
Cum se definește bugetul de accesare cu crawlere?
Publicat: 2016-09-14Cu toții vorbim despre asta ca SEO, dar cum funcționează de fapt bugetul de crawl? Știm că numărul de pagini pe care motoarele de căutare le accesează cu crawlere și indexează atunci când vizitează site-urile web ale clienților noștri are o corelație cu succesul lor în căutarea organică, dar este întotdeauna mai bine să ai un buget de accesare cu crawlere mai mare?
Ca orice lucru cu Google, nu cred că relația dintre bugetul de accesare cu crawlere a site-urilor dvs. și performanța clasamentului/SERP este 100% simplă, depinde de o serie de factori.
De ce este important bugetul de accesare cu crawlere? Din cauza actualizării Cofeinei din 2010. Cu această actualizare Google a reconstruit modul în care a indexat conținutul, cu indexare incrementală. Introducând sistemul „percolator”, au eliminat „gâtul de sticlă” al paginilor care se indexează.
Cum stabilește Google bugetul de accesare cu crawlere?
Totul ține de PageRank, Fluxul de citare și Fluxul de încredere.
De ce nu am menționat Autoritatea de domeniu? Sincer, în opinia mea, este una dintre cele mai greșit utilizate și neînțelese metrice disponibile pentru SEO și marketerii de conținut care, își are locul, dar mult prea multe agenții și SEO-i pun prea multă preț, mai ales atunci când construiesc link-uri.
PageRank este acum, desigur, învechit, mai ales că au scăpat bara de instrumente, așa că totul este despre raportul de încredere al unui site (Ratio de încredere = Flux de încredere/Flux de citare). În esență, domeniile mai puternice au bugete de accesare cu crawlere mai mari, așa că cum identificați activitatea botului Google pe site-ul dvs. web și, mai important, identificați orice probleme de accesare cu crawlere a botului? Fișierele jurnal ale serverului.
Acum știm cu toții că, pentru a indica paginile botului Google pe care le-am indexat (și clasificăm), utilizăm structura internă de legături și le păstrăm aproape de domeniul rădăcină, nu de 5 subfoldere de-a lungul URL-ului. Dar cum rămâne cu problemele mai tehnice? Cum ar fi risipa de buget cu crawl, capcanele bot sau dacă Google încearcă să completeze formulare pe site (se întâmplă).
Identificarea activității crawler-ului
Pentru a face acest lucru, trebuie să puneți mâna pe unele fișiere jurnal de server. Poate fi necesar să le solicitați de la clientul dvs. sau le puteți descărca direct de la compania de găzduire.
Ideea din spatele acestui lucru este că doriți să încercați să găsiți o înregistrare a botului Google care lovește site-ul dvs. - dar, deoarece acesta nu este un eveniment programat, poate fi necesar să obțineți date de câteva zile. Există diverse programe software disponibile pentru a analiza aceste fișiere.
Mai jos este un exemplu de accesare a unui server Apache:
50.56.92.47 – – [31/May/2012:12:21:17 +0100] „GET” – „/wp-content/themes/wp-theme/help.php” – „404” „-” „Mozilla/ 5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)” – www.hit-example.com
De aici puteți utiliza instrumente (cum ar fi OnCrawl) pentru a analiza fișierele jurnal și a identifica probleme precum accesarea cu crawlere a paginilor PPC de către Google sau solicitări infinite GET către scripturi JSON – ambele putând fi remediate în fișierul Robots.txt.
Când este o problemă bugetul de accesare cu crawlere?
Bugetul de accesare cu crawlere nu este întotdeauna o problemă, dacă site-ul dvs. are o mulțime de adrese URL și are o alocare proporțională a „crawlerilor”, sunteți bine. Dar ce se întâmplă dacă site-ul tău are 200.000 de adrese URL și Google accesează cu crawlere doar 2.000 de pagini de pe site-ul tău în fiecare zi? Ar putea dura până la 100 de zile până când Google observă adrese URL noi sau reîmprospătate – acum aceasta este o problemă.
Un test rapid pentru a vedea dacă bugetul de accesare cu crawlere reprezintă o problemă este să utilizați Google Search Console și numărul de adrese URL de pe site pentru a calcula „numărul de accesare cu crawlere”.
- Mai întâi trebuie să determinați câte pagini există pe site-ul dvs., puteți face acest lucru făcând un site: căutare, de exemplu, oncrawl.com are aproximativ 512 pagini în index:
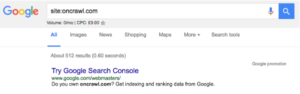

- În al doilea rând, trebuie să accesați contul Google Search Console și să accesați Crawl, apoi Statistici despre accesare cu crawlere. Dacă contul dvs. GSC nu a fost configurat corect, este posibil să nu aveți aceste date.
- Al treilea pas este să luați numărul mediu „Pagini accesate cu crawlere pe zi” (cel din mijloc) și numărul total de adrese URL de pe site-ul dvs. și să le împărțiți:
Numărul total de pagini de pe site/Media pagini accesate cu crawlere pe zi = X
Dacă X este mai mare de 10, trebuie să vă uitați la optimizarea bugetului de accesare cu crawlere. Dacă este mai puțin de 5, bravo. Nu trebuie să citiți mai departe.
Optimizarea capacității dvs. de „buget de accesare cu crawlere”.
Poți avea cel mai mare buget de crawl de pe internet, dar dacă nu știi cum să-l folosești, nu are valoare.
Da, este un clișeu, dar este adevărat. Dacă Google accesează cu crawlere toate paginile site-ului dvs. și constată că marea majoritate dintre ele sunt duplicate, goale sau se încarcă atât de lent încât provoacă erori de timeout, bugetul dvs. poate de asemenea să fie mic.
Pentru a profita la maximum de bugetul de accesare cu crawlere (chiar și fără acces la fișierele jurnal ale serverului), trebuie să vă asigurați că faceți următoarele:
Eliminați paginile duplicate
Adesea, pe site-urile de comerț electronic, instrumente precum OpenCart pot crea mai multe adrese URL pentru același produs, am văzut exemple ale aceluiași produs pe 4 URL-uri cu subdosare diferite între destinație și rădăcină.
Nu doriți ca Google să indexeze mai mult de o versiune a fiecărei pagini, așa că asigurați-vă că aveți etichete canonice care indică Google către versiunea corectă.
Rezolvați linkurile rupte
Utilizați Google Search Console sau software de crawling și găsiți toate linkurile interne și externe rupte de pe site-ul dvs. și remediați-le. Utilizarea 301-urilor este grozavă, dar dacă sunt link-uri de navigare sau link-uri de subsol care sunt întrerupte, trebuie doar să schimbați adresa URL către care indică, fără a vă baza pe un 301.
Nu scrie pagini subțiri
Evitați să aveți multe pagini pe site-ul dvs. care oferă puțină sau deloc valoare utilizatorilor sau motoarelor de căutare. Fără context, Google îi este greu să clasifice paginile, ceea ce înseamnă că nu contribuie cu nimic la relevanța generală a site-ului și sunt doar pasageri care preiau bugetul de accesare cu crawlere.
Eliminați lanțurile de redirecționare 301
Redirecționările în lanț sunt inutile, dezordonate și neînțelese. Lanțurile de redirecționare vă pot deteriora bugetul de accesare cu crawlere în mai multe moduri. Când Google ajunge la o adresă URL și vede un 301, nu îl urmează întotdeauna imediat, ci adaugă noua adresă URL la o listă și apoi o urmează.
De asemenea, trebuie să vă asigurați că sitemap-ul dvs. XML (și harta site-ului HTML) este corectă și, dacă site-ul dvs. este multilingv, asigurați-vă că aveți sitemap pentru fiecare limbă a site-ului. De asemenea, trebuie să implementați arhitectura inteligentă a site-ului, arhitectura URL și să vă accelerați paginile. Punerea site-ului dvs. în spatele unui CDN precum CloudFlare ar fi, de asemenea, benefică.
TL;DR:
Accesați cu crawlere bugetul ca orice buget este o oportunitate, vă folosiți, teoretic, bugetul pentru a câștiga timp pe care Googlebot, Bingbot și Slurp îl petrec pe site-ul dvs., este important să profitați la maximum de acest timp.
Optimizarea bugetului de accesare cu crawlere nu este ușoară și, cu siguranță, nu este un „câștig rapid”. Dacă aveți un site mic sau un site de dimensiuni medii care este bine întreținut, probabil că sunteți bine. Dacă aveți un site uriaș cu zeci de mii de URL-uri și fișierele jurnal de server vă trec peste cap - poate fi timpul să apelați la experți.