
Extrageți date din API-ul Google Search Console pentru analiza datelor în Python
Publicat: 2022-03-01Google Search Console (GSC) este cu siguranță unul dintre cele mai utile instrumente pentru specialiștii SEO, deoarece vă permite să obțineți informații despre acoperirea indexului și în special interogările pentru care vă clasați în prezent. Știind acest lucru, mulți oameni analizează datele GSC folosind foi de calcul și este bine, atâta timp cât înțelegeți că există mult mai mult loc de îmbunătățire cu instrumente precum limbajele de programare.
Din păcate, interfața GSC este destul de limitată atât în ceea ce privește rândurile afișate (doar 5000), cât și perioada de timp disponibilă, doar 16 luni. Este clar că acest lucru vă poate limita sever capacitatea de a obține informații și nu este potrivit pentru site-uri web mai mari.
Python vă permite să obțineți cu ușurință date GSC și să automatizați calcule mai complexe, care ar necesita mult mai mult efort în software-ul tradițional pentru foi de calcul.
Aceasta este soluția pentru una dintre cele mai mari probleme din Excel, și anume limita de rând și viteza. În zilele noastre, aveți mult mai multe alternative pentru a analiza datele decât înainte și aici intervine Python.
Nu aveți nevoie de cunoștințe avansate de codificare pentru a urma acest tutorial, ci doar înțelegerea unor concepte de bază și ceva practică cu Google Colab.
Noțiuni introductive cu API-ul Google Search Console
Înainte de a începe, este important să configurați API-ul Google Search Console. Procesul este destul de simplu, tot ce aveți nevoie este un cont Google. Pașii sunt următorii:
- Creați un nou proiect pe Google Cloud Platform. Ar trebui să aveți un cont Google și sunt destul de sigur că aveți unul. Accesați consolă și apoi ar trebui să găsiți o opțiune în partea de sus pentru a crea un nou proiect.
- Faceți clic pe meniul din stânga și selectați „API și servicii”, veți ajunge la un alt ecran.
- Din bara de căutare din partea de sus, căutați „Google Search Console API” și activați-l.
- Apoi treceți la fila „Acreditări”, aveți nevoie de un fel de permisiune pentru a utiliza API-ul.
- Configurați ecranul „consimțământ”, deoarece acesta este obligatoriu. Nu contează pentru utilizarea pe care o vom face dacă este publică sau nu.
- Puteți alege „Desktop App” pentru tipul de aplicație
- Vom folosi OAuth 2.0 pentru acest tutorial, ar trebui să descărcați un fișier json și acum ați terminat.
Aceasta este de fapt cea mai grea parte pentru majoritatea oamenilor, în special pentru cei care nu sunt obișnuiți cu API-urile Google. Nu vă faceți griji, următorii pași vor fi mult mai ușori și mai puțin problematici.
Obținerea datelor din API-ul Google Search Console cu Python
Recomandarea mea este să utilizați un notebook precum Jupyter Notebook sau Google Colab. Acesta din urmă este mai bun, deoarece nu trebuie să vă faceți griji cu privire la cerințe. Prin urmare, ceea ce voi explica se bazează pe Google Colab.
Înainte de a începe, actualizați fișierul json la Google Colab cu următorul cod:
din fișierele de import google.colab files.upload()
Apoi, să instalăm toate bibliotecile de care vom avea nevoie pentru analiza noastră și să facem o vizualizare mai bună a tabelului cu acest fragment de cod:
%%captură #încărcați ceea ce este necesar !pip install git+https://github.com/joshcarty/google-searchconsole importa panda ca pd import numpy ca np import matplotlib.pyplot ca plt din google.colab import data_table !git clona https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip instalează umap-learn data_table.enable_dataframe_formatter() #pentru o mai bună vizualizare a tabelului
În cele din urmă, puteți încărca biblioteca searchconsole, care oferă cel mai simplu mod de a face acest lucru fără a vă baza pe funcții lungi. Rulați următorul cod cu argumentele pe care le folosesc și asigurați-vă că client_config are același nume cu fișierul json încărcat.
import searchconsole cont = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Veți fi redirecționat către o pagină Google pentru autorizarea aplicației, selectați contul dvs. Google și apoi copiați și lipiți codul pe care îl veți primi în bara Google Colab.
Încă nu am terminat, trebuie să selectați proprietatea pentru care veți avea nevoie de date. Vă puteți verifica cu ușurință proprietățile prin account.webproperties pentru a vedea ce ar trebui să alegeți.
property_name = input('Inserați numele site-ului dvs. așa cum este listat în GSC: ')
webproperty=cont[str(nume_proprietate)]
După ce ați terminat, veți rula o funcție personalizată pentru a crea un obiect care conține datele noastre.
def extract_gsc_data(webproperty, start, stop, *args):
dacă proprietatea web nu este Niciunul:
print(f'Extragerea datelor pentru {webproperty}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
returnează gsc_data
altceva:
print('Proprietatea web nu a fost găsită, vă rugăm să selectați cea corectă')
return Niciunul
Ideea funcției este de a lua proprietatea pe care ați definit-o înainte și un interval de timp, sub formă de date de început și de sfârșit, împreună cu dimensiuni.
Alegerea de a putea selecta dimensiuni este crucială pentru specialiștii SEO, deoarece vă permite să înțelegeți dacă aveți nevoie de un anumit nivel de granularitate. De exemplu, este posibil să nu fiți interesat să obțineți dimensiunea dată, în unele cazuri.
Sugestia mea este să alegeți întotdeauna interogarea și pagina, deoarece interfața Google Search Console le poate exporta separat și este foarte enervant să le îmbinați de fiecare dată. Acesta este un alt beneficiu al API-ului Search Console.
În cazul nostru putem obține direct și dimensiunea datei, pentru a arăta câteva scenarii interesante în care trebuie să țineți cont de timp.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'query', 'page', 'data')
Selectați un interval de timp adecvat, având în vedere că pentru proprietăți mai mari va trebui să așteptați mult timp. Pentru acest exemplu, mă gândesc doar la un interval de timp de 3 luni, care este suficient pentru a obține informații valoroase din majoritatea seturilor de date, în medie.
Puteți selecta chiar și o săptămână dacă aveți de-a face cu o cantitate imensă de date, ceea ce ne pasă este procesul.
Ceea ce vă voi arăta aici se bazează fie pe date sintetice, fie pe date reale modificate de dragul de a fi potrivite pentru exemple. În consecință, ceea ce vedeți aici este total realist și poate reflecta scenarii din lumea reală.
Curățarea datelor
Pentru cei care nu știu, nu putem folosi datele noastre așa cum sunt, există câțiva pași suplimentari pentru a ne asigura că lucrăm corect. În primul rând, trebuie să ne transformăm obiectul într-un cadru de date Pandas, o structură de date cu care trebuie să fii familiarizat, deoarece este baza analizei datelor în Python.
df = pd.DataFrame(data=ex) df.head()
Metoda head poate afișa primele 5 rânduri ale setului dvs. de date, este foarte util să aruncați o privire la cum arată datele dvs. Putem număra câte pagini avem folosind o funcție simplă.
O modalitate bună de a elimina duplicatele este de a converti un obiect într-un set, deoarece seturile nu pot conține elemente duplicate.
Unele dintre fragmentele de cod au fost inspirate din caietul lui Hamlet Batista și din altul de la Masaki Okazawa.
Eliminarea termenilor de marcă
Primul lucru de făcut este să eliminați cuvintele cheie de marcă, căutăm acele interogări care nu conțin termenii noștri de marcă. Acest lucru este destul de simplu de făcut cu o funcție personalizată și, de obicei, veți avea un set de termeni de marcă.
În scopuri demonstrative, nu trebuie să le filtrați pe toate, dar vă rugăm să o faceți pentru analize reale. Este unul dintre cei mai importanți pași de curățare a datelor în SEO, altfel riscați să prezentați rezultate înșelătoare.
nume_domeniu = str(input('Inserați termenii mărcii separați prin virgulă: ')).replace(',', '|')
import re
nume_domeniu = re.sub(r"\s+", "", nume_domeniu)
print('Eliminați toate spațiile folosind RegEx:\n')
df['Brand/Non-branded'] = np.where(
df['query'].str.contains(domain_name), 'Brand', 'Non-branded'
)
Vom adăuga o nouă coloană la setul nostru de date pentru a recunoaște diferența dintre cele două clase. Putem vizualiza prin tabele sau diagrame cu bare cât de mult reprezintă ele pentru numărul total de interogări.
Nu vă voi arăta barplotul deoarece este foarte simplu și cred că un tabel este mai bun pentru acest caz.
brand_count_df = df['Brand/Non-branded'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Procentaj'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Puteți vedea rapid care este raportul dintre cuvintele cheie de marcă și cele fără marcă pentru a vă face o idee despre cât de mult veți elimina din setul de date. Nu există un raport ideal aici, deși cu siguranță doriți să aveți un procent mai mare de cuvinte cheie fără marcă.
Apoi, putem să aruncăm toate rândurile marcate ca marcă și să trecem cu alți pași.
#selectați doar cuvinte cheie fără marcă df = df.loc[df['Brand/Non-branded'] == 'Fără brand']
Completarea valorilor lipsă și alți pași
Dacă setul de date conține valori lipsă (sau NA în jargon), aveți mai multe opțiuni. Cele mai obișnuite sunt fie să le renunți pe toate, fie să le completezi cu o valoare de substituent precum 0 sau media acelei coloane.
Nu există un răspuns corect și ambele abordări au argumente pro și contra, precum și riscuri. Pentru datele din Google Search Console, cel mai bun sfat este să puneți o valoare de substituent precum 0, pentru a subestima efectul unor valori.
df.fillna(0, inplace = True)
Înainte de a trece la analiza reală a datelor, trebuie să ne adaptăm caracteristicile, și anume coloanele setului nostru de date. Poziția este deosebit de interesantă, deoarece vrem să o folosim pentru niște tabele pivot interesante.
Putem rotunji poziția pentru a fi un număr întreg, ceea ce ne servește scopului.
df['poziție'] = df['poziție'].round(0).astype('int64')
Ar trebui să urmați toți ceilalți pași de curățare descriși mai sus și apoi să ajustați coloana de dată.
Extragem luni și ani cu ajutorul panda. Nu trebuie să fii atât de specific dacă lucrezi cu un interval de timp mai scurt, acesta este un exemplu care ia în considerare jumătate de an.
#convertiți data în formatul adecvat df['data'] = pd.to_datetime(df['data']) #extract luni df['lună'] = df['data'].dt.lună #extract ani df['an'] = df['data'].dt.an
[Ebook] Data SEO: următoarea mare aventură
 Citiți cartea electronică
Citiți cartea electronicăAnaliza exploratorie a datelor
Principalul avantaj al Python este că poți face aceleași lucruri pe care le faci în Excel, dar cu multe mai multe opțiuni și mai ușor. Să începem cu ceva pe care fiecare analist îl știe foarte bine: tabele pivot.
Analizând CTR mediu pe grup de poziții
Se analizează medie CTR per grup de poziții este una dintre cele mai perspicace activități, deoarece vă permite să înțelegeți situația generală a unui site web. Aplicați pivotul și apoi să-l trasăm.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['poziție'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['poziție'], ascending=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Poziție medie')
ax.set_ylabel('CTR')
ax.set_title('CTR după poziția medie')
ax.grid('on')
ax.get_legend().remove()
plt.xticks(rotation=0)
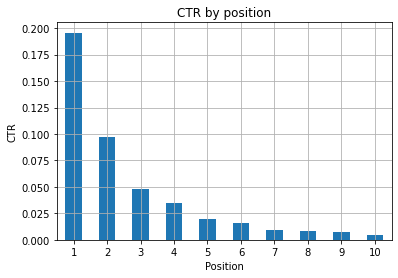
Figura 1: Reprezentarea CTR după poziție pentru a detecta anomaliile.
Scenariul ideal aici este să aveți un CTR mai bun în partea stângă a graficului, deoarece în mod normal rezultatele din Poziția 1 ar trebui să prezinte un CTR mult mai mare. Ai grijă totuși, s-ar putea să vezi unele cazuri în care primele 3 puncte au un CTR mai mic decât cel așteptat și trebuie să investigați.
Vă rugăm să luați în considerare și cazurile marginale, de exemplu cele în care poziția 11 este mai bună decât a fi primul. După cum se explică în documentația Google pentru Search Console, această valoare nu urmează ordinea pe care o credeți la început.
Mai mult, adaugă că această măsurătoare este o medie, deoarece poziția link-ului se schimbă de fiecare dată și este imposibil să aveți o acuratețe de 100%.
Uneori, paginile tale au un rang ridicat, dar nu sunt suficient de convingătoare, așa că ai putea încerca să repari titlul. Deoarece aceasta este o prezentare generală la nivel înalt, nu veți vedea diferențe granulare, așa că așteptați-vă să acționați rapid dacă această problemă este la scară largă.
Fiți conștienți și atunci când un grup de pagini aflate în poziții inferioare au un CTR mediu mai mare decât cele din locuri mai bune.
Din acest motiv, poate doriți să vă extindeți analiza până la poziția 15 sau mai mult, pentru a identifica tipare ciudate.
Numărul de interogări pe poziție și măsurarea eforturilor SEO
O creștere a interogărilor pentru care vă clasați este întotdeauna un semnal bun, dar nu înseamnă neapărat o clasare mai bună în viitor. Numărarea interogărilor este procesul de numărare a numărului de interogări pentru care vă clasați și este una dintre cele mai importante sarcini pe care le puteți face cu datele GSC.
Tabelele pivot sunt de mare ajutor încă o dată și putem reprezenta rezultatele.
ranking_queries = df.pivot_table(index=['poziție'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['poziție']).head(10)
Ceea ce doriți ca specialist SEO este să aveți un număr mai mare de interogări în partea din stânga, locurile de sus. Motivul este destul de natural, pozițiile înalte obțin în medie un CTR mai bun, ceea ce se poate traduce prin faptul că mai mulți oameni fac clic pe pagina ta.
ax = ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('Numărul de interogări')
ax.set_xlabel('Poziție')
ax.set_title('Distribuția clasamentului')
ax.grid('on')
ax.get_legend().remove()
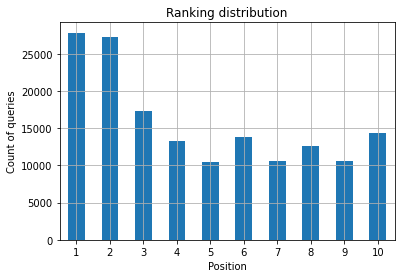
Figura 2: Câte interogări am în funcție de poziție?
Ceea ce vă interesează este creșterea numărului de interogări în primele poziții pe măsură ce trece timpul.
Jucând cu dimensiunea datei
Să vedem cum variază clicurile într-un interval de timp considerat, să obținem mai întâi suma clicurilor:
clicks_sum = df.groupby('data')['clicks'].sum()
Grupăm datele după dimensiunea datei și obținem suma clicurilor pentru fiecare dintre ele, este un tip de rezumat.
Acum suntem gata să trasăm ceea ce am primit, codul va fi destul de lung doar pentru a îmbunătăți vizualizarea, nu vă speriați de el.
# Suma clicurilor pe parcursul perioadei
%config InlineBackend.figure_format = 'retina'
din figura de import matplotlib.pyplot
figură(dimensiunea fig.=(8, 6), dpi=80)
ax = clicks_sum.plot(color='red')
ax.grid('on')
ax.set_ylabel(„Suma de clicuri”)
ax.set_xlabel('Lună')
ax.set_title(„Cum au variat clicurile pe o bază lunară”)
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('italic')
xlab.set_size(10)
ylab.set_style('italic')
ylab.set_size(10)
ttl = ax.titlu
ttl.set_weight('bold')
ax.spines['dreapta'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='galben')
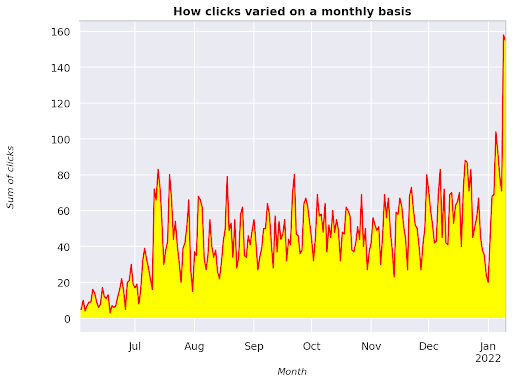

Figura 3: Graficul sumei clicurilor în raport cu variabila lună
Acesta este un exemplu începând din iunie 2021 și mergând direct până la jumătatea lunii ianuarie 2022. Toate rândurile pe care le vedeți mai sus au rolul de a face această vizualizare mai frumoasă, puteți încerca să vă jucați cu ea pentru a vedea ce se întâmplă.
Număr de interogări pe poziție, instantaneu lunar
O altă vizualizare grozavă pe care o putem reprezenta în Python este harta termică, care este chiar mai vizuală decât un simplu barplot. Vă voi arăta cum să afișați numărul de interogări în timp și în funcție de poziția sa.
import seaborn ca sns sns.set_theme() df_new = df.loc[(df['poziție'] <= 10) & (df['an'] != 2022),:] # Încărcați exemplul de setul de date despre zboruri și convertiți-l în format lung df_heat = df_new.pivot_table(index = "poziție", coloane = "lună", valori = "interogare", aggfunc='count') # Desenați o hartă termică cu valorile numerice din fiecare celulă f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["Septembrie", "Octombrie", "Noiembrie", "Decembrie"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Lună', ylabel='Poziție', title = 'Cum se modifică numărul de interogări pe poziție în timp') #rotate Etichetele de poziție pentru a le face mai lizibile plt.yticks(rotation=0)
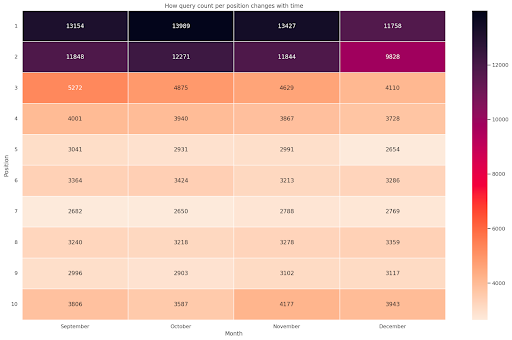
Figura 4: Hartă termică care arată progresul numărului de interogări în funcție de poziție și lună.
Aceasta este una dintre hărțile mele preferate, hărțile termice pot fi destul de eficiente pentru a afișa tabele pivot, cum ar fi în acest exemplu. Perioada se întinde pe 4 luni și dacă o citiți pe orizontală puteți vedea cum se modifică numărul de interogări pe măsură ce trece timpul. Pentru poziția 10 aveți o mică creștere din septembrie până în decembrie, dar pentru poziția 2 aveți o scădere izbitoare, așa cum arată culoarea violet.
În următorul scenariu, aveți majoritatea interogărilor în primele locuri, ceea ce poate fi izbitor de neobișnuit. Dacă se întâmplă acest lucru, poate doriți să reveniți și să analizați cadrul de date, căutând posibili termeni de marcă, dacă există.
După cum vedeți din cod, nu este atât de greu să faceți comploturi complexe, atâta timp cât aveți logica în spate.
Numărul de interogări ar trebui să crească odată cu trecerea timpului dacă faceți lucrurile „corecte” și putem reprezenta diferența în două intervale de timp diferite. În exemplul pe care l-am oferit, clar nu este cazul, mai ales pentru pozițiile de top, unde ar trebui să aveți un CTR mai mare.
Prezentarea unor concepte de bază NLP
Procesarea limbajului natural (NLP) este o mană cerească pentru SEO și nu trebuie să fii un expert pentru a aplica algoritmii de bază. N-gramele sunt una dintre cele mai puternice, dar simple idei care vă pot oferi informații despre datele GSC.
N-gramele sunt secvențe contigue de litere, silabe sau cuvinte. Pentru analiza noastră cuvintele vor fi unitatea de măsură. Un n-gram se numește bigram când elementele adiacente sunt două (o pereche) și trigramă dacă sunt trei și așa mai departe. Vă sugerez să testați cu diferite combinații și să mergeți până la cel mult 5 grame.
În acest fel, puteți identifica cele mai comune propoziții din paginile concurenților sau să le evaluați pe ale dvs. Deoarece Google se poate baza pe indexarea bazată pe fraze, este mai bine să optimizeze propoziții decât cuvintele cheie individuale, așa cum arată brevetele Google care implică acest subiect.
După cum a spus în pagina de mai sus de către Bill Slawski însuși, valoarea înțelegerii termenilor aferenti este de mare valoare pentru optimizare și pentru utilizatorii dvs.
Biblioteca nltk este foarte renumită pentru aplicațiile NLP și ne oferă posibilitatea de a elimina cuvintele oprite într-o anumită limbă, cum ar fi engleza. Gândiți-vă la ele ca la zgomot pe care doriți să îl eliminați, de fapt, articolele și cuvintele foarte frecvente nu adaugă nicio valoare în înțelegerea unui text.
import nltk
nltk.download('stopwords')
de la nltk.corpus importarea cuvintelor oprite
stoplist = stopwords.words('engleză')
din sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# matrice de ngrame
ngrams = c_vec.fit_transform(df['query'])
# frecvența de numărare a ngramelor
count_values = ngrams.toarray().sum(axis=0)
# listă de ngrame
vocab = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frecvenţă', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
Luăm coloana de interogare și numărăm frecvența bigramelor pentru a crea un cadru de date care stochează bigramele și numărul lor de apariții.
Acest pas este de fapt foarte important pentru a analiza și site-urile concurenților. Puteți pur și simplu să le răzuiți textul și să verificați care sunt cele mai comune n-grame, ajustând n de fiecare dată pentru a vedea dacă observați modele diferite pe paginile de rang înalt.
Dacă vă gândiți la asta pentru o secundă, are mult mai mult sens, deoarece un cuvânt cheie individual nu vă spune nimic despre context.
Fructe agățate
Unul dintre cele mai drăguțe lucruri de făcut este să verifici fructele care se agăță jos, acele pagini pe care le poți îmbunătăți ușor pentru a vedea rezultate bune cât mai devreme. Acest lucru este crucial în primii pași ai fiecărui proiect SEO pentru a vă convinge părțile interesate. Prin urmare, dacă există o oportunitate de a folosi astfel de pagini, doar fă-o!
Criteriile noastre pentru a considera o pagină ca atare sunt cuantile pentru afișări și CTR. Cu alte cuvinte, filtrăm rânduri care se află în primele 80% dintre afișări, dar se află în 20% care primesc cel mai mic CTR. Aceste rânduri vor avea un CTR mai slab decât 80% din restul.
top_impressions = df[df['afișări'] >= df['afișări'].quantile(0,8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0,2)].sort_values('afișări', crescător = False))
Acum aveți o listă cu toate oportunitățile sortate după Afișări, în ordine descrescătoare.
Puteți să vă gândiți la alte criterii pentru a defini ce este un fruct low-hanging, în funcție de nevoile site-ului dvs. și de dimensiunea acestuia.
Pentru site-urile web mai mici, vă puteți gândi să căutați procente mai mari, în timp ce în site-urile mari ar trebui să obțineți deja o mulțime de informații cu criteriile pe care le folosesc.
[Ebook] SEO tehnic pentru gânditori non-tehnici
 Citiți cartea electronică
Citiți cartea electronicăPrezentarea querycat: clasificare și asocieri
Querycat este o bibliotecă simplă, dar puternică, care include extragerea regulilor de asociere pentru gruparea cuvintelor cheie și multe altele. Vă voi arăta doar asociațiile deoarece sunt mai valoroase în acest tip de analiză.
Puteți afla mai multe despre această bibliotecă minunată aruncând o privire la depozitul querycat GitHub.
Scurtă introducere despre învățarea regulilor de asociere
Învățarea regulilor de asociere este o metodă de a găsi reguli care definesc asocierile și co-aparițiile între seturi de elemente. Aceasta este ușor diferită de o altă metodă de învățare automată nesupravegheată, așa-numita clustering.
Totuși, obiectivul final este același, obținerea de grupuri de cuvinte cheie pentru a înțelege cum merge site-ul nostru pentru anumite subiecte.
Querycat vă oferă posibilitatea de a alege între doi algoritmi: Apriori și FP-Growth. O să-l alegem pe cel din urmă pentru performanțe mai bune, așa că îl puteți ignora pe primul.
FP-Growth este o versiune îmbunătățită a Apriori pentru a găsi modele frecvente în seturile de date. Învățarea regulilor de asociere este foarte utilă și pentru tranzacțiile de comerț electronic, ați putea fi interesat să înțelegeți ce cumpără oamenii împreună, de exemplu.
În acest caz, accentul nostru este pus pe interogări, dar cealaltă aplicație pe care am menționat-o poate fi o altă idee utilă pentru datele Google Analytics.
Explicarea acestor algoritmi dintr-o perspectivă a structurii datelor este destul de dificilă și, în opinia mea, nu este necesară pentru sarcinile tale SEO. Voi explica doar câteva concepte de bază pentru a înțelege ce înseamnă parametrii.
Cele 3 elemente principale ale celor 2 algoritmi sunt:
- Suport – Exprimă popularitatea unui articol sau a unui set de articole. În cuvinte tehnice, este numărul de tranzacții în care interogarea X și interogarea Y apar împreună împărțit la numărul total de tranzacții.
Mai mult, poate fi folosit ca prag pentru a elimina articolele rare. Foarte util pentru creșterea semnificației statistice și a performanței. Stabilirea unui suport minim bun este foarte bine. - Încrederea – vă puteți gândi la ea ca la probabilitatea de apariție concomitentă pentru termeni.
- Creștere – Raportul dintre suportul pentru (termenul 1 și termenul 2) și suportul pentru termenul 1. Ne putem uita la valoarea acestuia pentru a obține informații despre relația dintre termeni. Dacă este mai mare de 1 termenii sunt corelați; dacă mai mic de 1 este puțin probabil ca termenii să aibă o asociere: dacă liftul este exact 1 (sau aproape) nu există o relație semnificativă.
Mai multe detalii sunt furnizate în acest articol despre querycat scris de autorul bibliotecii.
Acum suntem gata să trecem la partea practică.
import querycat
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('categorie').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#create grup pentru a filtra categoriile cu mai puțin de 15 clicuri (număr arbitrar)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
grup de filtrare
#aplica filtru
df = df.merge(filtergroup, on=['categorie','categorie'], cum='interior')
Am filtrat categorii mai puțin frecvente în acest proces, am ales 15 ca etalon în cazul meu. Este doar un număr arbitrar, nu există niciun criteriu în spate.
Să ne verificăm categoriile cu următorul fragment:
df['categorie'].value_counts()
Cum rămâne cu cele 10 categorii cu cele mai multe clicuri? Să verificăm câte interogări avem pentru fiecare dintre ele.
df.groupby('categorie').sum()['clicuri'].sort_values(crescator=False).head(10)
Numărul de ales este arbitrar, asigurați-vă că alegeți unul care filtrează un procent bun de grupuri. O idee potențială este să obțineți mediana afișărilor și să reduceți cel mai mic 50%, cu condiția să doriți să excludeți grupurile mici.
Obținerea clusterelor și ce trebuie făcut cu rezultatul
Recomandarea mea este să exportați noul cadru de date pentru a evita rularea FP-Growth din nou, vă rugăm să faceți acest lucru pentru a economisi timp util.
De îndată ce aveți clustere, doriți să aflați clicurile și afișările pentru fiecare dintre ele, pentru a evalua care zone necesită cele mai multe îmbunătățiri.
grouped_df = df.groupby('categorie')[['clicuri', 'afişări']].agg('suma')
Cu o anumită manipulare a datelor, putem să ne îmbunătățim rezultatele asocierii și să avem clicuri și afișări pentru fiecare cluster.
group_ex = df.groupby(['categorie'])['interogare'].apply(' | '.join).reset_index()
#eliminați interogările duplicate și apoi sortați-le alfabetic
group_ex['query'] = group_ex['query'].aplica (lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['categorie', 'categorie'], cum='interior')
df_final.head()
Acum aveți un fișier CSV cu toate grupurile de cuvinte cheie, împreună cu clicurile și afișările.
#salvați fișierul csv și descărcați-l pe mașina dvs. locală. Dacă utilizați Safari, vă rugăm să luați în considerare trecerea la Chrome pentru a descărca aceste fișiere, deoarece este posibil să nu funcționeze.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
De fapt, există metode mai bune pentru grupare, acesta este doar un exemplu despre cum puteți folosi querycat pentru a efectua mai multe sarcini pentru o utilizare imediată. Scopul principal aici este de a obține cât mai multe informații, în special pentru site-urile web noi unde nu aveți atât de multe cunoștințe.
Momentan, cele mai bune abordări implică semantica, așa că dacă doriți să vă concentrați pe clustering, vă sugerez să luați în considerare învățarea graficelor sau înglobărilor.
Cu toate acestea, acestea sunt subiecte avansate dacă sunteți începător și puteți încerca pur și simplu câteva aplicații Streamlit predefinite disponibile online.
Date oncrawl³
 Află mai multe
Află mai multeConcluzie și ce urmează
Python vă poate oferi un ajutor major în analiza site-ului dvs. și vă poate ajuta să combinați curățarea, vizualizarea și analiza datelor într-un singur loc. Extragerea datelor din API-ul GSC este cu siguranță necesară pentru sarcini mai avansate și este o introducere „blândă” în automatizarea datelor.
Deși puteți face o mulțime de calcule mai avansate cu Python, recomandarea mea este să verificați ce are sens în ceea ce privește valoarea SEO.
De exemplu, numărul de interogări este mult mai important în ansamblu pe termen lung, deoarece doriți ca site-ul dvs. să fie luat în considerare pentru mai multe interogări.
Utilizarea notebook-urilor este de mare ajutor pentru a împacheta codul cu comentarii și acesta este motivul principal pentru care vă sugerez să vă obișnuiți cu Google Colab.
Acesta este doar începutul a ceea ce vă poate oferi analiza de date, deoarece cele mai bune idei provin din îmbinarea diferitelor seturi de date.
Google Search Console este în sine un instrument puternic și este complet gratuit, cantitatea de informații practice pe care o puteți obține din el este aproape nelimitată în mâinile bune.