
Ce este o curbă CTR și cum se calculează cu Python?
Publicat: 2022-03-22Curba CTR, sau, cu alte cuvinte, rata de clic organică în funcție de poziție, este date care vă arată câte link-uri albastre de pe o pagină de rezultate ale motorului de căutare (SERP) obțin CTR pe baza poziției lor. De exemplu, de cele mai multe ori, primul link albastru din SERP primește cel mai mare CTR.
La sfârșitul acestui tutorial, veți putea să calculați curba CTR a site-ului dvs. pe baza directoarelor sale sau să calculați CTR organic pe baza interogărilor CTR. Ieșirea codului meu Python este o casetă și un diagramă cu bare perspicace care descrie curba CTR a site-ului.
Dacă ești începător și nu cunoști definiția CTR, o voi explica mai multe în secțiunea următoare.
Ce este Organic CTR sau Organic Click Through Rate?
CTR provine din împărțirea clicurilor organice în afișări. De exemplu, dacă 100 de persoane caută „măr” și 30 de persoane dau clic pe primul rezultat, CTR-ul primului rezultat este 30 / 100 * 100 = 30%.
Asta înseamnă că din 100 de căutări, primești 30% dintre ele. Este important să rețineți că afișările din Google Search Console (GSC) nu se bazează pe aspectul link-ului site-ului dvs. în fereastra de căutare. Dacă rezultatul apare pe SERP de căutare, obțineți o impresie pentru fiecare dintre căutări.
Care sunt utilizările curbei CTR?
Unul dintre subiectele importante în SEO este predicțiile organice de trafic. Pentru a îmbunătăți clasamentul într-un anumit set de cuvinte cheie, trebuie să alocăm mii și mii de dolari pentru a obține mai multe acțiuni. Dar întrebarea la nivelul de marketing al unei companii este adesea: „Este rentabil pentru noi să alocăm acest buget?”.
De asemenea, pe lângă subiectul alocărilor bugetare pentru proiectele SEO, trebuie să obținem o estimare a creșterii sau scăderii traficului nostru organic în viitor. De exemplu, dacă vedem că unul dintre concurenții noștri încearcă din greu să ne înlocuiască în poziția noastră de rang SERP, cât ne va costa asta?
În această situație sau în multe alte scenarii, avem nevoie de curba CTR a site-ului nostru.
De ce nu folosim studiile curbei CTR și nu folosim datele noastre?
Răspuns simplu, nu există niciun alt site web care să aibă caracteristicile site-ului tău în SERP.
Există multe cercetări pentru curbele CTR în diferite industrii și diferite caracteristici SERP, dar când aveți datele dvs., de ce site-urile dvs. nu calculează CTR în loc să se bazeze pe surse terțe?
Să începem să facem asta.
Calcularea curbei CTR cu Python: Noțiuni introductive
Înainte de a ne aprofunda în procesul de calcul al ratei de clic Google în funcție de poziție, trebuie să cunoașteți sintaxa de bază Python și să aveți o înțelegere de bază a bibliotecilor Python obișnuite, cum ar fi Pandas. Acest lucru vă va ajuta să înțelegeți mai bine codul și să-l personalizați în felul dumneavoastră.
În plus, pentru acest proces, prefer să folosesc un notebook Jupyter.
Pentru a calcula CTR organic pe baza poziției, trebuie să folosim aceste biblioteci Python:
- panda
- Intrigator
- Kaleido
De asemenea, vom folosi aceste biblioteci standard Python:
- os
- json
După cum am spus, vom explora două moduri diferite de a calcula curba CTR. Unii pași sunt aceiași în ambele metode: importarea pachetelor Python, crearea unui folder de ieșire a imaginilor plotului și setarea dimensiunilor plotului de ieșire.
# Importul bibliotecilor necesare pentru procesul nostru import os import json importa panda ca pd import plotly.express ca px import plotly.io ca pio import kaleido
Aici creăm un folder de ieșire pentru salvarea imaginilor noastre de plot.
# Crearea dosarului de ieșire a imaginilor grafice
dacă nu os.path.exists('./output plot images'):
os.mkdir('./output plot images')
Puteți modifica înălțimea și lățimea imaginilor grafice de mai jos.
# Setarea lățimii și înălțimii imaginilor grafice de ieșire pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Să începem cu prima metodă care se bazează pe interogări CTR.
Prima metodă: calculați curba CTR pentru un întreg site web sau pentru o anumită bază de proprietate URL pe baza interogărilor CTR
În primul rând, trebuie să obținem toate interogările noastre cu CTR, poziția medie și impresia. Prefer să folosesc o lună completă de date din luna trecută.
Pentru a face acest lucru, primesc date despre interogări de la sursa de date privind afișările site-ului GSC din Google Data Studio. Alternativ, puteți obține aceste date în orice mod doriți, cum ar fi GSC API sau suplimentul Google Sheets „Search Analytics for Sheets”, de exemplu. În acest fel, dacă blogul sau paginile de produse au o proprietate URL dedicată, le puteți folosi ca sursă de date în GDS.
1. Obținerea datelor privind interogările de la Google Data Studio (GDS)
Pentru a face acest lucru:
- Creați un raport și adăugați-i o diagramă tabel
- Adăugați sursa de date „Afișare site” a site-ului dvs. la raport
- Alegeți „interogare” pentru dimensiune, precum și „ctr”, „poziție medie” și „afișare” pentru valoare
- Filtrați interogările care conțin numele mărcii prin crearea unui filtru (Interogările care conțin mărci vor avea o rată de clic mai mare, ceea ce va scădea acuratețea datelor noastre)
- Faceți clic dreapta pe tabel și faceți clic pe Export
- Salvați rezultatul ca CSV
2. Încărcarea datelor noastre și etichetarea interogărilor pe baza poziției lor
Pentru a manipula fișierul CSV descărcat, vom folosi Pandas.
Cea mai bună practică pentru structura de foldere a proiectului nostru este să avem un folder „date” în care salvăm toate datele noastre.
Aici, de dragul fluidității în tutorial, nu am făcut asta.
query_df = pd.read_csv('./downloaded_data.csv')
Apoi etichetăm interogările noastre în funcție de poziția lor. Am creat o buclă „for” pentru etichetarea pozițiilor de la 1 la 10.
De exemplu, dacă poziția medie a unei interogări este 2,2 sau 2,9, aceasta va fi etichetată „2”. Prin manipularea intervalului de poziție medie, puteți obține precizia dorită.
pentru i în interval (1, 11):
query_df.loc[(query_df['Poziția medie'] >= i) & (
query_df['Poziție medie'] <i + 1), 'etichetă de poziție'] = i
Acum, vom grupa interogările în funcție de poziția lor. Acest lucru ne ajută să manipulăm datele fiecărei poziții interogări într-un mod mai bun în următorii pași.
query_grouped_df = query_df.groupby(['etichetă de poziție'])
3. Filtrarea interogărilor pe baza datelor lor pentru calcularea curbei CTR
Cel mai simplu mod de a calcula curba CTR este să utilizați toate datele interogărilor și să faceți calculul. In orice caz; nu uitați să vă gândiți la acele interogări cu o impresie în poziția a doua în datele dvs.
Aceste întrebări, bazate pe experiența mea, fac o mare diferență în rezultatul final. Dar cel mai bun mod este să încerci singur. Pe baza setului de date, acest lucru se poate schimba.
Înainte de a începe acest pas, trebuie să creăm o listă pentru ieșirea graficului cu bare și un DataFrame pentru stocarea interogărilor noastre manipulate.
# Crearea unui DataFrame pentru stocarea datelor manipulate „query_df”. modified_df = pd.DataFrame() # O listă pentru salvarea fiecărei poziții înseamnă pentru diagrama noastră cu bare mean_ctr_list = []
Apoi, trecem peste grupurile query_grouped_df și anexăm primele 20% interogări bazate pe afișări la modified_df DataFrame.
Dacă calcularea CTR numai pe baza primelor 20% dintre interogările care au cele mai multe afișări nu este cea mai bună pentru dvs., o puteți modifica.
Pentru a face acest lucru, îl puteți crește sau micșora manipulând .quantile(q=your_optimal_number, interpolation='lower')] și your_optimal_number trebuie să fie între 0 și 1.
De exemplu, dacă doriți să obțineți primele 30% dintre interogări, your_optimal_num este diferența dintre 1 și 0,3 (0,7).
pentru i în interval (1, 11):
# O încercare, cu excepția gestionării acelor situații în care un director nu are date pentru unele poziții
încerca:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['afișări'] >= query_grouped_df.get_group(i)['afișări']
.quantile(q=0,8, interpolare='inferioară')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append(tmp_df, ignore_index=True)
cu excepția KeyError:
mean_ctr_list.append(0)
# Ștergerea DataFrame-ului „tmp_df” pentru reducerea utilizării memoriei
del [tmp_df]
4. Desenarea unui box plot
Acest pas este ceea ce așteptăm. Pentru a desena diagrame, putem folosi Matplotlib, seaborn ca un înveliș pentru Matplotlib sau Plotly.
Personal, cred că utilizarea Plotly este una dintre cele mai potrivite pentru marketerii cărora le place să exploreze datele.
În comparație cu Mathplotlib, Plotly este atât de ușor de utilizat și, cu doar câteva linii de cod, puteți desena un complot frumos.
# 1. Box plot
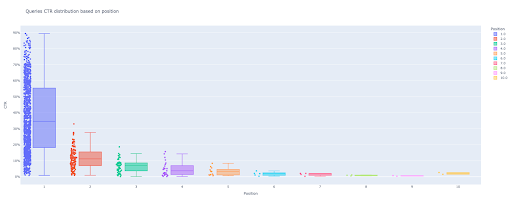
box_fig = px.box(modified_df, x='position label', y='Site CTR', title='Interogări CTR distribuţie bazată pe poziţie',
points='all', color='position label', labels={'position label': 'Pozition', 'Site CTR': 'CTR'})
# Se afișează toate cele zece căpușe ale axelor x
box_fig.update_xaxes(tickvals=[i pentru i în interval (1, 11)])
# Schimbarea formatului de bifare a axelor y în procente
box_fig.update_yaxes(tickformat=".0%)")
# Salvarea graficului în directorul „Imagini grafice de ieșire”.
box_fig.write_image('./output plot images/Queries box plot CTR curve.png')
Cu doar aceste patru rânduri, puteți obține o diagramă cu casetă frumoasă și puteți începe să vă explorați datele.
Dacă doriți să interacționați cu această coloană, rulați într-o nouă celulă:
box_fig.show()
Acum, aveți o diagramă de casetă atractivă în ieșire, care este interactivă.
Când treceți cu mouse-ul peste o diagramă interactivă în celula de ieșire, numărul important de care sunteți interesat este „omul” fiecărei poziții.
Aceasta arată CTR-ul mediu pentru fiecare poziție. Din cauza importanței medii, așa cum vă amintiți, creăm o listă care conține media fiecărei poziții. În continuare, vom trece la pasul următor pentru a desena un diagramă cu bare pe baza mediei fiecărei poziții.
5. Desenarea unui diagramă de bare
Ca un diagramă cu case, desenarea diagramei cu bare este atât de ușor. Puteți schimba title diagramelor modificând argumentul title al px.bar() .
# 2. Trama de bare
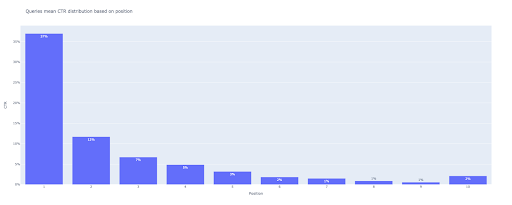
bar_fig = px.bar(x=[pos pentru poziția în interval (1, 11)], y=mean_ctr_list, title='Interogările înseamnă distribuția CTR bazată pe poziție',
labels={'x': 'Poziție', 'y': 'CTR'}, text_auto=True)
# Se afișează toate cele zece căpușe ale axelor x
bar_fig.update_xaxes(tickvals=[i pentru i în interval (1, 11)])
# Schimbarea formatului de bifare a axelor y în procente
bar_fig.update_yaxes(tickformat='.0%')
# Salvarea graficului în directorul „Imagini grafice de ieșire”.
bar_fig.write_image('./output plot images/Queries bar plot CTR curve.png')
La ieșire, obținem acest grafic:
Ca și în cazul diagramei cu casete, puteți interacționa cu acest diagramă rulând bar_fig.show() .
Asta e! Cu câteva linii de cod, obținem rata organică de clic pe baza poziției cu datele interogărilor noastre.
Dacă aveți o proprietate URL pentru fiecare dintre subdomeniile sau directoarele dvs., puteți obține aceste interogări cu proprietăți URL și puteți calcula curba CTR pentru ele.
[Studiu de caz] Îmbunătățirea clasamentului, vizitelor organice și vânzărilor cu analiza fișierelor jurnal
 Citiți studiul de caz
Citiți studiul de cazA doua metodă: calcularea curbei CTR pe baza adreselor URL ale paginilor de destinație pentru fiecare director
În prima metodă, ne-am calculat CTR organic pe baza interogărilor CTR, dar cu această abordare, obținem toate datele paginilor noastre de destinație și apoi calculăm curba CTR pentru directoarele selectate.

Îmi place așa. După cum știți, valoarea CTR pentru paginile noastre de produse este atât de diferită de cea a postărilor noastre de blog sau a altor pagini. Fiecare director are propriul CTR în funcție de poziție.
Într-o manieră mai avansată, puteți clasifica fiecare pagină de director și puteți obține rata de clic organic Google pe baza poziției pentru un set de pagini.
1. Obținerea datelor paginilor de destinație
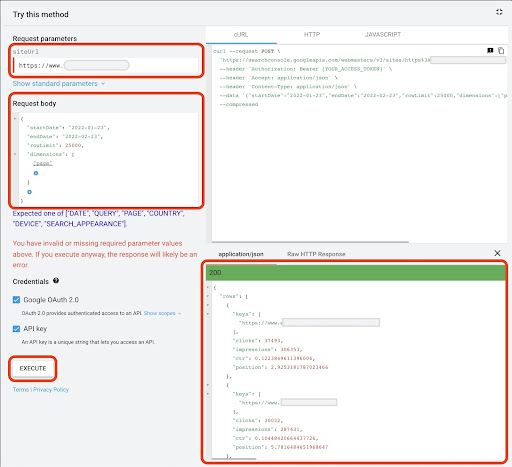
La fel ca prima metodă, există mai multe modalități de a obține date Google Search Console (GSC). În această metodă, am preferat să obțin datele paginilor de destinație din GSC API Explorer la: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Pentru ceea ce este necesar în această abordare, GDS nu oferă date solide ale paginii de destinație. De asemenea, puteți utiliza programul de completare „Search Analytics for Sheets” Google Sheets.
Rețineți că Google API Explorer este potrivit pentru acele site-uri cu mai puțin de 25.000 de pagini de date. Pentru site-uri mai mari, puteți obține date despre paginile de destinație parțial și le puteți concatena împreună, puteți scrie un script Python cu o buclă „for” pentru a obține toate datele dvs. din GSC sau puteți utiliza instrumente terțe.
Pentru a obține date din Google API Explorer:
- Navigați la pagina de documentație a API-ului GSC „Analitice de căutare: interogare”: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Utilizați API Explorer care se află în partea dreaptă a paginii
- În câmpul „siteUrl”, introduceți adresa URL a proprietății, cum ar fi
https://www.example.com. De asemenea, puteți introduce proprietatea domeniului dvs. după cum urmeazăsc-domain:example.com - În câmpul „corpul cererii” adăugați
startDateșiendDate. Prefer să obțin datele de luna trecută. Formatul acestor valori esteYYYY-MM-DD - Adăugați
dimensionși setați-i valorile lapage - Creați un „dimensionFilterGroups” și filtrați interogările cu numele variațiilor de marcă (înlocuind
brand_variation_namescu numele dvs. de marcă RegExp) - Adăugați
rawLimitși setați-l la 25000 - La sfârșit apăsați butonul „EXECUTE”.
De asemenea, puteți copia și lipi corpul solicitării de mai jos:
{
„startDate”: „2022-01-01”,
„endDate”: „2022-02-01”,
"dimensiuni": [
"pagină"
],
„dimensionFilterGroups”: [
{
"filtre": [
{
„dimensiune”: „QUERY”,
"expresie": "nume_variație_marcă",
„operator”: „EXCLUDING_REGEX”
}
]
}
],
„rowLimit”: 25000
}
După ce solicitarea este executată, trebuie să o salvăm. Din cauza formatului de răspuns, trebuie să creăm un fișier JSON, să copiem toate răspunsurile JSON și să-l salvăm cu numele de fișier downloaded_data.json .
Dacă site-ul dvs. este mic, cum ar fi site-ul unei companii SASS, iar datele paginii dvs. de destinație au mai puțin de 1000 de pagini, puteți seta cu ușurință data în GSC și puteți exporta datele paginilor de destinație pentru fila „PAGINI” ca fișier CSV.
2. Încărcarea datelor paginilor de destinație
De dragul acestui tutorial, voi presupune că obțineți date din Google API Explorer și le salvați într-un fișier JSON. Pentru a încărca aceste date, trebuie să rulăm codul de mai jos:
# Crearea unui DataFrame pentru datele descărcate
cu open('./downloaded_data.json') ca json_file:
landings_data = json.loads(json_file.read())['rows']
landings_df = pd.DataFrame(landings_data)
În plus, trebuie să schimbăm numele unei coloane pentru a-i oferi mai multă semnificație și să aplicăm o funcție pentru a obține adrese URL ale paginilor de destinație direct în coloana „pagină de destinație”.
# Redenumirea coloanei „chei” în coloana „pagină de destinație” și conversia listei „pagină de destinație” într-o adresă URL
landings_df.rename(columns={'keys': 'landing page'}, inplace=True)
landings_df['landing page'] = landings_df['landing page'].aply(lambda x: x[0])
3. Obținerea tuturor directoarelor rădăcină a paginilor de destinație
În primul rând, trebuie să definim numele site-ului nostru.
# Definiți numele site-ului dvs. între ghilimele. De exemplu, „https://www.example.com/” sau „http://mydomain.com/” site_name = ''
Apoi rulăm o funcție pe adresele URL ale paginilor de destinație pentru a obține directoarele lor rădăcină și le vedem în ieșire pentru a le alege.
# Obținerea fiecărui director al paginii de destinație (URL).
landings_df['directory'] = landings_df['landing page'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Pentru a obține toate directoarele în ieșire, trebuie să manipulăm opțiunile Pandas
pd.set_option("display.max_rows", Nici unul)
# Directoare de site-uri web
landings_df['director'].value_counts()
Apoi, alegem pentru ce directoare avem nevoie pentru a le obține curba CTR.
Introduceți directoarele în variabila important_directories .
De exemplu, product,tag,product-category,mag . Separați valorile directorului cu virgulă.
directoare_importante = ''
important_directories = important_directories.split(',')
4. Etichetarea și gruparea paginilor de destinație
La fel ca și interogările, etichetăm și paginile de destinație în funcție de poziția lor medie.
# Etichetarea poziției paginilor de destinație
pentru i în interval (1, 11):
landings_df.loc[(landings_df['poziție'] >= i) & (
landings_df['poziție'] <i + 1), 'etichetă de poziție'] = i
Apoi, grupăm paginile de destinație în funcție de „directorul” lor.
# Gruparea paginilor de destinație în funcție de valoarea lor „director”. landings_grouped_df = landings_df.groupby(['director'])
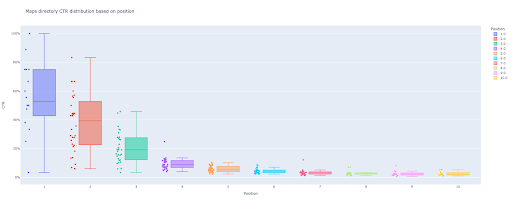
5. Generarea de diagrame cu case și bare pentru directoarele noastre
În metoda anterioară, nu am folosit o funcție pentru a genera diagramele. In orice caz; pentru calcularea automată a curbei CTR pentru diferite pagini de destinație, trebuie să definim o funcție.
# Funcția de creare și salvare a fiecărei diagrame de director
def each_dir_plot(dir_df, cheie):
# Gruparea paginilor de destinație a directorului în funcție de valoarea lor „etichetă de poziție”.
dir_grouped_df = dir_df.groupby(['etichetă de poziție'])
# Crearea unui DataFrame pentru stocarea datelor manipulate „dir_grouped_df”.
modified_df = pd.DataFrame()
# O listă pentru salvarea fiecărei poziții înseamnă pentru diagrama noastră cu bare
mean_ctr_list = []
'''
Buclă peste grupurile „query_grouped_df” și adăugarea primelor 20% interogări bazate pe afișări la DataFrame „modified_df”.
Dacă calcularea CTR numai pe baza primelor 20% dintre interogările care au cele mai multe afișări nu este cea mai bună pentru dvs., o puteți modifica.
Pentru a-l schimba, îl puteți crește sau micșora prin manipularea „.quantile(q=your_optimal_number, interpolation='lower')]'.
„you_optimal_number” trebuie să fie între 0 și 1.
De exemplu, dacă doriți să obțineți primele 30% dintre interogări, „your_optimal_num” este diferența dintre 1 și 0,3 (0,7).
'''
pentru i în interval (1, 11):
# O încercare, cu excepția gestionării acelor situații în care un director nu are date pentru unele poziții
încerca:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['afișări'] >= dir_grouped_df.get_group(i)['afișări']
.quantile(q=0,8, interpolare='inferioară')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append(tmp_df, ignore_index=True)
cu excepția KeyError:
mean_ctr_list.append(0)
# 1. Box plot
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} director CTR distribuție bazată pe poziție',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# Se afișează toate cele zece căpușe ale axelor x
box_fig.update_xaxes(tickvals=[i pentru i în interval (1, 11)])
# Schimbarea formatului de bifare a axelor y în procente
box_fig.update_yaxes(tickformat=".0%)")
# Salvarea graficului în directorul „Imagini grafice de ieșire”.
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
# 2. Trama de bare
bar_fig = px.bar(x=[pos pentru poz. în interval (1, 11)], y=mean_ctr_list, title=f'{key} directorul de distribuție CTR medie bazată pe poziție',
labels={'x': 'Poziție', 'y': 'CTR'}, text_auto=True)
# Se afișează toate cele zece căpușe ale axelor x
bar_fig.update_xaxes(tickvals=[i pentru i în interval (1, 11)])
# Schimbarea formatului de bifare a axelor y în procente
bar_fig.update_yaxes(tickformat='.0%')
# Salvarea graficului în directorul „Imagini grafice de ieșire”.
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
După definirea funcției de mai sus, avem nevoie de o buclă „for” pentru a trece peste datele directoarelor pentru care dorim să obținem curba lor CTR.
# Buclă peste directoare și executarea funcției „each_dir_plot”.
pentru cheie, articol din landings_grouped_df:
dacă tastați importante_directoare:
each_dir_plot(articol, cheie)
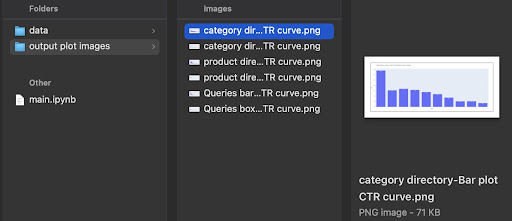
În ieșire, obținem diagramele noastre în folderul output plot images .
Sfat avansat!
De asemenea, puteți calcula curbele CTR ale diferitelor directoare utilizând pagina de destinație a interogărilor. Cu câteva modificări ale funcțiilor, puteți grupa interogări pe baza directoarelor paginilor de destinație ale acestora.
Puteți utiliza corpul solicitării de mai jos pentru a face o solicitare API în API Explorer (nu uitați limitarea de 25000 de rânduri):
{
„startDate”: „2022-01-01”,
„endDate”: „2022-02-01”,
"dimensiuni": [
"interogare",
"pagină"
],
„dimensionFilterGroups”: [
{
"filtre": [
{
„dimensiune”: „QUERY”,
"expresie": "nume_variație_marcă",
„operator”: „EXCLUDING_REGEX”
}
]
}
],
„rowLimit”: 25000
}
Sfaturi pentru personalizarea calculării curbei CTR cu Python
Pentru a obține date mai precise pentru calcularea curbei CTR, trebuie să folosim instrumente terțe.
De exemplu, pe lângă faptul că știți ce interogări au un fragment special, puteți explora mai multe funcții SERP. De asemenea, dacă utilizați instrumente terțe, puteți obține perechea de interogări cu rangul paginii de destinație pentru acea interogare, pe baza caracteristicilor SERP.
Apoi, etichetarea paginilor de destinație cu directorul lor rădăcină (părinte), gruparea interogărilor pe baza valorilor directorului, luând în considerare caracteristicile SERP și, în final, gruparea interogărilor în funcție de poziție. Pentru datele CTR, puteți îmbina valorile CTR din GSC cu interogările de la egal la egal.