
Prognoza traficului SEO cu Prophet și Python
Publicat: 2021-03-16Stabilirea de obiective și evaluarea realizării în timp este un exercițiu foarte interesant pentru a înțelege ce suntem capabili să realizăm și dacă strategia pe care o folosim este eficientă sau nu. Cu toate acestea, de obicei nu este atât de ușor să stabilim aceste ținte, deoarece mai întâi va trebui să venim cu o prognoză.
Crearea unei prognoze nu este un lucru fără efort, dar datorită unor proceduri de prognoză disponibile, procesorului nostru și a unor abilități de programare îi putem reduce complexitatea destul de mult. În această postare, vă voi arăta cum putem face predicții precise și cum puteți aplica acest lucru la SEO folosind Python și biblioteca Profet și fără a fi nevoie să aveți superputeri ghicitoare.
Dacă nu ai auzit niciodată despre Profet, s-ar putea să te întrebi ce este. Pe scurt, Prophet este o procedură de prognoză care a fost lansată de echipa Core Data Science a Facebook, care este disponibilă în Python și R și care tratează foarte bine valorile aberante și efectele sezoniere pentru
oferiți predicții precise și rapide.
Când vorbim despre prognoză, trebuie să luăm în considerare două lucruri:
- Cu cât avem mai multe date istorice, cu atât modelul nostru și, prin urmare, predicțiile noastre vor fi mai precise.
- Modelul predictiv va fi valabil doar dacă factorii interni rămân aceiași și nu există factori externi care să-l afecteze. Aceasta înseamnă că, de exemplu, dacă publicăm o postare pe săptămână și începem să publicăm două postări pe săptămână, acest model ar putea să nu fie valid pentru a prezice care va fi rezultatul acestei schimbări de strategie. Pe de altă parte, dacă există o actualizare a algoritmului, este posibil ca nici modelul să nu fie valid. Rețineți că modelul este construit pe baza datelor istorice.
Pentru a aplica acest lucru la SEO, ceea ce vom face este să anticipăm sesiunile SEO pentru luna următoare, urmând următorii pași:
- Obținerea de date de la Google Analytics despre sesiunile organice pentru o anumită perioadă de timp.
- Pregătirea modelului nostru.
- Prognoza traficului SEO pentru luna viitoare.
- Evaluarea cât de bun este modelul nostru cu eroarea medie absolută.
Doriți să aflați mai multe despre cum funcționează această procedură de prognoză? Să începem atunci!
Obținerea datelor de la Google Analytics
Putem aborda extragerea datelor din Google Analytics în două moduri: exportând un fișier Excel din interfața normală sau folosind API-ul pentru a prelua aceste date.
Importul datelor dintr-un fișier Excel
Cel mai simplu mod de a obține aceste date din Google Analytics este să accesați secțiunea Canale din bara laterală, să faceți clic pe Organic și să exportați datele cu butonul din partea de sus a paginii. Asigurați-vă că selectați din meniul drop-down din partea de sus a graficului variabila pe care doriți să o analizați, în acest caz Sessions.
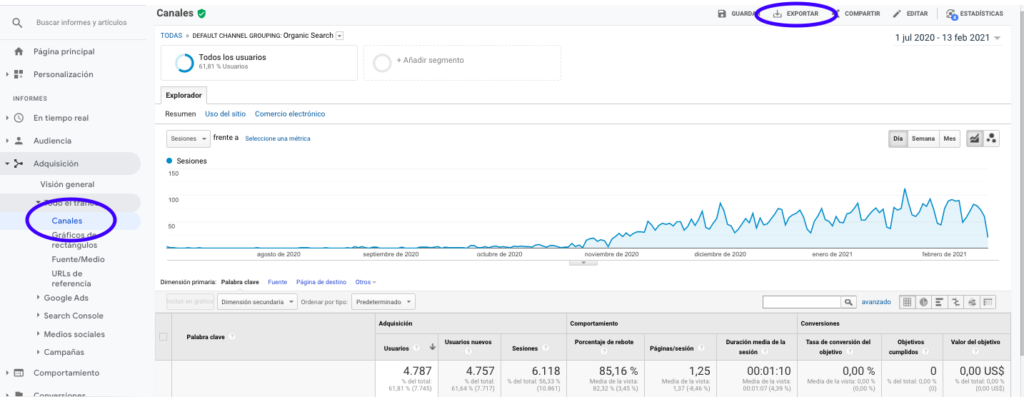
După exportarea datelor ca fișier Excel, le putem importa în notebook-ul nostru cu Pandas. Rețineți că fișierul Excel cu astfel de date va conține file diferite, astfel încât fila cu traficul lunar trebuie specificată ca argument în fragmentul de cod care este mai jos. De asemenea, ștergem ultimul rând pentru că conține cantitatea totală de sesiuni, ceea ce ar distorsiona modelul nostru.
importa panda ca pd
df = pd.read_excel ('.xlsx', sheet_name= "")
df = df.drop(len(df) - 1)
Putem desena cu Matplotlib cum arată datele:
din matplotlib import pyplot
df["Sesiones"].plot(title = "Sesiones")
pyplot.show() 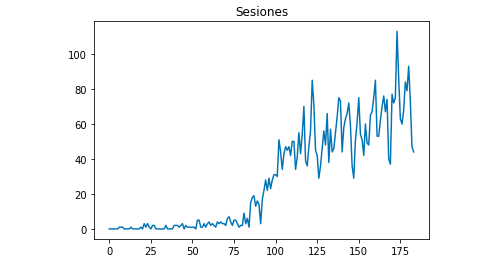
Utilizarea API-ului Google Analytics
În primul rând, pentru a utiliza API-ul Google Analytics, trebuie să creăm un proiect pe consola pentru dezvoltatori Google, să activăm serviciul de raportare Google Analytics și să obținem acreditările. Jean-Christophe Chouinard explică foarte bine în acest articol cum să configurați acest lucru.
Odată ce acreditările sunt obținute, atunci trebuie să ne autentificăm înainte de a face cererea noastră. Autentificarea trebuie făcută cu fișierul de acreditări care a fost obținut inițial din consola pentru dezvoltatori Google. De asemenea, va trebui să notăm în codul nostru ID-ul GA View de la proprietatea pe care dorim să o folosim.
din apiclient.discovery import build
din oauth2client.service_account import ServiceAccountCredentials
SCOPE = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
VEDERE_
credentials = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
analytics = build('analyticsreporting', 'v4', credentials=credentials)După autentificare, trebuie doar să facem cererea. Cel pe care trebuie să îl folosim pentru a obține datele despre sesiunile organice pentru fiecare zi este:
răspuns = analytics.reports().batchGet(body={
'reportRequests': [{
„viewId”: VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
„metrics”: [
{"expression": "ga:sessions"}
], "dimensiuni": [
{"nume": "ga:data"}
],
"filtersExpression":"ga:channelGrouping=~Organic",
"includeEmptyRows": "adevărat"
}]}).a executa()Rețineți că selectăm intervalul de timp în intervalul de date. În cazul meu, voi prelua date de la 1 septembrie până la 31 ianuarie: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
După aceasta, trebuie doar să preluăm fișierul de răspuns pentru a adăuga la o listă zilele cu sesiunile lor organice:
list_values = [] pentru x ca răspuns["rapoarte"][0]["date"]["rânduri"]: list_values.append([x[„dimensiuni”][0],x[„valori”][0][„valori”][0]])
După cum puteți vedea, utilizarea API-ului Google Analytics este destul de simplă și poate fi folosită pentru multe obiective. În acest articol, am explicat cum puteți utiliza API-ul Google Analytics pentru a crea alerte pentru a detecta paginile slabe.

Adaptarea listelor la Dataframes
Pentru a folosi Prophet, trebuie să introducem un Dataframe cu două coloane care trebuie denumite: „ds” și „y”. Dacă ați importat datele dintr-un fișier Excel, le avem deja ca Dataframe, așa că va trebui doar să numiți coloanele „ds” și „y”:
df.columns = ['ds', 'y']
În cazul în care ați folosit API-ul pentru a prelua datele, atunci trebuie să transformăm lista într-un cadru de date și să numim coloanele după cum este necesar:
din panda import DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
Antrenarea modelului
Odată ce avem Dataframe-ul cu formatul necesar, ne putem determina și antrena foarte ușor modelul cu:
import fbprophet din fbprophet import Prophet model = Profet() model.fit(df_sessions)
Făcând predicțiile noastre
În sfârșit, după antrenarea modelului nostru putem începe să prognozăm! Pentru a continua cu predicțiile, va trebui mai întâi să creăm o listă cu intervalul de timp pe care am dori să-l prezicem și să ajustăm formatul de dată și oră:
de la importul panda la_datetime forecast_days = [] pentru x în interval (1, 28): data = "2021-02-" + str(x) forecast_days.append([data]) forecast_days = DataFrame(forecast_days) forecast_days.columns = ['ds'] forecast_days['ds']= to_datetime(forecast_days['ds'])
În acest exemplu, folosesc o buclă care va crea un cadru de date care va conține toate zilele din februarie. Și acum este doar o chestiune de a folosi modelul care a fost antrenat anterior:
prognoza = model.predict(forecast_days)
Putem trasa o diagramă care evidențiază perioada de timp prognozată:
din matplotlib import pyplot model.plot(prognoză) pyplot.show()
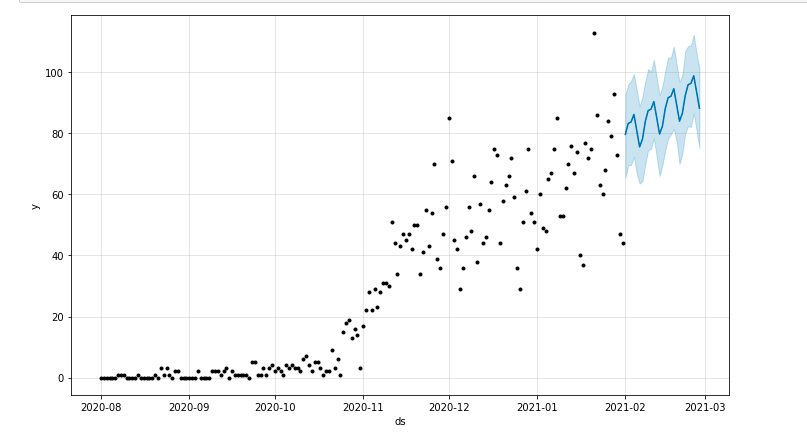
Evaluarea modelului
În cele din urmă, putem evalua cât de precis este modelul nostru eliminând câteva zile din datele care sunt utilizate pentru antrenamentul modelului, prognozând sesiunile pentru acele zile și calculând eroarea medie absolută.
De exemplu, ceea ce voi face este să elimin din cadrul de date original ultimele 12 zile din ianuarie, prognozând sesiunile pentru fiecare zi și comparând traficul real cu cel prognozat.
Mai întâi eliminăm din cadrul de date original ultimele 12 zile cu pop și creăm un nou cadru de date care va include doar acele 12 zile care vor fi folosite pentru prognoză:
tren = df_sessions.drop(df_sessions.index[-12:]) viitor = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Acum antrenăm modelul, facem prognoza și calculăm eroarea medie absolută. În final, putem desena un grafic care să arate diferența dintre valorile reale prognozate și cele reale. Acesta este ceva ce am învățat din acest articol scris de Jason Brownlee.
din sklearn.metrics import mean_absolute_error
import numpy ca np
din matricea de import numpy
#Pregăm modelul
model = Profet()
model.fit(tren)
#Adaptați cadrul de date care este utilizat pentru zilele de prognoză la formatul cerut de Prophet.
viitor = lista(viitor)
viitor = DataFrame(viitor)
viitor = future.rename(columns={0: 'ds'})
# Facem prognoza
previziune = model.predict(viitor)
# Calculăm MAE între valorile reale și valorile prezise
y_true = df_sessions['y'][-12:].valori
y_pred = prognoză['yhat'].valori
mae = mean_absolute_error(y_true, y_pred)
# Graficăm rezultatul final pentru o înțelegere vizuală
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='Actual')
pyplot.plot(y_pred, label='Previzat')
pyplot.legend()
pyplot.show()
print(mae) 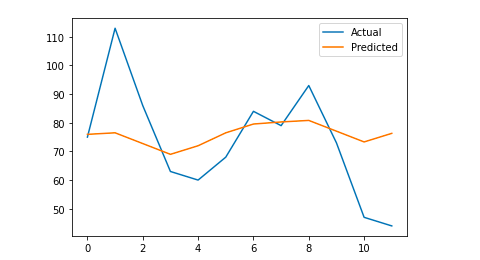
Eroarea mea absolută medie este 13, ceea ce înseamnă că modelul meu prognozat atribuie în fiecare zi cu 13 sesiuni mai multe decât cele reale, ceea ce pare a fi o eroare acceptabilă.
Asta e tot oameni buni! Sper că ați găsit acest articol interesant și puteți începe să vă faceți predicții SEO pentru a vă stabili obiective.
Mergând mai departe: OnCrawl Labs
Dacă v-a plăcut să vă prognozați traficul cu această metodă, veți fi, de asemenea, interesat de OnCrawl Labs, laboratorul OnCrawl de știință a datelor și de învățare automată care oferă proiecte precodificate pentru fluxurile dvs. de lucru SEO.
În prognoza SEO, OnCrawl Labs vă va ajuta să vă îmbunătățiți proiecțiile SEO:
- Obțineți o mai bună înțelegere a teoriilor și procesului din spatele algoritmului Facebook Prophet
- Analizați un segment de trafic, cum ar fi traficul numai pentru cuvintele cheie cu coadă lungă sau numai pentru cuvintele cheie de marcă...
- Urmați un proces pas cu pas pentru a stabili evenimentele istorice, ajustându-le influența și probabilitatea de a se repeta.