
Actualizări de bază Google: efecte, probleme și soluții pentru site-urile YMYL
Publicat: 2019-12-04În acest studiu de caz, mă voi uita la Hangikredi.com, care este unul dintre cele mai mari active financiare și digitale ale Turciei. Vom vedea subtitluri tehnice SEO și câteva elemente grafice.
Acest studiu de caz este prezentat în două articole. Acest articol se ocupă de actualizarea Google Core din 12 martie, care a avut un efect negativ puternic asupra site-ului web și de ceea ce am făcut pentru a o contracara. Vom analiza 13 probleme tehnice și soluții, precum și probleme holistice.
Citiți a doua tranșă pentru a vedea cum am aplicat învățarea din această actualizare pentru a deveni un câștigător din fiecare actualizare Google Core.
Probleme și soluții: remedierea efectelor actualizării Google Core din 12 martie
Până la actualizarea algoritmului de bază din 12 martie, totul a mers fără probleme pentru site-ul web, pe baza datelor de analiză. Într-o zi, după ce a fost lansată știrea despre Actualizarea Algoritmului Core, a existat o scădere uriașă a clasamentelor și o mare frustrare în birou. Eu personal nu am văzut acea zi pentru că am ajuns doar când m-au angajat să încep un nou proiect și proces SEO 14 zile mai târziu.
[Studiu de caz] Îmbunătățirea clasamentului, vizitelor organice și vânzărilor cu analiza fișierelor jurnal
 Citiți studiul de caz
Citiți studiul de cazRaportul de daune pentru site-ul web al companiei după actualizarea algoritmului de bază din 12 martie este mai jos:
- 36% pierdere organică a sesiunii
- 65% Faceți clic pe Drop
- Pierdere CTR de 30%.
- 33% Pierdere organică de utilizatori
- 100 000 de afișări pierdute pe zi.
- 9,72% Pierdere de impresii
- 8 000 de cuvinte cheie pierdute

Acum, așa cum am afirmat la începutul articolului studiului de caz, ar trebui să punem o întrebare. Nu am putut să întrebăm „Când va avea loc următoarea actualizare a algoritmului de bază?” pentru că s-a întâmplat deja. A mai rămas o singură întrebare.
„Ce criterii diferite a luat în considerare Google între mine și concurentul meu?”
După cum puteți vedea din graficul de mai sus și din raportul de daune, ne-am pierdut principalul trafic și cuvintele cheie.
1. Problemă: Legătura internă
Am observat că atunci când am verificat pentru prima dată numărul de link-uri interne, textul de ancorare și fluxul de linkuri, concurentul meu era înaintea mea.
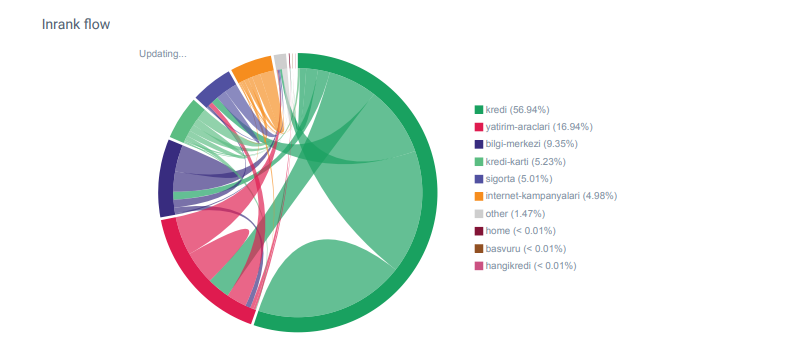
Raport Linkflow pentru categoriile Hangikredi.com din OnCrawl
Principalul meu concurent are peste 340 000 de link-uri interne cu mii de texte ancora. În aceste zile, site-ul nostru web avea doar 70 000 de link-uri interne fără texte de ancorare valoroase. În plus, lipsa legăturilor interne a afectat bugetul de accesare cu crawlere și productivitatea site-ului web. Chiar dacă 80% din traficul nostru a fost colectat pe doar 20 de pagini de produse, 90% din site-ul nostru a constat în pagini de ghid cu informații utile pentru utilizatori. Și majoritatea cuvintelor cheie și scorul de relevanță pentru interogările financiare provin din aceste pagini. De asemenea, erau nenumărate prea multe pagini orfane.
Din cauza lipsei structurii de legături interne, când am făcut Log Analysis cu Kibana, am observat că paginile cele mai accesate cu crawlere erau cele care au primit cel mai puțin trafic. De asemenea, când am asociat acest lucru cu rețeaua de link-uri interne, am descoperit că paginile corporative cu cel mai mic trafic (Privacy, Cookies, Security, About Us Pagini) au numărul maxim de link-uri interne.
După cum voi discuta în secțiunea următoare, acest lucru a determinat Googlebot să elimine factorul de link intern din Pagerank atunci când a accesat cu crawlere site-ul, realizând că linkurile interne nu au fost construite așa cum s-a dorit.
2. Problemă: arhitectura site-ului, Pagerank intern, eficiența traficului și a accesării cu crawlere
Potrivit declarației Google, linkurile interne și textele de ancorare ajută Googlebot să înțeleagă importanța și contextul unei pagini web. Pagerank sau Inrank intern se calculează pe mai mult de un factor. Potrivit lui Bill Slawski, linkurile interne sau externe nu sunt toate egale. Valoarea unui link pentru fluxul Pagerank se modifică în funcție de poziția, tipul, stilul și greutatea fontului.

Dacă Googlebot înțelege ce pagini sunt importante pentru site-ul dvs., le va accesa cu crawlere mai mult și le va indexa mai repede. Link-urile interne și designul corect al Site-Tree sunt factori importanți pentru aceasta. Alți experți au comentat, de asemenea, această corelație de-a lungul anilor:
„Majoritatea link-urilor oferă un pic de context suplimentar prin textul de ancorare. Cel puțin ar trebui, nu?”
– John Mueller, Google 2017„Dacă aveți pagini pe care le considerați importante pe site-ul dvs. , nu le îngropați la 15 legături adânc în site-ul dvs. și nu mă refer la lungimea directorului, ci vorbesc despre efectiv, trebuie să faceți clic pe 15 link-uri pentru a găsi pagina respectivă. dacă există o pagină care este importantă sau care are marje mari de profit sau conversii cu adevărat – ei bine – escaladă, care pune un link către pagina respectivă din pagina rădăcină, acesta este genul de lucru în care poate avea mult sens.”
–Matt Cutts, Google 2011„Dacă o pagină trimite la alta cu cuvântul „contact” sau cuvântul „despre”, iar pagina la care este legată include o adresă, acea locație a adresei ar putea fi considerată relevantă pentru pagina care face acea legătură.”
12 metode de analiză a linkurilor Google care s-ar fi putut schimba – Bill Slawski
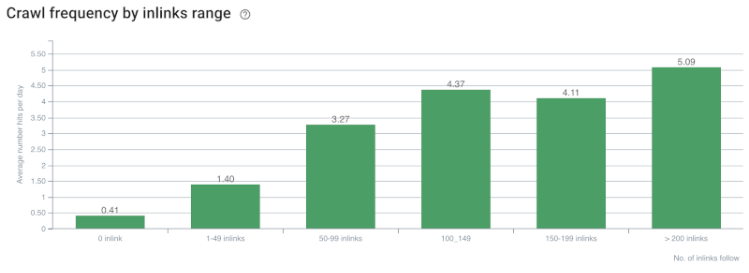
Rata de accesare cu crawlere/cererea și corelația numărului de legături interne. Sursa: OnCrawl.
Până acum, putem face aceste inferențe:
- Google îi pasă de adâncimea clicurilor. Dacă o pagină web este mai aproape de pagina de pornire, ar trebui să fie mai importantă. Acest lucru a fost confirmat și de John Mueller la 1 iulie 2018 în engleză Google Webmaster Hangout.
- Dacă o pagină web are o mulțime de link-uri interne care o indică, ar trebui să fie important.
- Textele de ancorare pot da putere contextuală unei pagini web.
- Un link intern poate transmite diferite sume de Pagerank în funcție de poziția, tipul, greutatea fontului sau stilul său.
- Un arbore de site prietenos cu UX, care oferă mesaje clare despre Autoritatea internă a paginii crawlerelor motoarelor de căutare este o alegere mai bună pentru distribuția Inrank și eficiența accesării cu crawlere.
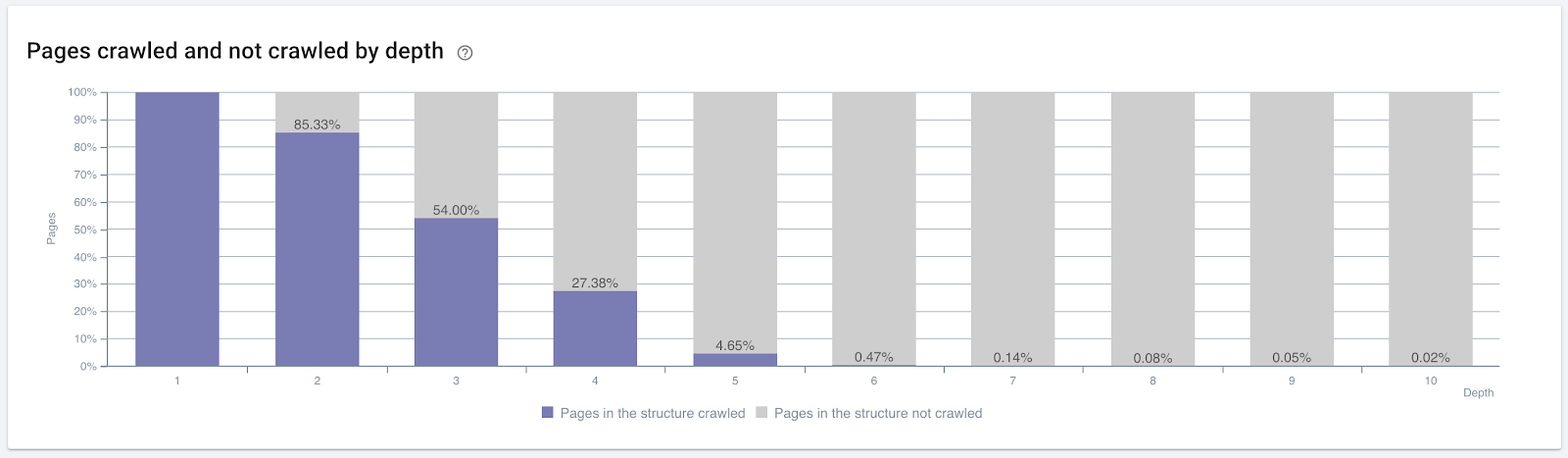
Procentul de pagini accesate cu crawlere în funcție de adâncimea clicurilor. Sursa: OnCrawl.
Dar acestea nu sunt suficiente pentru a înțelege natura legăturilor interne și efectele asupra eficienței accesului cu crawlere.
Oncrawl SEO Crawler
 Află mai multe
Află mai multeDacă paginile cu cele mai multe link-uri interne nu creează trafic sau nu primesc clic, acesta oferă semnale care indică faptul că arborele site-ului și structura link-urilor interne nu sunt construite conform intenției utilizatorului. Și Google încearcă întotdeauna să găsească paginile tale cele mai relevante cu intenția utilizatorului sau entități de căutare. Avem o altă citare de la Bill Slawski care face acest subiect mai clar:
„Dacă o resursă este legată de un număr de resurse care este disproporționat în raport cu traficul primit prin utilizarea acelor legături, resursa respectivă poate fi retrogradată în procesul de clasare.”
Actualizarea Groundhog tocmai a avut loc la Google? — Bill Slawski„Scorul de calitate al selecției poate fi mai mare pentru o selecție care are ca rezultat un timp de așteptare lung (de exemplu, mai mare decât o perioadă de timp prag) decât scorul de calitate al selecției pentru o selecție care are ca rezultat un timp de așteptare scurt.”
Actualizarea Groundhog tocmai a avut loc la Google? — Bill Slawski
Deci mai avem doi factori:
- Dwell Time în pagina legată.
- Traficul utilizatorului produs de link.
Numărul de link-uri interne și stilul/poziția nu sunt singurii factori. Numărul de utilizatori care urmăresc aceste linkuri și valorile lor de comportament sunt, de asemenea, importante. În plus, știm că linkurile și paginile pe care se face clic/vizitate sunt accesate cu crawlere de Google mult mai mult decât link-urile și paginile care nu sunt accesate sau vizitate.
„Ne-am îndreptat din ce în ce mai mult spre înțelegerea secțiunilor unui site pentru a înțelege calitatea acelor secțiuni.”
John Mueller, 2 mai 2017, engleză Google Webmasters Hangout.
Având în vedere toți acești factori, voi împărtăși două rezultate diferite și diferite ale Simulatorului Pagerank:
Aceste calcule Pagerank sunt realizate presupunând că toate paginile sunt egale, inclusiv pagina de pornire. Diferența reală este determinată de ierarhia legăturilor.
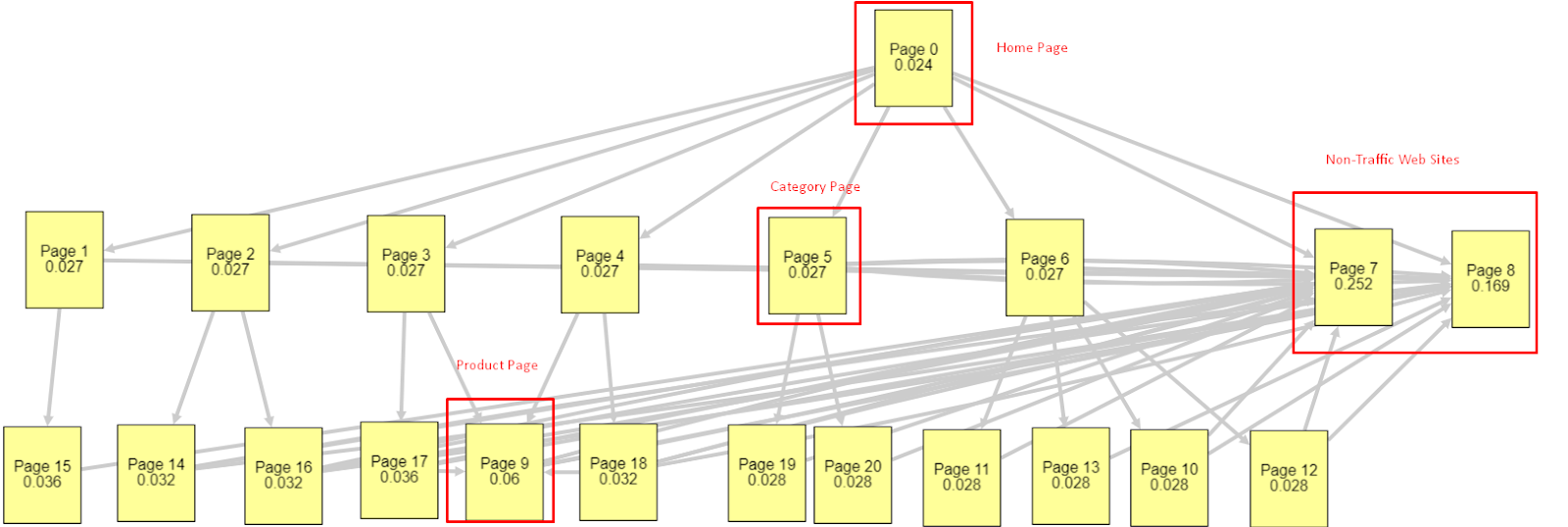
Exemplul prezentat aici este mai aproape de structura legăturilor interne înainte de 12 martie. PR pagina principală: 0,024, PR pagină categorie: 0,027, PR pagină produs: 0,06, PR pagini web fără trafic: 0,252.
După cum puteți observa, Googlebot nu poate avea încredere în această structură de link-uri interne pentru a calcula pagerankul intern și importanța paginilor interne. Paginile fără trafic și fără produse au de 12 ori mai multă autoritate decât pagina de pornire. Are mai mult decât pagini de produse.

Acest exemplu este mai aproape de situația noastră dinaintea actualizării algoritmului de bază din 5 iunie.. PR pagina principală: 0,033, Pagina categorie: 0,037, Pagina produsului: 0,148 și PR al paginilor fără trafic: 0,037.
După cum puteți observa, structura internă a legăturilor nu este încă corectă, dar cel puțin Paginile Web fără trafic nu au mai multe PR decât Paginile de categorii și Paginile de produse.
Care este o dovadă suplimentară că Google a scos link-ul intern și structura site-ului din sfera Pagerank, în funcție de fluxul utilizatorilor, solicitări și intenții? Desigur, comportamentul Googlebot și corelațiile Inlink Pagerank și Ranking:
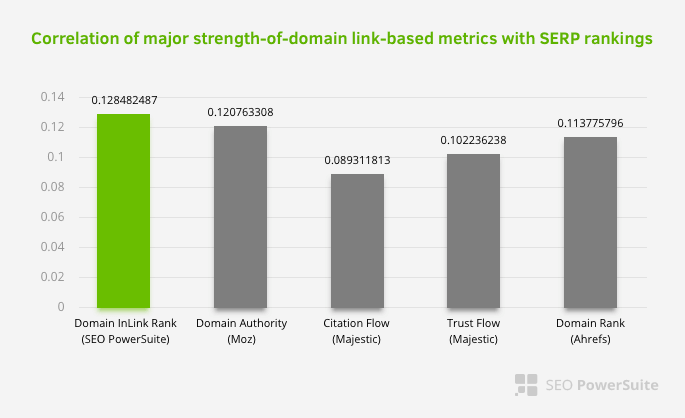
Acest lucru nu înseamnă că rețeaua de legături interne, în special, este mai importantă decât alți factori. Perspectiva SEO care se concentrează pe un singur punct nu poate avea niciodată succes. Într-o comparație între instrumente terțe, arată că valoarea internă Pagerank progresează în raport cu alte criterii.
Conform cercetării Inlink Rank și corelarea rangului realizată de Aleh Barysevich, paginile cu cele mai multe legături interne au clasamente mai ridicate decât celelalte pagini ale site-ului. Conform sondajului efectuat în perioada 4-6 martie 2019, au fost analizate 1.000.000 de pagini conform valorii interne Pagerank pentru 33.500 de cuvinte cheie. Rezultatele acestei cercetări efectuate de SEO PowerSuite au fost comparate cu diferitele valori ale Moz, Majestic și Ahrefs și au dat rezultate mai precise.
Iată câteva dintre numerele de link-uri interne de pe site-ul nostru înainte de actualizarea algoritmului de bază din 12 martie:
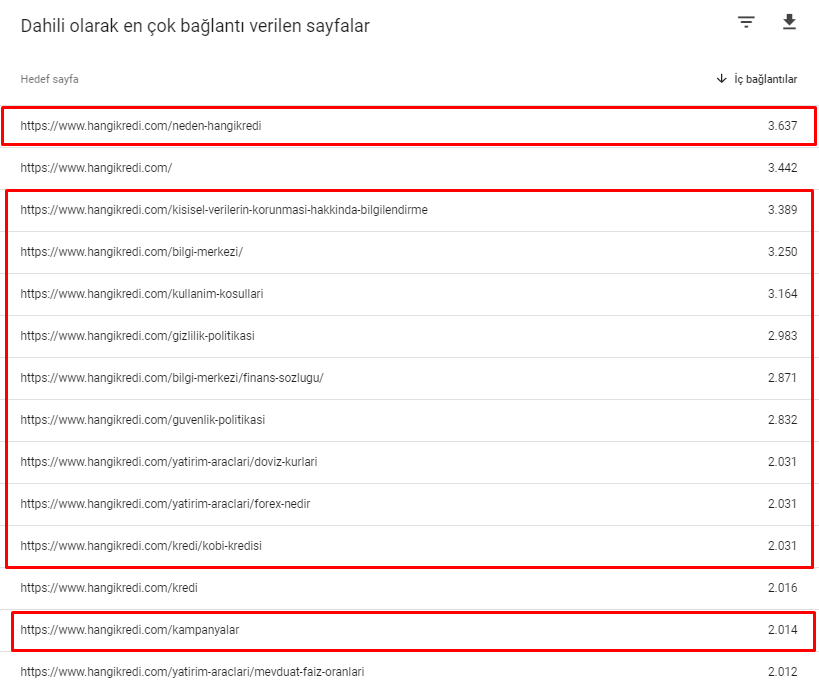
După cum puteți vedea, schema noastră de conexiune internă nu a reflectat intenția și fluxul utilizatorului. Paginile care primesc cel mai puțin trafic (pagini minore de produse) sau care nu primesc niciodată trafic (cu roșu) au fost direct în 1st Click Depth și primesc PR de pe pagina de start. Și unii aveau chiar mai multe link-uri interne decât pagina de pornire.
Având în vedere toate acestea, există doar ultimele două puncte pe care le putem arăta pe acest subiect.
- Rata de accesare cu crawlere / cererea pentru cele mai multe pagini conectate intern
- Link Sculpting și Pagerank
Între 1 februarie și 31 martie, iată paginile pe care Googlebot a accesat cel mai des cu crawlere:
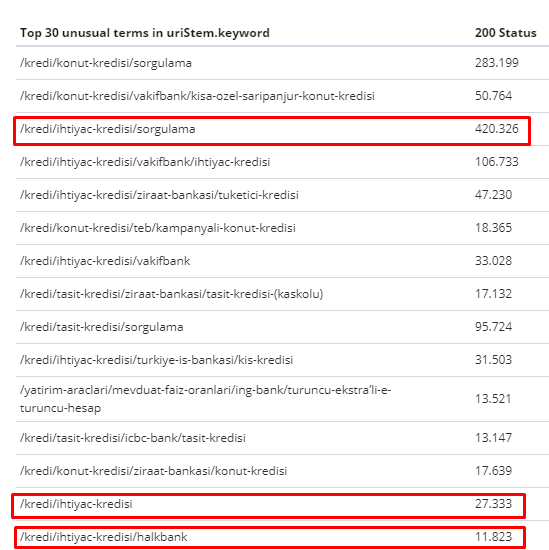
După cum puteți observa, paginile accesate cu crawlere și paginile care au cele mai multe legături interne sunt complet diferite unele de altele. Paginile cu cele mai multe legături interne nu erau convenabile pentru intenția utilizatorului; nu au cuvinte cheie organice sau orice fel de valoare SEO directă. (
Adresele URL din casetele roșii sunt cele mai vizitate și importante categorii de pagini de produse ale noastre. Celelalte pagini din această listă sunt a doua sau a treia categorii cele mai vizitate și importante.)
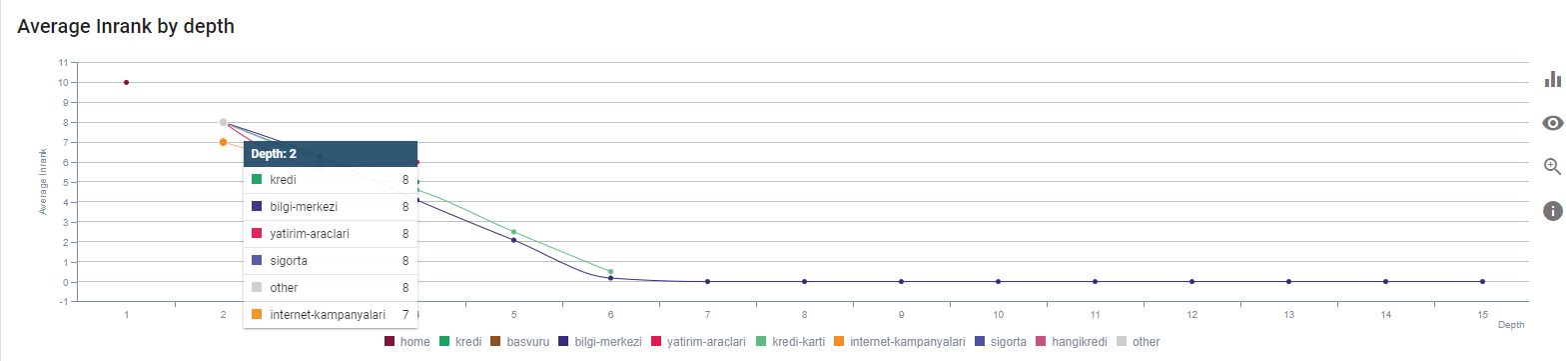
Inrankul nostru actual în funcție de adâncimea paginii. Sursa: Oncrawl.
Ce este Link Sculpting și ce să faci cu link-urile interne nefollowed?
Spre deosebire de ceea ce cred majoritatea SEO, linkurile marcate cu o etichetă „nofollow” trec în continuare valoarea Pagerank internă. Pentru mine, după toți acești ani, nimeni nu a povestit acest element SEO mai bine decât Matt Cutts în articolul său Sculpting Pagerank din 15 iunie 2009.
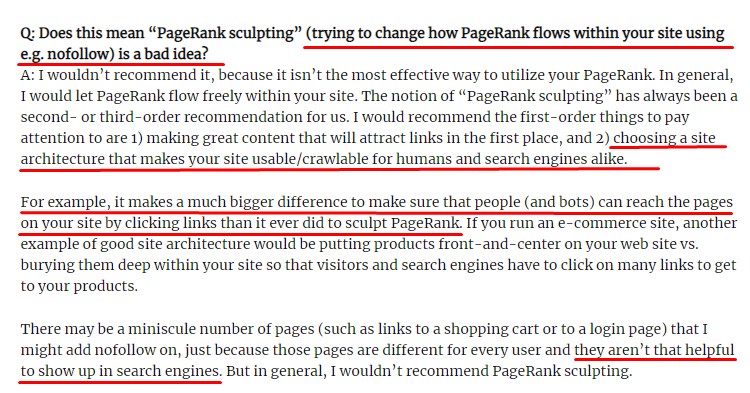
O parte utilă pentru Link Sculpting, care arată scopul real al Pagerank Sculpting.
„Recomand să nu folosiți nofollow pentru un fel de sculptare PageRank într-un site web , deoarece probabil că nu face ceea ce credeți că face.”
– John Mueller, Google 2017
Dacă aveți pagini web fără valoare în ceea ce privește Google și utilizatori, nu ar trebui să le etichetați cu „nofollow”. Nu va opri fluxul Pagerank. Ar trebui să le interziceți din fișierul robots.txt. În acest fel, Googlebot nu le va accesa cu crawlere, dar nici nu le va transmite Pagerank-ul intern. Dar ar trebui să-l folosești doar pentru pagini fără valoare, așa cum spunea Matt Cutts în urmă cu zece ani. Paginile care fac redirecționări automate pentru marketing afiliat sau paginile fără conținut sunt câteva exemple convenabile aici.
Soluție: Structură de legătură internă mai bună și mai naturală
Concurentul nostru a avut un dezavantaj. Site-ul lor avea mai mult text anchor, mai multe link-uri interne, dar structura lor nu era naturală și utilă. Același text ancora a fost folosit cu aceeași propoziție pe fiecare pagină de pe site-ul lor. Paragraful de intrare pentru fiecare pagină a fost acoperit cu acest conținut repetitiv. Fiecare utilizator și motor de căutare pot recunoaște cu ușurință că aceasta nu este o structură naturală care ia în considerare beneficiile utilizatorului.
Așa că am decis trei lucruri de făcut pentru a remedia structura internă a legăturilor:
- Site Information Architecture sau Site-Tree ar trebui să urmeze o cale diferită de link-urile plasate în conținut. Ar trebui să urmărească mai îndeaproape mintea utilizatorului și o rețea neuronală cu cuvinte cheie.
- În fiecare porțiune de conținut, cuvintele cheie secundare ar trebui folosite împreună cu cuvintele cheie principale ale paginii vizate.
- Textele de ancorare ar trebui să fie naturale, adaptate la conținut și ar trebui să fie utilizate într-un punct diferit al fiecărei pagini, cu atenție la percepția utilizatorului
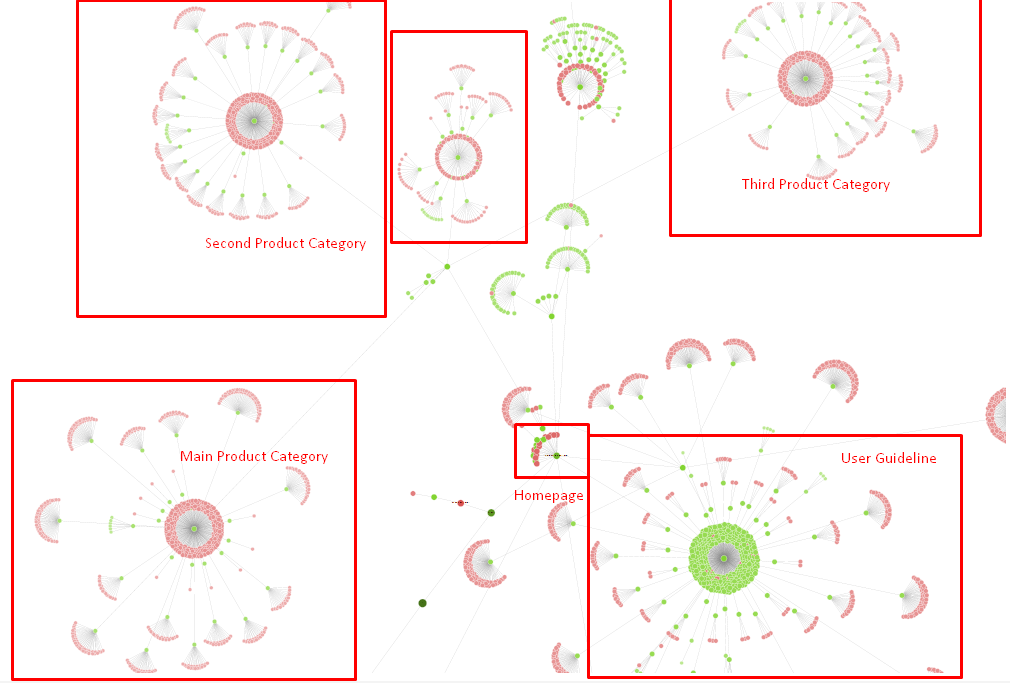
Arborele nostru de site și o parte a structurii inlink pentru moment.
În diagrama de mai sus, puteți vedea link-ul nostru intern actual și arborele site-ului.
Unele dintre lucrurile pe care le-am făcut pentru a remedia această problemă sunt mai jos:
- Am creat încă 30 000 de link-uri interne cu ancore utile..
- Am folosit pete naturale și cuvinte cheie pentru utilizator.
- Nu am folosit propozițiile și modelele repetitive pentru legături interne.
- Am dat semnalele potrivite Googlebot-ului despre Inrank-ul unei pagini web.
- Am examinat efectele structurii corecte a legăturilor interne asupra eficienței accesării cu crawlere prin Log Analysis și am văzut că paginile noastre principale de produse au fost accesate cu crawlere mai mult în comparație cu statisticile anterioare.
- A creat peste 50 000 de link-uri interne pentru paginile orfane.
- A folosit link-uri interne ale paginii de pornire pentru a alimenta sub-paginile și a creat mai multe surse de link-uri interne pe pagina de pornire.
- Pentru a proteja Puterea Pagerank, am folosit și eticheta nofollow pentru unele link-uri externe inutile. (Nu a fost vorba despre link-uri interne, dar servește aceluiași scop.)
3. Problemă: Structura conținutului
Google spune că pentru site-urile web YMYL, încrederea și autoritatea sunt mult mai importante decât pentru alte tipuri de site-uri.

Pe vremuri, cuvintele cheie erau doar cuvinte cheie. Dar acum, ele sunt, de asemenea, entități care sunt bine definite, singulare, semnificative și distinse. În conținutul nostru, au existat patru probleme principale:
- Conținutul nostru a fost scurt. (În mod normal, lungimea conținutului nu este importantă. Dar, în acest caz, acestea nu conțineau suficiente informații despre subiecte.)
- Numele scriitorilor noștri nu erau singulare, semnificative sau distinse ca entitate.
- Conținutul nostru nu a fost prietenos cu ochii. Cu alte cuvinte, nu a fost conținut „fast-food”. Era conținut fără subtitluri.
- Am folosit un limbaj de marketing. În spațiul unui paragraf, am putea identifica numele mărcii și publicitatea acestuia pentru utilizator.
- Au existat o mulțime de butoane care trimiteau utilizatorii către paginile de produse din paginile informaționale.
- În conținutul paginilor noastre de produse, nu existau suficiente informații sau linii directoare cuprinzătoare.
- Designul nu a fost ușor de utilizat. Folosim practic aceeași culoare pentru font și fundal. (Acest lucru este încă valabil din cauza problemelor de infrastructură.)
- Imaginile și videoclipurile nu au fost văzute ca parte a conținutului.
- Intenția utilizatorului și intenția de căutare pentru un anumit cuvânt cheie nu fuseseră considerate ca importante înainte.
- A existat o mulțime de conținut duplicat, inutil și repetitiv pentru același subiect.
Accesați cu crawlere Auditul conținutului duplicat de astăzi.
Soluție: Structură de conținut mai bună pentru încrederea utilizatorilor
Când verificați o problemă la nivelul întregului site, folosirea unui program de audit la nivelul întregului site ca asistent este o modalitate mai bună de a organiza timpul petrecut pe proiecte SEO. La fel ca în secțiunea de link-uri interne, am folosit Oncrawl Site Audit împreună cu alte instrumente și inspecții Xpath.
În primul rând, rezolvarea fiecărei probleme din secțiunea de conținut ar fi luat prea mult timp. În acele zile de criză care se prăbușeau, timpul era un lux. Așa că am decis să remediez problemele de câștig rapid, cum ar fi:
- Ștergerea conținutului duplicat, inutil și repetitiv
- Unificarea conținutului scurt și subțire fără informații complete
- Republicarea conținutului care nu avea subtitluri și structură care poate fi urmărită vizual
- Fixarea tonului de marketing intensiv în conținut
- Ștergerea multor butoane de apel la acțiune din conținut
- Comunicare vizuală mai bună cu imagini și videoclipuri
- Asigurarea conținutului și a cuvintelor cheie vizate compatibile cu intenția utilizatorului și a căutării
- Utilizarea și afișarea entităților financiare și educaționale în conținut pentru încredere
- Utilizarea comunității sociale pentru a crea dovezi sociale de aprobare
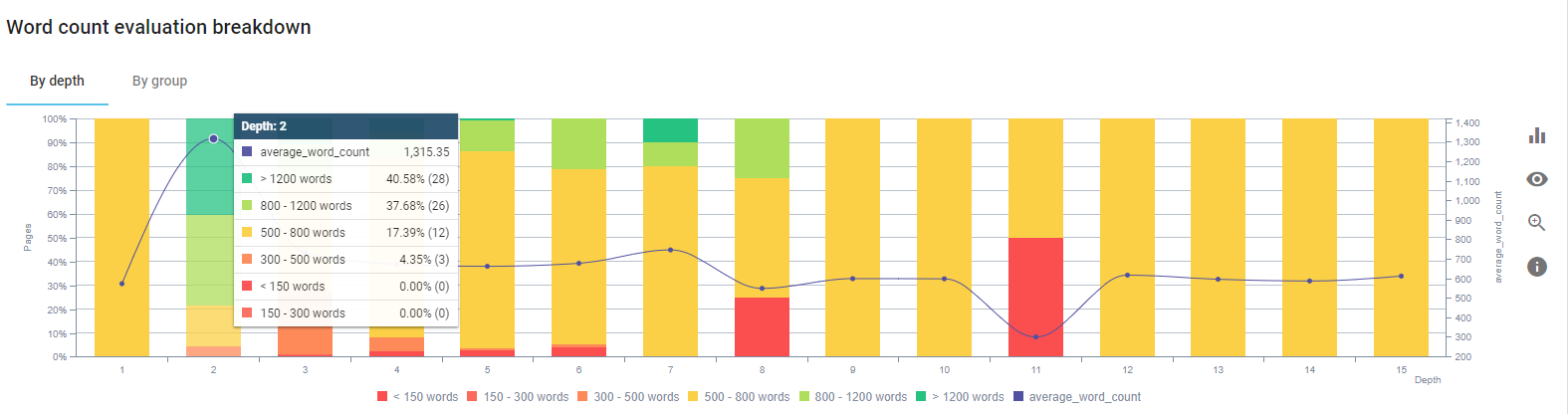

Ne-am concentrat pe remedierea conținutului paginilor de produse și a paginilor de ghid cele mai apropiate de acestea.
La începutul acestui proces, cele mai multe dintre paginile noastre de destinație/ghid pentru produse și tranzacții aveau mai puțin de 500 de cuvinte fără informații complete.
În 25 de zile, acțiunile pe care le-am desfășurat sunt mai jos:
- Au fost șterse 228 de pagini cu conținut duplicat, inutil și repetitiv. (Profilurile de backlink ale Ccontent au fost verificate înainte de procesul de ștergere. Și am folosit coduri de stare 301 sau 410 pentru o comunicare mai bună cu Googlebot.)
- Au fost combinate peste 123 de pagini fără informații complete.
- Subtitluri folosite în funcție de importanța și cererea utilizatorului în conținut.
- Numele mărcii și butoanele CTA au fost șterse cu un limbaj de marketing.
- Includeți text în imagini pentru a consolida subiectul principal.
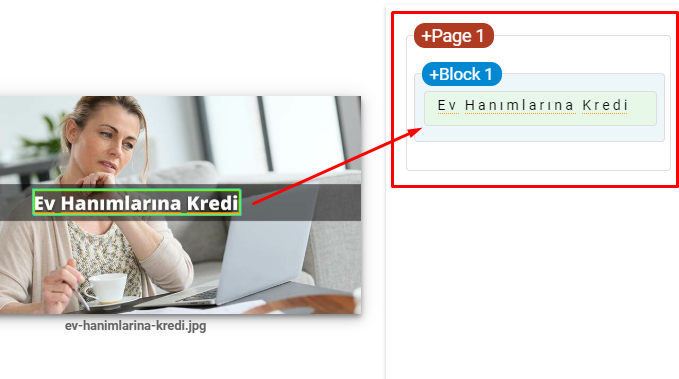
Aceasta este o captură de ecran de la Google Vision AI. Google poate citi textul din imagini și poate detecta sentimentele și identitățile din cadrul entităților.
- Am activat rețeaua noastră socială pentru a atrage mai mulți utilizatori.
- Am examinat decalajul de conținut dintre concurenți și noi și am creat peste 80 de noi piese de conținut.
- Am folosit Google Analytics, Search Console și Google Data Studio pentru a determina paginile subperformate, cu o rată de respingere ridicată și trafic redus.
- Am făcut cercetări pentru fragmentele recomandate și cuvintele cheie și structura conținutului acestora. Am adăugat aceleași titluri și aceeași structură de conținut în conținutul nostru asociat. Aceasta a crescut fragmentele noastre recomandate.
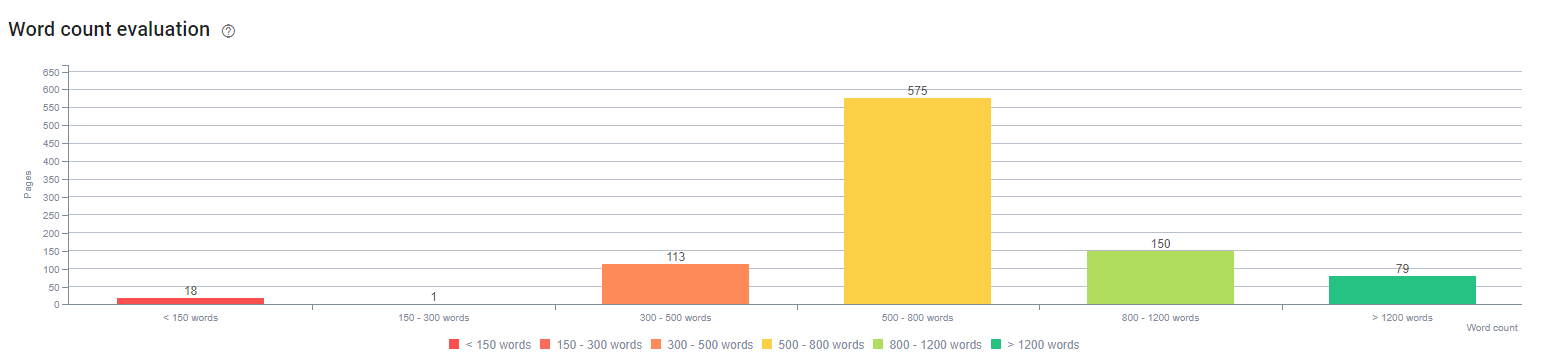
La începutul acestui proces, conținutul nostru era alcătuit în mare parte din 150 și 300 de cuvinte. Lungimea medie a conținutului nostru a crescut cu 350 de cuvinte pentru întregul site.
4. Problemă: Indexarea poluării, umflare și etichete canonice
Google nu a făcut niciodată o declarație despre poluarea indexată și, de fapt, nu sunt sigur dacă cineva l-a folosit ca termen SEO înainte sau nu. Toate paginile care nu au sens pentru Google pentru un scor de index mai eficient ar trebui eliminate din paginile de index Google. Paginile care provoacă poluare cu index sunt pagini care nu au generat trafic de luni de zile. Au zero CTR și zero cuvinte cheie organice. În cazurile în care au câteva cuvinte cheie organice, ar trebui să devină un concurent al altor pagini de pe site-ul tău pentru aceleași cuvinte cheie.
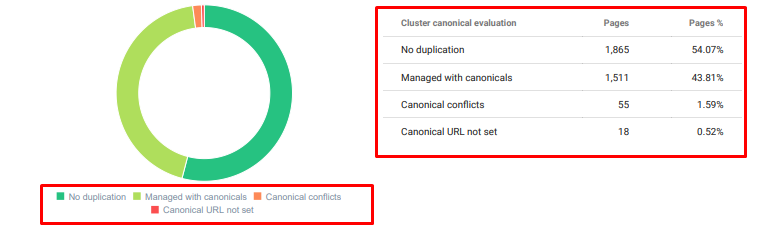
De asemenea, am efectuat cercetări pentru balonarea indexului și am găsit și mai multe pagini indexate inutile. Aceste pagini au existat din cauza unei structuri eronate de informații ale site-ului sau din cauza unei structuri de URL proaste.
Un alt motiv pentru această problemă a fost etichetele canonice utilizate incorect. De mai bine de doi ani, etichetele canonice au fost tratate ca doar indicii pentru Googlebot. Dacă sunt utilizate incorect, Googlebot nu le va calcula și nu le va acorda atenție în timp ce evaluează site-ul. Și, de asemenea, pentru acest calcul, probabil că îți vei consuma ineficient bugetul de crawl. Din cauza utilizării incorecte a etichetelor canonice, au fost indexate peste 300 de pagini de comentarii cu conținut duplicat.
Scopul teoriei mele de a arăta Google numai pagini de calitate și necesare, cu potențial de a câștiga clicuri și de a crea valoare pentru utilizatori.
Soluție: Remedierea indicelui de poluare și balonare
În primul rând, am luat sfatul de la John Mueller de la Google. L-am întrebat dacă am folosit eticheta noindex pentru aceste pagini, dar totuși i-am lăsat pe Googlebot să le urmărească, „aș pierde echitatea linkurilor și eficiența accesării cu crawlere?”
După cum puteți ghici, el a spus da la început, dar apoi a sugerat că utilizarea legăturilor interne poate depăși acest obstacol.
De asemenea, am constatat că utilizarea etichetelor noindex în același timp cu dofollow a scăzut rata de accesare cu crawlere de către Googlebot în aceste pagini. Aceste strategii mi-au permis să fac Googlebot să acceseze cu crawlere produsele mele și paginile cu ghid importante mai des. De asemenea, mi-am modificat structura internă a legăturilor, așa cum mi-a recomandat John Mueller.
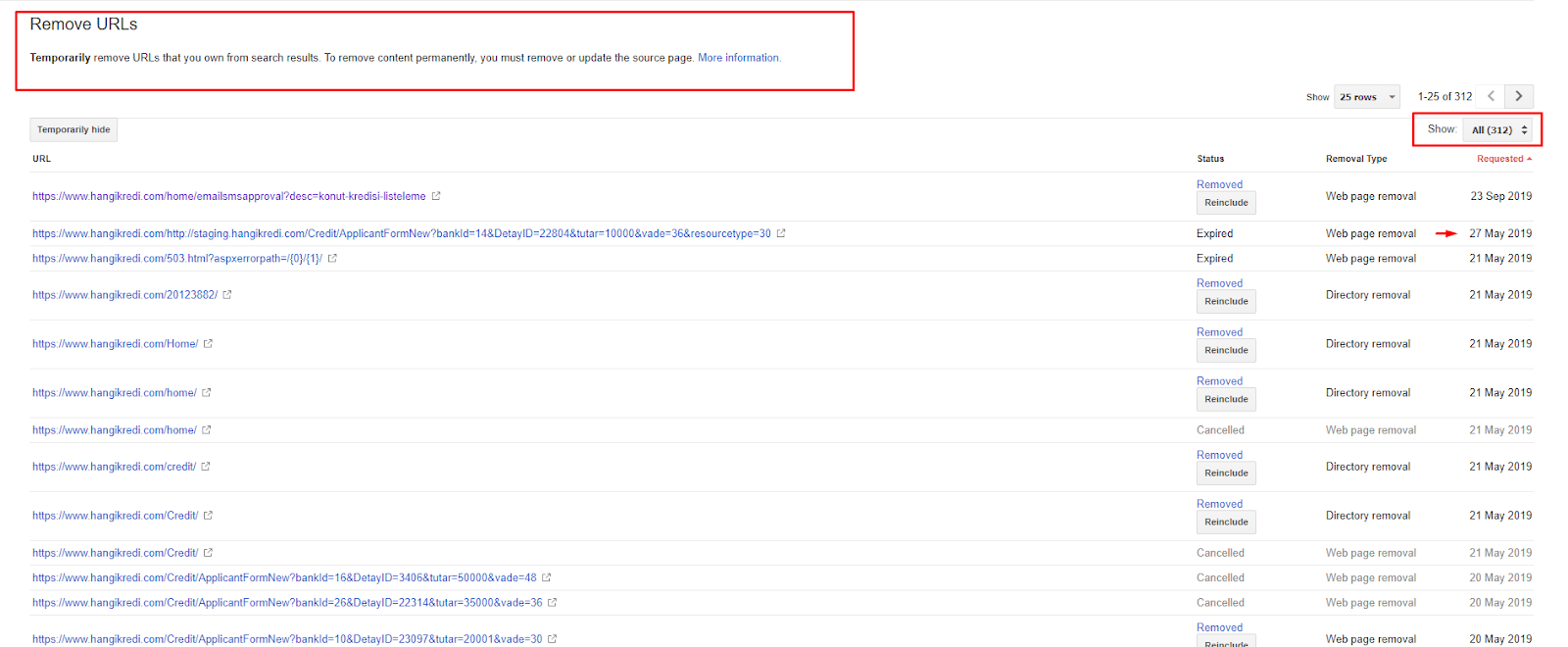
In scurt timp:
- Au fost descoperite pagini indexate inutile.
- Peste 300 de pagini au fost eliminate din index.
- Eticheta Noindex a fost implementată.
- Structura internă a linkurilor a fost modificată pentru paginile care au primit linkuri de la paginile care au fost eliminate din index.
- Eficiența și calitatea crawlului au fost examinate de-a lungul timpului.
5. Problemă: coduri de stare greșite
La început, am observat că Googlebot vizitează o mulțime de conținut șters din trecut. Până și paginile de acum opt ani erau încă târâte. Acest lucru s-a datorat utilizării codurilor de stare incorecte, în special pentru conținutul șters.
Există o diferență uriașă între funcțiile 404 și 410. Unul dintre ele este pentru o pagină de eroare în care nu există conținut, iar celălalt este pentru conținutul șters. În plus, paginile valide au făcut referire la o mulțime de adrese URL de sursă și de conținut șterse. Unele imagini șterse și elemente CSS sau JS au fost, de asemenea, folosite pe paginile publicate valide ca resurse. În cele din urmă, au existat o mulțime de pagini soft 404 și mai multe lanțuri de redirecționare și 302-307 redirecționări temporare pentru paginile redirecționate permanent.
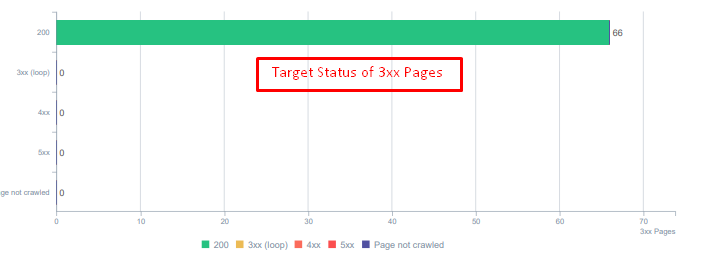
Codurile de stare pentru activele redirecționate astăzi.
Soluție: Remedierea codurilor de stare greșite
- Fiecare cod de stare 404 a fost convertit în codul de stare 410. (Mai mult de 30000)
- Fiecare resursă cu codul de stare 404 a fost înlocuită cu o nouă resursă validă. (Mai mult de 500)
- Fiecare redirecționare 302-307 a fost convertită în redirecționare permanentă 301. (Mai mult de 1500)
- Lanțurile de redirecționare au fost eliminate din activele utilizate.
- În fiecare lună, primim peste 25 000 de accesări pe pagini și resurse cu un cod de stare 404 în analiza noastră de jurnal. Acum, este mai puțin de 50 pentru 404 coduri de stare pe lună și zero accesări pentru 410 coduri de stare...
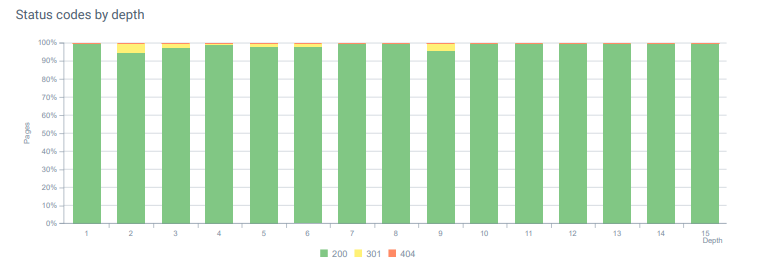
Codurile de stare în toată adâncimea paginii astăzi.
6. Problemă: HTML semantic
Semantica se referă la ceea ce înseamnă ceva. HTML semantic include etichete care dau semnificația componentei paginii într-o ierarhie. Cu această structură de cod ierarhică, puteți spune Google care este scopul unei părți a conținutului. De asemenea, în cazul în care Googlebot nu poate accesa cu crawlere toate resursele necesare pentru redarea completă a paginii dvs., puteți să specificați cel puțin aspectul paginii dvs. web și funcțiile părților de conținut pentru Googlebot.
Pe Hangikredi.com, după actualizarea Google Core Algorithm din 12 martie, știam că nu era suficient buget de accesare cu crawlere din cauza structurii site-ului web neoptimizate. Așadar, pentru a face Googlebot să înțeleagă mai ușor scopul, funcția, conținutul și utilitatea paginii web, am decis să folosesc HTML semantic.
Soluție: Utilizare HTML semantică
Conform Ghidurilor Google pentru evaluarea calității, fiecare căutator are o intenție și fiecare pagină web are o funcție în conformitate cu această intenție. Pentru a demonstra aceste funcții Googlebot, am adus câteva îmbunătățiri structurii noastre HTML pentru unele dintre paginile care sunt accesate cu crawlere mai puțin de Googlebot.
- Eticheta <main> folosită pentru a afișa conținutul principal și funcția paginii.
- Folosit <nav> pentru partea de navigare.
- Folosit <footer> pentru subsolul site-ului.
- Folosit <articol> pentru articol.
- Etichetele <section> utilizate pentru fiecare etichetă de titlu.
- S-au folosit etichete <picture>, <table>, <citation> pentru imagini, tabele și citate din conținut.
- Eticheta <aside> folosită pentru conținutul suplimentar.
- S-au rezolvat problemele de ierarhie H1-H6 (în ciuda ultimei declarații Google „folosirea a două H1 nu este o problemă”, folosirea structurii corecte ajută Googlebot.)
- La fel ca în secțiunea Structura conținutului, am folosit și HTML semantic pentru fragmentele recomandate, am folosit tabele și liste pentru mai multe rezultate din fragmentele recomandate.

Pentru noi, aceasta nu a fost o dezvoltare implementabilă în mod realist pentru întregul site. Cu toate acestea, cu fiecare actualizare de design, continuăm să implementăm etichete HTML semantice pentru pagini web suplimentare.
7. Problemă: Utilizarea datelor structurate
Asemenea utilizării HTML semantic, datele structurate pot fi utilizate pentru a afișa funcțiile și definițiile părților paginilor web către Googlebot. În plus, datele structurate sunt obligatorii pentru rezultate bogate. Pe site-ul nostru web, datele structurate nu au fost folosite sau, mai frecvent, au fost utilizate incorect până la sfârșitul lunii martie. Pentru a crea relații mai bune cu entitățile de pe site-ul nostru web și de conturile noastre off-page, am început să implementăm Date Structurate.
Soluție: Utilizarea corectă și testată a datelor structurate
Pentru instituțiile financiare și site-urile web YMYL, datele structurate pot rezolva o mulțime de probleme. De exemplu, pot arăta identitatea mărcii, tipul de conținut și pot crea o vizualizare mai bună a fragmentului. Am folosit următoarele tipuri de date structurate pentru pagini la nivel de site și individuale:
- Întrebări frecvente Date structurate pentru paginile principale de produse
- Date structurate ale paginii web
- Date structurate ale organizației
- Date structurate Breadcrumb
8. Sitemap și optimizare Robots.txt
Pe Hangikredi.com, nu există un Sitemap dinamic. Harta site-ului existentă în acel moment nu includea toate paginile necesare și includea și conținut șters. De asemenea, în fișierul Robots.txt, unele dintre paginile de referință afiliate cu mii de link-uri externe nu au fost interzise. Acestea au inclus și unele fișiere JS terță parte care nu au legătură cu conținutul și alte resurse suplimentare care nu erau necesare pentru Googlebot.
Au fost aplicați următorii pași:
- Am creat un sitemap_index.xml pentru mai multe sitemap-uri care sunt create în funcție de categoriile de site-uri pentru semnale de accesare cu crawlere mai bune și o mai bună examinare a acoperirii.
- Unele dintre fișierele JS de la terțe părți și unele fișiere JS inutile au fost interzise în fișierul robots.txt.
- Paginile afiliate cu linkuri externe și fără valoare a paginii de destinație au fost interzise, așa cum am menționat în secțiunea Pagerank sau Internal Link Sculpting.
- S-au rezolvat peste 500 de probleme de acoperire. (Majoritatea dintre ele erau pagini care s-au indexat în ciuda faptului că au fost interzise de Robots.txt.)
Puteți vedea creșterea ratei de accesare cu crawlere, a sarcinii și a cererii din graficul de mai jos:
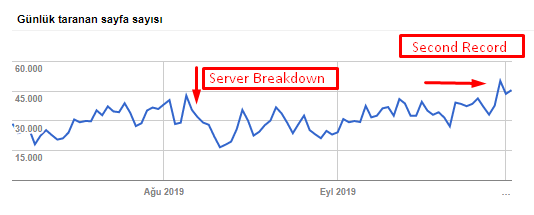
Număr de pagini accesate cu crawlere pe zi de Googlebot. A existat o creștere constantă a paginilor accesate cu crawlere pe zi până la 1 august. După ce un atac a provocat o defecțiune a serverului la începutul lunii august, acesta și-a recăpătat stabilitatea în puțin peste o lună.

Încărcarea cu crawlere pe zi de Googlebot a evoluat în paralel cu numărul de pagini accesate cu crawlere pe zi.
9. Remedierea problemelor AMP
Pe site-ul web al companiei, fiecare pagină de blog are o versiune AMP. Din cauza implementării incorecte a codului și a lipsei canonicelor AMP, toate paginile AMP au fost șterse în mod repetat din index. Acest lucru a creat un scor de index instabil și lipsă de încredere pentru site-ul web. În plus, paginile AMP aveau termeni și cuvinte în limba engleză în mod implicit pentru conținutul turc.
- Etichetele canonice au fost remediate pentru mai mult de 400 de pagini AMP.
- Au fost găsite și remediate implementări incorecte de cod. (S-a datorat în principal implementării incorecte a etichetelor AMP-Analytics și AMP-Canonical.)
- Termenii englezi au fost traduși implicit în turcă.
- Stabilitatea indexului și a clasamentului a fost creată pentru partea blogului site-ului companiei.
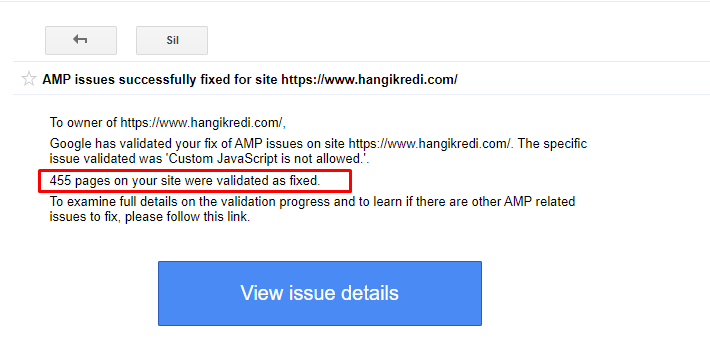
Un exemplu de mesaj în GSC despre îmbunătățirile AMP
10. Probleme și soluții cu metaetichete
Din cauza problemelor legate de bugetul de accesare cu crawlere, uneori în interogările de căutare critice pentru paginile de produse principale importante, Google nu a indexat și nu a afișat conținut în metaetichetele. În loc de meta titlu, lista SERP a arătat doar numele firmei construit din două cuvinte. Nu s-a afișat nicio descriere a fragmentului. Acest lucru ne reduce CTR și dăuna identității mărcii noastre. Am rezolvat această problemă mutând metaetichetele în partea de sus a codului nostru sursă, așa cum se arată mai jos.
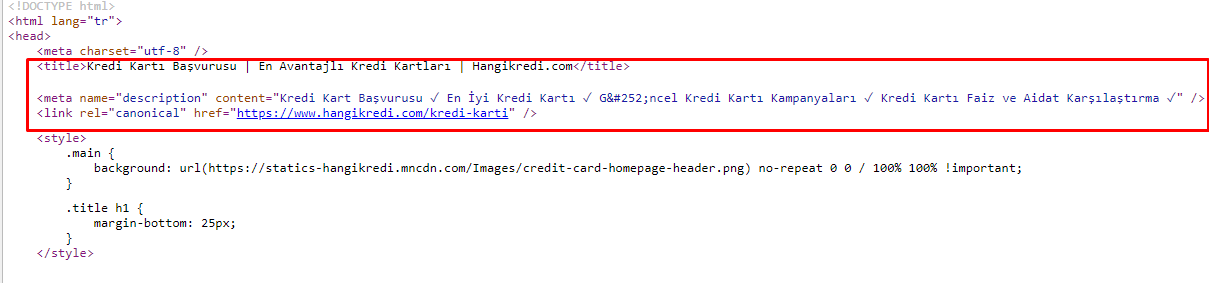
Pe lângă bugetul de accesare cu crawlere, am optimizat și peste 600 de metaetichete pentru paginile tranzacționale și informative:
- Lungimea caracterelor optimizată pentru dispozitivele mobile.
- S-au folosit mai multe cuvinte cheie în titluri
- Am folosit stiluri diferite de meta-etichete și am examinat CTR-ul, Gap-ul cuvintelor cheie și modificările de clasare
- Am creat mai multe pagini cu structura corectă a arborelui site-ului pentru a viza mai bine cuvintele cheie secundare datorită acestor procese de optimizare.
- Pe site-ul nostru, avem în continuare diferite meta titluri, descrieri și titluri pentru testarea algoritmului Google și CTR-ul utilizatorului de căutare.
11. Probleme de performanță a imaginii și soluții
Problemele de imagine pot fi împărțite în două tipuri. Pentru comoditatea conținutului și pentru viteza paginii. Pentru ambele, site-ul web al companiei are încă multe de făcut.
În martie și aprilie, după actualizarea negativă a algoritmului de bază din 12 martie:
- Imaginile nu aveau etichete alt sau aveau etichete alt greșite.
- Nu aveau titluri.
- Nu aveau o structură URL corectă.
- Nu aveau extensii de generația următoare.
- Nu s-au comprimat.
- Nu aveau rezoluția potrivită pentru fiecare dimensiune a ecranului dispozitivului.
- Nu aveau subtitrări.
Pentru a vă pregăti pentru următoarea actualizare Google Core Algorithm:
- Imaginile au fost comprimate.
- Extensiile lor au fost parțial schimbate.
- Etichetele Alt au fost scrise pentru majoritatea dintre ele.
- Titlurile și legendele au fost remediate pentru utilizator.
- Structurile URL au fost parțial fixate pentru utilizator.
- Am găsit câteva imagini neutilizate care sunt încă încărcate de browser și le-am șters din sistem.
Din cauza infrastructurii site-ului, am implementat parțial corecții SEO pentru imagini.
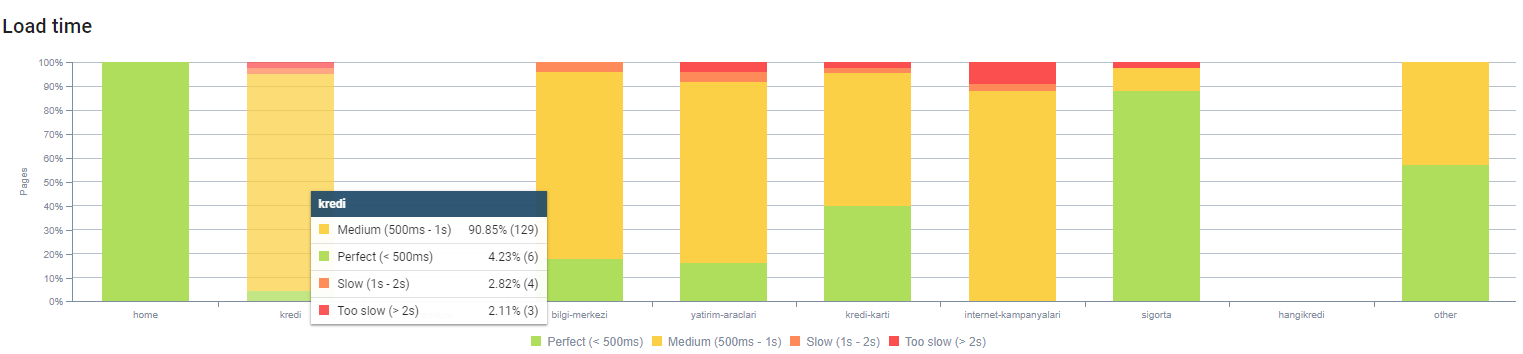
Puteți observa timpul de încărcare a paginii noastre în funcție de adâncimea paginii de mai sus. După cum puteți vedea, majoritatea paginilor de produse sunt încă grele.
12. Probleme și soluții pentru cache, preîncărcare și preîncărcare
Înainte de actualizarea algoritmului de bază din 12 martie, pe site-ul web al companiei exista un sistem de cache liber. Unele părți de conținut erau în cache, dar unele nu erau. Aceasta a fost o problemă în special pentru paginile de produse, deoarece acestea au fost mai lente decât paginile de produse ale concurenților noștri de două ori. Majoritatea componentelor paginilor noastre web sunt de fapt surse statice, dar tot nu aveau etag-uri pentru a indica intervalul de cache.
Pentru a vă pregăti pentru următoarea actualizare Google Core Algorithm:
- Am stocat în cache câteva componente pentru fiecare pagină web și le-am făcut statice.
- Aceste pagini erau pagini importante de produse.
- Încă nu folosim etichete electronice din cauza infrastructurii site-ului.
- În special imaginile, resursele statice și unele părți importante de conținut sunt acum stocate complet în cache pe tot site-ul.
- Am început să folosim codul dns-prefetch pentru unele resurse externalizate uitate.
- Încă nu folosim codul de preîncărcare, dar lucrăm la călătoria utilizatorului pe site pentru a-l implementa în viitor.
13. Optimizarea și minimizarea HTML, CSS și JS
Din cauza problemelor legate de infrastructura site-ului, nu erau atât de multe lucruri de făcut pentru viteza site-ului. Am încercat să reduc decalajul cu fiecare metodă posibilă, inclusiv ștergerea unor componente ale paginii. Pentru paginile de produse importante, am curățat structura codului HTML, am redus-o și am comprimat-o.
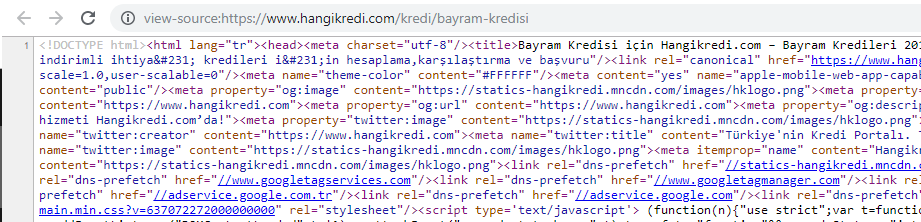
O captură de ecran din codul sursă al unuia dintre codurile sursă ale paginii noastre de produs sezoniere, dar importante. Utilizarea datelor structurate cu întrebări frecvente, reducerea HTML, optimizarea imaginilor, reîmprospătarea conținutului și legăturile interne ne-au oferit primul loc la momentul potrivit. (Cuvântul cheie este „Bayram Kredisi” în turcă, adică „credit de vacanță”)
De asemenea, am implementat CSS Factoring, Refactoring și JS Compression parțial cu pași mici. Când clasamentul a scăzut, am examinat diferența de viteză a site-ului dintre paginile concurenței noastre și ale noastre. Alegesem niște pagini urgente pe care le puteam grăbi. De asemenea, am purificat și comprimat parțial fișierele CSS critice de pe aceste pagini. Am inițiat procesul de eliminare a unora dintre fișierele JS terțe utilizate de diferite departamente ale companiei, dar acestea nu au fost încă eliminate. Pentru unele pagini de produse, am putut modifica și ordinea de încărcare a resurselor.
Examinarea concurenților
Pe lângă fiecare îmbunătățire tehnică SEO, inspectarea concurenților a fost cel mai bun ghid pentru a înțelege natura și obiectivele actualizării algoritmului de bază. Am folosit câteva programe utile și utile pentru a urmări schimbările de design, conținut, rang și tehnologie ale concurenților mei.
- Pentru modificările de clasare a cuvintelor cheie, am folosit Wincher, Semrush și Ahrefs.
- Pentru mențiuni de marcă, am folosit Google Alerts, BuzzSumo, Talkwalker.
- Pentru link-uri noi și rapoarte noi de obținere a cuvintelor cheie am folosit Ahrefs Alert.
- Pentru modificări de conținut și design, am folosit Visualping.
- Pentru schimbările tehnologice, am folosit SimilarTech.
- Pentru Știri și inspecție Google Update, am folosit în principal Semrush Sensor, Algoroo și CognitiveSEO Signals.
- Pentru a inspecta istoricul URL-urilor concurenților, am folosit Wayback Machine.
- Pentru viteza serverului concurenților, am folosit Chrome DevTools și ByteCheck.
- Pentru costul de accesare cu crawlere și randare, am folosit „Cât costă site-ul meu”. (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.