
Cum să prognozați veniturile din trafic organic fără marcă pe baza poziției URL cu Python
Publicat: 2022-05-24Ce este prognoza SEO?
Prognoza SEO, sau estimarea traficului organic, este procesul de utilizare a datelor propriului site sau a datelor de la terți pentru a estima viitorul trafic organic al site-ului dvs., veniturile SEO și rentabilitatea investiției SEO. Această estimare poate fi calculată folosind multe metode diferite pe baza datelor noastre.
În acest tutorial, dorim să anticipăm veniturile noastre organice fără marcă și traficul organic fără marcă pe baza pozițiilor URL-urilor noastre și a veniturilor lor actuale. Acest lucru ne poate ajuta, în calitate de SEO, să obținem mai multă acceptare de la alte părți interesate: de la un buget lunar, trimestrial sau anual crescut la mai multe ore de lucru din partea echipei de produs și de dezvoltare.
Rețineți că acest tutorial nu este aplicabil numai traficului organic fără marcă; făcând câteva modificări și cunoscând Python, îl puteți folosi pentru a estima traficul paginilor țintă.
Ca rezultat, putem produce o foaie de calcul Google ca imaginea de mai jos.
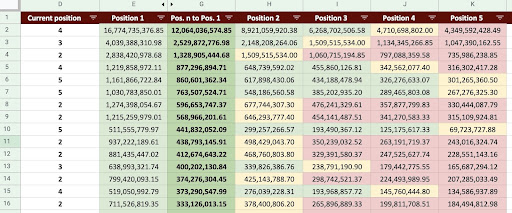
Imagine Google Sheets
Prognoza traficului SEO fără marcă
Prima întrebare pe care o puteți pune după ce ați citit introducerea este „De ce să calculați traficul organic fără marcă?”.
Să luăm în considerare o companie precum Amazon. Când doriți să cumpărați o carte sau o mască, veți căuta pur și simplu „cumpărați masca Amazon”.
Brandurile sunt adesea în fruntea mea și atunci când vrei să cumperi ceva, preferința ta este să cumperi lucrurile de care ai nevoie de la aceste companii. În fiecare industrie, există companii de marcă care afectează comportamentul utilizatorilor în căutările pe Google.
Dacă ar fi să verificăm datele Google Search Console (GSC) ale Amazon, probabil am descoperi că primește mult trafic din interogări de marcă și, de cele mai multe ori, primul rezultat al interogărilor de marcă este site-ul mărcii respective.
Ca SEO, ca și mine, probabil că ați auzit de multe ori că „Numai marca noastră ne ajută SEO!” Cum putem spune „Nu, nu este cazul” și să arătăm traficul și veniturile interogărilor care nu sunt legate de marcă?
Este și mai complicat să dovedești acest lucru, deoarece știm că algoritmii Google sunt atât de complexi și că este dificil să se separe în mod distinct căutările cu marcă de cele fără marcă. Dar acesta este ceea ce face ca ceea ce facem ca SEO este cu atât mai important.
În acest tutorial, vă voi arăta cum să faceți distincția între cele două – de marcă și fără marcă – și vă voi arăta cât de puternic poate fi SEO.
Chiar dacă compania dvs. nu are o marcă, puteți câștiga foarte mult din acest articol: puteți afla cum să estimați datele organice ale site-ului dvs.
ROI SEO bazat pe estimarea traficului
Indiferent unde te afli sau ce faci, există o limitare a resurselor; fie că este vorba de un buget sau pur și simplu de numărul de ore din ziua de lucru. A ști cum să alocați cel mai bine resursele joacă un rol major în rentabilitatea investiției (ROI) generală și SEO.
Un CMO, un VP de marketing sau un agent de marketing de performanță au toate KPI diferiți și necesită resurse diferite pentru a-și îndeplini obiectivele. Cel mai bun mod de a vă asigura că obțineți ceea ce aveți nevoie este să dovediți necesitatea acestuia, demonstrând profiturile pe care le va aduce companiei. SEO ROI nu este diferit. Când vine perioada de alocare a bugetului din an și echipa dvs. dorește să solicite un buget mai mare, estimarea rentabilității investiției SEO vă poate oferi avantaj în negocieri. Odată ce ați calculat estimarea traficului fără marcă, puteți evalua mai bine bugetul necesar pentru a obține rezultatele dorite.
Efectul predicției SEO asupra strategiei SEO
După cum știm, la fiecare 3 sau 6 luni ne revizuim strategia SEO și o ajustăm pentru a obține cele mai bune rezultate posibile. Dar ce se întâmplă când nu știi unde este cel mai mare profit pentru compania ta? Puteți lua decizii, dar acestea nu vor fi la fel de eficiente ca deciziile luate atunci când aveți o vedere mai cuprinzătoare asupra traficului site-ului.
Estimarea veniturilor din trafic organic fără marcă poate fi combinată cu paginile de destinație și segmentarea interogărilor pentru a oferi o imagine de ansamblu care vă va ajuta să dezvoltați strategii mai bune ca manager SEO sau strateg SEO.
Diferite moduri de a prognoza traficul organic
Există o mulțime de metode și scripturi publice diferite în comunitatea SEO pentru a prezice viitorul trafic organic.
Unele dintre aceste metode includ:
- Prognoza organica a traficului pe intreg site-ul
- Prognoza organică a traficului pe anumite pagini (blog, produse, categorii, etc) sau o singură pagină
- Prognoza organică a traficului pentru anumite interogări (interogările conțin „cumpără”, „cum se face”, etc.) sau o interogare
- Prognoza organică a traficului pentru anumite perioade (în special pentru evenimente sezoniere)
Metoda mea este pentru anumite pagini și intervalul de timp este de o lună.
[Studiu de caz] Stimularea creșterii pe noi piețe cu SEO pe pagină
 Citiți studiul de caz
Citiți studiul de cazCum se calculează veniturile organice din trafic
Modul precis se bazează pe datele dvs. Google Analytics (GA). Dacă site-ul dvs. este nou-nouț, va trebui să utilizați instrumente terțe. Prefer să evit să folosesc astfel de instrumente atunci când aveți propriile date.
Rețineți că va trebui să testați datele terță parte pe care le utilizați cu unele dintre datele reale ale paginii dvs. pentru a găsi eventuale erori în datele lor.
Cum se calculează veniturile din traficul SEO fără marcă cu Python
Până acum, am acoperit o mulțime de concepte teoretice cu care ar trebui să fim familiarizați pentru a înțelege mai bine diferitele aspecte ale predicției noastre organice de trafic și venituri. Acum, ne vom scufunda în partea practică a acestui articol.
În primul rând, vom începe prin a calcula curba CTR. În articolul meu despre curba CTR despre Oncrawl, explic două metode diferite și, de asemenea, alte metode pe care le puteți utiliza făcând câteva modificări în codul meu. Vă recomand să citiți mai întâi articolul despre curba de clic; vă oferă informații despre acest articol.
În acest articol, modific unele părți ale codului meu pentru a obține rezultatele specifice pe care le dorim în estimarea traficului. Apoi, vom obține datele noastre de la GA și vom folosi dimensiunea venit GA pentru a estima veniturile noastre.
Estimarea veniturilor din trafic organic non-marcă cu Python: Noțiuni introductive
Puteți rula acest cod singur, fără să cunoașteți niciun Python. Cu toate acestea, prefer să știți puțin despre sintaxa Python și cunoștințele de bază despre bibliotecile Python pe care le voi folosi în acest cod de prognoză. Acest lucru vă va ajuta să înțelegeți mai bine codul meu și să-l personalizați într-un mod care vă este util.
Pentru a rula acest cod, voi folosi Visual Studio Code cu extensia Python de la Microsoft, care include extensia „Jupyter”. Dar, puteți utiliza notebook-ul Jupyter în sine.
Pentru întregul proces, trebuie să folosim aceste biblioteci Python:
- Numpy
- panda
- Intrigator
De asemenea, vom importa câteva biblioteci standard Python:
- JSON
- pprint
# Importul bibliotecilor de care avem nevoie pentru procesul nostru import json din pprint import pprint import numpy ca np importa panda ca pd import plotly.express ca px
Pasul 1: Calcularea curbei CTR relative (Curba de clic relativ)
În primul pas, dorim să ne calculăm curba CTR relativă. Dar, care este curba CTR relativă?
Care este curba CTR relativă?
Să începem mai întâi prin a vorbi despre „curba CTR absolută”. Când calculăm curba CTR absolută, spunem că CTR-ul median (sau CTR-ul mediu) al primei poziții este de 36%, iar a doua poziție este de 20% și așa mai departe.
În curba CTR relativă, instant de procent, împărțim mediana fiecărei poziții la CTR-ul primei poziții. De exemplu, curba CTR relativă a primei poziții ar fi 0,36 / 0,36 = 1, a doua ar fi 0,20 / 0,36 = 0,55 și așa mai departe.
Poate te întrebi de ce este util să calculezi asta? Gândiți-vă la o pagină clasată pe poziția unu, care are 44% CTR. Dacă această pagină ajunge în poziția a doua, curba CTR nu scade la 20%, este mai probabil ca CTR să scadă la 44% * 0,55 = 24,2%.
1. Obținerea de date de trafic organic de marcă și fără marcă de la GSC
Pentru procesul nostru de calcul, trebuie să obținem datele noastre de la GSC. Prima dată, toate datele se vor baza pe interogări de marcă, iar data viitoare, toate datele se vor baza pe interogări fără marcă.
Pentru a obține aceste date, puteți folosi diferite metode: din scripturi Python sau din programul de completare „Search Analytics for Sheets” Google Sheets. Voi folosi exploratorul GSC API.
Rezultatele acestor date sunt două fișiere JSON care arată performanța fiecărei pagini. Un fișier JSON care arată performanța paginilor de destinație pe baza interogărilor de marcă, iar celălalt arată performanța paginilor de destinație pe baza interogărilor fără marcă.
Pentru a obține date din GSC API Explorer, urmați acești pași:
- Accesați https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maximizați exploratorul API care se află în colțul din dreapta sus al paginii.
- În câmpul „
siteUrl”, introduceți numele de domeniu. De exemplu, „https://www.example.com” sau „ http:http://your-domain.com”. - În corpul cererii, mai întâi trebuie să definim parametrii „
startDate” și „endDate”. Preferința mea sunt ultimele 30 de zile. - Apoi adăugăm „
dimensions” și selectăm „page” pentru această listă. - Acum adăugăm „
dimensionFilterGroups” pentru a filtra interogările noastre. O dată pentru cele de marcă și o a doua pentru interogări fără marcă. - La final, ne-am setat „
rowLimit” la 25.000. Dacă paginile site-ului dvs. care înregistrează trafic organic în fiecare lună sunt mai mari de 25.000, trebuie să vă modificați corpul solicitării. - După efectuarea fiecărei solicitări, salvați răspunsul JSON. Pentru performanța de marcă, salvați fișierul JSON ca „
branded_data.json” iar pentru performanța fără marcă, salvați fișierul JSON ca „non_branded_data.json”.
După ce înțelegem parametrii din corpul cererii noastre, singurul lucru pe care trebuie să-l faceți este să copiați și să lipiți sub corpurile solicitării. Luați în considerare înlocuirea denumirilor dvs. de mărci cu „ brand variation names ”.
Trebuie să separați numele mărcilor cu o conductă sau „ | ”. De exemplu, „ amazon|amazon.com|amazn ”.
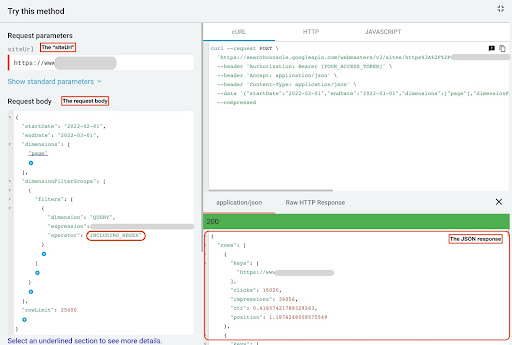
GSC API Explorer
Corpul cererii de marcă:
{
„startDate”: „2022-02-01”,
„endDate”: „2022-03-01”,
"dimensiuni": [
"pagină"
],
„dimensionFilterGroups”: [
{
"filtre": [
{
„dimensiune”: „QUERY”,
"expression": "nume variații de mărci",
„operator”: „INCLUDING_REGEX”
}
]
}
],
„rowLimit”: 25000
}
Organism de solicitare fără marcă:
{
„startDate”: „2022-02-01”,
„endDate”: „2022-03-01”,
"dimensiuni": [
"pagină"
],
„dimensionFilterGroups”: [
{
"filtre": [
{
„dimensiune”: „QUERY”,
"expression": "nume variații de mărci",
„operator”: „EXCLUDING_REGEX”
}
]
}
],
„rowLimit”: 25000
}
2. Importarea datelor în notebook-ul nostru Jupyter și extragerea directoarelor site-ului
Acum, trebuie să ne încărcăm datele în notebook-ul nostru Jupyter pentru a le putea modifica și a extrage ceea ce dorim din el. Să reluăm de unde am rămas mai sus.
Pentru a încărca date de marcă, trebuie să executați acest bloc de cod:
# Crearea unui DataFrame pentru performanța adreselor URL ale site-ului web pe marcă și interogările de marcă
cu open("./branded_data.json") ca fișier_json:
branded_data = json.loads(json_file.read())["rânduri"]
branded_df = pd.DataFrame(branded_data)
# Redenumirea coloanei „chei” în coloana „pagină de destinație” și conversia listei „pagină de destinație” într-o adresă URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["landing page"] = branded_df["landing page"].aply(lambda x: x[0])
Pentru performanța paginilor de destinație fără marcă, va trebui să executați acest bloc de cod:
# Crearea unui DataFrame pentru performanța URL-urilor site-ului web în interogările fără marcă
cu open("./non_branded_data.json") ca fișier_json:
non_branded_data = json.loads(json_file.read())["rânduri"]
non_branded_df = pd.DataFrame(non_branded_data)
# Redenumirea coloanei „chei” în coloana „pagină de destinație” și conversia listei „pagină de destinație” într-o adresă URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["landing page"] = non_branded_df["landing page"].aplica(lambda x: x[0])
Ne încărcăm datele, apoi trebuie să definim numele site-ului nostru pentru a-i extrage directoarele.
# Definiți numele site-ului dvs. între ghilimele. De exemplu, „https://www.example.com/” sau „http://mydomain.com/” SITE_NAME = „https://www.your_domain.com/”
Trebuie doar să extragem directoarele din performanța fără marcă.
# Obținerea fiecărui director al paginii de destinație (URL).
non_branded_df[„director”] = non_branded_df[„pagină de destinație”].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Apoi tipărim directoarele pentru a le selecta care sunt importante pentru acest proces. Poate doriți să selectați toate directoarele pentru a obține o perspectivă mai bună asupra site-ului dvs.

# Pentru a obține toate directoarele în ieșire, trebuie să manipulăm opțiunile Pandas
pd.set_option("display.max_rows", Nici unul)
# Directoare de site-uri web
non_branded_df[„director”].value_counts()
Aici, puteți insera orice directoare sunt importante pentru dvs.
""" Alegeți care directoare sunt importante pentru obținerea curbei CTR.
Introduceți directoarele în variabila „important_directories”.
De exemplu, „product,tag,product-category,mag”. Separați valorile directorului cu virgulă.
"""
IMPORTANT_DIRECTORIES = „directoarele_importante”
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. Etichetarea paginilor pe baza poziției lor și calcularea curbei CTR relative
Acum trebuie să ne etichetăm paginile de destinație în funcție de poziția lor. Facem acest lucru, deoarece trebuie să calculăm curba CTR relativă pentru fiecare director pe baza poziției paginii de destinație.
# Etichetarea pozițiilor fără marcă
pentru i în interval (1, 11):
non_branded_df.loc[
(non_branded_df["poziție"] >= i) & (non_branded_df["poziție"] <i + 1),
„etichetă de poziție”,
] = i
Apoi, grupăm paginile de destinație în funcție de directorul lor.
# Gruparea paginilor de destinație în funcție de valoarea lor „director”. non_brand_grouped_df = non_branded_df.groupby([„director”])
Să definim funcția pentru a calcula curba CTR relativă.
def each_dir_relative_ctr_curve(dir_df, cheie):
"""Funcția calculează fiecare curbă CTR relativă IMPORTANT_DIRECTORIES.
"""
# Gruparea „non_brand_grouped_df” pe baza valorii „poziție etichetă”.
dir_grouped_df = dir_df.groupby([„etichetă de poziție”])
# O listă pentru salvarea CTR mediană a fiecărei poziții
median_ctr_list = []
# Stocarea fiecărui director ca o cheie și este „median_ctr_list” ca valoare
directories_median_ctr = {}
# Buclă peste fiecare grup „dir_grouped_df”.
pentru i în interval (1, 11):
# O încercare, cu excepția gestionării acelor situații în care un director, de exemplu, nu are date pentru poziția 4
încerca:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
cu exceptia:
median_ctr_list.append(0)
# Calcularea curbei CTR relative
directories_median_ctr[cheie] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
return directories_median_ctr
După ce definim funcția, o rulăm.
# Buclă peste directoare și executarea funcției „each_dir_relative_ctr_curve”
directories_median_ctr_dict = dict()
pentru cheie, articol din non_brand_grouped_df:
dacă introduceți IMPORTANT_DIRECTORIES:
directories_median_ctr_dict.update(each_dir_relative_ctr_curve(articol, cheie))
pprint(directories_median_ctr_dict)
Acum, vom încărca paginile noastre de destinație, de marcă și fără marcă, performanța și vom calcula curba CTR relativă pentru datele noastre non-marcă. De ce facem acest lucru numai pentru date care nu sunt legate de marcă? Pentru că vrem să anticipăm traficul organic și veniturile non-marcă.
Pasul 2: estimarea veniturilor din trafic organic fără marcă
În acest al doilea pas, vom afla cum să ne recuperăm datele privind veniturile și să ne anticipăm veniturile.
1. Fuzionarea datelor organice de marcă și fără marcă
Acum, vom îmbina datele noastre de marcă și cele fără marcă. Acest lucru ne va ajuta să calculăm procentul de trafic organic fără marcă pe fiecare pagină de destinație în comparație cu tot traficul.
# „main_df” este o combinație de „date întregului site” și „date non-brand” DataFrames.
# Folosind acest DataFrame, puteți afla unde sunt cele mai multe clicuri și afișări
# provin din interogări care nu sunt de marcă.
main_df = non_branded_df.merge(
branded_df, on="landing page", sufixe=("_non_brand", "_branded")
)
Apoi modificăm coloanele pentru a le elimina pe cele inutile.
# Modificarea coloanelor „main_df” la cele de care avem nevoie
main_df = main_df[
[
"pagina de destinație",
„clicks_non_brand”,
"ctr_non_brand",
"director",
„etichetă de poziție”,
„clicks_branded”,
]
]
Acum, să calculăm procentul de clicuri fără marcă la numărul total de clicuri ale unei pagini de destinație.
# Calcularea procentului de clicuri în interogări fără marcă pe baza paginilor de destinație la toate clicurile pe pagina de destinație
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
axa=1,
)
[Ebook] Automatizarea SEO cu Oncrawl
 Citiți cartea electronică
Citiți cartea electronică2. Încărcarea veniturilor din trafic organic
La fel ca și recuperarea datelor GSC, avem mai multe moduri de a obține datele GA: am putea folosi „suplimentul Google Analytics Sheets” sau API-ul GA. În acest tutorial, prefer să folosesc Google Data Studio (GDS) datorită simplității sale.
Pentru a obține datele GA de la GDS, urmați acești pași:
- În GDS, creați un nou raport sau explorator și un tabel.
- Pentru parametru adăugați „pagină de destinație”, iar pentru valoare, trebuie să adăugăm „Venituri”.
- Apoi, va trebui să creați un segment personalizat în Google Analytics bazat pe sursă și mediu. Filtrați traficul „Google/organic”. După crearea segmentului, adăugați-l la secțiunea de segmente din GDS.
- La pasul final, exportați tabelul și salvați-l ca „
landing_pages_revenue.csv”.
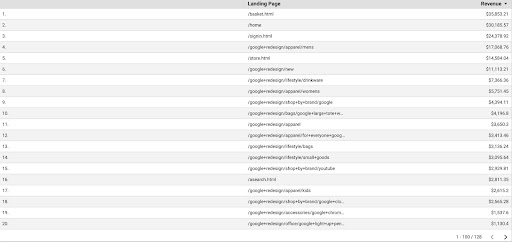
Venitul paginilor de destinație export csv
Să ne încărcăm datele.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Acum, trebuie să atașăm numele site-ului nostru la adresele URL ale paginilor de destinație GA.
Când ne exportăm datele din GA, paginile de destinație sunt într-o formă relativă, dar datele noastre GSC sunt în formă absolută.
Nu uitați să verificați datele paginilor de destinație GA. În seturile de date cu care am lucrat, am constatat că datele GA au nevoie de puțină curățare de fiecare dată.
# Conectarea adreselor URL ale paginilor de destinație GA cu SITE_NAME.
# De asemenea, redenumirea coloanelor
organic_revenue_df.loc[:, „Pagină de destinație”] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Pagină de destinație": "pagină de destinație", "Venituri": "venituri"}, inplace=True)
Acum, să îmbinăm datele noastre GSC cu datele GA.
# În acest pas, îmbin „main_df” cu „dk_organic_revenue_df” DataFrame care conține procentul de date interogări non-marcă main_df = main_df.merge(organic_revenue_df, on="landing page", how="left")
La sfârșitul acestei secțiuni, facem o mică curățare a coloanelor noastre DataFrame.
# Un pic de curățare a DataFrame-ului „main_df”.
main_df = main_df[
[
"pagina de destinație",
„clicks_non_brand”,
"ctr_non_brand",
"director",
„etichetă de poziție”,
„clicks_non_brand_percentage”,
"venituri",
]
]
3. Calculul veniturilor fără marcă
În această secțiune, vom procesa datele pentru a extrage informațiile pe care le căutăm.
Dar înainte de orice, haideți să ne filtram paginile de destinație pe baza „ IMPORTANT_DIRECTORIES ”:
# Eliminarea altor directoare pagini de destinație, care nu sunt incluse în „IMPORTANT_DIRECTORIES”
main_df = (
main_df[main_df[„director”].isin(IMPORTANT_DIRECTORIES)]
.dropna(subset=[„venituri”])
.reset_index(drop=True)
)
Acum, să calculăm traficul de venituri organice fără marcă.
Am definit o metrică pe care nu o putem calcula ușor și este mai mult intuiția decât orice altceva care ne determină să îi atribuim un număr.
Valoarea „ brand_influence ” arată puterea mărcii dvs. Dacă credeți că căutările non_brand generează mai puține vânzări către afacerea dvs., reduceți acest număr; ceva de genul 0,8 de exemplu.
# Dacă marca dvs. este atât de puternică încât interogarea fără marca dvs. poate vinde la fel de mult ca interogarea cu marca dvs., atunci 1 este bun pentru dvs.
# Gândiți-vă să căutați o carte fără un nume de marcă inclus în interogarea dvs. Când vezi Amazon, cumperi din alte piețe sau magazine?
influența_marcii = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["venit"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
Să creăm o diagramă circulară pentru a obține o perspectivă asupra veniturilor fără marcă pe baza directoarelor importante.
# În această celulă vreau să obțin toate veniturile din paginile de destinație care nu sunt de marcă pe baza directorului lor
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
index="director",
values="["non_brand_revenue"],
aggfunc={"non_brand_revenue": "sum"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
values="non_brand_revenue",
names=non_branded_directory_dist_revenue_df.index,
title="Venit fără marcă bazat pe directoarele site-urilor web",
)
pie_fig.update_traces(textposition="inside", textinfo="procent+label")
pie_fig.show()
Acest grafic arată distribuția interogărilor fără marcă pe IMPORTANT_DIRECTORIES .
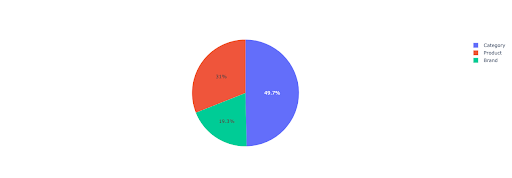
Distribuție de interogări fără marcă
Pe baza datelor curbei mele CTR, văd că nu mă pot baza pe CTR pentru poziții mai mari de 5. Din acest motiv, îmi filtrez datele în funcție de poziție.
Puteți modifica blocul de cod de mai jos pe baza datelor dvs.
# Datorită preciziei CTR în curba noastră CTR, cred că putem sări peste aterizări cu poziția mai mare de 5. Din acest motiv, am filtrat alte pagini de destinație main_df = main_df[main_df["poziție etichetă"] < 6].reset_index(drop=True)
4. Calcularea „Venituri pe clic” (RPC)
Aici, am creat o valoare personalizată și am numit-o „Venit pe clic” sau RPC. Aceasta ne arată venitul generat de fiecare clic fără marcă.
Puteți utiliza această valoare în moduri diferite. Am găsit o pagină cu RPC mare, dar clicuri scăzute. Când am verificat pagina, am aflat că a fost indexată în urmă cu mai puțin de o săptămână și putem folosi diferite metode pentru a optimiza pagina.
# Calcularea venitului generat cu fiecare clic (RPC: Venituri pe clic)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], axa=1
)
5. Previziunea veniturilor!
Ajungem la final, am așteptat până acum să ne prezicem veniturile organice fără marcă.
Să rulăm ultimele blocuri de cod.
# Funcția principală de calculare a veniturilor pe baza diferitelor poziții
pentru index, row_values în main_df.iterows():
# Comutați între directoare lista CTR
ctr_curve = directories_median_ctr_dict[row_values[„director”]]
# Buclă peste pozițiile de la 1 la 5 și calculați venitul pe baza creșterii sau scăderii CTR
pentru i în interval (1, 6):
if i == row_values["etichetă de poziție"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
altceva:
# main_df.loc[index, i + 1] ==
main_df.loc[index, i] = (
row_values["non_brand_revenue"]
* (curba_ctr[i - 1])
/ ctr_curve[int(row_values["poziție etichetă"] - 1)]
)
# Calcularea metricii „N la 1”. Aceasta arată creșterea veniturilor atunci când clasarea dvs. trece de la „N” la „1”
main_df.loc[index, „N la 1”] = main_df.loc[index, 1] - main_df.loc[index, row_values[„poziție etichetă”]]
Privind rezultatul final, avem noi coloane. Numele acestor coloane sunt „1”, „2”, „3”, „4”, „5”.
Ce înseamnă aceste nume? De exemplu, avem o pagină în poziția 3 și vrem să-i anticipăm veniturile dacă își îmbunătățește poziția sau vrem să știm cât vom pierde dacă vom scădea în clasament.
Coloanele „1” și „2” arată veniturile paginii atunci când poziția medie a acestei pagini se îmbunătățește, iar coloanele „4” și „5” arată veniturile acestei pagini atunci când coborâm în clasament.
Coloana „3” din acest exemplu arată venitul curent al paginii.
De asemenea, am creat o măsurătoare numită „N la 1”. Aceasta vă arată dacă poziția medie a acestei pagini se mută de la „3” (sau N) la „1” și cât de mult poate afecta veniturile mutarea.
Încheierea
Am tratat multe în acest articol și acum este rândul tău să-ți murdărești mâinile și să prezici veniturile din trafic organic fără marcă.
Acesta este cel mai simplu mod în care putem folosi această predicție. Am putea face acest algoritm mai complex și să-l combinăm cu unele modele ML, dar asta ar complica articolul.
Prefer să salvez aceste date într-un CSV și să le încarc într-o foaie de calcul Google. Sau, dacă plănuiesc să-l partajez cu ceilalți membri ai echipei sau organizației, îl voi deschide cu Excel și voi formata coloanele folosind culori, astfel încât să fie mai ușor de citit.
Pe baza acestor date, puteți prezice rentabilitatea investiției organice a traficului fără marcă și îl puteți utiliza în procesul de negociere.