
Deep Learning vs. Machine Learning – cum să facem diferența?
Publicat: 2020-03-10În ultimii ani, învățarea automată, învățarea profundă și inteligența artificială au devenit cuvinte de interes. Drept urmare, le puteți găsi peste tot în materialele de marketing și reclamele din ce în ce mai multe companii.
Dar ce sunt Machine Learning și Deep Learning? De asemenea, care sunt diferențele dintre ele? În acest articol, voi încerca să răspund la aceste întrebări și să vă arăt câteva cazuri de aplicații Deep and Machine Learning.
Ce este Machine Learning?
Învățarea automată este o parte a Informaticii care se ocupă cu reprezentarea unor evenimente sau obiecte din lumea reală cu modele matematice, pe baza datelor. Aceste modele sunt construite cu algoritmi speciali care adaptează structura generală a modelului astfel încât să se potrivească cu datele de antrenament. În funcție de tipul de problemă care se rezolvă, definim algoritmi de învățare automată și învățare automată supravegheați și nesupravegheați.
Învățare automată supravegheată vs. nesupravegheată
Învățarea automată supravegheată se concentrează pe crearea de modele care ar putea transfera cunoștințele pe care le avem deja despre datele la îndemână către date noi. Noile date nu sunt văzute de algoritmul de construire a modelului (antrenament) în timpul fazei de antrenament. Oferim un algoritm cu datele caracteristicilor împreună cu valorile corespunzătoare pe care algoritmul ar trebui să învețe să le deducă din acestea (așa-numita variabilă țintă).
În învățarea automată nesupravegheată, oferim algoritmului doar funcții. Acest lucru îi permite să-și descopere singur structura și/sau dependențele. Nu este specificată o variabilă țintă clară. Noțiunea de învățare nesupravegheată poate fi greu de înțeles la început, dar aruncând o privire la exemplele oferite în cele patru diagrame de mai jos ar trebui să clarifice această idee.
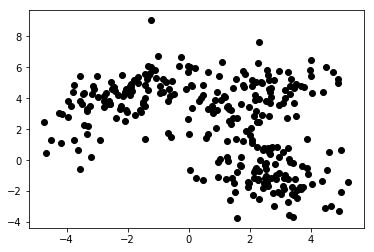
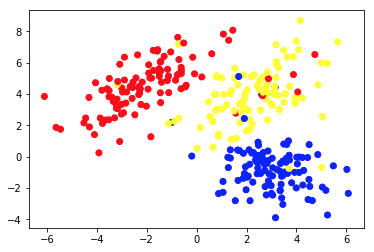

Graficul 1a prezintă câteva date descrise cu 2 caracteristici pe axele x și y . Cel marcat ca 1b arată aceleași date colorate. Am folosit algoritmul de grupare K- means pentru a grupa aceste puncte în 3 grupuri și le-am colorat în consecință. Acesta este un exemplu de algoritm de învățare automată nesupravegheată . Algoritmului i s-au dat doar caracteristicile, iar etichetele (numerele grupului) trebuiau să fie descoperite.
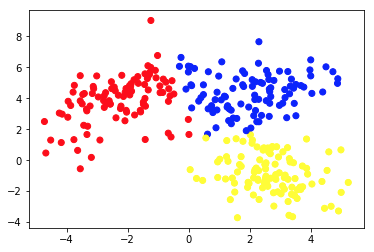
A doua imagine prezintă Diagrama 2a, care prezintă un set diferit de date etichetate (și colorate corespunzător). Știm că grupurile fiecăruia dintre punctele de date aparțin a priori . Folosim un algoritm SVM pentru a găsi 2 linii drepte care ne-ar arăta cum să împărțim punctele de date pentru a se potrivi cel mai bine acestor grupuri. Această divizare nu este perfectă, dar aceasta este cea mai bună care se poate face cu linii drepte. Dacă vrem să atribuim un grup unui punct de date nou, neetichetat, trebuie doar să verificăm unde se află în avion. Acesta este un exemplu de aplicație de învățare automată supravegheată .
Aplicații ale modelelor Machine Learning
Algoritmii standard de învățare automată sunt creați pentru manipularea datelor într-o formă tabelară. Aceasta înseamnă că pentru a le folosi avem nevoie de un fel de masă. Într-un astfel de tabel, rândurile pot fi considerate ca exemple ale obiectului modelat (de exemplu, un împrumut). În același timp, coloanele ar trebui văzute ca caracteristici (caracteristici) ale acestei instanțe particulare (de exemplu, plata lunară a împrumutului, venitul lunar al împrumutatului).

Ești curios despre dezvoltarea Machine Learning?
Află mai multeTabelul 1. este un exemplu foarte scurt de astfel de date. Desigur, nu înseamnă că datele pure în sine trebuie să fie tabelare și structurate. Dar dacă vrem să aplicăm un algoritm standard de Machine Learning pe un set de date, de obicei trebuie să curățăm, să amestecăm și să îl transformăm într-un tabel. În învățarea supravegheată, există, de asemenea, o coloană specială care conține valoarea țintă (de exemplu, informații dacă împrumutul a rămas neplată).
Algoritmul de antrenament încearcă să încadreze structura generală a modelului în aceste date. Algoritmul menționat face asta prin modificarea parametrilor modelului. Acest lucru are ca rezultat un model care descrie relația dintre datele date și variabila țintă cât mai precis posibil.
Este important ca modelul nu numai să se potrivească bine cu datele de antrenament date, dar să fie și capabil să se generalizeze. Generalizarea înseamnă că putem folosi modelul pentru a deduce ținta pentru instanțe care nu sunt utilizate în timpul antrenamentului. Este, de asemenea, o caracteristică crucială a unui model util. Construirea unui model bine generalizat nu este o sarcină ușoară. Adesea necesită tehnici de validare sofisticate și testare amănunțită a modelului.
| loan_id | vârsta_împrumutatului | venit_lunar | sumă împrumutată | plata lunara | Mod implicit |
| 1 | 34 | 10.000 | 100.000 | 1.200 | 0 |
| 2 | 43 | 5.700 | 25.000 | 800 | 0 |
| 3 | 25 | 2.500 | 24.000 | 400 | 0 |
| 4 | 67 | 4.600 | 40.000 | 2.000 | 1 |
| 5 | 38 | 35.000 | 2.500.000 | 10.000 | 0 |
Tabelul 1. Date de împrumut în formă tabelară
Oamenii folosesc algoritmi de învățare automată într-o varietate de aplicații. Tabelul 2. prezintă câteva cazuri de utilizare în afaceri care permit algoritmi și modele de aplicații non-deep Machine Learning. Există, de asemenea, scurte descrieri ale datelor potențiale, variabilelor țintă și algoritmilor aplicabili selectați.
| Utilizare caz | Exemple de date | Valoarea țintă (modelată). | Algoritmul/modelul utilizat |
| Recomandări de articole pe un site de blog | ID-urile articolelor citite de utilizatori, timpul petrecut pe fiecare dintre ele | Preferințele utilizatorilor față de articole | Filtrare colaborativă cu cele mai mici pătrate alternative |
| Scorul de credit al creditelor ipotecare | Istoricul tranzacțional și de creditare, datele privind veniturile unui potențial împrumutat | Valoarea binară care arată dacă un împrumut va fi rambursat integral sau dacă va fi implicit | LightGBM |
| Prezicerea numărului de utilizatori premium ai unui joc mobil | Timpul petrecut zilnic jucând, timpul de la prima lansare, progresul în joc | Valoare binară care arată dacă un utilizator va anula abonamentul luna viitoare | XGBoost |
| Detectarea fraudei cu cardul de credit | Date istorice ale tranzacțiilor cu cardul de credit – sumă, loc, dată și oră | Valoare binară care arată dacă o tranzacție cu cardul de credit este frauduloasă | pădure întâmplătoare |
| Segmentarea clienților unui magazin pe internet | Istoricul achizițiilor membrilor programului de loialitate | Număr de segment atribuit fiecărui client | K-înseamnă |
| Întreținerea predictivă a unui parc de mașini | Date de la senzorii de performanță, temperatură, umiditate etc | Una dintre următoarele clase – „bine”, „a respecta”, „necesită întreținere” | Arborele de decizie |
Tabelul 2. Exemple de cazuri de utilizare a Machine Learning
Învățare profundă și rețele neuronale profunde
Deep Learning face parte din Machine Learning în care folosim modele de un anumit tip, numite rețele neuronale artificiale profunde (ANN). De la introducerea lor, rețelele neuronale artificiale au trecut printr-un proces extins de evoluție. Acest lucru a condus la o serie de subtipuri, dintre care unele sunt foarte complicate. Dar pentru a le introduce, cel mai bine este să explicați una dintre formele lor de bază – un perceptron multistrat (MPL).
Perceptron multistrat
Mai simplu spus, un MLP are o formă de grafic (rețea) de vârfuri (numite și neuroni) și margini (reprezentate prin numere numite greutăți). Neuronii sunt aranjați în straturi, iar neuronii în straturi consecutive sunt conectați între ei. Datele circulă prin rețea de la nivelul de intrare la nivelul de ieșire. Datele sunt apoi transformate la neuroni și marginile dintre ei. Odată ce un punct de date trece prin întreaga rețea, stratul de ieșire conține valorile prezise în neuronii săi.
De fiecare dată când o bucată din datele de antrenament trece prin rețea, comparăm predicțiile cu valorile adevărate corespunzătoare. Acest lucru ne permite să adaptăm parametrii (greutățile) modelului pentru a face predicții mai bune. O putem face cu un algoritm numit backpropagation. După un anumit număr de iterații, dacă structura modelului este bine concepută special pentru a aborda problema de învățare automată la îndemână.
Obținerea unui model de înaltă precizie
Odată ce suficiente date au trecut prin rețea de mai multe ori, obținem un model de mare precizie. În practică, există o mulțime de transformări care pot fi aplicate la neuroni. Asta face ca ANN-urile să fie foarte flexibile și puternice. Puterea ANN-urilor are totuși un preț. De obicei, cu cât structura modelului este mai complicată, cu atât este nevoie de mai multe date și timp pentru a-l antrena cu precizie ridicată.
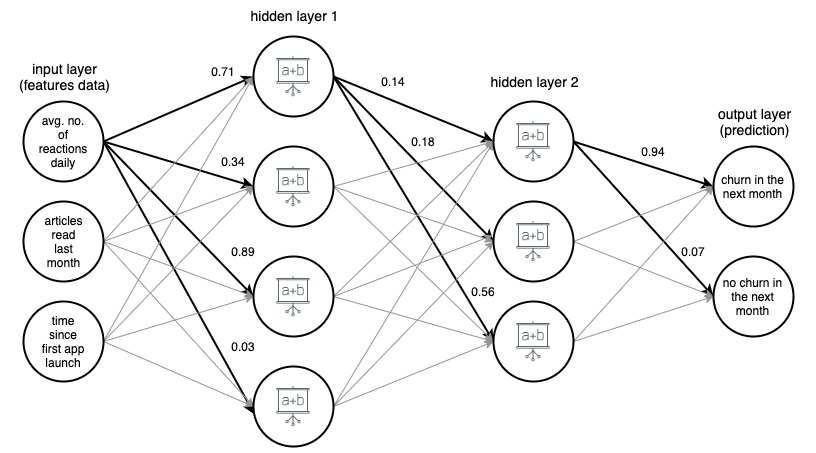
Imaginea 1. (draw.io) Structura unei rețele neuronale artificiale cu 4 straturi, care prezice dacă un utilizator al unei aplicații de știri va renunța luna viitoare, pe baza a trei caracteristici simple.
Pentru claritate, greutățile au fost marcate numai pentru marginile selectate (îngroșate), dar fiecare margine are propria greutate. Datele circulă din stratul de intrare în stratul de ieșire, trecând prin 2 straturi ascunse din mijloc. Pe fiecare muchie, o valoare de intrare este înmulțită cu greutatea muchiei, iar produsul rezultat merge la nodul în care se termină muchia. Apoi, în fiecare dintre nodurile din straturile ascunse, semnalele primite de la margini sunt însumate și apoi transformate cu o anumită funcție. Rezultatul acestor transformări este apoi tratat ca o intrare la stratul următor.
În stratul de ieșire, datele primite sunt din nou însumate și transformate, obținând rezultatul sub formă de două numere - probabilitatea ca un utilizator să renunțe la aplicație în luna următoare și probabilitatea ca acesta să nu o facă.
Tipuri avansate de rețele neuronale
În rețelele neuronale de tipuri mai avansate, straturile au o structură mult mai complexă. Ele constau nu numai din straturi simple dense cu neuroni cu o singură operație cunoscuți din MLP, ci și straturi mult mai complicate, cu mai multe operații, cum ar fi straturi convoluționale și recurente.
Straturi convoluționale și recurente
Straturile convoluționale sunt utilizate mai ales în aplicațiile de viziune computerizată . Ele constau din rețele mici de numere care alunecă peste reprezentarea în pixeli a imaginii. Valorile pixelilor sunt înmulțite cu aceste numere și apoi agregate, obținând o reprezentare nouă, condensată, a imaginii.
Straturile recurente sunt folosite pentru a modela date secvențiale ordonate, cum ar fi seriile temporale sau textul . Ei aplică transformări mult mai complicate cu mai multe argumente datelor primite, încercând să descopere dependențele dintre elementele secvenței. Cu toate acestea, indiferent de tipul și structura rețelei, există întotdeauna unele (unul sau mai multe) straturi de intrare și ieșire și căi și direcții strict definite în care datele circulă prin rețea.
În general, rețelele neuronale profunde sunt ANN-uri cu mai multe straturi. Imaginile 1, 2 și 3 de mai jos arată arhitecturi ale rețelelor neuronale artificiale profunde selectate. Toate au fost dezvoltate și instruite la Google și puse la dispoziția publicului. Ele oferă o idee despre cât de complexe sunt rețelele artificiale profunde de mare precizie folosite astăzi.
Aceste rețele au dimensiuni enorme. De exemplu, parțial prezentat în imaginea 3 InceptionResNetV2 are 572 de straturi și peste 55 de milioane de parametri în total! Toate au fost dezvoltate ca modele de clasificare a imaginilor (acestea atribuie o etichetă, de exemplu, „mașină” unei anumite imagini) și au fost instruite pe imagini din setul ImageNet, constând din peste 14 milioane de imagini etichetate.

Imaginea 2. Structura NASNetMobile (pachetul Keras)

Imaginea 3. Structura XCeption (pachetul Keras)

Imaginea 4. Structura unei părți (aproximativ 25%) a InceptionResNetV2 (pachet Keras)
În ultimii ani, am observat o mare dezvoltare în Deep Learning și aplicațiile sale. Multe dintre funcțiile „inteligente” ale smartphone-urilor și aplicațiilor noastre sunt rodul acestui progres. Deși ideea de ANN-uri nu este nouă, acest boom recent este rezultatul îndeplinirii câtorva condiții. În primul rând, am descoperit potențialul GPU computing. Arhitectura unităților de procesare grafică este excelentă pentru calcule paralele, foarte utilă în Deep Learning eficient.
În plus, creșterea serviciilor de cloud computing a făcut accesul la hardware de înaltă eficiență mult mai ușor, mai ieftin și posibil la o scară mult mai mare. În cele din urmă, puterea de calcul a celor mai noi dispozitive mobile este suficient de mare pentru a aplica modele de Deep Learning, creând o piață uriașă de potențiali utilizatori ai funcțiilor bazate pe DNN.
Aplicații ale modelelor de Deep Learning
Modelele de învățare profundă sunt de obicei aplicate problemelor care se ocupă de date care nu au o structură simplă rând-coloană, cum ar fi clasificarea imaginilor sau traducerea limbii, deoarece sunt excelente în operarea cu date nestructurate și cu structură complexă pe care aceste sarcini le gestionează - imagini, text , și sunet. Există probleme cu gestionarea datelor de aceste tipuri și dimensiuni cu algoritmii clasici de învățare automată, iar crearea și aplicarea unor rețele neuronale profunde la aceste probleme au cauzat dezvoltări extraordinare în domeniile recunoașterii imaginilor, recunoașterii vorbirii, clasificării textului și traducerii limbilor în ultimii câțiva ani.
Aplicarea Deep Learning la aceste probleme a fost posibilă datorită faptului că DNN-urile acceptă tabele multidimensionale de numere, numite tensori, atât ca intrare, cât și ca ieșire, și pot urmări relațiile spațiale și temporale dintre elementele lor. De exemplu, putem prezenta o imagine ca un tensor tridimensional, unde dimensiunea unu și doi reprezintă rezoluția imaginii digitale (deci au dimensiunile lățimii și, respectiv, înălțimii imaginii), iar a treia dimensiune reprezintă culoarea RGB codificarea fiecărui pixel (deci a treia dimensiune este de dimensiunea 3).
Acest lucru ne permite nu numai să reprezentăm toate informațiile despre imagine într-un tensor, dar și să păstrăm relațiile spațiale dintre pixeli, ceea ce se dovedește a fi crucial în aplicarea așa-numitelor straturi convoluționale, cruciale în rețelele de clasificare și recunoaștere a imaginilor de succes.
Flexibilitatea rețelei neuronale în structurile de intrare și ieșire ajută și în alte sarcini, cum ar fi traducerea limbii . Când avem de-a face cu date text, alimentăm rețelele neuronale profunde cu reprezentări numerice ale cuvintelor, ordonate în funcție de apariția lor în text. Fiecare cuvânt este reprezentat de un vector de o sută sau câteva sute de numere, calculate (de obicei folosind o rețea neuronală diferită) astfel încât relațiile dintre vectorii corespunzători unor cuvinte diferite să mimeze relațiile cuvintelor în sine. Aceste reprezentări ale limbajului vectorial, numite înglobări, odată antrenate, pot fi reutilizate în multe arhitecturi și sunt un element central al modelelor de limbaj de rețele neuronale.
Exemple de utilizare a modelelor de Deep Learning
Tabelul 3. conține exemple de aplicare a modelelor de Deep Learning la problemele din viața reală. După cum puteți vedea, problemele abordate și rezolvate de algoritmii de învățare profundă sunt mult mai complexe decât sarcinile rezolvate prin tehnici standard de învățare automată, precum cele prezentate în tabelul 1.
Cu toate acestea, este important să ne amintim că multe dintre cazurile de utilizare pe care învățarea automată le poate ajuta în afaceri de astăzi nu necesită metode atât de sofisticate și pot fi rezolvate mai eficient (și cu o precizie mai mare) prin modele standard. Tabelul 3 oferă, de asemenea, o idee despre câte tipuri diferite de straturi de rețele neuronale artificiale există și câte arhitecturi utile diferite pot fi construite cu acestea.
| Utilizare caz | Date | Ținta/rezultatul modelului | Algoritmul/modelul utilizat |
| Clasificarea imaginilor | Imagini | Etichetă atribuită unei imagini | Rețeaua neuronală convoluțională (CNN) |
| Detectarea imaginii de către mașinile cu conducere autonomă | Imagini | Etichete și casete de delimitare în jurul obiectelor identificate pe imagini | R-CNN rapid |
| Sentiment analiza comentarii într-un magazin online | Textul comentariilor online | Eticheta de sentiment (de exemplu, pozitiv, neutru, negativ) atribuită fiecărui comentariu | Rețea bidirecțională de memorie pe termen lung și scurt (LSTM). |
| Armonizarea unei melodii | Fișier MIDI cu o melodie | Fișier MIDI cu această melodie armonizată | Rețeaua adversară generativă |
| Prognoza cuvântului următor într-o pe net editor | Text foarte mare (de exemplu, descărcarea tuturor articolelor Wikipedia în engleză) | Un cuvânt care se potrivește ca următorul textului scris până acum | Rețea neuronală recurentă (RNN) cu un strat de încorporare |
| Traducerea textului în altă limbă | Text în poloneză | Același text tradus în engleză | Encoder – Decoder Network construit cu straturi de rețea neuronală recurentă (RNN). |
| Transferul stilului lui Monet la orice imagine | Set de imagini cu picturile lui Monet și un set de alte imagini | Imaginile modificate pentru a arăta ca pictate de Monet | Rețeaua adversară generativă |
Tabelul 3. Exemple de cazuri de utilizare Deep Learning
Avantajele modelelor Deep Learning
Rețele adversare generative
Una dintre cele mai impresionante aplicații ale rețelelor neuronale profunde a venit odată cu creșterea rețelelor generative adversare (GAN). Au fost introduse în 2014 de Ian Goodfellow, iar ideea lui a fost de atunci încorporată în multe instrumente, unele cu rezultate uimitoare.
GAN-urile sunt responsabile pentru existența aplicațiilor care ne fac să arătăm mai bătrâni în fotografii, transformă imaginile astfel încât să arate ca și cum ar fi pictate de Van Gogh sau chiar armonizează melodiile pentru mai multe trupe de instrumente. În timpul antrenamentului unui GAN, două rețele neuronale concurează. O rețea generatoare generează o ieșire din intrări aleatorii, în timp ce discriminatorul încearcă să distingă instanțele generate de cele reale. În timpul antrenamentului, generatorul învață cum să „păcălească” cu succes discriminatorul și, în cele din urmă, este capabil să creeze rezultate care arată ca și cum ar fi reale.
Rețele neuronale profunde puternice în aplicațiile mobile
Este important de reținut că, deși antrenarea unei rețele neuronale profunde este o sarcină foarte costisitoare din punct de vedere computațional și poate dura mult timp, aplicarea unei rețele instruite pentru a îndeplini o anumită sarcină nu trebuie să fie, mai ales dacă este aplicată la una sau la o anumită sarcină. câteva cazuri deodată. De fapt, astăzi suntem capabili să rulăm rețele neuronale profunde puternice în aplicațiile mobile de pe smartphone-urile noastre.
Există chiar și unele arhitecturi de rețea concepute special pentru a fi eficiente atunci când sunt aplicate pe dispozitive mobile (de exemplu, NASNetMobile prezentat în Imaginea 1). Chiar dacă sunt mult mai mici în comparație cu rețelele de ultimă generație, ele sunt totuși capabile să obțină o performanță de predicție cu precizie ridicată.
Transferați învățarea
O altă caracteristică foarte puternică a rețelelor neuronale artificiale, care permite utilizarea pe scară largă a modelelor de învățare profundă, este învățarea prin transfer . Odată ce avem un model antrenat pe anumite date (fie creat de noi înșine, fie descărcat dintr-un depozit public), putem construi pe tot sau pe o parte a acestuia pentru a obține un model care să rezolve cazul nostru de utilizare particular. De exemplu, am putea folosi un model NASNetLarge pre-antrenat, antrenat pe uriașul set de date ImageNet, care atribuie o etichetă unei imagini, să facă câteva modificări mici în partea de sus a structurii acesteia, să-l antreneze în continuare cu un nou set de imagini etichetate și utilizați-l pentru a eticheta un anumit tip de obiecte (de exemplu, speciile unui copac pe baza imaginii frunzei sale).
Avantajele învățării prin transfer
Învățarea prin transfer este foarte utilă, deoarece, de obicei, antrenarea unei rețele neuronale profunde care va îndeplini anumite sarcini practice și utile necesită cantități mari de date și o putere de calcul uriașă. Acest lucru poate însemna adesea milioane de instanțe de date etichetate și sute de unități de procesare grafică (GPU) care rulează săptămâni întregi.
Nu toată lumea își poate permite sau are acces la astfel de active, ceea ce poate face foarte dificilă construirea de la zero a unei soluții personalizate de înaltă precizie pentru, să spunem, clasificarea imaginilor. Din fericire, unele modele pre-antrenate (în special rețele pentru clasificarea imaginilor și matrici de încorporare pre-antrenate pentru modele de limbaj) au fost open-source și sunt disponibile gratuit într-o formă ușor de aplicat (de exemplu, ca o instanță de model în Keras, un rețele API).
Cum să alegeți și să construiți modelul de învățare automată potrivit pentru aplicația dvs
Când doriți să aplicați Machine Learning pentru a rezolva o problemă de afaceri, probabil că nu trebuie să vă decideți imediat asupra tipului de model. De obicei, există câteva abordări care ar putea fi testate. Este adesea tentant să începeți cu cele mai complicate modele la început, dar merită să începeți simplu, și să creșteți treptat complexitatea modelelor aplicate. Modelele mai simple sunt de obicei mai ieftine în ceea ce privește configurarea, timpul de calcul și resursele. În plus, rezultatele lor sunt un punct de referință excelent pentru a evalua abordările mai avansate.
Având astfel de repere poate ajuta oamenii de știință de date să evalueze dacă direcția în care își dezvoltă modelele este cea corectă. Un alt avantaj este posibilitatea de a reutiliza unele dintre modelele construite anterior, și de a le îmbina cu altele mai noi, creând așa-numitul model de ansamblu. Amestecarea modelelor de diferite tipuri generează adesea valori de performanță mai mari decât ar avea fiecare dintre modelele combinate singur. De asemenea, verificați dacă există câteva modele pre-instruite care ar putea fi utilizate și adaptate la cazul dvs. de afaceri prin transfer de învățare.
Mai multe sfaturi practice
În primul rând, indiferent de modelul pe care îl utilizați, asigurați-vă că datele sunt gestionate corect. Țineți cont de regula „gunoi înăuntru, gunoi afară”. Dacă datele de antrenament furnizate modelului sunt de calitate scăzută sau nu au fost etichetate și curățate corespunzător, este foarte probabil ca și modelul rezultat să aibă performanțe slabe. De asemenea, asigurați-vă că modelul – indiferent de complexitatea lui – a fost validat pe scară largă în timpul fazei de modelare și, în final, testat dacă se generalizează bine la date nevăzute.
Într-o notă mai practică, asigurați-vă că soluția creată poate fi implementată în producție pe infrastructura disponibilă. Și dacă afacerea dvs. poate colecta mai multe date care ar putea fi folosite pentru a vă îmbunătăți modelul în viitor, ar trebui să fie pregătită un canal de recalificare pentru a asigura actualizarea ușoară a acestuia. O astfel de conductă poate fi chiar configurată pentru a reanaliza automat modelul cu o frecvență de timp predefinită.
Gânduri finale
Nu uitați să urmăriți performanța și gradul de utilizare al modelului după implementarea acestuia în producție, deoarece mediul de afaceri este foarte dinamic. Unele relații din cadrul datelor dvs. se pot schimba în timp și pot apărea noi fenomene. Prin urmare, acestea pot schimba eficiența modelului dvs. și ar trebui tratate corespunzător. În plus, pot fi inventate tipuri noi, puternice de modele. Pe de o parte, vă pot face soluția relativ slabă, dar, pe de altă parte, vă oferă posibilitatea de a vă îmbunătăți în continuare afacerea și de a profita de cea mai nouă tehnologie.
În plus, modelele Machine și Deep Learning vă pot ajuta să construiți instrumente puternice pentru afacerea și aplicațiile dvs. și să ofere clienților o experiență excepțională . Deși crearea acestor funcții „inteligente” necesită un efort substanțial, dar beneficiile potențiale merită. Doar asigurați-vă că dvs. și echipa dvs. de Data Science încercați modele adecvate și urmați bunele practici și veți fi pe drumul cel bun pentru a vă împuternici afacerea și aplicațiile cu soluții de ultimă oră de învățare automată.
Surse:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf