa numărul de pagini pe care un robot le accesează cu crawlere pe site-ul dvs. de fiecare dată când vine pentru o vizită. Este legat proporțional de numărul de pagini pe care le aveți pe site-ul dvs. și a fost deja accesat cu crawlere. Unele pagini sunt accesate cu crawlere mai des decât altele, mai ales dacă sunt actualizate în mod regulat sau dacă sunt legate de pagini importante.
De exemplu, casa dvs. este punctul dvs. principal de intrare, care va fi accesat cu târăre foarte des. Dacă aveți un blog sau o pagină de categorie, acestea vor fi accesate cu crawlere dacă sunt legate la navigarea principală. De asemenea, un blog va fi accesat cu crawlere des, deoarece este actualizat în mod regulat. O postare de blog poate fi accesată cu crawlere des când a fost publicată pentru prima dată, dar după câteva luni probabil că nu va fi actualizată.
Cu cât o pagină este accesată cu crawlere mai des, cu atât un robot consideră că este mai importantă în comparație cu altele. Acesta este momentul în care trebuie să începeți să lucrați la optimizarea bugetului de accesare cu crawlere.
Optimizarea bugetului de accesare cu crawlere
Pentru a vă optimiza bugetul și a vă asigura că paginile dvs. cele mai importante primesc atenția pe care o merită, puteți să vă analizați jurnalele serverului și să vedeți cum este accesat cu crawlere site-ul dvs.:
- Cât de des sunt accesate cu crawlere paginile tale de top
- Puteți vedea pagini mai puțin importante care sunt accesate cu crawlere mai mult decât altele mai importante?
- Roboții primesc adesea o eroare 4xx sau 5xx atunci când vă accesează cu crawlere site-ul?
- Întâlnesc roboții vreo capcană de păianjen? (Matthew Henry a scris un articol grozav despre ei)
Analizând jurnalele dvs., veți vedea care pagini considerați mai puțin importante sunt accesate cu crawlere. Apoi, trebuie să săpați mai adânc în structura dvs. internă a legăturilor. Dacă este accesat cu crawlere, trebuie să aibă o mulțime de link-uri care să indice către el.
De asemenea, puteți lucra la remedierea tuturor acestor erori (4xx și 5xx) cu OnCrawl. Va îmbunătăți accesul cu crawlere, precum și experiența utilizatorului, este un caz câștigător.
Crawling VS Scraping?
Crawlingul și răzuirea sunt două lucruri diferite care sunt folosite în scopuri diferite. Accesarea cu crawlere a unui site web înseamnă aterizarea pe o pagină și urmărirea linkurilor pe care le găsiți când scanați conținutul. Un crawler se va muta apoi la o altă pagină și așa mai departe.
Scraping, pe de altă parte, înseamnă scanarea unei pagini și colectarea de date specifice din pagină: etichetă de titlu, meta description, etichetă h1 sau o anumită zonă a site-ului dvs., o astfel de listă de prețuri. Scrapers acționează de obicei ca „oameni”, ei vor ignora orice reguli din fișierul robots.txt, vor înregistra formulare și vor folosi un user-agent de browser pentru a nu fi detectați.
Crawlerele motoarelor de căutare acționează de obicei ca scrapper și trebuie să colecteze date pentru a le procesa pentru algoritmul lor de clasare. Ei nu caută date specifice în comparație cu scrapper, ci doar folosesc toate datele disponibile pe pagină și chiar mai mult (timpul de încărcare este ceva ce nu poți obține dintr-o pagină). Crawlerele motoarelor de căutare se vor identifica întotdeauna ca crawler-uri, astfel încât proprietarul unui site web să știe când au vizitat ultima dată site-ul web. Acest lucru poate fi foarte util atunci când urmăriți activitatea reală a utilizatorului.
Așa că acum știi puțin mai multe despre crawling, cum funcționează și de ce este important, următorul pas este să începi să analizezi jurnalele serverului. Acest lucru vă va oferi informații profunde despre modul în care roboții interacționează cu site-ul dvs. web, ce pagini le vizitează des și câte erori întâmpină în timpul accesării site-ului dvs. web.
Pentru mai multe informații tehnice și istorice despre web crawler, puteți citi „O scurtă istorie a crawlerelor web”