
Cum se extrage conținut text relevant dintr-o pagină HTML?
Publicat: 2021-10-13Context
În departamentul de cercetare și dezvoltare al Oncrawl, căutăm din ce în ce mai mult să adăugăm valoare conținutului semantic al paginilor dvs. web. Folosind modele de învățare automată pentru procesarea limbajului natural (NLP), este posibil să se realizeze sarcini cu valoare adăugată reală pentru SEO.
Aceste sarcini includ activități precum:
- Reglați fin conținutul paginilor dvs
- Realizarea de rezumate automate
- Adăugarea de noi etichete la articolele dvs. sau corectarea celor existente
- Optimizarea conținutului în funcție de datele din Google Search Console
- etc.
Primul pas în această aventură este extragerea conținutului text al paginilor web pe care le vor folosi aceste modele de învățare automată. Când vorbim despre pagini web, acestea includ HTML, JavaScript, meniuri, media, antet, subsol,... Extragerea automată și corectă a conținutului nu este ușoară. Prin acest articol îmi propun să explorez problema și să discutăm câteva instrumente și recomandări pentru realizarea acestei sarcini.
Problemă
Extragerea conținutului text dintr-o pagină web poate părea simplă. Cu câteva linii de Python, de exemplu, câteva expresii regulate (regexp), o bibliotecă de analiză precum BeautifulSoup4 și este gata.
Dacă ignori pentru câteva minute faptul că tot mai multe site-uri folosesc motoare de randare JavaScript precum Vue.js sau React, analiza HTML nu este foarte complicată. Dacă doriți să conturați această problemă profitând de crawler-ul nostru JS în crawlerele dvs., vă sugerez să citiți „Cum să accesați cu crawlere un site în JavaScript?”.
Cu toate acestea, dorim să extragem text care are sens, care este cât mai informativ posibil. Când citești un articol despre ultimul album postum al lui John Coltrane, de exemplu, ignori meniurile, subsolul, … și, evident, nu vezi întregul conținut HTML. Aceste elemente HTML care apar pe aproape toate paginile tale se numesc boilerplate. Vrem să scăpăm de el și să păstrăm doar o parte: textul care poartă informații relevante.
Prin urmare, doar acest text dorim să-l transmitem modelelor de învățare automată pentru procesare. De aceea este esențial ca extracția să fie cât mai calitativă.
Soluții
În general, am dori să scăpăm de tot ce „atârnă” textul principal: meniuri și alte bare laterale, elemente de contact, link-uri de subsol etc. Există mai multe metode pentru a face acest lucru. Suntem mai ales interesați de proiecte Open Source în Python sau JavaScript.
doarText
jusText este o implementare propusă în Python dintr-o teză de doctorat: „Removing Boilerplate and Duplicate Content from Web Corpora”. Metoda permite ca blocurile de text din HTML să fie clasificate ca „bune”, „rele”, „prea scurte” în funcție de diferite euristici. Aceste euristici se bazează în mare parte pe numărul de cuvinte, raportul text/cod, prezența sau absența legăturilor etc. Puteți citi mai multe despre algoritm în documentație.
trafilatura
trafilatura, creată și în Python, oferă euristici atât pentru tipul de element HTML, cât și pentru conținutul acestuia, de exemplu lungimea textului, poziția/adâncimea elementului în HTML sau numărul de cuvinte. trafilatura folosește și justText pentru a efectua unele procesări.
lizibilitatea
Ați observat vreodată butonul din bara URL a Firefox? Este vizualizarea cititorului: vă permite să eliminați boilerplate din paginile HTML pentru a păstra doar conținutul textului principal. Destul de practic de utilizat pentru site-urile de știri. Codul din spatele acestei caracteristici este scris în JavaScript și se numește lizibilitate de către Mozilla. Se bazează pe munca inițiată de laboratorul Arc90.
Iată un exemplu despre cum să redați această caracteristică pentru un articol de pe site-ul France Musique. 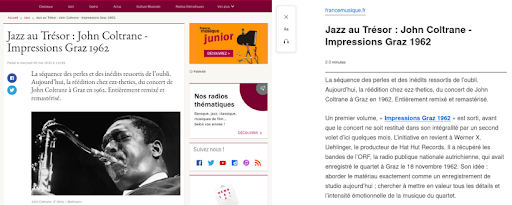
În stânga, este un extras din articolul original. În dreapta, este o redare a funcției Reader View în Firefox.
Alții
Cercetările noastre privind instrumentele de extragere a conținutului HTML ne-au determinat să luăm în considerare și alte instrumente:
- ziar: o bibliotecă de extracție de conținut mai degrabă dedicată site-urilor de știri (Python). Această bibliotecă a fost folosită pentru a extrage conținut din corpus OpenWebText2.
- boilerpy3 este un port Python al bibliotecii boilerpipe.
- Biblioteca dragnet Python inspirată și de boilerpipe.
Date oncrawl³
 Află mai multe
Află mai multeEvaluare și recomandări
Înainte de a evalua și compara diferitele instrumente, am dorit să știm dacă comunitatea NLP folosește unele dintre aceste instrumente pentru a-și pregăti corpus (set mare de documente). De exemplu, setul de date numit The Pile folosit pentru a antrena GPT-Neo are +800 GB de texte în limba engleză de la Wikipedia, Openwebtext2, Github, CommonCrawl etc. La fel ca BERT, GPT-Neo este un model de limbaj care utilizează transformatoare de tip. Oferă o implementare open-source similară cu arhitectura GPT-3.

Articolul „The Pile: An 800GB Dataset of Diverse Text for Language Modeling” menționează utilizarea justText pentru o mare parte a corpusului lor din CommonCrawl. Acest grup de cercetători plănuise, de asemenea, să facă un etalon al diferitelor instrumente de extracție. Din păcate, aceștia nu au putut face munca planificată din cauza lipsei de resurse. În concluziile lor, trebuie menționat că:
- justText a eliminat uneori prea mult conținut, dar a oferit totuși o calitate bună. Având în vedere cantitatea de date pe care le aveau, aceasta nu a fost o problemă pentru ei.
- Trafilatura a fost mai bună la păstrarea structurii paginii HTML, dar a păstrat prea mult boilerplate.
Pentru metoda noastră de evaluare, am luat aproximativ treizeci de pagini web. Am extras conținutul principal „manual”. Am comparat apoi extragerea textului diferitelor instrumente cu acest așa-numit conținut „de referință”. Am folosit scorul ROUGE, care este folosit în principal pentru a evalua rezumatele automate ale textului, ca măsură.
De asemenea, am comparat aceste instrumente cu un instrument „de casă” bazat pe regulile de analiză HTML. Se pare că trafilatura, justText și instrumentul nostru de casă se descurcă mai bine decât majoritatea altor instrumente pentru această măsurătoare.
Iată un tabel cu mediile și abaterile standard ale scorului ROUGE:
| Instrumente | Rău | Std |
|---|---|---|
| trafilatura | 0,783 | 0,28 |
| Oncrawl | 0,779 | 0,28 |
| doarText | 0,735 | 0,33 |
| boilerpy3 | 0,698 | 0,36 |
| lizibilitatea | 0,681 | 0,34 |
| năvod | 0,672 | 0,37 |
Având în vedere valorile abaterilor standard, rețineți că calitatea extracției poate varia foarte mult. Modul în care este implementat HTML-ul, consistența etichetelor și utilizarea adecvată a limbajului pot cauza multe variații în rezultatele extragerii.
Cele trei instrumente care funcționează cel mai bine sunt trafilatura, instrumentul nostru intern numit „oncrawl” pentru ocazie și justText. Deoarece jusText este folosit ca alternativă prin trafilatura, am decis să folosim trafilatura ca primă alegere. Cu toate acestea, atunci când acesta din urmă eșuează și extrage zero cuvinte, folosim propriile noastre reguli.
Rețineți că codul de trafilatura oferă și un benchmark pe câteva sute de pagini. Acesta calculează scorurile de precizie, scorul f1 și acuratețea pe baza prezenței sau absenței anumitor elemente în conținutul extras. Se remarcă două instrumente: trafilatura și gâscă3. Poate doriți să citiți și:
- Alegerea instrumentului potrivit pentru a extrage conținut de pe Web (2020)
- depozitul Github: punct de referință pentru extracția articolelor: biblioteci open-source și servicii comerciale
Concluzii
Calitatea codului HTML și eterogenitatea tipului de pagină fac dificilă extragerea conținutului de calitate. După cum au descoperit cercetătorii EleutherAI – care se află în spatele The Pile și GPT-Neo –, nu există instrumente perfecte. Există un compromis între conținutul uneori trunchiat și zgomotul rezidual din text atunci când nu a fost îndepărtat toată placa.
Avantajul acestor instrumente este că sunt fără context. Aceasta înseamnă că nu au nevoie de alte date decât HTML-ul unei pagini pentru a extrage conținutul. Folosind rezultatele Oncrawl, ne-am putea imagina o metodă hibridă folosind frecvențele de apariție a anumitor blocuri HTML în toate paginile site-ului pentru a le clasifica ca boilerplate.
În ceea ce privește seturile de date utilizate în benchmark-urile pe care le-am întâlnit pe Web, acestea sunt adesea de același tip de pagină: articole de știri sau postări de blog. Acestea nu includ neapărat site-uri de asigurări, agenții de turism, comerț electronic etc. unde conținutul textului este uneori mai complicat de extras.
În ceea ce privește reperul nostru și din cauza lipsei de resurse, suntem conștienți că aproximativ treizeci de pagini nu sunt suficiente pentru a obține o imagine mai detaliată a scorurilor. În mod ideal, am dori să avem un număr mai mare de pagini web diferite pentru a ne rafina valorile de referință. Și am dori să includem și alte instrumente precum goose3, html_text sau inscriptis.